目錄
一、應用場景
二、卷積神經網絡的結構
1. 輸入層(Input Layer)
2. 卷積層(Convolutional Layer)
3. 池化層(Pooling Layer)
最大池化(max_pooling)或平均池化(?mean_pooling):
4. 全連接層(Fully Connected Layer)
5. 輸出層(Output Layer)
?三、?Relu激活函數
四、?Softmax激活函數
定義和公式:?
五、損失函數(softmax_loss)
1、定義:
2. 作用(Function)
(1)衡量預測與真實標簽之間的差異
(2)優化網絡參數
(3)適用于多分類任務
(4)防止數值不穩定
(5)損失函數與Softmax的結合
3. 示例說明
4. 總結
?六、前向傳播(forward propagation)
cnn例子圖解:?
1.輸入層---->卷積層
2.卷積層---->池化層?
3.池化層---->全連接層
4.全連接層---->輸出層
七、反向傳播?
八、參考文獻
一、應用場景
????????卷積神經網絡的應用不可謂不廣泛,主要有兩大類,數據預測和圖片處理。數據預測自然不需要多說,圖片處理主要包含有圖像分類,檢測,識別,以及分割方面的應用。
圖像分類:場景分類,目標分類
圖像檢測:顯著性檢測,物體檢測,語義檢測等等
圖像識別:人臉識別,字符識別,車牌識別,行為識別,步態識別等等
圖像分割:前景分割,語義分割

二、卷積神經網絡的結構
????????卷積神經網絡主要是由輸入層、卷積層、激活函數、池化層、全連接層、損失函數組成,表面看比較復雜,其實質就是特征提取以及決策推斷。
????????要使特征提取盡量準確,就需要將這些網絡層結構進行組合,比如經典的卷積神經網絡模型AlexNet:5個卷積層+3個池化層+3個連接層結構。
????????卷積的作用就是提取特征,因為一次卷積可能提取的特征比較粗糙,所以多次卷積,以及層層縱深卷積,層層提取特征。
1. 輸入層(Input Layer)
? ? ? ? ·輸入層是CNN的起點,負責接收輸入數據。在圖像處理中,輸入通常是一張RGB或灰度圖像,其尺寸為寬度×高度×通道數(即 height × width × channels)。對于顏色圖像,通道數為3(分別代表紅、綠、藍),而灰度圖像通道數為1。
????????定義:輸入層的形狀直接決定了網絡處理的原始數據的大小和格式。
????????作用:傳遞原始輸入數據到網絡中,為后續層提供基礎數據。
????????示例:比如,輸入一張224×224×3的圖像(224像素寬,224像素高,3個顏色通道),輸入層會將這些數據傳入網絡,供后續的卷積層處理。
2. 卷積層(Convolutional Layer)
????????卷積層是CNN的核心部分,負責從輸入數據中提取局部特征。通過應用一組可學習的濾鏡(kernel或filter),卷積層能夠檢測輸入圖像中的邊緣、紋理或其他顯著特征。
????????定義:每一卷積層由多個濾鏡組成,每個濾鏡負責檢測特定類型的特征。濾鏡在輸入圖像上滑動,計算局部區域的點積,得到特征圖(feature map)。
作用:
- 特征提取:通過濾鏡滑動,檢測輸入圖像中的特征,如邊緣、紋理等。
- 權重共享:每個濾鏡的參數在整個輸入圖像上共享,減少了參數數量,提升了計算效率。
- 空間感受野:每個特征圖中的每個單元只關注輸入圖像的局部區域,增強了網絡對局部結構的感知能力。
????????示例:假設輸入圖像為224×224×3,使用3×3×3的濾鏡,步長為1,無填充。卷積計算后,輸出特征圖的尺寸為222×222×n(n為濾鏡數量),每個特征圖對應一種特定的特征。
3. 池化層(Pooling Layer)
????????池化層的主要作用是降低特征圖的尺寸,減少計算復雜度,同時提升網絡的翻譯不變性(即網絡對輸入圖像的位置偏移的魯棒性)。
定義:池化層通過在特征圖上應用池化操作(如最大池化或平均池化),將局部區域的特征進行匯總,生成更小尺寸的特征圖。
作用:
- 降維:通過池化操作減少特征圖的空間尺寸,降低后續層的計算量。
- 防止過擬合:池化操作丟棄了部分特征,減少了網絡的復雜度,有助于防止過擬合。
- 平移不變性:池化使得網絡對目標位置的小范圍偏移不那么敏感,增強了網絡的穩健性。
示例:假設輸入特征圖為222×222×n,應用2×2的最大池化,步長為2。池化后的輸出尺寸為111×111×n,特征圖的尺寸減半,但保留了主要的特征信息。
最大池化(max_pooling)或平均池化(?mean_pooling):
????????mean_pooling 就是輸入矩陣池化區域求均值,這里要注意的是池化窗口在輸入矩陣滑動的步長跟stride有關,一般stride = 2.
????????最右邊7/4 => (1 + 1 + 2 + 3)/4

?????????max_pooling 最大值池化,就是每個池化區域的最大值放在輸出對應位置上。
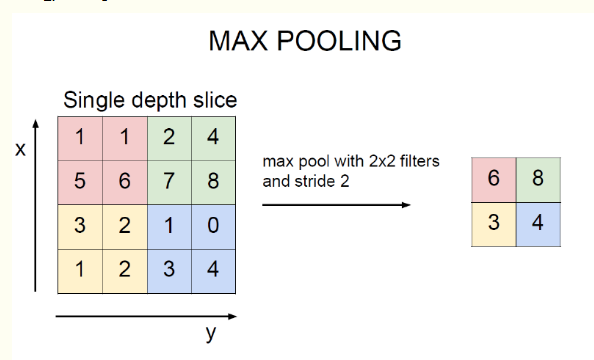
4. 全連接層(Fully Connected Layer)
????????全連接層是傳統的神經網絡層,每個神經元都與前一層的所有神經元相連。在CNN中,全連接層通常用于將特征圖展平(flatten)后,進行分類任務。
定義:全連接層接收展平的特征圖作為輸入,經過線性變換和激活函數,輸出到下一個層或作為最終的預測輸出。
作用:
- 特征整合:全連接層將來自不同區域和通道的特征進行綜合,提供一個全局的特征向量。
- 分類任務:通過全連接層,網絡可以進行多類別的分類,輸出每個類別的概率分數。
示例:假設池化后的特征圖為111×111×n,展平后為111×111×n = m個神經元。全連接層可能將m個輸入映射到類別數為k的向量,每個元素表示對應類別的概率。
5. 輸出層(Output Layer)
????????輸出層是CNN的最后一層,負責產生最終的分類結果或輸出其他需要的任務結果。
定義:輸出層的結構和激活函數取決于具體任務。例如,在分類任務中,輸出層通常使用Softmax激活函數(后面有介紹),輸出一個類別概率分布;在回歸任務中,可能直接輸出原始值。
作用:
- 預測結果:將前面的全連接層的輸出轉化為最終的預測結果。
- 損失計算:輸出層的輸出與真實標簽的對比,計算損失函數,指導網絡的訓練和參數優化。
示例:在分類任務中,輸出層可能包含與類別數量相同的神經元,每個神經元對應一個類別的概率,如Softmax函數輸出。?
?三、?Relu激活函數
1、 為什么要用激活函數?它的作用是什么?
????????由 y = w * x + b 可知,如果不用激活函數,每個網絡層的輸出都是一種線性輸出,而我們所處的現實場景,其實更多的是各種非線性的分布。
????????這也說明了激活函數的作用是將線性分布轉化為非線性分布,能更逼近我們的真實場景。
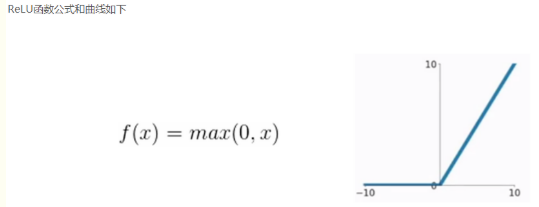
????????它的公式:f(x)=max(0,x)。也就是說,對于任何輸入x,如果x大于0,輸出就是x;如果x小于等于0,輸出就是0。這樣,ReLU函數可以將負數全部剪切為0,而正數保持不變。?
????????那Relu函數在卷積神經網絡中有什么作用呢?卷積神經網絡主要用于處理圖像數據,比如分類、檢測等任務。在這些任務中,激活函數是用來引入非線性,使模型能夠更好地擬合復雜的函數。
????????ReLU之前的激活函數,比如sigmoid或tanh,都有一個顯著的問題:當輸入很大的時候,梯度會變得非常小,導致訓練速度變慢甚至停止。這被稱為梯度消失問題。相比之下,ReLU函數在x>0時的梯度始終為1,這意味著在前向傳播和后向傳播過程中,梯度不會消失,這有助于加快訓練速度。
????????此外,ReLU能夠保留輸入的正部分,而將負部分置為0。這種稀疏性有助于減少計算量,因為不需要處理所有的負值。這也是為什么ReLU在計算效率上優于其他激活函數。
????????不過,ReLU也有一些缺點。比如,當輸入全是負數的時候,神經元會死亡,即輸出總是0,無法更新權重。為了克服這個問題,出現了修正線性單元的變種,比如Leaky ReLU和ELU。
????????總的來說,ReLU在卷積神經網絡中起到了引入非線性、加快訓練速度、減少計算量的重要作用。它幫助神經網絡更好地擬合復雜的函數,提升模型的準確性和效率。
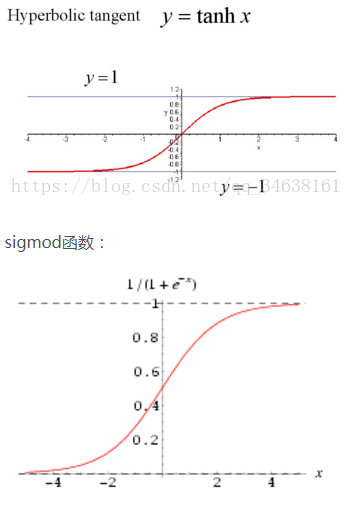
sigmoid或tanh的梯度消失問題原因:
? ? ? ? 由下圖可知:他們在x大于某個值時,輸出值y就變成了一個恒定值,因為求梯度時需要對函數求一階偏導數,而不論是sigmoid,還是tanhx,他們的偏導都為0(看斜率),也就是存在所謂的梯度消失問題,最終也就會導致權重參數w , b 無法更新。相比之下,Relu就不存在這樣的問題,另外在 x > 0 時,Relu求導 = 1,這對于反向傳播計算dw,db,是能夠大大的簡化運算的。
????????使用sigmoid還會存在梯度爆炸的問題,比如在進行前向傳播和反向傳播迭代次數非常多的情況下,sigmoid因為是指數函數,其結果中某些值會在迭代中累積,并成指數級增長,最終會出現NaN而導致溢出。
四、?Softmax激活函數
?????????Softmax函數是一種常見的激活函數,主要用于分類任務中將模型的輸出轉化為概率分布。它的圖像展示了輸入向量如何被轉換為概率向量。
定義和公式:?

????????Softmax函數將一個向量轉換為概率分布,使得每個元素的值在0到1之間,并且所有元素的和為1。這在分類任務中非常有用,因為它可以將模型的輸出轉化為類別概率。
????????首先,讓我畫一個簡單的圖例。假設我們有一個輸入向量,比如 SVM 訓練得到的兩個得分分別為 2 和 5。應用Softmax函數,這兩個得分會被轉換為兩個概率值,分別是 e2/(e2 + e?) ≈ 0.065 和 e?/(e2 + e?) ≈ 0.935。這兩個值加起來正好是1,表示第二個類別(得分5)的概率遠大于第一個類別。
????????接下來,我想分析一下Softmax函數的性質。Softmax函數的一個重要特點是對輸入的相對值感興趣。即使輸入的絕對值很大,只要相對比例不變,輸出的概率分布也不變。例如,如果兩個得分都是乘以一個相同的常數,比如2和10,Softmax的結果仍然保持相同的概率分布。這是因為在這個過程中,e2和e1?的計算已經考慮了相對大小。
-
作用:
- 將輸入的每個元素指數化,確保所有輸出值為正數。
- 對指數化后的值求和,使得所有輸出值之和為1,符合概率分布的特性。
-
圖像解釋:
- 輸入空間:假設輸入是一個二維向量(z?, z?),在復平面上表現為二維空間。
- 輸出空間:Softmax函數將二維輸入映射到二維概率輸出(p?, p?),滿足?𝑝1+𝑝2=1
- 圖像表現:
- 在輸入空間中,隨著z?和z?的變化,p?和p?的值也會變化,在圖上形成一個曲面。
- 當z?遠大于z?時,p?趨近于1,p?趨近于0。
- 當z?遠大于z?時,p?趨近于1,p?趨近于0。
- 當z?等于z?時,p? = p? = 0.5。
-
直觀理解:
- 最大值凸顯:Softmax函數會放大較大的輸入值,壓縮較小的輸入值,使得最大的輸入對應最高的概率。
- 平滑過渡:即使輸入之間差距不大,輸出的概率也會有平滑的變化,避免結果過于劇烈改變。
-
實際應用:
- 分類問題:Softmax函數常用于神經網絡的輸出層,將模型對各類別的原始輸出轉化為概率分布,便于進行分類決策。
- 多類別任務:適用于多于兩個類別的分類問題,能夠清晰地表示每個類別的概率。
????????通過以上分析,Softmax函數的圖像展示了它在轉換輸入到概率輸出中的核心作用,特別是在分類任務中的靈活性和有效性。
五、損失函數(softmax_loss)
1、定義:
????????在卷積神經網絡(CNN)中,softmax 損失函數(也稱為交叉熵損失函數)是用來衡量模型預測結果與真實標簽之間的差異的損失函數。它在分類任務中被廣泛使用,尤其是當輸出需要解釋為概率分布時。以下是其定義和作用的詳細解釋:


2. 作用(Function)
(1)衡量預測與真實標簽之間的差異
????????損失函數的作用是量化模型預測結果與真實標簽之間的差距。通過最小化損失函數,模型能夠調整參數(權重和偏置),從而更好地擬合數據。
(2)優化網絡參數
????????在訓練過程中,優化器(如Adam、SGD等)通過計算損失函數對參數的梯度(導數),使用反向傳播算法更新參數,以使損失最小化。
(3)適用于多分類任務
????????Softmax損失函數常用于多分類任務(類別數?K>2)。它的輸出是每個類別的概率,便于解釋和比較。
(4)防止數值不穩定
????????在計算過程中,使用log?(𝑎𝑖𝑗)log(aij?)?并結合交叉熵損失可以避免數值不穩定問題,例如當𝑎𝑖𝑗aij?趨近于0時,log?(𝑎𝑖𝑗)log(aij?)?的值不會變得過于極端。
(5)損失函數與Softmax的結合
????????Softmax函數將輸出值轉換為概率分布,而損失函數則將這些概率與真實標簽進行比較,計算損失。兩者的結合使得模型能夠在訓練過程中逐步調整參數,以提高預測的準確性。
3. 示例說明

4. 總結
- 定義:Softmax損失函數是結合了Softmax激活函數和交叉熵損失的函數,用于衡量模型預測結果與真實標簽之間的差異。
- 作用:
- 作為優化目標,引導模型調整參數以最小化損失。
- 適用于多分類任務,輸出概率分布便于解釋和比較。
????????通過理解Softmax損失函數的定義和作用,可以更好地理解卷積神經網絡在分類任務中的工作原理及其優化過程。
詳細可以看下面:
?Softmax函數詳解與推導 - 理想幾歲 - 博客園。
?常見損失函數解析-CSDN博客
?六、前向傳播(forward propagation)
??????前向傳播是 Feedforward 的過程,即從輸入層開始,經過一系列的卷積層、池化層、全連接層,最后到達輸出層,得到預測結果。理解前向傳播有助于理解整個網絡的工作流程及其設計原理。
????????首先,輸入層接收原始圖像數據。假設輸入圖像是一個 維的矩陣,通常表示為高度(height)、寬度(width)、通道數(channels)。對于灰度圖像,通道數為1;對于彩色圖像,通道數為3(對應RGB三通道)。
????????隨后,卷積層開始處理輸入數據。每個卷積層包含多個濾鏡(也稱為卷積核)。濾鏡的尺寸通常遠小于輸入圖像的尺寸(例如3x3或5x5),且濾鏡的數目可以是多個。濾鏡在輸入圖像上滑動,計算每個位置的點積,生成特征圖(feature map)。特征圖表示輸入在某個特定特征上的響應,例如邊緣或紋理。
????????卷積過程的一個關鍵點是權重共享,即每個濾鏡在圖像的每個位置上使用相同的權重,這減少了模型的參數數量,提高了計算效率。
????????接下來是池化層,常用的有最大池化(max pooling)和平均池化(average pooling)。池化層通過下采樣減少輸入的數據量,降低計算復雜度,并提高模型的平移不變性(scale invariance)。例如,一個2x2的池化操作會將每個2x2的區域簡化為一個值(最大值或平均值),從而將特征圖的高度和寬度各減少一半。
????????全連接層(Fully Connected Layer,FC)的作用是將前面所有層提取到的特征進行整合,最后輸出一個類別概率分布。全連接層的神經元與前一層的所有神經元相連,因此需要將前一層的特征圖展平(flattening)為一維向量。
????????最后,輸出層通過Softmax激活函數將輸出轉換為類別概率分布,以表示每個類別的預測概率。損失函數(Loss Function)計算模型預測結果與真實標簽之間的差異,作為優化目標。
????????通過前向傳播,模型能夠從輸入數據中提取特征,逐步變換數據,最終得到預測結果。為了優化模型,需要通過反向傳播(Backpropagation)計算損失函數對各個參數的梯度,進行參數更新,以最小化損失函數。
????????在實際應用中,設計不同的卷積層、池化層數目和尺寸,調整激活函數的類型,選擇合適的全連接層數目等,都是影響模型性能的重要因素。通過合理設計和調試,可以構建出高效、準確的卷積神經網絡模型。
?下圖為簡單的卷積神經網絡的前向傳播: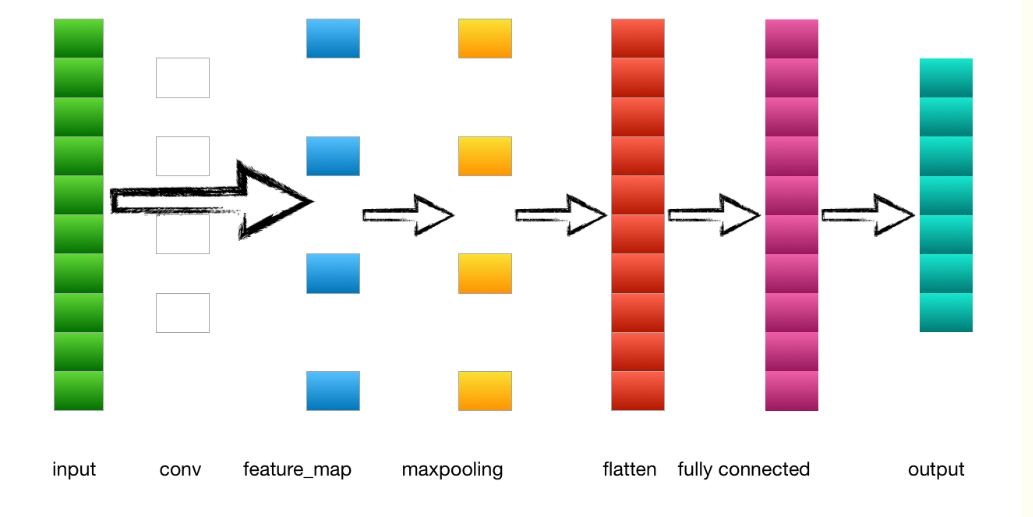
cnn例子圖解:?
1.輸入層---->卷積層
???輸入是一個4*4 的image,經過兩個2*2的卷積核進行卷積運算后,變成兩個3*3的feature_map
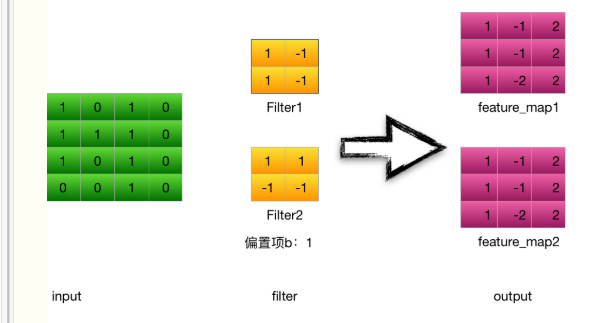
計算步驟:
????????以卷積核filter1為例(stride = 1 ):?


2.卷積層---->池化層?

3.池化層---->全連接層
池化層的輸出到flatten層把所有元素“拍平”,然后到全連接層。
4.全連接層---->輸出層
全連接層到輸出層就是正常的神經元與神經元之間的鄰接相連,通過softmax函數計算后輸出到output,得到不同類別的概率值,輸出概率值最大的即為該圖片的類別。
七、反向傳播?
????????卷積神經網絡(Convolutional Neural Network,簡稱 CNN)中反向傳播(Backpropagation)的作用主要是用于更新網絡中的參數(權重和偏置),以最小化損失函數,從而使模型能夠學習到數據中的特征和模式,具體如下:
????????計算梯度:反向傳播算法基于鏈式法則,從輸出層開始,將誤差逐層反向傳播到輸入層。在這個過程中,它會計算損失函數關于每個參數的梯度。通過計算梯度,反向傳播可以確定每個參數對損失函數的影響程度,即參數的變化會如何影響模型的輸出誤差。
????????更新參數:根據計算得到的梯度,反向傳播算法會相應地更新網絡中的參數。通常使用梯度下降(Gradient Descent)或其變體(如隨機梯度下降 SGD、Adagrad、Adadelta 等)來根據梯度調整參數的值。具體來說,會沿著梯度的反方向更新參數,使得損失函數的值逐漸減小。這樣,經過多次迭代后,模型的參數會逐漸調整到能夠使損失函數最小化的狀態,從而使模型能夠更好地擬合訓練數據,提高模型的準確性和泛化能力。
八、參考文獻
【深度學習系列】卷積神經網絡詳解(二)——自己手寫一個卷積神經網絡 - Charlotte77 - 博客園
深度學習之卷積神經網絡(CNN)詳解與代碼實現(一) - w_x_w1985 - 博客園



)















