
目錄
- 一、 為什么需要主從復制?🤔
- 二、 如何搭建主從架構?
- 前提條件?
- 步驟
- 📁 創建工作目錄
- 📜 創建 Docker Compose 配置文件
- 🚀 啟動所有 Redis
- 🔍 驗證主從狀態
- 💡 重要提示和后續改進
- 三、 主從復制的數據同步原理是什么?
- 四、 主從復制的優缺點是什么?
- 五、 總結
🌟我的其他文章也講解的比較有趣😁,如果喜歡博主的講解方式,可以多多支持一下,感謝🤗!
🌟了解 緩存雪崩、穿透、擊穿 請看 : 緩存雪崩、穿透、擊穿:別讓你的數據庫“壓力山大”!
其他優質專欄: 【🎇SpringBoot】【🎉多線程】【🎨Redis】【?設計模式專欄(已完結)】…等
如果喜歡作者的講解方式,可以點贊收藏加關注,你的支持就是我的動力
?更多文章請看個人主頁: 碼熔burning
Redis主從復制,可以把它想象成一個“跟班”系統
- Master (主節點):就是“大哥” ,所有的事情(寫數據📝、改數據??)都由他說了算,他手里有最新的、最全的信息(數據)。
- Slave (從節點):就是“小弟”或“跟班” ,他們不直接干活(默認不能寫數據),主要任務就是時刻盯著大哥 👀,大哥做了什么,他們就跟著學(復制數據🔄),保持和大哥信息同步。
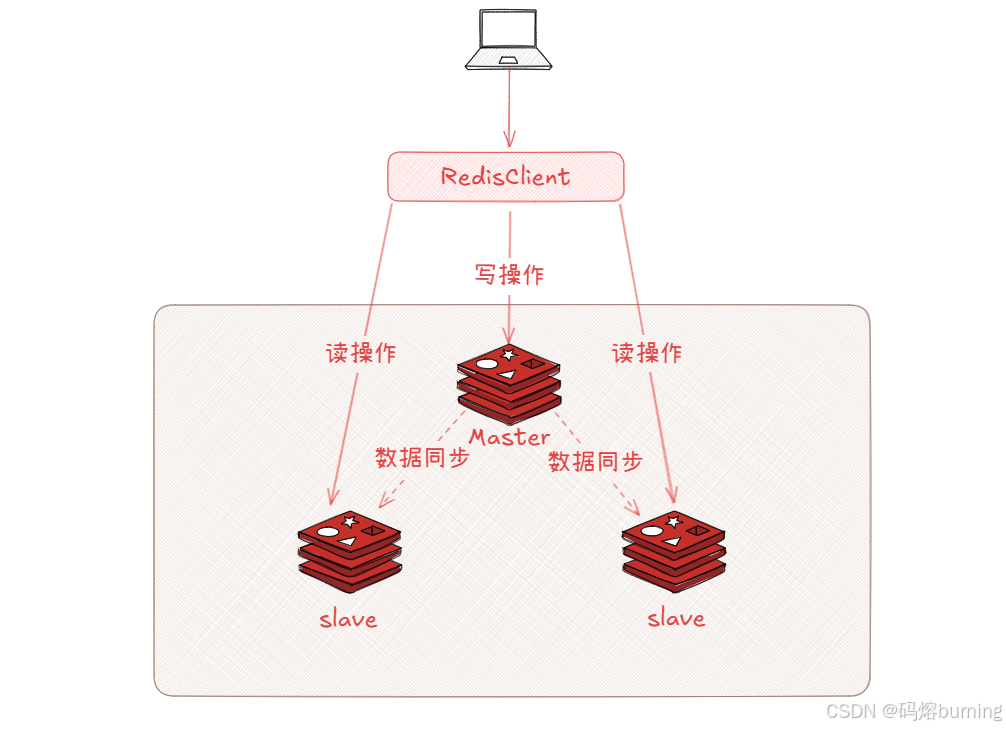
一、 為什么需要主從復制?🤔
主要有這么幾個原因:
-
a. 數據備份與高可用 (大哥萬一出事了 💀,有人頂上 💪):
- 備份:小弟手里有大哥數據的完整副本 📑。萬一大哥突然“掛了”(服務器宕機、硬盤壞了),數據不會完全丟失,至少小弟那里還有一份。
- 高可用:如果大哥真的出事了,我們可以快速“提拔”一個小弟當新大哥(這個過程叫“故障轉移”,通常需要配合哨兵模式或集群模式自動完成 ?),保證服務能快速恢復,不會停太久。
-
b. 讀寫分離,提升性能 (大哥太忙 🥵,小弟分擔點任務 🤝):
- 在一個系統中,“讀”數據的操作往往比“寫”數據的操作多得多。
- 如果所有讀寫請求都壓在大哥一個人身上,他可能會累垮(性能瓶頸 🏺)。
- 有了小弟后,可以讓大哥專門處理“寫”請求和少量的“讀”請求,而把大量的“讀”請求分流給各個小弟去處理。這樣大家分工合作,整個系統的處理能力就上去了 🚀,響應速度也更快 ?。這就像大哥負責決策和發布命令,小弟們負責對外宣傳和解答疑問。
-
c. 負載均衡 (分攤壓力 ??):
- 和讀寫分離類似,多個小弟可以分攤讀請求的壓力,避免所有讀請求都集中在一臺服務器上。
二、 如何搭建主從架構?
下面是使用一臺 Linux 服務器和 Docker 技術搭建 Redis 一主二從(Master-Slave)復制結構的步驟。我們將使用 Docker Compose 來簡化管理。
前提條件?
- 擁有一臺 Linux 服務器 🖥?。
- 服務器上已安裝 Docker 和 Docker Compose 🐳(這里就不演示了,自行查找教程安裝)。
- 安裝完成之后,使用
docker pull redis來拉去最新的redis的鏡像。
步驟
📁 創建工作目錄
在你的服務器上選擇一個合適的位置,創建一個用于存放配置文件的目錄。
mkdir redis-clustercd redis-cluster
📜 創建 Docker Compose 配置文件
在 redis-cluster 目錄下創建一個名為 docker-compose.yml 的文件,并填入以下內容:
services:redis-master:image: redis:latest # 或者指定具體版本, 如 redis:7.2container_name: redis-masterports:- "6379:6379" # 將主節點的 6379 端口映射到宿主機的 6379 端口networks:- redis-net# 可以添加 volumes 實現數據持久化 (可選) 💾# volumes:# - ./master-data:/data# - ./master-redis.conf:/usr/local/etc/redis/redis.conf # 如果需要自定義配置# command: redis-server /usr/local/etc/redis/redis.conf # 如果使用了自定義配置redis-slave1:image: redis:latestcontainer_name: redis-slave1ports:- "6380:6379" # 將第一個從節點的 6379 端口映射到宿主機的 6380 端口networks:- redis-netcommand: redis-server --slaveof redis-master 6379 # 🔑 指定主節點地址和端口depends_on:- redis-master # 確保主節點先啟動# 可以添加 volumes 實現數據持久化 (可選) 💾# volumes:# - ./slave1-data:/data# - ./slave1-redis.conf:/usr/local/etc/redis/redis.conf# command: redis-server /usr/local/etc/redis/redis.conf --slaveof redis-master 6379redis-slave2:image: redis:latestcontainer_name: redis-slave2ports:- "6381:6379" # 將第二個從節點的 6379 端口映射到宿主機的 6381 端口networks:- redis-netcommand: redis-server --slaveof redis-master 6379 # 🔑 指定主節點地址和端口depends_on:- redis-master # 確保主節點先啟動# 可以添加 volumes 實現數據持久化 (可選) 💾# volumes:# - ./slave2-data:/data# - ./slave2-redis.conf:/usr/local/etc/redis/redis.conf# command: redis-server /usr/local/etc/redis/redis.conf --slaveof redis-master 6379networks:redis-net:driver: bridge # 創建一個橋接網絡供容器間通信
配置說明:
services: 定義了三個服務(容器):redis-master,redis-slave1,redis-slave2。image: redis:latest: 指定使用最新的官方 Redis 鏡像。建議在生產環境中使用具體的版本號(如redis:7.2)。container_name: 為容器指定一個易于識別的名稱。ports: 將容器的 6379 端口映射到宿主機的不同端口。redis-master映射到 6379,redis-slave1映射到 6380,redis-slave2映射到 6381。這樣你可以在宿主機上通過不同端口訪問它們。networks: - redis-net: 將所有容器連接到名為redis-net的自定義 Docker 網絡。這使得容器可以通過容器名稱(redis-master,redis-slave1,redis-slave2)相互通信。command: redis-server --slaveof redis-master 6379🔑: 這是關鍵配置。它告訴redis-slave1和redis-slave2容器啟動時,連接到名為redis-master的容器的 6379 端口,并成為它的從節點。depends_on: - redis-master: 確保從節點容器在主節點容器啟動之后再啟動。networks: redis-net: driver: bridge: 定義了一個名為redis-net的自定義橋接網絡。volumes(注釋掉的部分) 💾: 如果需要數據持久化(即使容器停止或刪除,數據也不會丟失),取消這些行的注釋。./master-data:/data:將宿主機當前目錄下的master-data文件夾掛載到redis-master容器內的/data目錄(Redis 默認數據存儲目錄)。你需要手動創建master-data,slave1-data,slave2-data目錄。./master-redis.conf:/usr/local/etc/redis/redis.conf:如果你需要更復雜的 Redis 配置(如設置密碼requirepass和masterauth,修改 RDB/AOF 配置等),可以創建一個redis.conf文件,并將其掛載到容器內。如果掛載了自定義配置文件,通常需要修改command來指定加載該配置文件。
🚀 啟動所有 Redis
在 redis-cluster 目錄下(包含 docker-compose.yml 文件的目錄),運行以下命令:
# 啟動容器并在后臺運行
docker compose up -d
# 如果你的 docker compose 不是插件形式,可能是 docker-compose up -d
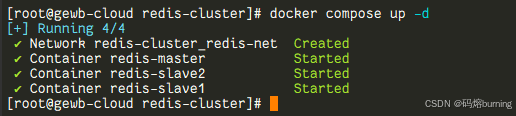
Docker Compose 會根據 `docker-compose.yml` 文件創建并啟動三個 Redis 容器。`-d` 參數表示在后臺(detached mode)運行。
🔍 驗證主從狀態
-
查看容器狀態:
docker compose ps # 或者 docker ps
你應該能看到
redis-master,redis-slave1,redis-slave2三個容器正在運行 (State 為Up)。? -
檢查主節點信息:
連接到主節點容器并查看復制信息。docker exec -it redis-master redis-cli進入
redis-cli后,輸入:INFO replication
在輸出中查找:
role:master?:確認它是主節點。connected_slaves:2?:確認有兩個從節點連接。- 下面會列出兩個 slave 的信息(IP、端口、狀態等)。
-
檢查從節點信息:
連接到任意一個從節點容器(例如redis-slave1)并查看復制信息。docker exec -it redis-slave1 redis-cli進入
redis-cli后,輸入:INFO replication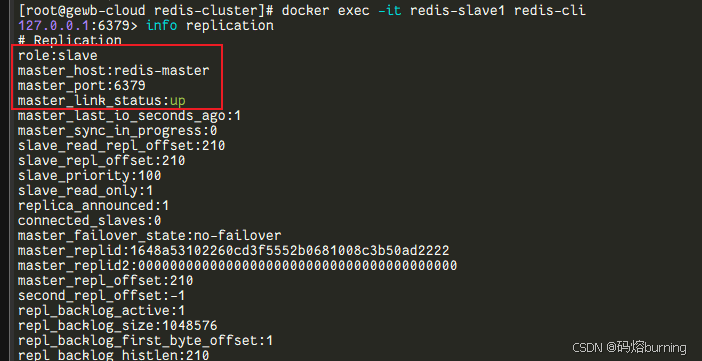
在輸出中查找:
role:slave?:確認它是從節點。master_host:redis-master?:確認主節點的主機名正確。master_port:6379?:確認主節點的端口正確。master_link_status:up?:確認與主節點的連接正常。
-
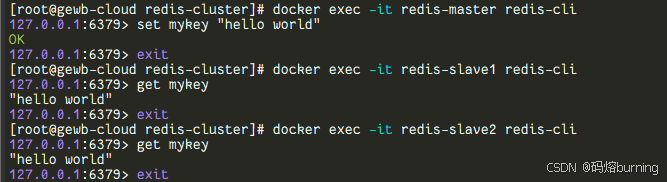
?? 測試數據同步:
- 在主節點 (
redis-master) 的redis-cli中設置一個鍵值對:
應該返回SET mykey "hello world from master! 👋"OK。 - 在從節點 (
redis-slave1或redis-slave2) 的redis-cli中獲取這個鍵的值:
應該能成功返回GET mykey"hello world from master! 👋"。這表明數據已從主節點同步到從節點 🎉。
- 在主節點 (
🛑 停止和清理 (如果需要):
如果你想停止并刪除這些容器、網絡,可以在 redis-cluster 目錄下運行:
docker compose down
如果使用了掛載卷(volumes)并且想刪除數據,可以添加 -v 選項:
docker compose down -v # 這個會把數據也刪掉哦,請小心!
💡 重要提示和后續改進
- 數據持久化: 上面的示例默認沒有啟用持久化。對于生產環境,強烈建議通過掛載
volumes💾 來持久化/data目錄,并可能需要配置 RDB 快照或 AOF 日志。 - 安全性: 示例沒有設置密碼 🔑。在生產環境中,務必為主節點設置
requirepass,并為從節點設置masterauth來連接到需要密碼的主節點。這需要在自定義的redis.conf文件中配置,并通過volumes掛載進去,同時修改command以加載配置文件。 - 高可用: 這個設置只是主從復制,如果主節點宕機 💥,從節點不會自動提升為主節點。你需要手動處理故障轉移,或者使用 Redis Sentinel(哨兵模式)或 Redis Cluster(集群模式)來實現自動故障轉移和更高可用性。
- 資源限制: 在生產環境中,你可能需要為每個 Redis 容器設置 CPU 和內存限制 ??,以防止它們消耗過多服務器資源。這可以在
docker-compose.yml文件的服務定義中通過deploy->resources->limits來配置。 - 監控: 部署后,需要建立監控機制 📊 來跟蹤 Redis 實例的健康狀況、內存使用、連接數和復制延遲等。
這樣,你就成功地在一臺 Linux 服務器上使用 Docker 搭建了一個 Redis 一主二從的復制結構啦!👍
三、 主從復制的數據同步原理是什么?
這個過程分為兩個階段:
-
a. 首次連接/全量復制 (小弟剛入門,大哥先給一本完整的秘籍 📖)
- 握手 🤝:小弟啟動后,會主動向大哥發送一個
PSYNC(或者舊版的SYNC) 命令,告訴大哥:“大哥,我是新來的(或者斷線重連的),我想跟你混,告訴我你的ID和現在的數據進度(偏移量)”。 - 大哥準備:大哥收到后,會執行一個
BGSAVE命令,在后臺生成一個當前數據的快照(RDB文件)📸。這就像大哥把目前所有的武功秘籍復印一份。 - 緩沖命令 ?:在生成快照期間,大哥如果又收到了新的寫命令(比如又學了新招式),會先把這些新命令緩存起來,不立刻發給這個正在等待快照的小弟。
- 發送快照 📤📁:大哥把生成的RDB快照文件發給小弟。
- 小弟加載 📥?:小弟收到快照文件后,會清空自己原來的舊數據(如果有的話),然后加載這個RDB文件,這樣小弟的數據就和大哥生成快照那個時間點完全一致了。
- 發送緩沖命令 📨:大哥把在生成快照期間緩存起來的新命令,再發給小弟。小弟執行這些命令,追上大哥最新的狀態。
- 完成 👍?:至此,小弟的數據就和大哥完全同步了。這個過程叫“全量復制”。
- 握手 🤝:小弟啟動后,會主動向大哥發送一個
-
b. 持續同步/增量復制 (入門后,大哥有新招式隨時教 🏃?♂?💨)
- 全量復制完成后,大哥每次執行一個“寫”命令(如
SET,DEL,INCR等),都會把這個命令實時地、異步地發送給所有跟著他的小弟 📡。 - 小弟收到命令后,就在自己這邊也執行一遍同樣的命令,從而保持和大哥的數據一致。
- 這個過程是持續不斷的,只要主從連接正常,大哥一有動作,小弟馬上跟著學。
- 全量復制完成后,大哥每次執行一個“寫”命令(如
-
斷線重連優化 (小弟臨時掉線了怎么辦?🔗?)
- Redis 2.8 版本之后引入了
PSYNC命令,支持部分重同步(Partial Resynchronization)。 - 大哥會維護一個“復制積壓緩沖區”(Replication Backlog),這是一個固定大小的隊列,記錄了最近發送給小弟們的命令。
- 如果小弟只是短暫斷線(比如網絡抖動),重連時,小弟會告訴大哥自己斷線前的“進度”(復制偏移量 offset)。
- 大哥檢查這個進度,如果在自己的積壓緩沖區里還能找到小弟斷線后產生的所有新命令,那么大哥就只把這些增量的命令發給小弟 🩹??。小弟執行完就追上了。這樣就避免了代價很高的全量復制。
- 如果小弟斷線時間太長,或者積壓緩沖區太小,大哥找不到小弟需要的增量信息了,那就只能辛苦一點 😥,再來一次全量復制 🏋??♀?。
- Redis 2.8 版本之后引入了
四、 主從復制的優缺點是什么?
-
優點 (好處 👍):
- 高可用性基礎 🛡?:是Redis Sentinel(哨兵)和 Redis Cluster(集群)實現自動故障轉移和高可用的基石。
- 讀擴展性好 📈:可以通過增加Slave節點來線性地擴展系統的讀性能。
- 數據冗余 📑:提供了數據的熱備份。
-
缺點 (不足之處 👎):
- 寫能力無擴展 ????:所有寫操作都必須經過Master,Master的寫壓力無法通過增加Slave來分攤。單點寫性能瓶頸 🏺。
- 主節點故障問題 (若無哨兵等機制) ??:如果Master宕機,需要手動將一個Slave提升為新的Master,并且通知應用切換連接,這期間服務會中斷。需要配合哨兵或集群才能實現自動故障恢復。
- 數據一致性問題 ?:主從復制是異步的。命令從Master發送到Slave需要時間,Slave執行也需要時間。所以在極短的時間窗口內,Slave的數據可能稍微落后于Master(比如Master剛寫完一個值,還沒來得及傳給Slave,這時去Slave讀可能讀到舊值)。這叫最終一致性,對于要求強一致性的場景可能有影響。
- 全量復制開銷 🏋??♀?💸:首次連接或斷線重連時間過長導致的全量復制,會對Master造成CPU、內存和網絡帶寬的壓力,尤其是在數據量大的情況下。
五、 總結
Redis主從復制就是找一堆小弟(Slaves)跟著大哥(Master)學習。好處是大哥倒了有人頂上(高可用備份 💪),人多力量大能幫大哥分擔讀數據的活兒(讀寫分離/負載均衡 🤝🚀)。搭建起來就是在小弟的配置文件里寫上大哥的地址和密碼 ??🔑。同步原理是,新來的小弟先拿一份大哥的完整筆記(全量復制 📸??📖),之后大哥有新動作就實時通知小弟們跟著做(增量復制 🏃?♂?💨)。缺點是寫操作還得大哥一個人扛 ????,大哥真掛了得有人手動扶小弟上位(除非有哨兵幫忙 ??),而且小弟學東西總會慢半拍(數據有延遲 ?)。
)
獨熱編碼)


-audiopolicyservice介紹)
)

:ReentrantLock 源碼分析)




中,在LCD中顯示兩位數字問題)

)

)


