文章目錄
- 標題
- 作者
- 摘要
- 一、介紹
- 1.1. 相關工作
- 1.1.1. 內鏡重建數據集
- 1.1.2. 注冊真實和虛擬內窺鏡圖像
- 1.1.3. 2D-3D注冊
- 1.2. 貢獻
- 二、方法
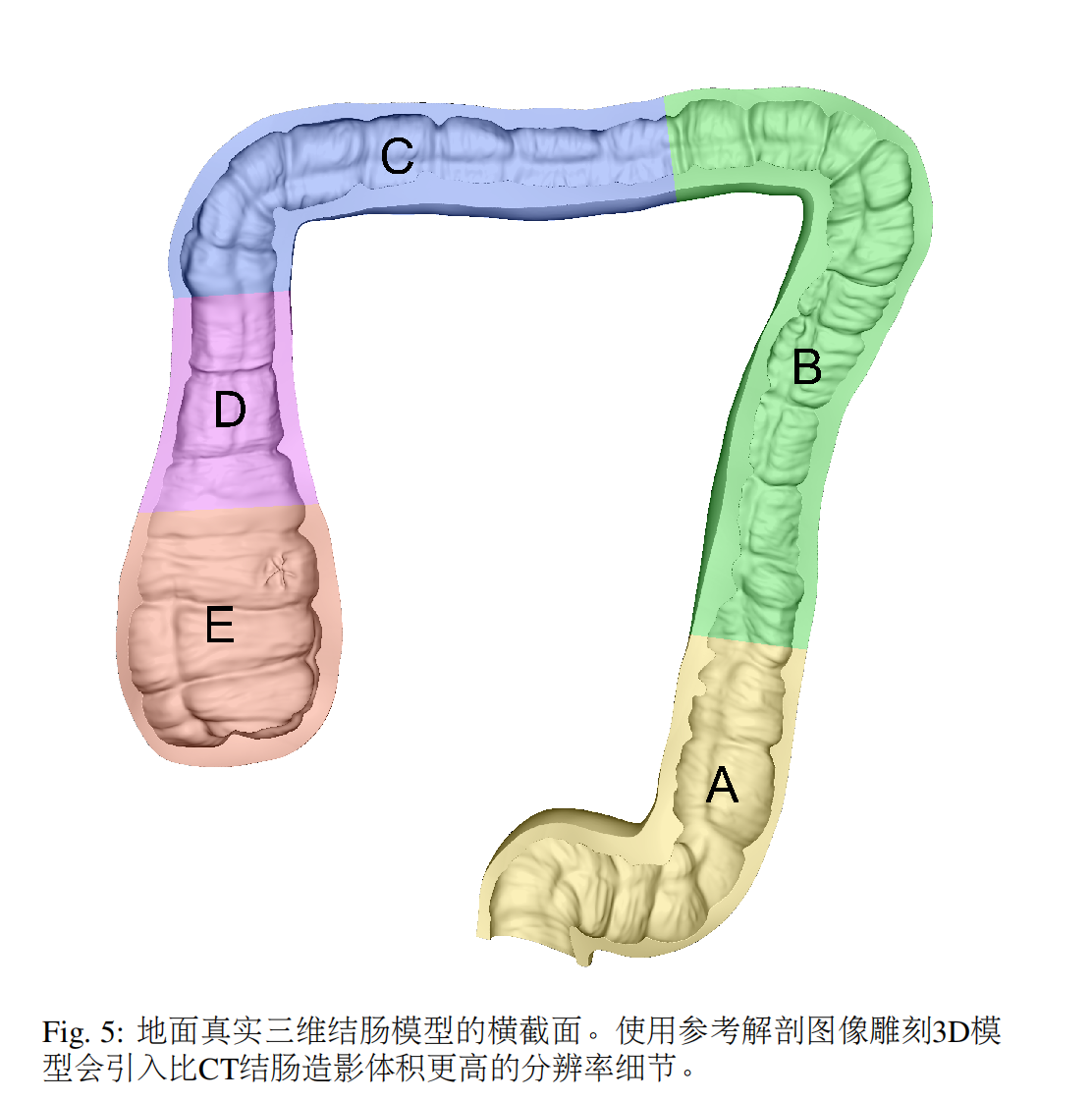
- 2.1. 幻影模型生產
- 2.2. 數據采集
- 2.3. 注冊流程概述
- 2.3.1. 數據預處理
- 2.3.2. 目標深度估計
- 2.3.3. 渲染深度幀
- 2.3.4. 邊緣損失和優化
- 2.4. 模擬篩查結腸鏡檢查
- 三、實驗與結果
- 3.1. 實施
- 3.2. 綜合數據評估
- 3.3. 使用真實視頻序列進行評估
- 四、數據集和分布格式
- 五、討論與結論
標題
??《結腸鏡3D視頻數據集,具有2D-3D配準的成對深度》
作者
??Taylor L. Bobrow, Mayank Golhar, Rohan Vijayan, Venkata S. Akshintala, Juan R. Garcia, Nicholas J. Durr
摘要
??篩查結腸鏡檢查是幾種3D計算機視覺技術的重要臨床應用,包括深度估計、表面重建和缺失區域檢測。然而,由于獲取地面真實數據的困難,這些技術在真實結腸鏡檢查視頻中的開發、評估和比較在很大程度上仍然是定性的。在這項工作中,我們提出了一個結腸鏡3D視頻數據集(C3VD),該數據集是通過高清臨床結腸鏡和高保真結腸模型獲得的,用于對結腸鏡檢查中的計算機視覺方法進行基準測試。我們介紹了一種新的多模態2D-3D配準技術,用于將光學視頻序列與已知3D模型的真實渲染視圖配準。通過使用生成對抗網絡將光學圖像轉換為深度圖,并使用進化優化器對齊邊緣特征,來注冊不同的模態。這種配準方法在模擬實驗中實現了0.321毫米的平均平移誤差和0.159度的平均旋轉誤差,其中可以獲得無誤差的地面真值。該方法還利用了視頻信息,與單幀配準相比,平移和旋轉的配準精度分別提高了55.6%和60.4%。注冊了22個短視頻序列,生成了10015個總幀,其中包含成對的地面真實深度、表面法線、光流、遮擋、六自由度姿態、覆蓋圖和3D模型。該數據集還包括胃腸病學家通過配對的地面真實姿勢和3D表面模型獲得的篩查視頻。數據集和注冊源代碼可在上durr.jhu.edu/C3VD獲得。
一、介紹
??結直腸癌(CRC)是美國(Siegel et al., 2021)癌癥致死率第二高的癌癥。據信,至少80%的CRC是由癌前腺瘤(Cunninghamet al., 2010)發展而來的。篩查結腸鏡檢查仍然是檢測和清除癌前病變的金標準,有效降低了患CRC(Rex et al.,2015)的風險。盡管如此,估計有22%的癌前病變在篩查過程(van Rijn et al., 2006)中未被發現。這些遺漏的病變被認為是間隔性CRC的主要原因,即在陰性篩查結腸鏡檢查后5年內發生CRC,占CRC病例(Samadder et al.,2014)的6%。
??結腸鏡檢查仍然是計算機視覺研究人員的一個積極應用,他們致力于降低病變漏檢率并改善臨床結果(Aliet al., 2020; Fu et al., 2021; Chadebecq et al., 2023)。最近的工作采用了卷積神經網絡(CNN)來檢測和提醒臨床醫生結腸鏡檢查視頻幀(Hassan et al., 2020; Livovsky et al.,2021; Luo et al., 2021)中可見但有時微妙的息肉。雖然這些算法已經證明了令人印象深刻的檢測率,但它們要求在檢測過程中息肉出現在結腸鏡視野(FoV)中。在內窺鏡視頻(McGill et al., 2018)的回顧性分析中發現,遺漏的區域——篩查過程中從未成像的結腸區域——估計占結腸表面的10%,使患者有患間歇性CRC的風險。
??為了減少遺漏區域的程度,研究探索了在篩查過程(Hong et al., 2007, 2011; Armin et al., 2016)中測量結腸的觀察覆蓋率。Freedman et al. (2020)描述了一種數據驅動的方法,用于使用深度學習直接回歸一小群幀的數值可見性得分。一些方法利用深度學習來回歸像素級深度(Mahmood and Durr, 2018; Rau et al., 2019; Cheng et al.,2021),這些信息可以結合到同步定位和映射(SLAM)技術中,以重建結腸表面(Chen et al., 2019b)。這些重建中的孔洞可能表明未被觀察到的組織區域,這些區域已被實時標記以提醒結腸鏡醫生(Ma et al., 2019)。3D計算機視覺技術在結腸鏡檢查中的其他相關應用包括息肉大小預測(Abdelrahim et al., 2022)、表面形貌重建(Parotet al., 2013)、視覺里程計估計(Yao et al., 2021)以及通過3D增強(Mahmood et al., 2018b)增強的病變分類。
1.1. 相關工作
1.1.1. 內鏡重建數據集
??用于評估內窺鏡重建方法的數據集因預期應用、模型類型、記錄設置和地面真實數據可用性而異。在手術環境中獲取具有準確表面信息的數據集通常是不切實際的。作為替代方案,已經探索了商業(Stoyanov et al.,2010)和計算機斷層掃描(CT)衍生(Penza et al., 2018)的硅膠模型。表面信息可以通過CT或光學掃描(OS)直接測量,一些腹腔鏡中的立體傳感器配置可用于生成地面真實深度(Recasens et al., 2021)。除了具有相對均勻光學特性的合成模型外,離體 (Mahmood and Durr, 2018;Edwards et al., 2022; Allan et al., 2021; Maier-Hein et al.,2014; Ozyoruk et al., 2021)和體內 (Ye et al., 2017)動物組織都被用來生成具有更真實的雙向散射分布函數(BSDF)的數據。
??最近,Unity(Unity Technologies)等游戲引擎已被用于渲染來自3D解剖模型的合成圖像,如CT結腸造影體積(Mahmood et al., 2018a; Rau et al., 2019; Ozyoruk et al.,2021; Zhang et al., 2021; Rau et al., 2022)。渲染數據是有利的,因為可以從渲染圖元中獲得無誤差的像素級地面真實標簽,如深度和表面法線。此外,可以快速生成大量數據。一個顯著的缺點是渲染引擎模擬真實世界相機光學、非全局照明、專有采集后處理、傳感器噪聲和光組織交互的能力有限。大多數具有真實圖像的內窺鏡重建數據集都是為腹部和胸部的腹腔鏡成像而設計的。腹腔鏡數據集不適合作為結腸鏡成像的基準,因為角度FoV(和相應的失真)、傳感器排列和器官幾何形狀存在很大差異。此外,用剛性腹腔鏡模擬結腸鏡的真實運動是具有挑戰性的。Ozyoruk等人提供了一個視頻數據集,用于用幾種不同的相機類型對胃、小腸和結腸進行成像,并使用臨床結腸鏡(Ozyoruk et al., 2021)記錄一個序列。該數據集中的每個視頻序列都與地面實況相機軌跡和3D表面模型配對,但沒有生成像素級的地面實況數據,限制了數據的實用性。由于空間受限的成像環境、高分辨率要求和與臨床應用相關的大范圍工作距離,生成像素級地面真實信息對結腸鏡檢查來說尤其具有挑戰性。
1.1.2. 注冊真實和虛擬內窺鏡圖像
??將內窺鏡框架與地面實況表面模型進行配準,可以提取衍生的地面實況數據和度量。例如,如果已知內窺鏡相對于表面模型的姿態,則可以將地面真實深度幀分配給真實的內窺鏡圖像。然而,由于缺乏魯棒的角點和內窺鏡圖像中常見的可變鏡面反射,使用傳統的基于特征的方法進行配準具有挑戰性。為了規避這一挑戰,分段基準點已被用于將光學圖像配準到地面真實CT體積(Rau et al., 2019; Stoyanov et al.,2010)。雖然這種方法很穩健,但一個缺點是整個圖像FoV中存在不切實際的基準點。Edwards et al. (2022)選擇移除基準點,轉而依賴于虛擬相機與地面真實CT體積的手動對齊。這種方法的手動性質對于生成少量數據非常有效,但它是注冊大量數據的障礙,其準確性受到操作員之間可變性的限制。Penza et al. (2018)使用校準目標來校準固定相機和激光掃描儀的坐標系,允許在不受尺寸限制的腹腔鏡成像環境中同時記錄內窺鏡幀和3D表面信息。
??表1中報告了現有和擬議的內窺鏡3D數據集和采集方法的總結。
1.1.3. 2D-3D注冊
??2D-3D配準能夠將2D圖像與3D空間體積配準,并且它經常用于將3D術前CT體積與2D術中X射線圖像對齊。大多數方法依賴于優化目標2D圖像與在估計姿態(Markeljet al., 2012)下采集的3D體積的模擬2D射線照片之間的相似性。常見的相似性度量是基于梯度、強度和特征(Groher et al., 2007)的度量。最近,2D-3D配準方法已經發展到包括基于學習的算法,以解決跨模態配準(Oulbacha and Kadoury, 2020)和特征提取(Grupp et al.,2020)中的挑戰。
1.2. 貢獻
??雖然計算機視覺在結腸鏡檢查中的研究范圍很廣,但由于缺乏地面實況注釋數據,評估和基準測試方法仍然是一個挑戰。在這項工作中,我們提出了一個高清晰度(HD)結腸鏡3D視頻數據集(C3VD),用于定量評估計算機視覺方法。據我們所知,這是第一個完全用臨床結腸鏡記錄的具有3D地面真相的視頻數據集。在這項工作中,我們做出了貢獻:
- 2D-3D視頻配準算法,用于將真實的2D光學結腸鏡檢查視頻序列與地面真實3D模型對齊。將GAN估計的深度幀與沿著測量的相機軌跡渲染的預測視圖進行比較,以最小化基于邊緣的損失。
- 一種生成具有不同紋理和顏色的高保真硅膠體模模型以促進域隨機化的技術。
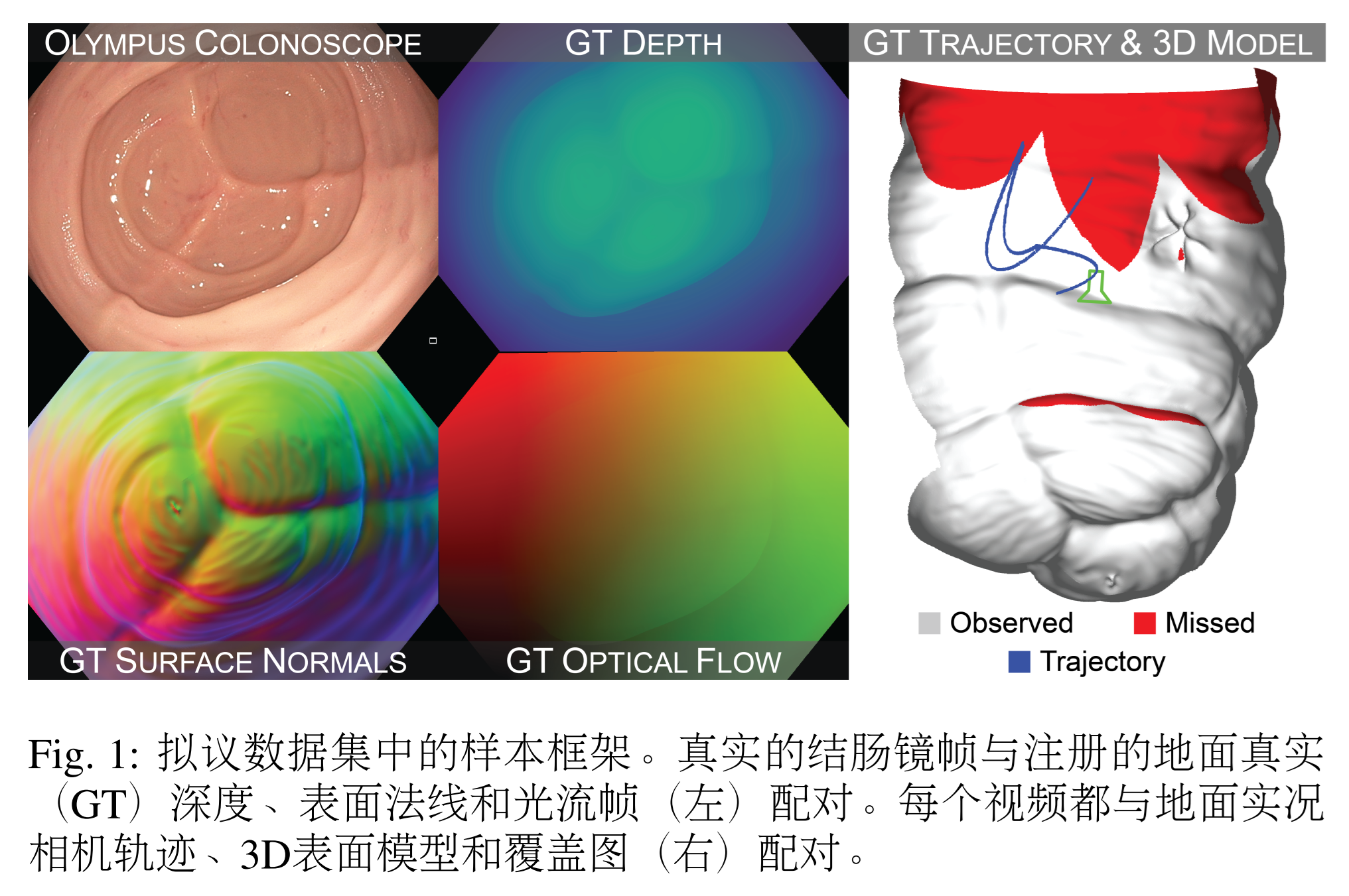
- 具有像素級配準到已知3D模型的地面真實數據集,用于定量評估結腸鏡檢查中的計算機視覺技術。該數據集包含10015個高清視頻幀,這些幀是通過臨床結腸鏡獲得的逼真結腸體模模型。每一幀都與地面真實深度、表面法線、遮擋、光流和六自由度相機姿態配對。每個視頻都與地面實況表面模型和覆蓋圖配對(圖1)。
??數據集、3D結腸模型、體模和2D-3D配準算法都可以在durr.jhu.edu/C3VD上公開。
二、方法
??我們提出了一種通過臨床結腸鏡生成視頻序列的方法,該方法具有成對的像素級地面實況。我們首先描述了一種用于生成高保真幻影模型(第2.1節)和記錄具有地面真實軌跡的視頻序列(第2.2節”)的協議。然后,我們介紹了一種將獲取的視頻和軌跡序列與地面真實3D表面模型進行配準的新技術(第2.3節)。
2.1. 幻影模型生產
??一個完整的3D結腸模型——從乙狀結腸到盲腸——由一位經過委員會認證的整形外科醫生(JRG)使用結腸鏡檢查程序的參考解剖圖像在Zbrush(Pixologic)中進行了數字雕刻。與分辨率受限的CT結腸成像模型相比,該方法在數字模型中引入了更高頻率的細節。我們將雕刻的模型分為五個部分:乙狀結腸、降結腸、超越結腸、升結腸和盲腸。每個部分都生成了三個零件模具。兩部分由外殼的兩半組成,一個插入部分形成結腸腔和粘膜表面。所有模具均采用Objet 260 Connex 3進行3D打印,分辨率為16微米。每個模具的鑄件用硅樹脂制成(Dragon SkinTM,Smooth-On,股份有限公司)。使用硅樹脂顏料(Silc PigTM,Smooth-On,股份有限公司)來改變顏色和質地。硅膠以不同程度的不透明性手動施加5-12層,以模擬不同光學深度下患者特定的組織特征和脈管系統模式。在記錄時間將硅酮潤滑劑(015594011516,BioFilm,股份有限公司)施加到模型的表面以模擬粘膜的高度鏡面外觀。
2.2. 數據采集

??用于數據采集的設置如圖2所示。使用奧林巴斯CF-HQ190L視頻結腸鏡、CV-190視頻處理器和CLV-190光源記錄體模模型的視頻序列。模型被放置在模具內,插入物被移除,以保持其靜止,在視頻錄制過程中不會變形。結腸鏡的尖端牢固地安裝在UR-3(通用機器人)機械臂上。對于每個視頻片段,手動編程4-8個連續的姿勢,以模仿典型的結腸鏡檢查軌跡。機器人手臂以10微米的可重復性在這些姿勢之間進行插值,穿過結腸。以63Hz的采樣率記錄手臂的姿勢日志。結腸鏡視頻是使用連接到奧林巴斯視頻處理器SDI輸出的OrionHD(Matrox)圖像采集卡以未壓縮的HD格式錄制的。
2.3. 注冊流程概述
??通過沿記錄的軌跡移動虛擬相機并渲染3D模型的地面實況幀,生成了每個視頻幀的像素級地面實況。雖然虛擬相機的結腸鏡軌跡是已知的,但體模相對于該軌跡的位置是未知的。假設幻影模型在視頻序列的持續時間內是靜止的,幻影姿態可以表示為單個剛體變換(Tfinal),由旋轉分量(θ)和平移分量(t)組成。我們使用三個歐拉角和一個平移向量([θα θβ θγ tx ty tz])來參數化這個變換。為了估計這種未知的變換,我們利用2D-3D配準方法來對齊2D視頻幀和體模的虛擬3D模型之間共享的幾何特征。注冊管道對模型變換預測的參數空間進行采樣(Ti),評估當前模型變換時目標深度幀和渲染之間的特征對齊,并使用進化優化器更新模型變換預測。此注冊方法如圖3所示,并在以下小節中詳細說明。
2.3.1. 數據預處理
??在開始配準優化之前,對每個視頻序列、姿態日志和地面真實3D模型進行了預處理。對于由N幀組成的視頻序列,關鍵幀的δ采樣間隔為δ,總共有K個關鍵幀。然后使用經過訓練以估計深度的生成對抗網絡為每個關鍵幀估計深度幀(第節2.3.2)。對于每個關鍵幀,從姿勢日志中采樣一個姿勢Ai,描述機器人手臂末端執行器相對于基座的位置。通過求解相對時間偏移,實現了視頻序列和姿態日志之間的同步,該偏移導致光流幅度和相機姿態位移之間的最大相關性。進行了手眼校準,XAi以表征機器人手臂姿勢和結腸鏡相機姿勢之間的轉換(Bi)。此校準允許以下關系
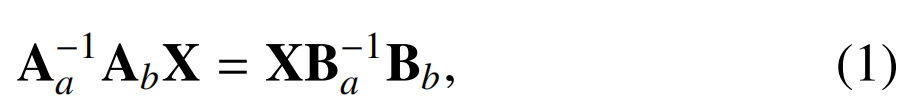
??其中Aa/Ba和Ab/BaBb是為校準而捕獲的成對機器人和相機姿態。校準后,通過求解重新排列的手眼關系,將機器人手臂姿勢轉換為相機姿勢
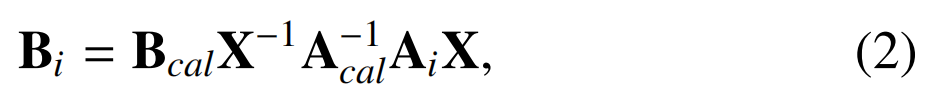
??其中Acal和Bcal是從校準中保留的一對姿勢。
??最后,將地面實況三角網格轉換為分割邊界體積層次(SBVH),并創建渲染上下文,用于從3D地面實況模型渲染深度幀(第2.3.3節)。手動對齊每個視頻序列的初始模型變換(Tinitial)。我們使用了一個自定義的圖形用戶界面,當模型變換被手動擾動時,該界面將第一個關鍵幀與在相機姿態B1下渲染的幀疊加在一起。
2.3.2. 目標深度估計
??預測每個關鍵幀的像素級深度被制定為圖像到圖像的轉換任務。使用合成渲染的輸入-輸出圖像對訓練條件生成對抗網絡(cGAN),并對真實圖像進行推理。先前的研究表明,當在合成數據上訓練并應用于使用cGAN網絡架構(Chen et al., 2018; Rau et al., 2019)激勵的真實數據時具有很強的領域泛化能力。使用虛擬3D模型和3個獨特的BSDF進行域隨機化,渲染了1000對具有成對深度的合成結腸鏡檢查圖像。降結腸模型和第四個BSDF從訓練數據中省略,并保存用于驗證實驗。為了實現高清分辨率的訓練,除了傳統的GAN損失(Wanget al., 2018)外,還采用了多尺度鑒別器模型和多層特征匹配損失。關鍵幀被饋送到訓練好的生成器,以生成用于對齊的目標深度幀。
2.3.3. 渲染深度幀
??使用3D結腸模型中的虛擬相機渲染每個相機姿態的深度幀,并將這些幀與目標深度幀進行比較,以評估當前模型變換預測的準確性。寬FoV(≈170°)是臨床結腸鏡的一個關鍵特征,它最大限度地提高了外周結腸表面的可見度。然而,這種魚眼效應尚未在合成內窺鏡數據(Ozyoruk et al., 2021; Rau et al., 2022)集中進行模擬。為了對商用結腸鏡的整個FoV進行建模,我們采用了如圖4所示的球面相機固有模型(Scaramuzza et al., 2006)。
??對于每個像素[u v],都存在一個從相機原點O ∈ R3發射到世界空間的光線方向V →∈ N3。像素坐標首先相對于相機c ∈ R2×1的光學中心進行偏移,然后通過仿射變換A ∈ R2×2進行傾斜,以考慮鏡頭錯位,從而產生失真的像素坐標[u′v′] ∈ R2:

??畸變像素坐標和相應的光線方向通過參數方程相關聯

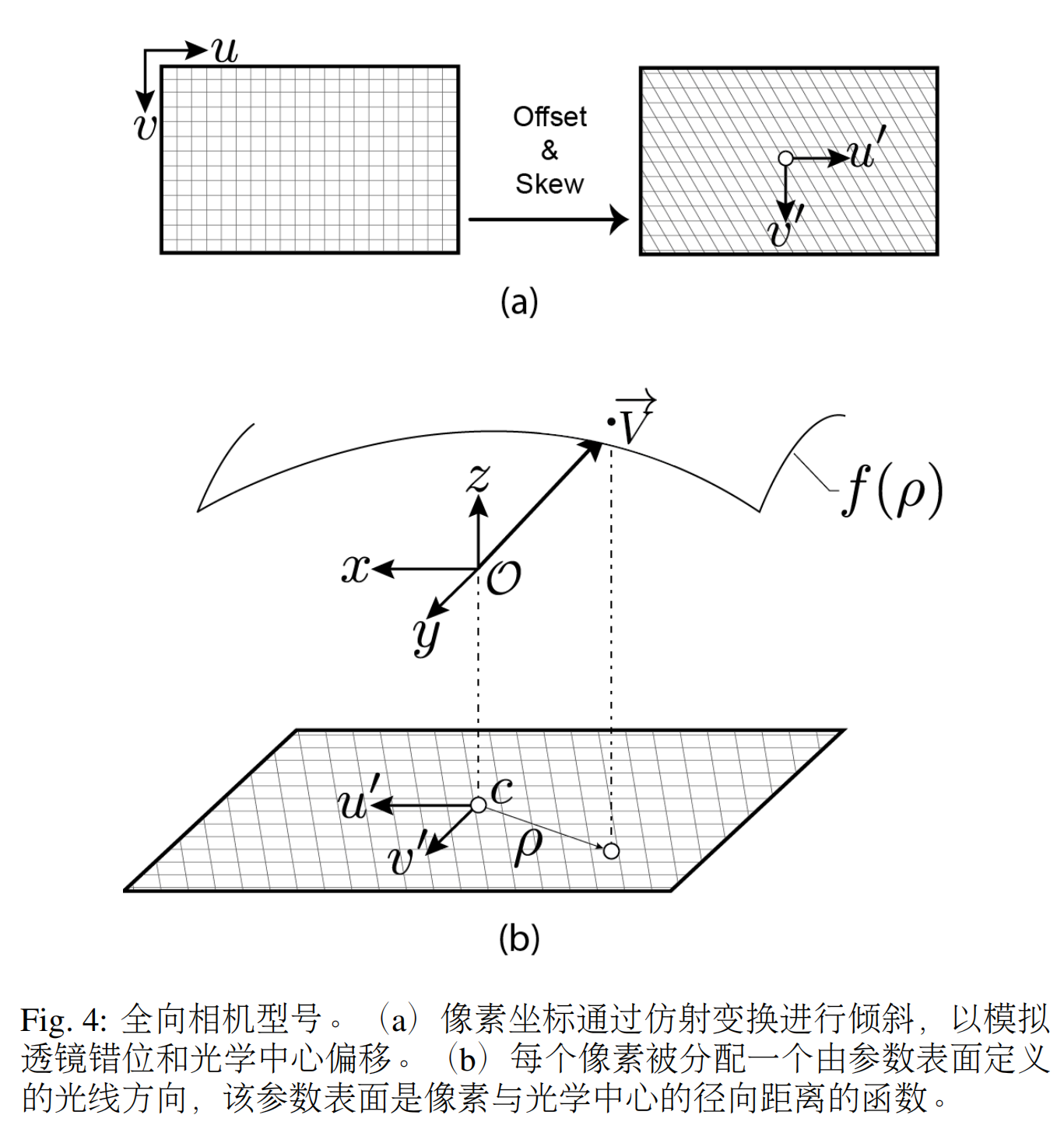
??其 中ρ =√u‘2 + v′2, 、f(ρ) = α0 + α2ρ2 + α3ρ3 +α4ρ4和α0…α4是校準期間求解的系數參數。通過當前相機姿態的旋轉矩陣進行變換,并從光線原點投射出最終的光線方向。
??對于每次優化迭代,首先將模型變換更新為當前樣本(Ti?1 → Ti),并在每個虛擬相機姿態(B1 · · · BK)處渲染深度幀(DTB1 · · · BK)。為了高效計算,我們使用英偉達?OptiXTM光線追蹤API實現了自定義光線投射引擎。這使得可以直接訪問GPU RT內核(Parker et al.,2010)。SBVH模型用于初始化加速結構,并且該結構隨著每個新的模型變換而更新。
2.3.4. 邊緣損失和優化
??將目標和渲染的深度幀進行比較,以評估當前預測的準確性。為了最小化深度學習預測的深度中常見的尺度不一致的影響,我們比較了目標和模型深度幀中深度不連續性的幾何輪廓。使用Canny邊緣提取和二值化來提取輪廓。為了在比較目標和模型深度幀時提供連續平滑的損失函數,我們用歸一化高斯核模糊了這些邊緣,將此操作表示為E? = E(D)。然后,配準優化旨在通過計算幀對之間的相似性度量來最大化這些模糊邊緣幀的重疊,
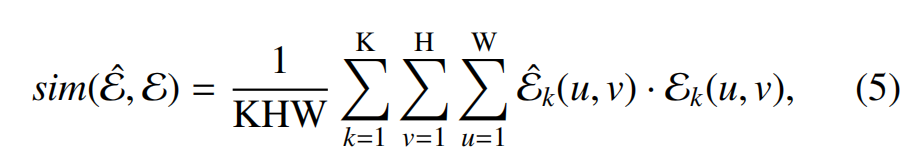
??其中E?是渲染邊緣幀的集合,E是目標邊緣幀的集,是幀對的數量。此相似性函數的輸出是一個介于0.0和1.0之間的值,當目標邊緣和渲染邊緣等效且完全對齊時,該值最大。為了將函數重新定義為最小化問題,從1.0中減去相似性值,得到完整的目標函數

??模型變換的評估樣本由稱為協方差矩陣自適應進化策略(CMA-ES)(Hansen et al., 2003)的進化優化器迭代細化。
2.4. 模擬篩查結腸鏡檢查
??除了可以用機器人手臂精細姿態信息計算像素級地面真實度的視頻片段外,我們還記錄了四個具有粗略六自由度姿態和3D表面模型的模擬篩查結腸鏡檢查視頻序列。用硅樹脂粘合劑(Sil-PoxyTM,Smooth-On,股份有限公司)將體模節段粘附在一起,并安裝在激光切割的泡沫支架中。將電磁場發生器(Aurora,Northern Digital股份有公司)定位在模型上方,并將六自由度電磁傳感器(EM,610016,Northern Digital股份有限公司)剛性地固定到瞄準鏡的遠端,用于以40Hz記錄姿勢信息。從盲腸開始,一名訓練有素的胃腸病學家(VSA)撤回了范圍,同時記錄了視頻和姿勢信息。EM姿態被同步,并使用第2.3.1節中描述的相同過程轉換為相機姿態。如果傳感器未能跟蹤軌跡的一部分,則對時間上相鄰的姿勢進行線性插值。
三、實驗與結果
3.1. 實施
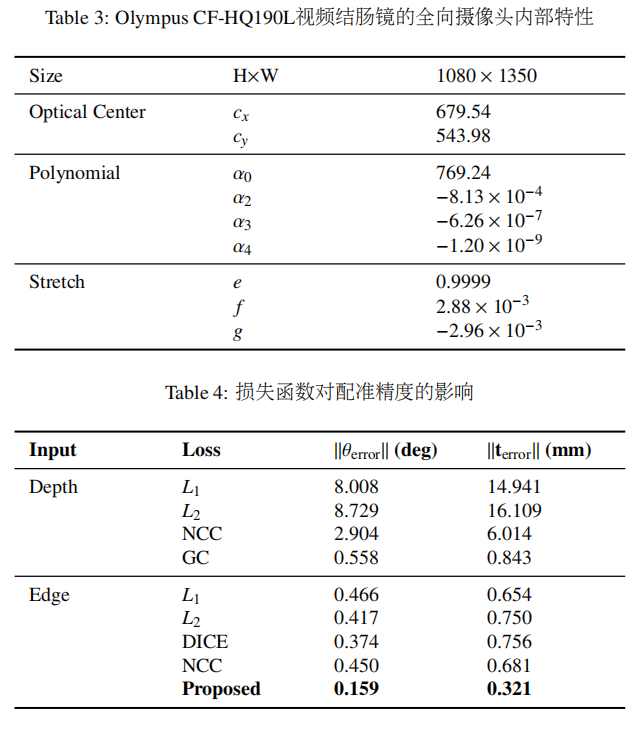
??完整的雕刻結腸模型的橫截面如圖5所示。模型節段長度、病變類型和長軸直徑如表2所示。該模型的3D打印模具用于鑄造四套完整的模型。每個幻影組都是用獨特的材料屬性鑄造的。使用具有10x10平方毫米的10x15棋盤的30幅圖像和Matlab 2022a相機校準工具箱(Mathworks)測量了CF-HQ190L視頻結腸鏡的相機固有參數。校準導致0.47像素的平均重投影誤差。表3中報告了該校準的最終結果。根據校準估計的相機外部姿態與相應的機器人姿態一起計算手眼變換X。使用提出的XPark and Martin (1994)優化方法找到了的X解決方案。
??深度估計網絡架構在Pytorch中實現。0.0002的初始學習率在前50個迭代周期內保持不變,然后在最后50個迭代階段線性衰減。輸入幀被零填充到的1088 × 1376大小,并以1的1088 × 1376批大小饋送到網絡。訓練計算分為4個Nvidia? RTX A5000圖形處理單元,需要31個小時才能完成。然后將真實的結腸鏡檢查視頻幀輸入到訓練好的生成器中,以生成目標深度幀。由于在配準優化過程中目標深度幀保持不變,因此在開始迭代優化之前提取一次目標邊緣特征。
??完 整 的 注 冊 流 程 是 用C++和CUDA實 現 的 , 并 使用Nvidia? RTX 2080 TI圖形處理單元進行計算。渲染樣本評估,提取邊緣,并以每個關鍵幀4.0毫秒的平均速率計算損失。使用100個樣本的總體大小計算CMA-ES迭代。相對于(Tinitial),參數空間以θ = ±0.1弧度和t = ±7.5毫米為界。在參數采樣期間,邊界被線性縮放到均勻空間(σ = 0.1),以解釋旋轉和平移參數之間的比例差異。
3.2. 綜合數據評估
??為了定量驗證所提出算法的配準誤差,使用3D模型和BSDF渲染了10個合成視頻序列,每個序列由200幀組成,BSDF不包括在用于訓練深度估計網絡的數據集中。在每個實驗中,首先手動對齊模型初始變換,然后使用配準流水線進行優化。為了量化配準精度,我們將誤差Terror計算為
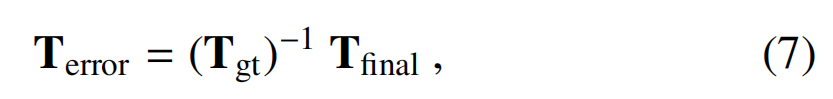
??其中Tgt是地面真值模型變換,是最終的注冊變換,兩者都是齊次形式。齊次變換Terror被分解為旋轉和平移分量,將旋轉分量轉換為歐拉形式(θ),然后獨立評估∥θ∥和∥t∥。
??使用這些合成序列和驗證度量,我們首先研究了關鍵幀K數量對配準精度的影響。對所有10個視頻序列進行了優化,范圍從1到10。結果如圖6所示。我們發現,配準精度的提高率在K等于K5時顯著降低,達到0.321毫米和0.159度的精度。與僅使用單個幀相比,這導致平移精度提高了55.6%,旋轉精度提高了60.4%。考慮到這一點,K對于剩余的實驗,K將其設置為等于5,以平衡配準精度和計算時間效率。
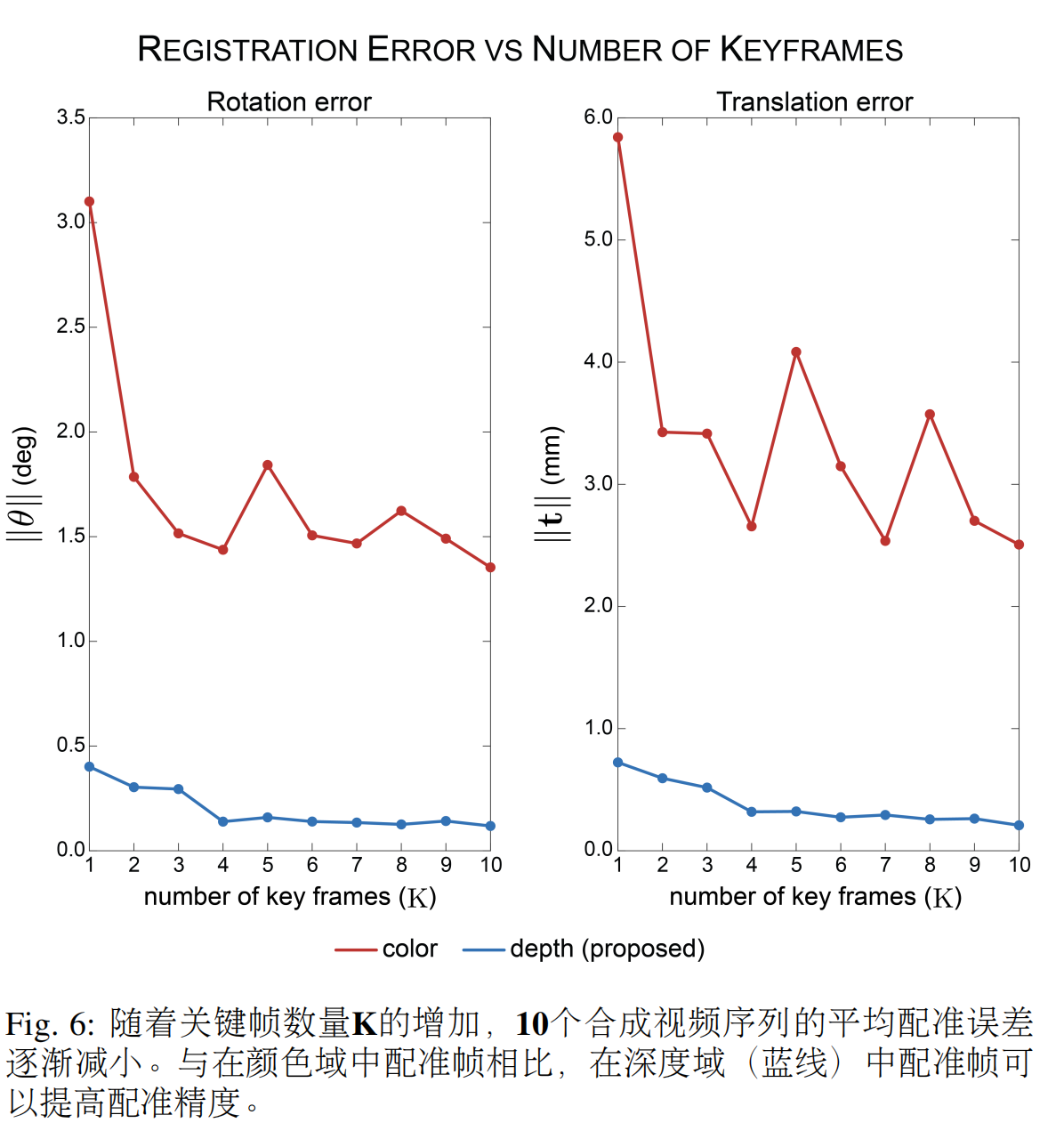
??為了評估在損失函數中使用模糊邊緣特征的效果,我們在邊緣提取之前對深度幀的對齊進行了優化實驗。基于深度的配準使用L1、、L2歸一化互相關(NCC)和梯度相關(GC)損失函數(De Silva et al., 2016)進行了優化。為了驗證我們對邊緣的損失函數選擇,我們還對L1DICE(使用二值化邊緣)和NCC損失與邊緣幀進行了實驗。表4中報告了每種輸入類型和損失函數的結果。
??為了評估在深度域中注冊的好處,我們將沒有深度變換的合成視頻幀注冊到用朗伯BSDF渲染的預測視圖中。從彩色合成幀中提取邊緣,渲染預測視圖,并使用提出的函數計算損失。這種方法的平均配準精度比深度域中的配準精度高一個數量級(圖6)。
??最后,我們研究了軌跡復雜性如何影響配準精度。合成結腸鏡檢查序列使用三種日益復雜的軌跡類型進行渲染:簡單(僅線性平移)、中等(僅螺旋平移)和復雜(帶俯仰和偏航旋轉的螺旋平移)。每種軌跡類型渲染10個合成序列,并將其注冊到地面真實3D模型中。該實驗分別導致簡單、中等和復雜軌跡的旋轉誤差為0.117度、0.063度和0.070度。對于簡單、中等和復雜的軌跡,平移誤差分別為0.150毫米、0.070毫米和0.089毫米。
3.3. 使用真實視頻序列進行評估
??一旦使用具有可用地面實況的合成數據驗證了注冊管道,該算法就被應用于真實記錄的視頻和姿勢。雖然真實數據的地面真值模型變換未知,但可以通過定性比較每個視頻的邊緣對齊質量來評估每個配準的質量。記錄序列的樣本結果如圖7所示。結果表明,配準流水線在整個視頻中將樣本幀與目標幀對齊。

四、數據集和分布格式
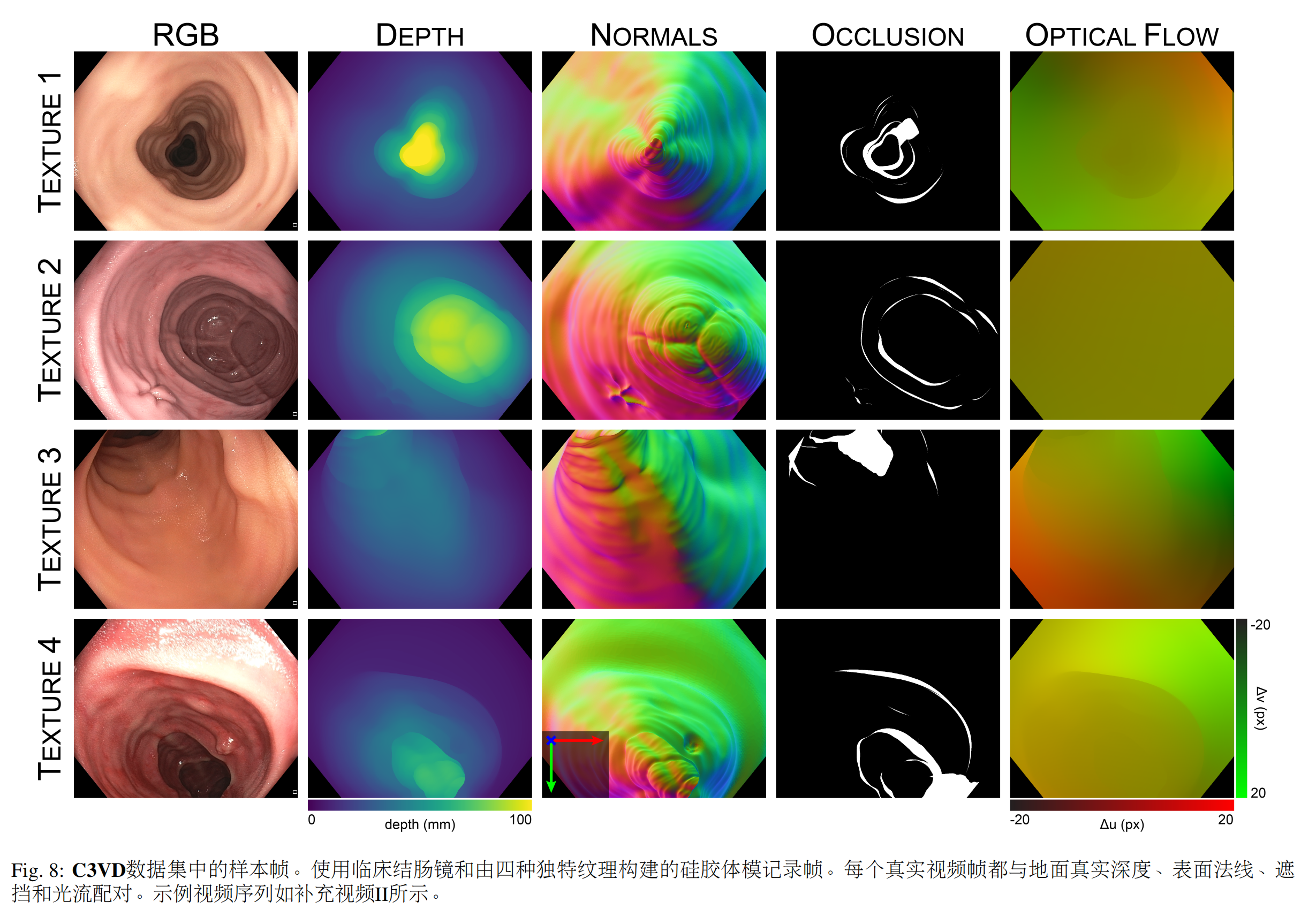
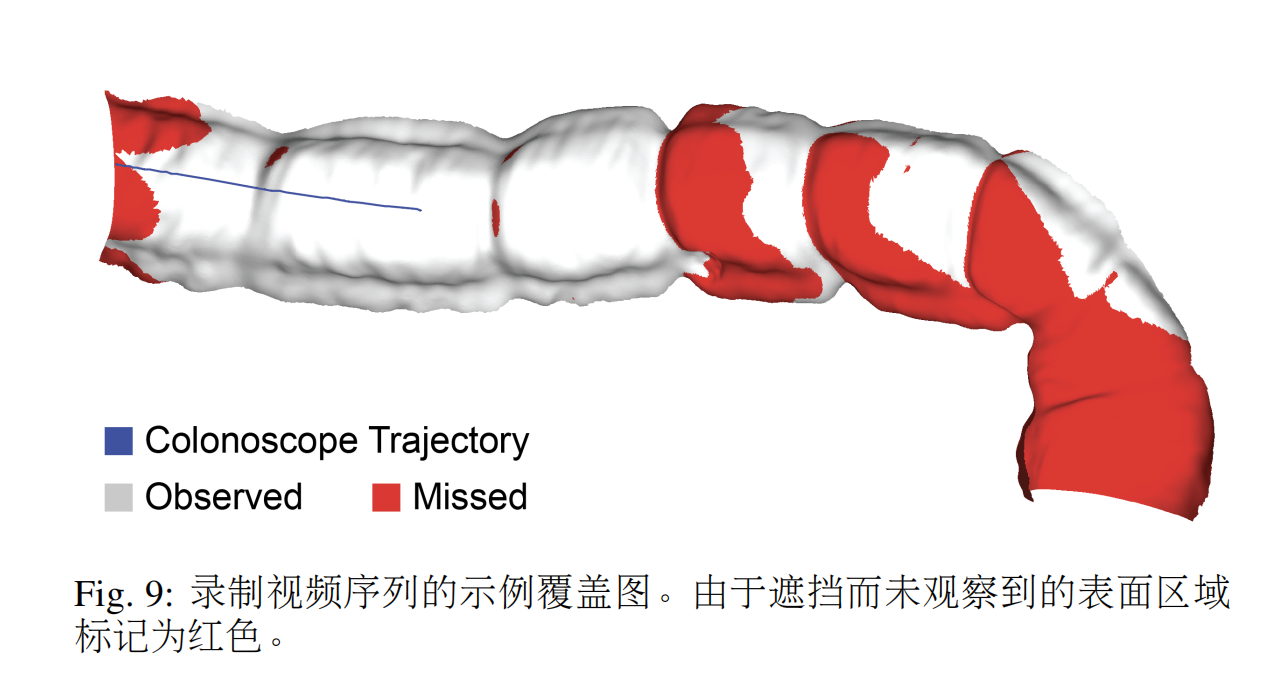
??由10015幀組成的22個視頻序列被注冊以包含在數據集中。通過調整臨床光源的照明模式(自動與手動)和照明功率設置,改變每個序列中的照明條件。這些序列還包括“桶下”、“正面”和部分遮擋的視圖的組合。表5中列出了數據集視頻序列。注冊后,虛擬相機將移動到與每個視頻幀對應的相機姿態,并為每個幀渲染地面真實深度、表面法線、遮擋和光流。示例數據集框架如圖8所示。對于每個視頻序列,通過累積整個視頻中每一幀中觀察到的表面人臉,然后標記那些未被觀察到的人臉,生成覆蓋圖。數據集中視頻序列的樣本覆蓋圖如圖9所示。對于視頻數據集中的每一幀,我們提供相應的:
? 深度幀:沿相機幀-z軸的深度,從0-100毫米夾緊。值被線性縮放并編碼為16位灰度圖像。
? 表面法線幀:相對于相機坐標系報告。X/Y/Z分量存儲在單獨的R/G/B顏色通道中。組件從±1線性縮放到0-65535。值被編碼為16位彩色圖像。
? 光流幀:從當前幀到前一幀的計算流,這意味著序列中的第一幀沒有值:Ii?1 = Ii(u + ?u, v + ?v)。值保存在彩色圖像中,其中R通道包含X方向運動(左右→,-20到20像素),G通道包含Y方向運動(上下→,-20到二十像素)。值從0線性縮放到65535,并編碼為16位彩色圖像。
? 遮 擋 幀 : 編 碼 為8位 二 進 制 圖 像 。 遮 擋 相 機 原點100毫米內其他網格面的像素被分配為255,所有其他像素被分配了0。
? 相機姿態:以均勻形式保存。
??對于每個視頻序列,我們還提供:
? 3D模型:地面實況三角網格,存儲為WavefrontOBJ文件。
? 覆蓋圖:二進制紋理,指示攝像機在視頻序列中觀察到哪些網格面(1=觀察到,2=未觀察到)。
??最 后 , 我 們 包 括 四 個 模 擬 篩 選 過 程 的 視 頻 序 列 ,由20058幀和均勻形式的地面實況相機姿態組成。
五、討論與結論
??這項工作提出了一種2D-3D配準方法,用于獲取和配準體模結腸鏡檢查視頻數據與地面真實表面模型。與
注冊單個視圖的傳統2D-3D注冊技術不同,這種方法對視頻序列和測量的姿態進行操作。我們的結果表明,與注冊單個幀相比,利用這種時間信息可以提高注冊精度(圖6)。為了避免由鏡面反射和表面紋理引起的配準誤差,我們將關鍵幀轉換到深度域進行相似性評估。轉換后的深度幀顯示出尺度不一致(圖7),這在GAN預測深度中很常見。我們發現,通過對齊從深度幀中提取的邊緣特征,可以減少這種不一致性的影響,從而進一步提高配準精度(表4)。此外,我們的損失函數優于NCC和DICE等其他指標,同時計算成本也更低。
??我們還發現,中等和復雜軌跡的配準精度優于簡單軌跡。一種可能的解釋是用于對齊的獨特邊緣特征的數量增加,以及它們在中等和復雜軌跡的成像平面中的平移增加。在配準優化之前,對輸入序列進行采樣以生成一組關鍵幀,并且所有軌跡的關鍵幀數量都是恒定的(K=5)。雖然簡單的軌跡僅包括主要在結腸長軸方向上的線性平移,但中等和復雜的軌跡還包括橫向平移以及俯仰和偏航變化。復雜軌跡中的相機姿態比簡單軌跡更加多樣化,這導致對齊的邊緣特征更加多樣化。此外,與垂直于結腸軸的相機平移相比,平行于結腸主軸的相機簡單線性平移會導致圖像特征的位移小得多。
??這種配準方法用于生成C3VD,這是第一個結腸鏡檢查重建數據集,其中包括用配準的地面真相標記的真實結腸鏡檢查視頻。與EndoSLAM數據集(Ozyoruk et al.,2021)不同,C3VD完全用HD臨床結腸鏡記錄,包括深度、表面正常、閉塞和光流幀標簽。雖然EndoSLAM使用安裝在非管狀支架上的真實豬組織,但我們選擇管狀體模模型來模擬幾何形狀逼真的管腔。通過使用真實的結腸鏡進行記錄,C3VD克服了渲染器模擬非全局照明、光散射和非線性后處理(Rau et al., 2022)的有限能力。與省略大部分角FoV的其他數據集相比,C3VD是第一個通過全向相機模型對整個結腸鏡FoV進行建模的數據集。
??C3VD可用于驗證SLAM重建算法的子組件,包括估計像素級深度、表面法線、光流和遮擋區域。地面實況表面模型和覆蓋圖可用于評估整個SLAM重建方法和技術,以識別遺漏區域。此外,3D模型資產是開源的,為渲染合成訓練數據提供了CT結腸造影體積的更高分辨率替代方案。還提供了模具文件和制造協議,以便其他研究人員可以生產和修改幻影結腸模型。模擬篩查結腸鏡檢查視頻可用于在具有真實范圍運動的全序列上測試算法。
??所提出的方法有幾個重要的局限性。需要精確的姿態測量來生成注冊的視頻序列,這些軌跡是通過將結腸鏡安裝到機器人手臂上來記錄的。雖然這種方法能夠提供幾種其他形式的地面實況信息,但運動的范圍和類型是有限的。此外,在視頻采集過程中,體模模型必須保持靜止,而結腸組織是靈活的、動態的,在成像過程中經常與內窺鏡接觸。最后,手眼校準中的小誤差會累積,導致相機軌跡逐漸漂移。未來的工作可以通過調整數據采集協議和注冊算法來改善這些局限性。更精確的射頻位置傳感器可以繞過機器人手臂施加的軌跡限制。通過共同優化模型變換和手眼變換,可以減少手眼校準誤差。這種方法也可以與動態CT配對,類似于Stoyanovet al. (2010)使用可變形結腸模型生成視頻數據。
??這里提出的C3VD數據集在多樣性和范圍方面也有重要局限性。未來的工作可以擴展這個數據集,以涵蓋更多種類的內窺鏡成像和組織狀況。對于質量度量應用,如分數覆蓋率,應開發具有各種遺漏區域的額外軌跡和結腸形狀。將3D重建算法應用于結腸鏡檢查的挑戰之一是松散的糞便和經常堵塞視野的碎片。為了模擬這些偽影,可以將人造糞便應用于硅膠模型,以涵蓋不同水平的腸道準備質量。結腸鏡的輔助噴水和抽吸系統可用于模擬視頻中的腸道清潔和水下成像。同樣,空氣和水噴嘴可用于去除物鏡上的碎屑。未來的數據集也可能受益于包括替代內窺鏡系統和模式,如窄帶成像(NBI)和染色內窺鏡。還可以探索EndoCuff(Rex et al., 2018)等遠端附件的使用及其對觀察覆蓋率的影響。最后,我們還設想生成地面真實數據,用于評估結構化照明Parot et al.(2013)和高光譜方法(Yoon et al., 2021)。這些方法的驗證數據可能包括具有調諧光學散射和吸收特性的體模,以真實地模擬光與組織的相互作用(Ayers et al., 2008; Chenet al., 2019a; Sweer et al., 2019)。





filesystem篇)
)








)



)