Boost庫搜索引擎
項目開源地址
Github:https://github.com/H0308/BoostSearchingEngine
Gitee:https://gitee.com/EPSDA/BoostSearchingEngine
版本聲明
當前為最初版本,后續會根據其他內容對當前項目進行修改,具體見后續版本。
后續版本待更新
前置知識
了解搜索引擎
搜索引擎是一種信息檢索系統,它能夠自動從互聯網或特定數據集合中收集、分析和組織信息,并根據用戶的查詢需求快速定位和返回相關結果。搜索引擎通常由爬蟲、索引器和檢索系統三大核心組件構成,實現數據采集、處理和高效查詢
一般情況下,搜索引擎分為兩種:
- 站內搜索引擎:只在當前網站的內容之上進行搜索,實現難度較為容易
- 全網搜索引擎:在整個互聯網的內容之上進行搜索,實現難度大且維護成本高
本次只實現站內搜索,了解站內搜索基本原理再推測全網搜索的原理
分詞
分詞是將文本切分成有意義的基本單元(詞語或詞元)的過程,是搜索引擎和自然語言處理的基礎環節
一般分詞可以分為兩種模式:
- 全模式:切分出文本中所有可能成詞的單元,不考慮語義合理性,特點是同一個字可能出現在多個詞中,產生詞語重疊。這種模式適合模糊匹配的需求,但是會產生大量冗余結果
- 精確模式:只切分出最符合語義的詞語組合,特點是每個字只會出現在一個詞中,無重疊現象。這種模式下分詞結果符合人類語義理解,但是依賴高質量詞典或訓練語料
例如,將“我來到北京清華大學”這段話,通過分詞可以分為:
- 我/ 來到/ 北京/ 清華/ 清華大學/ 華大/ 大學(全模式)
- 我/ 來到/ 北京/ 清華大學(精確模式)
本次項目中會使用分詞技術查找出滿足條件的文檔
正排索引和倒排索引
正排索引(Forward Index)
正排索引是以文檔為中心的索引結構:
- 定義:以文檔ID為索引,文檔內容為值的數據結構
- 結構:文檔ID → 文檔內容/詞項集合
- 示例:
文檔1 → {標題:"Boost庫簡介", 內容:"Boost是一個C++庫集合..."} 文檔2 → {標題:"C\+\+編程", 內容:"C\+\+是一種面向對象編程語言..."} - 特點:
- 適合已知文檔ID時獲取文檔內容
- 類似于圖書館中按編號排列的書架
- 不利于根據關鍵詞查找文檔
- 構建簡單,存儲效率低
倒排索引(Inverted Index)
倒排索引是以詞項為中心的索引結構:
- 定義:以詞項為索引,包含該詞項的文檔列表為值
- 結構:詞項 → 文檔ID列表(可能包含位置、頻率等信息)
- 示例:
"Boost" → {文檔1: [位置1, 位置4], 文檔3: [位置2]} "C++" → {文檔1: [位置10], 文檔2: [位置1, 位置5]} - 特點:
- 適合根據關鍵詞快速查找相關文檔
- 類似于圖書館中的關鍵詞目錄
- 支持高效的全文檢索
- 構建復雜,查詢高效
兩者對比與應用
| 特性 | 正排索引 | 倒排索引 |
|---|---|---|
| 查詢方向 | 文檔→詞項 | 詞項→文檔 |
| 適用場景 | 文檔展示和獲取 | 關鍵詞搜索 |
| 構建復雜度 | 低 | 高 |
| 查詢效率 | 特定文檔高 | 關鍵詞搜索高 |
| 存儲需求 | 大 | 相對小 |
實際搜索引擎通常同時使用兩種索引:
- 用倒排索引快速找到匹配查詢的文檔集合
- 用正排索引獲取匹配文檔的完整內容以展示給用戶
倒排索引是現代搜索引擎的核心數據結構,使得快速全文檢索成為可能
項目準備
本次項目會使用到下面的內容:
- 后端:C++、cpp-httplib開源庫、Jieba分詞、Jsoncpp
- 前端:HTML、CSS和JavaScript
- 搜索內容:1.78版本的Boost庫中的
doc/html中的內容 - 日志:在Linux下實現的日志系統
- 操作系統:Ubuntu 24.04(Linux)
- 注意,這里的Boost庫不要使用最新的,最新的Boost庫中的HTML文件并不存在。另外,官網下載有的時候可能比較慢,可以使用本鏈接作為替代,這個鏈接是官方認可的資源站
- 本項目中會用到C++ 17的filesystem和string_view,如果不了解請先看C++ 17 filesystem和C++ 17 string_view
實現思路
根據常見搜素引擎的搜索結果可以看出,一條結果一般包含下面三個內容:
- 內容標題
- 描述內容或者部分主體內容
- 內容網址
但是直接從下載到的Boost庫資源中可以看到都是HTML文件,直接從該文件中獲取到上面三個內容就需要做最重要的一步:去除HTML文件中的標簽留下純文本內容,這便是本次實現的第一步:數據清洗
完成數據清洗之后就需要對構建搜索引擎做準備,首先需要完成的就是索引的構建,在前面提到了兩種索引方式:正排索引和倒排索引,本次實現中也會包含這兩種索引,根據兩種索引的特點完成索引的構建
構建完成索引后就需要根據用戶的輸入查找索引給用戶返回查找到的內容
最后,編寫前端代碼,完善服務端模塊,客戶端請求即可完成搜索
數據清洗
介紹
根據前面提到的一條搜索結果的構成可以分析出需要創建一個結構體包含這三個字段:
// 結果基本內容結構
struct ResultData
{std::string title; // 結構標題std::string body; // 結果內容或描述std::string url; // 網址
};
接著就是將一個正常HTML文件中的內容依次讀取到結構體對應的字段中,下面分三步走:
- 讀取到源文件目錄下所有的HTML文件,將其拼接為一個字符串存儲到vector中
- 根據上一步得到的vector中的數據,取出每一個文件中的三個字段:文檔標題、文檔內容和文檔在Boost官網的URL都存放到一個結構化對象中,再將該對象存儲到一個vector中
- 根據上一步結果的vector中每一個結構化數據讀取并寫入到一個文本文檔
raw,每一個結構化數據以一個\n分隔,而其中的成員以\3分隔
下面是本次項目的目錄結構:
- 根路徑- data- source- html // 所有的HTML文件位于這里- raw // 結構化數據存儲到這里// 頭文件和源文件文件與data目錄平級
接著,創建一個DataParse類,用于進行數據清洗:
class DataParse
{
private:};
讀取所有HTML路徑
本步驟的基本思路就是獲取到HTML路徑存儲到vector中,所以需要使用C++ 17中的filesystem庫,也可以使用Boost庫中提供的filesystem,二者在使用方式上都是一樣的。
首先定義出當前HTML文件所在路徑:
// HTML文件路徑
const fs::path g_datasource_path = "data/source/html";
接著,實現函數讀取到所有的HTML文件,如果不是HTML文件就不統計。因為當前HTML文件路徑中存在目錄,目錄中還存在更多的HTML文件,所以還需要用到遞歸遍歷目錄
基于上面的思路,首先需要添加一個vector成員sources和獲取HTML文件函數getHtmlSourceFiles:
class DataParse
{
public:// 獲取HTML文件路徑函數bool getHtmlSourceFiles(){}
private:std::vector<fs::path> sources;
};
讀取思路:從g_datasource_path開始遍歷,遇到后綴為HTML的文件就添加到sources中,如果遇到的是目錄就進入目錄繼續查找,實現代碼如下:
// HTML文件后綴
const std::string g_html_extension = ".html";// 獲取HTML文件路徑函數
bool getHtmlSourceFiles()
{// 如果路徑不存在,直接返回falseif (!fs::exists(g_datasource_path)){ls::LOG(ls::LogLevel::DEBUG) << "不存在指定路徑";return false;}// 遞歸目錄結束位置,相當于空指針nullptrfor (const auto &entry : fs::recursive_directory_iterator(g_datasource_path)){// 1. 不是普通文件就是目錄,繼續遍歷if (!fs::is_regular_file(entry))continue;// 2. 是普通文件,但是不是HTML文件,繼續遍歷if (entry.path().extension() != g_html_extension)continue;// 3. 是普通文件并且是HTML文件,插入結果sources_.push_back(std::move(entry.path()));}// 空結果返回falsereturn !sources_.empty();
}
讀取HTML文件內容到結構體字段中
基本邏輯介紹
本部分的思路就是根據HTML文件中的特點提取出對應的內容,因為HTML文件的內容都是由標簽和普通文本構成,而需要的內容就是文本,對應的行為就是去標簽。本次實現分四步:
- 讀取文件
- 截取標題
- 截取主體內容
- 構建URL
對于每一個HTML文件都需要走這四步,所以需要使用一個循環,通過一個函數readInfoFromHtml包裹主體邏輯:
// 讀取HTML文件內容
bool readInfoFromHtml()
{// 不存在路徑返回falseif (sources_.empty()){ls::LOG(ls::LogLevel::WARNING) << "文件路徑不存在";return false;}// 每一個文件都執行四步for (const auto &path : sources_){std::string out; // 存儲HTML文件內容struct pd::ResultData rd;// 1. 讀取文件if (!readHtmlFile(path, out)){ls::LOG(ls::LogLevel::WARNING) << "打開文件:" << path << "失敗";// 讀取當前文件失敗時繼續讀取后面的文件continue;}// 2. 獲取標題if (!getTitleFromHtml(out, &rd.title)){ls::LOG(ls::LogLevel::WARNING) << "獲取文件標題失敗";continue;}// 3. 讀取文件內容if (!getContentFromHtml(out, &rd.body)){ls::LOG(ls::LogLevel::WARNING) << "獲取文件內容失敗";continue;}// 4. 構建URLif (!constructHtmlUrl(path, &rd.url)){ls::LOG(ls::LogLevel::WARNING) << "構建文件URL失敗";continue;}}return true;
}
最后,四個邏輯全部正常執行完后需要將形成的結構體對象插入到一個vector對象results_,此處需要一個添加類成員results_:
class DataParse
{
public:// ...// 從HTML文件中讀取信息bool readInfoFromHtml(){// 不存在路徑返回falseif (sources_.empty()){ls::LOG(ls::LogLevel::WARNING) << "文件路徑不存在";return false;}for (const auto &path : sources){// ...results_.push_back(std::move(rd));}return true;}private:// ...std::vector<pd::ResultData> results_;
};
接著,根據上面的函數主體,依次實現其中的四個函數
實現讀取文件內容readHtmlFile
讀取HTML文件內容比較簡單,就是簡單的讀取文件內容操作,參考代碼如下:
// 讀取HTML文件
bool readHtmlFile(const fs::path &p, std::string &out)
{if (p.empty())return false;std::fstream f(p);if (!f.is_open())return false;// 讀取文件std::string buffer;while (getline(f, buffer))out += buffer;f.close();return true;
}
實現讀取文件標題getTitleFromHtml
因為一個標準的HTML文件中存在且只存在一個語義化標簽<title></title>,所以只需要在文件中找到這個標簽,并提取出其中的普通文本即可:
// 讀取標題
// &為輸入型參數,*為輸出型參數
bool getTitleFromHtml(std::string &in, std::string *title)
{if(in.empty())return false;// 找到開始標簽<title>auto start = in.find("<title>");if(start == std::string::npos)return false;// 找到終止標簽</title>auto end = in.find("</title>");if (end == std::string::npos || start > end)return false;// 截取出其中的內容,左閉右開*title = in.substr(start + std::string("<title>").size(), end - (start + std::string("<title>").size()));return true;
}
實現讀取文件內容getContentFromHtml
前面提到一個HTML文件只有兩種內容:標簽和普通文本,所以可以創建一個簡單的狀態機:如果當前的內容是標簽,狀態為Label,否則為OrdinaryContent,所以首先需要一個枚舉類型描述這兩個狀態:
// 內容狀態
enum ContentStatus
{Label, // 標簽狀態OrdinaryContent // 普通文本狀態
};
接下來考慮何時進行兩種狀態的切換,默認從文件開始,讀取到的內容就是<,所以默認狀態為Label,而讀取到>有三種情況:
- 單標簽的結尾
- 雙標簽開始標簽的結尾
- 雙標簽閉合標簽的結尾
而對于這三種情況,第三種情況和第一種情況可以歸類為一種情況,因為這兩種情況下都是作為當前標簽的最后一個>,所以現在就變成了兩種情況:
- 雙標簽起始標簽的結尾
> - 當前標簽的最后一個
>
根據這兩個情況以一個HTML內容為例進行分析:
<div>內容1</div>
<img />
內容2
<div>內容3</div>
以雙標簽為例,起始時,狀態為Label,讀取到第一個>時,得到一個條件:Label且>,假設此時可以修改狀態為OrdinaryContent,那么接下來讀取的就是文本內容,接著讀取第一個到<時,得到下一個條件:OrdinaryContent且<,假設此時可以修改狀態為Label,那么在讀取到最后一個>時,狀態為Label,即回到默認值Label繼續讀取后續內容
接著讀取到單標簽,狀態為Label,得到一個條件:Label且<,根據上面的邏輯,不進行狀態改變,接著讀取到第一個>,得到一個條件:Label且>,根據上面的思路此時修改狀態為OrdinaryContent,接下來讀取文本內容,當讀取到<div>內容3</div>的第一個<時,得到下一個條件:OrdinaryContent且<,根據上面的邏輯可以修改狀態為Label,即回到默認值Label繼續讀取后續內容
所以,綜上所述,狀態切換時機為:
- 當前狀態為
Label且遇到的是>,切換為OrdinaryContent - 當前狀態為
OrdinaryContent且遇到的是<,切換為Label
根據上面的邏輯,在函數中判斷出狀態為OrdinaryContent就可以執行插入內容,需要注意的是,后面需要使用\n作為分隔符,所以為了防止源文件內容中的\n干擾,需要將該\n替換為一個空格字符:
// 讀取HTML文件內容
bool getContentFromHtml(std::string &out, std::string *body)
{// 默認狀態為標簽ContentStatus cs = ContentStatus::Label;// 注意,因為文檔沒有中文,直接用char沒有問題for (char ch : out){switch (cs){// 讀取到右尖括號且狀態為標簽說明接下來為文本內容case ContentStatus::Label:if(ch == '>')cs = ContentStatus::OrdinaryContent; // 切換狀態break;case ContentStatus::OrdinaryContent:// 去除\nif (ch == '<')cs = ContentStatus::Label; // 切換狀態else{if (ch == '\n')*body += ' ';else *body += ch;}break;default:break;}}return true;
}
實現URL構建constructHtmlUrl
要構建一個有效的URL,就必須要將本地文件的路徑和官網的路徑進行對比,找出一個固定的值和可以改變的部分,例如以accumulators.html,在本地的路徑和官網URL路徑分別如下:
本地路徑:data/source/html/accumulators.html
官網路徑:https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html
從上面的路徑可以看出,只需要獲取到本地路徑中的最后一個文件內容/accumulators.html拼接到https://www.boost.org/doc/libs/1_78_0/doc/html后方即可
基于這個思路,實現下面的函數:
// 構建URL
bool constructHtmlUrl(const fs::path& p, std::string *url)
{// 在本地路徑中找到"/文件"std::string t_path = p.string();auto pos = t_path.rfind("/");if(pos == std::string::npos)return false;// 從/開始截取一直到結尾std::string source_path = t_path.substr(pos);*url = g_url_to_concat + source_path;return true;
}
寫入結構體對象數據到文本文件中
首先指定好文本文件的位置和分隔符:
// 文本文件路徑
const fs::path g_rawfile_path = "data/raw";
// 結構體字段間的分隔符
const std::string g_rd_sep = "\3";
// 不同HTML文件的分隔符
const std::string g_html_sep = "\n";
接著就是基本的文件寫入操作,但是為了保證不可打印字符可以正常顯示,建議使用二進制寫入的方式,函數實現如下:
// 將結構體字段寫入文本文件中
bool writeToRawFile()
{// 以二進制形式打開文件std::fstream f(g_rawfile_path);if (!f.is_open()){ls::LOG(ls::LogLevel::WARNING) << "文本文件不存在";return false;}// 寫入結構化數據for (auto &rd : results_){std::string temp;temp += rd.title;temp += g_rd_sep;temp += rd.body;temp += g_rd_sep;temp += rd.url;temp += g_html_sep;f.write(temp.c_str(), temp.size());}f.close();return true;
}
構建正排索引和構建倒排索引
基本思路和結構介紹
因為正排索引和倒排索引最后都會篩選出一組數據,這個數據肯定包括前面封裝的結構體ResultData;另外,因為不論是正排索引和倒排索引,最后都需要知道當前的文檔ID,所以此處需要創建一個結構體,包含這里提到的兩個字段:
struct SelectedDocInfo
{struct pd::ResultData rd;uint64_t id;
};
接著,為了創建一個類用于構建正排索引和倒排索引。在這個類中需要有兩個成員,一個成員存儲正排索引的結果,另外一個成員存儲倒排索引的結果
首先考慮正排索引,正排索引只需要根據文檔ID查詢到文檔的信息即可,而因為數組可以通過下標訪問元素,這就可以保證文檔ID與數組下標進行對應,將來查詢時直接使用文檔ID即可獲取到指定的文章信息,所以存儲正排索引的結構可以是一個動態數組,而每一個元素就是SelectedDocInfo結構體對象
接著是倒排索引,倒排索引是根據關鍵字進行構建的結果,而一個關鍵字可能對應著多個文章信息,所以這里首先需要一個有關當前關鍵字和相關文章的對應關系,也就是說,并不是直接通過關鍵字找出某一個文章信息,而是通過關鍵字對應的相關屬性查詢到具體的文章,這個屬性包含文檔ID、當前關鍵字和權重信息,通過權重信息篩選出結果后再根據其中的文檔ID通過正排索引查詢出對應的文章。根據這個思路,首先就需要一個用于保存關鍵字相關屬性的結構:
// 倒排索引時當前關鍵字的信息
struct BackwardIndexElement
{uint64_t id; // 文檔IDstd::string word; // 關鍵字int weight; // 權重信息
};
接著,因為在查詢時肯定需要用到獲取方法,可能是獲取正排索引,也可能是獲取倒排索引,所以在類中需要提供兩個函數用于獲取當前正排索引的SelectedDocInfo對象和倒排索引中存儲BackwardIndexElement對象數組,為了避免結構體對象的頻繁拷貝,考慮返回對應節點的指針
考慮如何獲取,對于正排索引來說,在前面介紹時已經提到是通過文檔ID進行查詢,所以獲取時需要的參數就是文檔ID;對于倒排索引來說,因為一個關鍵字可能對應著多個關鍵字信息節點BackwardIndexElement,對應的就需要用一個數組存儲所有的信息節點,所以就需要建立一個哈希表用于關鍵字和關鍵字信息節點數組之間的映射關系,對應的獲取時通過關鍵字獲取到的就是關鍵字信息節點數組
=== “getForwardIndexDocInfo函數”
SelectedDocInfo *getForwardIndexDocInfo()
{
}
=== “getBackwardIndexElement函數”
// 獲取倒排索引結果
std::vector<BackwardIndexElement> *getBackwardIndexElement()
{
}
接著,既然是建立索引,那么少不了的就是構建索引的函數。這個函數并不是只進行正排索引或者倒排索引,而是二者都進行,即當前函數包含著正排索引和倒排索引的主邏輯:
// 構建索引
bool buildIndex()
{}
所以,當前用于構建索引的類的結構如下:
class SearchIndex
{
public:// 獲取正排索引結果SelectedDocInfo *getForwardIndexDocInfo(){}// 獲取倒排索引結果std::vector<BackwardIndexElement> *getBackwardIndexElement(){}// 構建索引bool buildIndex(){}private:std::vector<SelectedDocInfo> forward_index_; // 正排索引結果std::unordered_map<std::string, std::vector<BackwardIndexElement>> backward_index_; // 倒排索引結果
};
實現構建索引函數
既然要構建索引,那么少不了的就是獲取到用于構建索引的內容,而在上一步:數據清洗中已經將清洗后的數據存儲到了一個文本文件中,所以當前構建索引函數只需要從該文件中讀取數據即可。讀取數據時需要根據寫入時的格式和方式進行讀取,因為當時是使用二進制的方式進行寫入,那么讀取時就需要使用二進制的方式讀取;另外,在構建內容時,每一個ResultData對象之間都是以\n進行的分隔,所以在讀取一個ResultData對象數據時就可以直接使用getline函數(該函數不會讀取到用于分隔的\n)
接著,根據讀取到的數據進行正排索引的構建和倒排索引的構建。這里的設計就涉及到前面提到的思路。首先,構建正排索引需要根據當前讀取到的信息構建,所以參數需要傳遞一個當前讀取到的信息,另外當前函數考慮返回一個SelectedDocInfo對象地址,只要這個對象地址不為空,就說明是成功構建一個了SelectedDocInfo對象,否則就不是。接著就是構建倒排索引,根據前面的思路,構建倒排索引需要使用到SelectedDocInfo對象中的文檔ID值,所以構建倒排索引的函數需要傳遞一個SelectedDocInfo對象,而這個函數可以考慮返回一個布爾值
基于上面的思路,所以構建索引函數的基本邏輯如下:
// 構建索引
bool buildIndex()
{// 以二進制方式讀取文本文件中的內容std::fstream in(pd::g_rawfile_path, std::ios::in | std::ios::binary);if(!in.is_open()){ls::LOG(ls::LogLevel::WARNING) << "打開文本文件失敗";return false;}// 讀取每一個ResultData對象std::string line;while(getline(in, line)){// 構建正排索引struct SelectedDocInfo* s = buildForwardIndex(line);if(s == nullptr){ls::LOG(ls::LogLevel::WARNING) << "構建正排索引失敗";continue;}// 構建倒排索引bool flag = buildBackwardIndex(*s);if(!flag){ls::LOG(ls::LogLevel::WARNING) << "構建倒排索引失敗";continue;}}return true;
}
接下來就是實現構建正排索引函數和構建倒排索引函數
實現構建正排索引buildForwardIndex
構建正排索引函數思路就是根據當前文章的內容填入SelectedDocInfo對象中對應的信息
思路雖然比較簡短,但是其中的實現方式其實并不簡短。當前buildForwardIndex函數接收到了一行的數據,這個數據不包括結尾的\n,所以在當前函數中要考慮的就是讀取到一行數據中以\3分隔的三個字段,這里涉及到了對整體數據按照某一種分隔符進行切割,按照之前的思路就是使用strtok函數,但是這個函數使用起來并不方便,所以本次可以考慮兩個思路:
- 使用Boost庫中的
split函數 - 使用string_view實現自定義的
split函數
使用Boost庫中的split函數:
首先介紹第一種思路,在Boost庫中,提供了字符串切割的函數split,這個函數的原型如下:
template<typename SequenceSequenceT, typename RangeT, typename PredicateT>
SequenceSequenceT & split(SequenceSequenceT &, RangeT &&, PredicateT, token_compress_mode_type = token_compress_off);
這個函數的第一個參數是輸出型參數,表示切割后的每一段內容的存儲位置,第二個參數表示需要切割的內容,第三個參數表示分隔符,第四個參數表示是否需要開啟壓縮模式,默認為關閉狀態,使用示例如下:
#include <boost/algorithm/string.hpp>int main()
{std::string str = "aaaaa\3bbbbb\3ccccc"; // 原始數據std::vector<std::string> out; // 存儲切割后的數據// 以\3作為切割符切割,默認不壓縮boost::split(out, str, boost::is_any_of("\3"));std::for_each(out.begin(), out.end(), [&out](std::string s){std::cout << s << std::endl;});return 0;
}輸出結果:
aaaaa
bbbbb
ccccc
上面使用默認的不壓縮,所謂的壓縮,就是對于連續出現多次\3時將其壓縮為一個\3處理:
#include <boost/algorithm/string.hpp>int main()
{std::string str = "aaaaa\3\3\3\3\3bbbbb\3ccccc"; // 原始數據std::vector<std::string> out; // 存儲切割后的數據// 以\3作為切割符切割,壓縮boost::split(out, str, boost::is_any_of("\3"), boost::token_compress_on);std::for_each(out.begin(), out.end(), [&out](std::string s){std::cout << s << std::endl;});return 0;
}輸出結果:
aaaaa
bbbbb
ccccc
如果上面的代碼中不進行壓縮,那么默認結果如下:
int main()
{// ...boost::split(out, str, boost::is_any_of("\3"));// ...
}輸出結果:
aaaaabbbbb
ccccc
基于上面的使用示例,接下來就是根據\3對讀取到的一行內容進行分隔,將分割后的內容存儲到一個vector中便于接下來創建ResultData對象可以快速填充字段,為了便于可維護性,將切割邏輯單獨作為一個函數抽離:
=== “切割字符串函數”
// boost中的split
void split(std::vector<std::string>& out, std::string& line, std::string sep)
{boost::split(out, line, boost::is_any_of("\3"), boost::token_compress_on);
}
=== “構建正排索引函數”
SelectedDocInfo *buildForwardIndex(std::string &line)
{std::vector<std::string> out;split(out, line, pd::g_rd_sep);if (out.size() != 3){ls::LOG(ls::LogLevel::WARNING) << "無法讀取元信息";return nullptr;}SelectedDocInfo sd;// 注意填充順序sd.rd.title = out[0];sd.rd.body = out[1];sd.rd.url = out[2];// 先設置id時直接使用正排索引數組長度sd.id = forward_index_.size();// 再添加SelectedDocInfo對象forward_index_.push_back(std::move(sd));return &forward_index_.back();
}
使用string_view實現自定義的split函數:
接下來思考第二種方式,使用string_view自主實現一個split函數,實現的基本思路與直接使用string是基本一致的,但是如果直接使用string會出現各種拷貝的情況。而最后在插入到結果集中時需要注意重新轉換為string對象,因為參數傳遞的line屬于局部對象,離開了while代碼塊就會銷毀,這就直接導致了vector中存儲的數據丟失導致的野指針問題,所以vector需要存儲string對象,這里是無法避免的。整體的實現方式如下:
// 使用string_view自主實現split
void split(std::vector<std::string> &out, std::string_view line, std::string_view sep)
{if (line.empty())return;size_t pos = 0;size_t found;while ((found = line.find(sep, pos)) != std::string_view::npos){// 添加當前位置到分隔符之間的子字符串out.push_back(std::string(line.substr(pos, found - pos)));// 更新位置到分隔符之后pos = found + sep.length();}// 添加最后一個分隔符之后的子字符串if (pos < line.length())out.push_back(std::string(line.substr(pos)));
}
構建正排索引的主邏輯代碼不需要改變,因為string_view對象可以通過string對象構建
實現構建倒排索引buildBackwardIndex
為了構建倒排索引首先需要知道本次構建倒排索引的思路:
倒排索引本質就是根據已有的關鍵字篩選出出現該關鍵字的文章
基于上面這個本質,可以推出兩種情況:
- 一個關鍵字可能對應著多個文檔
- 一個文檔內可能含有多個關鍵字
很明顯,上面構成的是一種“多對多”的關系
首先從一方面考慮:一個文檔中含有多個關鍵字。根據前面的結構SelectDocInfo中的內容,其中的ResultData結構體中存在著title和content字段,這兩個字段都有可能出現某一個關鍵字,所以二者都需要考慮。再看前面的BackwardIndexElement結構,這個結構中含有關鍵字、文檔ID和文章權重三個字段,既然是一個文檔中含有多個關鍵字,那么對于同一篇文檔,多個關鍵字BackwardIndexElement對象中的文檔ID一定是相同的
接下來考慮關鍵字的問題,關鍵字既可能出現在title中,也可能出現在content中,那么必然需要對title和content兩部分進行分詞解析提取出其中的關鍵字,這里可以為每一個關鍵字建立一個結構體WordCount,這個結構體中存儲著當前關鍵字在當前文檔中的標題和內容部分出現的次數,所以有兩個變量title_cnt和body_cnt,而為了建立關鍵字和對應的關鍵字出現次數結構體之間的映射關系,就需要用到一個unordered_map<string, WordCount>,分別統計title和content中關鍵字出現的次數更新對應字段的值即可統計出當前關鍵字在當前文檔中出現的次數
最后,在BackwardIndexElement中還有一個字段:權重,本質上這里需要涉及到相關性分析,但是相關性分析是一套很復雜的過程,所以本次為了簡便,考慮一種思路:關鍵字出現在標題的權重值要大于關鍵字出現在內容的權重值,所以可以設計權重的計算公式為 t i t l e × 10 + b o d y title \times 10 + body title×10+body,這樣就完成了一篇文檔內所有關鍵字的統計
最后,既然是“多對多”的關系,那么除了考慮一個文檔內含有多個關鍵字以外,還需要考慮一個關鍵字對應多個文檔的情況。實際上,因為每一個文檔都需要統計當前文檔中所有的關鍵字,而一旦所有的文檔全部統計完畢就相當于處理了一個關鍵字對應多個文檔的情況
基于上面的思路,首先需要一個結構體WordCount表示一個關鍵字分別在標題和文章中出現的頻率:
// 頻率結構
struct WordCount
{int title_cnt;int body_cnt;
};
接著,還需要一個哈希表用于表示這個關鍵字和對應詞頻結構對象之間的映射關系,所以需要在索引類中添加一個哈希表成員:
std::unordered_map<std::string, WordCount> word_cnt_; // 詞頻統計
根據上面的思路實現buildBackwardIndex函數,但是實現之前首先需要提取出標題和內容中的關鍵字,這里就需要用到分詞工具Jieba:
根據Jieba的操作指示,首先需要將遠程的Jieba克隆到本地,具體存放位置自定義:
git clone https://github.com/yanyiwu/cppjieba.git
接著,為了能在項目中使用,考慮在當前路徑下建立軟鏈接指向cppjieba文件夾中的include目錄,例如:
ln -s /home/epsda/dependencies/cppjieba/include include
創建完成后就可以看到下面的信息:
lrwxrwxrwx 1 epsda epsda 41 Apr 3 09:28 include -> /home/epsda/dependencies/cppjieba/include/
在接下來的項目中使用就可以通過下面的方式引入:
#include "include/cppjieba/Jieba.hpp"
但是,如果執行上面的步驟就會出現丟失文件的問題,本質是因為Jieba.hpp中的QuerySegment.hpp引入了limonp/Logging.hpp,這個文件在新版的Jieba庫中并不是直接存儲在Jieba倉庫中,而是單獨在limonp倉庫中,所以接下來需要克隆limonp倉庫:
git clone https://github.com/yanyiwu/limonp.git
克隆完成后可以在該倉庫中的include文件夾下找到limonp文件夾,這個文件夾中就包含了Logging.hpp文件,所以只需要將include/limonp拷貝到cppjieba目錄中的include目錄中即可,最后的目錄結構如下:
/home/epsda/dependencies/cppjieba/include/cppjieba
├── DictTrie.hpp
├── FullSegment.hpp
├── HMMModel.hpp
├── HMMSegment.hpp
├── Jieba.hpp
├── KeywordExtractor.hpp
├── MPSegment.hpp
├── MixSegment.hpp
├── PosTagger.hpp
├── PreFilter.hpp
├── QuerySegment.hpp
├── SegmentBase.hpp
├── SegmentTagged.hpp
├── TextRankExtractor.hpp
├── Trie.hpp
├── Unicode.hpp
└── limonp // limonp文件├── ArgvContext.hpp├── Closure.hpp├── Colors.hpp├── Condition.hpp├── Config.hpp├── ForcePublic.hpp├── LocalVector.hpp├── Logging.hpp├── NonCopyable.hpp├── StdExtension.hpp└── StringUtil.hpp
接著,執行Jieba的測試代碼:
#include <iostream>
#include "include/cppjieba/Jieba.hpp"using namespace std;int main(int argc, char **argv)
{cppjieba::Jieba jieba;vector<string> words;vector<cppjieba::Word> jiebawords;string s;string result;s = "他來到了網易杭研大廈";cout << s << endl;cout << "[demo] Cut With HMM" << endl;jieba.Cut(s, words, true);cout << limonp::Join(words.begin(), words.end(), "/") << endl;cout << "[demo] Cut Without HMM " << endl;jieba.Cut(s, words, false);cout << limonp::Join(words.begin(), words.end(), "/") << endl;s = "我來到北京清華大學";cout << s << endl;cout << "[demo] CutAll" << endl;jieba.CutAll(s, words);cout << limonp::Join(words.begin(), words.end(), "/") << endl;s = "小明碩士畢業于中國科學院計算所,后在日本京都大學深造";cout << s << endl;cout << "[demo] CutForSearch" << endl;jieba.CutForSearch(s, words);cout << limonp::Join(words.begin(), words.end(), "/") << endl;return EXIT_SUCCESS;
}
上面的代碼相對于原始的
demo.cpp中刪除了部分不需要的代碼,不影響整體代碼運行
這個代碼在demo.cpp文件中,demo.cpp可以在此鏈接處可以找到,但是需要注意,如果直接使用這個文件會出現找不到字典文件的問題,因為該文件中默認初始化Jieba類時使用的是下面的方式:
// ...
int main(int argc, char** argv) {cppjieba::Jieba jieba;// ...
}
但是,在Jieba.hpp中可以看到初始化時默認字典值都是空:
// ...
class Jieba {public:Jieba(const string& dict_path = "", const string& model_path = "",const string& user_dict_path = "", const string& idf_path = "", const string& stop_word_path = "") : dict_trie_(getPath(dict_path, "jieba.dict.utf8"), getPath(user_dict_path, "user.dict.utf8")),model_(getPath(model_path, "hmm_model.utf8")),mp_seg_(&dict_trie_),hmm_seg_(&model_),mix_seg_(&dict_trie_, &model_),full_seg_(&dict_trie_),query_seg_(&dict_trie_, &model_),extractor(&dict_trie_, &model_, getPath(idf_path, "idf.utf8"), getPath(stop_word_path, "stop_words.utf8")) {}// ...static string getPath(const string& path, const string& default_file) {if (path.empty()) {string current_dir = getCurrentDirectory();string parent_dir = current_dir.substr(0, current_dir.find_last_of("/\\"));string grandparent_dir = parent_dir.substr(0, parent_dir.find_last_of("/\\"));return pathJoin(pathJoin(grandparent_dir, "dict"), default_file);}return path;}
}
根據getPath函數的邏輯:如果用戶指定的字典文件路徑為空,那么就會讀取默認路徑的值例如如果dict_path為空,jieba.dict.utf8就會作為默認文件路徑,在函數內部會調用pathJoin將祖父路徑、dict目錄和當前jieba.dict.utf8拼接形成一個路徑。但是當前因為是軟鏈接,所以實際三個路徑獲取的結果都是include/cppjieba,此時根據Jieba.hpp的文件位置:include/cppjieba,如果要使用原始文件就需要將cppjieba/dict目錄拷貝到cppjieba/include目錄中。對于這種情況,使用的目錄結構如下:
/home/epsda/dependencies/cppjieba/include
├── cppjieba // Jieba.hpp所在的路徑
│ ├── DictTrie.hpp
│ ├── FullSegment.hpp
│ ├── HMMModel.hpp
│ ├── HMMSegment.hpp
│ ├── Jieba.hpp
│ ├── KeywordExtractor.hpp
│ ├── MPSegment.hpp
│ ├── MixSegment.hpp
│ ├── PosTagger.hpp
│ ├── PreFilter.hpp
│ ├── QuerySegment.hpp
│ ├── SegmentBase.hpp
│ ├── SegmentTagged.hpp
│ ├── TextRankExtractor.hpp
│ ├── Trie.hpp
│ ├── Unicode.hpp
│ └── limonp
│ ├── ArgvContext.hpp
│ ├── Closure.hpp
│ ├── Colors.hpp
│ ├── Condition.hpp
│ ├── Config.hpp
│ ├── ForcePublic.hpp
│ ├── LocalVector.hpp
│ ├── Logging.hpp
│ ├── NonCopyable.hpp
│ ├── StdExtension.hpp
│ └── StringUtil.hpp
└── dict // 與cppjieba目錄同級的dict目錄├── README.md├── hmm_model.utf8├── idf.utf8├── jieba.dict.utf8├── pos_dict│ ├── char_state_tab.utf8│ ├── prob_emit.utf8│ ├── prob_start.utf8│ └── prob_trans.utf8├── stop_words.utf8└── user.dict.utf8
另外還有一種方法,在當前項目路徑中創建一個軟鏈接指向cppjieba/dict目錄,例如:
ln -s /home/epsda/dependencies/cppjieba/dict dict
再在代碼中創建Jieba對象時指定字典文件:
int main(int argc, char **argv)
{cppjieba::Jieba jieba("./dict/jieba.dict.utf8","./dict/hmm_model.utf8","./dict/user.dict.utf8","./dict/idf.utf8","./dict/stop_words.utf8");// ...
}
本次考慮使用第一種方案,運行demo.cpp代碼就可以看到下面的結果:
他來到了網易杭研大廈
[demo] Cut With HMM
他/來到/了/網易/杭研/大廈
[demo] Cut Without HMM
他/來到/了/網易/杭/研/大廈
我來到北京清華大學
[demo] CutAll
我/來到/北京/清華/清華大學/華大/大學
小明碩士畢業于中國科學院計算所,后在日本京都大學深造
[demo] CutForSearch
小明/碩士/畢業/于/中國/科學/學院/科學院/中國科學院/計算/計算所/,/后/在/日本/京都/大學/日本京都大學/深造
在本次使用中,只需要用到其中的CutForSearch方法,其定義如下:
void CutForSearch(const string& sentence, vector<string>& words, bool hmm = true) const;
雖然函數中有三個參數,但是本次只需要考慮前兩個參數即可。第一個參數表示待切割的內容,第二個參數表示切割后的結果存放位置
基于上面的介紹,現在繼續完成buildBackwardIndex的邏輯。因為需要統計切分后的詞在標題和內容中的頻次,所以需要對標題和內容分別進行切分,這里分兩步走:
- 切分標題統計切分后的詞出現的次數
- 切分內容統計切分后的詞出現的次數
統計完畢后,接下來需要根據關鍵字構建對應的倒排索引文章信息節點,這一步只需要創建倒排索引文章信息節點再填入對應的信息即可完成構建
所以,構建倒排索引buildBackwardIndex函數基本邏輯如下:
class SearchIndex
{
private:static const int title_weight_per = 10;static const int body_weight_per = 1;
public:// ...// 構建倒排索引bool buildBackwardIndex(SelectedDocInfo &sd){// 統計標題中關鍵字出現的次數cppjieba::Jieba jieba;std::vector<std::string> title_words;jieba.CutForSearch(sd.rd.title, title_words);for (auto &tw : title_words)word_cnt_[tw].title_cnt++;// 統計內容中關鍵字出現的次數std::vector<std::string> body_words;jieba.CutForSearch(sd.rd.body, body_words);for (auto &bw : body_words)word_cnt_[bw].body_cnt++;// 遍歷關鍵字哈希表獲取關鍵字填充對應的倒排索引節點for (auto &word : word_cnt_){BackwardIndexElement b;b.id = sd.id;b.word = word.first;// 權重統計按照公式計算b.weight = word.second.title_cnt * title_weight_per + word.second.body_cnt * body_weight_per;backward_index_[b.word].push_back(std::move(b));}return true;}// ...
private:// ...std::unordered_map<std::string, std::vector<BackwardIndexElement>> backward_index_; // 倒排索引結果std::unordered_map<std::string, WordCount> word_cnt_; // 詞頻統計
};
實現搜索引擎模塊
基本實現
搜索的本質就是根據搜索關鍵字在已有的關鍵字中查詢出需要的文章,所以這里首先建立一個類用于表示搜索服務:
class SearchEngine
{};
既然是搜索引擎,那么在初始化搜索引擎對象時就需要先構建需要用到的索引,所以考慮搜索引擎的構造函數中完成對索引對象的初始化。所以在搜索引擎類中需要有一個SearchIndex類對象作為成員,接著在SearchEngine的構造函數中初始化這個成員:
class SearchEngine
{
public:SearchEngine(){// 構建索引search_index_.buildIndex();}private:si::SearchIndex search_index_;
};
上面這種創建SearchIndex類成員的方式可以達到需要的效果,但是如果SearchEngine類對象被多次創建就會出現多次構建索引的情況,所以為了避免這個問題,考慮將SearchIndex類設置為單例模式:
class SearchIndex
{
private:// ...// 私有構造函數SearchIndex(){}// 禁用拷貝和賦值SearchIndex(const SearchIndex& si) = delete;SearchIndex& operator=(SearchIndex& si) = delete;SearchIndex(SearchIndex&& si) = delete;static SearchIndex* si;
public:// 獲取單例對象static SearchIndex* getSearchIndexInstance(){if(!si){// 加鎖mtx.lock();if(!si)si = new SearchIndex();mtx.unlock();}return si;}// ...
private:// ...static std::mutex mtx;
};SearchIndex* SearchIndex::si = nullptr;
std::mutex SearchIndex::mtx;
接著,在SearchEngine對象中通過調用getSearchIndexInstance函數獲取SearchIndex類對象:
class SearchEngine
{
public:SearchEngine(): search_index_(si::SearchIndex::getSearchIndexInstance()){// 構建索引search_index_->buildIndex();}~SearchEngine(){}private:si::SearchIndex* search_index_;
};
完成索引的構建之后就需要根據用戶輸入的關鍵字查詢出對應的結果,這里可以通過一個search函數包裹整體邏輯,這個函數的第一個參數就是用戶輸入的關鍵字,第二個參數是查詢到的結果。因為后面需要進行網絡傳輸,所以少不了的就是對查詢的結果進行協議化,為了保證客戶端也可以正常識別當前服務端傳送的數據,這里考慮使用JSON字符串作為第二個參數,即:
// 根據關鍵字進行搜索
void search(std::string& keyword, std::string& json_string)
{}
接下來考慮search函數中的邏輯,因為用戶輸入的詞可能并不是文章中一定存在的某一個關鍵詞,所以此處還需要對用戶輸入的內容進行分詞。對搜索關鍵字進行分詞之后就是在哈希表中查詢出相應的結果,這里可以需要考慮將內容存儲到一個結構中。這里需要考慮兩個問題:
- 前面建立了兩個哈希表,具體需要查詢哪一個哈希表
- 如何處理分詞后的結果
對于第一個問題,兩張哈希表分別為unordered_map<string, WordCount>用于統計關鍵字和對應權重的映射關系以及unordered_map<string, vector<BackwardIndexElement>>用于統計關鍵字和所有倒排結果的映射關系,考慮到后面需要根據BackwardIndexElement中的文檔ID查詢正排索引,所以需要查詢的哈希表實際上就是unordered_map<string, vector<BackwardIndexElement>>
對于第二個問題,在unordered_map<string, vector<BackwardIndexElement>>中通過關鍵字查詢得到的結果就是出現指定關鍵字對應的關鍵字信息節點數組,所以接下來為了在下一步可以對結果進行排序,考慮將查詢出的結果存儲到一個數組中。注意這個數組中存儲的不是vector<BackwardIndexElement>,而是其中的BackwardIndexElement對象,因為獲取到所有的結果后實際上就已經不需要再考慮關鍵字的問題了,接下來考慮的只是權重優先級問題
明確了上面提到的兩個問題之后,思考search函數的基本邏輯:首先對用戶輸入的關鍵詞進行切分。接著,根據切分后的每個詞查找倒排索引得到其中存儲倒排索引文章信息節點的數組vector<BackwardIndexElement>,將這個數組中的每一個BackwardIndexElement對象存儲到一個單獨的結構中便于接下來的排序,本次排序的基本思路就是按照倒排信息節點中的權重字段進行降序排序(即權重高的排在前面)
基于上面的思路,首先需要實現SearchIndex類中的getBackwardIndexElement函數:
// 獲取倒排索引結果
std::vector<BackwardIndexElement> *getBackwardIndexElement(const std::string &keyword)
{auto pos = backward_index_.find(keyword);if(pos == backward_index_.end()){ls::LOG(ls::LogLevel::WARNING) << "不存在對應的關鍵字";return nullptr;}return &backward_index_[keyword];
}
接著實現search函數中的邏輯:
// 根據關鍵字進行搜索
void search(std::string &keyword, std::string &json_string)
{// 對用戶輸入的關鍵字進行切分cppjieba::Jieba jieba;std::vector<std::string> keywords;jieba.CutForSearch(keyword, keywords);// 查詢哈希表得到結果std::vector<si::BackwardIndexElement> results;for (auto &word : keywords){// 查倒排索引std::vector<si::BackwardIndexElement>* ret_ptr = search_index_->getBackwardIndexElement(word);if(!ret_ptr)continue;// 插入結果results.insert(results.end(), ret_ptr->begin(), ret_ptr->end());}// 按照權重排序std::stable_sort(results.begin(), results.end(), [](si::BackwardIndexElement &b1, si::BackwardIndexElement &b2){ return b1.weight > b2.weight; });
}
雖然上面的過程能實現基本的目標,但是還存在一個問題:如果存在多個關鍵字對應著同樣的文章,例如關鍵字1和關鍵字2都對應著文檔1和文檔2。這種情況下執行上面的邏輯就會出現文檔1和文檔2的結果被插入兩次導致最后的結果存在相同的內容。為了解決這個問題,可以考慮下面的思路:
因為問一個BackwardIndexElement節點都有對應的文檔ID,可以根據文檔ID是否重復出現判斷是否出現了重復插入,所以這里可以建立一張哈希表,這個哈希表的第二個元素類型就是BackwardIndexElement,第一個元素類型就是文檔ID:
std::unordered_map<uint64_t, si::BackwardIndexElement> select_map;
接著,在每一次遍歷獲取倒排索引文章信息節點數組后遍歷該數組,判斷其中的文章是否已經在select_map出現,沒有出現就插入,否則不插入。當遍歷完用戶輸入的所有可能的關鍵詞后將select_map再插入到results即可:
// 根據關鍵字進行搜索
void search(std::string &keyword, std::string &json_string)
{// ...for (auto &word : keywords){// ...for(auto &bi : *ret_ptr){// 如果文檔ID已經存在,說明已經存在,否則不存在if(select_map.find(bi.id) == select_map.end())select_map[bi.id] = bi;}}// 遍歷select_map存儲結果for(auto &pair : select_map)results.push_back(std::move(pair.second));// ...
}
但是,僅僅有上面的邏輯還不足以完成去重的行為,因為當前只考慮了多個關鍵字對應同一篇文檔的情況,也可能存在文檔內部存在多個關鍵字的情況,對于第二種情況上面的邏輯就只是簡單的獲取賦值而已,并沒有實現去重
解決第二種情況的方式很簡單,就是將同一個文檔中多個關鍵字進行累積,但是基于已有的BackwardIndexElement無法做到這一點,因為BackwardIndexElement中只能保存一個關鍵字,所以考慮創建一個新的節點結構SearchIndexElement,該結構與BackwardIndexElement主要不同點就是std::string word變為std::vector<std::string> words:
// 搜索節點結構
struct SearchIndexElement
{uint64_t id;std::vector<std::string> words;int weight;
};
另外,為了后續計算安全,考慮提供一個構造函數對成員進行初始化:
SearchIndexElement():id(0), weight(0)
{}
接著更改用于去重的哈希表結構:
// std::unordered_map<uint64_t, si::BackwardIndexElement> select_map;
std::unordered_map<uint64_t, SearchIndexElement> select_map;
基于上面的哈希表結構,修改去重邏輯:
// 根據關鍵字進行搜索
void search(std::string &keyword, std::string &json_string)
{// ...for (auto &word : keywords){// ...for (auto &bi : *ret_ptr){// 如果文檔ID已經存在,說明已經存在,否則不存在if (select_map.find(bi.id) == select_map.end()){// 獲取當前文檔搜索結構節點,不存在自動插入,存在直接獲取auto &el = select_map[bi.id];// 如果是新節點,直接賦值;如果是重復出現的節點,覆蓋el.id = bi.id;// 如果是新節點,第一次添加;如果是重復節點,追加el.words.push_back(bi.word);// 如果是新節點,直接賦值;如果是重復節點,累加el.weight += bi.weight;}}}// ...
}
接著添加去重后的節點到結果集中便于后續排序,此處需要修改結果集結構:
// std::vector<si::BackwardIndexElement> results;
std::vector<SearchIndexElement> results;
修改排序邏輯:
// std::stable_sort(results.begin(), results.end(), [](const si::BackwardIndexElement &b1, const si::BackwardIndexElement &b2) { return b1.weight > b2.weight; });
std::stable_sort(results.begin(), results.end(), [](const SearchIndexElement &b1, const SearchIndexElement &b2){ return b1.weight > b2.weight; });
完成上面的邏輯之后,最后就是將結果轉換為JSON字符串存儲到search函數的第二個參數中。因為需要給用戶返回的內容時文章標題、文章內容和文章在官網的URL,而此處的SearchIndexElement并沒有這三個字段,所以此處還需要借助正排索引,這就是為什么需要同時在正排索引文章信息節點SelectDocInfo和SearchIndexElement設置文檔ID字段的原因。一旦獲取到文章信息后,就可以將三個字段的內容轉換為JSON字符串并賦值給json_string
基于這個邏輯,首先實現獲取正排索引文章信息節點函數getForwardIndexDocInfo:
// 獲取正排索引結果
SelectedDocInfo *getForwardIndexDocInfo(uint64_t id)
{if(id < 0 || id > forward_index_.size()){ls::LOG(ls::LogLevel::WARNING) << "不存在對應的文檔ID";return nullptr;}return &forward_index_[id];
}
接著,實現search最后一部分邏輯。對于一個文檔中含有多個關鍵字的情況,此處為了簡便只取出第一個關鍵詞:
// 根據關鍵字進行搜索
void search(std::string &keyword, std::string &json_string)
{// ...// 轉換為JSON字符串Json::Value root;for (auto &el : results){// 通過正排索引獲取文章內容si::SelectedDocInfo *sd = search_index_->getForwardIndexDocInfo(el.id);Json::Value item;item["title"] = sd->rd.title;// 取出第一個關鍵詞item["body"] = getPartialBodyWithKeyword(sd->rd.body, el.words[0]);item["url"] = sd->rd.url;// 將item作為一個JSON對象插入到root中作為子JSON對象root.append(item);}json_string = root.toStyledString();
}
搜索關鍵字查詢優化
使用上面實現的搜索引擎會發現一個比較影響體驗的問題:大小寫問題。在實際生活中使用的搜索引擎實際上都是忽略大小寫的,所以為了保證本次實現的搜索引擎符合日常使用,添加忽略大小寫的功能到當前項目中
既然要實現忽略大小寫,那么必然涉及到兩個方面:
- 構建索引時對應的關鍵字需要忽略大小寫
- 獲取到用戶輸入的關鍵字需要忽略大小寫
根據上面兩個方面對前面的代碼進行修改:
首先是構建索引部分,只有倒排索引需要修改。對于標題和內容都需要忽略大小寫,而忽略大小寫的時機就在切割關鍵詞之后,統計關鍵詞頻次之前,修改如下:
// 構建倒排索引
bool buildBackwardIndex(SelectedDocInfo &sd)
{// 統計標題中關鍵字出現的次數cppjieba::Jieba jieba;std::vector<std::string> title_words;jieba.CutForSearch(sd.rd.title, title_words);for (auto &tw : title_words){// 忽略大小寫boost::to_lower(tw);word_cnt_[tw].title_cnt++;}// 統計內容中關鍵字出現的次數std::vector<std::string> body_words;jieba.CutForSearch(sd.rd.body, body_words);for (auto &bw : body_words){boost::to_lower(bw);word_cnt_[bw].body_cnt++;}// ...
}
接著就是對用戶輸入的關鍵字進行大小寫忽略,執行的位置就是在分詞之后,查找之前:
// 根據關鍵字進行搜索
void search(std::string &keyword, std::string &json_string)
{// 對用戶輸入的關鍵字進行切分cppjieba::Jieba jieba;std::vector<std::string> keywords;jieba.CutForSearch(keyword, keywords);// 查詢哈希表得到結果std::vector<si::BackwardIndexElement> results;std::unordered_map<uint64_t, si::BackwardIndexElement> select_map;for (auto &word : keywords){// 忽略大小寫boost::to_lower(word);// 查倒排索引// ...}// ...
}
查詢結果優化
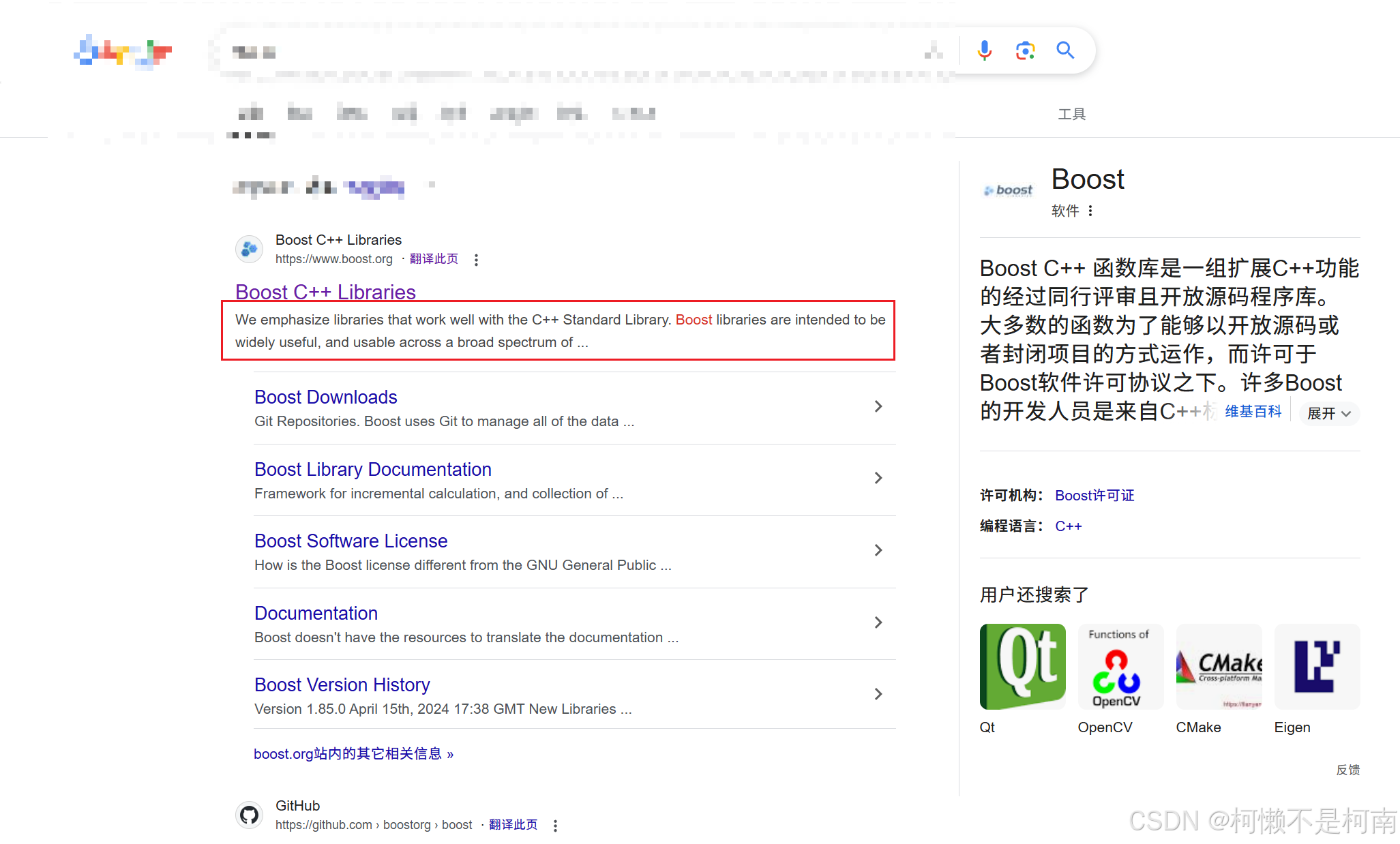
在上面的代碼中可以發現獲取到的內容中有些body部分內容特別多,這是因為在寫入時直接寫入了整個body的內容,這個內容對應的就是去除標簽后整個網頁的內容,其中還包括了標題,但是在一個搜索引擎結果中,描述性文字實際上只有用戶輸入的關鍵字附近的一部分內容,如下圖所示:
本次實現同樣考慮實現這個方案,實現方式很簡單,只需要截取以關鍵字為中心附近的字符組成一個新字符串再轉換為JSON字符串即可。這里實現可以考慮使用string_view,因為涉及到大量的字符串操作
本次實現中考慮取出第一個關鍵字前50個字符(如果沒有就從頭開始取)以及后100個字符(如果沒有就取到結尾)構成一個新的字符串:
static const int prev_words = 50;
static const int after_words = 100;
std::string getPartialBodyWithKeyword(std::string_view body, std::string_view keyword)
{// 找到關鍵字size_t pos = body.find(keyword);if(pos == std::string_view::npos){ls::LOG(ls::LogLevel::WARNING) << "無法找到關鍵字,無法截取文章內容";return "Fail to cut body, can't find keyword";}// 默認起始位置為0,終止位置為body字符串最后一個字符int start = 0;int end = static_cast<int>(body.size() - 1);// 如果pos位置前有50個字符,就取前50個字符if(pos - prev_words > start) start = pos - prev_words;// 如果pos位置后有100個字符,就取后100個字符if(pos + static_cast<int>(keyword.size() + after_words) < end)end = pos + static_cast<int>(keyword.size()) + after_words;if(start > end){ls::LOG(ls::LogLevel::WARNING) << "內容不足,無法截取文章內容";return "Fail to cut body, body is not enough";}// 左閉右閉區間return std::string(body.substr(start, end - start + 1));
}
第一階段問題
構建索引速度慢
在構建索引函數buildIndex中分別添加兩條日志:
// 構建索引
bool buildIndex()
{// debugls::LOG(ls::LogLevel::DEBUG) << "開始建立索引";// ..ls::LOG(ls::LogLevel::DEBUG) << "建立索引完成";return true;
}
測試上面的代碼可以發現幾乎3秒鐘執行一次10次構建,而raw文件中的內容有8141行,計算下來需要花費將近40分鐘進行構建
出現這個問題的主要原因就是buildBackwardIndex和search兩個函數中的Jieba分詞對象都是以局部變量的形式創建的,search會在用戶搜索時執行,剛開始并沒有出現明顯的速度拖慢,但是buildBackwardIndex會在每一行內容構建時執行,這就導致了Jieba對象需要創建8141次
解決這個問題的方式就是將Jieba分詞對象作為成員變量:
=== “SearchIndex類”
class SearchIndex{// ...public:// ...private:// ...// 構建倒排索引bool buildBackwardIndex(SelectedDocInfo &sd){// ...std::vector<std::string> title_words;jieba_.CutForSearch(sd.rd.title, title_words);// ...}//...private:// ...cppjieba::Jieba jieba_;};
=== “SearchEngine類”
class SearchEngine
{
public:SearchEngine(): search_index_(si::SearchIndex::getSearchIndexInstance()){// 構建索引search_index_->buildIndex();}// 根據關鍵字進行搜索void search(std::string &keyword, std::string &json_string){// 對用戶輸入的關鍵字進行切分std::vector<std::string> keywords;jieba_.CutForSearch(keyword, keywords);// ...}~SearchEngine(){}// ...private:// ...cppjieba::Jieba jieba_;
};
進程占滿內存,系統殺死進程
解決第一個問題之后,再次運行代碼可以發現建立索引的速度的確變快了,但是同時出現了第二個問題,當前系統的內存為4GB,在建立到五千行時會出現系統殺死進程,本質就是當前進程在運行一段時間后占滿了內存,操作系統為了保護自己不得已殺死進程,如下圖:
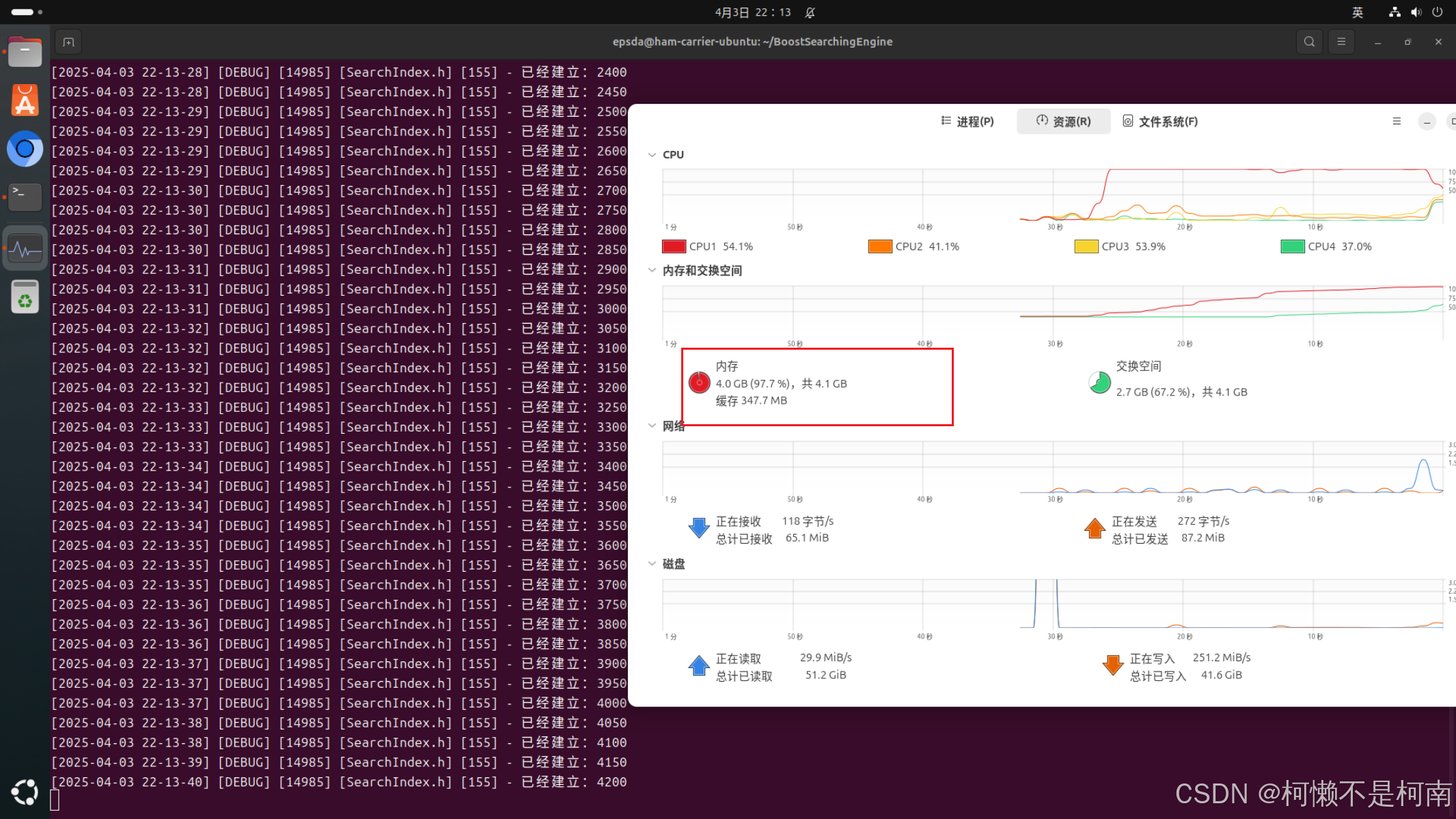
出現這個問題的原因就是用于統計詞頻的哈希表成員。這張哈希表作為了成員變量,其生命周期隨著對象,而當前對象只有在SearchEngine對象銷毀時才會銷毀,這就導致了word_cnt_成員在8141次構建倒排索引時一直在增長,最后內存無法存儲這么大的哈希表不得已殺死進程
但是實際上,word_cnt_只需要統計當前一行的關鍵字即可,因為在buildBackwardIndex中最后會將詞頻計算存儲到倒排索引信息節點的權重屬性,所以執行完這一步,word_cnt_當前的內容就可以不需要了
解決方案有兩種:
- 將
word_cnt_作為buildBackwardIndex函數的成員變量 - 在
buildBackwardIndex函數剛開始調用word_cnt_的clear函數清空當前的word_cnt_
本次采用第二種方法,修改如下:
// 構建倒排索引
bool buildBackwardIndex(SelectedDocInfo &sd)
{word_cnt_.clear();// ...
}
錯誤進入本不應該進入的邏輯
進入getPartialBodyWithKeyword中無法找到關鍵字分支
出現這個問題的本質是在getPartialBodyWithKeyword函數中,因為第一個參數獲取到的是文章原始內容,其中的每一個單詞包含大寫和小寫,但是第二個參數是忽略大小寫之后的結果,這就導致在查找倒排索引時的確查得到,但是截取時因為可能存在大寫字母而沒有忽略大小寫導致沒有截取到對應的關鍵字
最簡單的解決方案就是將內容全部轉換為小寫,但是這樣的成本過高,另外一種方案就是在查找的時候忽略大小寫,但是string_view中并沒有提供忽略大小寫查找的方案,所以需要借助<algorithm>中的search方法解決,該方法的原型如下:
template <class ForwardIterator1, class ForwardIterator2, class BinaryPredicate>
ForwardIterator1 search (ForwardIterator1 first1, ForwardIterator1 last1,ForwardIterator2 first2, ForwardIterator2 last2,BinaryPredicate pred);
該方法的含義是根據pred的比較方式查找第一個容器中是否連續含有第二個容器的內容,因為本次查找就是為了查找出內容中是否含有關鍵字并且需要忽略大小寫,本質就是查找是否在內容中存在連續的字符轉換為小寫與關鍵字的每一個字符在轉換小寫后相同
但是,search函數會返回一個迭代器而不是整數表示第一次出現的位置,所以還需要計算出當前迭代器位置與原始內容字符串開始的距離
這里可以使用<iterator>庫中的distance函數,該函數原型如下:
template<class InputIterator>
typename iterator_traits<InputIterator>::difference_type
distance (InputIterator first, InputIterator last);
該函數會返回第一個迭代器和第二個迭代器之間的位置值,如果將迭代器類比為指針,因為當前元素是字符,占用一個字節,那么就可以理解為兩個指針直接相減得到的值
基于上面這個解決方案,修改原來的getPartialBodyWithKeyword函數:
std::string getPartialBodyWithKeyword(std::string_view body, std::string_view keyword)
{// 找到關鍵字// size_t pos = body.find(keyword);auto pos_t = std::search(body.begin(), body.end(), keyword.begin(), keyword.end(), [](char c1, char c2){ return std::tolower(c1) == std::tolower(c2); });if (pos_t == body.end()){ls::LOG(ls::LogLevel::WARNING) << "無法找到關鍵字,無法截取文章內容";return "Fail to cut body, can't find keyword";}int pos = std::distance(body.begin(), pos_t);// ...
}
進入getPartialBodyWithKeyword中內容不足截取不到內容分支
出現這個問題的原因在getPartialBodyWithKeyword中,計算是否可以取出前50個字符時pos并沒有轉換為int,而是保留了size_t參與運算,這就導致計算pos - prev_words > start是出現了類型提升,即全部以size_t類型進行計算,而此時的pos一旦是size_t就會變成npos的值(即int類型下的-1,size_t下的 2 64 ? 1 2^{64} - 1 264?1),因此pos - prev_words始終大于start,因為根本減不到負數。這里條件成立進入分支之后執行start = pos - prev_words;。接著,一旦滿足start > end,就會進入到內容不足截取不到內容分支的邏輯
解決方案就是將pos轉換為int類型防止出現類型提升:
std::string getPartialBodyWithKeyword(std::string_view body, std::string_view keyword)
{// ...// 如果pos位置前有50個字符,就取前50個字符if (static_cast<int>(pos) - prev_words > start)start = pos - prev_words;// ...
}
構建的URL在官網出現頁面不存在
例如下面構建出的URL:
https://www.boost.org/doc/libs/1_78_0/doc/html/some_basic_explanations.html
官網實際的URL為:
https://www.boost.org/doc/libs/1_78_0/doc/html/interprocess/some_basic_explanations.html
首先排除目錄路徑問題,如下:
epsda@ham-carrier-ubuntu:~/BoostSearchingEngine$ find -name some_basic_explanations.html
./data/source/html/interprocess/some_basic_explanations.html
可以看到在html目錄下的確存在interprocess/some_basic_explanations.html,如果按照預期的拼接方式應該為:
https://www.boost.org/doc/libs/1_78_0/doc/html/ + interprocess/some_basic_explanations.html
但是這里的拼接方式為:
https://www.boost.org/doc/libs/1_78_0/doc/html/ + some_basic_explanations.html
這就導致出現了頁面不存在(404)的問題
出現這個問題的代碼就是constructHtmlUrl中截取本地路徑部分。原始的邏輯是找到最后一個/就停止查找,導致截取出的some_basic_explanations.html實際上缺少了其父級目錄interprocess/,進而導致構建URL時得到的URL在官網不存在
解決這個問題的思路很簡單,只需要查找路徑/data/source/html在/data/source/html/interprocess/some_basic_explanations.html出現的起始位置值pos,再從pos + 路徑長度開始截取后面的內容即可
基于上面的思路修改代碼如下:
// 構建URL
bool constructHtmlUrl(const fs::path &p, std::string *url)
{// 查找/data/source/htmlstd::string t_path = p.string();auto pos = t_path.find(g_datasource_path);// ...std::string source_path = t_path.substr(pos + g_datasource_path.string().size());*url = g_url_to_concat + source_path;return true;
}
權重計算異常
在構建JSON字符串時,添加文檔ID、權重和關鍵字后測試:
void search(std::string &keyword, std::string &json_string)
{// ...// 轉換為JSON字符串Json::Value root;for (auto &bi : results){// ...item["id"] = sd->id;item["word"] = bi.word;item["weight"] = bi.weight;// ...}// ...
}
測試結果可以看到,有些權重計算結果存在一定誤差,例如搜索split:
{"body" : "Class template split_iteratorHomeLibrariesPeopleFAQMoreClass template split_iteratorboost::algorithm::split_iterator \u2014 ","id" : 6164,"title" : "Class template split_iterator","url" : "https://www.boost.org/doc/libs/1_78_0/doc/html/boost/algorithm/split_iterator.html","weight" : 34,"word" : "split"
},
通過網址到官網啟動瀏覽器搜索可以看到結果總共是25,其中標題中也存在split,按照設定的權重計算公式 t i t l e × 10 + b o d y title \times 10 + body title×10+body應該是35而并非34
為了找出這個問題出現的原因,需要在查詢時針對當前文檔ID單獨打印處理,猜測出現這個問題的原因是分詞工具的分詞邏輯和瀏覽器的分詞邏輯不同,修改buildBackwardIndex代碼如下:
// 構建倒排索引
bool buildBackwardIndex(SelectedDocInfo &sd)
{// ...// 一旦文檔ID為6164就打印出標題的所有分詞結果if (sd.id == 6164){for (auto &s : title_words){std::cout << "title: " << s << std::endl;}}// ...// 一旦文檔ID為6164就打印出所有文檔內容的所有分詞結果if (sd.id == 6164){for (auto &s : body_words){std::cout << "body: " << s << std::endl;}}// ...
}
再次進行測試,可以發現,標題存在1個split,文章內容中只有24個split,根據前面的計算公式可以得出權重值為34,可以發現代碼并沒有問題,只是分詞的邏輯不同而已
創建服務器
本次創建服務器不直接使用原生的網絡接口,而是使用封裝后的cpp-httplib庫,所以首先需要準備該庫:
git clone https://github.com/yhirose/cpp-httplib.git
接著,在當前項目目錄下建立一個軟鏈接指向cpp-httplib對應的目錄即可,例如:
ln -s /home/epsda/dependencies/cpp-httplib/
完成安裝后即可寫出對應的服務器代碼
關于cpp-httplib的基本使用可以看對應倉庫中的介紹,此處不再提及
首先,為了保證客戶端可以直接通過IP地址+端口號的方式直接訪問到主頁,先設置Web根目錄為wwwroot,其中含有一個index.html文件作為主頁,并在服務器程序中通過cpp-httplib.h中的set_base_dir函數設置:
// 設置網頁根路徑
httplib::Server s;
s.set_base_dir(pd::root_path);
設置完成后直接訪問IP地址+端口號即可訪問到主頁
接著服務器需要設置對應處理請求的方案,本次考慮用戶請求/search服務時調用服務器中的search方法執行搜索,所以實現方式如下:
void run(se::SearchEngine& s_engine, const httplib::Request& req, httplib::Response &resp)
{}int main()
{// ...se::SearchEngine s_engine;s.Get("/search", std::bind(run, std::ref(s_engine), std::placeholders::_1, std::placeholders::_2));// ...
}
接著,本次考慮需要用戶按照下面的方式請求才可以獲取到內容:
http://IP地址+端口/search?keyword=xxx
所以可以編寫出對應的代碼為:
void run(se::SearchEngine& s_engine, const httplib::Request& req, httplib::Response &resp)
{// 如果不存在word,說明在請求不存在的頁面,返回404if(!req.has_param("keyword")){se::ls::LOG(se::ls::LogLevel::INFO) << "請求不存在的資源";resp.status = httplib::StatusCode::NotFound_404;resp.set_file_content("wwwroot/404.html", "text/html");return;}// 此時說明存在對應的值,獲取值auto val = req.get_param_value("keyword");// 執行搜索std::string json_string;s_engine.search(val, json_string);se::ls::LOG(se::ls::LogLevel::INFO) << "搜索關鍵詞: " << val;resp.set_content(json_string, "application/json");
}
最后,為了保證服務器可以正常被客戶端訪問,服務器還需要啟動監聽。本次考慮監聽端口由啟動方設定:
int main(int argc, char* argv[])
{if(argc != 2){se::ls::LOG(se::ls::LogLevel::ERROR) << "啟動方式錯誤";return 1;}// ...// 獲取端口int port = std::stoi(argv[1]);// 監聽任意端口s.listen("0.0.0.0", port);return 0;
}

:ReentrantLock 源碼分析)




中,在LCD中顯示兩位數字問題)

)

)



)
)



