文章目錄
- 1、前置知識
- 1.1、Buffer Pool介紹
- 1.2、后臺線程
- 1.2.1、Master Thread
- 1.2.2、IO Thread
- 1.2.3、Purge Thread
- 1.2.4、Page Cleaner Thread
- 1.3、重做日志緩沖池
- 2、Buffer Pool 組成
- 2.1、數據頁
- 2.2、索引頁
- 2.3、undo頁
- 2.4、插入緩沖
- 2.5、鎖空間
- 2.6、數據字典
- 2.6、自適應哈希索引
- 3、Buffer Pool 內存管理
- 3.0、控制塊
- 3.1、Free List
- 3.2、Flush List
- 3.3、LRU List
1、前置知識
1.1、Buffer Pool介紹
MySQL數據庫具有可拔插的存儲引擎,其中最常用的是InnoDB,而Buffer Pool緩沖池是InnoDB存儲引擎中特有的內存結構,MySQL向操作系統內存申請一塊內存空間用于Buffer Pool緩沖池使用,因為硬盤和內存性能差距大,所以Buffer Pool緩沖池用于協調CPU速度和硬盤速度的鴻溝,Buffer Pool大幅度提升MySQL數據庫的讀寫性能。
按照我們的慣性思維,這里會有一個疑問:不都說MySQL的數據是基于硬盤存儲嗎,為什么這里會提到Buffer Pool緩沖池內存這概念?
MySQL當然是通過硬盤
持久化存儲,Buffer Pool并不是 MySQL 真正意義上存儲數據的單元載體。
MySQL僅僅是借助Buffer Pool提升讀寫性能,畢竟內存的訪問速度要比硬盤快得多!這并不沖突。
我們進行數據的查詢操作,MySQL并不是直接從硬盤文件中查找對應的數據信息,會先查看Buffer Pool中是否有想要查詢數據。如果有,直接返回給用戶;如果沒有,去硬盤中的查詢想要的數據。查詢到結果后會同步到Buffer Pool中,下次用戶再次發起查詢就不用訪問磁盤了,修改操作也是同理(先操作Buffer Pool中的數據,然后數據刷入硬盤的文件中,有點像Redis),我們先站在操作系統維度看看 Buffer Pool 在內存中的樣貌:
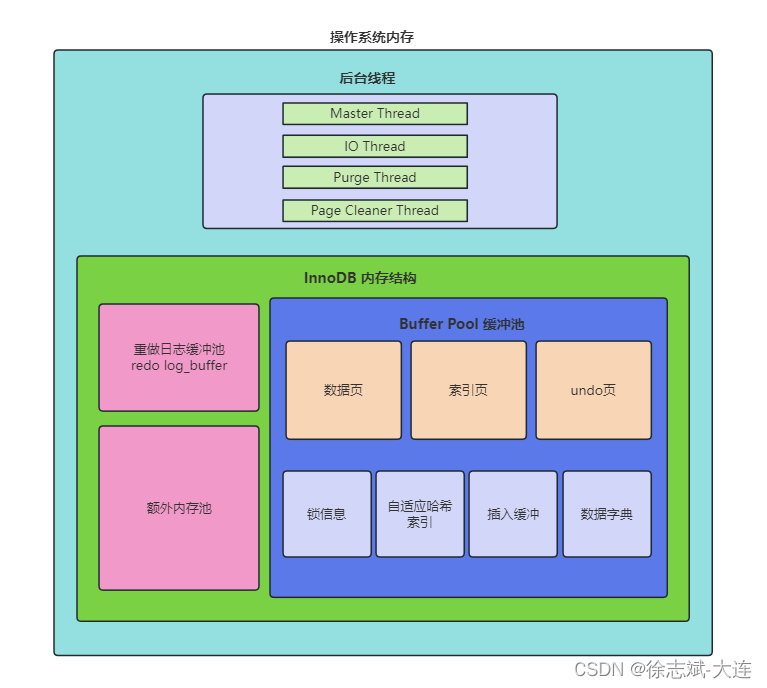
Buffer Pool緩沖池有數據頁,硬盤中MySQL表數據加載到Buffer Pool中就是通過數據頁來存放的,Buffer Pool默認大小128MB,InnoDB存儲引擎已經將硬盤中的數據劃分為一個個頁,默認大小16KB,通過頁為基本單位,進行硬盤與內存之間的交互。
上面提到了查詢、修改等SQL操作,無論是Buffer Pool將修改的頁刷盤到硬盤,還是從硬盤加載到Buffer Pool,都是以數據頁為單元進行操作的,而不是操作頁中的某幾行數據。
這里有個注意點,Buffer Pool緩沖池并不是只有一個的,可以申請多個內存區域作為緩沖池同時工作。
1.2、后臺線程
之前提到一個概念叫做刷盤,意思是Buffer Pool中緩存頁數據會異步刷新到硬盤中,保證了數據的一致性,后臺線程的主要作用就是對緩沖池中的頁進行進行操作。InnoDB存儲引擎后臺線程主要有以下幾種:
1.2.1、Master Thread
該線程主要用于將Buffer Pool 緩沖池中的數據進行刷盤,保證數據一致性。主要主責包括:臟頁刷盤、插入緩沖合并、undo頁回收等。
1.2.2、IO Thread
該線程主要用于處理AIO(Async IO)請求回調,因為InnoDB存儲引擎中存在大量的異步IO操作,IO Thread可以極大數據庫性能。
1.2.3、Purge Thread
當事務提交之后,undo頁就沒有任何存在的意義了,該線程主要職責就是回收無用的undo頁。
上面1.2.1 Master Thread中提到,Master Thread主要職責就包括了回收undo頁,但是后續InnoDB版本開始將部分purge操作交給Purge Thread來完成,減少Master Thread的工作壓力,提升性能。也就是說回收undo頁功能Master Thread和Purge Thread都具備,該線程就是為了替Master Thread分擔回收undo頁的工作壓力。
1.2.4、Page Cleaner Thread
該線程也是為Master Thread分擔工作壓力,提升數據庫性能。不過Page Cleaner Thread分擔了什么壓力呢?臟頁刷盤操作。
1.3、重做日志緩沖池
硬盤中存在重做日志文件,主要用于故障恢復,保證MySQL事務的持久性,重做日志緩沖池就是用于存放重做日志信息,然后按照一定頻率刷盤重做日志文件中,常用于數據庫的故障恢復場景,這并不是本文章的重點。
2、Buffer Pool 組成
2.1、數據頁
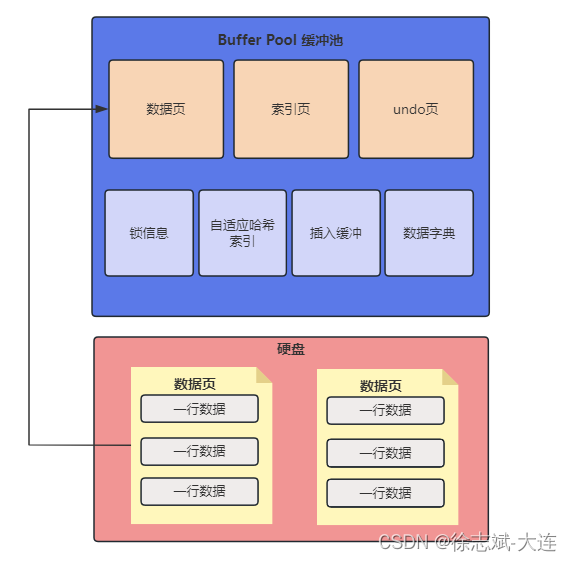
當我們進行查詢的數據不在緩沖池中時,就會將磁盤中的數據對應的頁加載到Buffer Pool中,這就是數據頁。當我們對數據頁內容進行修改,此時數據頁就會變成臟頁,而不是直接操作硬盤中的文件頁,只需要將臟頁刷新到磁盤中,這樣通過頁為單位交互性能好很多。
2.2、索引頁
Buffer Pool緩沖池中,不僅會存放數據頁,還會存放索引頁。
之所以這樣,是因為我們不能保證每次查詢操作都能從緩沖池的數據頁中拿到想要的結果,此時就需要對磁盤中數據文件進行IO訪問操作。如果本次的查詢操作命中了索引,我們又該如何知道索引的根節點到底在磁盤中的哪個位置呢?這個時候就需要索引頁來幫助我們,當MySQL實例啟動時,就會將數據庫中的索引根節點放入到緩沖池的索引頁中,當我們的查詢SQL命中了索引,就不需要在整個磁盤中查找對應的索引根節點了!
2.3、undo頁
undo頁主要記錄事務回滾操作信息,常用于事務回滾操作。
事務如何通過undolog進行回滾操作呢?這個很好理解,我們只需要在undolog日志中記錄事務中的反向操作即可,例如:
事務進行
insert操作,undolog記錄delete操作
事務進行delete操作,undolog記錄insert操作
事務進行update操作(a改為b),undolog記錄update操作(b改為a)
2.4、插入緩沖
插入緩沖只針對非聚集、不唯一索引頁增、刪、改操作。
當我們對非聚集、不唯一索引頁進行插入、修改操作時,不是直接操作索引頁,而是先判斷當前索引頁是否在Buffer Pool緩沖池中,如果在直接操作索引頁即可,如果不在就放入Insert Buffer對象中,然后以一定頻率進行插入緩沖和輔助索引頁合并操作,大大提升非聚集索引操作性能!
那為什么聚集索引或者說主鍵索引不需要插入緩沖?因為主鍵索引插入操作是按照主鍵順序遞增的,屬于順序插入,不需要隨機讀取硬盤,性能很快。
2.5、鎖空間
鎖空間就是專門用來存儲鎖結構、并發事務的鏈表的一塊內存區域,這里不過多介紹。
2.6、數據字典
MySQL數據庫啟動時,會自動從硬盤中將系統表相關信息加載到Buffer Pool緩沖池中,有了數據字典,這樣當我們使用show index、show tables相關命令就能查到表、索引相關的信息,主要分為以下:
SYS_TABLES:存儲所有InnoDB表信息。
SYS_COLUMNS:存儲所有用戶定義的表字段信息。
SYS_INDEXES:存儲所有InnoDB引擎表索引信息。
SYS_FIELDS:存儲所有索引的定義信息。
2.6、自適應哈希索引
默認情況下,我們的索引頁采用B+Tree的結構,大幅度提高我們對數據庫的查詢性能,雖然性能已經很好了,但是自適應哈希索引的性能棒不得了!O(1)時間復雜度,查詢性能非常高。
自適應哈希索引不需要我們主動人為干涉,它是InnoDB自動生成的,自適應哈希索引針對是熱點索引頁,而不是整張表,并且生成的條件也比較苛刻。當我們對某個索引頁連續的訪問模式條件一樣,訪問模式例如:
where a = xxx
where a = xxx and b = yyy
上面舉例這兩種訪問模式不能交替執行,否則也不會生成自適應哈希索引,那何時自動生成呢,有以下兩種情況:
以某個模式訪問100次
以某個模式訪問 n 次(n = 頁中記錄 / 16)
3、Buffer Pool 內存管理
3.0、控制塊
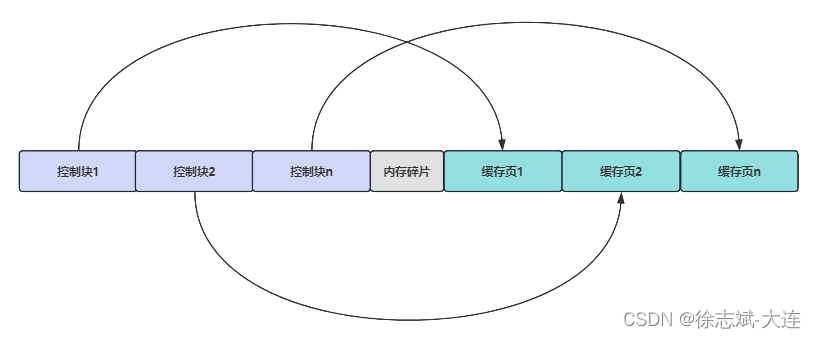
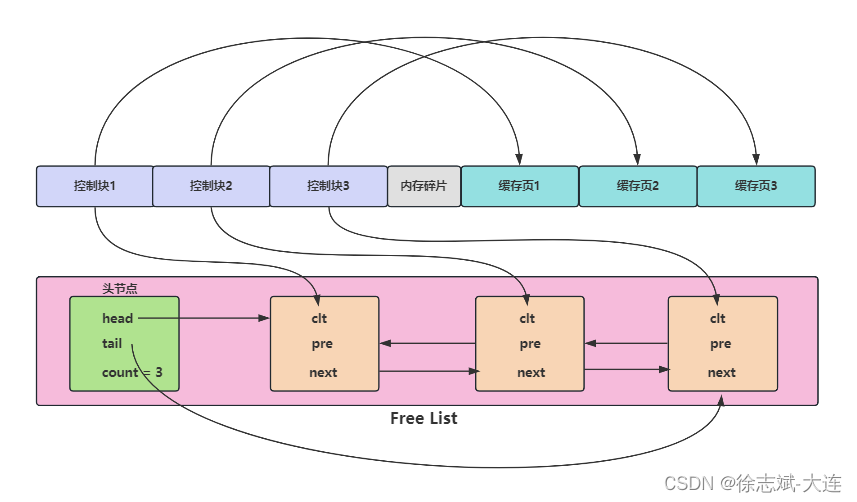
InnoDB在操作系統中為Buffer Pool緩沖池申請創建了一塊連續的內存,內存被劃分成一塊塊緩沖頁(之前提過緩沖池是以頁為基本單位與磁盤進行交互),InnoDB存儲引擎為緩沖池中每個緩沖頁都生成了一個控制塊,一對一關系。
控制塊中記錄了數據頁所屬的表空間、頁號、緩沖頁地址、鏈表節點指針等信息。控制塊和緩存頁關系圖如下:發現圖中有個內存碎片,這是因為緩沖池剩余空間不夠一對控制塊和緩存頁的大小,這點剩余內存空間就被稱為內存碎片:
3.1、Free List
Buffer Pool緩沖池內存被劃分為一個個頁,但并不是所有頁都被使用,有一些頁是處于空閑狀態的(沒存數據),這種空閑頁會被Free List進行管理,方便快速查找使用。
當硬盤中的頁刷入到Buffer Pool緩沖池中時,就會從Free List中查找是否有空閑頁,如果有,就將空閑頁從Free List中取出使用(移除);如果沒有,就會使用后續提到的LRU List列表的尾部的數據頁。下圖中頭節點解釋:
head:指針,指向 Free List 的第一個控制塊。
ail:指針,指向 Free List 的最后一個控制塊。
count:數字,記錄 Free List 的節點數量。
3.2、Flush List
之前提到過臟頁刷盤這個操作,所謂臟頁就是緩沖池中緩存頁中內容發生了改變(修改、刪除、新增),此時這個該頁就稱為臟頁。臟頁數據和磁盤中文件數據是不一致的,需要后臺線程將數據異步刷新到磁盤中。這些臟頁的管理就需要Flush List,結構圖跟3.1 Free List大同小異,這里就不重復畫了。
3.3、LRU List
知道了Free List維護空閑頁,Flush List維護臟頁,那么LRU List維護的是什么頁?
LRU List用來管理已經讀取的頁,所以當數據庫剛啟動時,LRU List也是空的,這時候的空閑頁都在Free List中,當需要從硬盤中加載數據頁到Buffer Pool時,就會從Free List查找是否有空閑頁可以使用,如果沒有空閑頁就根據LRU算法淘汰LRU List尾部頁,將內存空間分配給新頁。
硬盤中的頁加載到緩沖池中,沒有任何修改操作,那就說這個緩沖頁是干凈的(干凈頁),或者說臟頁數據刷盤到磁盤后,就變成了干凈頁。不過有一點需要強調,當我們對干凈頁進行修改操作時,也就是它變成了臟頁,此時臟頁也不會從LRU List中移除,這個臟頁將會同時存在于LRU List和Flush List中。
關于
臟頁是否同時在LRU、Flush List中存在,這里有些爭議,有些人認為臟頁不在LRU List中記錄,只在Flush List中記錄;
不過《MySQL技術內幕 InnoDB存儲引擎》這本書中介紹的是:臟頁既存在于LRU List,也存在于Flush List
LRU List管理緩存頁是通過LRU算法,就是說訪問頻率低(最近最少使用)的緩存頁將會放到LRU List列表尾部,訪問頻率比較高的熱點頁將會放到LRU List首部,當可用的空閑頁不足時,就會淘汰LRU List鏈表末尾的數據頁。我們先來看下LRU List大致是什么樣子:

LRU List的LRU算法跟常規的LRU算法是有區別的,InnoDB之所以使用特殊的LRU算法,主要是考慮到傳統的LRU算法有這兩個問題:
- 預讀無效
- Buffer Pool污染
預讀的意思是 Buffer Pool 在加載數據頁時,會把它相鄰的數據頁一起加載到緩沖池中,目的是減少了磁盤IO操作。不過常規LRU算法會將預讀的數據頁也放置到LRU List頭部,這樣可能出現預讀數據頁幾乎不會使用到(大大降低LRU List的使用性能)。
Buffer Pool污染大概也是這個意思,如果偶爾做一次大數據量的表查詢操作(全表掃描),直接出現許多不常用數據頁在LRU List頭部,導致本身的熱點頁被移除。降低了LRU List使用性能。
針對以上常規LRU算法所帶來的問題,LRU List是用了特殊LRU算法。上圖中可以看到midpoint,通過midpoint為分界線,將midpoint左側數據頁區域稱為NEW區,右側稱為OLD區。NEW區域的數據頁是經常使用、訪問的,這些數據頁我們稱之為熱點頁,midpoint位于LRU List鏈表的5/8處(37 : 63),這個比例可以通過參數innodb_old_blocks_pct調整,這樣我們最新訪問的數據頁不會直接放到NEW區域的頭部,而是放到OLD區域的頭部。
那么什么時候會從OLD區移動到NEW區呢?InnoDB存儲引擎通過一個時間參數innodb_old_blocks_time控制頁讀取到midpoint位置時,等待多久才會加入到NEW區,這個時間默認為1000ms。如果后續的訪問時間與第一次訪問的時間不在這個時間間隔內,那么該緩存頁就會移動到 NEW 區域的頭部,這就是LRU List管理緩存頁的方式。




的中心位置)




)




_29_PPP協議判斷【6道題】)


 和 post() 方法—— W3school 詳解 簡單易懂(二十四))
)
)