一、基礎概述
在分析獲取最小幀數前,我們先來了解幾個相關的概念。
1,幀
幀(frame):表示一個完整的聲音單元,所謂的聲音單元是指一個采樣樣本。如果是雙聲道,那么一個完整的聲音單元就是 2 個樣本,如果是 5.1 聲道,那么一個完整的聲音單元就是 6 個樣本了。幀的大小(一個完整的聲音單元的數據量)等于聲道數乘以采樣位寬,即 frameSize = channelCount * bytesPerSample。這里bytesPerSample就是量化編碼的字節大小。無論是框架層還是內核層,都是以幀為單位去管理音頻數據緩沖區的。在音頻開發領域通常也會說采樣點來對應幀這個概念。因為將幀的個數除以采樣率就可以直接獲得對應音頻數據的時長。(PCM格式),又因為采樣頻率的倒數,就是一個采樣點的時間,乘以采樣點的數量就是整體音頻的時長了。
2,傳輸延遲
傳輸延遲(latency):一個處理單元引入的delay。
3,周期
周期(period):Linux ALSA 把數據緩沖區劃分為若干個塊,dma 每傳輸完一個塊上的數據即發出一個硬件中斷,CPU 收到中斷信號后,再配置 dma 去傳輸下一個塊上的數據。一個塊即是一個周期。
4,周期大小
周期大小(periodSize):即是一個數據塊的幀數。
再回到傳輸延遲(latency),每次傳輸產生的延遲等于周期大小除以采樣率,即 latency = periodSize / sampleRate。因為periodSize 指的是幀數,而幀大小 channelCount * bytesPerSample,所以幀總數除以采樣頻率就是整個傳輸過程消耗的時間。
5,音頻重采樣
音頻重采樣是指這樣的一個過程——把一個采樣率的數據轉換為另一個采樣率的數據。Android 原生系統上,音頻硬件設備一般都工作在一個固定的采樣率上(如 48 KHz),因此所有音軌數據都需要重采樣到這個固定的采樣率上,然后再輸出。因為系統中可能存在多個音軌同時播放,而每個音軌的采樣率可能是不一致的,比如在播放音樂的過程中,來了一個提示音,這時需要把音樂和提示音混音并輸出到硬件設備,而音樂的采樣率和提示音的采樣率不一致,問題來了,如果硬件設備工作的采樣率設置為音樂的采樣率的話,那么提示音就會失真,因此最簡單見效的解決方法是:硬件設備工作的采樣率固定一個值,所有音軌在 AudioFlinger 都重采樣到這個采樣率上,混音后輸出到硬件設備,保證所有音軌聽起來都不失真。 sample、frame、period、latency 這些概念與 Linux ALSA 及硬件設備的關系非常密切。
二,Audio buffersize實現流程分析
1.參數介紹
AudioSource:采樣通道,一般為MediaRecorder.AudioSource.MIC;
SampleRate:采樣率,一般在8000Hz~48000Hz之間,不同的硬件設備這個值不同;
Channel:采樣聲道數,一般為單通道或立體聲,即 AudioFormat.CHANNEL_CONFIGURATION_MONO或 AudioFormat.CHANNEL_CONFIGURATION_STEREO;
AudioFormat:采樣精度,一般為8位或16位,即AudioFormat.ENCODING_16BIT或8BIT;
bufferSize:緩沖區大小:可以通過getMinBufferSize來獲取;
buffer:DMA緩沖區大小
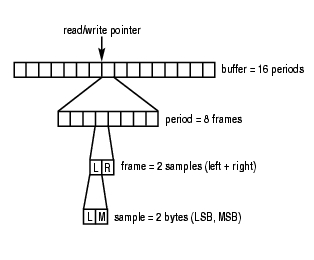
period: 周期,是每兩個硬件中斷之間的幀數,即傳輸多少個采樣幀數據,DMA反饋一個中斷,一般一個周期包含1024個采樣幀,在HAL層中定義。
frame: 每個采樣幀的大小。為一個采樣點的字節數*聲道數,因為對于多通道的話,用1個采樣點的字節數表示不全,因為播放的時候肯定是多個聲道的數據都要播放出來才行,所以為了方便,就說1秒鐘有多少個frame,這樣就能拋開聲道數,把意思表達全了。
sample: 采樣聲道,一般為2個字節。
在Audio系統中,buffer的組成如圖所示
2,Audio子系統之AudioRecord.getMinBufferSize
為了讓音頻數據通路能正常運轉,共享FIFO必須達到最小緩沖區的大小。如果數據緩沖區分配得過小,那么播放聲音會頻繁遭遇 underrun,underrun 是消費者(AudioFlinger::PlaybackThread)不能及時從緩沖區拿到數據,造成的后果就是聲音斷續卡頓。
1、獲取方法
AudioTrack.getMinBufferSize(48000, AudioFormat.CHANNEL_OUT_STEREO, AudioFormat.ENCODING_PCM_16BIT);
從函數參數來看,返回值取決于采樣率、音頻格式、聲道數這三個屬性。
2,接下來進入系統分析具體實現
調用服務端的函數,獲取frameCount大小,最后返回了frameCount聲道數采樣精度,其中frameCount表示最小采樣幀數,繼續分析frameCount的計算方法
frameworks/av/media/libmedia/AudioRecord.cpp
status_t AudioRecord::getMinFrameCount(size_t* frameCount,uint32_t sampleRate,audio_format_t format,audio_channel_mask_t channelMask)
{if (frameCount == NULL) {return BAD_VALUE;}size_t size;status_t status = AudioSystem::getInputBufferSize(sampleRate, format, channelMask, &size);if (status != NO_ERROR) {ALOGE("AudioSystem could not query the input buffer size for sampleRate %u, format %#x, ""channelMask %#x; status %d", sampleRate, format, channelMask, status);return status;}//計算出最小的frame// We double the size of input buffer for ping pong use of record buffer.// Assumes audio_is_linear_pcm(format)if ((*frameCount = (size * 2) / (audio_channel_count_from_in_mask(channelMask) *audio_bytes_per_sample(format))) == 0) {ALOGE("Unsupported configuration: sampleRate %u, format %#x, channelMask %#x",sampleRate, format, channelMask);return BAD_VALUE;}return NO_ERROR;
}
此時frameCount= size2/(聲道數采樣精度),注意這里需要double一下,而size是由hal層得到的,AudioSystem::getInputBufferSize()函數最終會調用到HAL層
frameworks/av/media/libmedia/AudioSystem.cpp
status_t AudioSystem::getInputBufferSize(uint32_t sampleRate, audio_format_t format,audio_channel_mask_t channelMask, size_t* buffSize)
{const sp<IAudioFlinger>& af = AudioSystem::get_audio_flinger();if (af == 0) {return PERMISSION_DENIED;}Mutex::Autolock _l(gLockCache);// Do we have a stale gInBufferSize or are we requesting the input buffer size for new valuessize_t inBuffSize = gInBuffSize;if ((inBuffSize == 0) || (sampleRate != gPrevInSamplingRate) || (format != gPrevInFormat)|| (channelMask != gPrevInChannelMask)) {gLockCache.unlock();inBuffSize = af->getInputBufferSize(sampleRate, format, channelMask);gLockCache.lock();if (inBuffSize == 0) {ALOGE("AudioSystem::getInputBufferSize failed sampleRate %d format %#x channelMask %x",sampleRate, format, channelMask);return BAD_VALUE;}// A benign race is possible here: we could overwrite a fresher cache entry// save the request paramsgPrevInSamplingRate = sampleRate;gPrevInFormat = format;gPrevInChannelMask = channelMask;gInBuffSize = inBuffSize;}*buffSize = inBuffSize;return NO_ERROR;
}
所以實際上會通過binder到達AudioFlinger中
frameworks\av\services\audioflinger\AudioFlinger.cpp
size_t AudioFlinger::getInputBufferSize(uint32_t sampleRate, audio_format_t format,audio_channel_mask_t channelMask) const
{status_t ret = initCheck();if (ret != NO_ERROR) {return 0;}AutoMutex lock(mHardwareLock);mHardwareStatus = AUDIO_HW_GET_INPUT_BUFFER_SIZE;audio_config_t config;memset(&config, 0, sizeof(config));config.sample_rate = sampleRate;config.channel_mask = channelMask;config.format = format;audio_hw_device_t *dev = mPrimaryHardwareDev->hwDevice();size_t size = dev->get_input_buffer_size(dev, &config);mHardwareStatus = AUDIO_HW_IDLE;return size;
}
把參數傳遞給hal層,獲取buffer大小
hardware\aw\audio\tulip\audio_hw.c
static size_t get_input_buffer_size(uint32_t sample_rate, int format, int channel_count)
{size_t size;size_t device_rate;if (check_input_parameters(sample_rate, format, channel_count) != 0)return 0;/* take resampling into account and return the closest majoringmultiple of 16 frames, as audioflinger expects audio buffers tobe a multiple of 16 frames */size = (pcm_config_mm_in.period_size * sample_rate) / pcm_config_mm_in.rate;size = ((size + 15) / 16) * 16;return size * channel_count * sizeof(short);
}
這里包含一個結構體struct pcm_config,定義了一個周期包含了多少采樣幀,并根據結構體的rate數據進行重采樣計算,這里的rate是以MM_SAMPLING_RATE為標準,即44100,一個采樣周期有1024個采樣幀,然后計算出重采樣之后的size
同時audioflinger的音頻buffer是16的整數倍,所以再次計算得出一個最接近16倍的整數,最后返回size聲道數1幀數據所占字節數
struct pcm_config pcm_config_mm_in = {.channels = 2,.rate = MM_SAMPLING_RATE,.period_size = 1024,.period_count = CAPTURE_PERIOD_COUNT,.format = PCM_FORMAT_S16_LE,
};
3,總結:
minBuffSize = ((((((((pcm_config_mm_in.period_size * sample_rate) / pcm_config_mm_in.rate) + 15) / 16) * 16) * channel_count * sizeof(short)) * 2) / (audio_channel_count_from_in_mask(channelMask) * audio_bytes_per_sample(format))) * channelCount * audio_bytes_per_sample(format);
=(((((((pcm_config_mm_in.period_size * sample_rate) / pcm_config_mm_in.rate) + 15) / 16) * 16) * channel_count * sizeof(short)) * 2)
其中:pcm_config_mm_in.period_size=1024;pcm_config_mm_in.rate=44100;這里我們可以看到他除掉(channelCount*format),后面又乘回來了,這個是因為在AudioRecord.cpp對frameCount進行了一次校驗,判斷是否支持該參數的設置。
以getMinBufferSize(44100, MONO, 16BIT);為例,即sample_rate=44100,channel_count=1, format=2,那么
BufferSize = (((1024sample_rate/44100)+15)/16)16channel_countsizeof(short)*2 = 4096
即最小緩沖區大小為:周期大小 * 重采樣 * 采樣聲道數 * 2 * 采樣精度所占字節數;這里的2的解釋為We double the size of input buffer for ping pong use of record buffer,采樣精度:PCM_8_BIT為unsigned char,PCM_16_BIT為short,PCM_32_BIT為int。

)




)







—— 淺層路由和 Packaging)
)


、基于模板(RestTemplate)、基于 SDK、消息隊列、gRPC)對比詳解)
