這是對《SmolLM2: When Smol Goes Big — Data-Centric Training of a Small Language Model》的翻譯閱讀
?摘要
雖然大語言模型在人工智能的許多應用中取得了突破,但其固有的大規模特性使得它們在計算上成本高昂,并且在資源受限的環境中部署具有挑戰性。在本文中,我們記錄了SmolLM2的開發過程,這是一種最先進的 “小型”(17億參數)語言模型(LM)。
為了獲得強大的性能,我們使用多階段訓練過程,在約11萬億個詞元的數據上對SmolLM2進行過度訓練,該過程將網頁文本與專業的數學、代碼和指令跟隨數據混合在一起。此外,在我們發現現有數據集存在規模過小或質量較低的問題時,我們引入了新的專業數據集(FineMath、Stack-Edu和SmolTalk)。
為了為我們的設計決策提供依據,我們進行了小規模的消融實驗以及手動優化過程,根據前一階段的性能更新每個階段的數據集混合比例。最終,我們證明SmolLM2的性能優于其他近期的小型語言模型,包括Qwen2.5-1.5B和Llama3.2-1B。為了促進未來對語言模型開發以及小型語言模型應用的研究,我們發布了SmolLM2以及我們在項目過程中準備的所有數據集。
?1 引言
大語言模型(LMs)已成為現代人工智能系統的基石,因為它們能夠遵循自然語言指令,并靈活地執行各種各樣的任務(Touvron等人,2023;Bai等人,2023;Brown等人,2020;Dubey等人,2024;Groeneveld等人,2024;Chowdhery等人,2023;Young等人,2024;Taylor等人,2022)。從本質上講,大語言模型規模龐大,按照當前的慣例,是指具有許多參數(超過約100億)的模型。這種龐大的規模導致在訓練和推理過程中計算成本極高,這可能會阻礙大語言模型在資源受限的環境中使用。
為了解決這個問題,最近一系列工作旨在開發性能良好的小型(約30億參數或更少)語言模型(Gunter等人,2024;Yang等人,2024b;AI@Meta,2024b;Team等人,2024;Li等人,2023b)。這些小型語言模型計算成本低,可以在更廣泛的設備(如手機)上運行,同時在許多重要任務上提供令人滿意的性能。
語言模型性能和行為的一個關鍵因素是用于訓練它們的數據。雖然數據整理對任何規模的語言模型都很重要,但對于較小的模型來說,其影響尤為顯著,因為它們有限的容量必須仔細優化,以學習核心知識和基本能力,而不是記憶偶然的事實(Abdin等人,2024a;Rolnick等人,2017)。
大多數語言模型主要在從網絡爬取的文本上進行訓練(Radford等人,2019;Raffel等人,2020),最先進的流程包括復雜的過濾和處理階段,旨在提高數據質量(Li等人,2024c;Penedo等人,2024b、a;Soldaini等人,2024)。最近,從某些領域(如軟件代碼(Kocetkov等人,2022;Lozhkov等人,2024)和數學(Paster等人,2023;Han等人,2024))納入 “專業” 數據已變得很常見,這不僅可以提高在這些領域的性能,還可以更普遍地提高在需要推理的具有挑戰性的任務上的性能(Muennighoff等人,2023;Aryabumi等人,2024)。
受上述考慮因素的啟發,我們在本文中的貢獻如下:第一,我們對現有的網頁、代碼、數學和指令跟隨數據集進行了仔細評估(第3節),以幫助指導訓練數據的設計選擇,最終通過對不同來源進行多階段手動重新平衡來訓練SmolLM2,以最大化性能(第4節)。這種動態重新平衡是一種有前途的大規模訓練方法,因為大規模訓練成本高昂(SmolLM2的訓練大約需要1e23次浮點運算,相當于25萬美元的GPU計算成本),使得運行多個完整規模的訓練變得不切實際。按照標準做法,我們還開發了SmolLM2的指令調優變體(第5節)。此外,在發現現有數據集太小和 / 或質量較低后,我們創建了新的數據集FineMath、Stack-Edu和SmolTalk(分別用于數學、代碼和指令跟隨)。最終,我們表明SmolLM2的基礎版本和指令調優版本在類似規模的模型中都是最先進的(第4.7節和第5.4節)。
?2 背景
訓練一個現代語言模型通常從在大量(例如數萬億個詞元)無結構文本上進行 “預訓練” 開始。預訓練有助于模型適應語言結構(Clark,2019)并存儲事實性知識(Petroni等人,2019;Roberts等人,2020),因此已被證明是語言模型訓練的重要組成部分,這使得預訓練數據集的組成成為一個關鍵考慮因素。
預訓練對數據的大量需求導致了大規模網絡爬蟲的使用(com;ope;ant),但原始形式的這些數據可能會導致語言模型性能不佳(Penedo等人,2024b)。因此,現代語言模型預訓練數據集的主要整理方法是設計復雜的管道,用于自動過濾和重新格式化網頁文本(Penedo等人,2024a、b;Soldaini等人,2024;Soboleva等人,2023;Li等人,2024c),旨在保留足夠的數據以避免有害的重復(Muennighoff等人,2023),同時丟棄任何 “低質量” 數據。
除了網頁文本,納入來自某些領域的 “專業” 數據,特別是代碼(Kocetkov等人,2022;Li等人,2023a)和數學(Paster等人,2023;Han等人,2024;Wang等人;Azerbayev等人,2023),可以提高模型在涉及推理和世界知識的任務上的性能(Muennighoff等人,2023;Aryabumi等人,2024;Lewkowycz等人,2022;Shao等人,2024)。
小型專業數據集的貢獻可能會被大得多的基于網絡的預訓練數據源所掩蓋,這導致了多階段預訓練的設計,其中在訓練后期納入專業或高質量數據集(Abdin等人,2024b;Ai2,2024;Blakeney等人,2024;Singer等人,2024)。
在預訓練之后,語言模型在部署之前通常會經歷兩個額外的訓練階段:指令調優和偏好學習。在指令調優中,模型在指令 / 響應對上進行有監督訓練,這些對反映了語言模型應該如何回答查詢(Wei等人,2021;Mishra等人,2021;Sanh等人,2021;Wang等人,2022)。
這個過程提供了一種有價值的方式來定制語言模型,使其提供有用的響應,而不是簡單地嘗試繼續輸入(如在預訓練期間所學習的)。在偏好學習中,語言模型通過訓練以區分有用和無用的響應,進一步 “對齊” 到其預期用途(Ouyang等人,2022;Bai等人,2022)。
這個最后階段通常涉及對標記有人工或合成生成偏好的數據進行某種形式的強化學習(Bai等人,2022;Lee等人;Rafailov等人,2024)。
?3 預訓練數據集
預訓練數據整理對于小型語言模型尤為重要,因為它們對訓練數據中的噪聲更為敏感(Rolnick等人,2017;Abdin等人,2024a)。此外,設計預訓練策略不僅涉及選擇和整理數據,還涉及確定從不同來源 “混合”(即采樣)的比例,這在納入例如專業數學和代碼數據集時尤為重要。因此,我們對現有數據集進行了仔細評估,并在必要時創建了新的、改進的和更大的數據集。
?3.1 消融實驗設置
為了比較英語網頁數據集并找到訓練我們模型的最佳混合比例,我們采用了與Penedo等人(2024a)類似的實證方法。具體來說,我們在相同條件下在每個數據集上訓練模型:模型配置、訓練超參數和詞元數量。我們基于Llama架構(Touvron等人,2023)訓練了17億參數的Transformer(Vaswani等人,2017),序列長度為2048,全局批次大小約為200萬個詞元,使用GPT - 2分詞器(Radford等人,2019),并采用余弦學習率調度(Loshchilov和Hutter,2016),學習率為\(3.0×10^{-4}\)。每個數據集消融模型在從完整數據集中隨機采樣的3500億個詞元上進行訓練。-->(僅針對數據集比例進行的實驗還是?)
在評估方面,我們也遵循Penedo等人(2024a)的方法,使用lighteval(?)在各種知識、推理和文本理解基準上進行評估:MMLU(Hendrycks等人,2021)、HellaSwag(Zellers等人,2019)、OpenBook QA(Mihaylov等人,2018)、PIQA(Bisk等人,2019)、WinoGrande(Sakaguchi等人,2019)、ARC(Clark等人,2018)和CommonSenseQA(Talmor等人,2019)。
LightEval 是 Hugging Face 推出的一款輕量級 AI 評估工具,主要用于評估大型語言模型(LLMs)。其具備以下特性和功能:
- 多設備支持:可在 CPU、GPU 和 TPU 等多種硬件上運行,能適應不同硬件環境,滿足企業級用戶在不同硬件配置下的評估需求 。
- 使用便捷:提供用戶友好的命令行界面和編程接口,技術背景不強的用戶也能輕松上手,可在多種流行的基準測試上評估模型,還能定義自己的自定義任務 。
- 自定義評估:支持用戶根據自身需求定制評估流程,包括指定模型評估的配置,如模型的權重、管道并行性等 。
- 與生態集成:與 Hugging Face 的生態系統緊密集成,例如可與 Hugging Face Hub 等工具配合使用,便于模型的管理和共享 。
- 復雜配置支持:允許通過配置文件加載模型,進行復雜的評估配置,如使用適配器 / 增量權重或其他復雜的配置選項 。
- 流水線并行評估:支持在 16 位精度下評估超過約 400 億參數的模型,借助流水線并行技術將模型分片到多個 GPU,以適應有限的 VRAM(顯存) 。
數學和代碼能力通常在廣泛訓練后才會顯現,因此與Blakeney等人(2024)、Dubey等人(2024)、Ai2(2024)類似,在評估數學和代碼數據集時,我們從SmolLM2訓練到3萬億詞元的中間檢查點開始(第4節中有詳細介紹),該檢查點主要在網頁數據上進行訓練。
然后我們使用退火方法:在訓練包含評估數據集的混合數據時,學習率線性衰減至0。對于數學,我們在包含600億個評估數據集詞元和400億個檢查點前混合數據詞元的混合數據上進行退火。對于代碼消融實驗,我們在2000億個詞元上進行退火,這些詞元均勻分布在15種最常用的編程語言中(每種語言約140億個詞元)。
我們使用lighteval在GSM8K(Cobbe等人,2021)、MATH(Hendrycks等人,2021)和MMLU - STEM上評估數學消融模型,以評估它們的數學能力,并使用BigCode - Evaluation - Harness在HumanEval(Chen等人,2021)和MultiPL - E(Cassano等人,2022)上評估代碼消融模型。
退火階段不是訓練的最后階段。在 SmolLM2 訓練中,退火階段主要用于調整學習率,增強模型對特定數據的學習效果,提升模型在數學和代碼相關任務上的性能。
- 退火階段位置:訓練分為多個階段,退火階段處于穩定階段之后的衰減階段(從 10T 到 11T tokens)。在此階段,學習率會線性衰減至 0 ,但不是訓練的最后一步,之后還有上下文長度擴展等操作。
- 使用退火算法的目的:在訓練接近尾聲時,模型已學習到大部分知識,此時逐漸降低學習率,可以讓模型在已有學習成果基礎上,更精細地調整參數,避免學習率過高導致在訓練后期過度調整參數,從而提升模型性能。在 SmolLM2 訓練中,結合高質量的數學和代碼數據(如 FineMath 和部分 Stack - Edu 數據集)進行上采樣,使模型更聚焦于這些特定領域知識的學習,強化在數學和代碼任務方面的能力 。
- 實現方式:在訓練達到一定階段(如 SmolLM2 訓練到 10T tokens 時),開始退火階段。學習率按照線性衰減的方式逐漸降低至 0 。同時,調整數據集的混合比例,增加高質量數學和代碼數據集的比例。如在 SmolLM2 訓練的退火階段,數學內容占混合數據的 14% ,Stack - Edu 的比例也有所增加,且調整了各編程語言在 Stack - Edu 中的分配比例 。
?3.2 英語網頁數據
來自Common Crawl的網頁文本一直是預訓練數據的熱門來源,最近基于分類器的過濾技術顯著提高了預訓練數據的質量(Dubey等人,2024;Abdin等人,2024b、a;Kong等人,2024)。兩個使用基于分類器過濾的著名開放數據集示例是FineWeb - Edu(Penedo等人,2024a)和DCLM(Li等人,2024c)。
FineWeb - Edu由1.3萬億個詞元組成,這些詞元被基于Llama3 - 70B - Instruct(Dubey等人,2024)生成的注釋訓練的分類器判定為 “教育性”。DCLM包含3.8萬億個詞元,這些詞元是使用在來自OpenHermes 2.5(Teknium,2023a)的指令跟隨數據和r/ExplainLikeImFive(ELI5)子版塊的高分帖子上訓練的fastText分類器(Joulin等人,2016a、b)進行過濾的。
在FineWeb - Edu和DCLM上分別使用3500億個詞元訓練消融模型,得到的性能如表1所示。我們發現,FineWeb - Edu在教育基準MMLU、ARC和OpenBookQA上獲得了更高的分數,而DCLM在HellaSwag和CommonsenseQA上表現更好。這些結果與數據集的內容一致:FineWeb - Edu優先考慮教育材料,而DCLM捕獲了更多樣化的對話風格。
表1.對在FineWeb-Edu和DCLM上針對350 B 令牌訓練的模型進行評估。40/60和60/40表示FW-Edu/DCLM的比率。
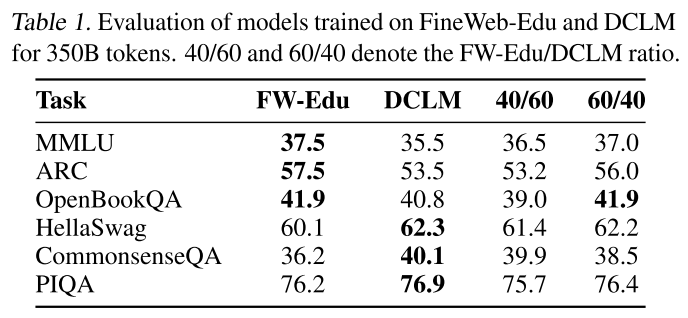
鑒于FineWeb - Edu和DCLM的互補優勢,我們探索了將它們混合是否可以進一步提高性能。在測試了不同的比例后,我們發現60%的FineWeb - Edu和40%的DCLM的混合效果很好,如表1所示:它在MMLU、ARC和OpenBookQA上的性能幾乎與FineWeb - Edu相當,同時在HellaSwag上與DCLM的結果一致,并在CommonsenseQA上接近其性能。將這些數據集結合起來,得到了5.1萬億個(英語)文本詞元。
?3.3 數學數據
專業的數學預訓練數據對于培養強大的數學理解能力至關重要。最近的研究表明,從Common Crawl中精心整理的數學內容,結合有針對性的過濾技術,可以顯著增強語言模型的數學推理能力(Dubey等人,2024;Yang等人,2024c;Shao等人,2024;Han等人,2024)。
?3.3.1 現有數據集比較
我們比較了兩個領先的公開可用數學數據集:OpenWebMath(OWM)(Paster等人,2023)和InfiMMWebMath(Han等人,2024)。OWM由120億個詞元組成,通過從Common Crawl中過濾特定于數學的內容,并使用專門的文本提取管道來保留數學格式和公式構建而成。InfiMMWebMath包含400億個文本詞元,其作者表明它與DeepSeekMath的私有數據集性能相當(Shao等人,2024)。
我們對OWM和InfiMM - WebMath進行了退火消融實驗(遵循第3.1節中描述的設置),發現InfiMM - WebMath在GSM8K上的峰值準確率為14%,而OWM為10%,而OWM在MATH上略微優于InfiMM - WebMath。完整的評估曲線可在附錄C.1中找到。
盡管在600億個數學詞元上進行了訓練(即OWM訓練5個epoch,InfiMM - WebMath訓練1.5個epoch),但性能仍然落后于專有的最先進小型模型(Yang等人,2024b)。進一步的分析突出了兩個關鍵限制:數據集規模不足,以及對逐步數學推理的關注不夠,同時過度代表了專注于高級概念的學術論文。
?3.3.2 新數據集:FineMath
上述OWM和InfiMMWebMath存在的問題促使我們開發FineMath1,這是一個包含多達540億個數學數據詞元的集合,通過基于分類器的過濾專注于數學推導和推理。
我們首先使用Resiliparse從Common Crawl WARC文件中提取文本,重點關注FineWeb數據集(Common Crawl的750億個唯一URL的一個子集)中的所有58億個唯一URL。然后,我們采用FineWeb - Edu過濾方法,使用Llama - 3.1 - 70B - Instruct(Dubey等人,2024)和一個提示(附錄C.2),該提示在3分制上對內容進行評分,其中1分表示包含一些數學內容,3分表示具有適當水平的逐步問題解決方案。
在基于這些銀標簽訓練了一個分類器之后,我們確定了包含至少10個質量得分在2分或更高的頁面的領域。我們通過納入來自OWM或InfiMM - WebMath中至少有10個URL的領域來擴大我們的領域覆蓋范圍。
從Common Crawl索引中,我們總共檢索到屬于該領域列表的77億個URL:其中57億個由我們的分類器識別,6億個來自OWM,13億個來自InfiWebMath。然后,我們使用OWM管道重新提取所有已識別的頁面,保留LaTeX格式并刪除所有樣板頁面,得到包含6.5萬億個詞元的71億個頁面。
為了僅保留高質量的數學內容,我們重新應用了一個基于Llama - 3.1 - 70B - Instruct注釋訓練的分類器,使用一個5分制提示(附錄C.3),專門針對具有推理和中學到高中水平內容的頁面。我們注意到InfiMM - WebMath使用了類似的分類器過濾管道,但他們的提示針對的不是相同類型的內容。
在分類之后,我們使用具有10個哈希的單波段MinHash LSH(Broder,1997)進行去重,并應用fastText語言分類(Joulin等人,2016a、b)以僅保留英語內容。最終,我們開發了多個FineMath變體,包括FineMath4 +(100億個詞元,670萬個文檔),它僅保留得分在4 - 5分的樣本,以及FineMath3 +(340億個詞元,2140萬個文檔),它包括得分在3 - 5分的樣本。
我們還對InfiMMWebMath應用了相同的分類器,創建了Infi - WebMath4 +(85億個詞元,630萬個文檔)和Infi - WebMath3 +(205億個詞元,1390萬個文檔)。與Yang等人(2024c)類似,我們使用13 - gram匹配和最長公共子序列的最小重疊比為0.6,對每個數據集針對GSM8K、MATH和MMLU進行去污染。
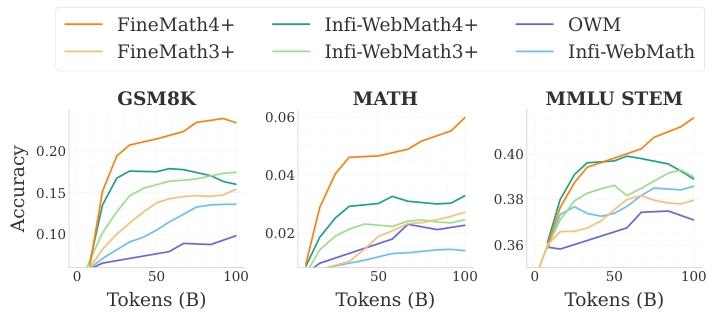
圖1展示了我們對FineMath進行退火消融實驗的結果。所有FineMath子集在GSM8K、MATH和MMLU-STEM上的表現始終優于OWM和InfiMM-WebMath。與InfiMM-WebMath相比,FineMath4 +在GSM8K上的準確率提高了2倍,在MATH上提高了6倍,這表明保留高質量且包含推理過程的數學內容的重要性。
此外,Infi-WebMath4 +的表現優于InfiMM-WebMath,但在訓練800億個詞元(大約10個epoch)后達到了性能平臺期,這可能是由于數據重復導致的,而這種趨勢在FineMath4 +中并未出現。
?3.4 代碼數據
代碼生成和理解正成為現代大語言模型的基本能力,支持諸如代碼補全、調試和軟件設計等多種應用場景。雖然專門的代碼模型(Lozhkov等人,2024;Bai等人,2023;Roziere等人,2023)是針對這些任務進行優化的,但通用大語言模型也越來越多地被用作編碼助手。
Stack數據集
此外,最近的研究表明,在預訓練中納入代碼數據不僅可以增強與代碼相關的能力,還可以提高自然語言推理和世界知識(Aryabumi等人,2024)。Stack數據集是最先進的開放代碼數據集(Li等人,2023a;Kocetkov等人,2022),包括Stack v1,它包含來自公共GitHub存儲庫的約3TB源代碼;StarCoderData(Li等人,2023a;Kocetkov等人,2022;Lozhkov等人,2024),這是一個經過篩選的子集,包含80種編程語言的2500億個詞元;Stack v2,其數據約為32TB,來源于Software Heritage代碼存檔;以及StarCoder2Data,它是StarCoder2模型(Lozhkov等人,2024)的訓練語料庫,包含跨越600多種編程語言的9000億個詞元。
構建的Stack-Edu
最近的研究表明,基于FineWeb-Edu分類器的過濾策略對代碼數據是有效的(Wei等人,2024b;Allal等人,2024)。因此,我們構建了Stack-Edu,它是StarCoder2Data的一個經過篩選的變體,專注于教育性和文檔完備的代碼。
具體來說,我們從StarCoder2Data中選擇了15種最大的編程語言,以匹配較小模型的容量限制(Lozhkov等人,2024),并確保在消融實驗中有基準覆蓋。這個子集大約有4500億個詞元。然后,我們使用StarEncoder模型(Li等人,2023a)在由Llama3-70B-Instruct(Dubey等人,2024)生成的合成注釋上訓練了15個特定語言的分類器(提示見附錄D.1),該注釋在0到5的量表上對教育質量進行評分。每個分類器在500,000個樣本上進行訓練,并且在應用3作為二分類閾值時,大多數語言的F1分數都高于0.7。
退火消融實驗評估Stack-Edu
為了評估Stack-Edu,我們按照第3.1節中描述的方法進行退火消融實驗。使用3作為閾值進行過濾在大多數語言上提高了性能,同時保留了足夠的數據,不過Java使用2作為閾值時表現更好。由于Markdown未包含在MultiPL-E基準中,我們無法定量確定該數據集的閾值;
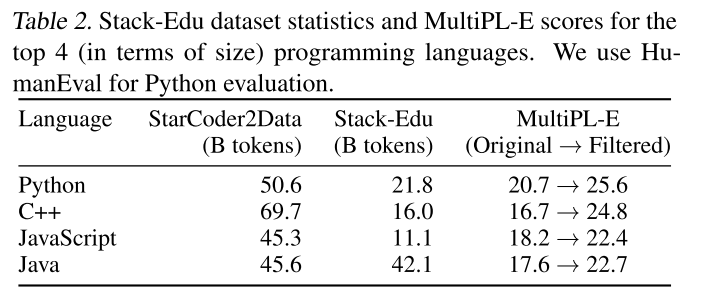
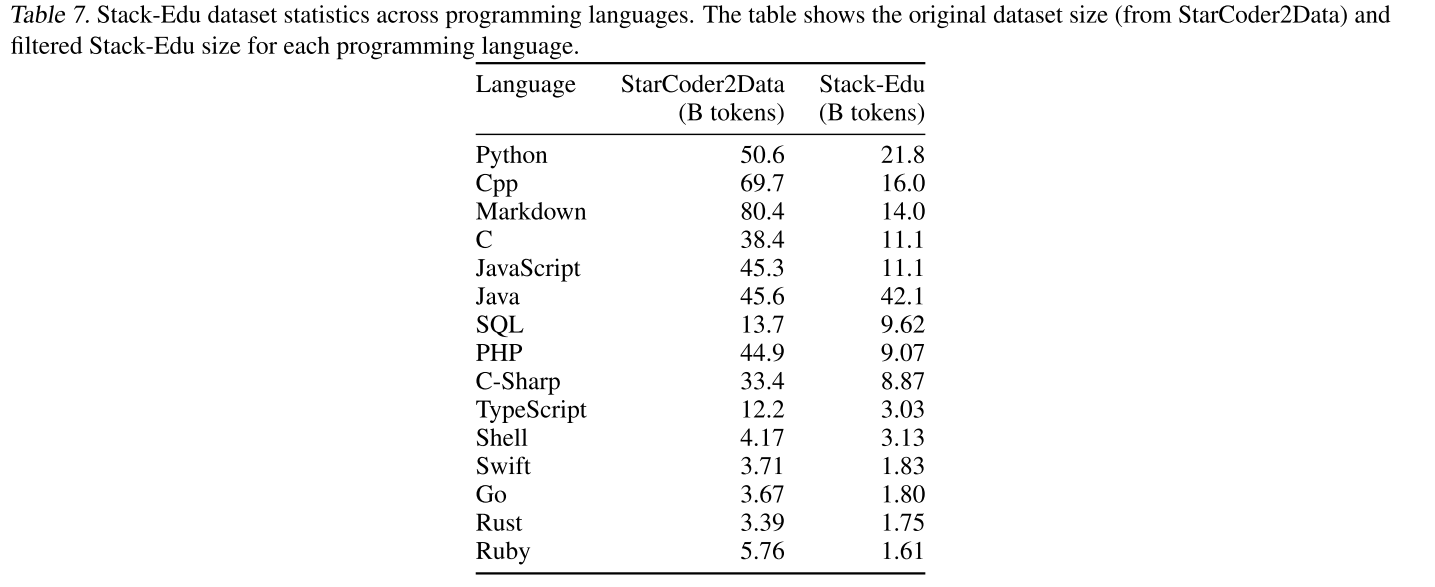
相反,我們基于定性分析使用了3作為閾值。最終得到的Stack-Edu數據集在其15種語言中包含約1250億個詞元(見附錄D.2)。表2展示了按大小排名前4的編程語言的統計信息,以及我們的教育過濾對MultiPL-E的影響。
表2.Stack-Edu數據集統計數據和MultiPL-E得分,針對排名前4位(按規模)的編程語言。我們使用HumanEval進行Python評估。
?4 預訓練
最近語言模型預訓練的趨勢明顯轉向顯著更長的訓練時長,特別是對于較小的模型(Yang等人,2024a、b;AI@Meta,2024b)。雖然這種策略偏離了Chinchilla最優準則(Hoffmann等人,2022),但由此帶來的性能提升和降低的推理成本使得延長訓練成為一種值得的權衡(de Vries,2023)。
例如,Qwen2-1.5B在7萬億個詞元上進行訓練,Qwen2.5-1.5B在18萬億個詞元上進行訓練,而Llama3.2-1B是從一個剪枝后的80億參數模型派生而來,通過蒸餾在9萬億個詞元上進行訓練(Yang等人,2024a、b;AI@Meta,2024b)。
在構建SmolLM2時,我們在11萬億個詞元上進行訓練(在我們收集的數據集上大約訓練兩個epoch),采用多階段訓練方法,而不是在整個預訓練過程中使用固定的數據集混合比例。
這種設計遵循四個關鍵原則:
(1)以性能為導向的干預措施,我們在關鍵基準上監控評估指標,并調整數據集混合比例以解決特定的能力瓶頸;
(2)在退火階段對高質量的數學和代碼數據進行上采樣,將像FineMath和部分Stack-Edu這樣的數據集保留到最后階段,以最大化它們的影響(Blakeney等人,2024;Ai2,2024);
(3)在訓練中期戰略性地引入中等規模的數據集,如OWM、InfiMM-WebMath和Stack-Edu,以避免在早期被更大的數據集稀釋;
(4)避免過度的數據重復,根據Muennighoff等人(2023)的建議,我們旨在使大多數數據集的訓練接近推薦的4-5個epoch的閾值。雖然進行多次從頭開始的訓練以探索不同的數據混合計劃可能會有成果,但SmolLM2預訓練的高昂成本(大約25萬美元的GPU計算成本)促使我們采用 “在線” 方法。
在以下各節中,我們將描述訓練過程的每個階段,詳細說明數據集的混合比例、我們選擇的理由以及指導我們進行干預的觀察結果。雖然一些決策是基于文獻中的既定發現,但其他決策則是由訓練過程中收集的實證見解驅動的。四個預訓練階段的數據混合比例如圖2所示。
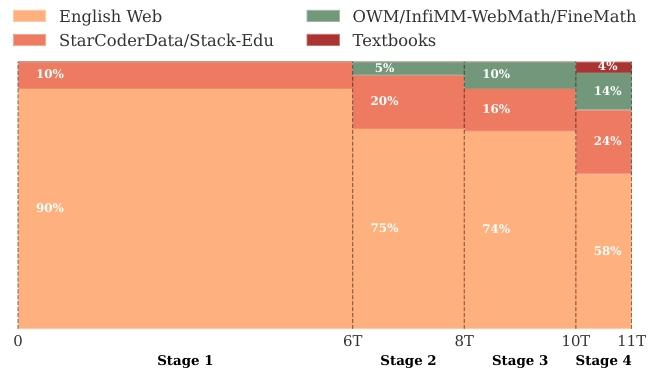
圖2.訓練階段的數據集混合。詳細描述見第4節。x軸表示訓練令牌的數量。?
?4.1 訓練設置
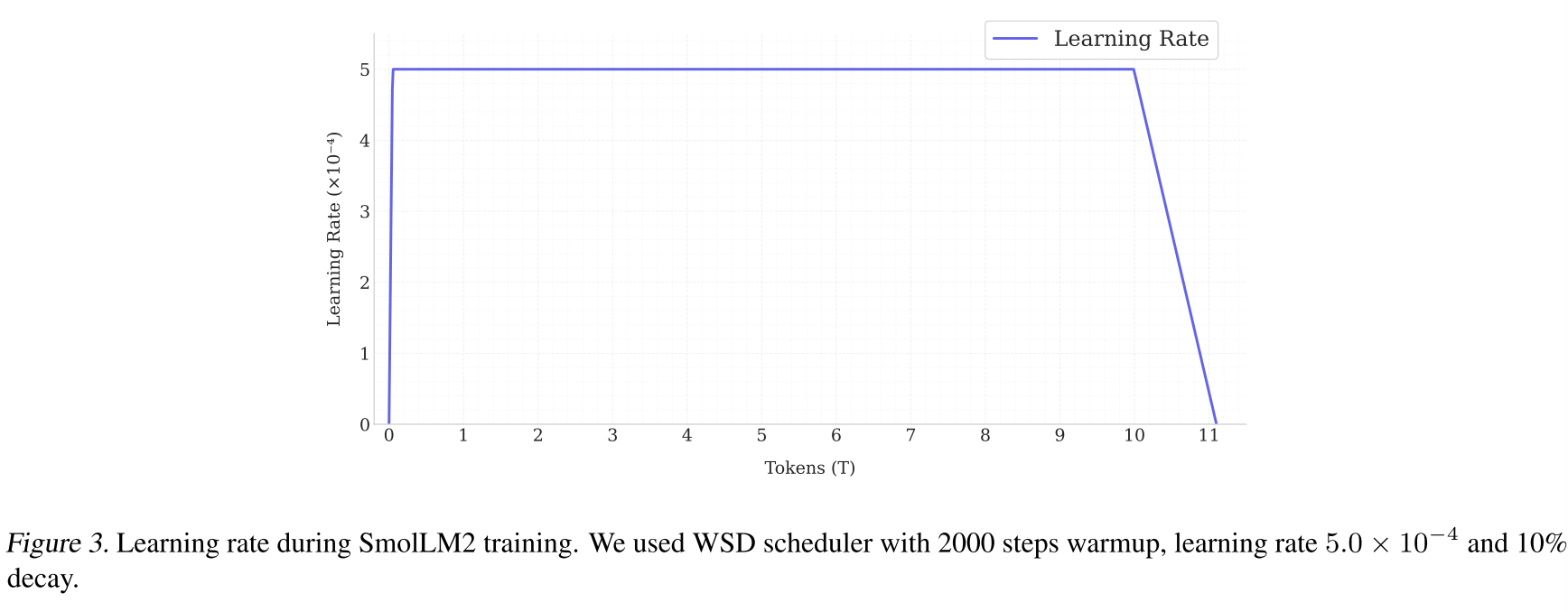
我們的基礎模型包含17億個參數,遵循LLama2(Touvron等人,2023)架構,附錄A中有詳細說明。我們使用nanotron框架(?)在256個H100上訓練模型,并使用AdamW優化器,其中\((\beta, \beta_{2})=(0.9, 0.95)\),并采用Warmup Stable Decay(WSD)(Hu等人,2024;Zhai等人,2022)學習率調度,以避免設置固定的訓練時長(見圖3,附錄A)。
nanotron?框架是 Hugging Face 開發的一個旨在簡化模型預訓練流程、加速大型 Transformer 模型定制化的預訓練框架。它具有以下特點和功能:
- 設計理念:核心圍繞簡單性和高性能,致力于將復雜的模型預訓練過程化繁為簡,讓開發者能夠快速地在自定義數據集上訓練自己的 Transformer 模型,提升了開發的便利性與效率 。
- 依托框架:PyTorch框架,集成了一系列高效的訓練策略 。
- 訓練策略與特性
- 分布式訓練:支持數據并行、張量并行和管道并行,通過這些并行技術,能顯著提升訓練效率,適應從小規模實驗到大規模工業級部署的不同需求,可將模型訓練任務拆分到多臺計算機上協同處理 。
- 專家平行:適用于混合專家模型,進一步優化訓練過程 。
- 高級特性:集成了如 ZeRO-1 優化器等高級特性,在加速模型學習的同時不犧牲精度。還支持參數綁扎、分片、自定義模塊檢查點,以及針對大規模模型的譜 μTransfer 參數化方法,在處理超大模型時具有獨特優勢 。
該調度從2000步的熱身階段開始,保持\(5.0×10^{-4}\)的峰值學習率(穩定階段),并在需要時轉換到衰減階段,在總訓練步數的10%內將學習率降至零(H?gele等人,2024)。我們使用Allal等人(2024)的分詞器,其詞匯表大小為49,152個詞元,是在70%的FineWeb-edu、15%的Cosmopedia-v2、8%的OpenWebMath、5%的StarCoderData和2%的StackOverflow的混合數據上進行訓練的。
?4.2 穩定階段:第1階段
數據混合:在SmolLM2預訓練的第一階段(0到6萬億個詞元),我們根據對英語網頁消融實驗的見解和現有文獻來設計數據集混合比例。對于網頁數據,我們采用60%的FineWeb-Edu和40%的DCLM的比例(在第2.2節中討論過),這在教育內容和多樣化的現實世界問答式數據之間提供了最佳平衡。
對于代碼數據,根據Aryabumi等人(2024)的方法,我們納入了StarCoderData,它包含80種編程語言的2500億個詞元,并將其限制在總混合比例的10%,以確保在11萬億個詞元的訓練中大約有4個epoch,同時為后續階段的上采樣留出空間。由于我們的數學數據集相對較小,在第1階段沒有包含數學數據。
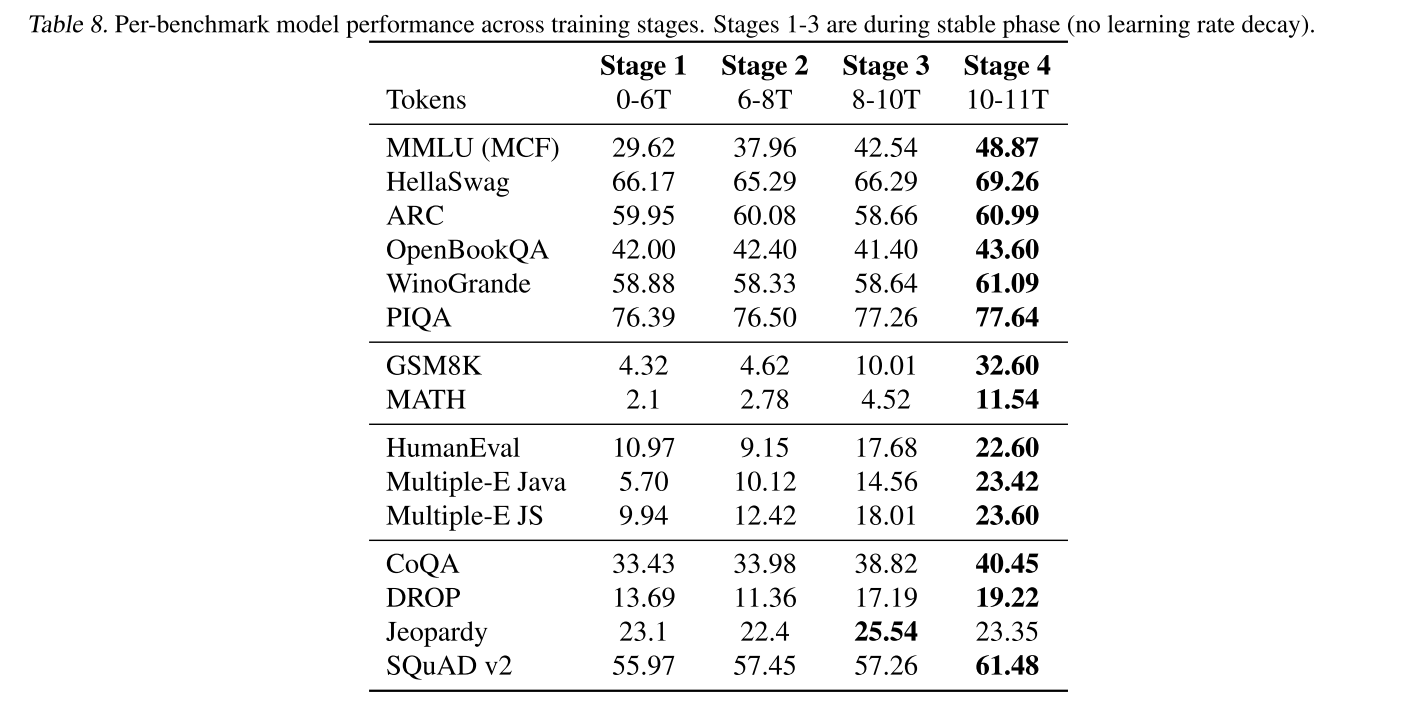
發現:在訓練6萬億個詞元后,我們在關鍵基準上對SmolLM2進行評估,結果如表3所示。知識和推理性能與我們基于英語網頁消融實驗的預期一致。然而,我們觀察到編碼和數學性能普遍較差。
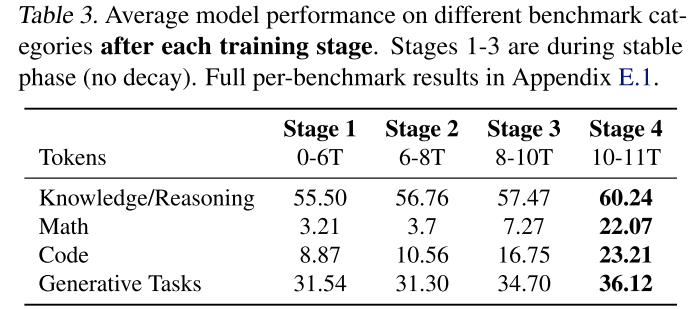
表3.在每個定型階段之后,不同基準類別的平均模型性能。階段1-3處于穩定階段(無衰變)。附錄E.1中列出了每項基準測試的完整結果。?
?4.3 穩定階段:第2階段
數據混合:在第2階段(6萬億到8萬億個詞元),我們將OWM以5%的比例添加到混合數據中,并增加代碼數據的比例,希望在保持強大的知識保留能力的同時,解決觀察到的編碼和數學推理方面的差距。以較低比例納入OWM反映了該數據集的規模較小(120億個詞元),以及我們逐步納入數學內容的方法。
第2階段的最終混合數據包括75%的英語網頁數據(保持第1階段中FineWeb-Edu與DCLM的60/40比例)、20%的代碼數據和5%的數學數據,如圖2所示。
發現:在第2階段之后,大多數語言的代碼性能都有所提高,這驗證了對StarCoderData進行上采樣的決策。OWM的集成對數學性能沒有顯著影響,這突出了在后續階段需要更大、更高質量的數學數據集。
除了代碼和數學性能外,如圖6(附錄E.2)所示,我們觀察到在多項選擇形式(MCF,即明確從’A’、’B’、’C’或’D’中輸出一個選項,而不是像完形填空形式那樣計算不同答案的可能性)的MMLU測試中,準確率高于隨機水平(>25%)。
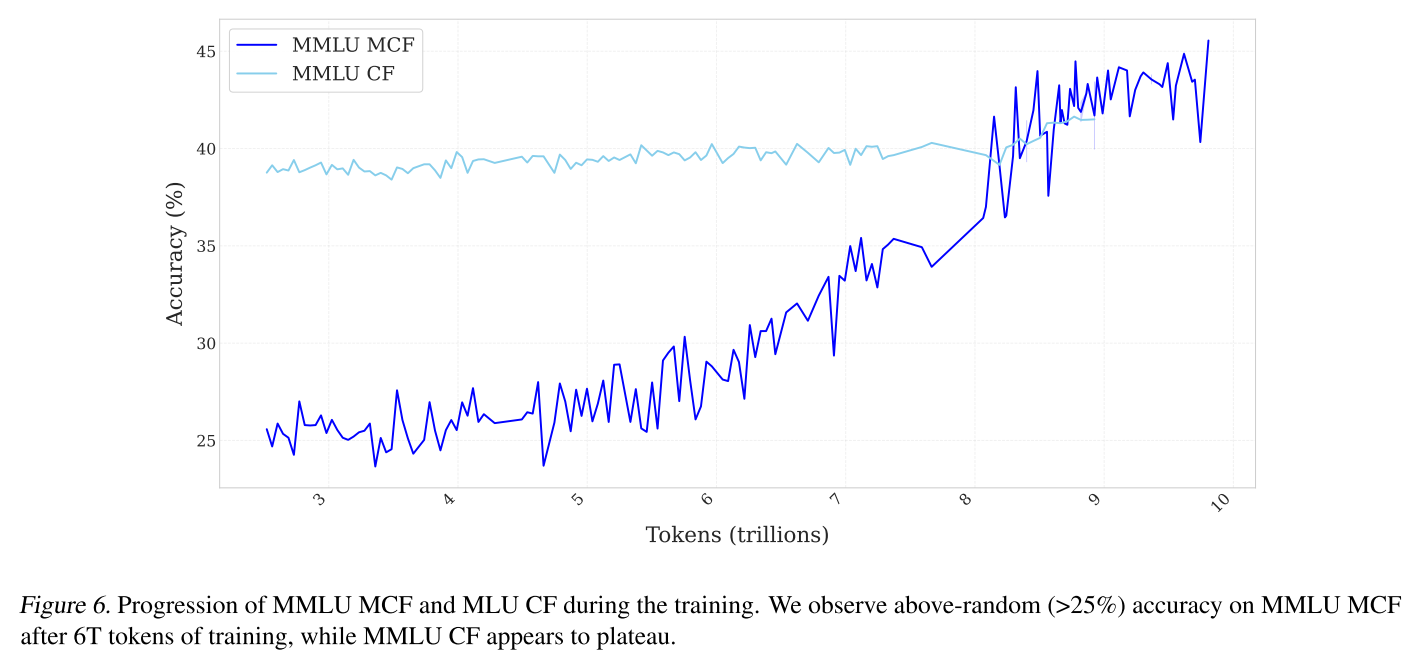
這與之前的研究結果形成對比,之前的研究表明小模型在MCF上存在困難(Gu等人,2024;Du等人,2024),這表明對小模型進行長時間訓練可以使其獲得通常與大模型相關的能力(Blakeney等人,2024;Gu等人,2024;Du等人,2024)。
為了進一步優化MMLU性能,我們通過額外的退火消融實驗重新審視了我們的英語數據集混合比例,發現在此階段相對于FineWeb-Edu增加DCLM的比例可以略微提高MMLU MCF的成績。
?4.4 穩定階段:第3階段
數據混合:在穩定階段的第三也是最后一個階段(8萬億到10萬億個詞元,在退火開始之前),我們將InfiMM-WebMath的純英語文本部分與OWM一起添加進來,使數學數據的總比例達到約10%,如圖2所示。
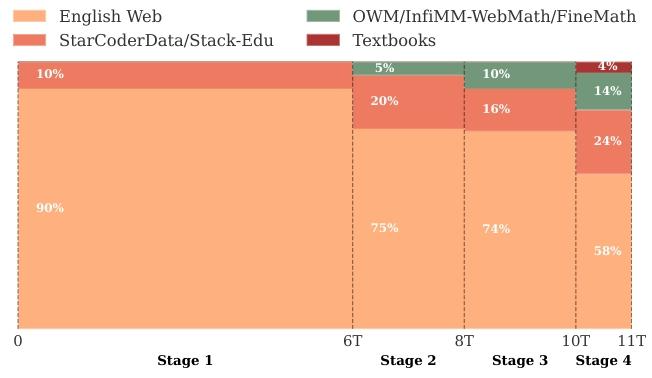
圖2.訓練階段的數據集混合。詳細描述見第4節。x軸表示訓練令牌的數量。?
對于英語網頁數據,我們回顧了消融實驗的結果,并將FineWeb-Edu與DCLM的比例調整為40/60。對于代碼數據,我們用Stack-Edu(第3.4節)取代了StarCoderData。對于在Stack-Edu中詞元數量少于40億的語言(TypeScript、Shell、Swift、Go、Rust和Ruby),我們使用它們在StarCoder2Data中的子集。我們還添加了來自StarCoder2(Lozhkov等人,2024)的Jupyter筆記本,它提供了豐富的、帶有解釋的代碼上下文示例,增強了模型在編程任務方面的推理能力。
發現:雖然這些新數據集的集成在多個基準上帶來了改進,但我們在這個階段觀察到了明顯的損失峰值,即使在回滾訓練并跳過與峰值相關的數據后,這種損失仍然存在(Chowdhery等人,2023;Almazrouei等人,2023)。確切原因尚不清楚,但大多數評估指標在該階段結束時恢復了。
?4.5 衰減階段:第4階段
數據混合:最后一個階段是在總訓練時長的10%(從10萬億到11萬億個詞元)內將學習率線性衰減至0(H?gele等人,2024)。根據Blakeney等人(2024)的方法,我們引入了我們最高質量的數學數據集InfiWebMath-3 +和FineMath 4 +。此外,我們將混合數據的0.08%分配給OWM,0.02%分配給AugGSM8K(Li等人,2024a),這是GSM8K基準訓練集的增強版本,已成為近期預訓練數據集的常見組成部分(Achiam等人,2023;Dubey等人,2024;Ai2,2024)。
總體而言,數學內容占混合數據的14%。我們擴展了Stack-Edu,納入了第3階段未涵蓋的其他編程語言,并將該數據集的占比設置為混合數據的24%。我們保持了各編程語言之間的自然分布,對Python的分配比例更高。
剩余的混合數據包括58%的英語網頁數據(保持DCLM相對于FineWeb-Edu更高的比例)和4%的Cosmopedia v2(Allal等人,2024),它提供了300億個高質量的合成教科書、博客文章和故事詞元。
發現:在第4階段之后,所有基準任務都有改進,我們觀察到編碼性能有顯著提升,最明顯的是數學性能,這驗證了我們針對這些領域的特定數據混合策略。
?4.6 上下文長度擴展
為了支持長上下文應用,我們遵循標準做法(Gao等人,2024),將上下文長度從2k擴展到8k詞元。具體做法是從第4階段(在最后750億個詞元訓練之前)獲取一個中間檢查點,然后使用不同的數據混合比例和RoPE值為130k繼續訓練。混合數據調整為包含40%的長上下文文檔(8k詞元或更多),這些文檔來自DCLM(10%)、FineWeb-Edu(10%)和Dolma的書籍子集(20%)(Soldaini等人,2024),而其余60%遵循第4階段的混合比例。經過這一步,我們得到了最終的SmolLM2基礎模型。
上下文長度擴展是指增加模型在處理文本時能夠考慮的前后文信息的長度。在自然語言處理中,模型理解當前文本往往需要依賴其前后的內容,更長的上下文長度能讓模型獲取更豐富的語境信息,從而更準確地處理復雜的語言任務。例如在閱讀理解、文本生成等任務里,長上下文能幫助模型更好地把握文章整體脈絡和語義關聯,做出更合理的回答或生成更連貫的文本。在本文中,SmolLM2 將上下文長度從 2k 擴展到 8k 詞元,意味著模型在處理文本時可以參考更廣泛的前后文內容,增強其對長文本的理解和處理能力。
原因
- 支持長上下文應用:隨著自然語言處理任務的日益復雜,許多應用場景需要模型能夠處理長文本,如長篇文章的閱讀理解、長對話的理解與生成等。擴展上下文長度可以使 SmolLM2 更好地支持這些長上下文應用,滿足實際需求。例如在處理長篇技術文檔或多輪復雜對話時,更長的上下文能幫助模型綜合更多信息,提供更準確、更連貫的回答或生成更優質的文本 。
- 提升模型性能:長上下文能為模型提供更豐富的語境信息,有助于模型更準確地理解文本含義,從而提升在各種任務上的性能。通過擴展上下文長度并在訓練中融入長上下文文檔,模型可以學習到長文本中的復雜語義關系和邏輯結構,進而在涉及長文本理解和生成的任務中表現更出色 。
具體做法
- 獲取中間檢查點:從第 4 階段(在最后 750 億個詞元訓練之前)獲取一個中間檢查點。這個中間檢查點包含了模型在之前訓練階段學習到的參數和知識,作為后續繼續訓練以擴展上下文長度的基礎。
- 調整數據混合比例:使用不同的數據混合比例繼續訓練。混合數據調整為包含 40% 的長上下文文檔(8k 詞元或更多),這些文檔分別來自 DCLM(占 10%)、FineWeb - Edu(占 10%)和 Dolma 的書籍子集(占 20%)。其余 60% 遵循第 4 階段的混合比例。通過這種數據混合方式,讓模型在繼續訓練過程中逐漸適應長上下文的學習,從不同來源的長文本數據中學習長序列信息處理的能力。
- 設置 RoPE 值:將 RoPE(旋轉位置嵌入,Rotary Position Embeddings)值設為 130k。RoPE 是一種位置編碼方式,它能讓模型更好地捕捉文本中詞元的相對位置關系。設置特定的 RoPE 值有助于模型在處理擴展后的長上下文時,更有效地利用位置信息,提升對長序列文本的理解和處理效果 。
?4.7 基礎模型評估
我們在廣泛的基準上評估并比較最終的SmolLM2基礎模型與現有的類似規模的最先進模型,即Qwen2.5-1.5B(Yang等人,2024b)和Llama3.2-1B(AI@Meta,2024a)。除非另有說明,評估使用lighteval并在零樣本設置下進行。
表4中的評估結果顯示了SmolLM2基礎模型的強大性能,在HellaSwag和ARC上的表現優于Qwen2.5基礎模型。SmolLM2在訓練期間未監控的保留基準上也表現出色,如MMLU-Pro(Wang等人,2024c)、TriviaQA(Joshi等人,2017)和Natural Questions(NQ,Kwiatkowski等人,2019)。值得注意的是,該模型在MMLU-Pro上比Qwen2.5-1.5B高出近6個百分點,進一步驗證了其泛化能力。
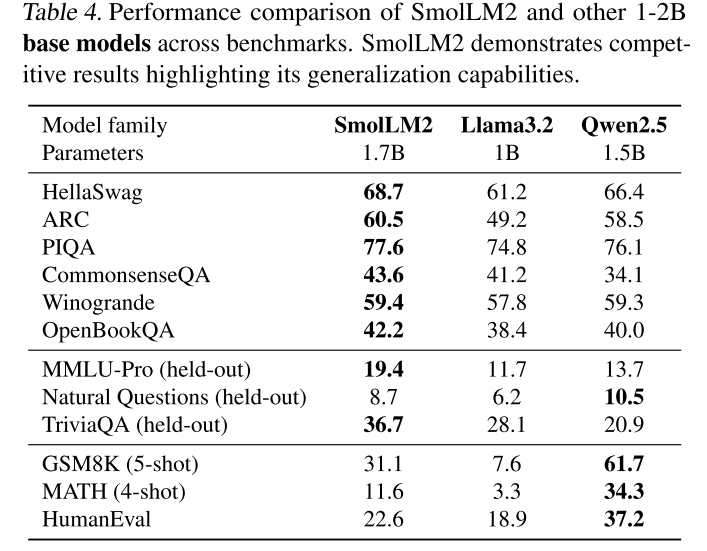
表4.SmolLM 2與其他1- 20億基本機型在性能指標評測中的性能比較。SmolLM 2展示了突出其泛化能力的競爭性結果。?
在數學和編碼基準上,SmolLM2表現出有競爭力的性能。雖然它在某些方面落后于Qwen2.5-1.5B,但在GSM8K、MATH和HumanEval上的表現優于Llama3.2-1B。
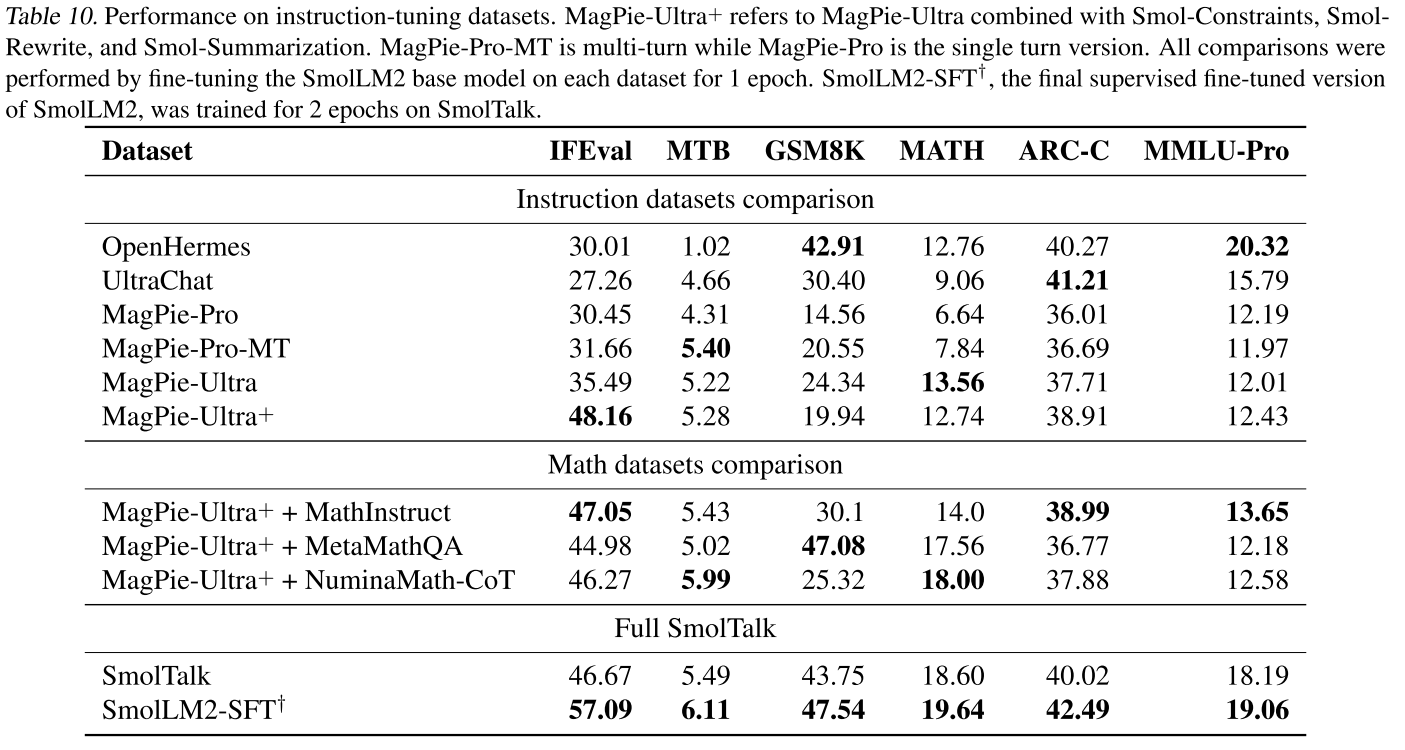
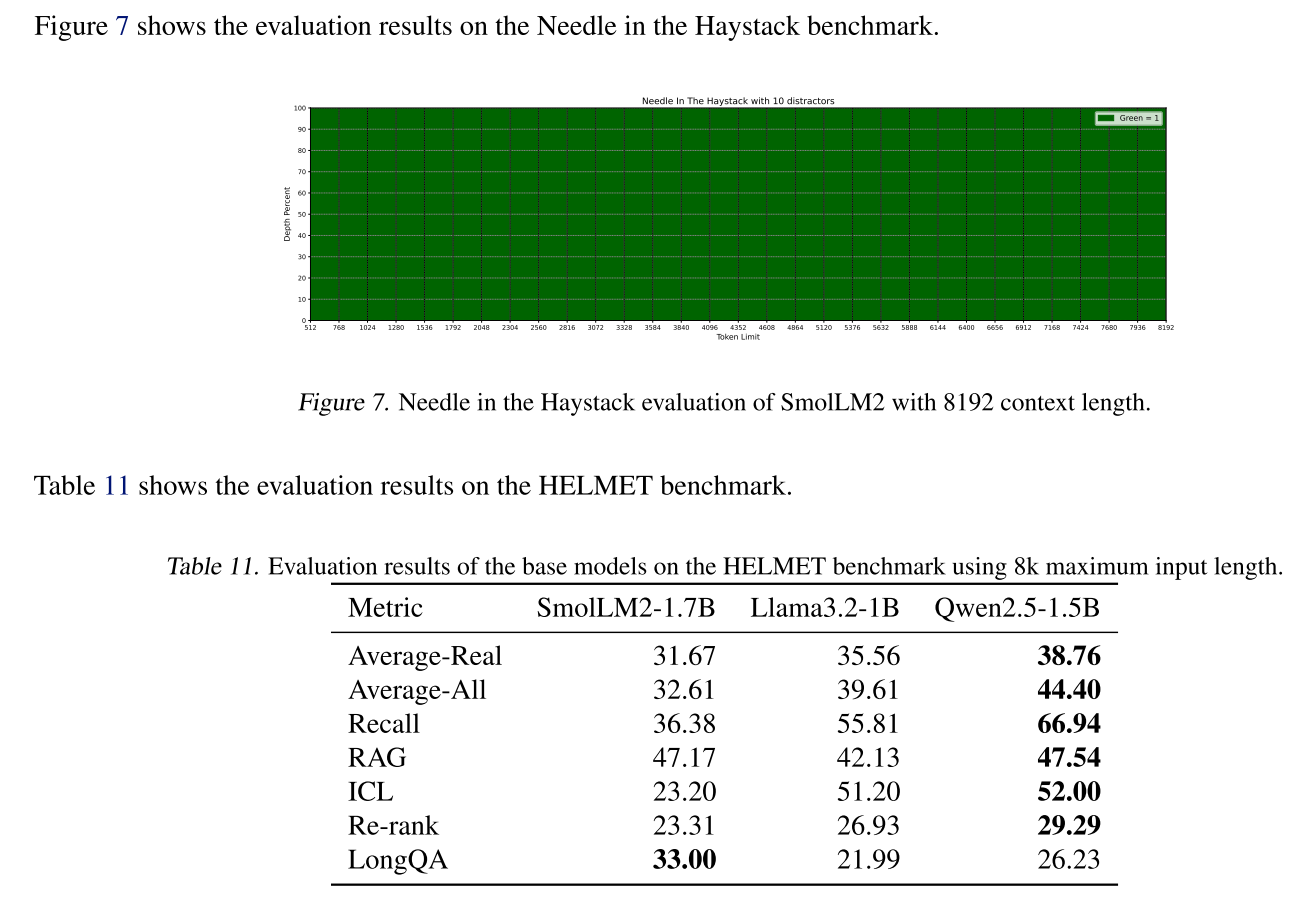
重要的是,在上下文長度擴展后,我們幾乎沒有看到性能下降,而HELMET(Yen等人,2024)和Needle in the Haystack(NIAH)(Kamradt,2024)的結果顯示出強大的性能-見附錄G。這些結果突出了我們精心整理的數據集、數據混合比例和訓練階段的有效性。
?5 訓練后處理
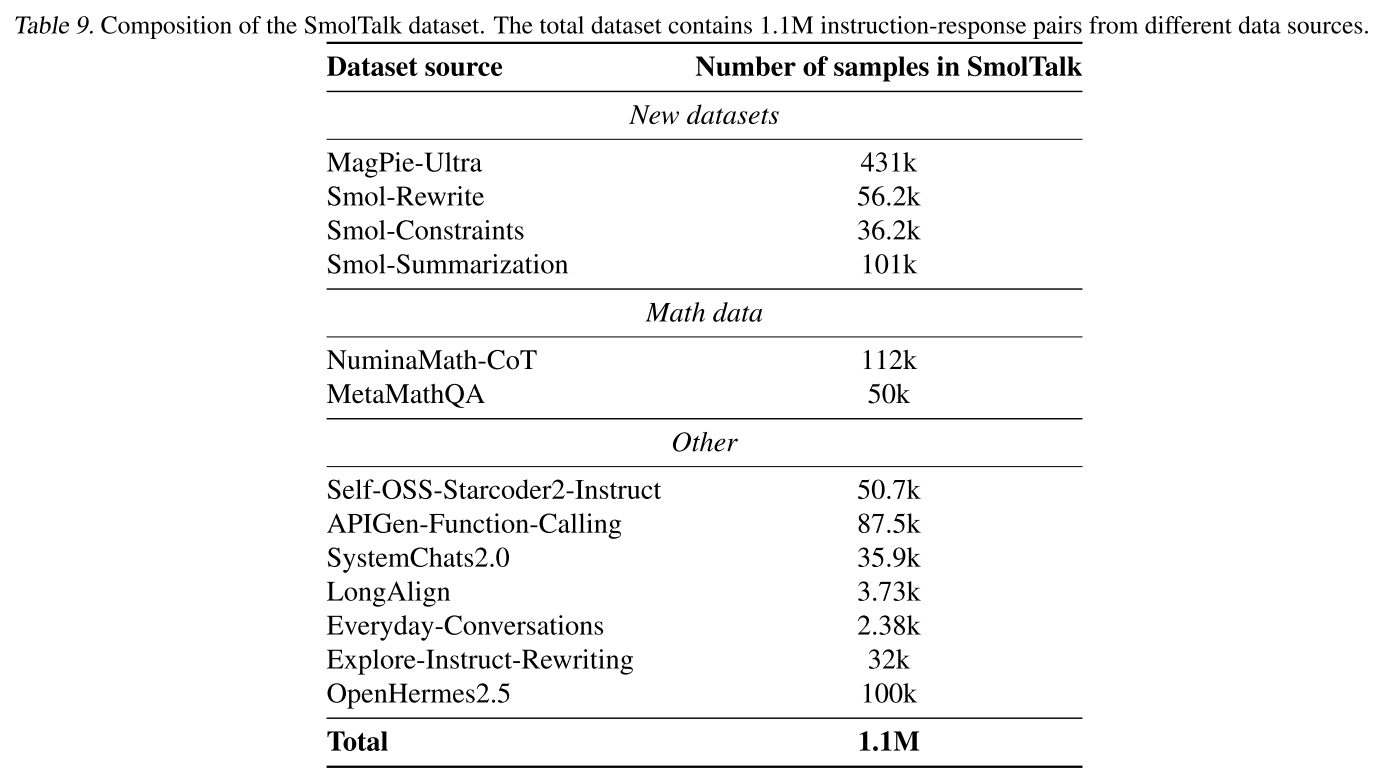
在訓練完SmolLM2基礎模型后,我們遵循當前的標準做法,通過指令調優和偏好學習進行訓練后處理,以最大化性能和實用性。在訓練后處理階段,我們除了使用一個名為SmolTalk的新指令調優數據集外,還利用了現有數據集。
- 基本概念:偏好學習的核心是讓模型學習如何區分不同輸出的優劣,使模型朝著更符合預期用途的方向調整。在語言模型領域,模型訓練完成后,雖然具備一定能力,但輸出可能并非總是符合用戶期望或實際應用的最佳結果。偏好學習就是通過訓練模型來識別有用和無用的響應,讓模型的輸出更加合理和實用。
- 具體操作:文中提到使用直接偏好優化(Direct Preference Optimization, DPO)進行偏好學習 。在 DPO 過程中,模型會在有偏好標簽的數據上進行訓練。這些標簽可以是人工標注的,也可以是通過合成生成的,用來表示不同輸出的質量高低或用戶偏好程度。例如,對于一個問答任務,可能會將更準確、更詳細、更符合用戶需求的回答標記為更受偏好的答案,模型通過學習這些偏好標簽,調整自身參數,使得后續生成的回答更接近這些優質答案。
- 應用目的:偏好學習能提升模型在多種任務上的表現。在 SmolLM2 的訓練中,通過偏好學習,模型在 MT - Bench、MMLU - Pro 和 MATH 等基準測試中的成績得到改善 ,這表明模型在指令跟隨、知識問答和數學推理等方面的能力有所提升,使其更適合作為實用的聊天助手等應用場景。
?5.1 SmolTalk
盡管SmolLM2基礎模型在10-20億參數范圍內的表現優于其他最先進的基礎模型,但在像MagPie-Pro(Xu等人,2024)或OpenHermes2.5(Teknium,2023b)這樣的公共數據集上進行微調后,其性能低于這些其他模型的訓練后版本。
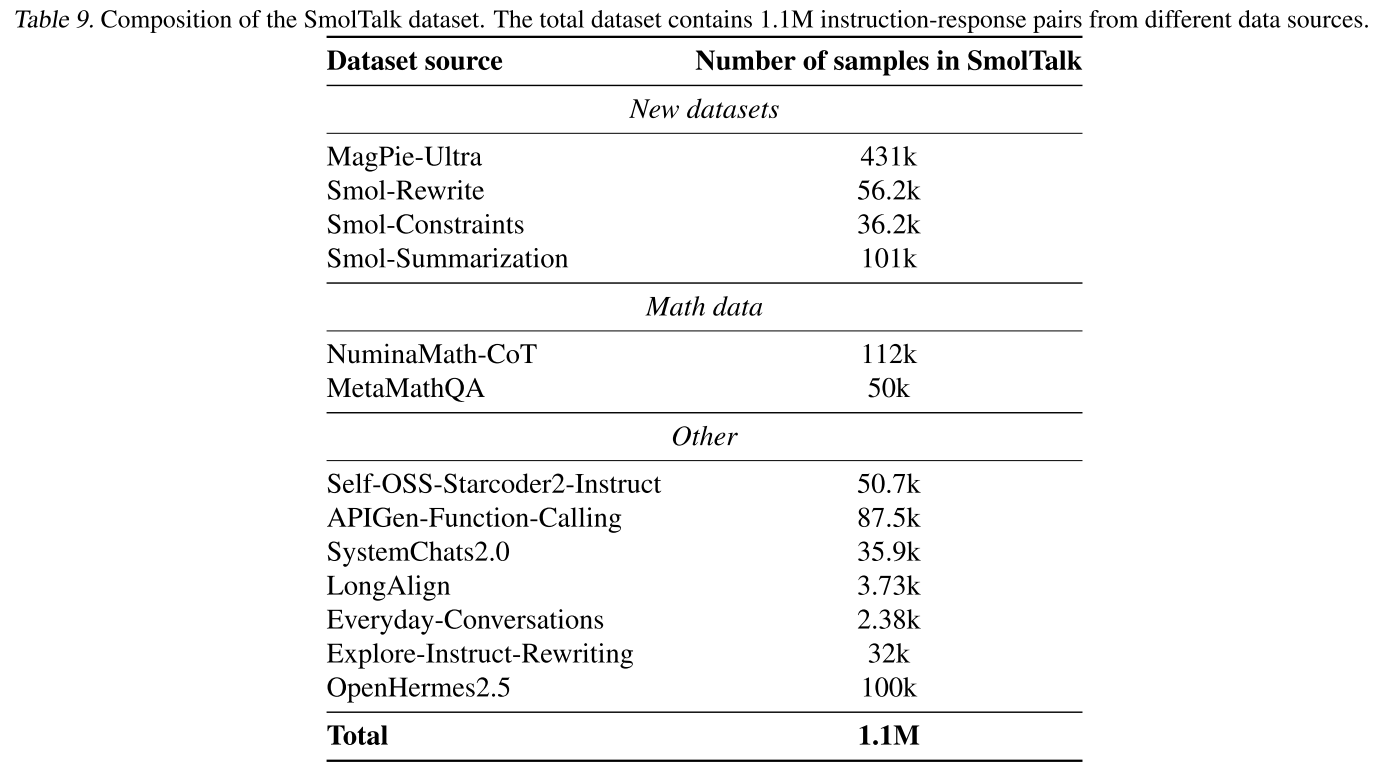
這一觀察結果促使我們開發SmolTalk2,這是一個新的指令跟隨數據集,它仔細地將選定的現有數據集與我們開發的新合成數據集相結合,包括Magpie-Ultra對話數據集以及其他解決特定能力的專業數據集,如Smol-Constraint、Smol-Rewrite和Smol-Summarization。所有數據集都是使用Distilabel(Bartolomé Del Canto等人,2024)生成的。
?5.1.1 對話數據
MagPie-Ultra是一個多輪數據集,使用(Xu等人,2024)中的兩步提示方法創建。與MagPie不同,MagPie使用Llama-3-70B-Instruct且沒有特定的系統提示來生成兩輪對話,而MagPie-Ultra利用更大、更強大的模型Llama-3.1-405B-Instruct-FP8(Dubey等人,2024)。
我們還納入了系統提示來指導生成,生成了一個包含100萬個樣本的平衡數據集,每個樣本包含三輪對話。生成的數據集進一步使用較小的Llama模型(Llama-3. 5.1.1 對話數據MagPie-Ultra是一個多輪數據集,采用(Xu等人,2024)提出的兩步提示法創建。
與MagPie不同,MagPie使用Llama-3-70B-Instruct且未設置特定系統提示來生成兩輪對話,而MagPie-Ultra借助更大且更強大的模型Llama-3.1-405B-Instruct-FP8(Dubey等人,2024),同時納入系統提示以引導生成過程,最終產出了一個包含100萬個樣本的均衡數據集,每個樣本均為三輪對話。
隨后,我們利用較小的Llama模型(Llama-3.1-8B-Instruct和Llama-Guard-3-8B)對生成的數據集進行篩選,以確保生成指令的質量和安全性。此外,我們還借助ArmoRM(Wang等人,2024b;a)對對話進行質量評分篩選,并使用gte-large-env1.5(Zhang等人,2024;Li等人,2023c)對語義相似的對話進行去重處理。
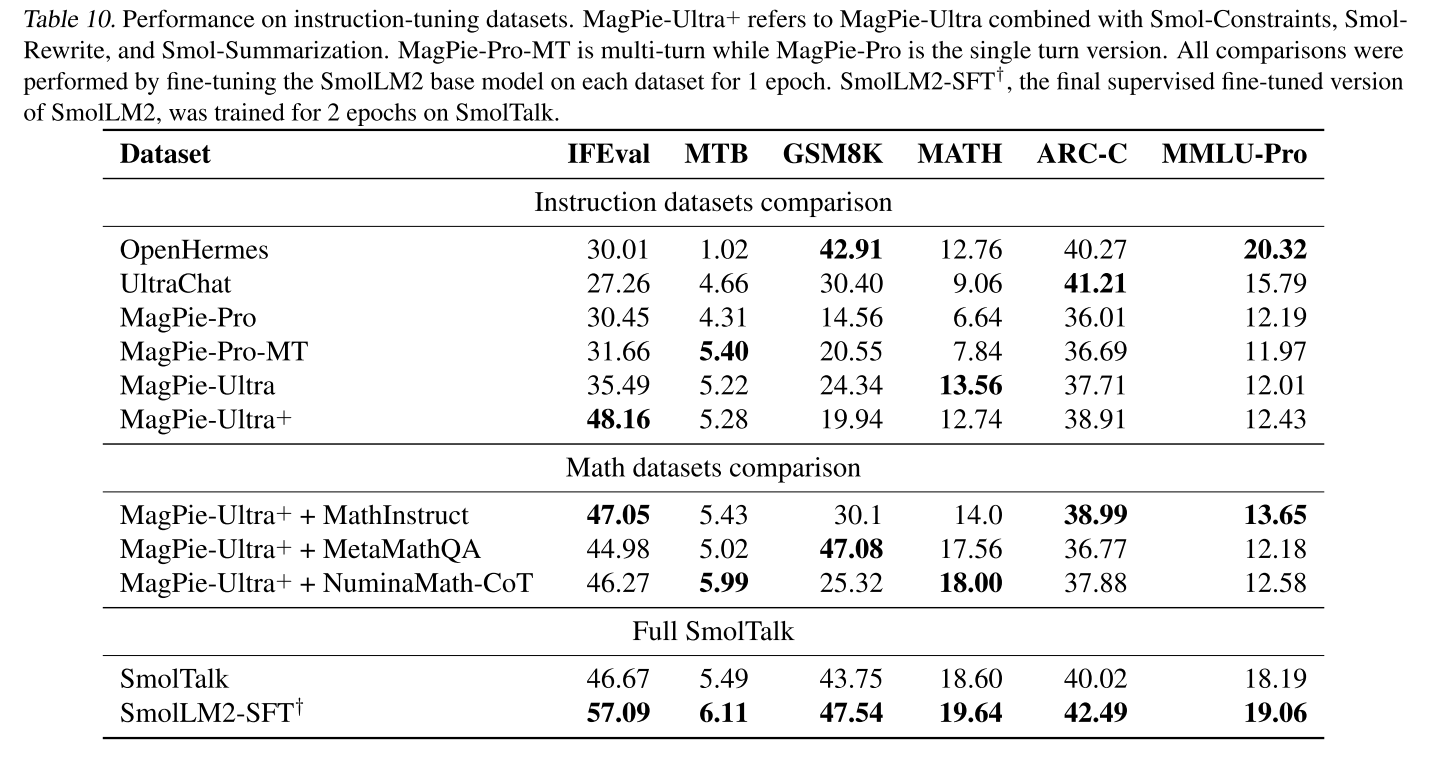
我們在表10(附錄F)中將MagPie-Ultra與現有的公開監督微調(SFT)數據集進行了比較。評估套件涵蓋指令跟隨和對話基準測試IFEval(Zhou等人,2023)和MTBench(Zheng等人,2023);ARC Challenge中的推理任務;MMLU-Pro中的知識測試;以及用于數學評估的GSM8K和MATH。我們的數據集在大多數基準測試中優于MagPie-Pro,并且在IFEval和MT-Bench上大幅超越OpenHermes2.5和UltraChat(Ding等人,2023)。
表10顯示了在我們考慮的SmolTalk的不同組件上訓練后的性能。上半部分比較了基于不同指令數據集微調SmolLM 2的結果,下半部分評估了在SFT期間將20%專用數學數據添加到80% MagPie-Ultra+的基礎混合物中的影響。最后一行,SmolLM 2-SFT,表示在DPO之前SmolLM 2的最終SFT檢查點,在完整的SmolTalk數據集上訓練了兩個epoch。
表10.指令調優數據集上的性能。MagPie-Ultra+是指結合了Smol約束、Smol重寫和Smol匯總的MagPie-Ultra。MagPie-Pro-MT是多圈型,而MagPie-Pro是單圈型。所有比較均通過在每個數據集上微調SmolLM 2基礎模型進行,持續1個時期。SmolLM 2-SFT?是SmolLM 2的最終監督微調版本,在SmolTalk上訓練了2個時期。
?5.1.2 特定任務數據
我們開發了額外的特定任務數據集,以進一步增強模型在指令跟隨方面的能力,使其具備詳細約束(Smol-Constraint)、總結(Smol-Summarization)和改寫(Smol-Rewrite)等功能。Smol-Constraint包含3.6萬個帶有詳細約束的指令,這些約束與IFEval(Zhou等人,2023)中的類似。我們采用(Xu等人,2024)的方法并設置針對性的系統提示,使用Qwen2.5-72B-Instruct(Yang等人,2024b)為這些指令生成了55萬個指令和響應。
然后,我們篩選掉包含沖突約束或錯誤響應的生成指令,最終得到5.63萬個指令-響應對,在針對IFEval進行去污染處理(10元語法重疊)后,得到3.6萬個對。對于Smol-Summarization和Smol-Rewrite,我們首先生成高質量的源文本,作為總結和改寫任務的基礎。
我們利用PersonaHub(Ge等人,2024)和FinePersonas數據集(Argilla,2024;Chan等人,2024)中的人物角色,合成了一系列多樣化的電子郵件、推文、領英帖子和筆記。通過向Qwen2.5-72B-Instruct提供特定的系統提示和人物角色描述,我們能夠生成具有不同寫作風格、主題和視角的文本。
接著,我們讓Qwen2.5-72B-Instruct對給定文本進行總結和改寫,分別獲得約100萬個總結和60萬個改寫文本。將這3個Smol數據集添加到MagPie-Ultra中(MagPieUltra+),進一步提升了在IFEval上的性能,如表10(附錄F)所示。
?5.1.3 數學數據
為了提升數學推理能力,我們通過在包含80%通用指令數據(MagPie Ultra + Smol-Constraint、Smol-Rewrite、Smol-Summarization)和20%來自不同來源的數學數據的混合數據上進行微調,對公開的數學指令數據集進行了評估。表10(附錄F)中的結果凸顯了不同數據集的互補優勢:NuminaMath-CoT(Li等人,2024b)在MATH和MT-Bench上表現出色,而MetaMathQA(Yu等人,2023,也包含在OpenHermes2.5中)在GSM8K上的結果有所改善。基于這些發現,我們將這兩個數據集的組合納入了SmolTalk。
?5.1.4 其他專業數據
對于代碼生成,我們使用了Self-OSS-Starcoder2Instruct(Wei等人,2024a),其中包含5萬個高質量的Python指令-響應對。為了支持系統提示,我們從SystemChats2.0(Computations,2024)中隨機選取了3萬個樣本,并且為了實現函數調用功能,我們添加了來自APIGen-FunctionCalling(Liu等人,2024)的8萬個樣本。
此外,為了在長上下文任務中保持強大的性能,我們納入了LongAlign(Bai等人,2024)的英語子集(3700個樣本,長度為8k-16k詞元)。由于OpenHermes2.5在知識(MMLU-Pro)、日常對話(Face,2024)、2200個休閑多輪交互以及ExploreInstruct(Wan等人,2023)改寫任務中表現出色,我們還隨機添加了10萬個OpenHermes2.5樣本。
我們發現,按指定數量納入這些數據集能夠有效增強模型在目標能力方面的表現,同時在其他基準測試中也能保持良好的性能。
?5.2 監督微調(SFT)
表9(附錄F)展示了SmolTalk的最終組成。我們在SmolTalk上對基礎SmolLM2進行了2輪監督微調,全局批次大小為128,序列長度為8192,學習率為\(3.0×10^{-4}\)。此SFT階段后的評估結果見表10(附錄F)。
?5.3 對齊
對于偏好學習,我們采用直接偏好優化(DPO)(Rafailov等人,2024)。我們對各種公開的合成反饋數據集(Ivison等人,2024)進行了實驗,包括UltraFeedback(Cui等人,2024)、UltraInteract(Yuan等人,2024)、Capybara(Daniele & Suphavadeeprasit,2023)和ORCA(Lv等人,2023)。結果表明,UltraFeedback在各個基準測試中表現最為穩定有效,能夠提升MT-Bench、MMLU-Pro和MATH的成績。我們進行了2輪訓練,學習率為\(1.0×10^{-6}\),beta值為0.5,全局批次大小為128,序列長度為1024詞元。在完成這一最終的DPO訓練階段后,我們得到了指令調優后的SmolLM2模型。正如Dubey等人(2024)所指出的,在DPO中使用短上下文數據不會影響模型的8k上下文處理能力。
?5.4 指令模型評估
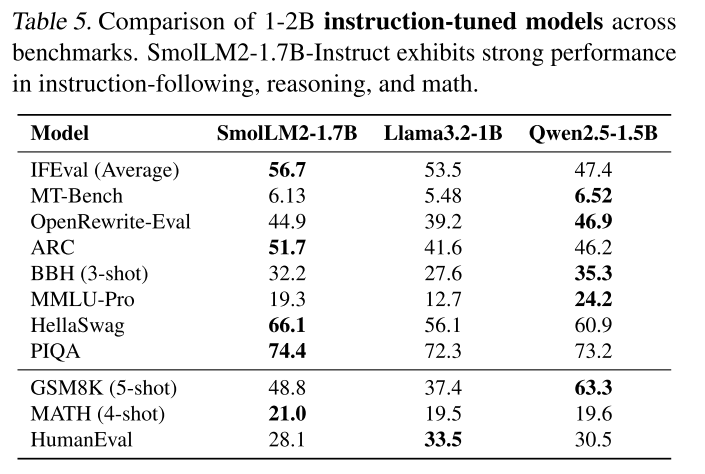
我們對最終的指令調優版本SmolLM2進行評估,并將其與Qwen2.5-1.5B和Llama3.2-1B的指令調優變體進行比較,結果見表5。SmolLM2-Instruct展現出強大的指令跟隨能力,在IFEval上的表現遠超Qwen2.5-1.5B-Instruct;在MT-Bench和OpenRewriteEval(Shu等人,2024)的文本改寫任務中具有競爭力;并且在GSM8K和MATH的分數中體現出強大的數學能力。這些結果突出了SmolLM2在各種任務中的泛化能力,展示了其作為強大聊天助手的潛力。
?6 SmolLM2 135M和360M
除了SmolLM2-1.7B,我們還訓練了兩個更小的模型:SmolLM2-360M(3.6億參數,在4萬億詞元上進行訓練)和SmolLM2-135M(1.35億參數,在2萬億詞元上進行訓練),它們在各自的參數規模類別中同樣處于領先水平。鑒于它們較小的容量和較低的訓練成本,我們在目標訓練長度上重新進行數據消融實驗,以確定最有效的數據混合方案。
我們發現,使用FineWeb-Edu分類器對DCLM進行篩選,去除分數為0的樣本,并對分數為1和2的樣本進行下采樣的效果最佳。與采用多階段訓練策略的SmolLM2-1.7B不同,這些較小的模型受益于單階段訓練方法,且訓練數據始終保持高質量。
我們從一開始就納入了Stack-Edu,以及InfiMM-WebMath、FineMath和Cosmopedia。這些模型與SmolLM2-1.7B具有相同的架構,但使用分組查詢注意力(GQA),并采用WSD調度器進行訓練,衰減率為20%,學習率為\(3.0×10^{-3}\)。
在訓練后處理階段,我們使用經過篩選的SmolTalk3進行SFT,去除了復雜的指令跟隨任務(例如函數調用)和MagPie-Ultra中的難題,以更好地匹配模型的能力。最后,我們使用UltraFeedback進行DPO訓練,在保持連貫性和實用性的同時,優化模型的指令跟隨能力。關于SmolLM2-360M和135M的更多詳細信息,可在它們各自的模型卡片中查看。
?7 結論
SmolLM2通過精心整理數據集和多階段訓練,推動了開放小型語言模型的發展,達到了新的技術水平。我們的方法強調了高質量、專業化數據集在使較小模型在各種基準測試中取得優異性能方面的關鍵作用。
FineMath、Stack-Edu和SmolTalk的開發彌補了現有公開數據集的不足,提升了模型在推理、數學和指令跟隨任務方面的能力。為了支持未來的研究與開發,我們發布了SmolLM2以及訓練過程中使用的數據集和代碼。這些資源為訓練高性能小型語言模型提供了全面的基礎,使更廣泛的研究人員和應用能夠使用它們。
?影響聲明
本文所呈現的工作旨在推動機器學習領域的發展。我們的工作可能會產生許多潛在的社會影響,但在此我們認為無需特別強調其中任何一點。
?
附錄
?A. 訓練設置
表6展示了SmolLM2 17億參數版本的架構細節。
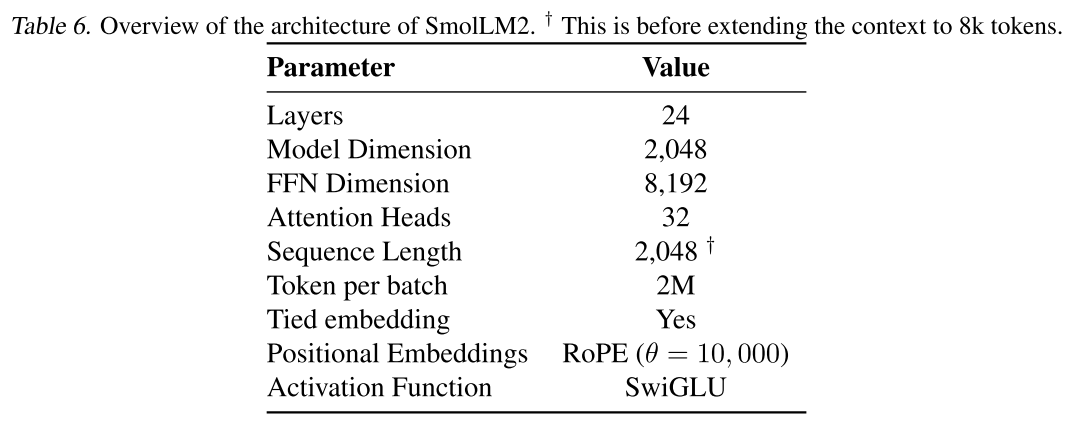
表6 SmolLM2架構概述。? 這是在將上下文擴展到8k詞元之前的情況。
圖3展示了使用WSD調度器在訓練過程中學習率的變化情況。
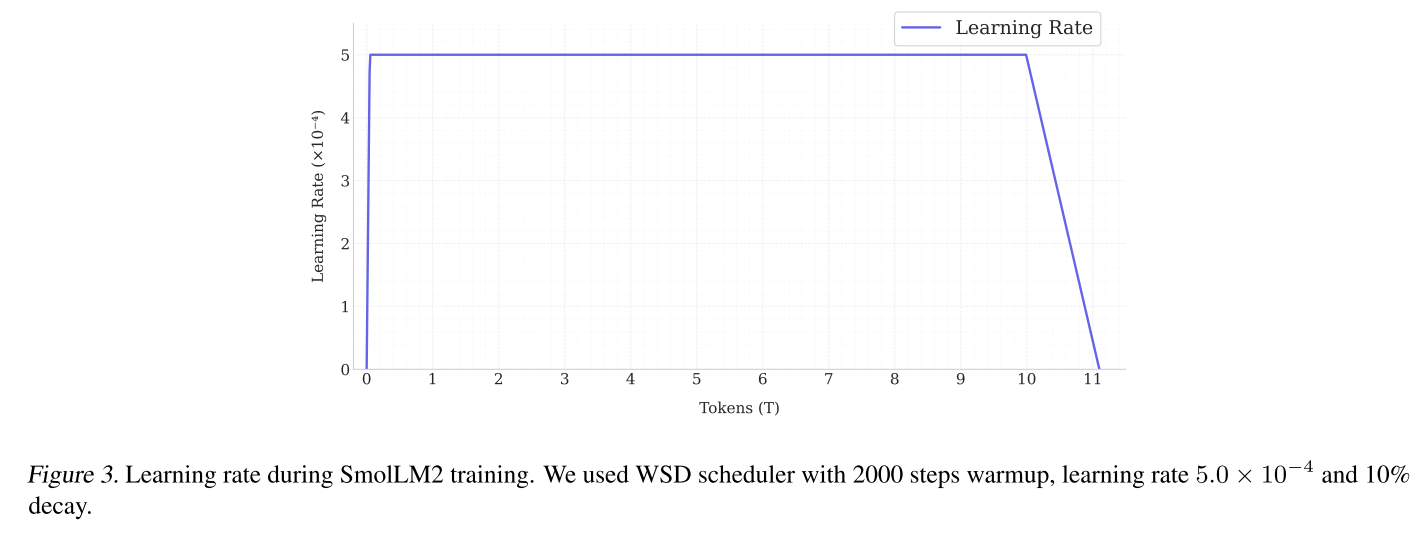
圖3 SmolLM2訓練期間的學習率。我們使用了帶有2000步熱身、學習率為\(5.0×10^{-4}\) 且衰減率為10%的WSD調度器。
?B. 英語網頁數據消融實驗
圖4展示了在DCLM、FineWeb-Edu及其混合數據集上使用3500億個詞元訓練的消融模型的評估曲線。
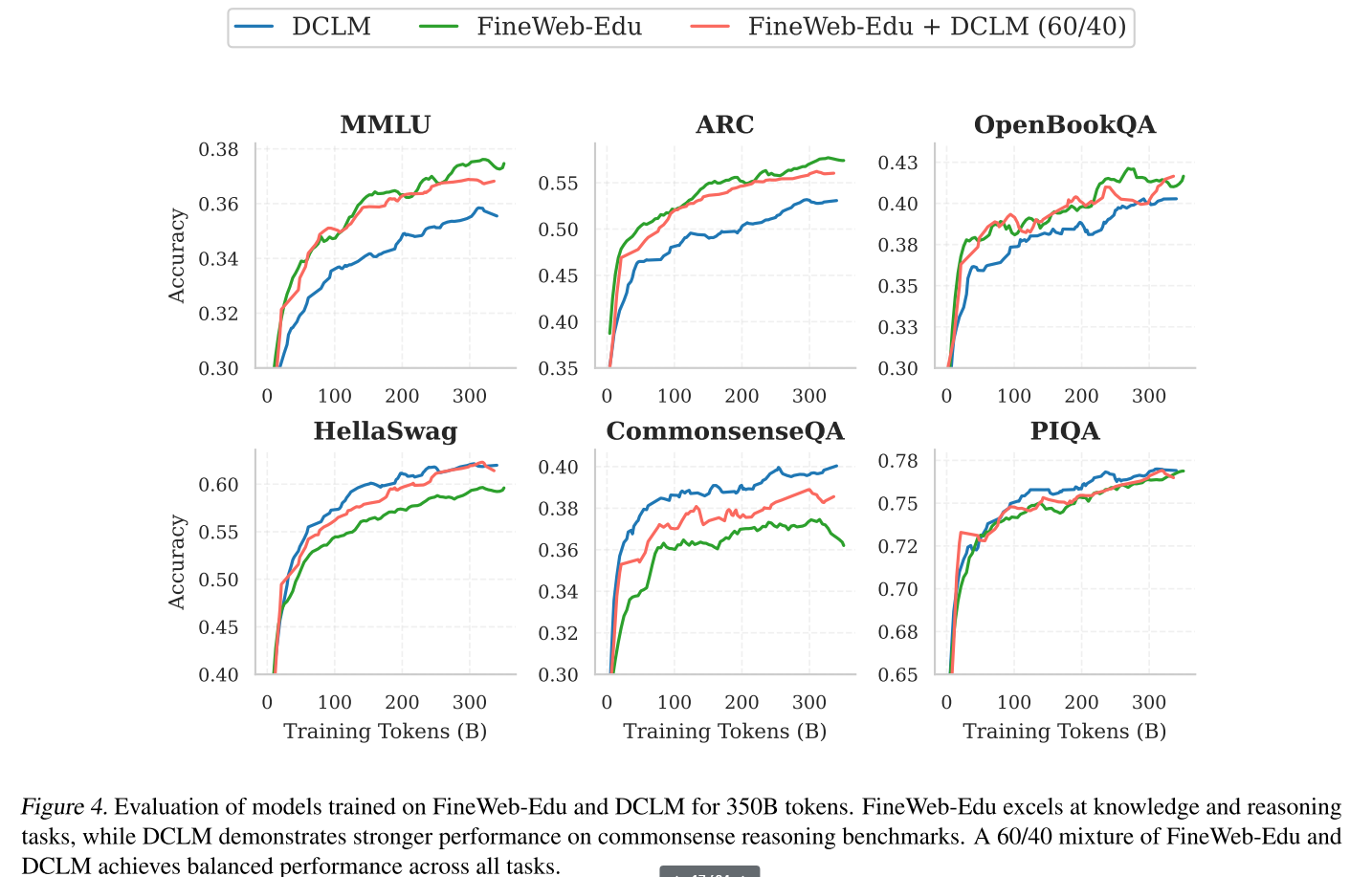
圖4 在FineWeb-Edu和DCLM上使用3500億個詞元訓練的模型評估。FineWeb-Edu在知識和推理任務上表現出色,而DCLM在常識推理基準測試中表現更強。FineWeb-Edu和DCLM按60/40的混合比例在所有任務中實現了平衡的性能。
?C. FineMath
C.1 公共數據集比較
圖5展示了在OWM和InfiMM-WebMath上訓練的消融模型在GSM8K和MATH上的性能。
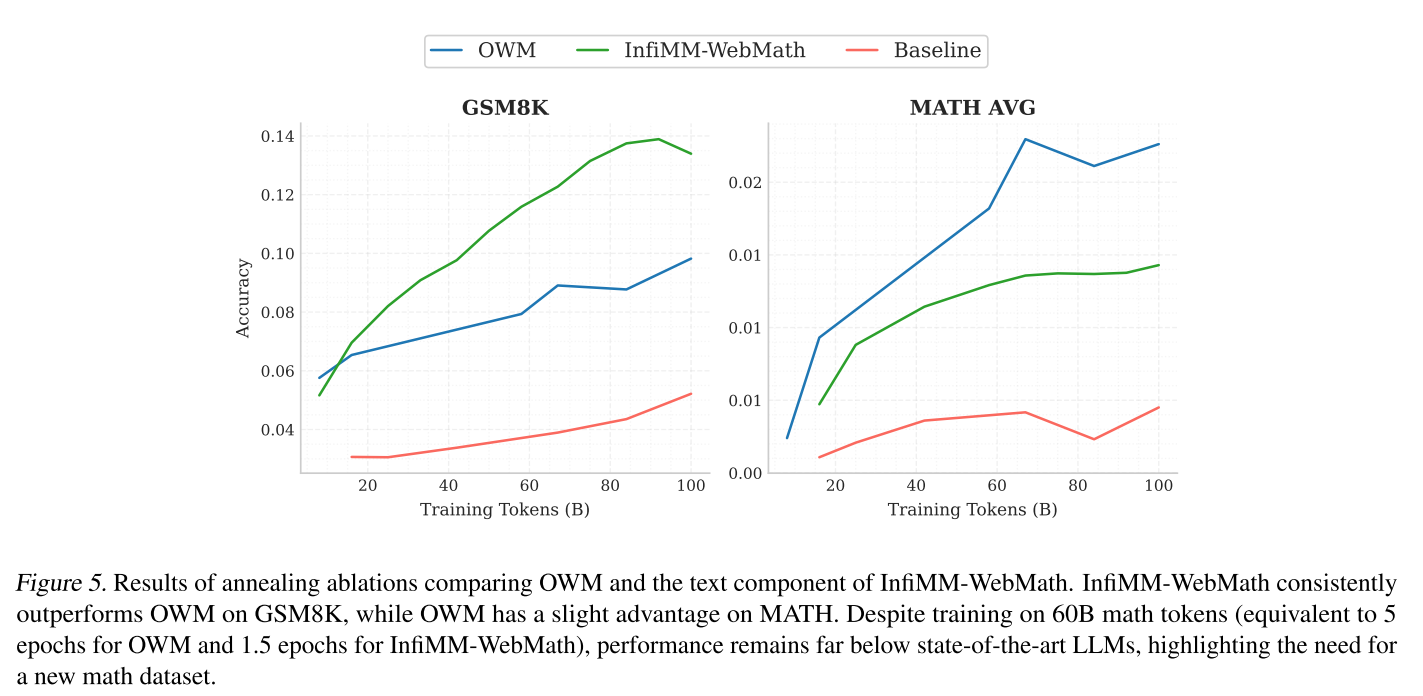
圖5 比較OWM和InfiMM-WebMath文本部分的退火消融實驗結果。InfiMM-WebMath在GSM8K上的表現始終優于OWM,而OWM在MATH上略有優勢。盡管在600億個數學詞元上進行了訓練(相當于OWM訓練5個epoch,InfiMM-WebMath訓練1.5個epoch),但性能仍遠低于最先進的大語言模型,這凸顯了對新數學數據集的需求。
?C.2 注釋提示(3分制)
我們使用以下提示模板,利用Llama3模型為FineMath生成3分制的銀標簽注釋:
評估以下文本片段對高中和本科早期數學學習的潛在有用性。使用以下描述的3分評分系統。根據每個標準的滿足情況累積分數:
如果片段包含一些數學內容,即使對學習不太有用或屬于過于高級的學術論文,加1分。
如果片段在數學背景下展示了邏輯推理,即使缺乏逐步解釋或過于高級,再加1分。
如果片段處于適當水平(高中和本科早期),并包含清晰的數學推導和數學問題的逐步解決方案,加3分。
符合標準的問答格式(例如來自教育網站或論壇的內容)是可以接受的。忽略任何格式錯誤或缺失的公式,并根據整體內容進行假設。
文本片段:
<EXTRACT>
檢查完片段后:
簡要說明你的總分,不超過100字。
以“最終得分:<總分>”的格式給出得分。
?C.3 注釋提示(5分制)
在第二階段過濾時,我們使用以下提示模板,利用Llama3模型為FineMath生成5分制的注釋:
評估以下文本片段對高中和本科早期數學學習的潛在有用性。使用以下描述的5分評分系統。根據每個標準的滿足情況累積分數:
如果片段包含一些數學內容,即使對學習不太有用,或者包含非學術內容,如廣告以及用于轉換重量和貨幣的生成頁面,加1分。
如果片段涉及數學主題,即使寫得不好或過于復雜(如過于高級的學術論文),再加1分。
如果片段在數學背景下展示了解題或邏輯推理,即使缺乏逐步解釋,加3分。
如果片段處于適當水平(高中和本科早期),并包含清晰的數學推導和數學問題的逐步解決方案,類似于教科書章節或教程,加4分。
如果片段在中學和高中數學教學和學習方面具有卓越的教育價值,包含非常詳細且易于理解的解釋,加5分。
符合標準的問答格式(例如來自教育網站或論壇的內容)是可以接受的。
文本片段:
<EXTRACT>
檢查完片段后:
簡要說明你的總分,不超過100字。
以“最終得分:<總分>”的格式給出得分。
D. Stack-Edu
D.1 提示
我們使用下面的提示模板為Stack-Edu(在本例中為Python)生成了5個比例的注釋,使用的是Llama 3模型:以下是Python程序的摘錄。評估它是否具有很高的教育價值,是否有助于教授編程。使用下面描述的加性5分評分系統。分數是根據每個標準的滿足程度來累積的:
-如果程序包含有效的Python代碼,即使它不是教育性的,比如樣板代碼、配置和利基概念,也加1分。- 如果程序涉及實際概念,即使沒有注釋,也要加一分。
- 如果該程序適合教育用途并引入了編程中的關鍵概念,即使該主題是高級的(例如,深度學習)。該代碼應該結構良好,并包含一些注釋。
- 如果該程序是獨立的,并且與編程教學高度相關,請給第四分。它應該類似于學校練習、教程或Python課程部分。
- 如果該項目的教育價值突出,并且非常適合教授編程,則得5分。它應該寫得很好,容易理解,并包含一步一步的解釋和評論。
摘要:<EXAMPLE>在檢查摘要后:-簡要說明你的總分,最多100字。- 使用以下格式總結分數:“教育分數:<total points>我們對Stack-Edu中的其他14種編程語言使用類似的提示,調整第三個標準中的示例以反映特定于語言的主題。例如,在JavaScript提示符中,我們將“深度學習”替換為“異步編程”。
D.2.Stack-Edu語言統計
表7顯示了在教育過濾之前和之后的Stack-Edu中每種編程語言的大小。最初,我們還包括了HTML,但是分類器的性能很差,所以我們保留了StarCoder 2Data。
表7.跨編程語言的Stack-Edu數據集統計。該表顯示了每種編程語言的原始數據集大小(來自StarCoder 2Data)和過濾后的Stack-Edu大小。
E.詳細的預訓練結果
E.1.各訓練階段后的評價
各訓練階段結束時的SmolLM 2的評價結果如表8所示。除了消融期間使用的基準,我們還增加了四項生成性任務:CoQA(Reddy等人,2019年)、DROP(Dua等人,2019年)、Jeopardy(MosaicML,2024年)和SQuAD v2(Rajpurkar等人,2018年)
表8.每個基準模型在各個訓練階段的性能。階段1-3處于穩定階段(無學習速率衰減)。?
E.2.MMLU進展
圖6顯示了整個穩定期內MMLU評分的進展。
F.后訓練
表9顯示了SmolTalk數據集的最終組成。?
 ?
?
G.長上下文評估?
 ?
?







—— 淺層路由和 Packaging)
)


、基于模板(RestTemplate)、基于 SDK、消息隊列、gRPC)對比詳解)






)
