目錄
1.@TableName
1.1 問題
1.2 通過@TableName解決問題
1.3 通過全局配置解決問題
2.@TableId
2.1 問題
2.2 通過@TableId解決問題
2.3 @TableId的value屬性
2.4 @TableId的type屬性
2.5 雪花算法
1.背景
2.數據庫分表
①垂直分表
②水平分表
1>主鍵自增
2>取模
3> 雪花算法
3.@TableField
3.1 情況1:駝峰命名
3.2 情況2:屬性字段不一樣
4.@TableLogic
4.1 邏輯刪除
4.2 實現邏輯刪除
?4.3 查詢
1.@TableName
????????經過以上的測試,在使用MyBatis-Plus實現基本的CRUD時,我們并沒有指定要操作的表,只是在?Mapper接口繼承BaseMapper時,設置了泛型User,而操作的表為user表
????????由此得出結論,??MyBatis-Plus在確定操作的表時,由BaseMapper的泛型決定,即實體類型決定,且默認操作的表名和實體類型的類名一致.
1.1 問題
????????若實體類類型的類名和要操作的表的表名不一致,會出現什么問題?
????????????????我們將表user更名為t_user?,測試查詢功能
????????程序拋出異常, ?Table?'mybatis_plus.user'doesn't?exist,因為現在的表名為t_user?,而默認操作的表名和實體類型的類名一致,即user表

1.2 通過@TableName解決問題
????????在實體類類型上添加@TableName("t_user"),標識實體類對應的表,即可成功執行SQL語句


1.3 通過全局配置解決問題
????????在開發的過程中,我們經常遇到以上的問題,即實體類所對應的表都有固定的前綴,例如t_或tbl_
????????此時,可以使用MyBatis-Plus提供的全局配置,為實體類所對應的表名設置默認的前綴,那么就不需要在每個實體類上通過@TableName標識實體類對應的表。
# 配置MyBatis日志
mybatis-plus:configuration:# 配置MyBatis日志log-impl: org.apache.ibatis.logging.stdout.StdOutImplglobal-config:db-config:# 配置MyBatis-Plus操作表的默認前綴table-prefix: t_2.@TableId
????????經過以上的測試,??MyBatis-Plus在實現CRUD時,會默認將id作為主鍵列,并在插入數據時,默認 基于雪花算法的策略生成id.
2.1 問題
????????若實體類和表中表示主鍵的不是id,而是其他字段,例如uid?,?MyBatis-Plus會自動識別uid為主鍵列嗎?
????????我們實體類中的屬性id改為uid,將表中的字段id也改為uid,測試添加功能


程序拋出異常,??Field?'uid'doesn't?have?a?default value,說明MyBatis-Plus沒有將uid作為主鍵?賦值

2.2 通過@TableId解決問題
? ????????在實體類中uid屬性上通過@TableId將其標識為主鍵,即可成功執行SQL語句

2.3 @TableId的value屬性
????????若實體類中主鍵對應的屬性為id,而表中表示主鍵的字段為uid,此時若只在屬性id上添加注解 ??@TableId,則拋出異常Unknown?column'id'in'field?list',即MyBatis-Plus仍然會將id作為表的?主鍵操作,而表中表示主鍵的是字段uid
????????此時需要通過@TableId注解的value屬性,指定表中的主鍵字段,??@TableId("uid")或@TableId(value="uid")


2.4 @TableId的type屬性
?type屬性用來定義主鍵策略
常用的主鍵策略:
值
描述
IdType.ASSIGN_ID?(默?認)
基于雪花算法的策略生成數據id,與數據庫id是否設置自增無關
IdType.AUTO
使用數據庫的自增策略,注意,該類型請確保數據庫設置了id自增,?否則無效
配置全局主鍵策略:
# 配置MyBatis日志
mybatis-plus:configuration:# 配置MyBatis日志log-impl: org.apache.ibatis.logging.stdout.StdOutImplglobal-config:db-config:# 配置MyBatis-Plus操作表的默認前綴table-prefix: t_# 配置MyBatis-Plus的主鍵策略id-type: auto2.5 雪花算法
1.背景
????????需要選擇合適的方案去應對數據規模的增長,以應對逐漸增長的訪問壓力和數據量。
????????數據庫的擴展方式主要包括:
????????????????業務分庫、主從復制,數據庫分表。
分庫:比如淘寶,VIP用戶有一個庫,普通用戶一個庫
主從復制:備份
分表:100萬按照什么規則分表
2.數據庫分表
????????將不同業務數據分散存儲到不同的數據庫服務器,能夠支撐百萬甚至千萬用戶規模的業務,但如果業務繼續發展,同一業務的單表數據也會達到單臺數據庫服務器的處理瓶頸。例如,淘寶的幾億用戶數據,??如果全部存放在一臺數據庫服務器的一張表中,肯定是無法滿足性能要求的,此時就需要對單表數據進行拆分。
????????單表數據拆分有兩種方式:垂直分表和水平分表。示意圖如下:

①垂直分表
????????垂直分表適合將表中某些不常用且占了大量空間的列拆分出去。
????????例如,前面示意圖中的 nickname?和 description?字段,假設我們是一個婚戀網站,用戶在篩選其他用戶的時候,主要是用 age?和 sex?兩個字段進行查詢,而 nickname?和 description?兩個字段主要用于展?示,?一般不會在業務查詢中用到。description?本身又比較長,因此我們可以將這兩個字段獨立到另外???一張表中,這樣在查詢 age?和 sex?時,就能帶來一定的性能提升。
②水平分表
????????水平分表適合表行數特別大的表,有的公司要求單表行數超過 5000 萬就必須進行分表,這個數字可以?作為參考,但并不是絕對標準,關鍵還是要看表的訪問性能。對于一些比較復雜的表,可能超過 1000??萬就要分表了;而對于一些簡單的表,即使存儲數據超過 1 億行,也可以不分表。
????????但不管怎樣,當看到表的數據量達到千萬級別時,作為架構師就要警覺起來,因為這很可能是架構的性能瓶頸或者隱患。
????????水平分表相比垂直分表,會引入更多的復雜性,例如要求全局唯一的數據id該如何處理
1>主鍵自增
????????①以最常見的用戶?ID 為例,可以按照 1000000?的范圍大小進行分段, ??1?~?999999 放到表 1中,?1000000?~?1999999 放到表2中,以此類推。
????????因為是自動遞增的,所以刪除一條數據在增加,ID是后面的,會導致一個表里數據多,一個表少。服務器承受的力度不一樣。(比如,第一個表刪除5號ID,再新增,ID就是6,這樣就會導致實際的表中沒有那么多數據。那么管理這個表的服務器實際上只管理那么一點數據。)
????????②復雜點:分段大小的選取。
????????????????分段太小會導致切分后子表數量過多,增加維護復雜度;
????????????????分段太大可能會?導致單表依然存在性能問題, ?
????????????????一般建議分段大小在 100 萬至 2000?萬之間,具體需要根據業務選取合適?的分段大小。
????????③優點:可以隨著數據的增加平滑地擴充新的表。例如,現在的用戶是 100 萬,如果增加到 1000 萬,?只需要增加新的表就可以了,原有的數據不需要動。
????????④缺點:分布不均勻。假如按照 1000 萬來進行分表,有可能某個分段實際存儲的數據量只有 1 條,而?另外一個分段實際存儲的數據量有 1000 萬條。
2>取模
????????①同樣以用戶 ID?為例,假如我們一開始就規劃了 10?個數據庫表,可以簡單地用 user_id?%?10?的值來表示數據所屬的數據庫表編號,??ID 為 985?的用戶放到編號為 5?的子表中, ??ID 為 10086?的用戶放到編號為 6?的子表中。
????????②復雜點:初始表數量的確定。表數量太多維護比較麻煩,表數量太少又可能導致單表性能存在問題。
????????③優點:表分布比較均勻。
????????④缺點:擴充新的表很麻煩,所有數據都要重分布。
3> 雪花算法
前兩種都是基于主鍵自增的。
????????雪花算法是由Twitter公布的分布式主鍵生成算法,它能夠保證不同表的主鍵的不重復性,以及相同表的?主鍵的有序性。
①核心思想:
????????長度共64bit(一個long型)。
????????首先是一個符號位,??1bit標識,由于long基本類型在Java中是帶符號的,最高位是符號位,正數是0,負 數是1,所以id一般是正數,最高位是0。
????????41bit時間截(毫秒級),存儲的是時間截的差值(當前時間截 - 開始時間截),結果約等于69.73年。
????????10bit作為機器的ID(?5個bit是數據中心,??5個bit的機器ID,可以部署在1024個節點)。
????????12bit作為毫秒內的流水號(意味著每個節點在每毫秒可以產生 4096 個 ID)。

②優點:整體上按照時間自增排序,并且整個分布式系統內不會產生ID碰撞,并且效率較高。
3.@TableField
????????經過以上的測試,我們可以發現,??MyBatis-Plus在執行SQL語句時,要保證實體類中的屬性名和表中的字段名一致
????????如果實體類中的屬性名和字段名不一致的情況,會出現什么問題呢?
3.1 情況1:駝峰命名
????????若實體類中的屬性使用的是駝峰命名風格,而表中的字段使用的是下劃線命名風格
例如實體類屬性userName,表中字段user_name
此時MyBatis-Plus會自動將下劃線命名風格轉化為駝峰命名風格
????????相當于在MyBatis中配置駝峰config配置。
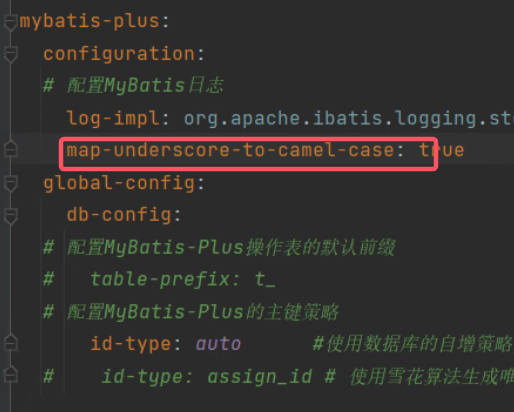
?????????默認開啟,在這里關閉他不會報錯,但是相關字段是null值。
3.2 情況2:屬性字段不一樣
????????若實體類中的屬性和表中的字段不滿足情況1
例如實體類屬性name?,表中字段username
此時需要在實體類屬性上使用@TableField("username")設置屬性所對應的字段名

4.@TableLogic
4.1 邏輯刪除
? ????????物理刪除:真實刪除,將對應數據從數據庫中刪除,之后查詢不到此條被刪除的數據
?? ????????邏輯刪除:假刪除,將對應數據中代表是否被刪除字段的狀態修改為“被刪除狀態”,之后在數據庫中仍舊能看到此條數據記錄
?? ????????使用場景:可以進行數據恢復
? ? ? ? 所以,像那種政府、公司等都會設置邏輯刪除,更安全,誤刪還能恢復。
4.2 實現邏輯刪除
step1?:數據庫中創建邏輯刪除狀態列,設置默認值為0

step2?:實體類中添加邏輯刪除屬性

step3?:測試
測試刪除功能,真正執行的是修改
UPDATE t_user SET is_deleted=1 WHERE id=? AND is_deleted=0測試查詢功能,被邏輯刪除的數據默認不會被查詢
SELECT id,username AS name,age,email,is_deleted FROM t_user WHERE is_deleted=0@Autowired
private PeopleMapper peopleMapper;
@Test
public void testDeleted(){peopleMapper.deleteById(7L);}
?4.3 查詢
@Test
public void testSelect(){peopleMapper.selectList(null);
}

)






:字符串切片)


)




)


)
