對象的創建
- 導入 Pandas 時,通常給其一個別名“pd”,即 import pandas as pd。
- 作為標簽庫,Pandas 對象在 NumPy 數組基礎上給予其行列標簽。可以說,列表之于字典,就如 NumPy 之于 Pandas。
- Pandas 中,所有數組特性仍在,Pandas 的數據以 NumPy 數組的方式存儲。
一維對象的創建
- 字典創建法
NumPy 中,可以通過 np.array()函數,將 Python 列表轉化為 NumPy 數組;同樣,Pandas 中,可以通過 pd.Series()函數,將 Python 字典轉化為 Series 對象。
import pandas as pd
# 創建字典
dict_v = { 'a':0, 'b':0.25, 'c':0.5, 'd':0.75, 'e':1 }
# 用字典創建對象
sr = pd.Series( dict_v )
sr #OUT:a 0.00# b 0.25# c 0.50# d 0.75# e 1.00# dtype: float64
- 數組創建法
最直接的創建方法即直接給 pd.Series()函數參數,其需要兩個參數。第一個參數是值 values(列表、數組、張量均可),第二個參數是鍵 index(索引)。
import pandas as pd
# 先定義鍵與值
v = [0, 0.25, 0.5, 0.75, 1]
k = ['a', 'b', 'c', 'd', 'e']# 用列表創建對象
sr = pd.Series( v, index=k )
sr #OUT:a 0.00# b 0.25# c 0.50# d 0.75# e 1.00# dtype: float64
其中,參數 index 可以省略,省略后索引即從 0 開始的順序數字。
一維對象的屬性
Series 對象有兩個屬性:values 與 index。
import numpy as np
import pandas as pd
# 用數組創建 sr
v = np.array( [ 53, 64, 72, 82 ] )
k = ['1 號', '2 號', '3 號', '4 號']
sr = pd.Series( v, index=k )
sr #OUT:1 號 53# 2 號 64# 3 號 72# 4 號 82# dtype: int32
# 查看 values 屬性
sr.values #OUT:array([53, 64, 72, 82])
# 查看 index 屬性
sr.index #OUT:Index(['1 號', '2 號', '3 號', '4 號'], dtype='object')
事實上,無論是用列表、數組還是張量來創建對象,最終 values 均為數組。雖然 Pandas 對象的第一個參數 values 可以傳入列表、數組與張量,但傳進去后默認的存儲方式是 NumPy 數組。這一點更加提醒我們,Pandas 是建立在 NumPy 基礎上的庫,沒有 NumPy 數組庫就沒有 Pandas 數據處理庫。當想要 Pandas 退化為 NumPy 時,查看其 values 屬性即可。
二維對象的創建
二維對象將面向矩陣,其不僅有行標簽 index,還有列標簽 columns。
- 字典創建法
用字典法創建二維對象時,必須基于多個 Series 對象,每一個 Series 就是一列數據,相當于對一列一列的數據作拼接。
- 創建 Series 對象時,字典的鍵是 index,其延展方向是豎直方向;
- 創建 DataFrame 對象時,字典的鍵是 columns,其延展方向是水平方向。
import pandas as pd
# 創建 sr1:各個病人的年齡
v1 = [ 53, 64, 72, 82 ]
i = [ '1 號', '2 號', '3 號', '4 號' ]
sr1 = pd.Series( v1, index=i )
sr1 #OUT:1 號 53# 2 號 64# 3 號 72# 4 號 82# dtype: int32# 創建 sr2:各個病人的性別
v2 = [ '女', '男', '男', '女' ]
i = [ '1 號', '2 號', '3 號', '4 號' ]
sr2 = pd.Series( v2, index=i )
sr2 #OUT:1 號 女# 2 號 男# 3 號 男# 4 號 女# dtype: object
# 創建 df 對象
df = pd.DataFrame( { '年齡':sr1, '性別':sr2 } )
df #OUT: 年齡 性別# 1 號 53 女# 2 號 64 男# 3 號 72 男# 4 號 82 女
如果 sr1 和 sr2 的 index 不完全一致,那么二維對象的 index 會取 sr1 與 sr2的所有 index,相應的,該對象就會產生一定數量的缺失值(NaN)。
2. 數組創建法
最直接的創建方法即直接給 pd.DataFrame 函數參數,其需要三個參數。第一個參數是值 values(數組),第二個參數是行標簽 index,第三個參數是列標簽columns。其中,index 和 columns 參數可以省略,省略后即從 0 開始的順序數字。
import numpy as np
import pandas as pd
# 設定鍵值
v = np.array( [ [53, '女'], [64, '男'], [72, '男'], [82, '女'] ] )
i = [ '1 號', '2 號', '3 號', '4 號' ]
c = [ '年齡', '性別' ]
# 數組創建法
df = pd.DataFrame( v, index=i, columns=c )
df #OUT: 年齡 性別# 1 號 53 女# 2 號 64 男# 3 號 72 男# 4 號 82 女
上述 NumPy 數組居然又含數字又含字符串,上一篇博文中明明講過數組只能容納一種變量類型。這里的原理是,數組默默把數字轉為了字符串,于是 v 就是一個字符串型數組。
二維對象的屬性
DataFrame 對象有三個屬性:values、index 與 columns。
import pandas as pd
# 設定鍵值
v = [ [53, '女'], [64, '男'], [72, '男'], [82, '女'] ]
i = [ '1 號', '2 號', '3 號', '4 號' ]
c = [ '年齡', '性別' ]
# 數組創建法
df = pd.DataFrame( v, index=i, columns=c )
df #OUT: 年齡 性別# 1 號 53 女# 2 號 64 男# 3 號 72 男# 4 號 82 女
# 查看 values 屬性 # 查看 index 屬性
df.index #OUT:array([[53, '女'],# [64, '男'],# [72, '男'],# [82, '女']], dtype=object)
# 查看 index 屬性
df.index #OUT:Index(['1 號', '2 號', '3 號', '4 號'], dtype='object')
# 查看 columns 屬性
df.columns #OUT:Index(['年齡', '性別'], dtype='object')
當想要 Pandas 退化為 NumPy 時,查看其 values 屬性即可。
# 提取完整的數組
arr = df.values
print(arr) #OUT:[['53' '女']# ['64' '男']# ['72' '男']# ['82' '女']]
# 提取第[0]列,并轉化為一個整數型數組
arr = arr[:,0].astype(int)
print(arr) #OUT:[53 64 72 82]
由于數組只能容納一種變量類型,因此需要 .astype(int) 的操作。但對象不用,對象每一列的存儲方式是單獨的,這就很好的兼容了大數據的特性。
對象的索引
在學習 Pandas 的索引之前,需要知道
- Pandas 的索引分為顯式索引與隱式索引。顯式索引是使用 Pandas 對象提供的索引,而隱式索引是使用數組本身自帶的從 0 開始的索引。
- 現假設某演示代碼中的索引是整數,這個時候顯式索引和隱式索引可能會出亂子。于是,Pandas 作者發明了索引器 loc(顯式)與 iloc(隱式),手動告訴程序自己這句話是顯式索引還是隱式索引。
一維對象的索引
- 訪問元素
import pandas as pd
# 創建 sr
v = [ 53, 64, 72, 82 ]
k = ['1 號', '2 號', '3 號', '4 號']
sr = pd.Series( v, index=k )
sr #OUT:1 號 53# 2 號 64# 3 號 72# 4 號 82# dtype: int64
# 訪問元素
sr.loc[ '3 號' ] #OUT:72 顯示索引
sr.iloc[ 2 ] #OUT:72 隱式索引
# 花式索引
sr.loc[ [ '1 號', '3 號' ] ] #OUT:1 號 53 顯示索引# 3 號 72# dtype: int64
sr.iloc[ [ 0, 2 ] ] #OUT:1 號 53 隱式索引# 3 號 72# dtype: int64
# 修改元素
sr.loc[ '3 號' ] = 100
sr #OUT:1 號 53 顯示索引# 2 號 64# 3 號 100# 4 號 82# dtype: int64
# 修改元素
sr.iloc[ 2 ] = 100
sr #OUT:1 號 53 隱式索引# 2 號 64# 3 號 100# 4 號 82# dtype: int64
- 訪問切片
使用顯式索引時,‘1 號’:‘3 號’ 可以涵蓋最后一個’3 號’,但隱式與之前一樣。
import pandas as pd
# 創建 sr
v = [ 53, 64, 72, 82 ]
k = ['1 號', '2 號', '3 號', '4 號']
sr = pd.Series( v, index=k )
sr #OUT:1 號 53# 2 號 64# 3 號 72# 4 號 82# dtype: int64
# 訪問切片
sr.loc[ '1 號':'3 號' ] #OUT: 1 號 53 顯示索引# 2 號 64# 3 號 72# dtype: int64
sr.iloc[ 0:3 ] #OUT:1 號 53 隱式索引# 2 號 64# 3 號 72# dtype: int64# 切片僅是視圖
cut = sr.loc[ '1 號':'3 號' ]
cut.loc['1 號'] = 100
sr #OUT: 1 號 53 顯示索引# 2 號 64# 3 號 72# dtype: int64
cut = sr.iloc[ 0:3 ]
cut.iloc[0] = 100
sr #OUT:1 號 53 隱式索引# 2 號 64# 3 號 72# dtype: int64
# 對象賦值僅是綁定
cut = sr
cut.loc['3 號'] = 200
sr #OUT:1 號 100 顯示索引# 2 號 64# 3 號 200# 4 號 82# dtype: int64
cut = sr
cut.iloc[2] = 200
sr #OUT:1 號 100 隱式索引# 2 號 64# 3 號 200# 4 號 82# dtype: int64
若想創建新變量,與 NumPy 一樣,使用.copy()方法即可。如果去掉 .loc 和 .iloc ,此時與 NumPy 中的索引語法完全一致。
二維對象的索引
在二維對象中,索引器不能去掉,否則會報錯,因此必須適應索引器的存在。
- 訪問元素:
import pandas as pd# 字典創建法
i = [ '1 號', '2 號', '3 號', '4 號' ]
v1 = [ 53, 64, 72, 82 ]
v2 = [ '女', '男', '男', '女' ]
sr1 = pd.Series( v1, index=i )
sr2 = pd.Series( v2, index=i )
df = pd.DataFrame( { '年齡':sr1, '性別':sr2 } )
df #OUT:# 年齡 性別# 1 號 53 女# 2 號 64 男# 3 號 72 男# 4 號 82 女
# 訪問元素
df.loc[ '1 號', '年齡' ] #OUT:53
df.iloc[ 0, 0 ] #OUT:53
# 花式索引
df.loc[ ['1 號', '3 號'] , ['性別','年齡'] ] #OUT: 性別 年齡# 1 號 女 53# 3 號 男 72
df.iloc[ [0,2], [1,0] ] #OUT: 性別 年齡# 1 號 女 53# 3 號 男 72
# 修改元素
df.loc[ '3 號', '年齡' ] = 100
df #OUT:# 年齡 性別# 1 號 53 女# 2 號 64 男# 3 號 100 男# 4 號 82 女
df.iloc[ 2, 0 ] = 100
df #OUT:# 年齡 性別# 1 號 53 女# 2 號 64 男# 3 號 100 男# 4 號 82 女
在 NumPy 數組中,花式索引輸出的是一個向量。但在 Pandas 對象中,考慮到其行列標簽的信息不能丟失,所以輸出一個向量就不行了。
2. 訪問切片
import pandas as pd# 數組創建法
v = [ [53, '女'], [64, '男'], [72, '男'], [82, '女'] ]
i = [ '1 號', '2 號', '3 號', '4 號' ]
c = [ '年齡', '性別' ]
df = pd.DataFrame( v, index=i, columns=c )
df #OUT:# 年齡 性別# 1 號 53 女# 2 號 64 男# 3 號 72 男# 4 號 82 女
# 切片
df.loc[ '1 號':'3 號' , '年齡' ] #OUT: 1 號 53# 2 號 64# 3 號 72# Name: 年齡, dtype: int64
df.iloc[ 0:3 , 0 ] #OUT: 1 號 53# 2 號 64# 3 號 72# Name: 年齡, dtype: int64# 提取二維對象的行
df.loc[ '3 號' , : ] #OUT: 年齡 72# 性別 男# Name: 3 號, dtype: object
df.iloc[ 2 , : ] #OUT: 年齡 72# 性別 男# Name: 3 號, dtype: object
# 提取矩陣對象的列
df.loc[ : , '年齡' ] #OUT: 1 號 53# 2 號 64# 3 號 72# 4 號 82# Name: 年齡, dtype: int64
df.iloc[ : , 0 ] #OUT: 1 號 53# 2 號 64# 3 號 72# 4 號 82# Name: 年齡, dtype: int64
在顯示索引中,提取矩陣的行或列還有一種簡便寫法,即
- 提取二維對象的行:df.loc[ ‘3 號’](原理是省略后面的冒號,隱式也可以)
- 提取二維對象的列:df [‘年齡’ ](原理是列標簽本身就是二維對象的鍵)
對象的變形
對象的轉置
有時候提供的大數據很畸形,行是特征,列是個體,這必須要先進行轉置。
import pandas as pd
# 創建畸形 df
v = [ [53, 64, 72, 82], [ '女', '男', '男', '女' ] ]
i = [ '年齡', '性別' ]
c = [ '1 號', '2 號', '3 號', '4 號' ]
df = pd.DataFrame( v, index=i, columns=c )
df #OUT: 1 號 2 號 3 號 4 號#年齡 53 64 72 82#性別 女 男 男 女
# 轉置
df = df.T
df #OUT:# 年齡 性別#1 號 53 女#2 號 64 男#3 號 72 男#4 號 82 女
對象的翻轉
# 左右翻轉
df = df.iloc[ : , : : -1 ]
df #OUT:# 性別 年齡 #1 號 女 53 #2 號 男 64 #3 號 男 72 #4 號 女 82 # 上下翻轉
df = df.iloc[ : : -1 , : ]
df #OUT:# 性別 年齡 #4 號 女 82#3 號 男 72#2 號 男 64#1 號 女 53
對象的重塑
考慮到對象是含有行列標簽的,.reshape()已不再適用,因此對象的重塑沒有那么靈活。但可以做到將 sr 并入 df,也可以將 df 割出 sr。
import pandas as pd
# 數組法創建 sr
i = [ '1 號', '2 號', '3 號', '4 號' ]
v1 = [ 10, 20, 30, 40 ]
v2 = [ '女', '男', '男', '女' ]
v3 = [ 1, 2, 3, 4 ]
sr1 = pd.Series( v1, index=i )
sr2 = pd.Series( v2, index=i )
sr3 = pd.Series( v3, index=i )
sr1, sr2, sr3 #OUT:(1 號 10 1 號 女 1 號 1#OUT:2 號 20 2 號 男 2 號 2#OUT:3 號 30 3 號 男 3 號 3#OUT:4 號 40 4 號 女 4 號 4#OUT:dtype: int64, dtype: object, dtype: int64)
# 字典法創建 df
df = pd.DataFrame( { '年齡':sr1, '性別':sr2 } )
df #OUT:年齡 性別#1 號 10 女#2 號 20 男#3 號 30 男#4 號 40 女
# 把 sr 并入 df 中
df['牌照'] = sr3
df #OUT: 年齡 性別 牌照#1 號 10 女 1#2 號 20 男 2#3 號 30 男 3#4 號 40 女 4
# 把 df['年齡']分離成 sr4
sr4 = df['年齡']
sr4 #OUT:1 號 10#2 號 20#3 號 30#4 號 40#Name: 年齡, dtype: int64
對象的拼接
Pandas 中有一個 pd.concat()函數,與 np.concatenate()函數語法相似。
- 一維對象的合并
import pandas as pd# 創建 sr1 和 sr2
v1 = [10, 20, 30, 40]
v2 = [40, 50, 60]
k1 = [ '1 號', '2 號', '3 號', '4 號' ]
k2 = [ '4 號', '5 號', '6 號' ]
sr1 = pd.Series( v1, index= k1 )
sr2 = pd.Series( v2, index= k2 )
sr1, sr2 #OUT:(1 號 10# 2 號 20# 3 號 30# 4 號 40# dtype: int64,# 4 號 40# 5 號 50# 6 號 60# dtype: int64)
# 合并
pd.concat( [sr1, sr2] ) #OUT:1 號 10# 2 號 20# 3 號 30# 4 號 40# 4 號 40# 5 號 50# 6 號 60# dtype: int64
值得注意的是,上述出現了兩個“4 號”,這是因為 Pandas 對象的屬性,放棄了集合與字典索引中“不可重復”的特性,實際中,這可以拓展大數據分析與處理的應用場景。那么,如何保證索引是不重復的呢?對對象的屬性 .index 或 .columns 使用 .is_unique 即可檢查,返回 True表示行或列不重復,False 表示有重復
sr3 = pd.concat( [sr1, sr2] )
sr3.index.is_unique #OUT:False
- 一維對象與二維對象的合并
一維對象與二維對象的合并,即可理解為:給二維對象加上一列或者一行。因此,不必使用 pd.concat()函數,只需要借助 2.2 小節“二維對象的索引”語法。
import pandas as pd
# 創建 sr1 與 sr2
v1 = [ 10, 20, 30]
v2 = [ '女', '男', '男']
sr1 = pd.Series( v1, index=[ '1 號', '2 號', '3 號'] )
sr2 = pd.Series( v2, index=[ '1 號', '2 號', '3 號'] )
sr1, sr2 #OUT:(1 號 10# 2 號 20# 3 號 30# dtype: int64,# 1 號 女# 2 號 男# 3 號 男# dtype: object)
# 創建 df
df = pd.DataFrame( { '年齡':sr1, '性別':sr2 } )
df #OUT:# 年齡 性別#1 號 10 女#2 號 20 男#3 號 30 男
# 加上一列
df['牌照'] = [1, 2, 3]
df #OUT:# 年齡 性別 牌照#1 號 10 女 1#2 號 20 男 2#3 號 30 男 3
# 加上一行
df.loc['4 號'] = [40, '女', 4]
df #OUT:# 年齡 性別 牌照#1 號 10 女 1#2 號 20 男 2#3 號 30 男 3#4 號 40 女 4
- 二維對象的合并
二維對象合并仍然用 pd.concat()函數,不過其多了一個 axis 參數。
import pandas as pd
# 設定 df1、df2、df3
v1 = [ [10, '女'], [20, '男'], [30, '男'], [40, '女'] ]
v2 = [ [1, '是'], [2, '是'], [3, '是'], [4, '否'] ]
v3 = [ [50, '男', 5, '是'], [60, '女', 6, '是'] ]
i1 = [ '1 號', '2 號', '3 號', '4 號' ]
i2 = [ '1 號', '2 號', '3 號', '4 號' ]
i3 = [ '5 號', '6 號' ]
c1 = [ '年齡', '性別' ]
c2 = [ '牌照', 'ikun' ]
c3 = [ '年齡', '性別', '牌照', 'ikun' ]
df1 = pd.DataFrame( v1, index=i1, columns=c1 )
df2 = pd.DataFrame( v2, index=i2, columns=c2 )
df3 = pd.DataFrame( v3, index=i3, columns=c3 )
df1 #OUT:# 年齡 性別#1 號 10 女#2 號 20 男#3 號 30 男#4 號 40 女
df2 #OUT:# 牌照 ikun#1 號 1 是#2 號 2 是#3 號 3 是#4 號 4 否
df3 #OUT:# 年齡 性別 牌照 ikun#5 號 50 男 5 是#6 號 60 女 6 是
# 合并列對象(添加列特征)
df = pd.concat( [df1,df2], axis=1 )
df #OUT: 年齡 性別 牌照 ikun#1 號 10 女 1 是#2 號 20 男 2 是#3 號 30 男 3 是#4 號 40 女 4 否
# 合并行對象(添加行個體)
df = pd.concat( [df,df3] )
df #OUT:# 年齡 性別 牌照 ikun#1 號 10 女 1 是#2 號 20 男 2 是#3 號 30 男 3 是#4 號 40 女 4 否#5 號 50 男 5 是#6 號 60 女 6 是
對象的運算
對象與系數之間的運算
- 一維對象
import pandas as pd
# 創建 sr
sr = pd.Series( [ 53, 64, 72 ] , index=['1 號', '2 號', '3 號'] )
sr #OUT:1 號 53# 2 號 64# 3 號 72# dtype: int64
sr = sr + 10
sr #OUT:1 號 63# 2 號 74# 3 號 82# dtype: int64
sr = sr * 10
sr #OUT:1 號 630# 2 號 740# 3 號 820# dtype: int64
sr = sr ** 2
sr #OUT:1 號 396900# 2 號 547600# 3 號 672400# dtype: int64
- 二維對象
import pandas as pd
# 創建 df
v = [ [53, '女'], [64, '男'], [72, '男'] ]
df = pd.DataFrame( v, index=[ '1 號', '2 號', '3 號' ], columns=[ '年齡', '性別' ] )
df #OUT: 年齡 性別#1 號 53 女#2 號 64 男#3 號 72 男
df['年齡'] = df['年齡'] + 10
df #OUT: 年齡 性別#1 號 63 女#2 號 74 男#3 號 82 男
df['年齡'] = df['年齡'] * 10
df #OUT: 年齡 性別#1 號 630 女#2 號 740 男#3 號 820 男
df['年齡'] = df['年齡'] ** 2
df #OUT: 年齡 性別#1 號 396900 女#2 號 547600 男#3 號 672400 男
對象與對象之間的運算
對象做運算,必須保證其都是數字型對象,兩個對象之間的維度可以不同。
- 一維對象之間的運算
import pandas as pd# 創建 sr1
v1 = [10, 20, 30, 40]
k1 = [ '1 號', '2 號', '3 號', '4 號' ]
sr1 = pd.Series( v1, index= k1 )
sr1 #OUT:1 號 10# 2 號 20# 3 號 30# 4 號 40# dtype: int64
# 創建 sr2
v2 = [1, 2, 3 ]
k2 = [ '1 號', '2 號', '3 號' ]
sr2 = pd.Series( v2, index= k2 )
sr2 #OUT: 1 號 1# 2 號 2# 3 號 3# dtype: int64
sr1 + sr2 #OUT:1 號 11.0 加法# 2 號 22.0# 3 號 33.0# 4 號 NaN# dtype: float64
sr1 - sr2 #OUT:1 號 9.0 減法# 2 號 18.0# 3 號 27.0# 4 號 NaN# dtype: float64
sr1 * sr2 #OUT:1 號 10.0 乘法# 2 號 40.0# 3 號 90.0# 4 號 NaN# dtype: float64
sr1 / sr2 #OUT:1 號 10.0 乘法# 2 號 10.0# 3 號 10.0# 4 號 NaN# dtype: float64
sr1 ** sr2 #OUT:1 號 10.0 乘法# 2 號 400.0# 3 號 27000.0# 4 號 NaN# dtype: float64
- 二維對象之間的運算
import pandas as pd
# 設定 df1 和 df2
v1 = [ [10, '女'], [20, '男'], [30, '男'], [40, '女'] ]
v2 = [ 1, 2 ,3, 6 ]
i1 = [ '1 號', '2 號', '3 號', '4 號' ]; c1 = [ '年齡', '性別' ]
i2 = [ '1 號', '2 號', '3 號', '6 號' ]; c2 = [ '牌照' ]
df1 = pd.DataFrame( v1, index=i1, columns=c1 )
df2 = pd.DataFrame( v2, index=i2, columns=c2 )
df1 #OUT:# 年齡 性別#1 號 10 女#2 號 20 男#3 號 30 男#4 號 40 女
df2 #OUT:# 牌照#1 號 1#2 號 2#3 號 3#6 號 6
# 加法
df1['加法'] = df1['年齡'] + df2['牌照']
df1 #OUT:# 年齡 性別 加法#1 號 10 女 11.0#2 號 20 男 22.0#3 號 30 男 33.0#4 號 40 女 NaN
# 減法、乘法、除法、冪方
df1['減法'] = df1['年齡'] - df2['牌照']
df1['乘法'] = df1['年齡'] * df2['牌照']
df1['除法'] = df1['年齡'] / df2['牌照']
df1['冪方'] = df1['年齡'] ** df2['牌照']
df1 #OUT:# 年齡 性別 加法 減法 乘法 除法 冪方#1 號 10 女 11.0 9.0 10.0 10.0 10.0#2 號 20 男 22.0 18.0 40.0 10.0 400.0#3 號 30 男 33.0 27.0 90.0 10.0 27000.0#4 號 40 女 NaN NaN NaN NaN NaN
- 使用 np.abs()、np.cos()、np.exp()、np.log() 等數學函數時,會保留索引;
- Pandas 中仍然存在布爾型對象,用法與 NumPy 無異,會保留索引。
對象的缺失值
發現缺失值
發現缺失值使用 .isnull() 方法。
import pandas as pd
# 創建 sr
v = [ 53, None, 72, 82 ]
k = ['1 號', '2 號', '3 號', '4 號']
sr = pd.Series( v, index=k )
sr #OUT:1 號 53.0#2 號 NaN#3 號 72.0#4 號 82.0#dtype: float64
# 創建 df
v = [ [None, 1], [64, None], [72, 3], [82, 4] ]
i = [ '1 號', '2 號', '3 號', '4 號' ]
c = [ '年齡', '牌照' ]
df = pd.DataFrame( v, index=i, columns=c )
df #OUT: 年齡 牌照#1 號 NaN 1.0#2 號 64.0 NaN#3 號 72.0 3.0#4 號 82.0 4.0
# 發現 sr 的缺失值
sr.isnull() #OUT: 1 號 False# 2 號 True# 3 號 False# 4 號 False# dtype: float64
df.isnull() #OUT: 年齡 牌照#1 號 True False#2 號 False True#3 號 False False#4 號 False False
除了.isnull() 方法,還有一個與之相反的 .notnull() 方法,但不如在開頭加一個非號“~”即可。
剔除缺失值
剔除缺失值使用 .dropna() 方法,一維對象很好剔除;二維對象比較復雜,要么單獨剔除 df 中含有缺失值的行,要么剔除 df 中含有缺失值的列。
import pandas as pd
# 創建 sr
v = [ 53, None, 72, 82 ]
k = ['1 號', '2 號', '3 號', '4 號']
sr = pd.Series( v, index=k )
sr #OUT:1 號 53.0#2 號 NaN#3 號 72.0#4 號 82.0#dtype: float64
# 剔除 sr 的缺失值
sr.dropna() #OUT:1 號 53.0#3 號 72.0#4 號 82.0#dtype: float64# 創建 df
v = [ [None, None], [64, None], [72, 3], [82, 4] ]
i = [ '1 號', '2 號', '3 號', '4 號' ]
c = [ '年齡', '牌照' ]
df = pd.DataFrame( v, index=i, columns=c )
df #OUT: 年齡 牌照#1 號 NaN NaN#2 號 64.0 NaN#3 號 72.0 3.0#4 號 82.0 4.0
df.dropna() #OUT: 年齡 牌照#3 號 72.0 3.0#4 號 82.0 4.0
把含有 NaN 的行剔除掉了,你也可以通過 df.dropna(axis=‘columns’)的方式剔除列。但請警惕,一般都是剔除行,只因大數據中行是個體,列是特征。
有些同學認為,只要某行含有一個 NaN 就剔除該個體太過殘忍,我們可以設定一個參數,只有當該行全部是 NaN,才剔除該列特征。
df.dropna(how='all') #OUT: 年齡 牌照#2 號 64.0 NaN#3 號 72.0 3.0#4 號 82.0 4.0
ps:也可以設置缺失值大于幾行時剔除。
填補缺失值
填充缺失值使用 .fillna() 方法,實際的數據填充沒有統一的方法,很靈活。
- 一維對象
import pandas as pd
# 創建 sr
v = [ 53, None, 72, 82 ]
sr = pd.Series( v, index=['1 號', '2 號', '3 號', '4 號'] )
sr #OUT:1 號 53.0#2 號 NaN#3 號 72.0#4 號 82.0#dtype: float64
# 用常數(0)填充
sr.fillna(0) #OUT:1 號 53.0#2 號 0.0#3 號 72.0#4 號 82.0#dtype: float64
# 用常數(均值)填充
import numpy as np
sr.fillna(np.mean(sr)) #OUT:1 號 53.0#2 號 69.0#3 號 72.0#4 號 82.0#dtype: float64
# 用前值填充
sr.fillna(method='ffill') #OUT:1 號 53.0#2 號 53.0#3 號 72.0#4 號 82.0#dtype: float64
# 用后值填充
sr.fillna(method='bfill') #OUT:1 號 53.0#2 號 72.0#3 號 72.0#4 號 82.0#dtype: float64
- 二維對象
import pandas as pd
# 設定 df
v = [ [None, None], [64, None], [72, 3], [82, 4] ]
i = [ '1 號', '2 號', '3 號', '4 號' ]; c = [ '年齡', '牌照' ]
df = pd.DataFrame( v, index=i, columns=c )
df #OUT:# 年齡 牌照#1 號 NaN NaN#2 號 64.0 NaN#3 號 72.0 3.0#4 號 82.0 4.0
# 用常數(0)填充
df.fillna(0) #OUT:# 年齡 牌照#1 號 0.0 0.0#2 號 64.0 0.0#3 號 72.0 3.0#4 號 82.0 4.0
# 用常數(均值)填充
import numpy as np
df.fillna( np.mean(df))#OUT:# 年齡 牌照#1 號 72.69 3.5#2 號 64.0 3.5#3 號 72.0 3.0#4 號 82.0 4.0
# 用前值填充
df.fillna(method='ffill')#OUT:# 年齡 牌照#1 號 NaN NaN#2 號 64.0 NaN#3 號 72.0 3.0#4 號 82.0 4.0
# 用后值填充
df.fillna(method='bfill')#OUT:# 年齡 牌照#1 號 64.0 3.0#2 號 64.0 3.0#3 號 72.0 3.0#4 號 82.0 4.0
導入Excel文件
創建Excel文件
首先,創建 Excel 文件,錄入信息,第一列為 index,第一行為 columns。(字體選擇微軟雅黑即可)
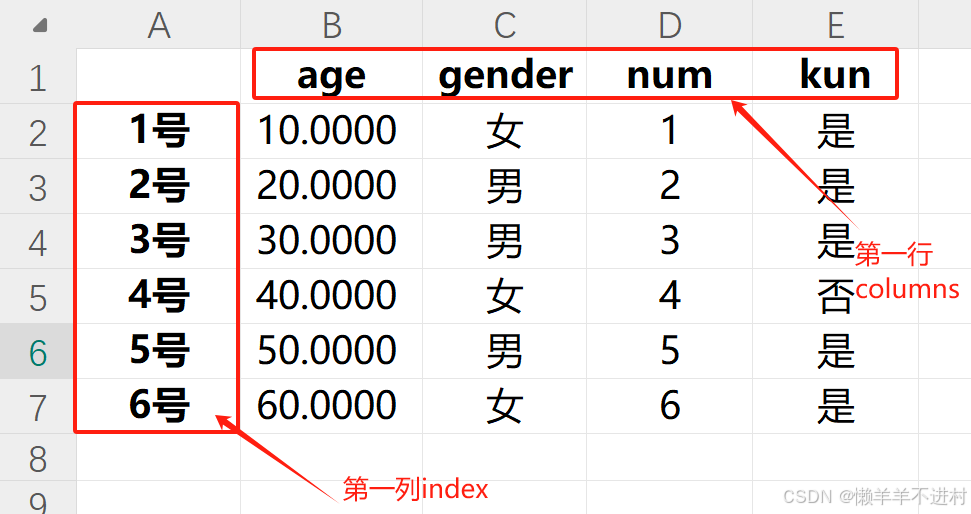
如果你的數據沒有 index 和 columns,也即你只是想導入一個數組,那么也請先補上行列標簽,后續用 .values 屬性就能將二維對象轉換為數組。
接著,將其另存為為 CSV 文件(在另存為的彈窗里面的保存類型選擇.csv )。
放入項目文件夾
將剛剛另存為的 CSV 文件放置工程文件下(不一定是默認路徑)。
導入Excel信息
import pandas as pd
# 導入 Pandas 對象
df = pd.read_csv('Data.csv', index_col=0)
df #OUT: # age Mgender num kun#1號 10.0 女 1 是#2號 20.0 男 2 是#3號 30.0 男 3 是#4號 40.0 女 4 否#5號 50.0 男 5 是#6號 60.0 女 6 是
# 提取純數組
arr = df.values
arr #OUT:array([[10.0, '女', 1, '是'],# [20.0, '男', 2, '是'],# [30.0, '男', 3, '是'],# [40.0, '女', 4, '否'],# [50.0, '男', 5, '是'],# [60.0, '女', 6, '是']], dtype=object)
數據分析
導入信息
按上一章內容導入信息
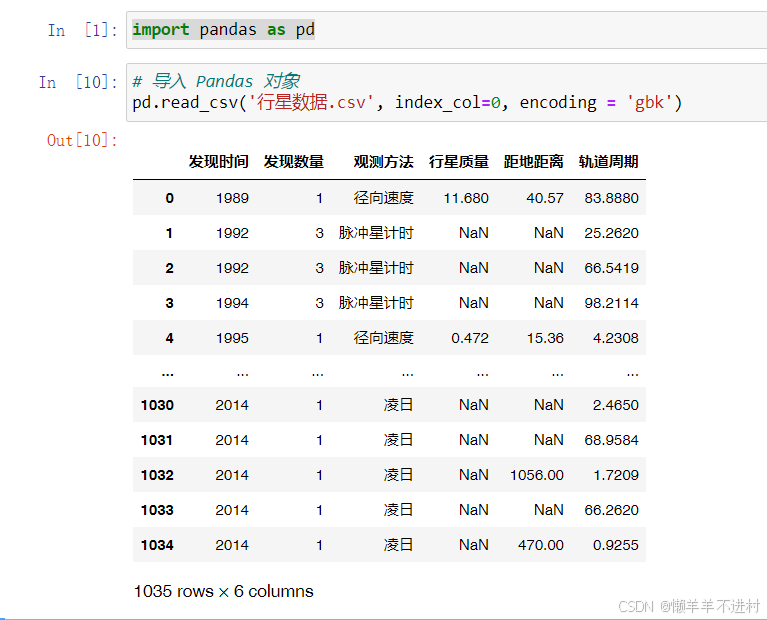
import pandas as pd
# 導入 Pandas 對象
pd.read_csv('行星數據.csv', index_col=0, encoding = 'gbk')
聚合方法
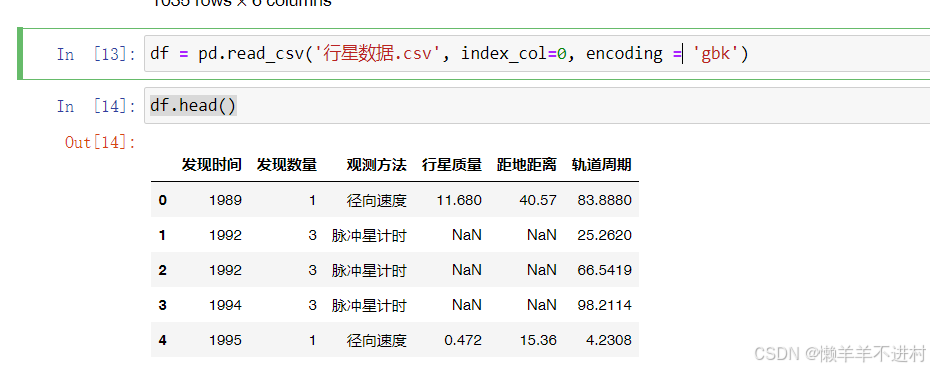
可在輸出 df 時,對其使用 .head() 方法,使其僅輸出前五行。
df = pd.read_csv('行星數據.csv', index_col=0, encoding = 'gbk')
df.head()
NumPy 中所有的聚合函數對 Pandas 對象均適用。此外,Pandas 將這些函數變為對象的方法,這樣,不導入 NumPy 也可使用。
# 最大值函數 np.max( )
df.max()
# 最小值函數 np.min( )
df.min()
# 均值函數 np.mean( )
df.mean()
# 標準差函數 np.std( )
df.std()
# 求和函數 np.sum( )
df.sum()
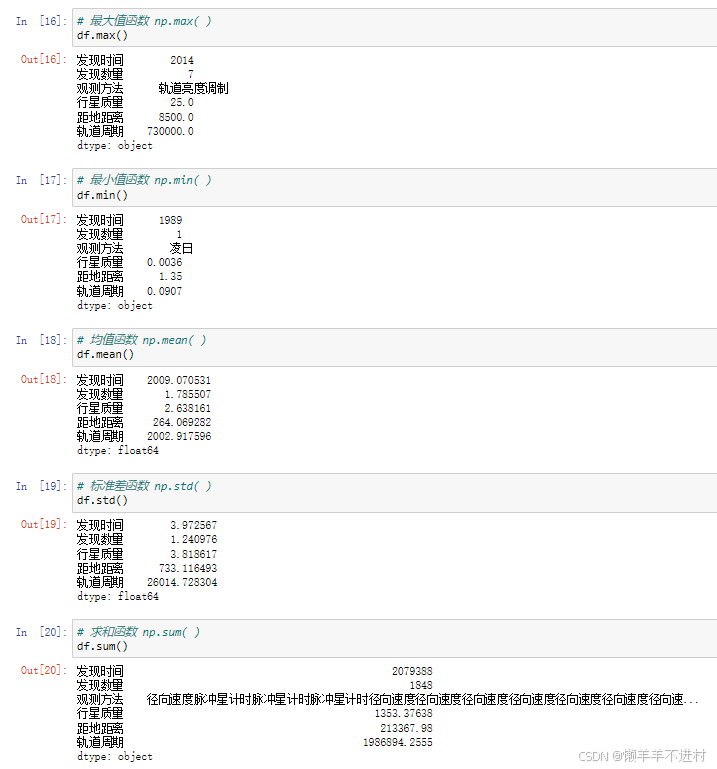
在這些方法中,像 NumPy 中一樣,有默認值為 0 的參數 axis。一般不要將其數值手動設定為 1,因為這種情況在數據分析中毫無意義。此外,這些方法都忽略了缺失值,屬于 NumPy 中聚合函數的安全版本。
描述方法
在數據分析中,用以上方法挨個查看未免太過麻煩,可以使用 .describe() 方法直接查看所有聚合函數的信息。
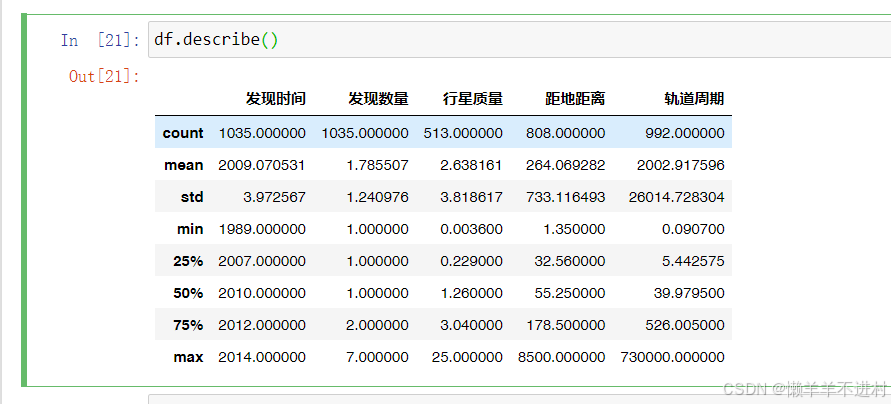
- 第 1 行 count 是計數項,統計每個特征的有效數量(即排除缺失值),從 count可以看出,行星質量的缺失值比較多,需要考慮一定的辦法填充或舍棄。
- 第 2 行至第 3 行的 mean 與 std 統計每列特征的均值與標準差。
- 第 4 行至第 8 行的 min、25%、50%、75%、max 的意思是五個分位點,即把數組從小到大排序后,0%、25%、50%、75%、100%五個位置上的數值的取值。顯然,50%分位點即中位數。
數據透視
- 兩個特征內的數據透視
數據透視,對數據分析來講十分重要。
現以泰坦尼克號的生還數據為例,以“是否生還”特征為考察的核心(或者說是神經網絡的輸出),研究其它特征(輸入)與之的關系,如示例所示。
import pandas as pd
# 導入 Pandas 對象
df = pd.read_csv('泰坦尼克.csv', index_col=0)
df.head()
# 一個特征:性別
df.pivot_table('是否生還', index='性別')
# 兩個特征:性別、船艙等級
df.pivot_table('是否生還', index='性別', columns='船艙等級')
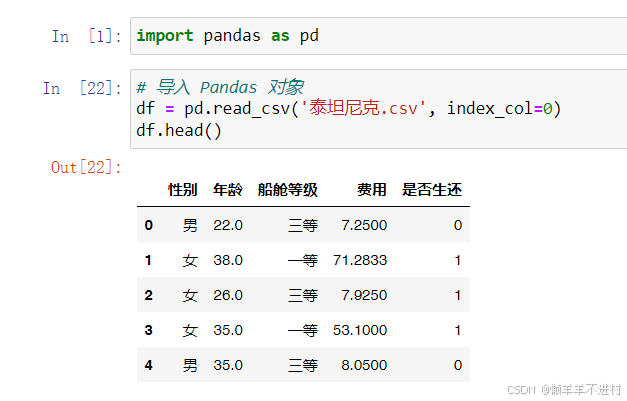
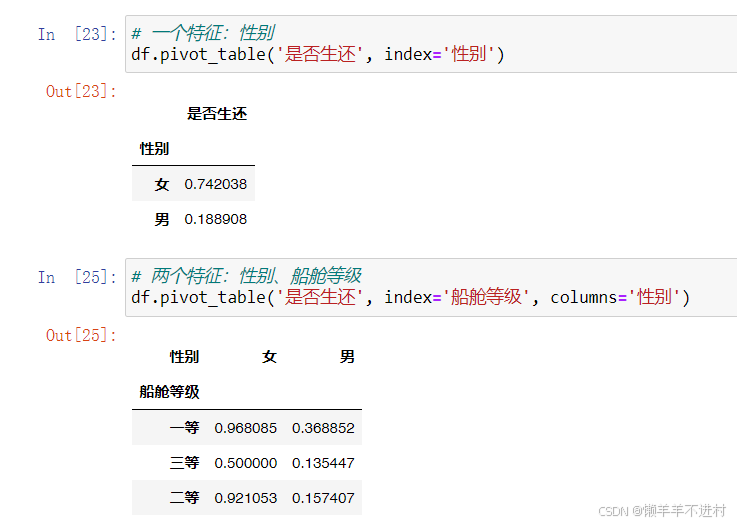
- 在上述示例中,數據透視表中的數值默認是輸出特征“是否生還”的均值(mean),行標簽和列標簽變成了其它的輸入特征。
- 值得注意的是,pivot_table() 方法有一個很重要的參數:aggfunc,其默認值是’mean’,除此以外,所有的聚合函數 ‘max’、‘min’、‘sum’、‘count’ 均可使用。顯然,對于這里的“是否生還”來說,'mean’就是最好的選擇,其剛好為概率
- 多個特征的數據透視
前面的示例只涉及到兩個特征,有時需要考察更多特征與輸出特征的關系。
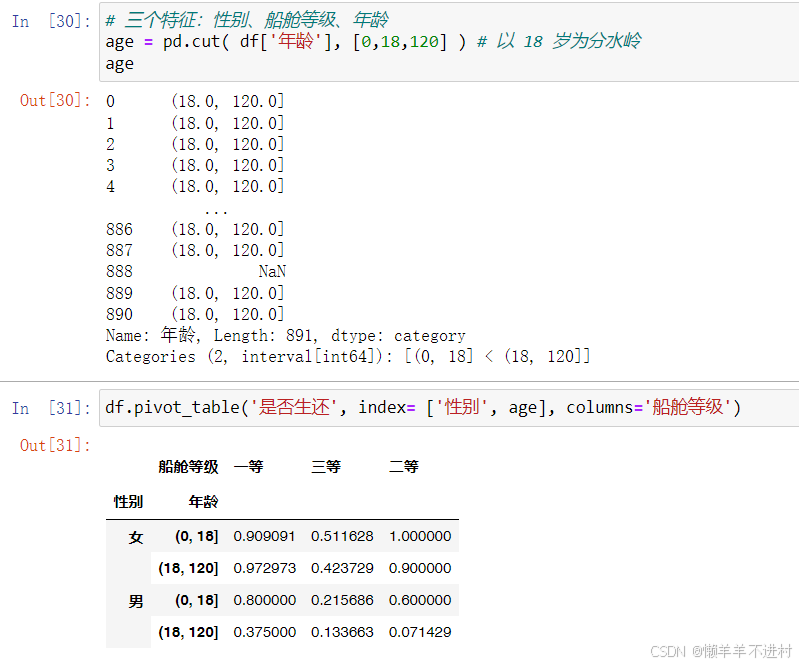
這里,將年齡和費用都加進去。但是,這兩個特征的數值很分散,之前的性別和船艙等級都可以按照類別分,現在已經不能再按類別分了。因此,需要涉及到數據透視表配套的兩個重要函數:pd.cut()與 pd.qcut()
# 三個特征:性別、船艙等級、年齡
age = pd.cut( df['年齡'], [0,18,120] ) # 以 18 歲為分水嶺
df.pivot_table('是否生還', index= ['性別', age], columns='船艙等級')
# 四個特征:性別、船艙等級、年齡、費用
fare = pd.qcut( df['費用'], 2 ) # 將費用自動分為兩部分
df.pivot_table('是否生還', index= ['船艙等級',fare], columns=['性別', age])
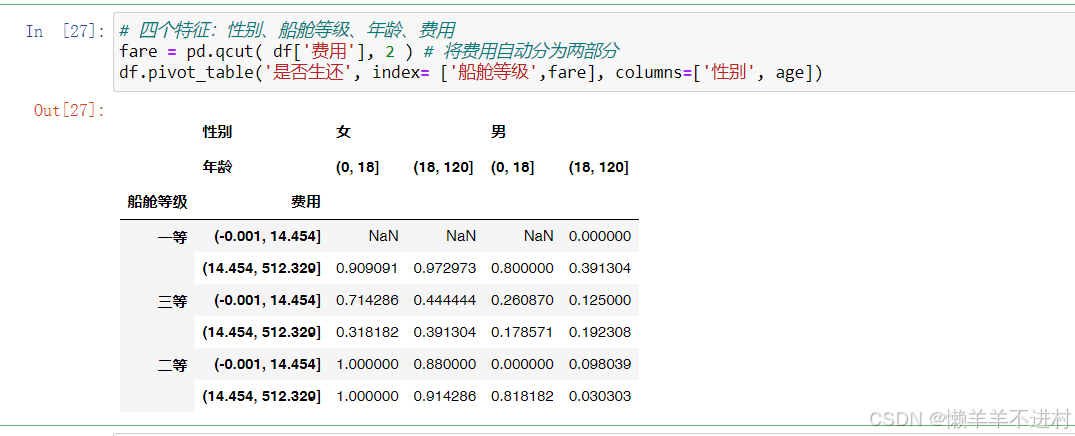
- pd.cut()函數需要手動設置分割點,也可以設置為[0,18,60,120]。
- pd.qcut()函數可自動分割,如果需要分割成 3 部分,可以設置為 3。



)
)
基礎)



)









