目錄
引入
?開散列的底層實現
哈希表的定義
哈希表的擴容
哈希表的插入
哈希表查找
哈希表的刪除
引入
接上一篇,我們使用了閉散列的方法解決了哈希沖突,此篇文章將會使用開散列的方式解決哈希沖突,后面對unordered_set和unordered_map的封裝也會用開散列的哈希表實現。
開散列,也叫哈希桶和拉鏈法,其數組中存儲的不再是單個數據,而是一個個的節點指針。通過將數據映射到對應位置后,插入到鏈表中去。
閉散列就像一個個的鏈表掛在數組上。?
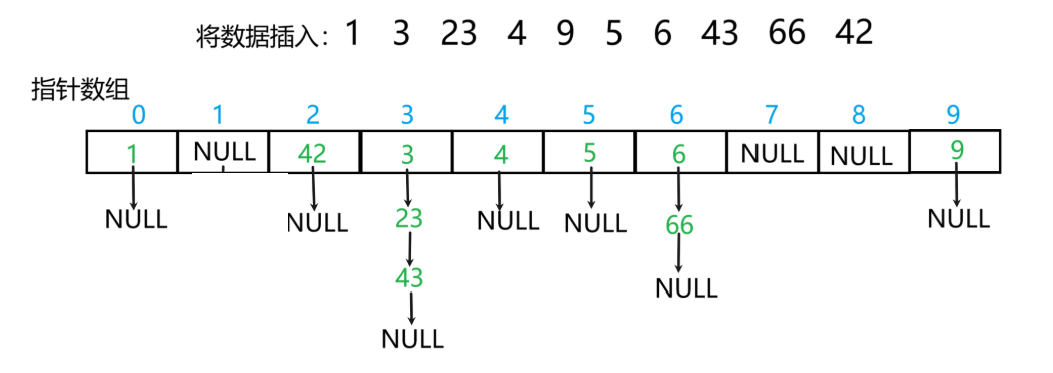
?開散列的底層實現
與閉散列不同的是,開散列哈希表中存儲的是節點,不再是具體數據;也不許需要再存儲狀態,只需要存儲下一個指針即可。
哈希表的定義
template<class K,class V>
struct HashNode
{//默認構造HashNode(const pair<K,V>& kv=pair()):_kv(kv),next(nullptr){ }pair<K, V> _kv;HashNode* _next;
};template<class K,class V>
class HashTable
{typedef HashNode<K, V> Node;
public://默認構造HashTable(){_table.resize(10); //初始情況下數組有10個空間_n = 0;}private:vector<Node*> _table;size_t _n; //存儲有效數據
};哈希表的擴容
開散列在插入時,像閉散列一樣也要檢查載荷因子時候滿足條件。開散列的載荷因子沒有閉散列那么嚴格,開散列的載荷因子要求小于1即可,平均每條鏈有一個數據。
在擴容后也需要對數據進行重新插入。
擴容方法:創建新的哈希表,將原數據的節點一個個的插入到新數組中,再將兩個數組進行交換。
//擴容
void More()
{if ((double)_n / _table.size() >= 1){//進行擴容HashTable newtable;size_t newsize = 2 * _table.size();newtable._table.resize(newsize); //擴容兩倍擴size_t hashi = 0;while (hashi < _table.size()){if (_table[hashi]){//將數據進行頭插Node* pcur = _table[hashi];while (pcur){Node* next = pcur->_next;pcur->_next = newtable._table[hashi];newtable._table[hashi] = pcur;pcur = next;}}hashi++;}_table.swap(newtable._table);}
}哈希表的插入
//插入
bool insert(const pair<K, V>& kv)
{//擴容More();size_t hashi = kv.first % _table.size();Node* newnode = new Node(kv);//將數據頭插到對應映射的位置newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;
}
哈希表查找
先找到映射的位置,在對應位置的鏈表中查找。
//查找
bool Find(const K& key)
{size_t hashi = key % _table.size();Node* pcur = _table[hashi];while (pcur){if (pcur->_kv.first == key){return true;}pcur = pcur->_next;}return false;
}哈希表的刪除
哈希表的刪除比較簡單:直接將該節點的前后指針連起來即可。
//刪除
bool Erase(const K& key)
{size_t hashi = key % _table.size();Node* pcur = _table[hashi];Node* parent = nullptr;while (pcur){if (pcur->_kv.first == key){if (parent == nullptr){delete pcur;pcur = nullptr;_table[hashi] = nullptr;}else{parent->_next = pcur->_next;delete pcur;}return true;}pcur = pcur->_next;}return false;
}到此,哈希表的開散列的基本實現已經完成。還有一些具體細節將在《哈希表的封裝》中進行具體分析。
:K-Means聚類原理與實戰)

之安裝Dashboard和CoreDNS)


-部分環境配置(git、數據庫))

 gcc編譯)




)

和DML(數據操作語言))
更新內容)
![[ctfshow web入門] web23](http://pic.xiahunao.cn/[ctfshow web入門] web23)


