【目標檢測】【深度學習】【Pytorch版本】YOLOV3模型算法詳解
文章目錄
- 【目標檢測】【深度學習】【Pytorch版本】YOLOV3模型算法詳解
- 前言
- YOLOV3的模型結構
- YOLOV3模型的基本執行流程
- YOLOV3模型的網絡參數
- YOLOV3的核心思想
- 前向傳播階段
- 反向傳播階段
- 總結
前言
YOLOV3是由華盛頓大學的Joseph Redmon等人在《YOLOv3: An Incremental Improvement》【論文地址】中提出的YOLO系列單階段目標檢測模型的升級改進版,核心思想是在YOLOV2基礎上,通過引入多項關鍵技術和模塊提升檢測性能,即特征金字塔網絡(FPN)結構的多尺度特征融合、更深的Darknet-53網絡、借鑒了ResNet的殘差連接設計、改進的損失函數等使得YOLOV3在保持高速的同時,大幅提升了檢測精度。
Joseph Redmon在提出了YOLO三部曲之后,宣布退出計算機視覺研究,后續的YOLO系列是其他人在其基礎上的創新改進。
YOLOV3的模型結構
YOLOV3模型的基本執行流程
下圖是博主根據原論文繪制了YOLOV3模型流程示意圖:
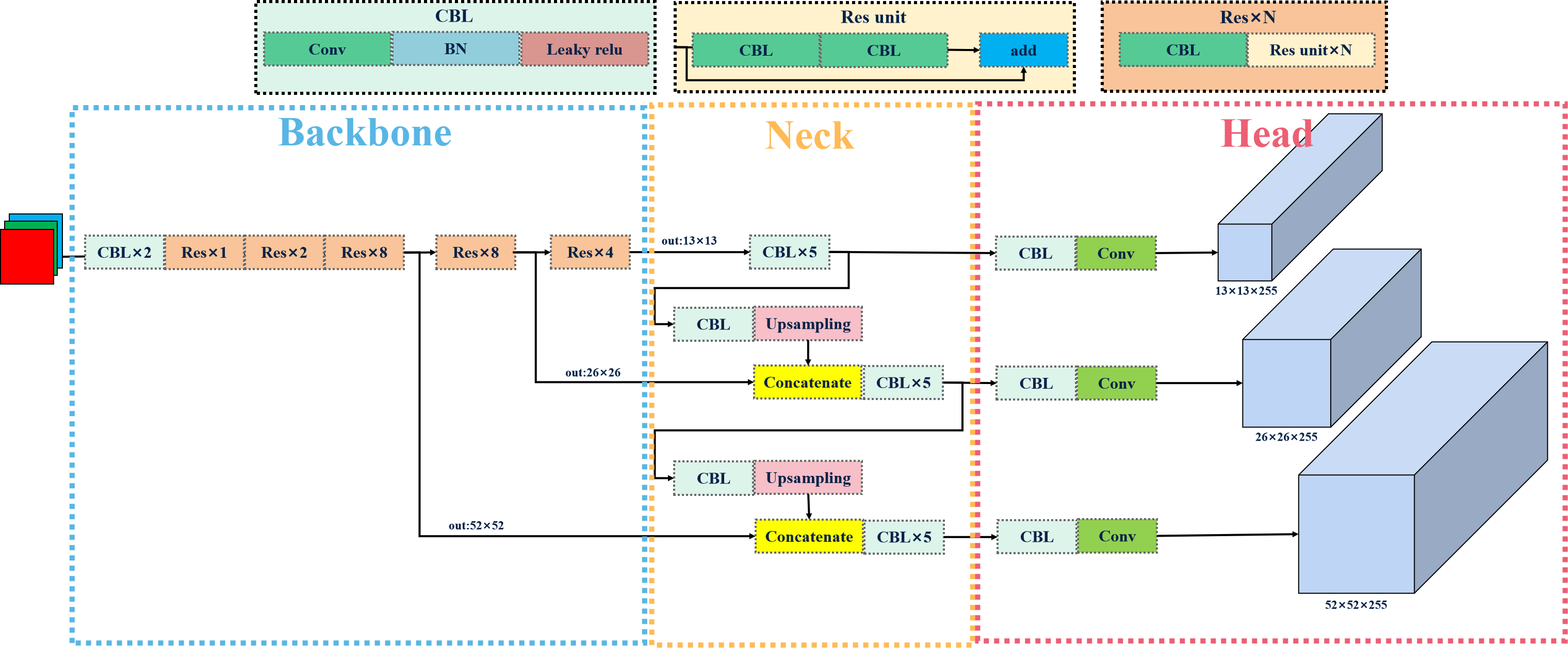
基本流程: 將輸入圖像調整為固定大小(416x416),使用Darknet-53作為骨干網絡來提取圖像的特征(包含了檢測框位置、大小、置信度以及分類概率),在三個不同尺度特征圖劃分網格,每個單元網格負責預測一定數量的邊界框及其對應的類別概率,分別對應于小、中、大尺寸目標的檢測。
YOLOV3模型的網絡參數
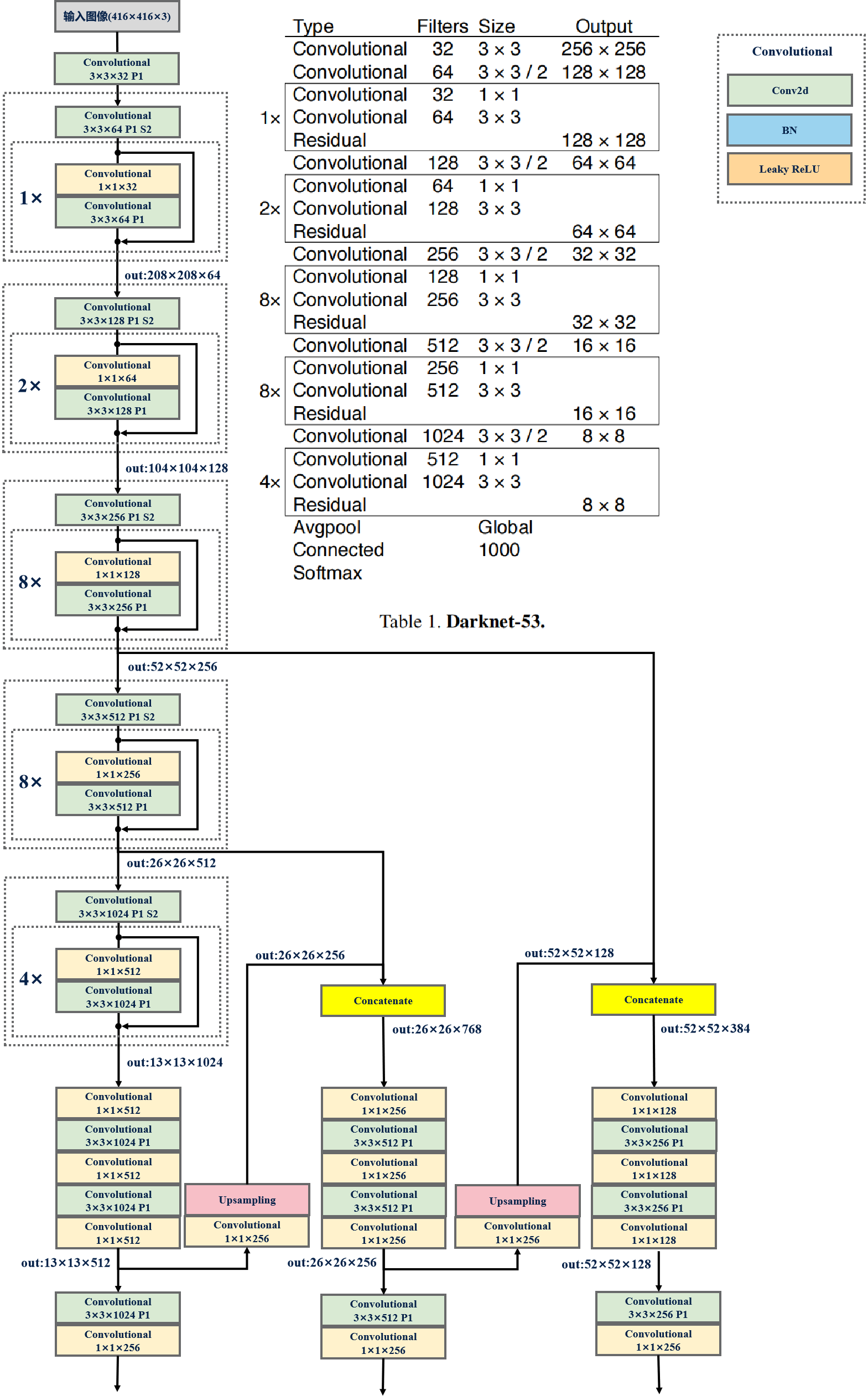
YOLOV3網絡參數: YOLOV3采用的Darknet-53結構,由于沒有全連接層,模型的輸入可以是任意圖片大小,不管是416×416還是320×320,因此可以進行多尺度訓練。
53是指有53個Convolutional層。
YOLOV3的核心思想
前向傳播階段
特征金字塔(FPN): 包含了從底層到頂層的多個尺度的特征圖,每個特征圖都融合了不同層次的特征信息,每一層都對應一個特定的尺度范圍,利用不同尺度的特征圖進行檢測,使得模型能夠同時處理不同大小的目標【參考】 。

通過以下步驟實現多尺度特征的提取和融合:
- step1(自底向上): 使用基礎網絡(ResNet等)作為骨干網絡(backbone),對輸入圖像中逐層提取特征,特征圖的分辨率逐漸降低,按照輸出特征圖分辨率大小劃分為不同的階段(stage),相鄰倆個階段的特征圖,后一個階段相對于前一個階段特征圖尺度縮小一半,通道數則增加一倍;
- step2(自頂向下): 后一階段的高層特征圖上采樣(up-sampling,通常采用2倍鄰近插值算法),使其分辨率尺寸與前一階段的低層特征圖相匹配,;
- step3(橫向連接): 將倆個特征圖進行通道拼接,完成低層特征圖的高分辨率信息與高層特征圖的豐富語義信息的融合。
檢測頭: 基于多尺度特征圖來預測目標的位置和類別,作用如下:
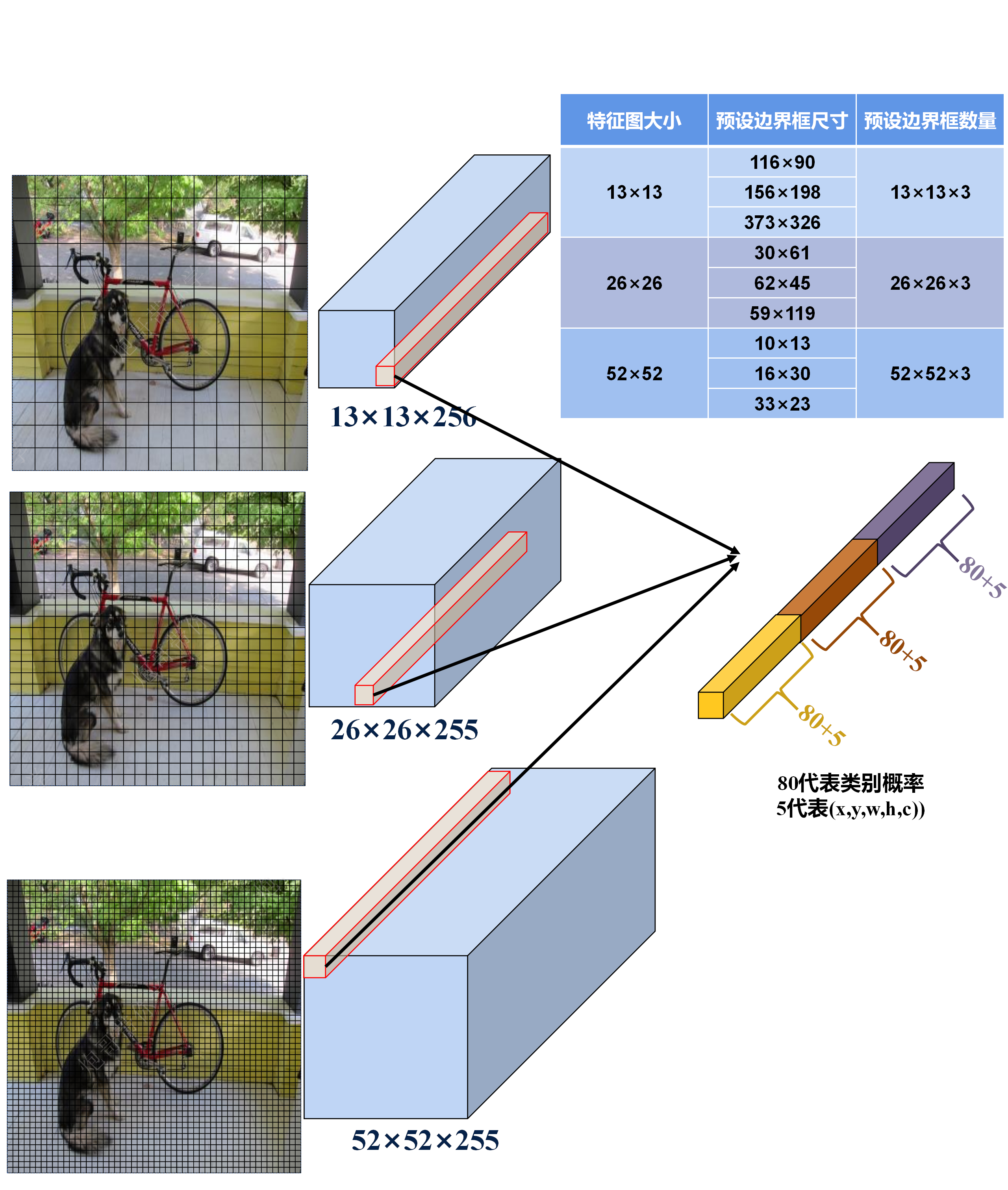
- 多尺度預測: 在三個不同尺度的特征圖上分別應用檢測頭,使得模型可以同時處理小、中、大型目標的檢測問題,有效地提高模型對不同尺寸目標的檢測能力;
- 邊界框預測: 每個檢測頭基于一組(3個)預選框(anchor boxes)負責預測邊界框,預測預選框相對于真實框(ground truth)的偏移和縮放來確定邊界框位置,預測框中目標存在的概率以及目標類別的概率來確定邊界框的類別。
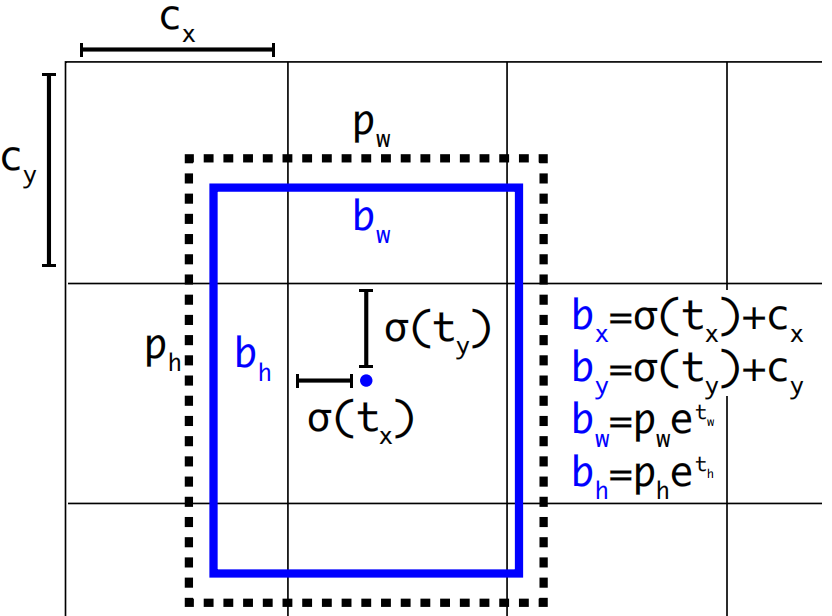
位置預測: YOLOV3延續了YOLOV2的設計,利用預選框來預測邊界框相對預選框之間的誤差補償(offsets),預測邊界框位置(中心點)在所屬網格單元左上角位置進行相對偏移值,預測邊界框尺寸基于所對應的預選框寬高進行相對縮放:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{array}{l} {b_x} = \sigma ({t_x}) + {c_x}\\ {b_y} = \sigma ({t_y}) + {c_y}\\ {b_w} = {p_w}{e^{{t_w}}}\\ {b_h} = {p_h}{e^{{t_h}}} \end{array} bx?=σ(tx?)+cx?by?=σ(ty?)+cy?bw?=pw?etw?bh?=ph?eth??
使用sigmoid函數處理偏移值,將邊界框中心點約束在所屬網格單元中,網格單元的尺度為1,而偏移值在(0,1)范圍內,防止過度偏移。
( c x , c y ) ({c_x},{c_y}) (cx?,cy?)是網格單元的左上角坐標, p w p_w pw?和 p h p_h ph?是預選框的寬度與高度, e t w e^{{t_w}} etw?和 e t h e^{{t_h}} eth?則沒有過多約束是因為物體的大小是不受限制的。
多尺度訓練: 采用不同分辨率的多尺度圖像訓練(輸入圖像尺寸動態變化),讓模型能夠魯棒地運行在不同尺寸的圖像上,提高了模型對不同尺寸目標的泛化能力 。

數據正負樣本: 、 預測框分為三 種情況::正樣本(positive)、負樣本(negative)和忽略樣本(ignore)。
-
正樣本: 任取一個真實框,計算與其類別相同的全部預測框IOU,IOU最大的預測框作為正樣本,正樣本IOU可能小于閾值。一個預測框只分配給一個真實框。正樣本產生置信度loss、檢測框loss以及類別loss,真實框的類別標簽是onehot編碼,置信度標簽為1。
當前真實框已經匹配了一個預測框,那么下一個真實框就在余下的預測框中匹配IOU最大的作為其正樣本。
-
忽略樣本: 與任意一個真實框IOU大于閾值但沒成為正樣本的預測框,就是忽略樣本。忽略樣樣本不產生任何loss。
-
負樣本: 任取一個真實框,計算與其類別相同的全部預測框IOU,IOU小于閾值的預測框作為負樣本。負樣本只產生置信度loss、真實框的置信度標簽為0。
根據上述標準,下圖中以檢測狗為例,淺綠色是真實框,綠色是正樣本預測框,橙色是忽略樣本預測框,紅色則是負樣本預測框。
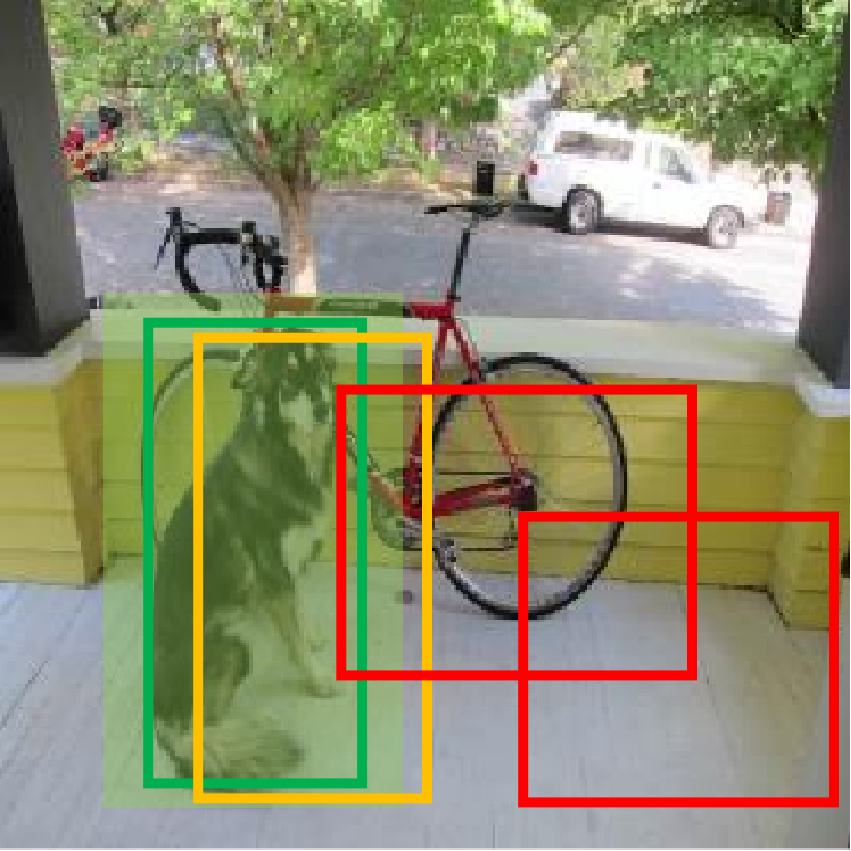
在之前的YOLO版本中,正樣本使用真實框與預測框的IOU作為置信度,置信度始終比較小,檢測的召回率不高(過濾太多找不全),特別是在學習小物體時,IOU可能更小,導致無法有效學習。YOLOV3將正樣本置信度設置為1,因為置信度本身就是二分類問題,即預測框中是不是一個真實物體,標簽是1或0更加合理。
反向傳播階段
損失函數: YOLOV3的損失函數公式為:
L o s s = ? λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ x ∧ i j log ? ( x i j ) + ( 1 ? x ∧ i j ) log ? ( 1 ? x i j ) + y ∧ i j log ? ( y i j ) + ( 1 ? y ∧ i j ) log ? ( 1 ? y i j ) ] + 1 2 λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i j ? w ∧ i j ) 2 + ( h i j ? h ∧ i j ) 2 ] ? ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ C ∧ i j log ? ( C i j ) + ( 1 ? C ∧ i j ) log ? ( 1 ? C i j ) ] ? λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i j n o o b j [ C ∧ i j log ? ( C i j ) + ( 1 ? C ∧ i j ) log ? ( 1 ? C i j ) ] ? ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ∑ c ∈ c l a s s e s [ P ∧ i j c log ? ( P i j c ) + ( 1 ? P ∧ i j c ) log ? ( 1 ? P i j c ) ] L{\rm{oss}} = - {\lambda _{coord}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{\mathop x\limits^ \wedge }_{ij}}\log ({x_{ij}}) + (1 - {{\mathop x\limits^ \wedge }_{ij}})\log (1 - {x_{ij}}) + {{\mathop y\limits^ \wedge }_{ij}}\log ({y_{ij}}) + (1 - {{\mathop y\limits^ \wedge }_{ij}})\log (1 - {y_{ij}})} \right]} } + \frac{1}{2}{\lambda _{coord}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{({w_{ij}} - {{\mathop w\limits^ \wedge }_{ij}})}^2} + {{({h_{ij}} - {{\mathop h\limits^ \wedge }_{ij}})}^2}} \right]} } - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{\mathop C\limits^ \wedge }_{ij}}\log ({C_{ij}}) + (1 - {{\mathop C\limits^ \wedge }_{ij}})\log (1 - {C_{ij}})} \right]} } - {\lambda _{noobj}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{noobj}\left[ {{{\mathop C\limits^ \wedge }_{ij}}\log ({C_{ij}}) + (1 - {{\mathop C\limits^ \wedge }_{ij}})\log (1 - {C_{ij}})} \right]} - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\sum\limits_{c \in classes} {\left[ {{{\mathop P\limits^ \wedge }_{ijc}}\log ({P_{ijc}}) + (1 - {{\mathop P\limits^ \wedge }_{ijc}})\log (1 - {P_{ijc}})} \right]} } } } Loss=?λcoord?i=0∑S2?j=0∑B?1ijobj?[x∧ij?log(xij?)+(1?x∧ij?)log(1?xij?)+y∧?ij?log(yij?)+(1?y∧?ij?)log(1?yij?)]+21?λcoord?i=0∑S2?j=0∑B?1ijobj?[(wij??w∧ij?)2+(hij??h∧?ij?)2]?i=0∑S2?j=0∑B?1ijobj?[C∧?ij?log(Cij?)+(1?C∧?ij?)log(1?Cij?)]?λnoobj?i=0∑S2?j=0∑B?1ijnoobj?[C∧?ij?log(Cij?)+(1?C∧?ij?)log(1?Cij?)]?i=0∑S2?j=0∑B?1ijobj?c∈classes∑?[P∧?ijc?log(Pijc?)+(1?P∧?ijc?)log(1?Pijc?)]
- ∑ i = 0 S 2 \sum\limits_{{\rm{i}} = 0}^{{S^2}} {} i=0∑S2?表示遍歷所有網格單元并進行累加;
- ∑ j = 0 B \sum\limits_{{\rm{j}} = 0}^B {} j=0∑B?表示遍歷所有預測邊界框并進行累加。
預測框位置損失: 計算了所有預測框的位置(中心坐標)與真實框的位置的交叉熵誤差損失和。
? λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ x ∧ i j log ? ( x i j ) + ( 1 ? x ∧ i j ) log ? ( 1 ? x i j ) + y ∧ i j log ? ( y i j ) + ( 1 ? y ∧ i j ) log ? ( 1 ? y i j ) ] - {\lambda _{coord}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{\mathop x\limits^ \wedge }_{ij}}\log ({x_{ij}}) + (1 - {{\mathop x\limits^ \wedge }_{ij}})\log (1 - {x_{ij}}) + {{\mathop y\limits^ \wedge }_{ij}}\log ({y_{ij}}) + (1 - {{\mathop y\limits^ \wedge }_{ij}})\log (1 - {y_{ij}})} \right]} } ?λcoord?i=0∑S2?j=0∑B?1ijobj?[x∧ij?log(xij?)+(1?x∧ij?)log(1?xij?)+y∧?ij?log(yij?)+(1?y∧?ij?)log(1?yij?)]
- ( x ∧ i j , y ∧ i j ) {({{\mathop {{\rm{ }}x}\limits^ \wedge }_{ij}},{{\mathop {{\rm{ y}}}\limits^ \wedge }_{ij}})} (x∧ij?,y∧?ij?)表示真實框的中心點坐標;
- ( x i j , y i j ) {({x_{ij}},{y_{ij}})} (xij?,yij?)表示預測框的中心點坐標;
- λ c o o r d {\lambda _{coord}} λcoord?表示協調系數, λ c o o r d = ( 2 ? w i j ∧ h i j ∧ ) {\lambda _{coord}} = (2 - {\mathop w\limits^ \wedge _{ij}}{\mathop h\limits^ \wedge _{ij}}) λcoord?=(2?ijw∧?ijh∧?)協調檢測目標不同大小對誤差函數的影響:檢測目標比較小時增大其對損失函數的影響,相反檢測目標比較大時消減其對損失函數的影響;
- 1 i j o b j {1_{ij}^{obj}} 1ijobj?表示當前預測框是否預測一個目標物體,如果預測一個目標則為1,否則等于0。
預測框尺度損失: 計算了所有預測框的寬高與真實框的寬高求和平方誤差損失和。
1 2 λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i j ? w ∧ i j ) 2 + ( h i j ? h ∧ i j ) 2 ] \frac{1}{2}{\lambda _{coord}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{({w_{ij}} - {{\mathop w\limits^ \wedge }_{ij}})}^2} + {{({h_{ij}} - {{\mathop h\limits^ \wedge }_{ij}})}^2}} \right]} } 21?λcoord?i=0∑S2?j=0∑B?1ijobj?[(wij??w∧ij?)2+(hij??h∧?ij?)2]
- ( w ∧ i j , h ∧ i j ) {({{\mathop {{\rm{ }}w}\limits^ \wedge }_{ij}},{{\mathop {{\rm{ h}}}\limits^ \wedge }_{ij}})} (w∧ij?,h∧ij?)表示真實框的中心點坐標;
- ( w i j , h i j ) {({w_{ij}},{h_{ij}})} (wij?,hij?)表示預測框的中心點坐標。
預測框置信度損失: 計算了所有預測框的置信度與真實框的置信度的交叉熵誤差損失和。
? ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ C ∧ i j log ? ( C i j ) + ( 1 ? C ∧ i j ) log ? ( 1 ? C i j ) ] ? λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i j n o o b j [ C ∧ i j log ? ( C i j ) + ( 1 ? C ∧ i j ) log ? ( 1 ? C i j ) ] - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{\mathop C\limits^ \wedge }_{ij}}\log ({C_{ij}}) + (1 - {{\mathop C\limits^ \wedge }_{ij}})\log (1 - {C_{ij}})} \right]} } - {\lambda _{noobj}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{noobj}\left[ {{{\mathop C\limits^ \wedge }_{ij}}\log ({C_{ij}}) + (1 - {{\mathop C\limits^ \wedge }_{ij}})\log (1 - {C_{ij}})} \right]} } ?i=0∑S2?j=0∑B?1ijobj?[C∧?ij?log(Cij?)+(1?C∧?ij?)log(1?Cij?)]?λnoobj?i=0∑S2?j=0∑B?1ijnoobj?[C∧?ij?log(Cij?)+(1?C∧?ij?)log(1?Cij?)]
- C ∧ i j {{{\mathop C\limits^ \wedge }_{ij}}} C∧?ij?表示真實框的置信度,包含檢測目標取值為1,否則還是0;
- C i j {{C_{ij}}} Cij?表示預測框的置信度;
- λ n o o b j {\lambda _{noobj}} λnoobj?表示預測框沒有目標的權重系數,通常大部分預測框都不包含檢測目標物體,導致模型預測傾向于預測框中沒有目標物體,因此必須減少沒有目標物體的預測框的損失權重。
預測框類別損失: 計算了所有預測框的類別概率與真實框的類別概率的交叉熵誤差損失和。
? ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ∑ c ∈ c l a s s e s [ P ∧ i j c log ? ( P i j c ) + ( 1 ? P ∧ i j c ) log ? ( 1 ? P i j c ) ] - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\sum\limits_{c \in classes} {\left[ {{{\mathop P\limits^ \wedge }_{ijc}}\log ({P_{ijc}}) + (1 - {{\mathop P\limits^ \wedge }_{ijc}})\log (1 - {P_{ijc}})} \right]} } } ?i=0∑S2?j=0∑B?1ijobj?c∈classes∑?[P∧?ijc?log(Pijc?)+(1?P∧?ijc?)log(1?Pijc?)]
- P ∧ i j c {{{\mathop P\limits^ \wedge }_{ijc}}} P∧?ijc?表示真實框的類別概率,onehot編碼,所屬的類別概率為1,其他類概率為0;
- P i j c {{P_{ijc}}} Pijc?表示預測框的類別概率。
在YOLOV1和YOLOV2利用softmax來進行概率預測,這種激活函數讓所有類別的概率相加等于1,因此只能進行單一分類預測,而在YOLOV3中將softmax修改成sigmoid函數,對不同類別單獨進行二分類概率預測,因此進行多標簽類別的分類預測。
YOLOV3可以同時是動物和豬倆類(sigmoid函數),而不是動物和豬中選擇概括最大的一類(softmax函數)。
總結
盡可能簡單、詳細的介紹了YOLOV3模型的結構,深入講解了YOLOV3核心思想。






)



)








——自適應優化系統、遺傳算法調參、Service Worker智能降級方案)