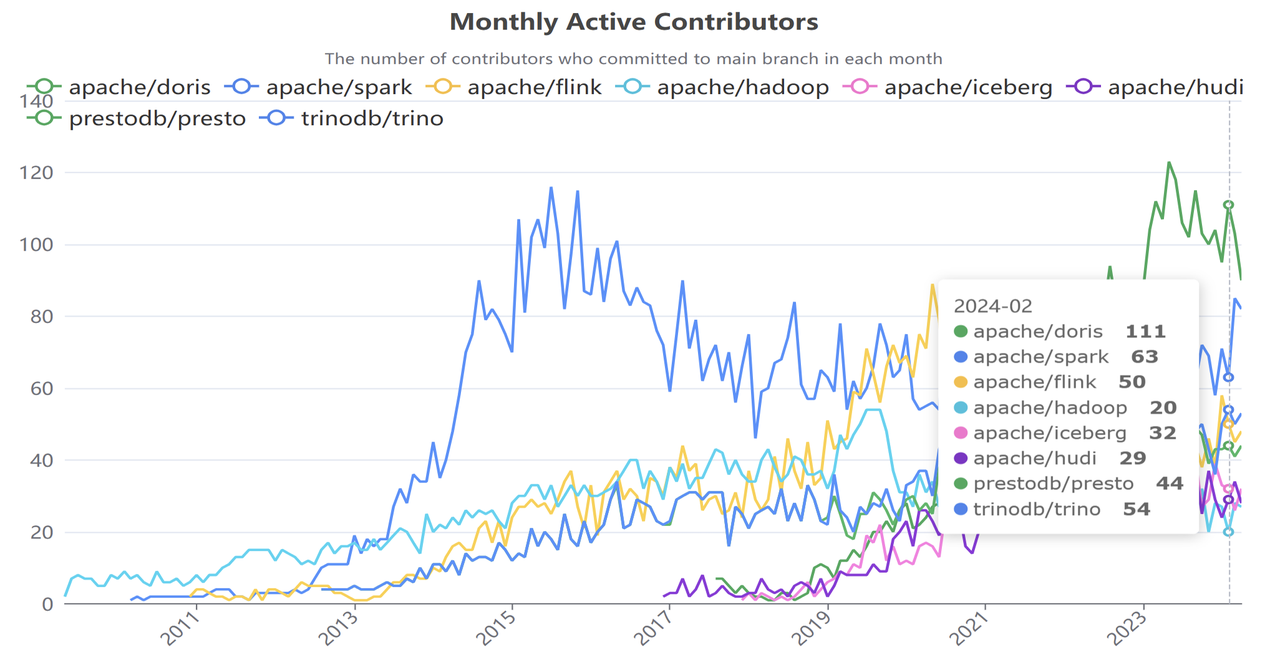
Apache Doris 是一款開源的 MPP 數據庫,以其優異的分析性能著稱,被各行各業廣泛應用在實時數據分析、湖倉融合分析、日志與可觀測性分析、湖倉構建等場景。Apache Doris 目前被 5000 多家中大型的企業深度應用在生產系統中,包含互聯網、金融、制造、電信、能源、物流、政務等行業。目前項目已在 GitHub 獲得超過 13000 Star,匯集 600 多名社區開發者,月度活躍貢獻者數量連續數月位居全球大數據開源項目榜首,成為全球大數據領域最活躍的開源項目之一。
SelectDB 是北京飛輪數據科技有限公司基于 Apache Doris 研發的現代化實時數據倉庫,提供包括面向私有化部署的 SelectDB Enterprise 和云原生存算分離的 SelectDB Cloud 云數倉服務。SelectDB 兼容 Apache Doris 的所有能力和接口,相比開源自建在安全、穩定、資源彈性等方面有明顯優勢。本文將對 Doris & SelectDB 適合的分析場景和技術能力進行概述解析。
1. Doris & SelectDB 典型分析場景
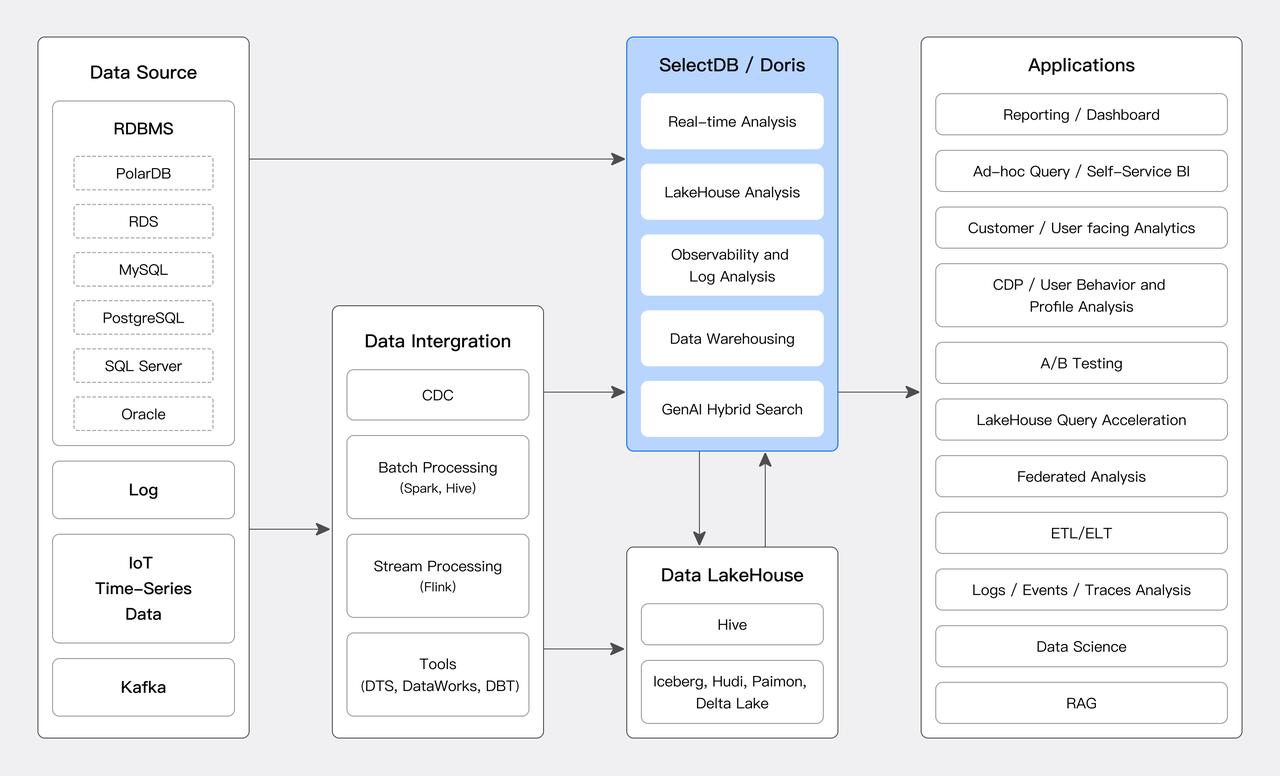
SelectDB & Doris 在如下的分析場景中通常是最優選擇:
- 實時分析
- 面向內部的實時報表和 Dashboard。
- Ad-Hoc 分析和自助式 BI。
- 面向終端客戶 / 用戶的高并發分析(Customer / User Facing Analysis):比如電商平臺面向數百萬廣告主 / 店鋪的數據分析、面向數十萬快遞員的分析,這類分析通常需要非常高的并發和較低的延時。
- 用戶行為和畫像分析(CDP,Customer Data Platform):分析用戶參與、留存、轉化等行為,A/B Testing,支持人群洞察和人群圈選等畫像分析,實現精細化的運營和精準的營銷。
- 湖倉融合分析
- 湖倉查詢和計算加速:作為查詢引擎直接查詢 Iceberg, Hudi, Paimon, DeltaLake, Hive 等湖倉中的數據,在不移動數據的情況下,實現查詢分析的數倍加速。
- 多源聯邦分析:作為統一的查詢網關,支持跨多個數據源查詢位于數據湖、數據倉庫、數據庫中的數據,實現聯邦查詢,簡化架構并消除數據孤島。
- 可觀測性和日志分析
- 實現對日志、事件、traces 的高效存儲和分析,替換 Elasticsearch, Loki, ClickHouse 等方案,實現數倍的性價比提升。
- 湖倉構建
- 對數據進行 ETL / ELT 實現數據的加工和建模,數據可以統一在 SelectDB & Doris 中存儲管理,也可以將加工處理過的數據回寫到 Iceberg,Hudi,Paimon,DeltaLake,Hive 等 Data LakeHouse 中,實現湖倉融合構建。
2. Doris & SelectDB 技術能力解析
2.1 極速
Doris & SelectDB 的查詢分析性能非常優異,在寬表聚合分析和復雜多表關聯場景中均表現突出:
- 在寬表聚合場景下,使用 SSB-FLAT benchmark 測試,相同資源下,是 ClickHouse 的 3.4 倍,是 Presto 的 92 倍,是業界標桿產品 Snowflake 的 6 倍。
- 在多表關聯場景下,使用 TPC-H benchmark 測試,相同資源下,其性能可達到 Redshift 的 1.5 倍,ClickHouse 的 49 倍,是業界標桿產品 Snowflake 的 2.5 倍,是 Greenplum 和 Presto 的 15 倍。
Doris & SelectDB 如此卓越的性能主要得益于以下技術加持:
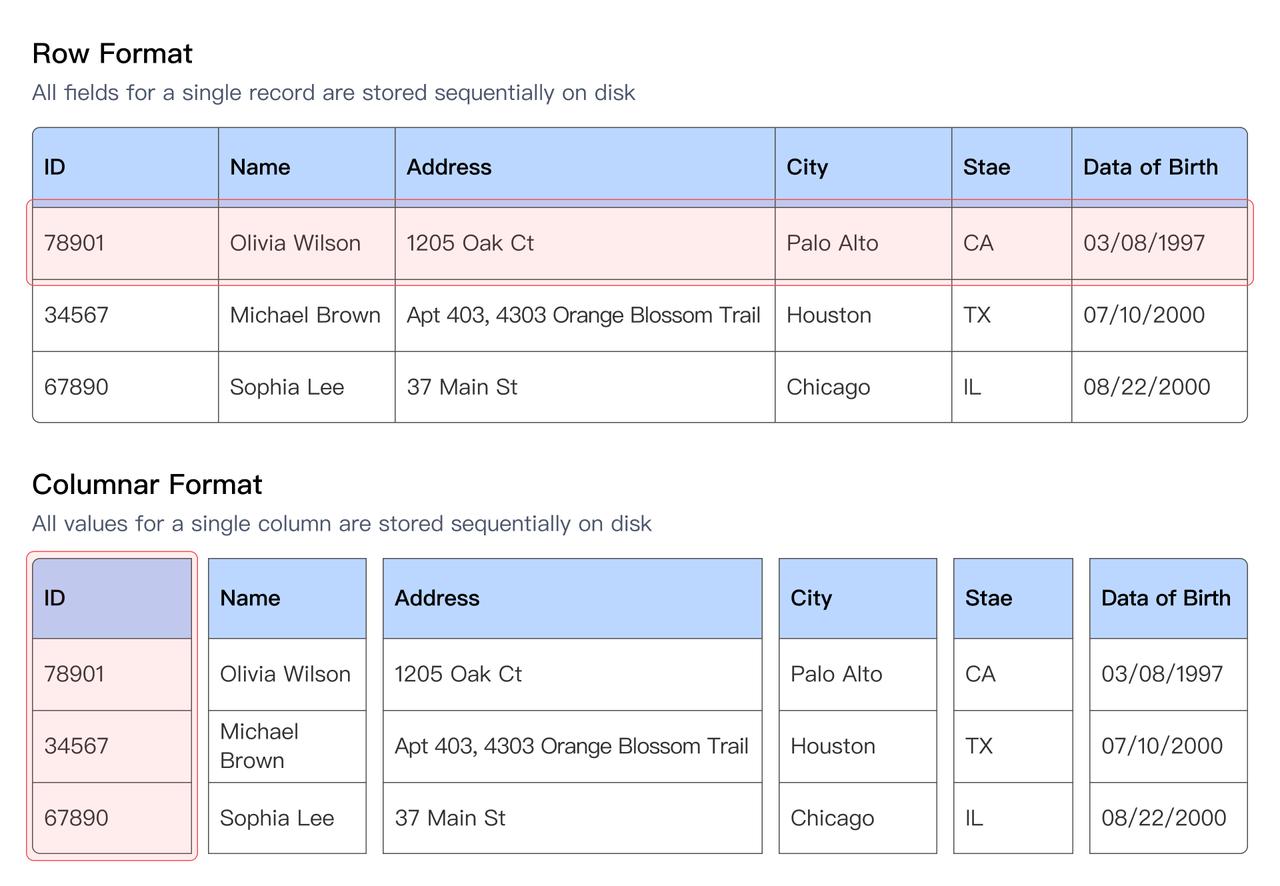
2.1.1 列式存儲
Doris & SelectDB 默認使用列式存儲組織數據,在數據分析場景下,相比行存儲通常有 5-10 倍的性能提升,這是因為:
- 只需要讀取 SQL 查詢涉及的列,不相關的列無需讀取和解壓過濾,大大降低了 IO 和 CPU 開銷。
- 同一列的數據類型一致,方便進行高效的數據編碼和壓縮。數值類型采用 RLE 編碼,字符串使用字典編碼。編碼后使用 LZ4 或者 ZSTD 等壓縮算法壓縮,大幅減少了數據存儲空間,也節省了讀取 IO。
2.1.2 豐富的索引
Doris & SelectDB 支持豐富的索引機制,通過索引機制,可以大幅減少對不相關數據的讀取和處理,從而能夠大幅提升性能。從加速的查詢和原理來看,Doris & SelectDB 的索引分為點查索引和跳數索引兩大類。
-
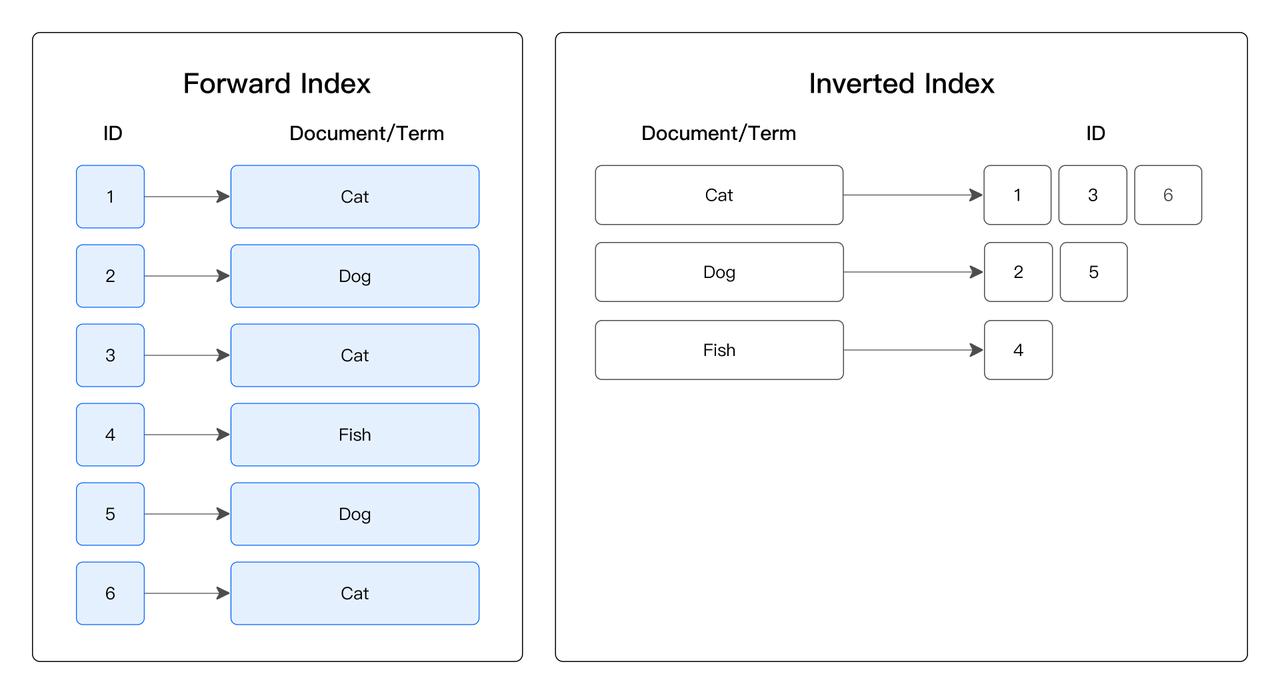
點查索引:常用于加速點查。 其原理是通過索引定位到滿足 WHERE 條件的位置,直接讀取其所在行。點查索引在滿足條件的行數較少時,效果尤為顯著。其點查索引包括前綴索引和倒排索引。
- 前綴索引:按照排序鍵以有序的方式存儲數據,并每隔 1024 行數據創建一個稀疏前綴索引。索引中的 Key 是當前 1024 行中第一行中排序列的值。如果查詢涉及已排序列,系統將找到相關 1024 行組的第一行,并從該行開始掃描。
- 倒排索引:對創建了倒排索引的列,建立每個值到對應行號集合的倒排表。對于等值查詢,先從倒排表中查到行號集合,然后直接讀取對應行的數據,而無需逐行掃描匹配數據,從而減少 I/O 、加速查詢。倒排索引還能加速范圍過濾、文本關鍵詞匹配,算法更加復雜但基本原理類似。
-
**跳數索引:常用于加速分析。**原理是通過索引確定不滿足 WHERE 條件的數據塊,跳過這些不滿足條件的數據塊,只讀取可能滿足條件的數據塊并再進行一次逐行過濾,最終得到滿足條件的行。跳數索引在滿足條件的行比較多時效果較好。其跳數索引包括 ZoneMap 索引、BloomFilter 索引、NGram BloomFilter 索引。
- ZoneMap 索引:自動維護每一列的統計信息,為每一個數據文件(Segment)和數據塊(Page)記錄最大值、最小值、是否有 NULL、Sum。對于等值查詢、范圍查詢、IS NULL,可以通過最大值、最小值、是否有 NULL 來判斷數據文件和數據塊是否可以包含滿足條件的數據,如果沒有則跳過不讀對應的文件或數據塊減少 I/O 加速查詢。比如下方 SQL 所示,有一個過濾條件
a<='100101',總共有三個數據塊,第一個數據塊通過讀 ZoneMap 索引發現,最大值是 100101,整個數據塊都滿足條件,那么直接從 ZoneMap 中取得 sum 結果作為第一個數據塊的聚合結果,不需要讀取和解壓數據塊。而第三個數據塊 ZoneMap 記錄的最小值都不滿足過濾條件,所以第三個數據塊直接排除。最終只需要解壓、過濾和聚合第二個數據塊。
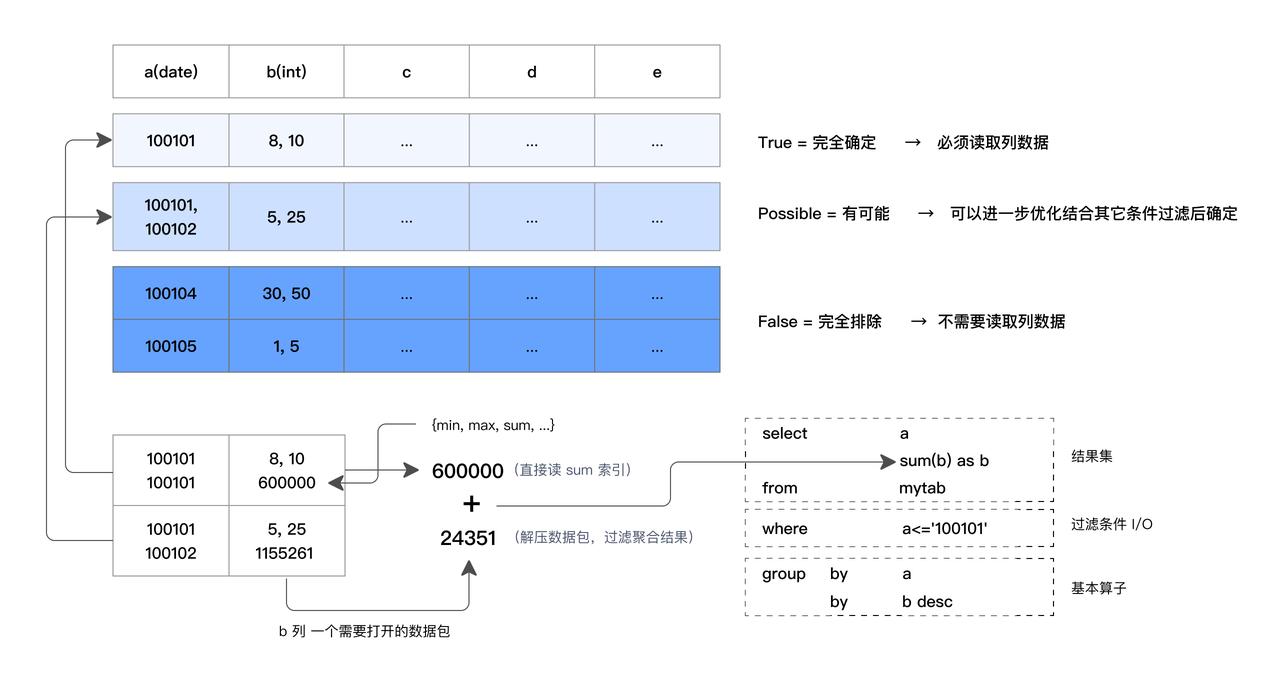
-
BloomFilter 索引:將索引對應列的可能取值存入 BloomFilter 數據結構中,它可以快速判斷一個值是否在 BloomFilter 里面,并且 BloomFilter 存儲空間占用很低。對于等值查詢,如果判斷這個值不在 BloomFilter 里面,就可以跳過對應的數據文件或者數據塊減少 I/O 加速查詢。
-
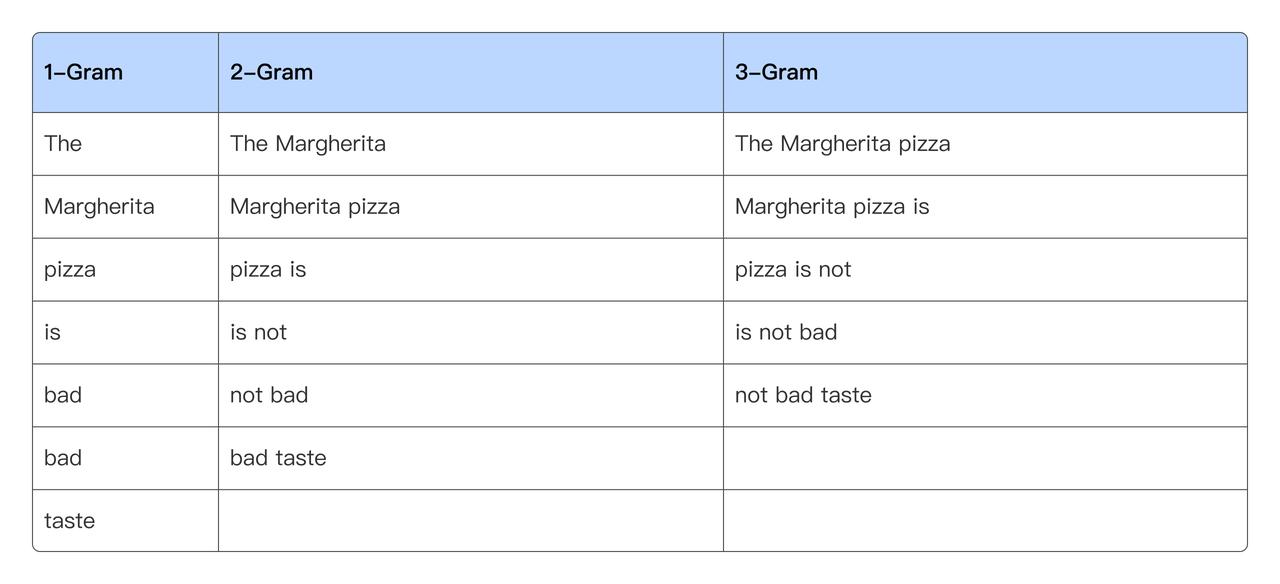
NGram BloomFilter 索引:用于加速文本 LIKE 查詢,基本原理與 BloomFilter 索引類似,只是存入 BloomFilter 的不是原始文本的值,而是對文本進行 NGram 分詞,每個詞作為值存入 BloomFilter。對于 LIKE 查詢,將 LIKE 的 pattern 也進行 NGram 分詞,判斷每個詞是否在 BloomFilter 中,如果某個詞不在,則對應的數據文件或者數據塊就不滿足 LIKE 條件,可以跳過這部分數據減少 I/O 加速查詢。
- ZoneMap 索引:自動維護每一列的統計信息,為每一個數據文件(Segment)和數據塊(Page)記錄最大值、最小值、是否有 NULL、Sum。對于等值查詢、范圍查詢、IS NULL,可以通過最大值、最小值、是否有 NULL 來判斷數據文件和數據塊是否可以包含滿足條件的數據,如果沒有則跳過不讀對應的文件或數據塊減少 I/O 加速查詢。比如下方 SQL 所示,有一個過濾條件
2.1.3 MPP 架構
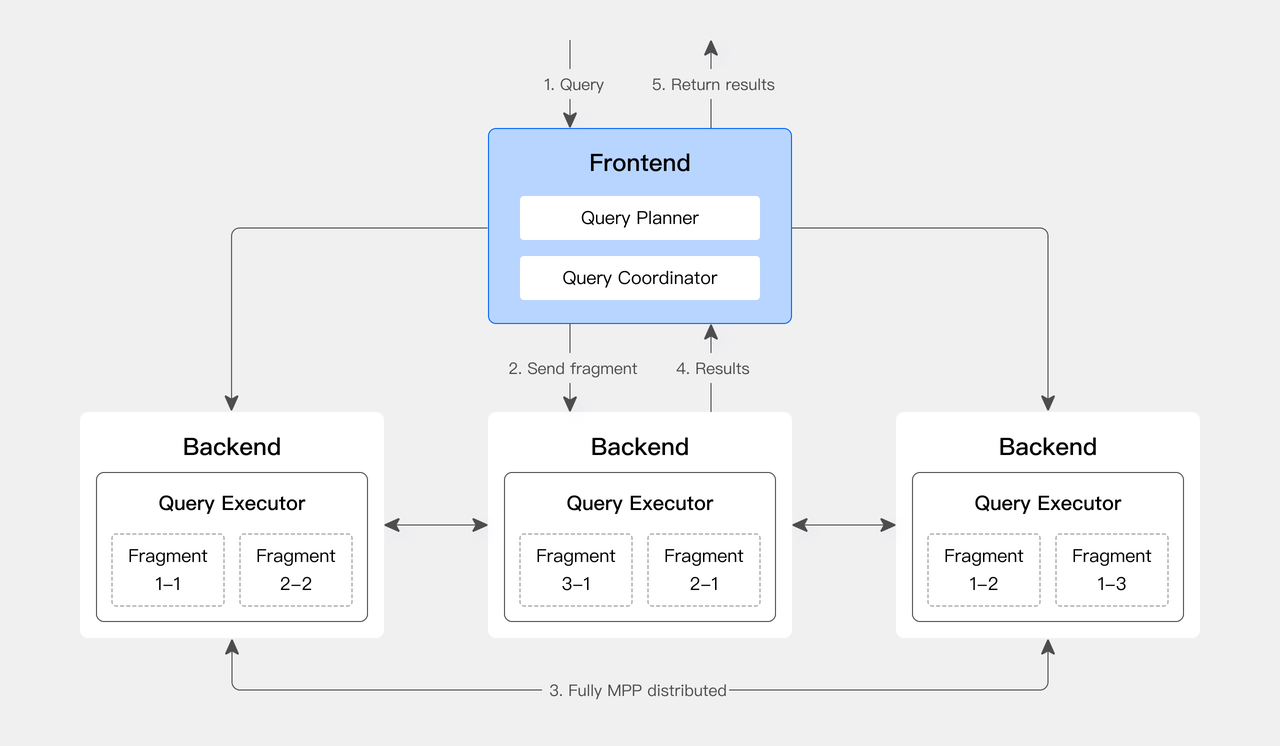
Doris & SelectDB 采用大規模并行處理(MPP)架構,一個 SQL 會被拆分成多個執行分片,分發到不同的機器上并行執行,節點內還支持多核的并行執行,將集群資源利用最大化。對于多張大表的 Join 操作,能夠通過 Shuffle 機制將數據打散到多個節點上進行,從而有效應對復雜查詢。
2.1.4 向量化引擎
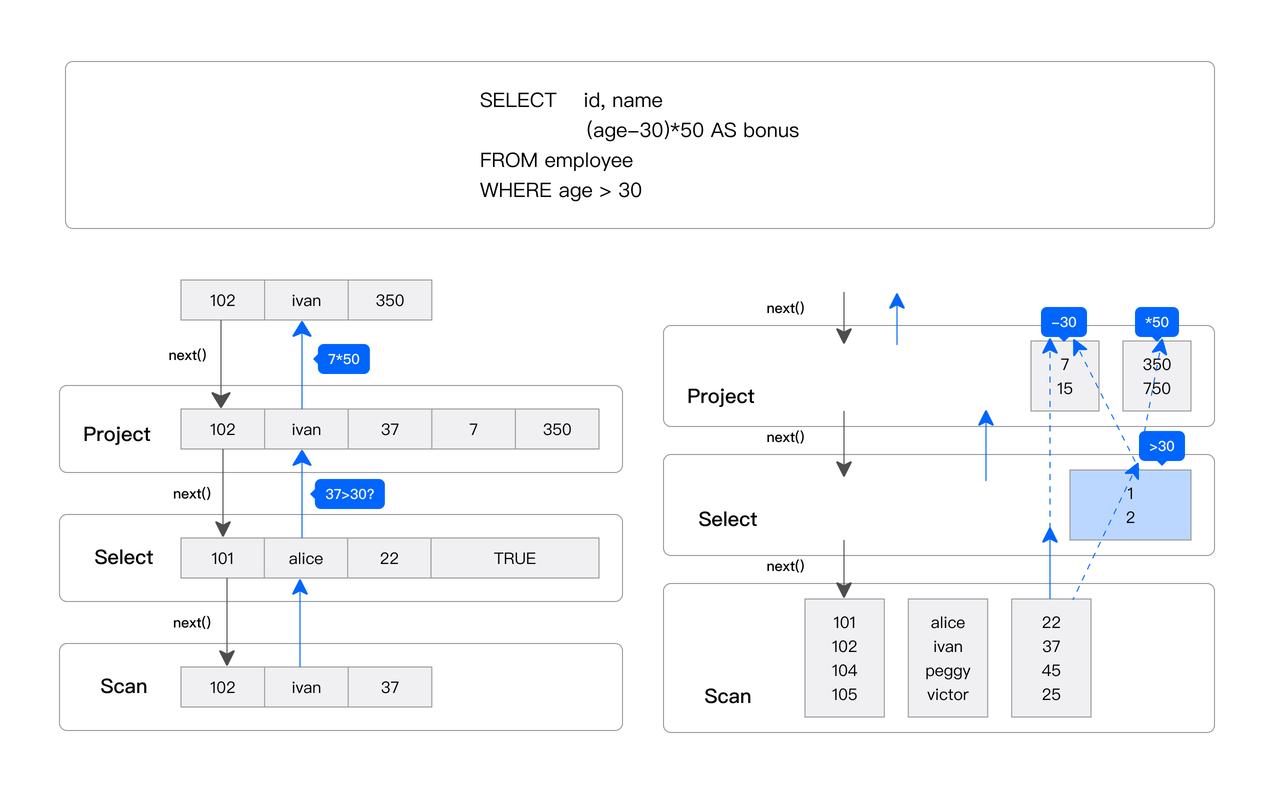
Doris & SelectDB 查詢引擎是向量化引擎,所有內存結構均按列式布局。它一次處理一批數據,而非逐條處理,可顯著減少虛函數調用、提高緩存命中率,并有效利用 SIMD 指令、充分采用延遲物化技術,進一步優化性能。比如下面一條 SQL ,左側是傳統的逐行處理的火山模型引擎,右側是 Doris & SelectDB 純向量化 + 延遲物化處理引擎,一次處理一個批量,在拼算子性能的寬表聚合場景下,向量化引擎帶來的性能提升多達 5-10 倍。
2.1.5 PipeLine 執行
采用 Pipeline 執行機制,該技術主要通過減少阻塞,數據流驅動的方式,以高并發原理充分提高查詢和數據處理的效率。其核心思想是將復雜的查詢或數據處理任務分解為多個階段或操作(稱為 PipeLine Task),每個階段負責處理數據的某個特定部分,例如過濾、投影、聚合或排序,通過并行或重疊執行這些步驟來加速整體處理過程。
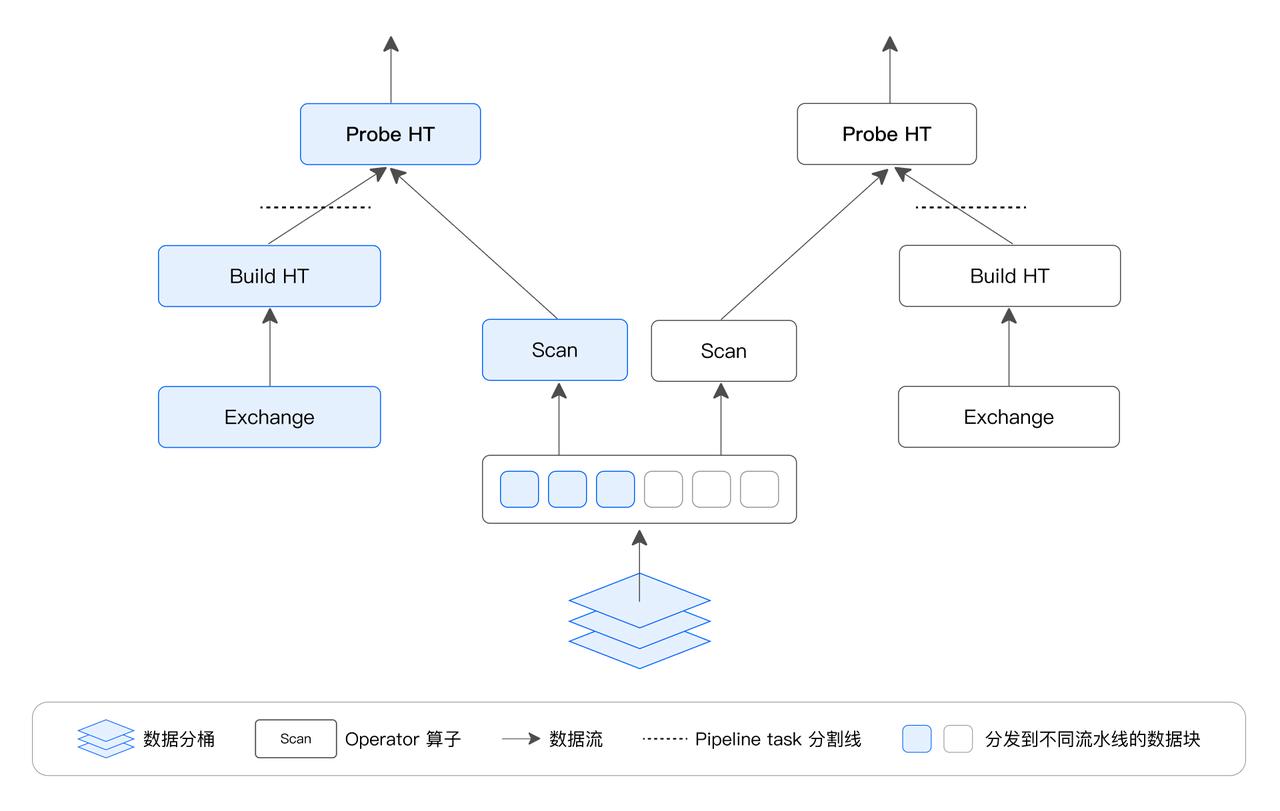
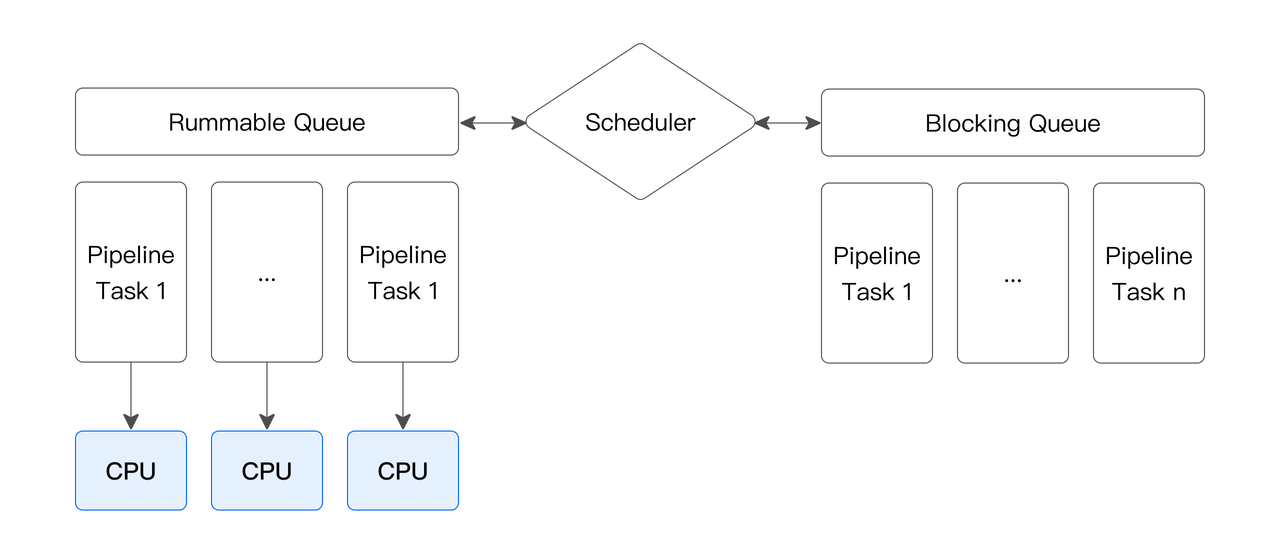
Pipeline 執行模型通過阻塞邏輯將執行計劃拆解成 Pipeline Task,將 Pipeline Task 分時調度到線程池中,實現了阻塞操作的異步化,解決了 Instance 長期占用單一線程的問題。同時,可以采用不同的調度策略,實現 CPU 資源在大小查詢間、不同租戶間的分配,從而更加靈活地管理系統資源。Pipeline 執行模型還采用了數據池化技術,將單個數據分桶中的數據進行池化和重分布,從而解除分桶數對 Instance 數量的限制,提高其對多核系統的利用能力,同時避免了線程頻繁創建和銷毀的問題,提高了系統的并發性能和穩定性。
2.1.6 智能優化器
Doris & SelectDB 采用 Cascades + Dphyper 混合智能枚舉框架,優化大規模查詢計劃,并結合基于規則的和基于代價的查詢改寫、函數依賴優化及分布式執行優化,提升查詢性能。同時,通過精準統計信息與動態調優,增強對業務場景的適配性,確保高效查詢執行。

- Cascades 和 Dphyper 混合智能枚舉框架 : Doris & SelectDB 優化器基于 Cascades 自頂向下枚舉框架,具備解耦、易擴展和提前剪支的優勢。為優化枚舉空間,采用 project 規范化和 group 合并策略,避免無效計劃膨脹。對于 8 張表以內的查詢,進行完整的 Cascade 枚舉,并引入 Dphyper 算法覆蓋 8-64 張表規模,通過圖簡化降低枚舉成本,確保高效查詢優化。總體而言,Doris & SelectDB 的 Cascades + Dphyper 混合枚舉框架,能夠支持 64 張表的大規模復雜查詢,提供卓越性能保障。
- 基于代價和規則的查詢改寫:支持豐富的改寫能力包含謂詞下推、常量折疊、分區/列裁剪、外連接消除、謂詞推導、子查詢提升、Limit 下壓、物化 CTE、窗口函數消除子查詢、Set 算子 Distinct 推導、Distinct 下壓、OR-expansion 等。
- 基于 FD 等屬性信息的優化:其優化器維護了多種邏輯屬性,如函數依賴、唯一性、均勻性和等值集合等,以支持多種優化規則的執行。例如,基于函數依賴屬性,Doris & SelectDB 優化框架能夠實現如 Group By Key/Order By Key/Join Elimination 等高效優化,從而顯著減少查詢計算量,大幅提升查詢性能。
- 深度的分布式查詢優化: Doris & SelectDB 在分布式查詢優化方面進行了深度優化。除了支持傳統的高效連接算法,如 colocate join 和 bucket shuffle join 外,還通過分析中間結果數據的分布特性,增強了聚合、連接和窗口函數等分布式查詢計劃,能夠智能識別數據特征,避免無效的數據重分布,從而提升查詢性能。
- 精準的統計信息管控和動態調優: 主流優化器依賴統計信息和代價模型選擇最優執行計劃,但在頻繁更新的數據場景或數據湖中,靜態統計信息易失效,影響計劃質量和查詢性能。Doris & SelectDB 通過精準控制統計信息的時效性,避免采集無效數據,防止低效計劃生成。此外,在缺乏列統計信息時,采用啟發式連接重排優化查詢,提升數倉及數湖場景適配性。同時,也在引入歷史執行反饋(HBO),實現統計信息校準和動態調優,進一步優化查詢性能。
2.1.7 物化視圖
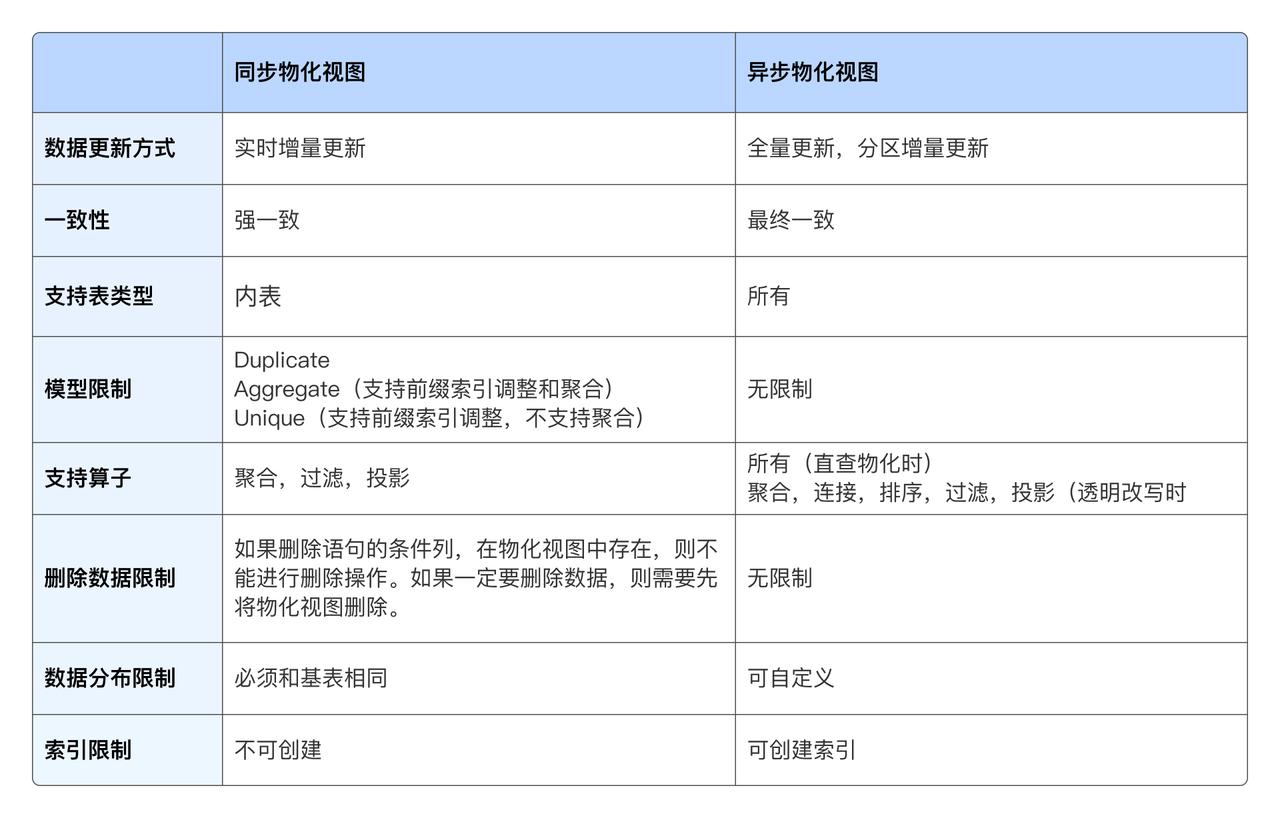
在數據分析中,物化視圖采用空間換時間的策略,提供了有效的查詢加速方案,兼具視圖的靈活性和物理表的高性能。它可以預先計算并存儲查詢結果集,從而在查詢請求到達時直接從物化視圖中獲取結果,而無需重新執行查詢語句。這種機制有效提升了查詢性能,降低了重復執行查詢的開銷。
Doris & SelectDB 支持兩種物化視圖:同步物化視圖和異步物化視圖。 前者能夠保持物化視圖和基表數據同步一致,但只支持單表,適合單表聚合查詢的分析加速。后者能夠支持多表以及復雜查詢,但是物化視圖更新滯后于基表(兩者最終一致),并支持對多表物化視圖的手動刷新和按照分區級別增量自動更新。下面對其物化視圖特性和適用場景的總結:
2.1.8 多級緩存
緩存技術是有效的加速手段,Doris & SelectDB 支持多級緩存機制:SQL 的最終結果、聚合結果緩存、原始數據緩存、存算分離和數據湖分析場景下的本地文件緩存。通過多級緩存機制,能夠最大程度實現數據的復用,減少不必要的執行和 IO,最大化系統性能。
- SQL Cache : 用于緩存 SQL 查詢的結果,特別適用于重復執行相同查詢的場景,例如報表生成或儀表盤應用。它根據 SQL 簽名、查詢表的分區 ID 以及分區的最新版本來緩存結果。只有當 SQL 語句完全一致時,緩存才會命中。這種緩存特別適合更新頻率不高的場景(比如 T+1),對于實時更新場景,盡管支持,但是命中率可能較低。
- Query Cache(聚合結果緩存 ):在處理聚合查詢時,都會將本地聚合的中間結果緩存于內存中。這樣,當后續收到相同或類似的聚合查詢時,能夠直接從 Query Cache 獲取匹配的聚合結果,無需再次從磁盤讀取并計算數據。
- Page Cache : 使用內存來緩存最近頻繁讀取的數據,這里面緩存的都是經過解壓之后的數據,這種緩存在優化 IO 的同時,也避免了 CPU 的解壓開銷。在高并發查詢場景下,優化效果尤為明顯。
- File Cache : 在存算分離和數據湖分析場景下,File Cache 通過緩存最近訪問的遠程存儲系統(如 HDFS 或對象存儲)中的數據文件來加速查詢,減少頻繁從遠程獲取數據的昂貴開銷。文件緩存將數據塊存儲在 Backend(BE)節點本地,并使用 LRU(最近最少使用)策略管理空間,顯著提升了熱點數據的查詢性能和穩定性。
2.1.9 分區分桶
**Doris & SelectDB 支持兩層數據劃分:分區和分桶。**通過分區分桶機制能夠有效將數據和負載劃分到多個節點上,以提升系統的擴展性和并行處理能力,與此同時也有利于對查詢進行分區分桶裁剪,減少非必要的數據掃描,從而提升系統的性能和高并發處理的能力。如下圖所示,以下查詢通過分區鍵 day裁剪掉不相關分區,通過分桶鍵id裁剪掉不相關分桶。
SELECT * FROM user_table
WHERE id = 5122 and day = '2022-01-01';

2.1.10 聚合模型
Doris & SelectDB 支持多種表模型,其中聚合模型是一種表模型,允許用戶在建表時指定聚合鍵(Aggregate Key)和聚合函數。在數據導入過程中,會根據聚合鍵對數據進行分組,并對每個分組應用指定的聚合函數進行預聚合。預聚合后的結果會被存儲,查詢時可以直接使用這些結果,而無需在運行時掃描和計算原始數據,從而優化查詢性能。這一技術通常被應用在一些指標分析的場景中。
2.1.11 高并發點查優化
在高并發點查的 DataServing 場景,Doris & SelectDB 特別做了幾項優化,使得高并發點查的單節點 QPS 提升到萬級別,并且可以隨著節點數線性擴展,具體來說:
- 行列混合存儲: 針對點查詢需求,支持在列式存儲基礎上另存行存格式數據,整行數據可直接讀取,減少單次點查詢的隨機 I/O 放大問題。
- 點查詢短路徑優化(Short-Circuit Path): 跳過傳統 MPP 查詢框架的復雜調度流程,直接通過輕量級執行計劃(Short-Circuit Plan)快速返回結果。例如,FE 解析 SQL 后,若查詢符合條件(如基于主鍵的等值查詢),直接生成短路徑計劃,減少 FE 資源消耗和網絡開銷。
- 預處理語句(Prepared Statement): 復用已解析的 SQL 結構和表達式,避免重復解析。例如,高并發場景下,FE 通過會話級緩存存儲預處理語句,降低 CPU 開銷,提升吞吐量。
2.2 實時
2.2.1 實時導入
數據從產生到能夠進入到 Doris & SelectDB 進行分析的實時性要求越來越高,尤其是在電商實時大屏、物聯網設備監控、金融分控系統等業務中。其提供了多種實時數據導入的機制,并且也在持續優化底層技術,來達到更好的時效性和并發吞吐。
- 流式同步:通過實時數據流(如 Flink、Kafka、事務數據庫)將數據實時導入到 Doris & SelectDB 表中,適用于需要實時分析和查詢的場景。
- 可以使用 Flink Doris Connector 將 Flink 的實時數據流寫入到 Doris & SelectDB 表中。
- 可以使用 Routine Load 或者 Doris Kafka Connector 將 Kafka 的實時數據流寫入到 Doris & SelectDB 表中。
- 可以使用 Flink CDC 或 Datax 將事務數據庫的 CDC 數據流寫入到 Doris & SelectDB 中。
- Stream Load:導入本地文件或者程序通過 HTTP 寫入數據到 Doris & SelectDB 中,既能夠保證時效性也能夠保證高吞吐,最快可達到秒級別可見。
- 數據集成工具導入:DTS、DataWorks 等數據集成工具也支持集成數據到 SelectDB
此外,還支持通過 JDBC INSERT 方式實時寫入數據,但該方式吞吐不優并不推薦。對于大批量數據寫入和高吞吐場景支持其他機制,包括通過數據湖 Insert Into Select 方式或 Broker Load 方式,來批量導入 HDFS 或對象存儲上的數據。
為保障實時導入效率,其進行了多項技術創新:
- Group Commit 事務合并: 將多個小批量寫入合并為單個事務提交,減少事務開銷,顯著提升高并發寫入性能。
- MemTable 前移優化: 在寫入協調端進行 MemTable 的構建,減少數據編碼次數和優化內存反壓策略,降低寫入延遲并提升穩定性
2.2.2 實時更新
在實時數據倉庫的業務場景中,支持數據的實時更新是核心能力之一。例如在數據庫同步(CDC)、電商交易訂單、廣告效果投放、營銷業務報表等業務場景中,面對上游數據的變化,通常需要快速獲取到變更記錄并針對單行或多行數據進行及時變更,保證業務分析師及相關分析平臺能快速捕捉到最新進展,提升業務決策的及時性。
傳統的大數據分析系統解決這類問題通常比較吃力,很多系統只能做到分區級別的更新。Doris & SelectDB 針對實時數據更新做了系統性優化,相比于傳統的 Merge-on-Read 或者 Copy-on-Write 的方案,Doris & SelectDB 采用的 Merge-on-Write 的方案使用記錄刪除標記和更新增量的方式,在查詢性能和更新性能方面取得了最佳平衡。
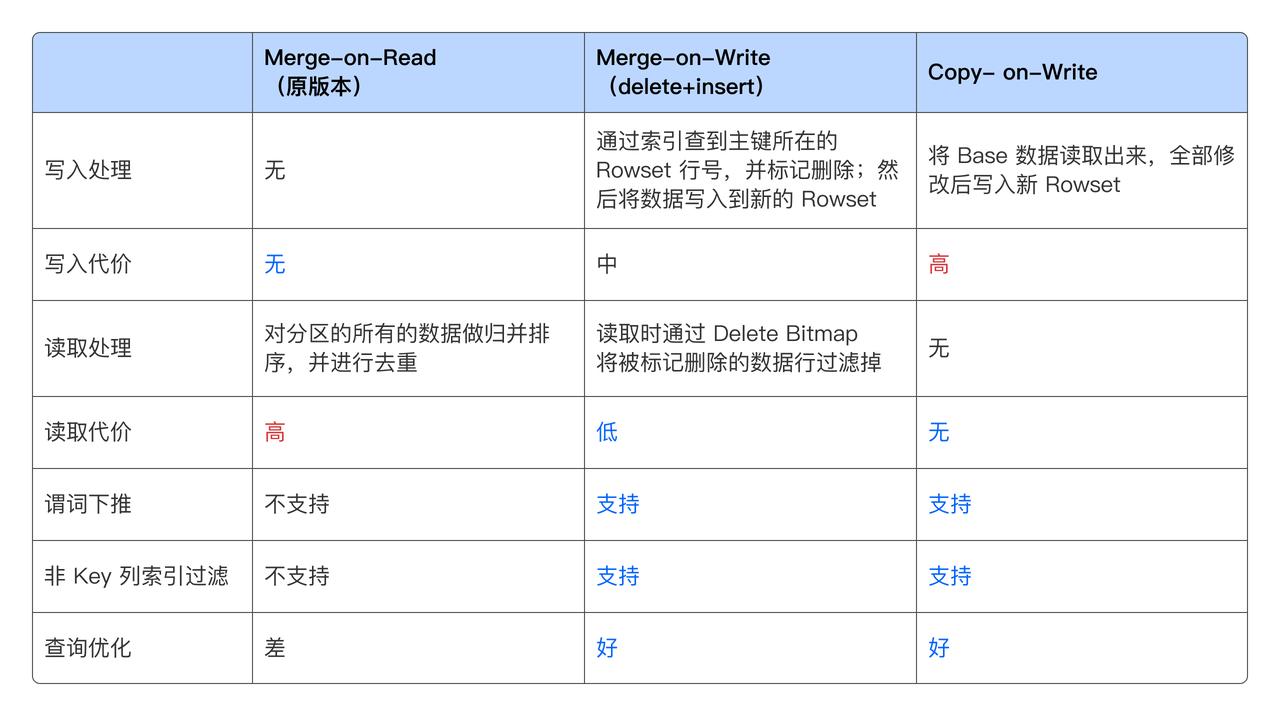
除了整行更新的模式,Doris & SelectDB 也支持部分列更新的模式,進一步優化了使用體驗。
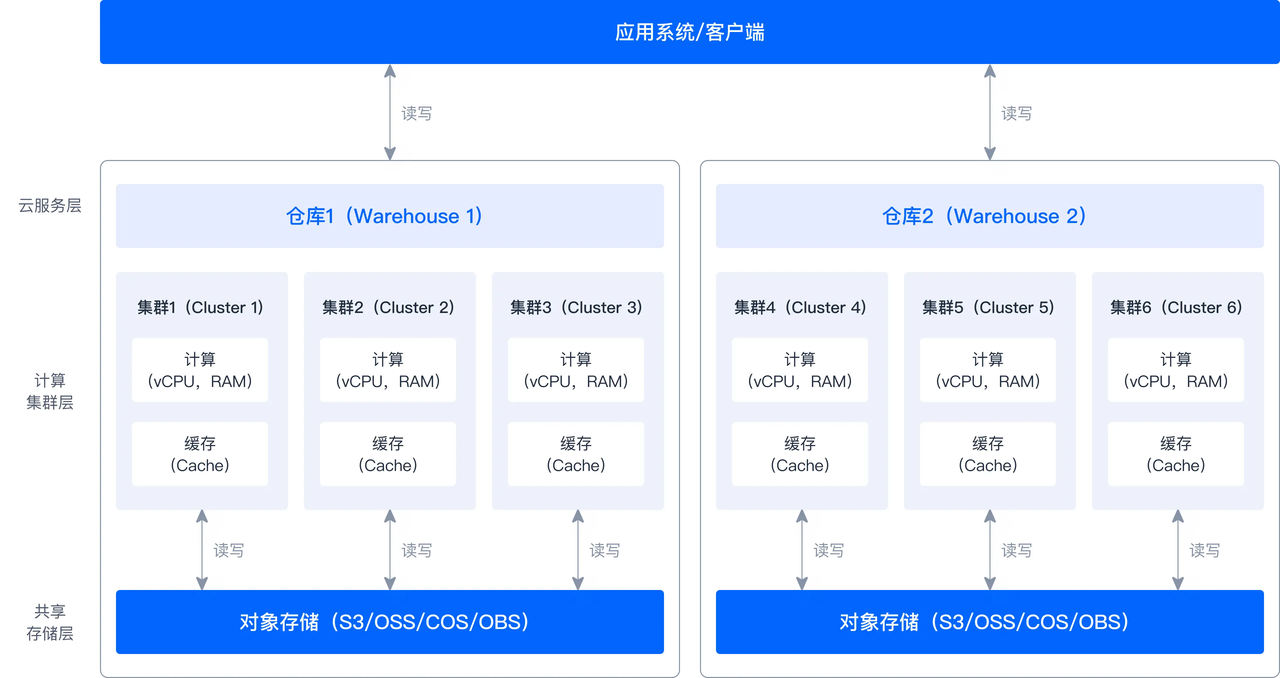
2.3 云原生
云計算基礎設施的成熟帶來了許多獨有的優勢,例如可根據需要快速增加或減少資源,無需擔心基礎設施的限制,只需為實際使用付費;又如提供了靈活多樣的存儲介質,可針對實際需求配置不同性能、不同價格的存儲。SelectDB Cloud 采用存算分離模式,將計算資源和存儲資源分開管理,從而更好地發揮云計算平臺的強大功能。 此外,Apache Doris 及 SelectDB Enterprise 在 3.0 版本開始也支持了存算分離架構。
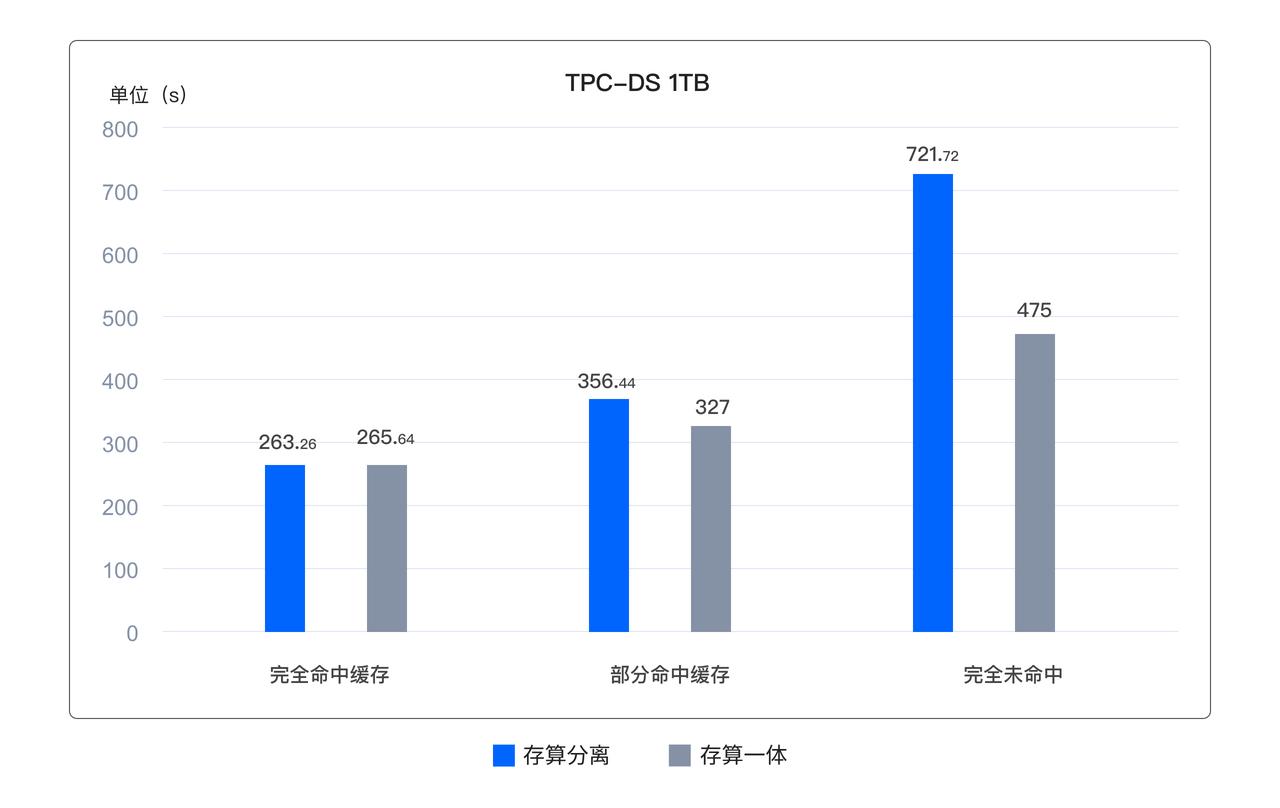
- 更低成本:與存算一體架構相比,存算分離架構綜合成本降低超 90%
- 按需付費:相較于存算一體,無需再預置計算和存儲資源,存儲可按實際使用付費,計算資源則可以靈活彈性擴展。
- 單副本存儲:數據僅需在低成本的對象存儲中存儲一份副本,而不再在高成本的塊存儲中存儲三個副本。熱數據則緩存于塊存儲中,這不僅降低了存儲量和硬件資源需求,還顯著降低了存儲成本(例如,云廠商的云盤價格通常是對象存儲的數倍),同時保證了查詢性能。
- 資源消耗降低:Compaction 操作所消耗的資源和副本數量成正比,在存算分離模式下只需要處理單一數據副本,資源消耗大幅減少。
- 極致彈性:得益于無狀態的計算節點設計,能夠更加靈活地應對不斷變化的業務需求,提供高效、彈性的計算資源管理
- 彈性擴縮容:支持靈活調整計算資源,更好應對業務高峰或波動。當系統負載增加時,計算節點可以迅速擴容;而在需求減少時,計算資源又可以靈活縮減,從而避免不必要的資源浪費。
- 計算節點按需分配:支持將不同配置的計算節點靈活分配到各計算組中,根據任務需求精確分配資源。例如,高性能計算節點被用于復雜查詢或高并發場景,而標準配置節點分配于簡單查詢或低頻請求。
- 負載隔離:提供高效的資源管理和負載隔離,為不同業務需求提供精細化的計算資源調度
- 業務間負載隔離:針對不同業務需求,可為每業務配置獨立計算組,并實現物理隔離。確保各業務計算任務在專用資源上運行,減少相互干擾,保障系統的穩定性和高效性。
- 離線負載隔離:對于大規模離線數據處理任務,可將其分配到特定的計算組,使用低成本的資源進行批量數據處理,而不影響實時業務的計算性能。
- 讀寫隔離:可分別為讀、寫操作創建計算組和用戶。寫計算組專門處理數據寫入(插入、更新等),而讀計算組專門處理查詢請求,確保在線業務的查詢延遲穩定。
在存算分離的架構中,數據需要從遠端共享存儲系統中讀取,是否會對查詢性能造成影響是客戶普遍關注的問題。為了加速數據訪問,Doris & SelectDB 實現了基于本地磁盤的高速緩存機制,并提供 LRU 和 TTL 兩種高效的緩存管理策略,并對索引相關的數據進行了優化,旨在最大程度上緩存用戶常用數據、提升查詢性能,并且能夠在多 Cluster 之間推送緩存,實現主動預熱。在實際的評測中,只要緩存配比合理,性能并未明顯降低。即使在沒有 Cache 完全從對象存儲冷讀的場景下,性能損失也只有 35%左右,相比業界同類系統有顯著優勢。
2.4 湖倉融合
除了將數據導入到 Doris & SelectDB 內進行高效分析外,Doris & SelectDB 還可以當做一個湖倉的計算和查詢(Data Lakehouse Compute & Query Engine)直接對位于 Data Lakehouse、數據庫、離線數據倉庫中的數據進行計算和查詢,在不進行數據移動的情況下,打通湖倉和數據庫的邊界,實現統一的查詢加速和多源聯邦分析,達到數據無界、湖倉融合的效果。
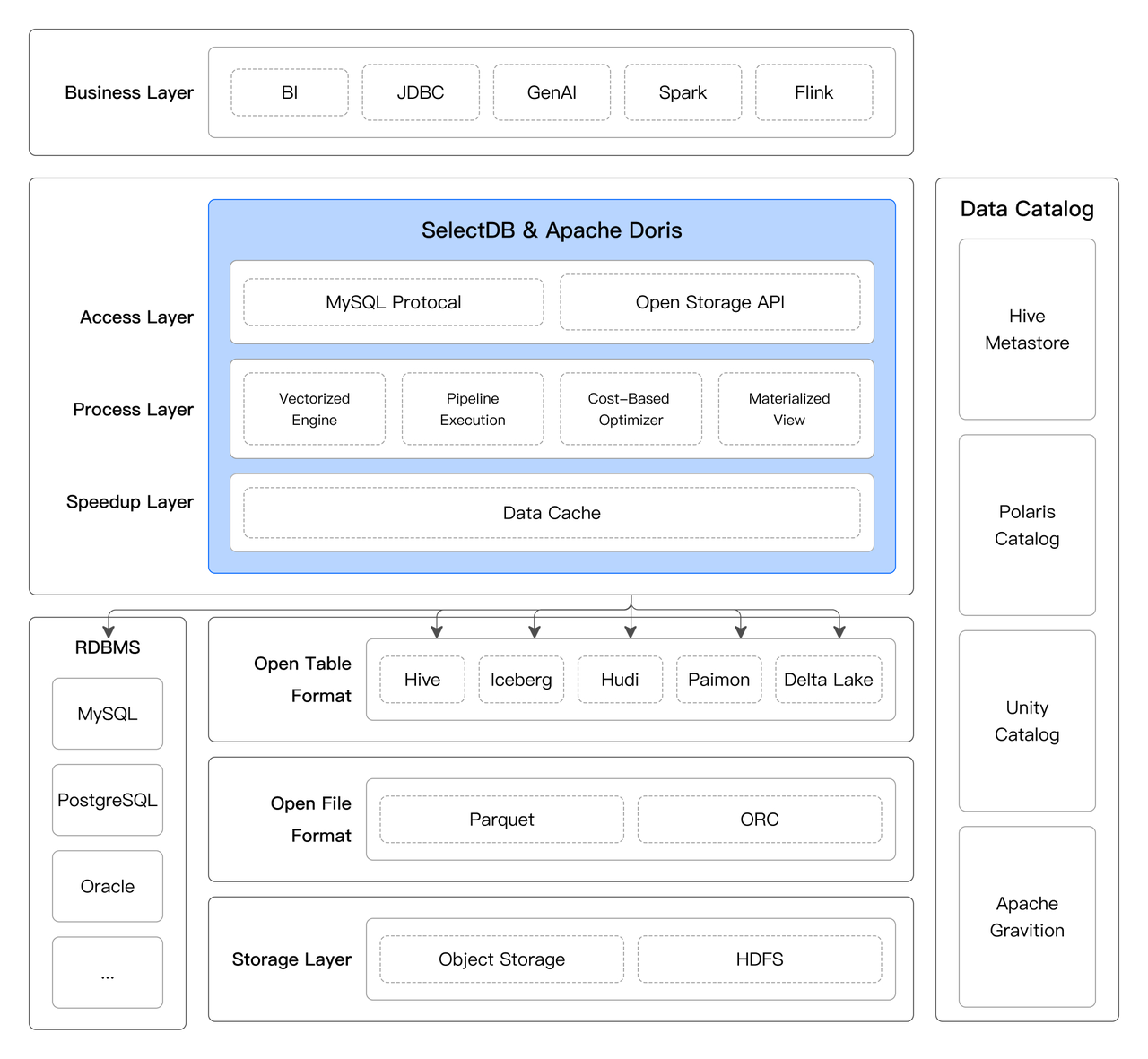
2.4.1 全面的數據打通
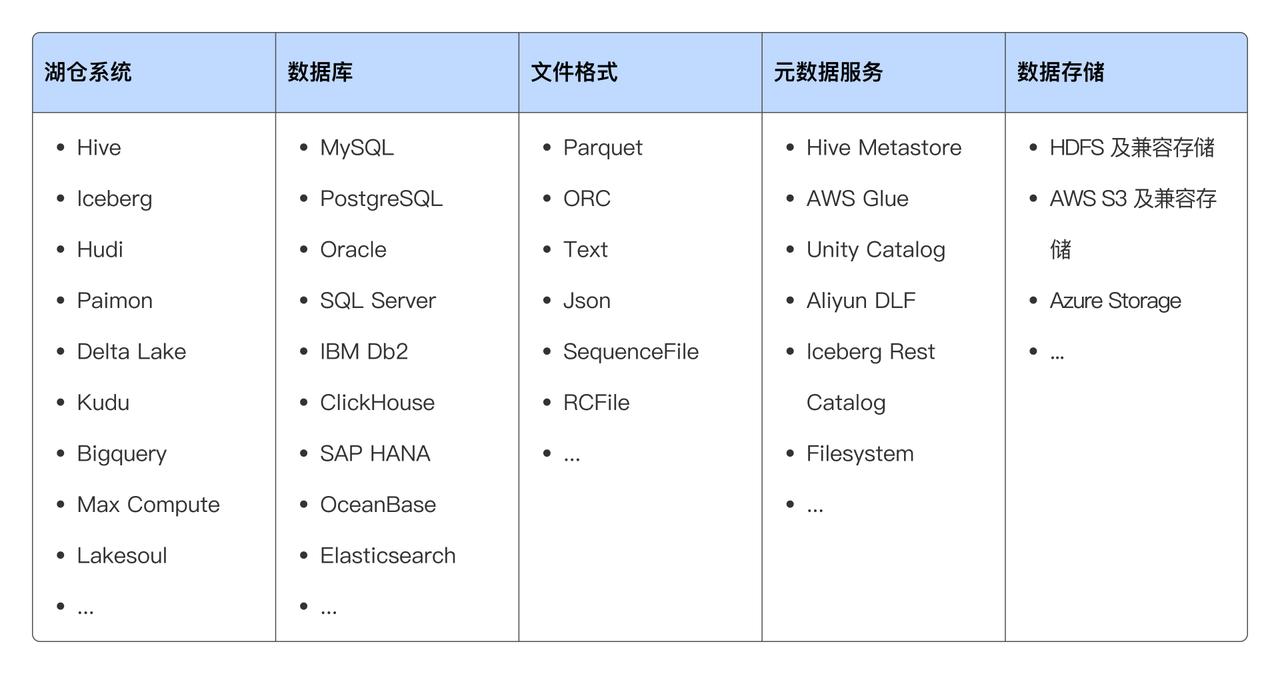
Doris & SelectDB 通過 Multi-Catalog 和 可擴展的連接器框架,支持主流數據系統和數據格式,并提供基于 SQL 的統一數據分析能力,用戶能夠在不改變現有數據架構的情況下,輕松實現跨平臺的數據查詢與分析。
2.4.2 湖倉加速效果
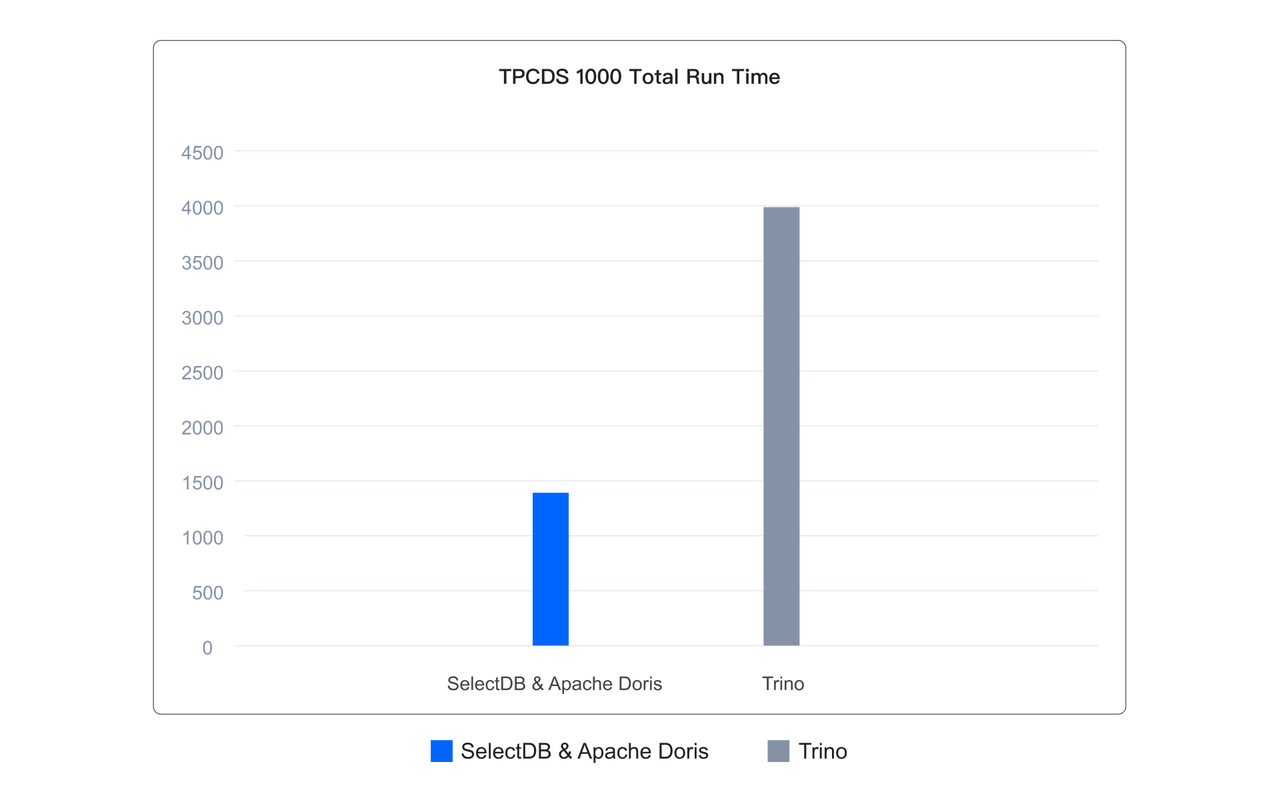
得益于上面提到的各種極速查詢的技術,當使用 Doris & SelectDB 作為湖倉計算和查詢引擎的時候,相比 Presto、Trino、SparkSQL、Hive 等引擎,通常有數倍的性能提升,如下所示,在基于 Iceberg 表格式的 1TB 的 TPCDS 標準測試集上,其執行 99 個查詢的總體運行耗時僅為 Trino 的 1/3。
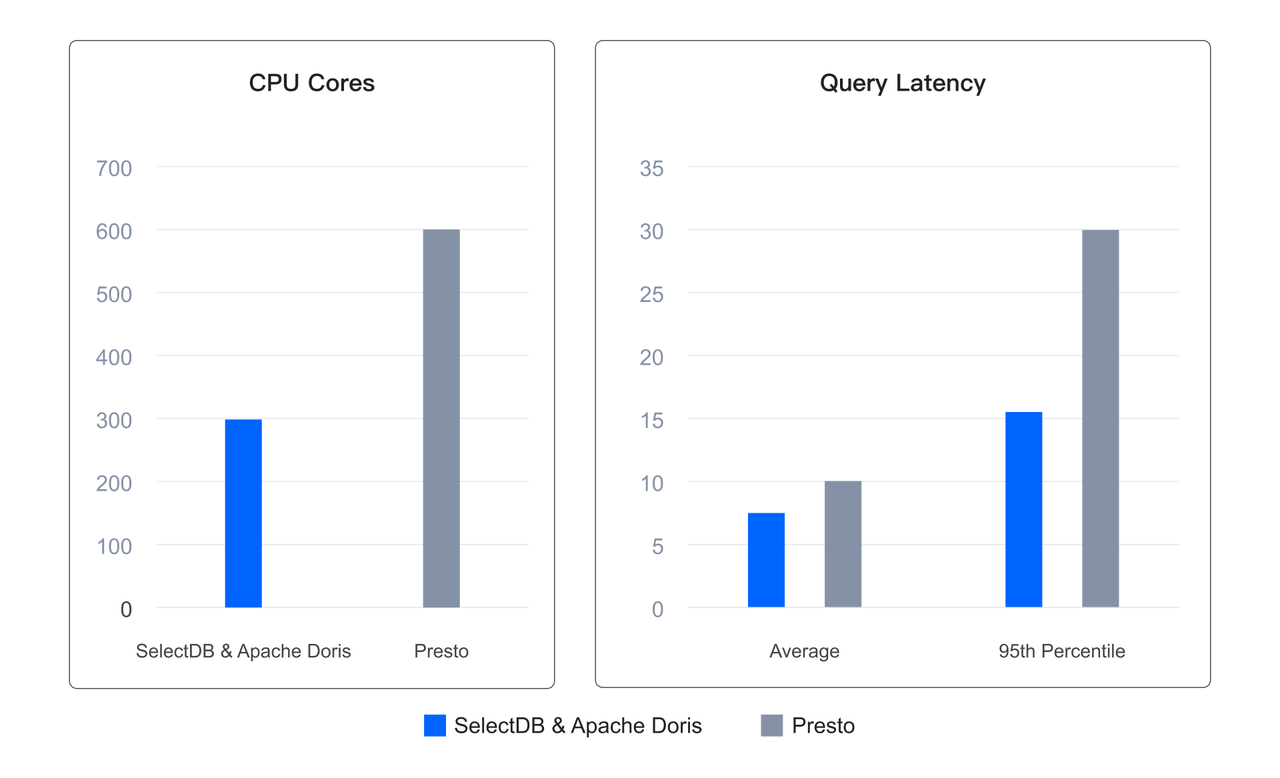
實際用戶場景中,在使用一半資源的情況下,相比 Presto 平均查詢延遲降低了 20%,95 分位延遲更是降低 50%,達到了降本增效的目的。
2.4.3 多 SQL 方言的兼容
在企業整合多個數據源并實現湖倉一體轉型的過程中,遷移業務的 SQL 查詢到 Doris & SelectDB 是一項挑戰,因為不同系統的 SQL 方言在語法和函數支持上存在差異。若沒有合適的遷移方案,業務側可能需要進行大量改造以適應新系統的 SQL 語法。
為了解決這個問題,Doris & SelectDB 提供了 SQL 轉換服務,允許用戶直接使用其他系統的 SQL 方言進行數據查詢。轉換服務會將這些 SQL 方言轉換為 Doris & SelectDB SQL,極大降低了用戶的遷移成本。目前,已支持 Presto/Trino、Hive、PostgreSQL 和 Clickhouse 等常見查詢引擎的 SQL 方言轉換,在某些實際用戶場景中,兼容率可達到 99%以上。
2.4.4 湖倉融合建模
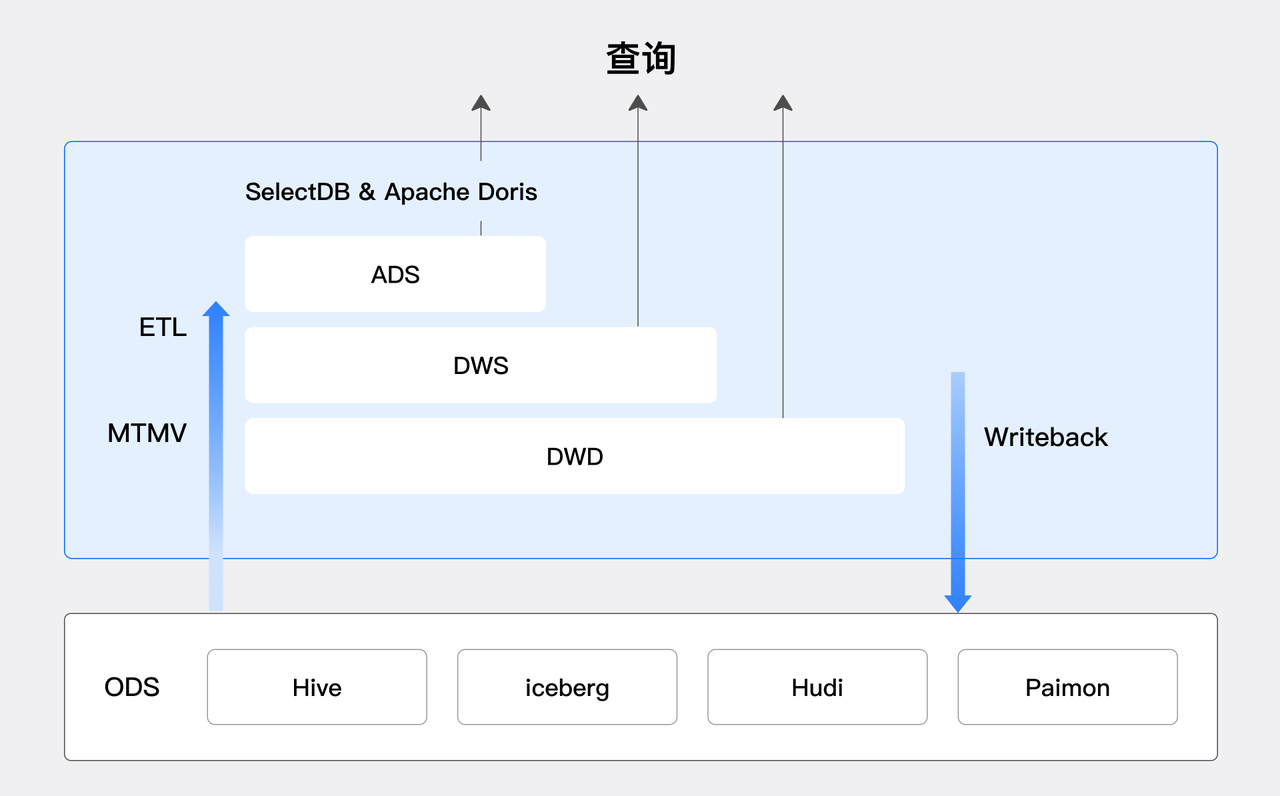
數據分層建模,ODS 層在 LakeHouse 中,DWD,DWS,ADS 層的數據加工和數據服務在 Doris & SelectDB 中,充分利用其性能優勢,此外還可以將其加工好的數據再通過 Write-Back 的機制寫回到 LakeHouse 中,實現備份歸檔或者供其他的數據系統繼續處理使用。
2.5 多模數據分析
現代化的數據分析系統,除了能夠高效的處理結構化的數據,也應該能夠高效的存儲和處理半結構化數據和非結構化數據:
- 半結構化數據: 半結構化數據雖然擁有一定的結構,但不嚴格固定,具有很強的靈活性。比較典型的是 JSON 格式,可以便捷地增加新字段或刪除不需要的字段,而日志、Trace、Metrics 是最典型的 JSON 格式半結構化數據。本章節將聚焦在高效的 JSON 數據分析和高性價比的可觀測性分析方案(基于日志、Trace、Metrics )。
- 非結構化數據:非結構化數據指沒有固定結構的數據,例如文本、音頻和視頻等,這類數據缺乏明顯的結構特征。針對非結構化數據的分析操作通常是檢索(Search),比如在大模型 GenAI 的 RAG 中通常包含兩類:
- 文本檢索:在文本中查找特定的關鍵字或短語,Doris & SelectDB 提供了倒排索引等功能,可以實現對非結構化文本數據的高效檢索,包括關鍵詞檢索、短語檢索等。
- 向量檢索:將非結構化數據轉化為高維向量,并在向量空間中計算相似性以實現高效檢索,目前也在增強這方面的能力。
2.5.1 高效 JSON 存儲分析方案 - VARIANT
JSON 格式數據的處理面臨如下幾個挑戰:
- 如何支持靈活的 Schema:字段隨著業務發展而增加/減少,類型也可能變化,數據中的嵌套結構也讓字段變的更加復雜,因此要求數據庫能夠支持靈活的 Schema。
- 如何高效存儲:大量重復的自描述內容,比如大量重復的字段名,通常是由機器產生。如果按原始數據存儲,數據冗余存儲帶來的資源浪費非常高,因此要求數據庫能夠高效存儲。
- 如何極速分析:半結構化數據通常為文本形式,直接對文本解析和分析雖然可行但性能較差。特別是在分組、聚合、過濾等操作時,要從大量的字段中分析其中的幾個字段,將帶來很多不必要的 IO 和解析開銷。
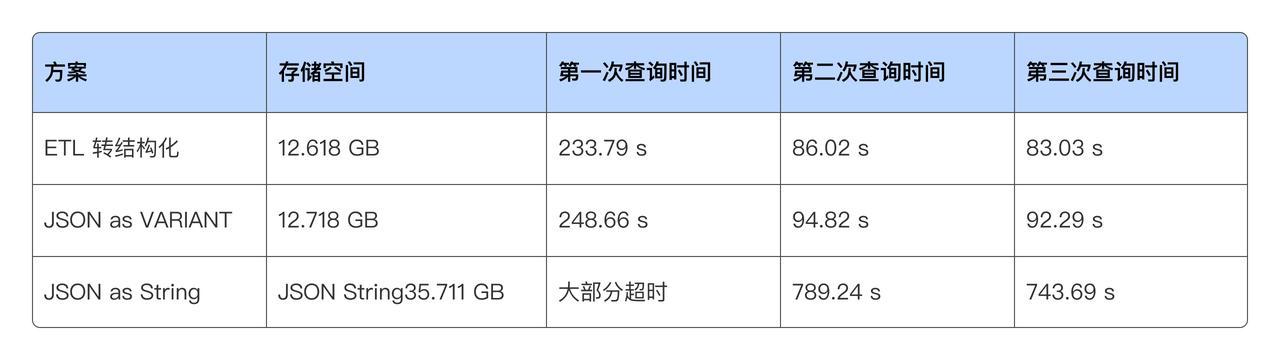
業界慣常的做法是將 JSON 存儲成 String,并且支持豐富的處理函數,這種方案能夠解決靈活 Schema 的問題,但是存儲和分析效率都非常低。
為此,推出了 VARIANT 數據類型,VARIANT 數據類型可以存儲任何合法的 JSON,可自動從 JSON 中抽取字段并推斷其類型;并將這些字段存儲為 VARIANT 列的子列,這些子列以列存的方式存儲,能夠高效壓縮存儲;這種列式存儲方式使得 VARIANT 具備很好的分析性能,當進行聚合/過濾/排序等查詢時,只需要讀取 VARIANT 子列數據即可,不會產生額外的數據解析開銷,查詢性能可獲得數量級的提升。VARIANT 的方案使得半結構化數據處理效率逼近結構化數據,同時又滿足了靈活性的目的。
2.5.2 高性價比可觀測性分析方案
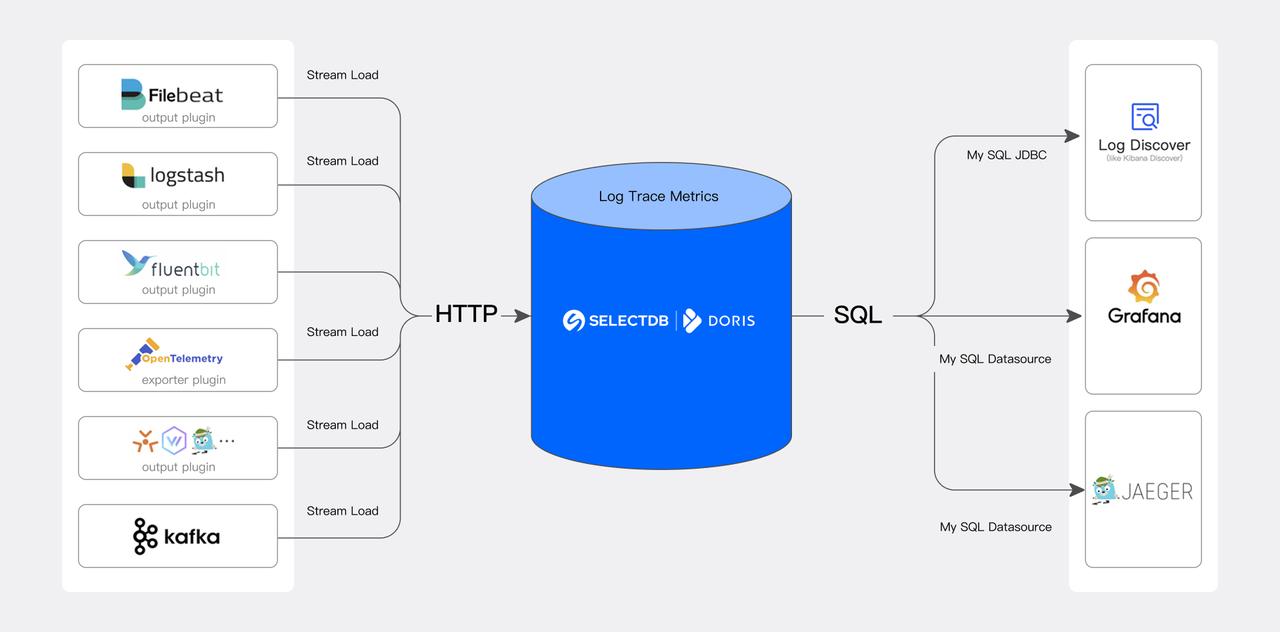
日志、Trace、Metrics 是最典型的 JSON 格式半結構化數據,而這些數據是可觀測性分析的主要內容。這類數據具有高寫入吞吐、海量存儲和實時響應需求,所以需要一個高性價的方案。
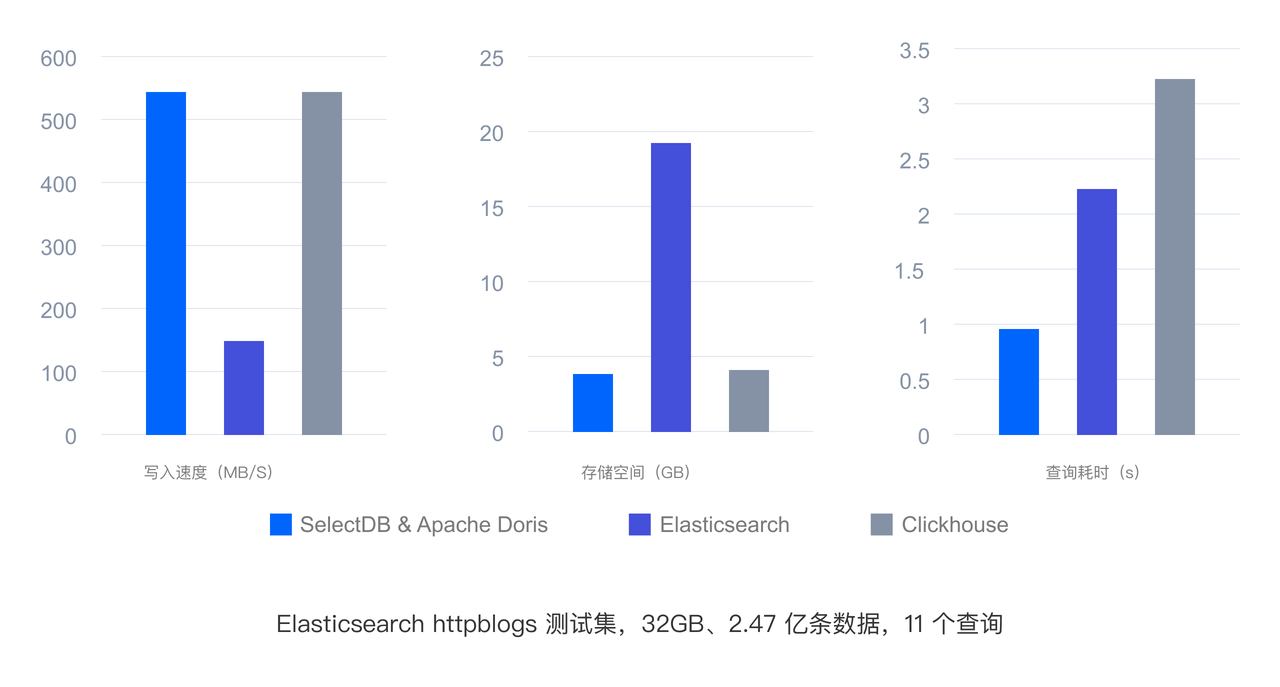
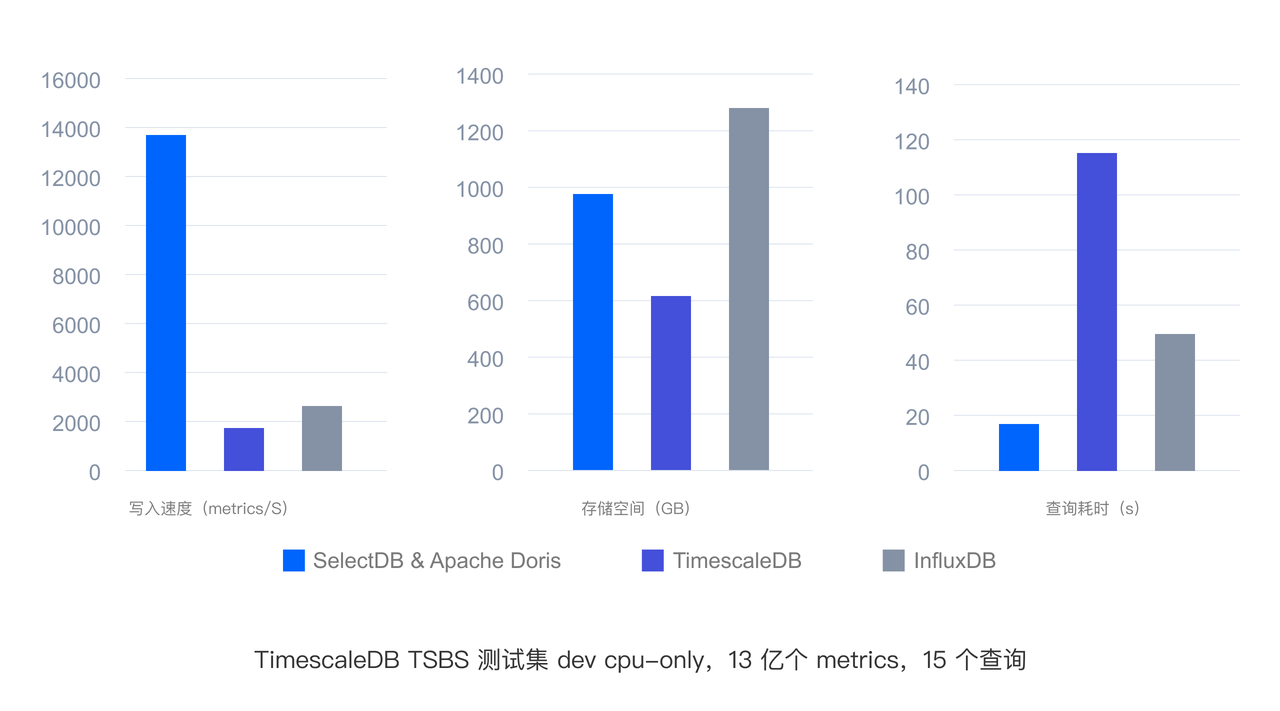
通過一系列的技術優化,使得在 Log Trace 相對于 ElasticSearch 寫入性能 3~5 倍,80% 存儲空間降低,查詢性能 2~3 倍;相對 CK 查詢性能 3 倍。Metrics 相對于 TimescaleDB InfluxDB 寫入性能 5~7 倍,查詢性能 2~6 倍。
- 提升寫入吞吐量
- 使用 SIMD 指令和 CPU 向量指令加速數據解析和索引創建。
- 移除不必要的正向索引,簡化索引創建過程。
- 降低存儲成本
- 移除占索引數據 30% 的正向索引。
- 采用列式存儲和 ZSTD 壓縮算法,壓縮比達 5:1 到 10:1
- 采用存算分離、冷熱數據分層存儲機制,將歷史日志存儲于低成本介質。
- 高性能查詢引擎 : 除之前介紹的極速分析,還對可觀測性場景下常用的 TopN 做了動態剪枝優化
- 高性能日志全文檢索分析:支持倒排索引和全文檢索,日志場景常見查詢(關鍵詞檢索明細、趨勢分析等)秒級響應。
- 標準 SQL 接口: 學習成本低,簡單易用,快速上手。
- 開放、易用的上下游生態: 上游通過 Stream Load 通用 HTTP APIs 對接常見的日志采集系統和數據源 Logstash、Filebeat、Fluentbit、Kafka 等,下游通過標準 MySQL 協議和語法對接各種可視化分析 UI,比如可觀測性 Grafana、BI 分析 Superset、類 Kibana 的日志檢索 Doris WebUI。
3. 結語
Doris & SelectDB 以其極速、實時、云原生、湖倉融合、高效多模數據分析的優秀能力,使得其成為實時數據分析、湖倉融合分析、可觀測性與日志分析、數倉構建的最佳選擇。安踏、長安汽車、順豐科技、特步、中通快遞、趣丸科技、MINISO、MiniMax、觀測云、迅雷、新東方、星火保等眾多客戶基于 Doris & SelectDB 構建了高效的數據分析平臺。未來,將持續提升其彈性的能力、批量處理能力、增量流式處理能力、面向大模型 GenAI 的混合檢索能力。如果您對 Doris & SelectDB 感興趣,歡迎體驗。
- Apache Doris 官網
- SelectDB 官網




)








)

)



)