2411 2411 2411
Zhang G R, Pan F, Mao Y H, et al. Reaching Consensus in the Byzantine Empire: A Comprehensive Review of BFT Consensus Algorithms[J]. ACM COMPUTING SURVEYS, 2024,56(5).出版時間: MAY 2024
索引時間(可被引用): 240412
被引: 9'ACM COMPUTING SURVEYS'
卷56期5 DOI10.1145/3636553
出版商名稱: ASSOC COMPUTING MACHINERY期刊影響因子 ?
2023: 23.8
五年: 21.1JCR 學科類別
COMPUTER SCIENCE, THEORY & METHODS
其中 SCIE 版本
類別排序 類別分區
1/144 Q1
Toward More Efficient BFT Consensus
一、PBFT Practical Byzantine fault tolerance-1999
Miguel Castro, Barbara Liskov, et al. 1999. Practical Byzantine fault tolerance. In OSDI, Vol. 99. 173–186.
角色介紹:
客戶端 Client:向區塊鏈網絡 發起交易或狀態更新請求,等待共識結果。
主節點 Leader/Primary:負責 接收請求「交易排序」,協調共識。(輪換時同步狀態)
副本節點 Replica:負責 備份請求,促進共識達成。「驗證合法,維護一致」
故障節點 Byzantine Fault:負責 選擇性響應,篡改數據。【何不直接剔除,因設計目標為容忍而非實時剔除】
正常流程:客戶端請求 → 主節點排序廣播 → 副本節點三階段驗證 → 客戶端確認。
1.請求 I n v o k e Invoke Invoke
客戶端 Client 向
Primary(ld)發送調用請求Req,并啟動計時器Timer。【OP: 時間戳】
Client 收到來自不同的 Replicas 的僅 F+1個回復 Reply,即可判定操作完成,停止計時 Timer。
否則直到計時器到期,認為調用失敗。【原因1:內部錯誤只能等待。原因2:鏈接不可靠未達Primary,廣播】
2.協商(共識)
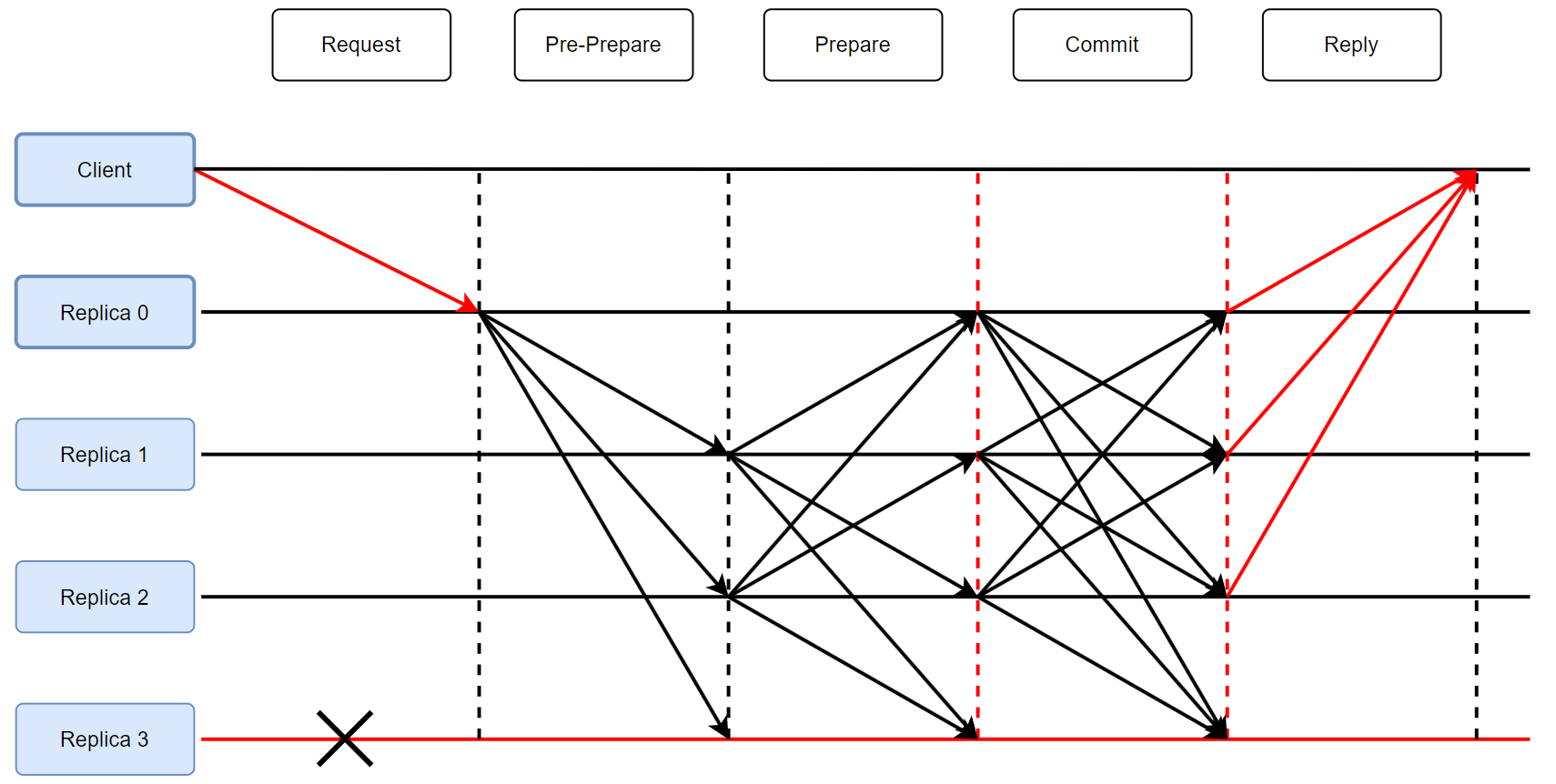
1.Pre-prepare階段
1> 分配唯一序列號 Sequence,范圍[h, h+k](h為最后一個穩定檢查點的 Seq,k為限增值)
2> 將ViewNum、Seq、對請求Req的摘要hash組成PRE-PREPARE,然后簽名Sig。(搭載原生Req)
3> 發給所有 Backups==Replicas。
總結,指定一個編號Seq,把請求打包發送給所有節點。
2.Prepare階段
1> 驗證Sig。
2> 檢查ViewNum是否處于同一視圖。
3> 檢查Seq未分配給其他Req。
4> 驗證hash。
廣播PREPARE消息,收集滿2F個消息后,造一個(都已準備)謂詞Prepared Predicate。【共識基本達成】
總結,檢驗消息包后廣播「沒問題,我已準備提交」,滿2F個后達成共識。
3.Commit階段
1> 通過廣播COMMIT消息,(廣播謂詞Prepared Predicate)。
2> 收集滿2F個消息后,造另一個謂詞committed-local predicate。【仲裁證書提供安全屬性:正確副本執行方式相同】
總結,上階段滿2F個準備消息后,廣播「我已提交」,再滿2F個后達成共識。
4.Reply階段
向Client發送REPLY消息 (resultOfOp=true)。
Weak Certificate 弱證書,僅需F+1個回復。
總結,上階段滿2F個提交消息后,向客戶端回復調用完成。
檢查點 C h e c k P o i n t CheckPoint CheckPoint
通過周期性狀態同步,解決日志膨脹問題。【我理解為狀態確認穩定后即可刪除多余「過期」日志】
當
Req被Commit時的 execute 會更新節點的狀態,該狀態需要確保所有正確副本一致性,通過檢查點機制。
O n c e a r e q u e s t i s c o m m i t t e d , t h e e x e c u t i o n o f t h e r e q u e s t r e f l e c t s t h e s t a t e o f a r e p l i c a . Once\ a\ request\ is\ committed,\ the\ execution\ of\ the\ request\ reflects\ the\ state\ of\ a\ replica. Once?a?request?is?committed,?the?execution?of?the?request?reflects?the?state?of?a?replica.
算法定期對一系列 exe 生成證明,稱為檢查點。
同樣的,在廣播CHECKPOINT并收集2F個回復后,進化成穩定檢查點。【水位范圍同上述Seq】
總結,節點「已提交」后會更新狀態,通過CheckPoint消息將其狀態廣播,滿2F個后確認狀態穩定。
3.視圖切換 V i e w C h a n g e ViewChange ViewChange
當
Primary故障或共識超時,啟動切換協議。【確保故障時系統活性】
視圖切換期間,節點處于異步狀態(i.e., 沒有完全同步)。協議來自論文1:但可能需要無限空間。
副本節點在收到 Req 后,啟動一個 「節點
Timer」等待 Req 被提交 Commit。
Commit 完成,則 Timer 終止; R e s t a r t s t h e T i m e r i f t h e r e a r e o u t s t a n d i n g v a l i d r e q u e s t s t h a t h a v e n o t b e e n c o m m i t t e d . Restarts\ the\ Timer\ if\ there\ are\ outstanding\ valid\ requests\ that\ have\ not\ been\ committed. Restarts?the?Timer?if?there?are?outstanding?valid?requests?that?have?not?been?committed.
若 Timer 到期,則認為 Primary 故障,廣播VIEWCHANGE消息,引發視圖切換。
該消息包含三個參數: C P Q CPQ CPQ.
選主公式:p = v mod |R| 。【R為節點總數】
各副本節點收到VIEWCHANGE后。
1> 驗證:生成PQ的視圖小于v。
2> 發送VIEWCHANGE-ACK消息給v+1的Primary(新主)「支持視圖切換」。【包含節點ID、摘要及發送方ID】
3> Primary在收集 2F-1 條VIEWCHANGE和*-ACK后,確認更改,將VIEWCHANGE*加入集合 S S S.【至少F+1條】
生成一個仲裁證書, view-change certificate。
總結:通過超時檢測和多方認證,切換Ld「視圖+1」。
Primary將 ID 與 S S S中的 msg 配對后,加入集合 V V V.
選擇檢查點最高值h。
提取[h, h+k]之間未提交的 Req,加入集合 X X X.【請求已在v或仲裁證書中準備好】
Backups 檢查 V 、 X V、X V、X中 msg 是否支持新主的【選擇檢查點和延續未提交請求】的決定。若不支持則切換視圖至v+2.
終止 View-Change 協議。
視圖切換期間異步處理請求。
總結,副本節點超時觸發視圖切換,新主節點基于最高檢查點恢復未完成請求。
4.優缺點
開創異步網絡中BFT的實用方案,啟發高效BFT算法時代。
二次消息復雜性,阻礙其在大規模網絡中的應用。
f a u l t y c l i e n t s u s e a n i n c o n s i s t e n t a u t h e n t i c a t o r o n r e q u e s t s . faulty\ clients\ use\ an\ inconsistent\ authenticator\ on\ requests. faulty?clients?use?an?inconsistent?authenticator?on?requests. 會導致系統重復視圖切換而卡死。
二、SBFT Scalable-2019
Guy Golan Gueta, Ittai Abraham, Shelly Grossman, Dahlia Malkhi, Benny Pinkas, Michael Reiter, Dragos-Adrian Seredinschi, Orr Tamir, and Alin Tomescu. 2019. SBFT: a scalable and decentralized trust infrastructure. In 2019 49th Annual IEEE/IFIP international conference on dependable systems and networks (DSN). IEEE, 568–580.
A s c a l a b l e a n d d e c e n t r a l i z e d t r u s t i n f r a s t r u c t u r e A\ scalable\ and\ decentralized\ trust\ infrastructure A?scalable?and?decentralized?trust?infrastructure.
共3f + 2c + 1個 Servers。【f為拜占庭故障,c為崩潰或流浪】
擁有Fast、Slow兩種模式,前者需要無故障節點、同步環境;后者就是線性PBFT。
利用門限簽名(閾值簽名, t h r e s h o l d threshold threshold)解決了二次拜占庭廣播問題。(其中閾值表示簽名者數量)
1.快速通道 F a s t p a t h Fast\ path Fast?path?
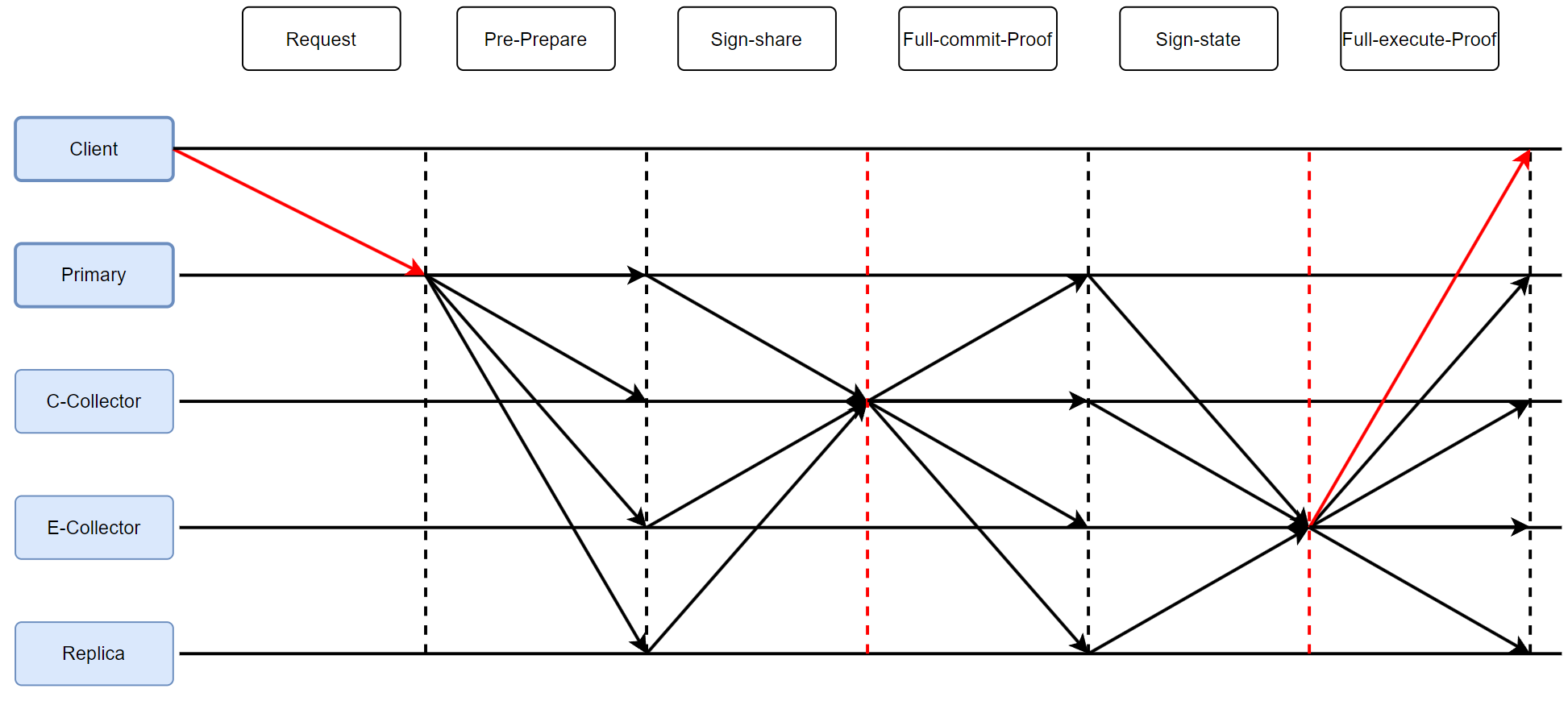
1.Pre-Prepare 階段
Primary 向所有 Servers 發送指令。
Servers 將回復發給 CommitCollector。
2.Full-commit-Proof 階段
C-Collector 將收集到的 s i g n e d r e p l i e s signed\ replies signed?replies 轉換成一個門限簽名 msg,并發給所有 Servers。
3.Full-execute-Proof 階段
Servers 將回復發給 ExecutionCollector。
E-Collector 將收集到的 s i g n e d r e p l i e s signed\ replies signed?replies 轉換成一個門限簽名 msg,并發給所有 Servers,包括 Client。【對比PBFT的F+1條確認】
2.線性PBFT l i n e a r ? P B F T linear-PBFT linear?PBFT
將所有 Collector 聚合到 Primary。【權柄收回】
i f S B F T u s e s o n l y t h e p r i m a r y a s a l l “ l o c a l ”? l e a d e r s i n e a c h p h a s e if\ SBFT\ uses\ only\ the\ primary\ as\ all\ “local”\ leaders\ in\ each\ phase if?SBFT?uses?only?the?primary?as?all?“local”?leaders?in?each?phase?.
那么工作流就類似PBFT。
但是擁有門限簽名。
給定視圖
Primary 根據視圖號選擇。
Collectors 根據視圖號和 Seq(commit state index)選擇。
SBFT 建議隨機選擇二者。
線性PBFT模式下,
Primary總是選最后一個Collector。
當視圖切換時,Servers 的角色更改。
3.視圖切換 V i e w C h a n g e ViewChange ViewChange?
View Change Trigger 階段
兩種情況會導致視圖切換:
- Timeout.
- 收到 F+1 個節點的質疑(主有問題)。
View Change 階段
l s ls ls:最后穩定 Seq( l a s t s t a b l e s e q u e n c e last\ stable\ sequence last?stable?sequence?)。【因部分同步可能不一致】
w i n win win:用于限制未完成塊數量,預定義值。【因此 Seq 在 l s ~ l s + w i n ls\sim ls+win ls~ls+win】
Seq 可以指明 Server 的狀態。
觸發 ViewChange 的 Server 會發送VIEWCHANGE消息給新主。【包含 l s ls ls和到 l s + w i n ls+win ls+win之間的狀態摘要】
New View 階段
收集滿 2F+2C+1 后,啟動新視圖,并將其廣播。
Accept a New-view 階段
節點們接受 l s ~ l s + w i n ls\sim ls+win ls~ls+win間的Seq,或一個安全的、可用于未來交易的Seq。
4.優缺點
兩種模式下均可實現線性消息傳輸,并且 Reply 階段的通信為O(1)。
繼承PBFT缺點,Client 完全可以只與F+1部分節點通信,觸發不必要的視圖切換。
關于實驗
實驗設置
- 部署規模:在真實世界規模的廣域網(WAN)上部署了200個副本。每個區域使用至少一臺機器,每臺機器配置32個VCPUs,Intel Broadwell E5-2686v4處理器,時鐘速度2.3 GHz,通過10 Gigabit網絡連接。
- 故障容忍:所有實驗都配置為能夠承受
f=64個拜占庭故障。 - 客戶端請求:使用公鑰簽名客戶端請求和服務器消息。
實驗方法
- 微基準測試:簡單的Key-Value存儲服務,每個客戶端順序發送1000個請求。
- 智能合約基準測試:使用以太坊的50萬筆真實交易數據,副本通過運行EVM字節碼執行每個合約,并將狀態持久化到磁盤。
- 無批處理模式:每個請求是一個單次put操作,寫入隨機值到隨機鍵。
- 批處理模式:每個請求包含64個操作,模擬智能合約工作負載。
'客戶端請求':客戶端通過將交易分批成12KB的塊(平均每批約50筆交易)發送操作。
三、HotStuff-2019??
Maofan Yin, Dahlia Malkhi, Michael K Reiter, Guy Golan Gueta, and Ittai Abraham. 2019. HotStuff: BFT consensus with linearity and responsiveness. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing. 347–356
共3F+1個Servers。
達成活躍性、安全性無需同步假設。樂觀響應:前2F+1個消息即可進行共識決策。
采用輪換 Primary 保證鏈質量。
采用門限簽名達到共識線性。(最壞情況,連續Primaries故障,復雜度為f*n)
1.請求
Client向所有Servers發送
Req。
同PBFT,等待F+1個Reply,操作完成。
客戶端請求失敗處理部分,引用了文獻:
Alysson Bessani, Joao Sousa, and Eduardo EP Alchieri. 2014. State machine replication for the masses with BFT-SMART. In 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks. IEEE, 355–362.
Miguel Castro, Barbara Liskov, et al. 1999. Practical Byzantine fault tolerance. In OSDI, Vol. 99. 173–186.
2.共識
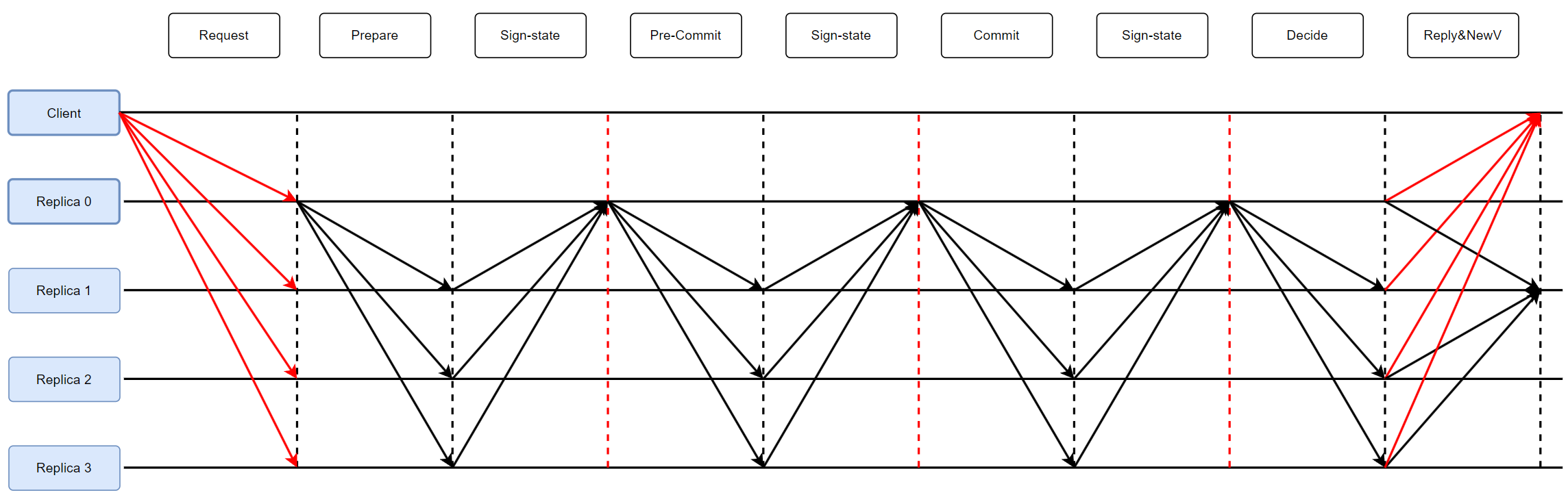
1.Prepare階段
Primary在收到Req后,向節點(Replica)廣播PREPARE消息。
節點驗證消息:
- 為上次提交的msg的擴展(無間隔)
- 最高View(最新視圖)
驗證后,用部分簽名對PREPARE-VOTE消息簽名,并發給Primary。
Primary在等待2F+1后,生成仲裁證書(Quorum Certificate,QC),記為 PrepareQC。【可以理解為完成】
2.Pre-Commit 階段
廣播帶有 PrepareQC 的msg,節點將其存儲。
將COMMIT-VOTE消息簽名后發給Primary。
Primary在集齊2F+1后,形成 Pre-CommitQC。
3.Commit 階段
廣播帶有 Pre-CommitQC 的msg。
節點回復COMMIT給Primary,并且更新變量 lockedQC。【保存QC計數/Req】
k e e p s c o u n t i n g t h e n u m b e r o f r e c e i v e d Q C s f o r a r e q u e s t keeps\ counting\ the\ number\ of\ received\ QCs\ for\ a\ request keeps?counting?the?number?of?received?QCs?for?a?request.
4.Decide 階段
Primary在收到2F+1后,廣播DECIDE給Replicas。
節點認為共識達成,開始執行請求。
然后ViewNum++。【視圖切換開始】
然后發送New-View給新主。
三個變量
-
p r e p a r e Q C prepareQC prepareQC:當前節點已知的最高鎖定 PREPARE msg(最新)。
-
l o c k e d Q C lockedQC lockedQC:已知最高鎖定 COMMIT msg(最新)。
-
v i e w N u m viewNum viewNum:節點當前所處視圖。
新主收到2F+1個New-View后,在 p r e p a r e Q C prepareQC prepareQC基礎上擴展。(理解為+1)
若未能及時收滿2F+1,則觸發超時,視圖切換。
3.視圖切換 V i e w C h a n g e ViewChange ViewChange
為了確保鏈質量,HotStuff可以更頻繁的切換試圖。
通過廣播協調消息和收集門限簽名進行共識。因此視圖切換被包含于HotStuff的核心流程。
新主選擇方式為 p = v m o d n p = v\mod n p=vmodn。
4.優缺點
使用門限簽名,實現線性消息傳遞。
每個階段的收集投票,構建門限簽名,可以被流水線化 p i p e l i n e d pipelined pipelined。從而簡化HotStuff協議的構建,例如Casper:(同時降低O(n))
Vitalik Buterin and Virgil Griffith. 2017. Casper the friendly finality gadget. arXiv preprint arXiv:1710.09437 (2017).
還可以用延遲塔 d e l a y t o w e r s delay\ towers delay?towers擴展到公有鏈:
Shashank Motepalli and Hans-Arno Jacobsen. 2022. Decentralizing Permissioned Blockchain with Delay Towers. (2022).
arXiv:2203.09714
在
failures情況下,HotStuff吞吐量顯著下降(不能達成共識)。
關于實驗
- 使用Amazon EC2 c5.4xlarge實例,每個實例有16個vCPU,由Intel Xeon Platinum 8000處理器支持。
- 所有核心的Turbo CPU時鐘速度高達3.4GHz。
- 每個副本運行在單個VM實例上。
網絡配置:
- 測得的TCP最大帶寬約為1.2 Gbps。(使用
iperf工具) - 網絡延遲小于1毫秒。
實驗設置:
- 實驗中使用了4個副本,配置為容忍單個故障(即f = 1)。
- 使用了空操作請求和響應,沒有觸發視圖更改。
- 實驗中使用了不同的批次大小(100、400和800)和不同的有效負載大小(0/0、128/128和1024/1024字節)。
軟件和工具:
- HotStuff的實現使用了大約4K行C++代碼,核心共識邏輯大約200行。
- 使用secp256k1進行數字簽名。
- 使用NetEm工具引入網絡延遲。
使用BFT-SMaRt的ThroughputLatencyServer和ThroughputLatencyClient程序測量吞吐量和延遲。
四、ISS: Insanely Scalable State Machine Replication-2022
Chrysoula Stathakopoulou, Matej Pavlovic, and Marko Vukoli?. 2022. State machine replication scalability made simple. In Proceedings of the Seventeenth European Conference on Computer Systems. 17–33.
會議17th European Conference on Computer Systems (EuroSys)歐洲計算機系統會議,頂級學術會議
地點Rennes, FRANCE
日期APR 05-08, 2022
贊助方Assoc Comp Machinery; ACM SIGOPS; USENIX; Huawei; Stormshield; Microsoft; Protocol Labs Res; Red Hat; Amazon; Meta; Google; Intel; Cisco
共3F+1節點。
是一個通用框架,
通過劃分工作負載,并且關聯 SB(Sequenced Broadcast) 實例與Leader,
將傳統的單Leader的 TOB(Total Order Broadcast) 協議擴展為多Leader的協議。
達成PBFT的37倍,Raft的55倍,Chained HotStuff的56倍。
1.初始配置
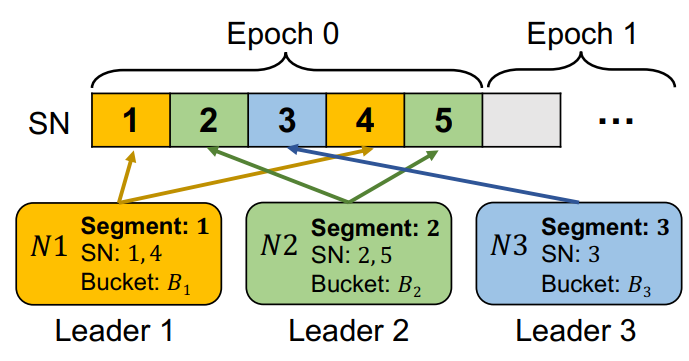
日志log:該節點接收的所有消息,由Req組成,被批處理以降低消息復雜性。
SN(Sequence Number)序列號:相對于日志開頭的偏移量。
將日志分成epoch,按SN以輪詢方式分配給Leader,再將epoch分成segment,這樣與Leader相對應。
所有Req基于modulo哈希函數分類到桶bucket中,再將桶分配給Leader。
段、Leader、桶,一一對應。
2.復制協議 R e p l i c a t i o n P r o t o c o l Replication\ Protocol Replication?Protocol?
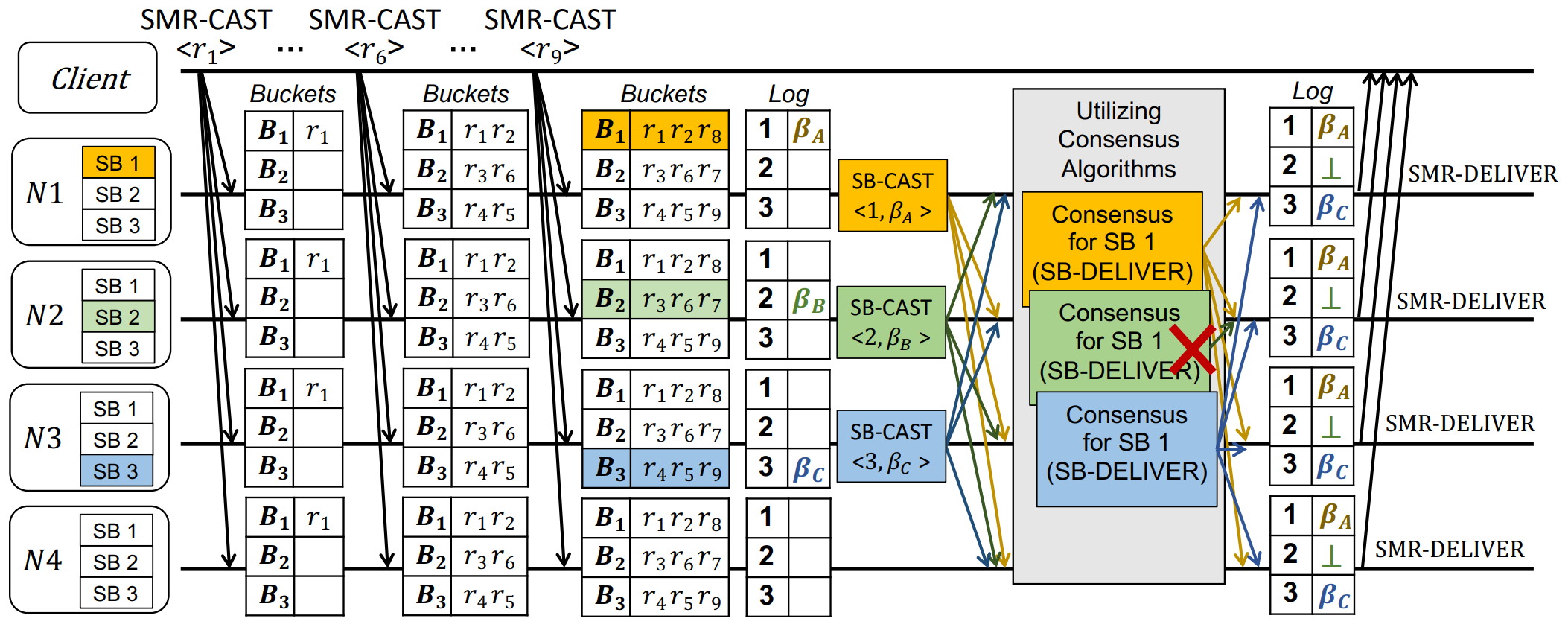
初始配置階段
1> 選中N123三個節點為Leader。
2> 分別分配segment 1、2、3。
分別對應SN1 4,2 5,3。
3> 分桶給Leader,包含用于提出提議的Req批次 r e q u e s t b a t c h e s request\ batches request?batches。
分別為B1、2、3。
等待
Req階段
通過多SB實例(共識實例)達成共識。
SB實例與一個Leader及其Segment相關聯。
等待客戶端發送請求,記為 S M R ? C A S T ∣ < r x > SMR-CAST|<r_x> SMR?CAST∣<rx?>,散列到本地桶隊列中。直到:
- 桶滿(預定義大小)如 ∣ B i ∣ = 3 |B_i|=3 ∣Bi?∣=3.
- 預定時間(距上次提案)。
將桶里的Req請求打包為一批次 β i \beta_i βi?。然后廣播 S B ? C A S T < 1 , β A > SB-CAST<1,\beta_A> SB?CAST<1,βA?>消息。
共識階段
每個Leader運行底層包裝的TOB協議,就其提議的SB實例達成共識。【可并行non-blocking】
- 共識成功,將SB中承載的一批
Req交付。 - 共識失敗,
log中記錄⊥。
TOB可以保證,成功時所有正確節點中的序列號與批次一致。
當一個epoch的所有SN號對應的log都被填滿時,節點向Client發送 S M R ? D E L I V E R E D SMR-DELIVERED SMR?DELIVERED,收滿 a q u o r u m a\ quorum a?quorum即完成。
3.多領導選擇 M u l t i p l e L e a d e r S e l e c t i o n Multiple\ Leader\ Selection Multiple?Leader?Selection
L e a d e r S e l e c t i o n P o l i c y , L E Leader\ Selection\ Policy,LE Leader?Selection?Policy,LE?選主策略可以自定義,只要能保證活性:each bucket will be assigned to a segment with a correct leader infinitely many times in an infinite execution將桶分配給正確Leader的段。
例如:保證足夠多的正確Leader.
Zarko Milosevic, Martin Biely, and André Schiper. 2013. Bounded delay in byzantine-tolerant state machine replication. In 2013 IEEE 32nd International Symposium on Reliable Distributed Systems. IEEE, 61–70
Leader 故障檢測
每個SB實例用== F a i l u r e D e t e c t o r Failure\ Detector Failure?Detector==,用來檢測quiet nodes。
ISS會從集合移除故障Leader,用LE再選個主。
4.優缺點
Pros
- 吞吐量,因為并行。
- 對客戶端高響應,可立即執行
Req。 - 資源不浪費,
Req僅入一個桶。
Cons
- 共識延遲,引入額外開銷。
- 故障時,SB實例高概率共識失敗。(任何Leader故障,新主,并重新提出未提交的
Req) Req需要發到所有節點,以確保Req放入正確桶。
五、DAG-Rider-2021
Idit Keidar, Eleftherios Kokoris-Kogias, Oded Naor, and Alexander Spiegelman. 2021. All you need is dag. In Proceedings of the 2021 ACM Symposium on Principles of Distributed Computing. 165–175.
D i r e c t e d a c y c l i c g r a p h ( D A G ) Directed\ acyclic\ graph\ (DAG) Directed?acyclic?graph?(DAG).有向無環圖。
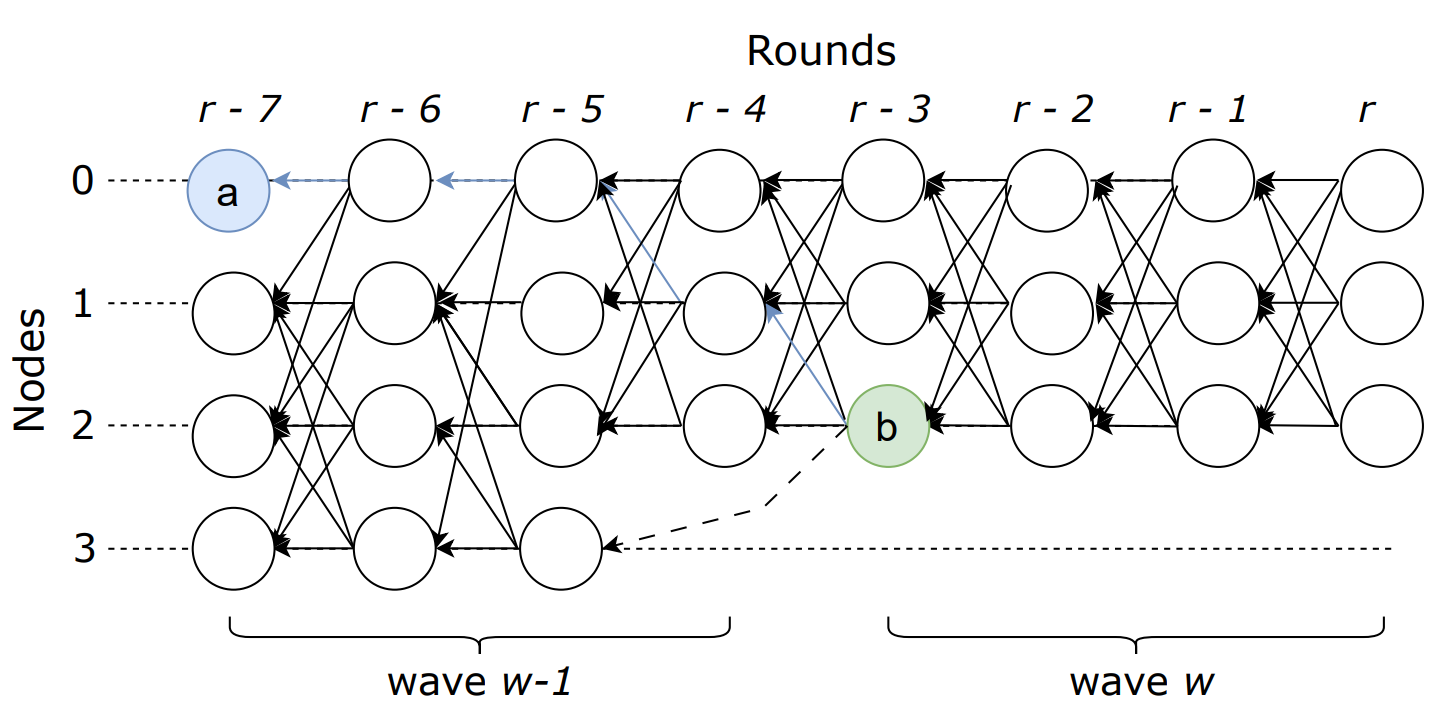
圖中為完整的消息傳播歷史,包含:遍歷的路徑、因果關系 c a u s a l h i s t o r y causal\ history causal?history.
傳統的Leader服務器承擔:
tx分發。 t r a n s a c t i o n d i s t r i b u t i o n transaction\ distribution transaction?distribution- 達成共識。 c o n s e n s u s p h a s e consensus\ phase consensus?phase
兩項責任,巨大工作量導致tx積壓、系統瓶頸。
而DAG-based算法將二者分離,在tx分發階段無需Leader(吞吐量顯著增加),在共識階段每個實例都有一個Leader。
1.系統模型&服務屬性 S y s t e m m o d e l a n d s e r v i c e p r o p e r t i e s . System\ model\ and\ service\ properties. System?model?and?service?properties.
DAG-Rider是一種異步拜占庭原子廣播協議( a s y n c h r o n o u s B y z a n t i n e A t o m i c B r o a d c a s t , B A B asynchronous\ Byzantine\ Atomic\ Broadcast, BAB asynchronous?Byzantine?Atomic?Broadcast,BAB)。
以最佳時間和消息復雜度實現了后量子安全。
分為兩層:
- 基于輪的結構化DAG,分發
tx用。 - 零開銷的共識協議,獨立確定提交消息順序。
使用
Bracha廣播。
共3F+1個節點。
假設了一個全局完美硬幣( g l o b a l p e r f e c t c o i n global\ perfect\ coin global?perfect?coin)來確保活性。允許在wave的實例上獨立選擇一個Leader.
2.DAG流水線 P i p e l i n i n g Pipelining Pipelining
節點獨立維護自己的DAG,用一個數組[]存儲。(所有節點間消息傳播拓撲)
以輪 r o u n d round round為單位。
強邊:分發相同的msg,直鏈(directly linked in the previous round)。
弱邊:沒有直鏈。
協議流程
驗證器一直等待客戶端發送交易(請求、頂點),存儲于緩沖區buffer,并監視:
定期檢查,若其所有前導頂點都已成功接收,則加入DAG[],并根據round組織起來。
當滿2F+1個頂點時,進入下一輪r+1。(下一波?雖然首輪也是下輪)
生成新的頂點v:r+1,弱邊,并廣播。
因為網絡部分同步,可能有不同的DAG出現,但BAB會保證最終收斂。
4.共識 C o n s e n s u s i n D A G s Consensus\ in\ DAGs Consensus?in?DAGs 「我也不知3跑哪了」
利用全局完美硬幣,節點可以獨立檢查DAG,推斷需交付的區塊及其提交順序。(無需額外協調)
在DAG于節點中發送頂點完畢后,系統啟動共識旨在確保分發的tx完成提交aimed at deterministically finalizing the commit of the disseminated transactions.
在這個過程中,DAG被分為波waves,每波有4個輪次rounds。
利用完美硬幣在第一輪中隨機選擇Leader(滿2F+1強邊)。
按照預先確定的順序交付頂點塊。交付區塊時,會將其因果關系歷史上的值也一并提交。
5.優缺點
Pros.
- 吞吐量顯著提升。
- DAG達成消息分發和促進共識兩種目的 d u a l p u r p o s e dual\ purpose dual?purpose?。
- 更穩定的提交。
Cons.
- 因為分離,延遲激增 𝑂 ( 𝑛 3 l o g ( 𝑛 ) + 𝑛 𝑀 ) 𝑂(𝑛 3 log(𝑛) + 𝑛𝑀) O(n3log(n)+nM)? 。
六、Narwhal and Tusk-2022
George Danezis, Lefteris Kokoris-Kogias, Alberto Sonnino, and Alexander Spiegelman. 2022. Narwhal and tusk: a dag-based mempool and efficient bft consensus. In Proceedings of the Seventeenth European Conference on Computer Systems. 34–50.
將tx傳播與tx排序分離,實現高效共識。
Mempool負責可靠傳播,少量元數據用來排序。
1.系統模型&服務屬性
共3F+1節點。
Mempool是一個KV鍵值存儲 ( d , b ) (d,b) (d,b)。
K:digest.
V:交易塊block。
服務屬性
- 完整性:(d,b)。
- 可用性:寫入(d,b)后。
- 包含性 C o n t a i n m e n t Containment Containment:后塊包含前塊。
- 2 / 3 2/3 2/3因果性:后塊包含至少 2 / 3 2/3 2/3前塊。
- 1 / 2 1/2 1/2鏈質量:至少有一半
causal history是誠實者所寫入。
2.復制協議
替換Bracha廣播。
用固有DAG+證書實現。
blocks包含
- hash sig。
txlist。- 證書
certificates of availability。
證書包含:hash、2F+1 sig、round。
原理
- 收集
tx——txlist 和 證書list。 r-1主收集2F+1證書 ——r,新塊廣播。- 驗證sig、含2F+1、唯一塊,簽名(確認)。
- 滿2F+1, 造一個證書并廣播,此時停止廣播新塊。
3.Tusk共識
- 選主同DAG-Riders。
- 一波三輪。
- 一三🉑重疊,4.5rounds。
4.優缺點
Pros.
- 一個基于DAG的BFT算法的具體實現。
- 吞吐量優勢。
Cons.
- 高延遲(提交區塊前等待多輪)。
- 未滿足標準的
tx需要等更多wave。
E n d . End. End.
Miguel Castro and Barbara Liskov. 2002. Practical Byzantine fault tolerance and proactive recovery. ACM Transactions on Computer Systems (TOCS) 20, 4 (2002), 398–461. ??



)



-clickhouse與hdfs)



被稱為 擴展運算符(Spread Operator) 或 剩余運算符(Rest Operator))







