深度學習中的優化算法詳解
優化算法是深度學習的核心組成部分,用于最小化損失函數以更新神經網絡的參數。本文將詳細介紹深度學習中常用的優化算法,包括其概念、數學公式、代碼示例、實際案例以及圖解,幫助讀者全面理解優化算法的原理與應用。
一、優化算法的基本概念
在深度學習中,優化算法的目標是通過迭代更新模型參數 θ \theta θ,最小化損失函數 L ( θ ) L(\theta) L(θ)。損失函數通常表示為:
L ( θ ) = 1 N ∑ i = 1 N l ( f ( x i ; θ ) , y i ) L(\theta) = \frac{1}{N} \sum_{i=1}^N l(f(x_i; \theta), y_i) L(θ)=N1?∑i=1N?l(f(xi?;θ),yi?)
其中:
- f ( x i ; θ ) f(x_i; \theta) f(xi?;θ):模型對輸入 x i x_i xi? 的預測;
- y i y_i yi?:真實標簽;
- l l l:單個樣本的損失(如均方誤差或交叉熵);
- N N N:樣本數量。
優化算法通過計算梯度 ? θ L ( θ ) \nabla_\theta L(\theta) ?θ?L(θ),按照一定規則更新參數 θ \theta θ,以逼近損失函數的最優解。
二、常見優化算法詳解
以下是深度學習中常用的優化算法,逐一分析其原理、公式、優缺點及代碼實現。
1. 梯度下降(Gradient Descent, GD)
概念
梯度下降通過計算整個訓練集的梯度來更新參數,公式為:
θ t + 1 = θ t ? η ? θ L ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta L(\theta_t) θt+1?=θt??η?θ?L(θt?)
其中:
- η \eta η:學習率,控制步長;
- ? θ L ( θ t ) \nabla_\theta L(\theta_t) ?θ?L(θt?):損失函數對參數的梯度。
優缺點
- 優點:全局梯度信息準確,適合簡單凸優化問題。
- 缺點:計算全量梯度開銷大,速度慢,易陷入局部極小值。
代碼示例
import numpy as np# 模擬損失函數 L = (theta - 2)^2
def loss_function(theta):return (theta - 2) ** 2def gradient(theta):return 2 * (theta - 2)# 梯度下降
theta = 0.0 # 初始參數
eta = 0.1 # 學習率
for _ in range(100):grad = gradient(theta)theta -= eta * grad
print(f"優化后的參數: {theta}") # 接近 2
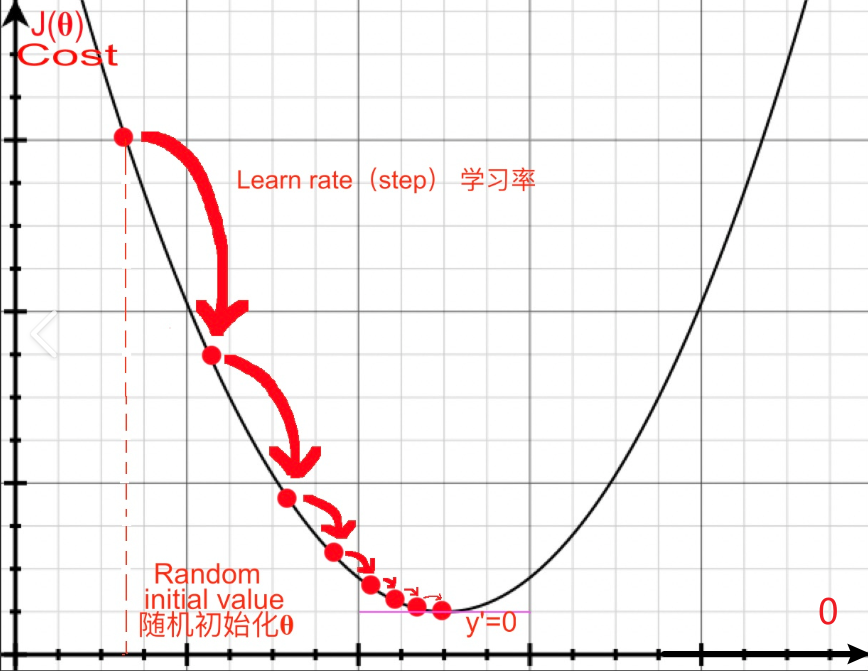
參數沿梯度方向逐步逼近損失函數的最優解。*
2. 隨機梯度下降(Stochastic Gradient Descent, SGD)
概念
SGD 每次僅基于單個樣本計算梯度,更新公式為:
θ t + 1 = θ t ? η ? θ l ( f ( x i ; θ t ) , y i ) \theta_{t+1} = \theta_t - \eta \nabla_\theta l(f(x_i; \theta_t), y_i) θt+1?=θt??η?θ?l(f(xi?;θt?),yi?)
優缺點
- 優點:計算效率高,適合大規模數據集,隨機性有助于逃離局部極小值。
- 缺點:梯度噪聲大,收斂路徑不穩定。
代碼示例
# 模擬 SGD
np.random.seed(42)
data = np.random.randn(100, 2) # 模擬數據
labels = data[:, 0] * 2 + 1 # 模擬標簽theta = np.zeros(2) # 初始參數
eta = 0.01
for _ in range(100):i = np.random.randint(0, len(data))x, y = data[i], labels[i]grad = -2 * (y - np.dot(theta, x)) * x # 均方誤差梯度theta -= eta * grad
print(f"優化后的參數: {theta}")
SGD 的更新路徑波動較大,但整體趨向最優解。*
3. 小批量梯度下降(Mini-Batch Gradient Descent)
概念
Mini-Batch GD 結合 GD 和 SGD 的優點,使用小批量樣本計算梯度:
θ t + 1 = θ t ? η 1 B ∑ i ∈ batch ? θ l ( f ( x i ; θ t ) , y i ) \theta_{t+1} = \theta_t - \eta \frac{1}{B} \sum_{i \in \text{batch}} \nabla_\theta l(f(x_i; \theta_t), y_i) θt+1?=θt??ηB1?∑i∈batch??θ?l(f(xi?;θt?),yi?)
其中 B B B 為批量大小。
優缺點
- 優點:平衡了計算效率和梯度穩定性,廣泛應用于深度學習框架。
- 缺點:批量大小需調優,學習率敏感。
代碼示例
import torch# 模擬數據
X = torch.randn(100, 2)
y = X[:, 0] * 2 + 1
theta = torch.zeros(2, requires_grad=True)
optimizer = torch.optim.SGD([theta], lr=0.01)# Mini-Batch GD
batch_size = 16
for _ in range(100):indices = torch.randperm(100)[:batch_size]batch_X, batch_y = X[indices], y[indices]pred = batch_X @ thetaloss = ((pred - batch_y) ** 2).mean()optimizer.zero_grad()loss.backward()optimizer.step()
print(f"優化后的參數: {theta}")
4. 動量法(Momentum)
概念
動量法通過引入速度項 v t v_t vt?,加速梯度下降,公式為:
v t + 1 = μ v t + ? θ L ( θ t ) v_{t+1} = \mu v_t + \nabla_\theta L(\theta_t) vt+1?=μvt?+?θ?L(θt?)
θ t + 1 = θ t ? η v t + 1 \theta_{t+1} = \theta_t - \eta v_{t+1} θt+1?=θt??ηvt+1?
其中 μ \mu μ 為動量系數(通常為 0.9)。
優缺點
- 優點:加速收斂,減少震蕩。
- 缺點:超參數需調優,可能超調。
代碼示例
# 動量法
theta = 0.0
v = 0.0
eta, mu = 0.1, 0.9
for _ in range(100):grad = gradient(theta)v = mu * v + gradtheta -= eta * v
print(f"優化后的參數: {theta}")
動量法通過累積速度平滑更新路徑。*
5. Adam(Adaptive Moment Estimation)
概念
Adam 結合動量法和自適應學習率,通過一階動量(均值)和二階動量(方差)更新參數:
m t + 1 = β 1 m t + ( 1 ? β 1 ) ? θ L ( θ t ) m_{t+1} = \beta_1 m_t + (1 - \beta_1) \nabla_\theta L(\theta_t) mt+1?=β1?mt?+(1?β1?)?θ?L(θt?)
v t + 1 = β 2 v t + ( 1 ? β 2 ) ( ? θ L ( θ t ) ) 2 v_{t+1} = \beta_2 v_t + (1 - \beta_2) (\nabla_\theta L(\theta_t))^2 vt+1?=β2?vt?+(1?β2?)(?θ?L(θt?))2
m ^ t + 1 = m t + 1 1 ? β 1 t + 1 , v ^ t + 1 = v t + 1 1 ? β 2 t + 1 \hat{m}_{t+1} = \frac{m_{t+1}}{1 - \beta_1^{t+1}}, \quad \hat{v}_{t+1} = \frac{v_{t+1}}{1 - \beta_2^{t+1}} m^t+1?=1?β1t+1?mt+1??,v^t+1?=1?β2t+1?vt+1??
θ t + 1 = θ t ? η m ^ t + 1 v ^ t + 1 + ? \theta_{t+1} = \theta_t - \eta \frac{\hat{m}_{t+1}}{\sqrt{\hat{v}_{t+1}} + \epsilon} θt+1?=θt??ηv^t+1??+?m^t+1??
其中:
- β 1 = 0.9 \beta_1 = 0.9 β1?=0.9, β 2 = 0.999 \beta_2 = 0.999 β2?=0.999;
- ? = 1 0 ? 8 \epsilon = 10^{-8} ?=10?8,防止除零。
優缺點
- 優點:自適應學習率,收斂快,適合復雜模型。
- 缺點:可能過早收斂到次優解。
代碼示例
import torch.optim as optim# 使用 PyTorch 的 Adam
model = torch.nn.Linear(2, 1)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for _ in range(100):pred = model(X)loss = ((pred - y) ** 2).mean()optimizer.zero_grad()loss.backward()optimizer.step()
print(f"優化后的參數: {model.weight}")
Adam 通過自適應步長快速逼近最優解。*
三、實際案例:優化神經網絡
任務
使用 PyTorch 訓練一個簡單的二分類神經網絡,比較 SGD 和 Adam 的性能。
代碼實現
import torch
import torch.nn as nn
import matplotlib.pyplot as plt# 生成模擬數據
X = torch.randn(1000, 2)
y = (X[:, 0] + X[:, 1] > 0).float().reshape(-1, 1)# 定義模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc = nn.Linear(2, 1)def forward(self, x):return torch.sigmoid(self.fc(x))# 訓練函數
def train(model, optimizer, epochs=100):criterion = nn.BCELoss()losses = []for _ in range(epochs):pred = model(X)loss = criterion(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()losses.append(loss.item())return losses# 比較 SGD 和 Adam
model_sgd = Net()
model_adam = Net()
optimizer_sgd = optim.SGD(model_sgd.parameters(), lr=0.01)
optimizer_adam = optim.Adam(model_adam.parameters(), lr=0.001)losses_sgd = train(model_sgd, optimizer_sgd)
losses_adam = train(model_adam, optimizer_adam)# 繪制損失曲線
plt.plot(losses_sgd, label="SGD")
plt.plot(losses_adam, label="Adam")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()
結果分析
Adam 通常比 SGD 收斂更快,損失下降更平穩,但在某些任務中 SGD 配合動量可能獲得更好的泛化性能。
四、優化算法選擇建議
- 小型數據集:SGD + 動量,簡單且泛化能力強。
- 復雜模型(如深度神經網絡):Adam 或其變體(如 AdamW),收斂速度快。
- 超參數調優:
- 學習率:嘗試 1 0 ? 3 10^{-3} 10?3 到 1 0 ? 5 10^{-5} 10?5;
- 批量大小:16、32 或 64;
- 動量系數:0.9 或 0.99。
五、總結
優化算法是深度學習訓練的基石,從簡單的梯度下降到自適應的 Adam,每種算法都有其適用場景。通過理解其數學原理、代碼實現和實際表現,開發者可以根據任務需求選擇合適的優化策略。






![[ctfshow web入門] web32](http://pic.xiahunao.cn/[ctfshow web入門] web32)












