前言
本文隸屬于專欄《機器學習的一百個概念》,該專欄為筆者原創,引用請注明來源,不足和錯誤之處請在評論區幫忙指出,謝謝!
本專欄目錄結構和參考文獻請見[《機器學習的一百個概念》
ima 知識庫
知識庫廣場搜索:
| 知識庫 | 創建人 |
|---|---|
| 機器學習 | @Shockang |
| 機器學習數學基礎 | @Shockang |
| 深度學習 | @Shockang |
正文
引言 🌟
在機器學習的數據預處理階段,我們經常會遇到分類變量(categorical variables)的處理問題。這些變量可能是性別、職業、教育程度等非數值型數據。由于大多數機器學習算法只能處理數值型數據,如何有效地將這些分類變量轉換為數值型特征就成為了一個關鍵問題。獨熱編碼(One-Hot Encoding)作為最常用的解決方案之一,在這個過程中扮演著重要角色。
核心原理 🔍
基本概念
獨熱編碼的核心思想是將每個類別值轉換為一個包含0和1的向量,向量的長度等于類別的總數。在這個向量中,只有一個位置的值為1(表示當前類別),其余位置都為0。
編碼流程

數學表示
對于具有 k k k 個不同類別的特征,獨熱編碼會創建一個 k k k 維向量空間,每個類別映射到這個空間中的一個標準基向量。形式化表示如下:
設類別集合 C = { c 1 , c 2 , . . . , c k } C = \{c_1, c_2, ..., c_k\} C={c1?,c2?,...,ck?}
對于類別 c i c_i ci?, 其獨熱編碼為:
e i = [ 0 , 0 , . . . , 1 , . . . , 0 ] e_i = [0,0,...,1,...,0] ei?=[0,0,...,1,...,0]
其中第 i i i 個位置為1,其余位置為0
示例說明
考慮一個包含顏色特征的數據集:
原始數據: ['紅', '藍', '綠', '紅', '綠']獨熱編碼后:
紅: [1, 0, 0]
藍: [0, 1, 0]
綠: [0, 0, 1]
紅: [1, 0, 0]
綠: [0, 0, 1]
深入理解獨熱編碼 🧠
幾何解釋
從幾何角度看,獨熱編碼將類別映射到多維空間中的正交向量。這種表示方法確保了:
- 所有類別之間的歐氏距離相等
- 沒有引入人為的順序關系
- 在向量空間中形成了線性可分的表示
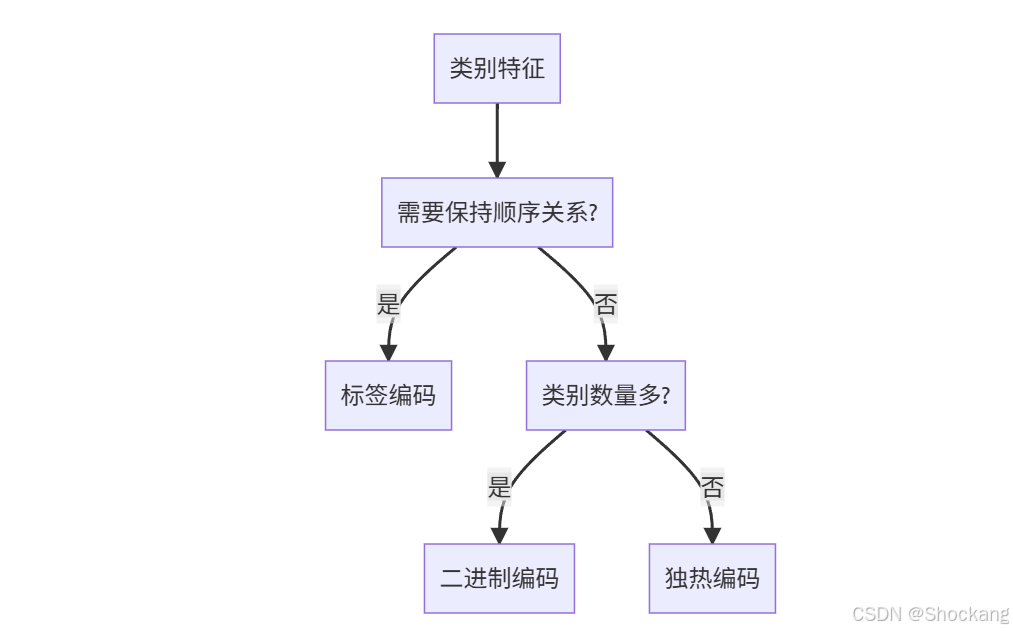
與其他編碼方式的對比
-
標簽編碼(Label Encoding)
- 直接將類別映射為整數
- 可能引入順序關系
- 計算效率高
- 適用于有序類別
-
二進制編碼(Binary Encoding)
- 使用二進制表示
- 維度增長為log2(n)
- 計算效率較高
- 可能失去可解釋性
-
獨熱編碼(One-Hot Encoding)
- 使用獨立維度表示每個類別
- 不引入順序關系
- 維度增長線性
- 保持可解釋性
優缺點分析 ??
優點 👍
-
無序性保證
- 消除了類別之間的人為順序關系
- 保持了特征的獨立性
- 適合無序類別變量
-
模型兼容性
- 與大多數機器學習算法兼容
- 特別適合線性模型和神經網絡
- 便于特征選擇和權重分析
-
可解釋性
- 結果直觀易懂
- 便于追蹤特征重要性
- 方便進行特征工程
缺點 👎
-
維度災難
- 類別數量大時維度劇增
- 產生稀疏矩陣
- 增加計算復雜度
-
內存消耗
- 需要更多存儲空間
- 可能導致內存溢出
- 處理大規模數據集困難
-
計算效率
- 訓練時間增加
- 預測速度降低
- 模型復雜度提升
應用場景 🎯
適用場景
-
低基數類別特征
- 性別(男/女)
- 教育程度(小學/中學/大學)
- 職業類別(少量分類)
-
模型類型
- 線性回歸
- 邏輯回歸
- 神經網絡
- 支持向量機
-
任務類型
- 分類問題
- 回歸問題
- 推薦系統
不適用場景
-
高基數特征
- 用戶ID
- 產品SKU
- 詳細地址
-
特定算法
- 決策樹
- 隨機森林
- XGBoost
實踐指南 💻
Python實現示例
- 使用Scikit-learn
from sklearn.preprocessing import OneHotEncoder
import numpy as np# 示例數據
data = np.array([['男'], ['女'], ['男'], ['女']])# 創建編碼器
encoder = OneHotEncoder(sparse=False)# 訓練并轉換數據
encoded_data = encoder.fit_transform(data)# 獲取特征名稱
feature_names = encoder.get_feature_names_out(['gender'])print("編碼結果:\n", encoded_data)
print("特征名稱:", feature_names)
- 使用Pandas
import pandas as pd# 創建示例數據框
df = pd.DataFrame({'color': ['紅', '藍', '綠', '紅'],'size': ['大', '中', '小', '中']
})# 對指定列進行獨熱編碼
df_encoded = pd.get_dummies(df, columns=['color', 'size'])print("編碼后的數據框:\n", df_encoded)
實際應用案例
- 客戶流失預測
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression# 假設數據準備
data = pd.DataFrame({'age': [25, 35, 45, 55],'gender': ['男', '女', '男', '女'],'occupation': ['工程師', '教師', '醫生', '工程師'],'churn': [0, 1, 1, 0]
})# 定義分類特征和數值特征
categorical_features = ['gender', 'occupation']
numeric_features = ['age']# 創建預處理流水線
preprocessor = ColumnTransformer(transformers=[('num', 'passthrough', numeric_features),('cat', OneHotEncoder(drop='first'), categorical_features)])# 創建完整流水線
pipeline = Pipeline([('preprocessor', preprocessor),('classifier', LogisticRegression())
])# 分割數據
X = data.drop('churn', axis=1)
y = data['churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 訓練模型
pipeline.fit(X_train, y_train)
高級技巧與優化 🚀
1. 稀疏矩陣優化
from scipy.sparse import csr_matrix# 使用稀疏矩陣存儲
encoder = OneHotEncoder(sparse=True)
sparse_encoded = encoder.fit_transform(data)# 轉換為CSR格式
csr_matrix = sparse_encoded.tocsr()
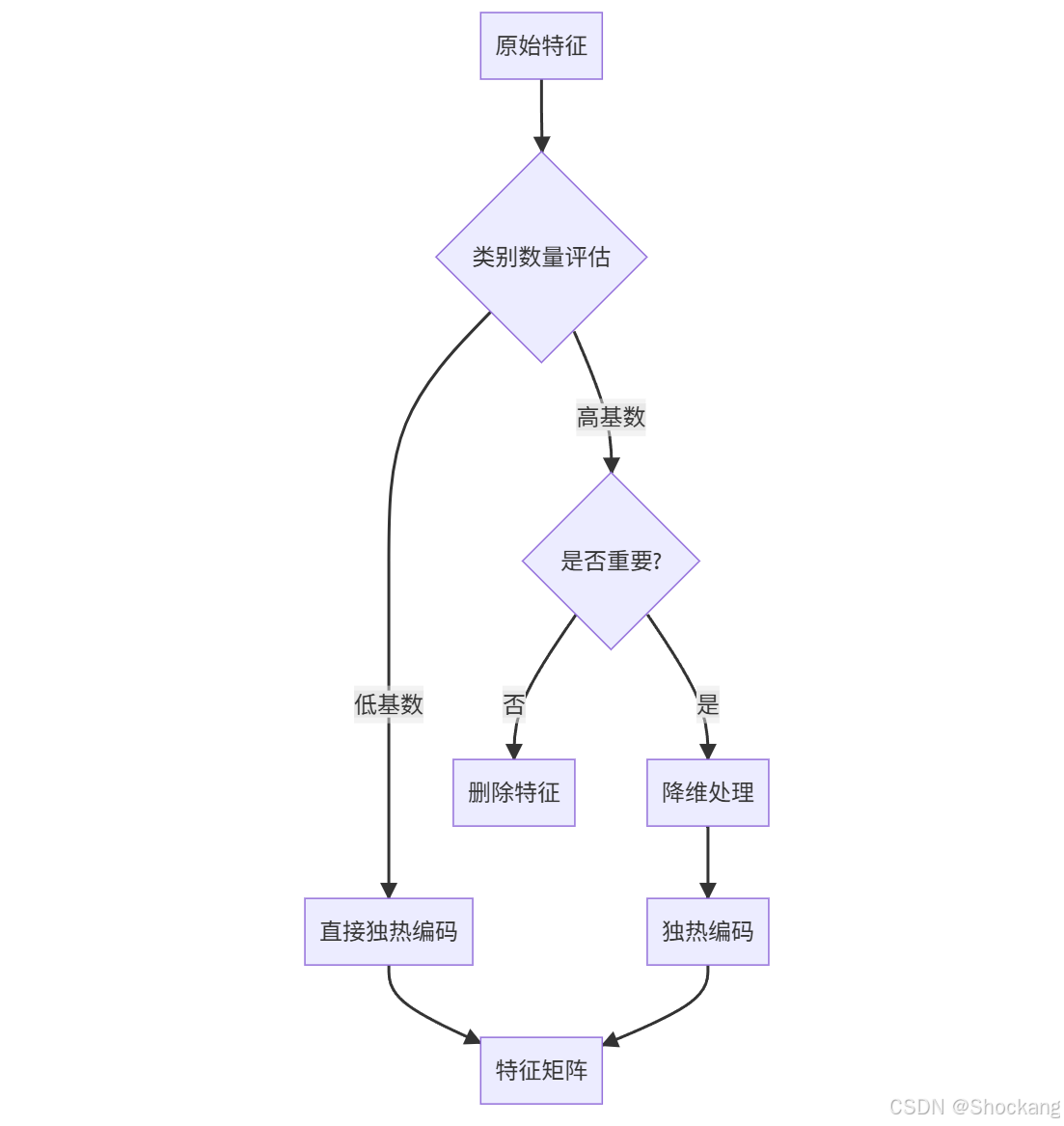
2. 特征選擇策略
3. 內存優化技巧
# 使用類別數據類型
df['category'] = df['category'].astype('category')# 指定dtypes減少內存使用
encoded_df = pd.get_dummies(df, columns=['category'], dtype=np.int8)
常見陷阱與注意事項 ??
-
虛擬變量陷阱
- 問題:完全共線性
- 解決:刪除一個類別或使用drop_first=True
-
類別處理
- 訓練集和測試集類別不一致
- 新類別出現的處理
- 缺失值的處理
-
維度控制
- 設置最大類別數量
- 合并低頻類別
- 使用降維技術
總結與展望 🎓
獨熱編碼作為處理分類變量的基礎方法,在機器學習中占據重要地位。它的簡單直觀和良好的可解釋性使其成為數據預處理的首選方法之一。然而,在實際應用中需要注意維度災難和計算效率等問題,并根據具體場景選擇合適的優化策略。
未來發展趨勢
-
高效編碼方法
- 哈希編碼
- 實體嵌入
- 目標編碼
-
自動化特征工程
- AutoML集成
- 智能編碼選擇
- 動態特征生成
-
混合編碼策略
- 多種編碼方法組合
- 上下文感知編碼
- 自適應編碼機制
通過深入理解和靈活運用獨熱編碼,我們可以更好地處理分類數據,為后續的機器學習模型訓練打下堅實基礎。在實踐中,需要根據具體問題和場景,選擇合適的編碼策略,并注意平衡表達能力和計算效率。


-audiopolicyservice介紹)
)

:ReentrantLock 源碼分析)




中,在LCD中顯示兩位數字問題)

)

)



)
)