Java IO
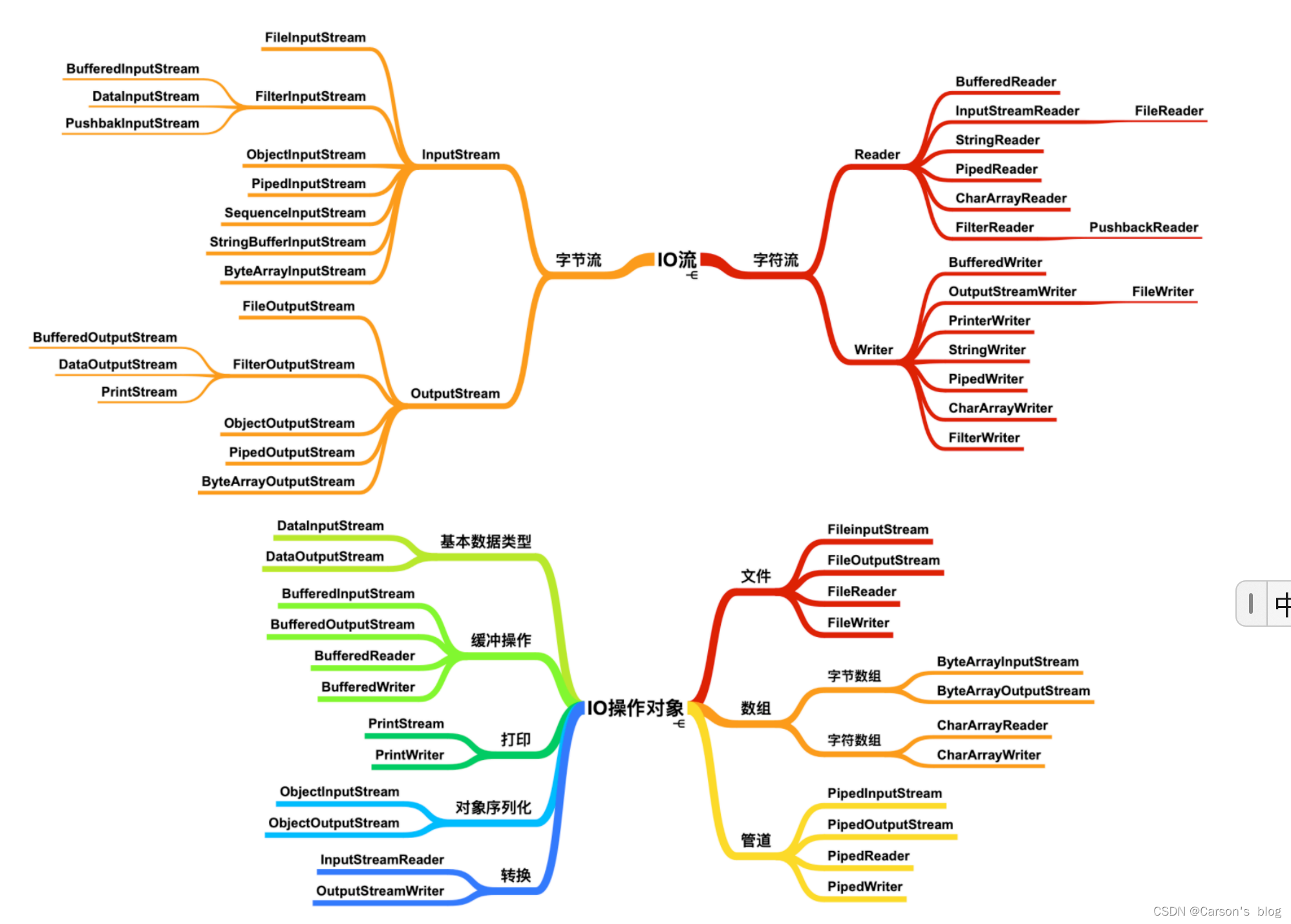
簡單做個總結:
- 1 .InputStream/OutputStream 字節流的抽象類。
- 2 .Reader/Writer 字符流的抽象類。
- 3 .FileInputStream/FileOutputStream 節點流:以字節為單位直接操作“文件”。
- 4 .ByteArrayInputStream/ByteArrayOutputStream 節點流:以字節為單位直接操作“字節數組對象”。
- 5 .ObjectInputStream/ObjectOutputStream 處理流:以字節為單位直接操作“對象”。
- 6 .DataInputStream/DataOutputStream 處理流:以字節為單位直接操作“基本數據類型與字符串類型”。
- 7 .FileReader/FileWriter 節點流:以字符為單位直接操作“文本文件”(注意:只能讀寫文本文件)。
- 8 .BufferedReader/BufferedWriter 處理流:將Reader/Writer對象進行包裝,增加緩存功能,提高讀寫效率。
- 9 .BufferedInputStream/BufferedOutputStream 處理流:將InputStream/OutputStream對象進行包裝,增加緩存功能,提高讀寫效率。
- 10 .InputStreamReader/OutputStreamWriter 處理流:將字節流對象轉化成字符流對象。
- 11 .PrintStream 處理流:將OutputStream進行包裝,可以方便地輸出字符,更加靈活。
IO流分類
流按處理的數據單元分類:
- 字節流:以字節為單位獲取數據,命名上以Stream結尾的流一般是字節流,如FileInputStream、FileOutputStream。
- 字符流:以字符為單位獲取數據,命名上以Reader/Writer結尾的流一般是字符流,如FileReader、FileWriter。
流按處理對象不同分類:
- 節點流:可以直接從數據源或目的地讀寫數據,如FileInputStream、FileReader、DataInputStream等。
- 處理流:不直接連接到數據源或目的地,是”
處理流的流”。通過對其他流的處理提高程序的性能,如BufferedInputStream、BufferedReader等。處理流也叫包裝流。
節點流處于IO操作的第一線,所有操作必須通過它們進行;處理流可以對節點流進行包裝,提高性能或提高程序的靈活性。
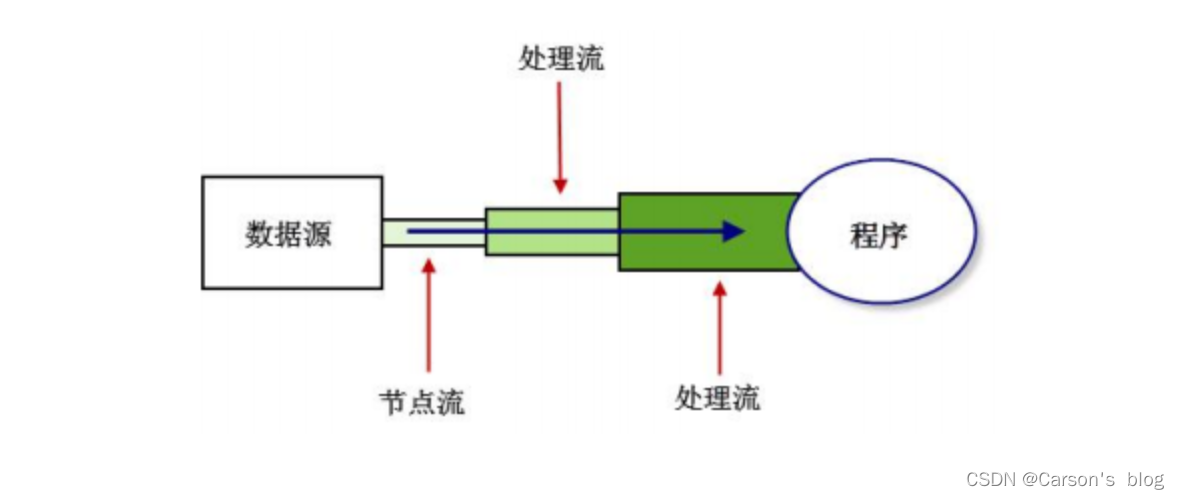
IO 流簡介
IO 即 Input/Output,輸入和輸出。
數據輸入到計算機內存的過程即輸入,反之輸出到外部存儲(比如數據庫,文件,遠程主機)的過程即輸出。
菜鳥雷區 輸入/輸出流的劃分是相對程序而言的,并不是相對數據源。
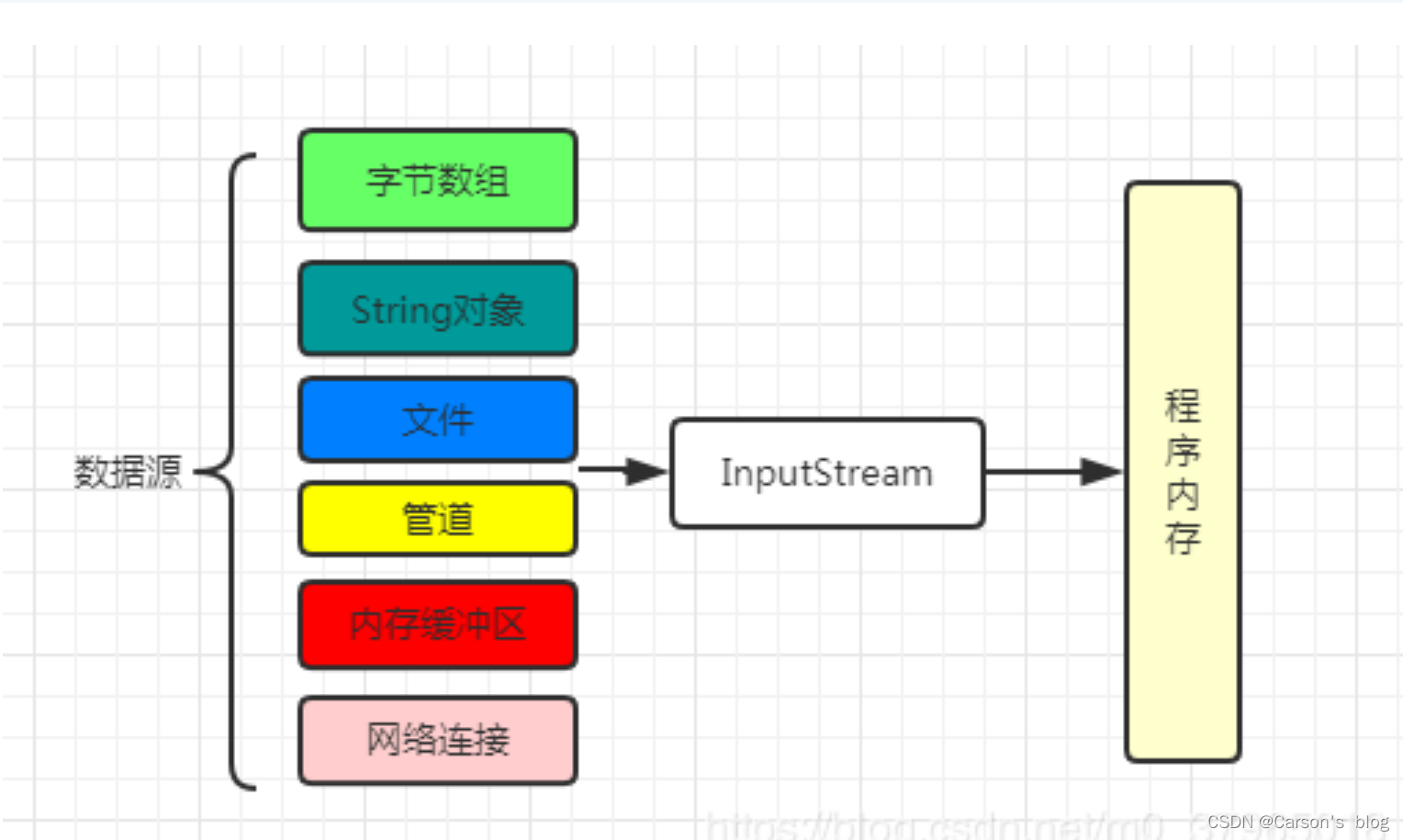
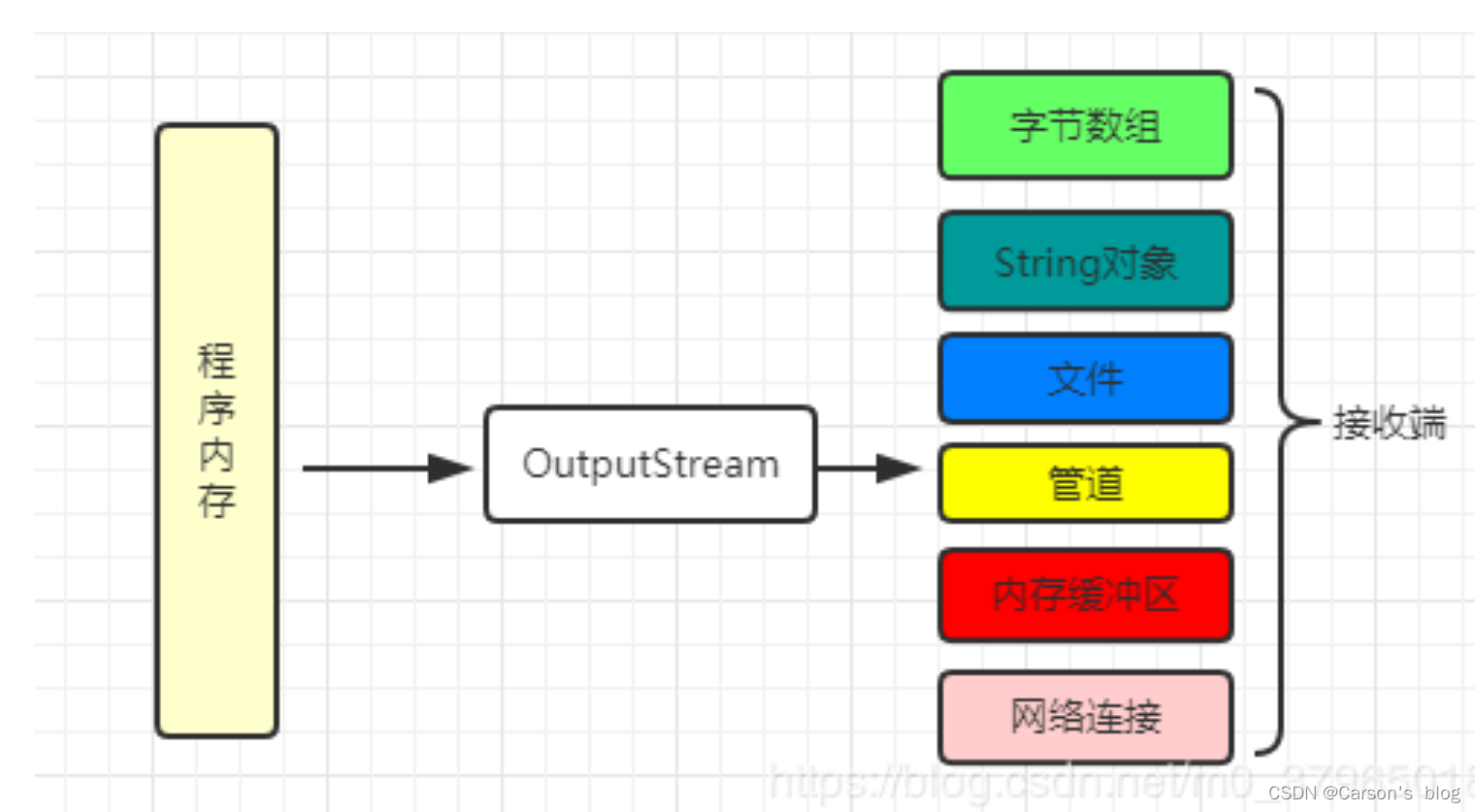
數據傳輸過程類似于水流,因此稱為 IO 流。我們把數據源和目的地可以理解為IO流的兩端。當然,通常情況下,這兩端可能是文件或者網絡連接。
Java IO 流的 40 多個類都是從如下 4 個抽象類基類中派生出來的。
-
InputStream/Reader: 所有的輸入流的基類,前者是字節輸入流,后者是字符輸入流。任何從InputStream或Reader派生而來的類都有read()基本方法,讀取單個字節或字節數組;適配器類InputStreamReader可以將InputStream轉成為Reader
-
OutputStream/Writer: 所有輸出流的基類,前者是字節輸出流,后者是字符輸出流。任何從OutputStream或Writer派生的類都含有write()的基本方法,用于寫單個字節或字節數組。適配器類OutputStreamWriter可以將OutputStream轉成為Writer
剛開始寫IO代碼,總被各種IO流類搞得暈頭轉向。這么多IO相關的類,各種方法,啥時候能記住。
其實只要我們掌握了IO類庫的總體設計思路,理解了它的層次脈絡之后,就很清晰。
知道啥時候用哪些流對象去組合想要的功能就好了(裝飾器模式),API的話,可以查手冊的。
一般在使用IO流的時候會有下面類似代碼:

這里其實是一種裝飾器模式的使用,IO流體系中使用了裝飾器模式包裝了各種功能流類。
在Java IO流體系中FilterInputStream/FilterOutStream和FilterReader/FilterWriter就是裝飾器模式的接口類,從該類向下包裝了一些功能流類。有DataInputStream、BufferedInputStream、LineNumberInputStream、PushbackInputStream等,當然還有面向字節的輸出的功能流類;面向字符的功能流類等。
Reader和Writer的基礎功能類,可以對比InputStream、OutputStream來學習
| 面向字節 | 面向字符 |
|---|---|
| InputStream | Reader |
| OutputStream | Writer |
| FileInputStream | FileReader |
| FileOutputStream | FileWriter |
| ByteArrayInputStream | CharArrayReader |
| ByteArrayOutputStream | CharArrayWriter |
| PipedInputStream | PipedReader |
| PipedOutputStream | PipedWriter |
| StringBufferInputStream(已棄用) | StringReader |
| 無對應類 | StringWriter |
File類
File類其實不止是代表一個文件,它也能代表一個目錄下的一組文件(代表一個文件路徑)。
常用方法
盤點一下File類中最常用到的一些方法:
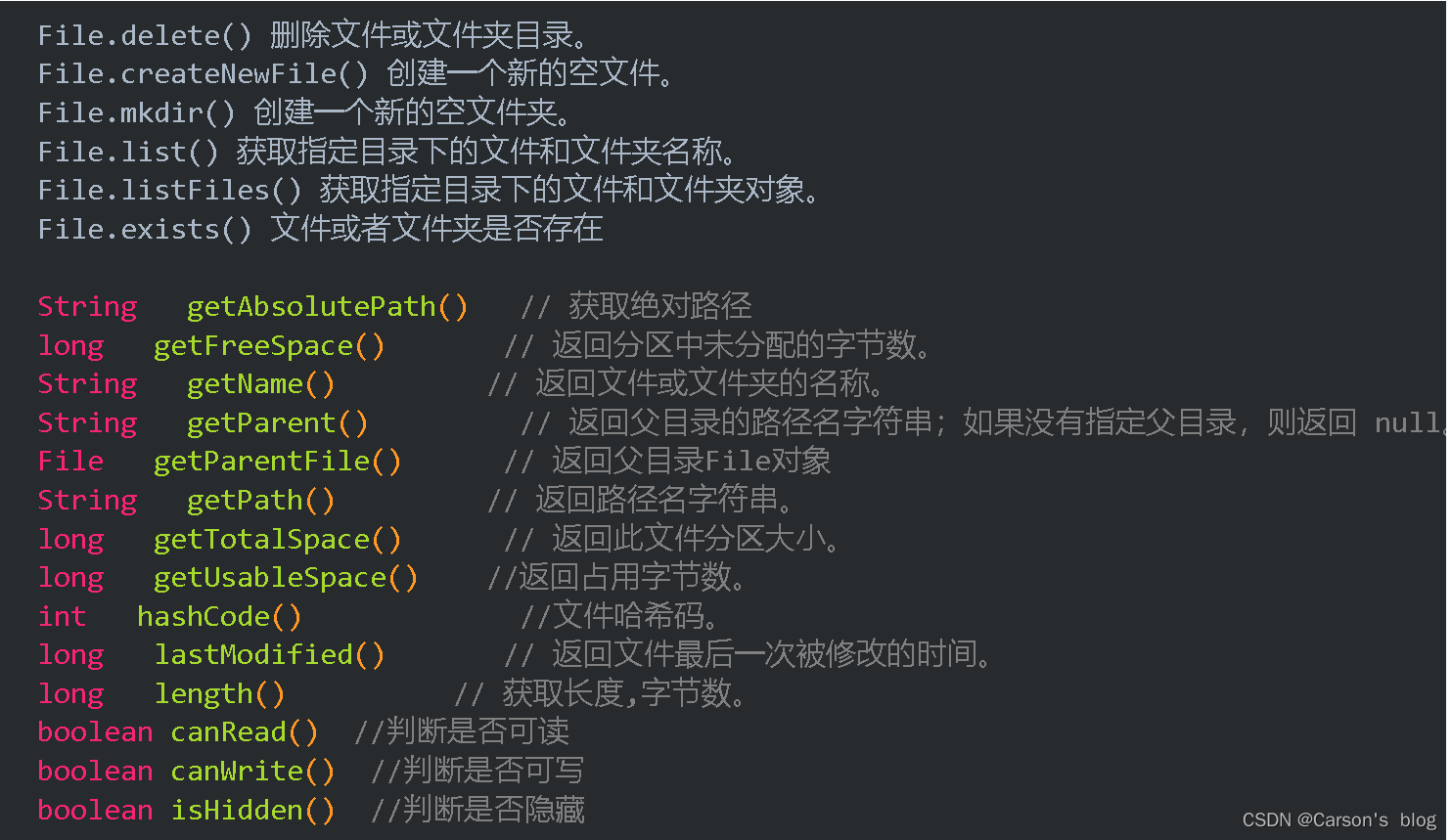
需要注意的是,不同系統對文件路徑的分割符表是不一樣的,比如Windows中是“\”,Linux是“/”。
而File類給提供了抽象的表示File.separator,屏蔽了系統層差異。因此平時在代碼中不要使用諸如“\”這種代表路徑,可能造成Linux平臺下代碼執行錯誤。
File類在IO中的作用
當以文件作為數據源或目標時,除了可以使用文件路徑字符串作為文件以及位置的指定以外,我們也可以使用File類指定。
如下示例:
package com.yoostar.coms;import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;public class FileInIODemo {public static void main(String[] args) {BufferedReader br = null;BufferedWriter bw = null;try {br = new BufferedReader(new FileReader(new File("d:/sxt.txt")));bw = new BufferedWriter(new FileWriter(new File("d:/sxt8.txt")));String temp = "";int i = 1;while ((temp = br.readLine()) != null) {bw.write(i + "," + temp);bw.newLine();i++;}bw.flush();} catch (Exception e) {e.printStackTrace();} finally {try {if (br != null) {br.close();}if (bw != null) {bw.close();}} catch (Exception e) {e.printStackTrace();}}}
}
字節流
InputStream(字節輸入流)
InputStream是輸入流,前面已經說到,它是從數據源對象將數據讀入程序內容時,使用的流對象。
通過看InputStream的源碼知道,它是一個抽象類:

InputStream 常用方法:
//從數據中讀入一個字節,并返回該字節,遇到流的結尾時返回-1
int read() //讀入一個字節數組,并返回實際讀入的字節數,最多讀入b.length個字節,遇到流結尾時返回-1
//如果有可用字節讀取,則最多讀取的字節數最多等于 `b.length` , 返回讀取的字節數。這個方法等價于read(b, 0, b.length)。
int read(byte[] b)// 讀入一個字節數組,返回實際讀入的字節數或者在碰到結尾時返回-1.
//b:代表數據讀入的數組, off:代表第一個讀入的字節應該被放置的位置在b中的偏移量,len:讀入字節的最大數量
int read(byte[],int off,int len)// 返回當前可以讀入的字節數量,如果是從網絡連接中讀入,這個方法要慎用,
int available() //在輸入流中跳過n個字節,返回實際跳過的字節數
long skip(long n)//標記輸入流中當前的位置
void mark(int readlimit) //判斷流是否支持打標記,支持返回true
boolean markSupported() // 返回最后一個標記,隨后對read的調用將重新讀入這些字節。
void reset() //關閉輸入流,這個很重要,流使用完一定要關閉
void close()
從 Java 9 開始,InputStream 新增加了多個實用的方法:
readAllBytes():讀取輸入流中的所有字節,返回字節數組。readNBytes(byte[] b, int off, int len):阻塞直到讀取len個字節。transferTo(OutputStream out):將所有字節從一個輸入流傳遞到一個輸出流。
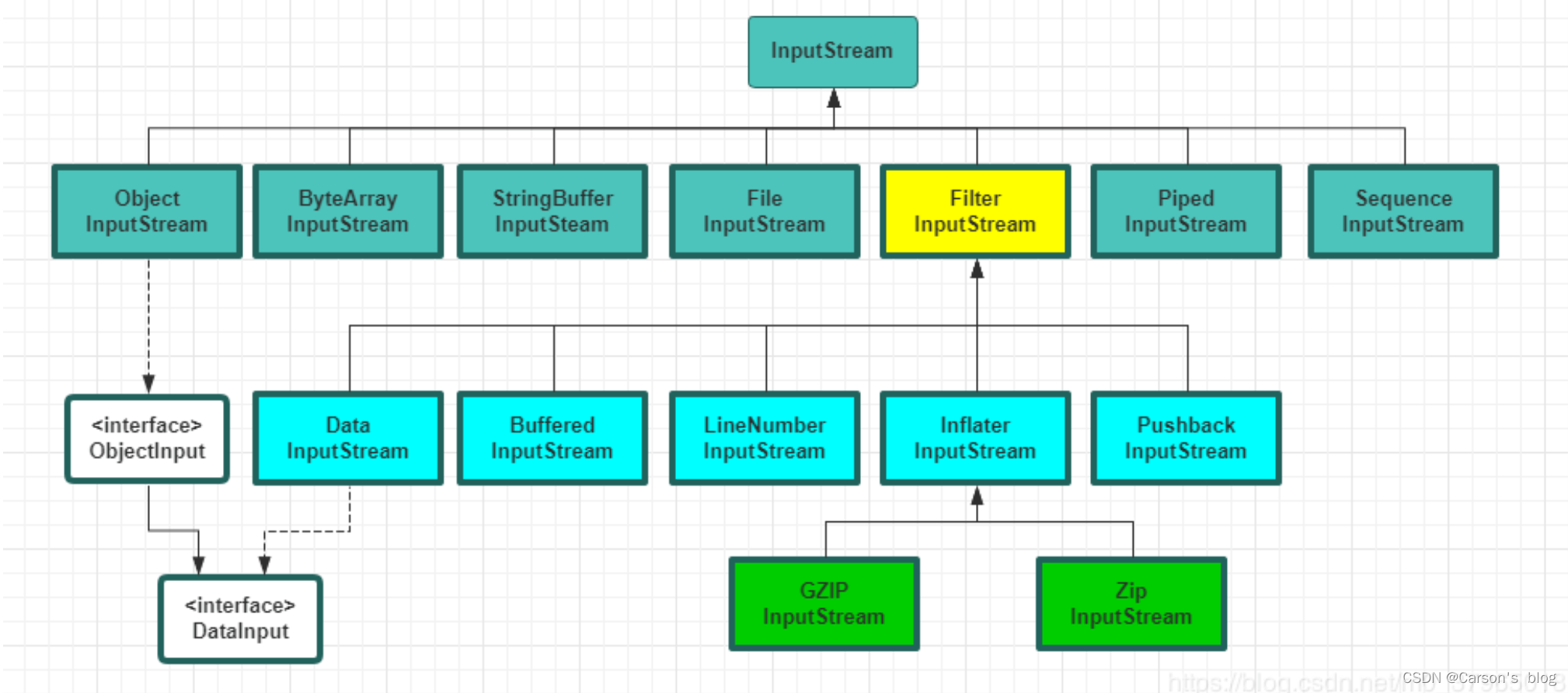
直接從InputStream抽象類繼承的流,可以發現基本上對應了每種數據源類型:
| 類 | 功能 |
|---|---|
| ByteArrayInputStream | 將字節數組作為InputStream. 即ByteArrayInputStream是把內存中的”字節數組對象”當做數據源。 |
| StringBufferInputStream | 將String轉成InputStream |
| FileInputStream | 從文件中讀取內容 |
| PipedInputStream | 產生用于寫入相關PipedOutputStream的數據。實現管道化 |
| SequenceInputStream | 將兩個或多個InputStream對象轉換成單一的InputStream |
| FilterInputStream | 抽象類,主要是作為“裝飾器”的接口類,實現其他的功能流 |
DataInputStream 用于讀取指定類型數據,不能單獨使用,必須結合 FileInputStream 。
DataInputStream和DataOutputStream提供了可以存取與機器無關的所有Java基礎類型數據(如:int、double、String等)的方法。
FileInputStream fileInputStream = new FileInputStream("input.txt");
//必須將fileInputStream作為構造參數才能使用
DataInputStream dataInputStream = new DataInputStream(fileInputStream);
//可以讀取任意具體的類型數據
dataInputStream.readBoolean();
dataInputStream.readInt();
dataInputStream.readUTF();//writeUTF()和readUTF()來寫入和讀取字符串
OutputStream(字節輸出流)
OutputStream用于將數據(字節信息)寫入到目的地(通常是文件)
OutputStream是輸出流的抽象基類,它是將程序內存中的數據寫入到目的地(也就是接收數據的一端)。

OutputStream 常用方法:

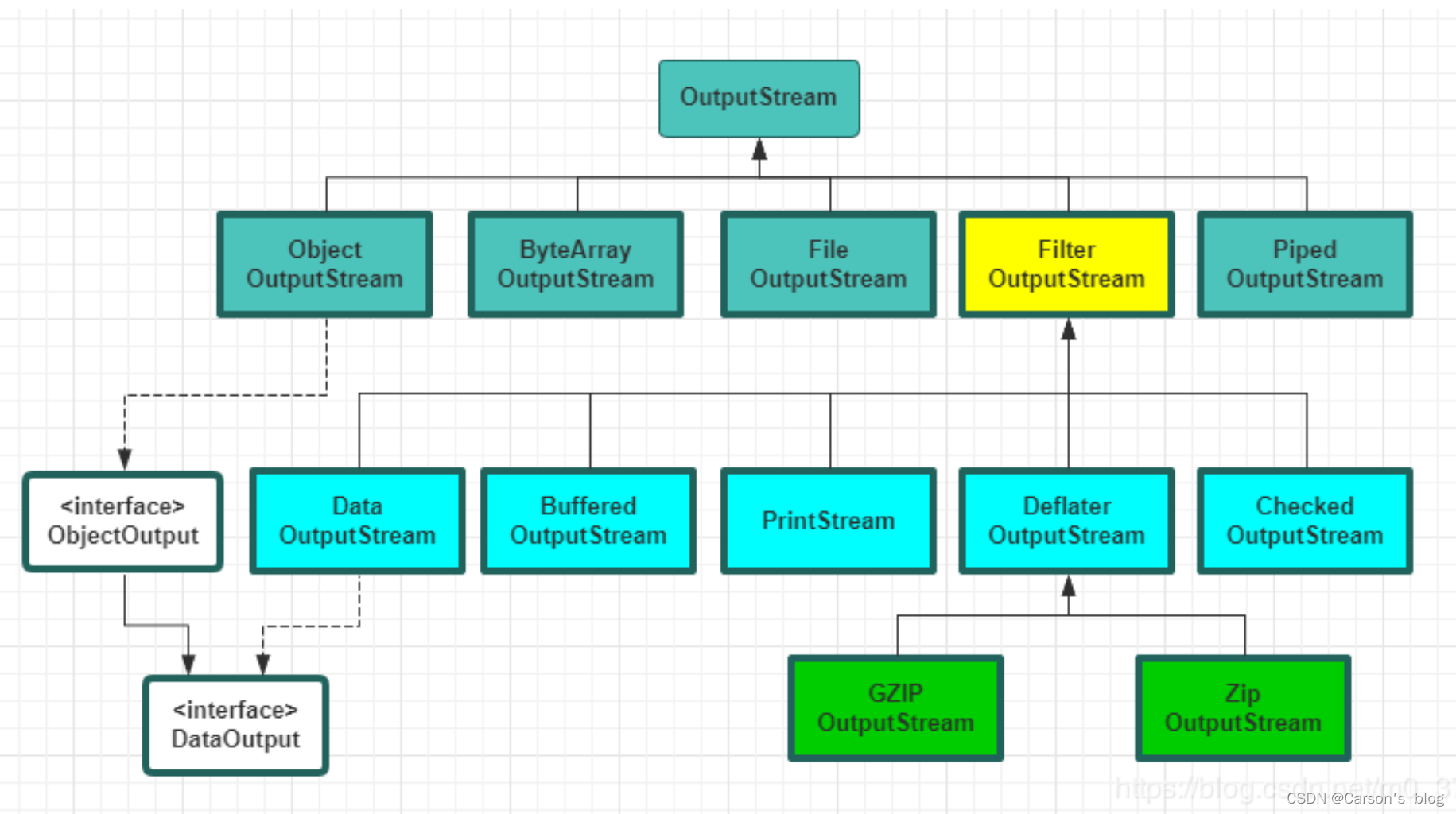
同樣地,OutputStream也提供了一些基礎流的實現,這些實現也可以和特定的目的地(接收端)對應起來,比如輸出到字節數組或者是輸出到文件/管道等:
| 類 | 功能 |
|---|---|
| ByteArrayOutputStream | 在內存中創建一個緩沖區,所有送往“流”的數據都要放在此緩沖區 |
| FileOutputStream | 將數據寫入文件 |
| PipedOutputStream | 和PipedInputStream配合使用。實現管道化 |
| FilterOutputStream | 抽象類,主要是作為“裝飾器”的接口類,實現其他的功能流 |
DataOutputStream 用于寫入指定類型數據,不能單獨使用,必須結合 FileOutputStream
DataInputStream和DataOutputStream提供了可以存取與機器無關的所有Java基礎類型數據(如:int、double、String等)的方法。
// 輸出流
FileOutputStream fileOutputStream = new FileOutputStream("out.txt");
DataOutputStream dataOutputStream = new DataOutputStream(fileOutputStream);
// 輸出任意數據類型
dataOutputStream.writeBoolean(true);
dataOutputStream.writeByte(1);
使用裝飾器包裝有用的流
Java IO 流體系使用了裝飾器模式來給基礎的輸入/輸出流添加額外的功能。
額外的功能可能是:可以將流緩沖起來提高性能、使流能夠讀寫基本數據類型等。
通過裝飾器模式添加功能的流類型都是從FilterInputStream和FilterOutputStream抽象類擴展而來的。
FilterInputStream類型
| 類 | 功能 |
|---|---|
| DataInputStream | 和DataOutputStream搭配使用,使得流可以讀取int char long等基本數據類型 |
| BufferedInputStream | 使用緩沖區,主要是提高性能. IO 操作是很消耗性能的,緩沖流將數據加載至緩沖區,一次性讀取/寫入多個字節,從而避免頻繁的 IO 操作,提高流的傳輸效率。 |
| LineNumberInputStream | 跟蹤輸入流中的行號,可以使用getLineNumber、setLineNumber(int) |
| PushbackInputStream | 使得流能彈出“一個字節的緩沖區”,可以將讀到的最后一個字符回退 |
FilterOutStream類型
| 類 | 功能 |
|---|---|
| DataOutputStream | 和DataInputStream搭配使用,使得流可以寫入int char long等基本數據類型 |
| PrintStream | 用于產生格式化的輸出 |
| BufferedOutputStream | 使用緩沖區,可以調用flush()清空緩沖區 |
因此要理解流的使用就是搭配起來或者使用功能流組合起來去轉移或者存儲數據。
通過緩沖區提高讀寫效率
方式一
通過創建一個指定長度的字節數組作為緩沖區,以此來提高IO流的讀寫效率。
該方式適用于讀取較大圖片時的緩沖區定義。
**注意:**緩沖區的長度一定是 2 的整數冪。一般情況下1024 長度較為合適。
package com.coms.util.excel;import java.io.FileInputStream;
import java.io.FileOutputStream;public class FileStreamBuffedDemo {public static void main(String[] args) {FileInputStream fis = null;FileOutputStream fos = null;try {//創建文件字節輸入流對象fis = new FileInputStream("d:/1.png");//創建文件字節輸出流對象fos = new FileOutputStream("d:/3.png");//創建一個緩沖區,提高讀寫效率byte[] buff = new byte[1024];int temp = 0;while ((temp = fis.read(buff)) != -1) {fos.write(buff, 0, temp);}} catch (Exception e) {e.printStackTrace();} finally {try {if (fis != null) {fis.close();}if (fos != null) {fos.close();}} catch (Exception e) {e.printStackTrace();}}}
}
方式二
通過創建一個字節數組作為緩沖區,數組長度是通過輸入流對象的available()返回當前文件的預估長度來定義的。在讀寫文件時,是在一次讀寫操作中完成文件讀寫操作的。注意:如果文件過大,那么對內存的占用也是比較大的。所以大文件不建議使用該方法。
package com.yoostar.coms;import java.io.FileInputStream;
import java.io.FileOutputStream;public class FileStreamBuffer2Demo {public static void main(String[] args) {FileInputStream fis = null;FileOutputStream fos = null;try {//創建文件字節輸入流對象 fis = new FileInputStream("d:/itbz.jpg");//創建文件字節輸出流對象 fos = new FileOutputStream("d:/cc.jpg");//創建一個緩沖區,提高讀寫效率 byte[] buff = new byte[fis.available()];fis.read(buff);//將數據從內存中寫入到磁盤中。 fos.write(buff);} catch (Exception e) {e.printStackTrace();} finally {try {if (fis != null) {fis.close();}if (fos != null) {fos.close();}} catch (Exception e) {e.printStackTrace();}}}
}通過緩沖流提高讀寫效率
Java緩沖流本身并不具有IO流的讀取與寫入功能,只是在別的流(節點流或其他處理流)上加上緩沖功能提高效率,就像是把別的流包裝起來一樣,因此緩沖流是一種處理流(包裝流)。 當對文件或者其他數據源進行頻繁的讀寫操作時,效率比較低,這時如果使用緩沖流就能夠更高效的讀寫信息。因為緩沖流是先將數據緩存起來,然后當緩存區存滿后或者手動刷新時再一次性的讀取到程序或寫入目的地。 因此,緩沖流還是很重要的,我們在IO操作時記得加上緩沖流來提升性能。BufferedInputStream和BufferedOutputStream這兩個流是緩沖字節流,通過內部緩存數組來提高操作流的效率。
package com.yoostar.coms;import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;public class FileStreamBuffed3Demo {public static void main(String[] args) {FileInputStream fis = null;FileOutputStream fos = null;BufferedInputStream bis = null;BufferedOutputStream bos = null;try {fis = new FileInputStream("d:/itbz.jpg");bis = new BufferedInputStream(fis);fos = new FileOutputStream("d:/ff.jpg");bos = new BufferedOutputStream(fos);//緩沖流中的 byte 數組長度默認是 8192int temp = 0;while ((temp = bis.read()) != -1) {bos.write(temp);}} catch (Exception e) {e.printStackTrace();} finally {try {//注意:關閉流順序:"后開的先關閉"if (bis != null) {bis.close();}if (fis != null) {fis.close();}if (bos != null) {bos.close();}if (fos != null) {fos.close();}} catch (Exception e) {e.printStackTrace();}}}
}
字符流
不管是文件讀寫還是網絡發送接收,信息的最小存儲單元都是字節。
那為什么 I/O 流操作要分為字節流操作和字符流操作呢?
個人認為主要有兩點原因:
- 字符流是由 Java 虛擬機將字節轉換得到的,這個過程還算是比較耗時。
- 如果字節流且我們不知道編碼類型就很容易出現中文亂碼問題。
因此,I/O 流就干脆提供了一個直接操作字符的接口,方便我們平時對字符進行流操作。
字符流默認采用的是 Unicode 編碼,我們可以通過構造方法自定義編碼。
utf8 :英文占 1 字節,中文占 3 字節,unicode:任何字符都占 2 個字節,gbk:英文占 1 字節,中文占 2 字節。
如果音頻文件、圖片等媒體文件用字節流比較好,如果涉及到字符的話使用字符流比較好
Reader(字符輸入流)
Reader用于從源頭(通常是文件)讀取數據(字符信息)到內存中,java.io.Reader抽象類是所有字符輸入流的父類。
Reader與InputStream類似,不同點在于,Reader基于字符而非基于字節。
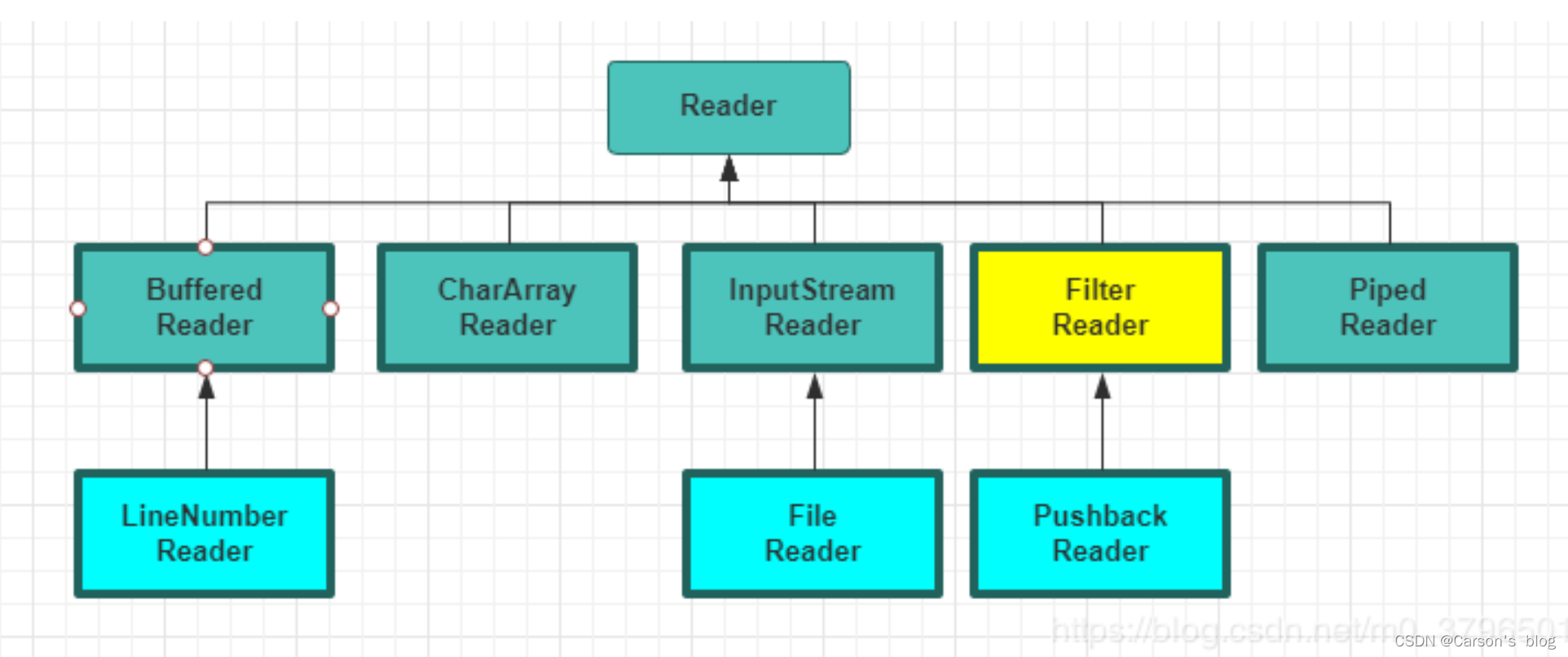
Reader 常用方法:
read(): 從輸入流讀取一個字符。read(char[] cbuf): 從輸入流中讀取一些字符,并將它們存儲到字符數組cbuf中,等價于read(cbuf, 0, cbuf.length)。read(char[] cbuf, int off, int len):在read(char[] cbuf)方法的基礎上增加了off參數(偏移量)和len參數(要讀取的最大字符數)。skip(long n):忽略輸入流中的 n 個字符 ,返回實際忽略的字符數。close(): 關閉輸入流并釋放相關的系統資源。
InputStreamReader 是字節流轉換為字符流的橋梁,其子類 FileReader 是基于該基礎上的封裝,可以直接操作字符文件。
// 字節流轉換為字符流的橋梁
public class InputStreamReader extends Reader {
}
// 用于讀取字符文件
public class FileReader extends InputStreamReader {
}
FileReader 代碼示例:
try (FileReader fileReader = new FileReader("input.txt");) {int content;long skip = fileReader.skip(3);System.out.println("The actual number of bytes skipped:" + skip);System.out.print("The content read from file:");while ((content = fileReader.read()) != -1) {System.out.print((char) content);}
} catch (IOException e) {e.printStackTrace();
}
input.txt 文件內容:
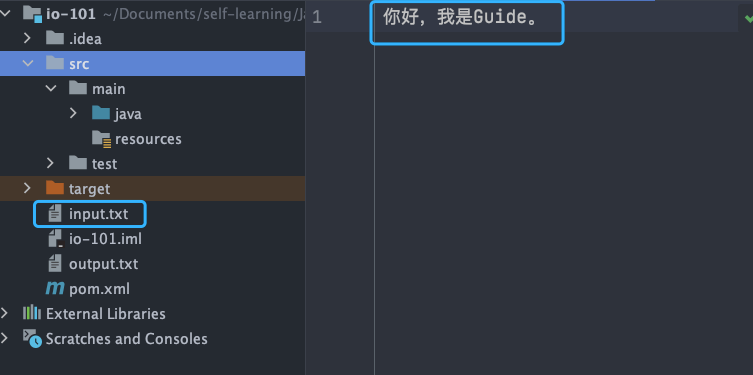
輸出:
The actual number of bytes skipped:3
The content read from file:我是Guide。
Writer(字符輸出流)
Writer用于將數據(字符信息)寫入到目的地(通常是文件),java.io.Writer抽象類是所有字符輸出流的父類。
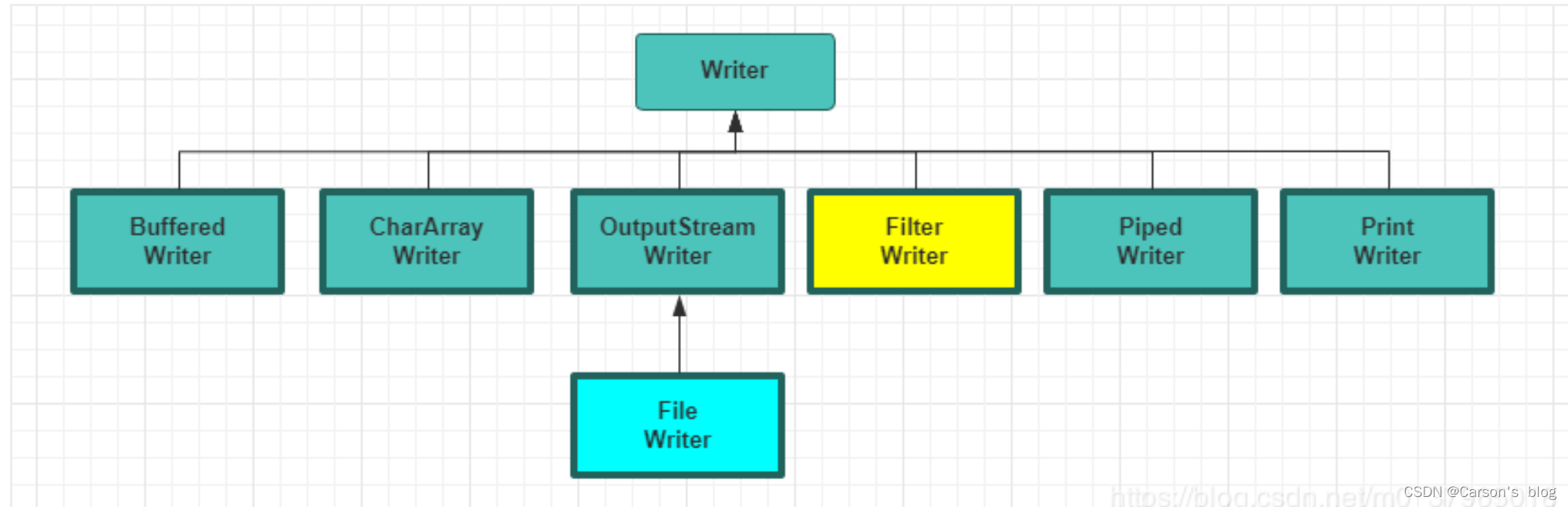
Writer 常用方法:
write(int c): 寫入單個字符。write(char[] cbuf):寫入字符數組cbuf,等價于write(cbuf, 0, cbuf.length)。write(char[] cbuf, int off, int len):在write(char[] cbuf)方法的基礎上增加了off參數(偏移量)和len參數(要讀取的最大字符數)。write(String str):寫入字符串,等價于write(str, 0, str.length())。write(String str, int off, int len):在write(String str)方法的基礎上增加了off參數(偏移量)和len參數(要讀取的最大字符數)。append(CharSequence csq):將指定的字符序列附加到指定的Writer對象并返回該Writer對象。append(char c):將指定的字符附加到指定的Writer對象并返回該Writer對象。flush():刷新此輸出流并強制寫出所有緩沖的輸出字符。close():關閉輸出流釋放相關的系統資源。
OutputStreamWriter 是字節流轉換為字符流的橋梁,其子類 FileWriter 是基于該基礎上的封裝,可以直接將字符寫入到文件。
// 字符流轉換為字節流的橋梁
public class OutputStreamWriter extends Writer {
}
// 用于寫入字符到文件
public class FileWriter extends OutputStreamWriter {
}
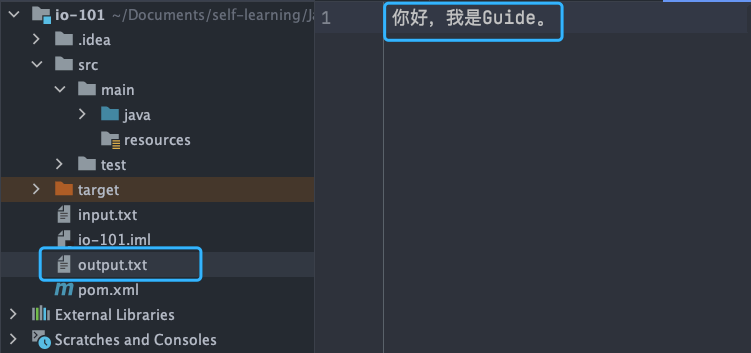
FileWriter 代碼示例:
try (Writer output = new FileWriter("output.txt")) {output.write("你好,我是Guide。");
} catch (IOException e) {e.printStackTrace();
}
輸出結果:
使用裝飾器包裝有用的流
當然也有類似字節流的裝飾器實現方式,給字符流添加額外的功能或這說是行為。
這些功能字符流類主要有:
-
BufferedReader
BufferedReader是針對字符輸入流的緩沖流對象,提供了更方便的按行讀取的方法:
readLine();在使用字符流讀取文本文件時,我們可以使用該方法以行為單位進行讀取.
-
BufferedWriter
BufferedWriter是針對字符輸出流的緩沖流對象,在字符輸出緩沖流中可以使用
newLine();方法實現換行處理。 -
PrintWriter
在Java的IO流中專門提供了用于字符輸出的流對象PrintWriter。
該對象具有自動行刷新緩沖字符輸出流,特點是可以按行寫出字符串,并且可通過
println();方法實現自動換行。 -
LineNumberReader
-
PushbackReader
轉換流
InputStreamReader/OutputStreamWriter用來實現將字節流轉化成字符流。比如,如下場景:
System.in是字節流對象,代表鍵盤的輸入,如果我們想按行接收用戶的輸入時,就必須用到緩沖字符流BufferedReader特有的方法readLine(),但是經過觀察會發現在創建BufferedReader的構造方法的參數必須是一個Reader對象,這時候我們的轉換流InputStreamReader就派上用場了。而System.out也是字節流對象,代表輸出到顯示器,按行讀取用戶的輸入后,并且要將讀取的一行字符串直接顯示到控制臺,就需要用到字符流的write(Stringstr)方法,所以我們要使用OutputStreamWriter將字節流轉化為字符流。(
還可以解決中文亂碼的問題)
對象序列化與反序列化
學習鏈接:https://mp.weixin.qq.com/s/0EfIUB9E-0Oh_Clwuxswuw
序列化就是將對象轉成字節序列的過程,反序列化就是將字節序列重組成對象的過程。

為什么要有對象序列化機制
程序中的對象,其實是存在有內存中,當我們JVM關閉時,無論如何它都不會繼續存在了。那有沒有一種機制能讓對象具有“持久性”呢?序列化機制提供了一種方法,你可以將對象序列化的字節流輸入到文件保存在磁盤上。
序列化機制的另外一種意義便是我們可以通過網絡傳輸對象了,Java中的 遠程方法調用(RMI),底層就需要序列化機制的保證。
對象序列化的作用有如下兩種:
- 持久化: 把對象的字節序列永久地保存到硬盤上,通常存放在一個文件中。
- 網絡通信: 在網絡上傳送對象的字節序列。比如:服務器之間的數據通信、對象傳遞。
在Java中怎么實現序列化和反序列化
首先要序列化的對象必須實現一個Serializable接口(這是一個標識接口,起標識作用,不包括任何方法)

其次需要是用兩個對象流類:ObjectInputStream 和ObjectOutputStream。
主要使用ObjectInputStream對象的readObject方法從流中讀入對象、ObjectOutputStream的writeObject方法將對象寫到流中
ObjectOutputStream代表對象輸出流,它的writeObject(Objectobj)方法可對參數指定的obj對象進行序列化,把得到的字節序列寫到一個目標輸出流中。ObjectInputStream代表對象輸入流,它的readObject()方法從一個源輸入流中讀取字節序列,再把它們反序列化為一個對象,并將其返回。只有實現了Serializable接口的類的對象才能被序列化。
Serializable接口是一個空接口,只起到標記作用。
下面我們通過序列化機制將一個簡單的pojo對象寫入到文件,并再次讀入到程序內存。
public class Student implements Serializable {private String name;private Integer age;private Integer score;@Overridepublic String toString() {return "Student:" + '\n' +"name = " + this.name + '\n' +"age = " + this.age + '\n' +"score = " + this.score + '\n';}// 序列化public static void serialize( ) throws IOException {Student student = new Student();student.setName("CodeSheep");student.setAge( 18 );student.setScore( 1000 );ObjectOutputStream objectOutputStream = new ObjectOutputStream( new FileOutputStream( new File("student.txt") ) );objectOutputStream.writeObject( student );objectOutputStream.close();System.out.println("序列化成功!已經生成student.txt文件");System.out.println("==============================================");}//反序列化public static void deserialize( ) throws IOException, ClassNotFoundException {ObjectInputStream objectInputStream = new ObjectInputStream( new FileInputStream( new File("student.txt") ) );//讀出來做一個強轉Student student = (Student) objectInputStream.readObject();objectInputStream.close();System.out.println("反序列化結果為:");System.out.println( student );}
}不想序列化的數據使用transient(瞬時)關鍵字屏蔽
如果我們上面的user對象有一個password字段,屬于敏感信息,這種是不能走序列化的方式的,但是實現了Serializable 接口的對象會自動序列化所有的數據域,怎么辦呢?在password字段上加上關鍵字transient就好了。

系統IO流:System類中的IO流
在標準IO模型中,Java提供了System.in、System.out和System.error。
System.in

是一個靜態域,未被包裝過的InputStream。通常我們會使用BufferedReader進行包裝然后一行一行地讀取輸入,這里就要用到前面說的適配器流InputStreamReader將inputStream轉為Reader。
System.out
System.out是一個PrintStream流。
System.out一般會把你寫到其中的數據輸出到控制臺上。
System.out通常僅用在類似命令行工具的控制臺程序上。
System.out也經常用于打印程序的調試信息(盡管它可能并不是獲取程序調試信息的最佳方式)。
System.err
System.err是一個PrintStream流。
System.err與System.out的運行方式類似,但它更多的是用于打印錯誤文本。
系統流重定向
盡管System.in, System.out, System.err這3個流是java.lang.System類中的靜態成員,并且已經預先在JVM啟動的時候初始化完成,你依然可以更改它們.
可以使用setIn(InputStream)、setOut(PrintStream)、setErr(PrintStream)進行重定向。
比如可以將控制臺的輸出重定向到文件中。

解壓縮數據流處理
Java IO類庫是支持讀寫壓縮格式的數據流的。
這些壓縮相關的流類是按字節處理的。
看下設計壓縮解壓縮的相關流類:
| 壓縮類 | 功能 |
|---|---|
| CheckedInputStream | getCheckSum()可以為任何InputStream產生校驗和(不僅是解壓縮) |
| CheckedOutputStream | getCheckSum()可以為任何OutputStream產生校驗和(不僅是壓縮) |
| DeflaterOutputStream | 壓縮類的基類 |
| ZipOutputStream | 繼承自DeflaterOutputStream,將數據壓縮成Zip文件格式 |
| GZIPOutputStream | 繼承自DeflaterOutputStream,將數據壓縮成GZIP文件格式 |
| InflaterInputStream | 解壓縮類的基類 |
| ZipInputStream | 繼承自InflaterInputStream,解壓縮Zip文件格式的數據 |
| GZIPInputStream | 繼承自InflaterInputStream,解壓縮GZIP文件格式的數據 |
表格中CheckedInputStream 和 CheckedOutputStream 一般會和Zip壓縮解壓過程配合使用,主要是為了保證我們壓縮和解壓過程數據包的正確性,得到的是中間沒有被篡改過的數據。
以CheckedInputStream 為例,它的構造器需要傳入一個Checksum類型:

而Checksum 是一個接口,因為是接口,所以可以看到這里又用到了策略模式,具體的校驗算法是可以選擇的。Java類庫給我提供了兩種校驗和算法:Adler32 和 CRC32,性能方面可能Adler32 會更好一些,不過CRC32可能更準確。
壓縮(ZIP)
我們可以把一個或一批文件壓縮成一個zip文檔。
將多個文件壓縮成zip包
1 public class ZipFileUtils {2 public static void compressFiles(File[] files, String zipPath) throws IOException {34 // 定義文件輸出流,表明是要壓縮成zip文件的5 FileOutputStream f = new FileOutputStream(zipPath);67 // 給輸出流增加校驗功能8 CheckedOutputStream checkedOs = new CheckedOutputStream(f,new Adler32());9
10 // 定義zip格式的輸出流,這里要明白一直在使用裝飾器模式在給流添加功能
11 // ZipOutputStream 也是從FilterOutputStream 繼承下來的
12 ZipOutputStream zipOut = new ZipOutputStream(checkedOs);
13
14 // 增加緩沖功能,提高性能
15 BufferedOutputStream buffOut = new BufferedOutputStream(zipOut);
16
17 //對于壓縮輸出流我們可以設置個注釋
18 zipOut.setComment("zip test");
19
20 // 下面就是從Files[] 數組中讀入一批文件,然后寫入zip包的過程
21 for (File file : files){
22
23 // 建立讀取文件的緩沖流,同樣是裝飾器模式使用BufferedReader
24 // 包裝了FileReader
25 BufferedReader bfReadr = new BufferedReader(new FileReader(file));
26
27 // 一個文件對象在zip流中用一個ZipEntry表示,使用putNextEntry添加到zip流中
28 zipOut.putNextEntry(new ZipEntry(file.getName()));
29
30 int c;
31 while ((c = bfReadr.read()) != -1){
32 buffOut.write(c);
33 }
34
35 // 注意這里要關閉
36 bfReadr.close();
37 buffOut.flush();
38 }
39 buffOut.close();
40 }
41
42 public static void main(String[] args) throws IOException {
43 String dir = "d:";
44 String zipPath = "d:/test.zip";
45 File[] files = Directory.getLocalFiles(dir,".*\\.txt");
46 ZipFileUtils.compressFiles(files, zipPath);
47 }
48}
解壓縮(ZIP)
解壓縮zip包到目標文件夾
1 public static void unConpressZip(String zipPath, String destPath) throws IOException {2 if(!destPath.endsWith(File.separator)){3 destPath = destPath + File.separator;4 File file = new File(destPath);5 if(!file.exists()){6 file.mkdirs();7 }8 }9 // 新建文件輸入流類,
10 FileInputStream fis = new FileInputStream(zipPath);
11
12 // 給輸入流增加檢驗功能
13 CheckedInputStream checkedIns = new CheckedInputStream(fis,new Adler32());
14
15 // 新建zip輸出流,因為讀取的zip格式的文件嘛
16 ZipInputStream zipIn = new ZipInputStream(checkedIns);
17
18 // 增加緩沖流功能,提高性能
19 BufferedInputStream buffIn = new BufferedInputStream(zipIn);
20
21 // 從zip輸入流中讀入每個ZipEntry對象
22 ZipEntry zipEntry;
23 while ((zipEntry = zipIn.getNextEntry()) != null){
24 System.out.println("解壓中" + zipEntry);
25
26 // 將解壓的文件寫入到目標文件夾下
27 int size;
28 byte[] buffer = new byte[1024];
29 FileOutputStream fos = new FileOutputStream(destPath + zipEntry.getName());
30 BufferedOutputStream bos = new BufferedOutputStream(fos, buffer.length);
31 while ((size = buffIn.read(buffer, 0, buffer.length)) != -1) {
32 bos.write(buffer, 0, size);
33 }
34 bos.flush();
35 bos.close();
36 }
37 buffIn.close();
38
39 // 輸出校驗和
40 System.out.println("校驗和:" + checkedIns.getChecksum().getValue());
41 }
42
43 // 在main函數中直接調用
44 public static void main(String[] args) throws IOException {
45 String dir = "d:";
46 String zipPath = "d:/test.zip";
47// File[] files = Directory.getLocalFiles(dir,".*\\.txt");
48// ZipFileUtils.compressFiles(files, zipPath);
49
50 ZipFileUtils.unConpressZip(zipPath,"F:/ziptest");
51 }
IO流的典型使用方式
IO流種類繁多,可以通過不同的方式組合I/O流類,但平時我們常用的也就幾種組合。
緩沖輸入文件
1 public class BufferedInutFile {2 public static String readFile(String fileName) throws IOException {3 BufferedReader bf = new BufferedReader(new FileReader(fileName));4 String s;56 // 這里讀取的內容存在了StringBuilder,當然也可以做其他處理7 StringBuilder sb = new StringBuilder();8 while ((s = bf.readLine()) != null){9 sb.append(s + "\n");
10 }
11 bf.close();
12 return sb.toString();
13 }
14
15 public static void main(String[] args) throws IOException {
16 System.out.println(BufferedInutFile.readFile("d:/1.txt"));
17 }
18}
格式化內存輸入
要讀取格式化的數據,可以使用DataInputStream。
1 public class FormattedMemoryInput {2 public static void main(String[] args) throws IOException {3 try {4 DataInputStream dataIns = new DataInputStream(5 new ByteArrayInputStream(BufferedInutFile.readFile("f:/FormattedMemoryInput.java").getBytes()));6 while (true){7 System.out.print((char) dataIns.readByte());8 }9 } catch (EOFException e) {
10 System.err.println("End of stream");
11 }
12 }
13}
基本的文件輸出
FileWriter對象可以向文件寫入數據。
首先創建一個FileWriter和指定的文件關聯,然后使用BufferedWriter將其包裝提供緩沖功能,為了提供格式化機制,它又被裝飾成為PrintWriter。
1public class BasicFileOutput {2 static String file = "BasicFileOutput.out";34 public static void main(String[] args) throws IOException {5 BufferedReader in = new BufferedReader(new StringReader(BufferedInutFile.readFile("f:/BasicFileOutput.java")));6 PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(file)));78 int lineCount = 1;9 String s;
10 while ((s = in.readLine()) != null){
11 out.println(lineCount ++ + ": " + s);
12 }
13 out.close();
14 in.close();
15 }
16}
下面是我們寫出的BasicFileOutput.out文件,可以看到我們通過代碼字節加上了行號
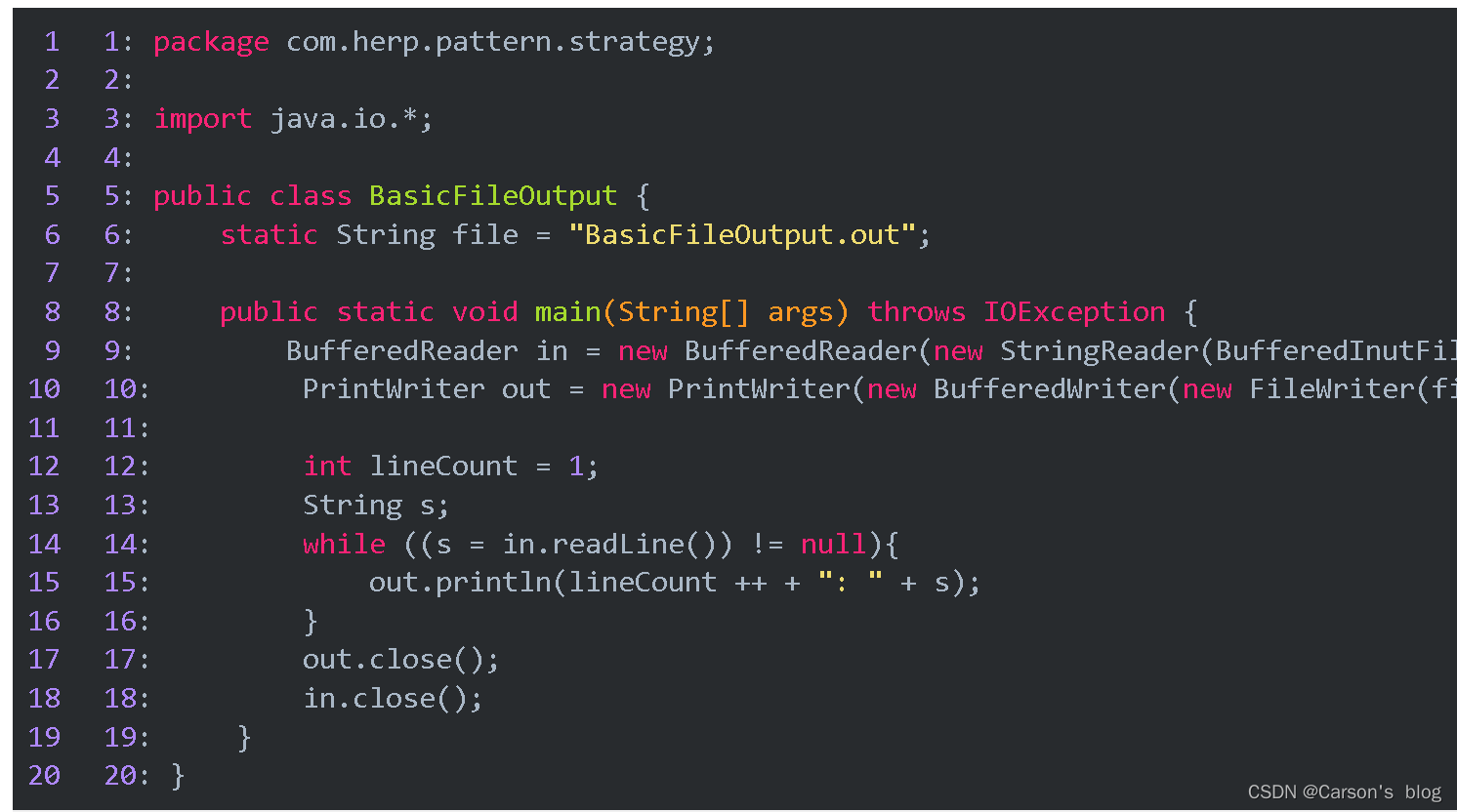
數據的存儲和恢復
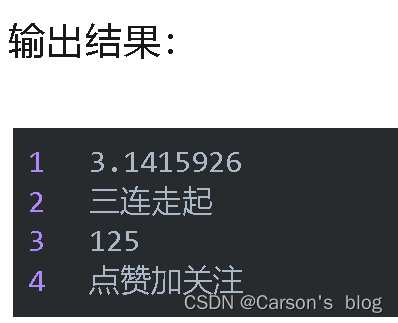
為了輸出可供另一個“流”恢復的數據,我們需要使用DataOutputStream寫入數據,然后使用DataInputStream恢復數據。
當然這些流可以是任何形式(這里的形式其實就是我們前面說過的流的兩端的類型),比如文件。
1public class StoringAndRecoveringData {2 public static void main(String[] args) throws IOException {3 DataOutputStream out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("data.txt")));4 out.writeDouble(3.1415926);5 out.writeUTF("三連走起");6 out.writeInt(125);7 out.writeUTF("點贊加關注");8 out.close();9
10 DataInputStream in = new DataInputStream(new BufferedInputStream(new FileInputStream("data.txt")));
11 System.out.println(in.readDouble());
12 System.out.println(in.readUTF());
13 System.out.println(in.readInt());
14 System.out.println(in.readUTF());
15 in.close();
16 }
17}
隨機訪問流
這里要介紹的隨機訪問流指的是支持隨意跳轉到文件的任意位置進行讀寫的 RandomAccessFile 。
RandomAccessFile可以實現兩個作用:
- 1 .實現對一個文件做讀和寫的操作。
- 2 .可以訪問文件的任意位置。不像其他流只能按照先后順序讀取。
RandomAccessFile 的構造方法如下,我們可以指定 mode(讀寫模式)。
// openAndDelete 參數默認為 false 表示打開文件并且這個文件不會被刪除
public RandomAccessFile(File file, String mode)throws FileNotFoundException {this(file, mode, false);
}
// 私有方法
private RandomAccessFile(File file, String mode, boolean openAndDelete) throws FileNotFoundException{// 省略大部分代碼
}
讀寫模式主要有下面四種:
r: 只讀模式。rw: 讀寫模式rws: 相對于rw,rws同步更新對“文件的內容”或“元數據”的修改到外部存儲設備。rwd: 相對于rw,rwd同步更新對“文件的內容”的修改到外部存儲設備。
文件內容指的是文件中實際保存的數據,元數據則是用來描述文件屬性比如文件的大小信息、創建和修改時間。
RandomAccessFile 中有一個文件指針用來表示下一個將要被寫入或者讀取的字節所處的位置。
我們可以通過 RandomAccessFile 的 seek(long pos) 方法來設置文件指針的偏移量(距文件開頭 pos 個字節處)。
如果想要獲取文件指針當前的位置的話,可以使用 getFilePointer() 方法。
學習這個流我們需掌握三個核心方法:
- 1 .RandomAccessFile(Stringname, String mode)name用來確定文件; mode取r(讀)或rw(可讀寫),通過mode可以確定流對文件的訪問權限。
- 2 .seek(long a) 用來定位流對象讀寫文件的位置,a確定讀寫位置距離文件開頭的字節個數。
- 3 .getFilePointer() 獲得流的當前讀寫位置。
RandomAccessFile 代碼示例:
RandomAccessFile randomAccessFile = new RandomAccessFile(new File("input.txt"), "rw");
System.out.println("讀取之前的偏移量:" + randomAccessFile.getFilePointer() + ",當前讀取到的字符" + (char) randomAccessFile.read() + ",讀取之后的偏移量:" + randomAccessFile.getFilePointer());
// 指針當前偏移量為 6
randomAccessFile.seek(6);
System.out.println("讀取之前的偏移量:" + randomAccessFile.getFilePointer() + ",當前讀取到的字符" + (char) randomAccessFile.read() + ",讀取之后的偏移量:" + randomAccessFile.getFilePointer());
// 從偏移量 7 的位置開始往后寫入字節數據
randomAccessFile.write(new byte[]{'H', 'I', 'J', 'K'});
// 指針當前偏移量為 0,回到起始位置
randomAccessFile.seek(0);
System.out.println("讀取之前的偏移量:" + randomAccessFile.getFilePointer() + ",當前讀取到的字符" + (char) randomAccessFile.read() + ",讀取之后的偏移量:" + randomAccessFile.getFilePointer());
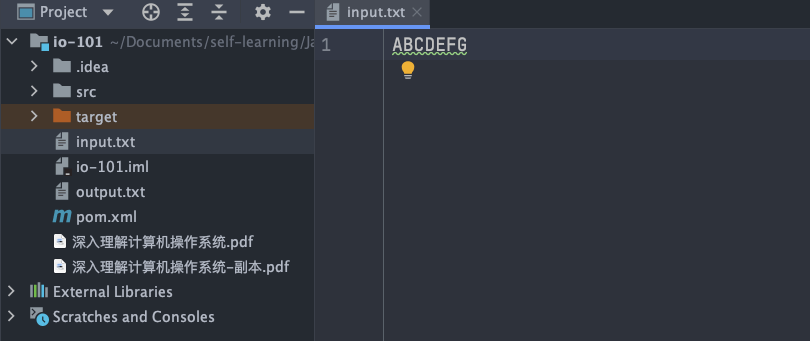
input.txt 文件內容:
輸出:
讀取之前的偏移量:0,當前讀取到的字符A,讀取之后的偏移量:1
讀取之前的偏移量:6,當前讀取到的字符G,讀取之后的偏移量:7
讀取之前的偏移量:0,當前讀取到的字符A,讀取之后的偏移量:1
input.txt 文件內容變為 ABCDEFGHIJK 。
RandomAccessFile 的 write 方法在寫入對象的時候如果對應的位置已經有數據的話,會將其覆蓋掉。
RandomAccessFile randomAccessFile = new RandomAccessFile(new File("input.txt"), "rw");
randomAccessFile.write(new byte[]{'H', 'I', 'J', 'K'});
假設運行上面這段程序之前 input.txt 文件內容為 ABCD ,運行之后則變為 HIJK 。
RandomAccessFile的應用
RandomAccessFile 比較常見的一個應用就是實現大文件的 斷點續傳 。
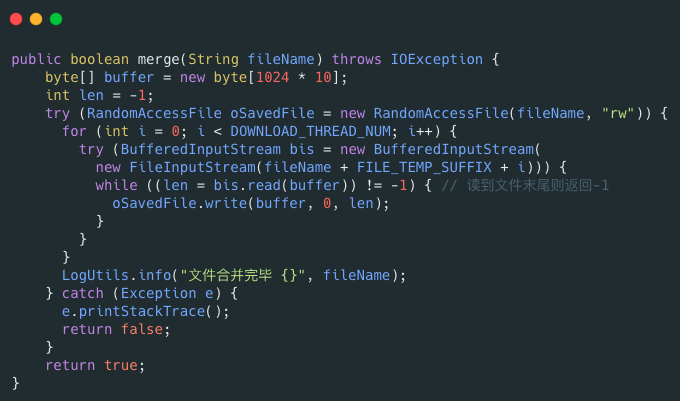
何謂斷點續傳?簡單來說就是上傳文件中途暫停或失敗(比如遇到網絡問題)之后,不需要全部重新上傳,只需要上傳那些未成功上傳的文件分片即可。分片(先將文件切分成多個文件分片)上傳是斷點續傳的基礎。
RandomAccessFile 可以幫助我們合并文件分片,示例代碼如下:
我在《Java 面試指北》open in new window中詳細介紹了大文件的上傳問題。

RandomAccessFile 的實現依賴于 FileDescriptor (文件描述符) 和 FileChannel (內存映射文件)。
Apache IO包
JDK中提供的文件操作相關的類,但是功能都非常基礎,進行復雜操作時需要做大量編程工作。實際開發中,往往需要你自己動手編寫相關的代碼,尤其在遍歷目錄文件時,經常用到遞歸,非常繁瑣。
Apache-commons-io工具包中提供了IOUtils/FileUtils,可以讓我們非常方便的對文件和目錄進行操作。
Apache IOUtils和FileUtils類庫為我們提供了更加簡單、功能更加強大的文件操作和IO流操作功能。
FileUtils的使用
FileUtils類中常用方法:
- cleanDirectory:清空目錄,但不刪除目錄。
- contentEquals:比較兩個文件的內容是否相同。
- copyDirectory:將一個目錄內容拷貝到另一個目錄。可以通過FileFilter過濾需要拷貝的文件。
- copyFile:將一個文件拷貝到一個新的地址。
- copyFileToDirectory:將一個文件拷貝到某個目錄下。
- copyInputStreamToFile:將一個輸入流中的內容拷貝到某個文件。
- deleteDirectory:刪除目錄。
- deleteQuietly:刪除文件。
- listFiles:列出指定目錄下的所有文件。
- openInputSteam:打開指定文件的輸入流。
- readFileToString:將文件內容作為字符串返回。
- readLines:將文件內容按行返回到一個字符串數組中。
- size:返回文件或目錄的大小。
- write:將字符串內容直接寫到文件中。
- writeByteArrayToFile:將字節數組內容寫到文件中。
- writeLines:將容器中的元素的toString方法返回的內容依次寫入文件中。
- writeStringToFile:將字符串內容寫到文件中。
demo1:
package com.yoostar.coms;import org.apache.commons.io.FileUtils;public class FileUtilsDemo1 {public static void main(String[] args) throws Exception {String content = FileUtils.readFileToString(new File("d:/sxt.txt"), "utf-8");System.out.println(content);}
}
demo2:
package com.yoostar.coms;import org.apache.commons.io.FileUtils;public class FileUtilsDemo2 {public static void main(String[] args) throws Exception {FileUtils.copyDirectory(new File("d:/a"), new File("c:/a"), new FileFilter() {//在文件拷貝時的過濾條件@Overridepublic boolean accept(File pathname) {if (pathname.isDirectory() || pathname.getName().endsWith("html")) {return true;}return false;}});}
}
IOUtils的使用
- buffer方法:將傳入的流進行包裝,變成緩沖流。并可以通過參數指定緩沖大小。
- closeQueitly方法:關閉流。
- contentEquals方法:比較兩個流中的內容是否一致。
- copy方法:將輸入流中的內容拷貝到輸出流中,并可以指定字符編碼。
- copyLarge方法:將輸入流中的內容拷貝到輸出流中,適合大于 2 G內容的拷貝。
- lineIterator方法:返回可以迭代每一行內容的迭代器。
- read方法:將輸入流中的部分內容讀入到字節數組中。
- readFully方法:將輸入流中的所有內容讀入到字節數組中。
- readLine方法:讀入輸入流內容中的一行。
- toBufferedInputStream,toBufferedReader:將輸入轉為帶緩存的輸入流。
- toByteArray,toCharArray:將輸入流的內容轉為字節數組、字符數組。
- toString:將輸入流或數組中的內容轉化為字符串。
- write方法:向流里面寫入內容。
- writeLine方法:向流里面寫入一行內容
demo
package com.yoostar.coms;import java.io.FileInputStream;public class IOUtilsDemo {public static void main(String[] args) throws Exception {String content = IOUtils.toString(new FileInputStream("d:/sxt.txt"), "utf-8");System.out.println(content);}
}
IO流總結
按流的方向分類:
- 輸入流:數據源到程序(InputStream、Reader讀進來)。
- 輸出流:程序到目的地(OutPutStream、Writer寫出去)。
按流的處理數據單元分類:
- 字節流:按照字節讀取數據(InputStream、OutputStream)。
- 字符流:按照字符讀取數據(Reader、Writer)。
按流的功能分類:
- 節點流:可以直接從數據源或目的地讀寫數據。
- 處理流:不直接連接到數據源或目的地,是處理流的流。通過對其他流的處理提高程序的性能。
IO的四個基本抽象類:
InputStream、OutputStream、Reader、Writer
InputStream的實現類:
- FileInputStream
- ByteArrayInutStream
- BufferedInputStream
- DataInputStream
- ObjectInputStream
OutputStream的實現類:
- FileOutputStream
- ByteArrayOutputStream
- BufferedOutputStream
- DataOutputStream
- ObjectOutputStream
- PrintStream
Reader的實現類
- FileReader
- BufferedReader
- InputStreamReader
Writer的實現類
- FileWriter
- BufferedWriter
- OutputStreamWriter
Java IO設計模式
參考學習鏈接:Java IO 設計模式總結 | JavaGuide(Java面試 + 學習指南)
- 裝飾器模式
- 適配器模式
- 工廠模式
- 觀察者模式
JAVA IO模型詳解
I/O
何為 I/O?
I/O(Input/Outpu) 即輸入/輸出 。
我們先從計算機結構的角度來解讀一下 I/O。
根據馮.諾依曼結構,計算機結構分為 5 大部分:運算器、控制器、存儲器、輸入設備、輸出設備。
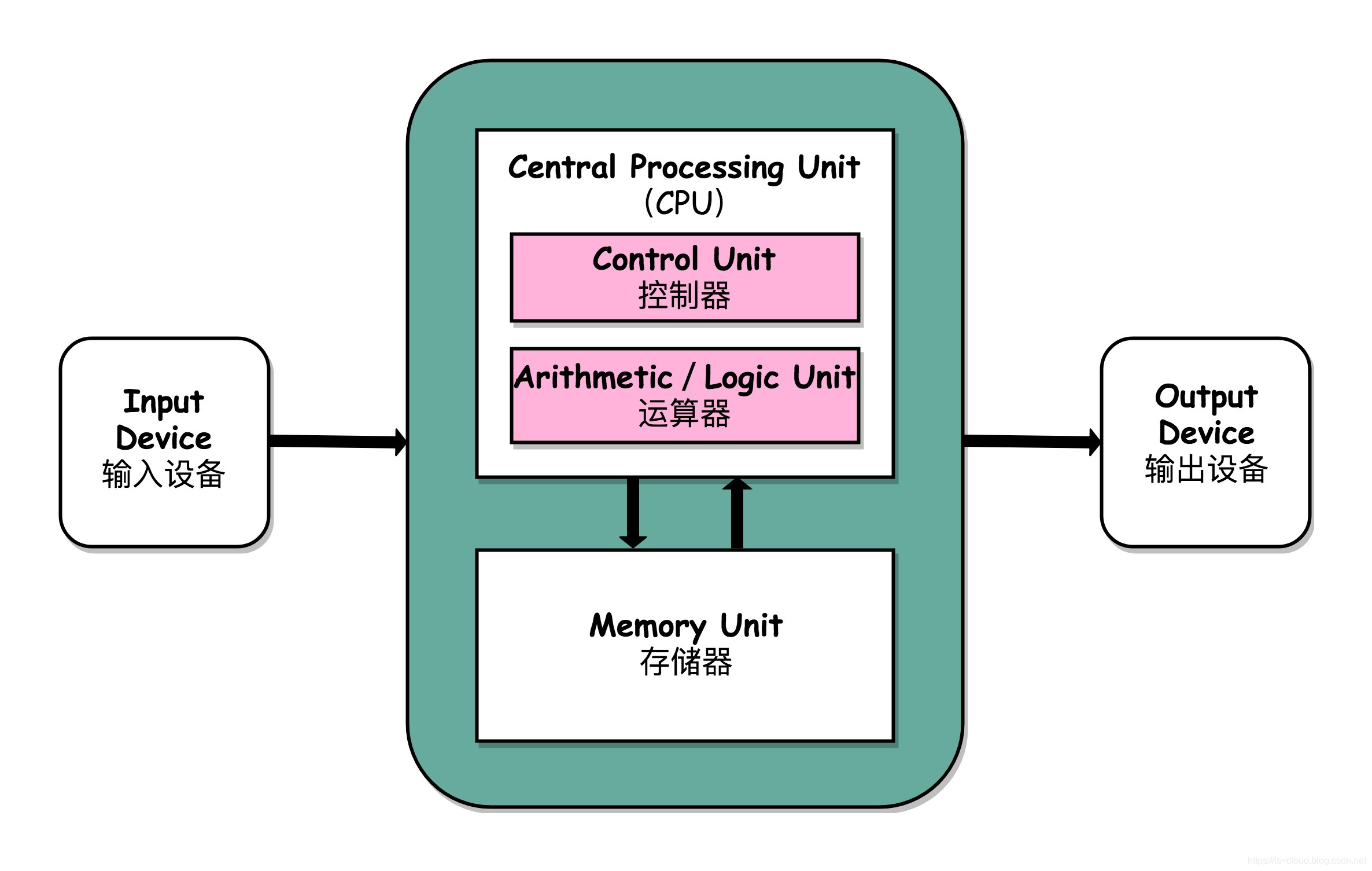 馮諾依曼體系結構
馮諾依曼體系結構
輸入設備(比如鍵盤)和輸出設備(比如顯示器)都屬于外部設備。網卡、硬盤這種既可以屬于輸入設備,也可以屬于輸出設備。
輸入設備向計算機輸入數據,輸出設備接收計算機輸出的數據。
從計算機結構的視角來看的話, I/O 描述了計算機系統與外部設備之間通信的過程。
我們再先從應用程序的角度來解讀一下 I/O。
根據大學里學到的操作系統相關的知識:為了保證操作系統的穩定性和安全性,一個進程的地址空間劃分為 用戶空間(User space) 和 內核空間(Kernel space ) 。
像我們平常運行的應用程序都是運行在用戶空間,只有內核空間才能進行系統態級別的資源有關的操作,比如文件管理、進程通信、內存管理等等。也就是說,我們想要進行 IO 操作,一定是要依賴內核空間的能力。
并且,用戶空間的程序不能直接訪問內核空間。
當想要執行 IO 操作時,由于沒有執行這些操作的權限,只能發起系統調用請求操作系統幫忙完成。
因此,用戶進程想要執行 IO 操作的話,必須通過 系統調用 來間接訪問內核空間
我們在平常開發過程中接觸最多的就是 磁盤 IO(讀寫文件) 和 網絡 IO(網絡請求和響應)。
從應用程序的視角來看的話,我們的應用程序對操作系統的內核發起 IO 調用(系統調用),操作系統負責的內核執行具體的 IO 操作。也就是說,我們的應用程序實際上只是發起了 IO 操作的調用而已,具體 IO 的執行是由操作系統的內核來完成的。
當應用程序發起 I/O 調用后,會經歷兩個步驟:
- 內核等待 I/O 設備準備好數據
- 內核將數據從內核空間拷貝到用戶空間。
有哪些常見的 IO 模型?
UNIX 系統下, IO 模型一共有 5 種:同步阻塞 I/O、同步非阻塞 I/O、I/O 多路復用、信號驅動 I/O 和異步 I/O。
這也是我們經常提到的 5 種 IO 模型。
Java 中 3 種常見 IO 模型
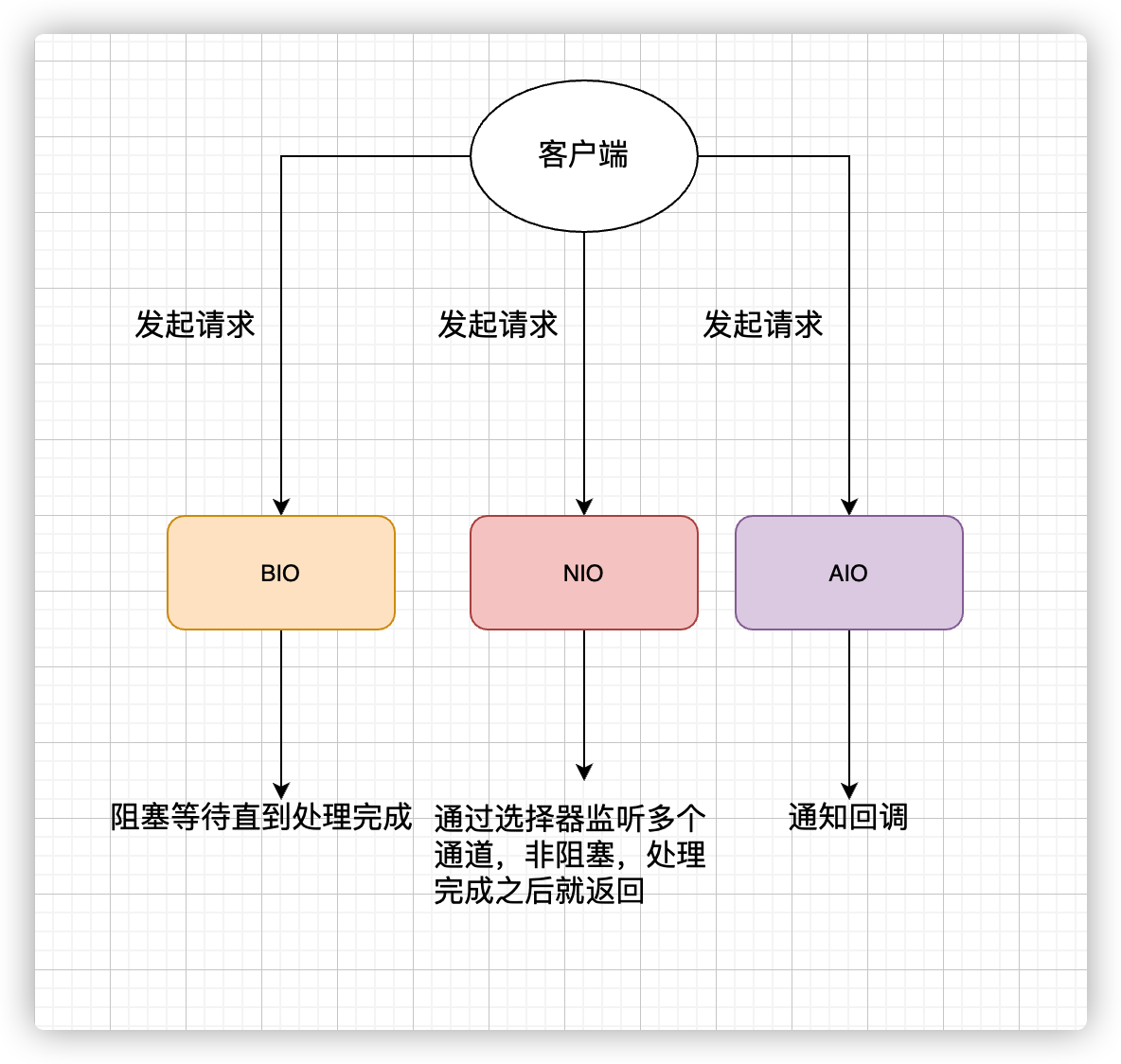
BIO (Blocking I/O)
BIO 屬于同步阻塞 IO 模型 。
同步阻塞 IO 模型中,應用程序發起 read 調用后,會一直阻塞,直到內核把數據拷貝到用戶空間。
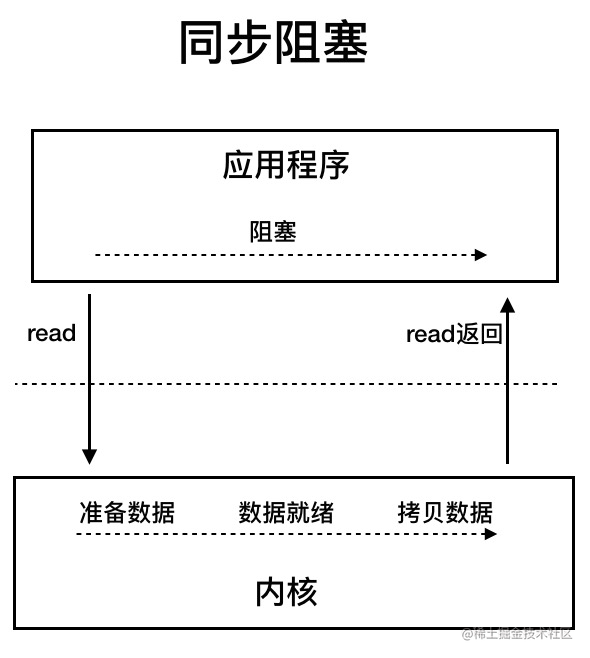 圖源:《深入拆解Tomcat & Jetty》
圖源:《深入拆解Tomcat & Jetty》
在客戶端連接數量不高的情況下,是沒問題的。但是,當面對十萬甚至百萬級連接的時候,傳統的 BIO 模型是無能為力的。因此,我們需要一種更高效的 I/O 處理模型來應對更高的并發量。
NIO (Non-blocking/New I/O)
Java 中的 NIO 于 Java 1.4 中引入,對應 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解為 Non-blocking,不單純是 New。它是支持面向緩沖的,基于通道的 I/O 操作方法。 對于高負載、高并發的(網絡)應用,應使用 NIO 。
Java 中的 NIO 可以看作是 I/O 多路復用模型。也有很多人認為,Java 中的 NIO 屬于同步非阻塞 IO 模型。
跟著我的思路往下看看,相信你會得到答案!
我們先來看看 同步非阻塞 IO 模型。
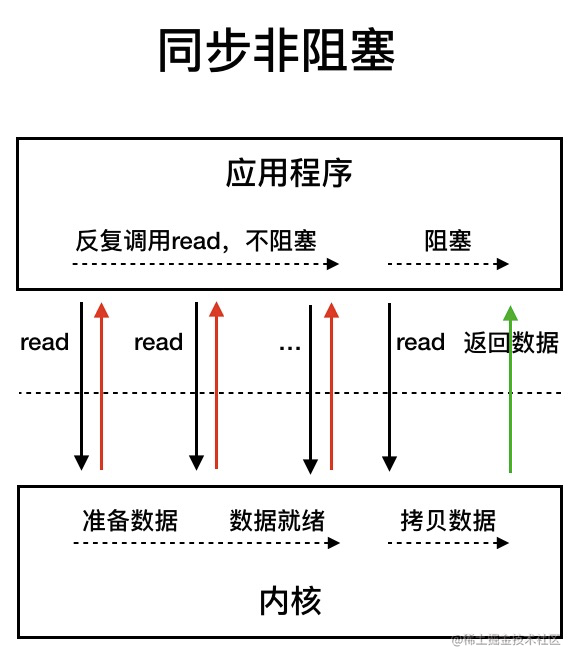 圖源:《深入拆解Tomcat & Jetty》
圖源:《深入拆解Tomcat & Jetty》
同步非阻塞 IO 模型中,應用程序會一直發起 read 調用,等待數據從內核空間拷貝到用戶空間的這段時間里,線程依然是阻塞的,直到在內核把數據拷貝到用戶空間。
相比于同步阻塞 IO 模型,同步非阻塞 IO 模型確實有了很大改進。通過輪詢操作,避免了一直阻塞。
但是,這種 IO 模型同樣存在問題:應用程序不斷進行 I/O 系統調用輪詢數據是否已經準備好的過程是十分消耗 CPU 資源的。
這個時候,I/O 多路復用模型 就上場了。
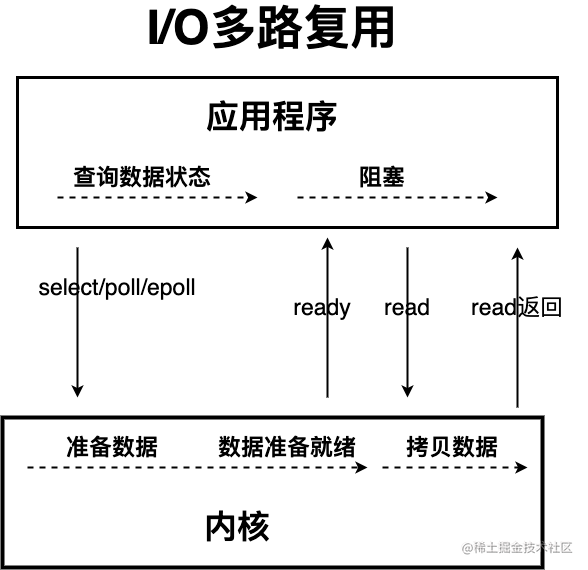
IO 多路復用模型中,線程首先發起 select 調用,詢問內核數據是否準備就緒,等內核把數據準備好了,用戶線程再發起 read 調用。read 調用的過程(數據從內核空間 -> 用戶空間)還是阻塞的。
目前支持 IO 多路復用的系統調用,有 select,epoll 等等。select 系統調用,目前幾乎在所有的操作系統上都有支持。
- select 調用:內核提供的系統調用,它支持一次查詢多個系統調用的可用狀態。幾乎所有的操作系統都支持。
- epoll 調用:linux 2.6 內核,屬于 select 調用的增強版本,優化了 IO 的執行效率。
IO 多路復用模型,通過減少無效的系統調用,減少了對 CPU 資源的消耗。
Java 中的 NIO ,有一個非常重要的選擇器 ( Selector ) 的概念,也可以被稱為 多路復用器。通過它,只需要一個線程便可以管理多個客戶端連接。當客戶端數據到了之后,才會為其服務。
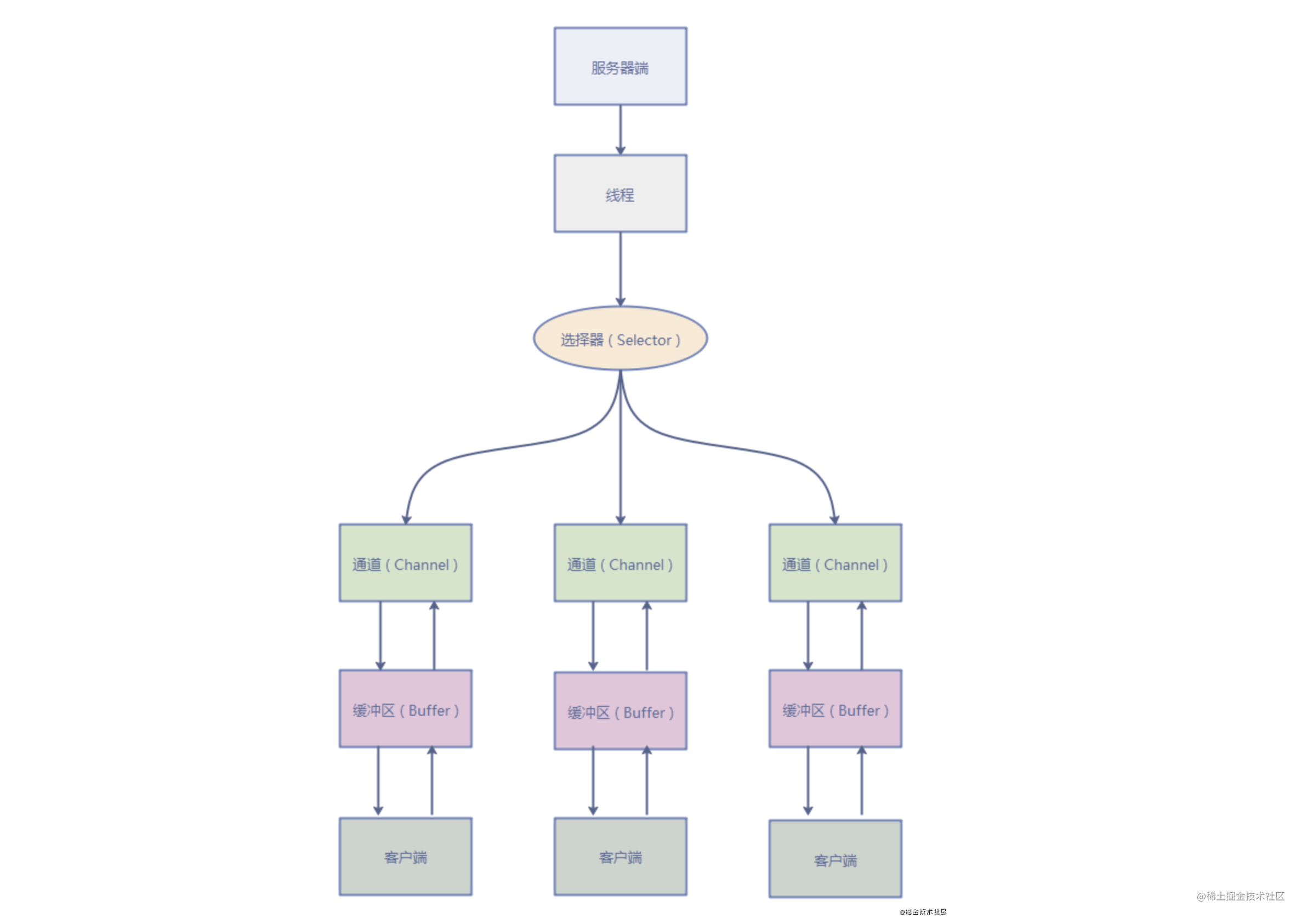
AIO (Asynchronous I/O)
AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改進版 NIO 2,它是異步 IO 模型。
異步 IO 是基于事件和回調機制實現的,也就是應用操作之后會直接返回,不會堵塞在那里,當后臺處理完成,操作系統會通知相應的線程進行后續的操作。
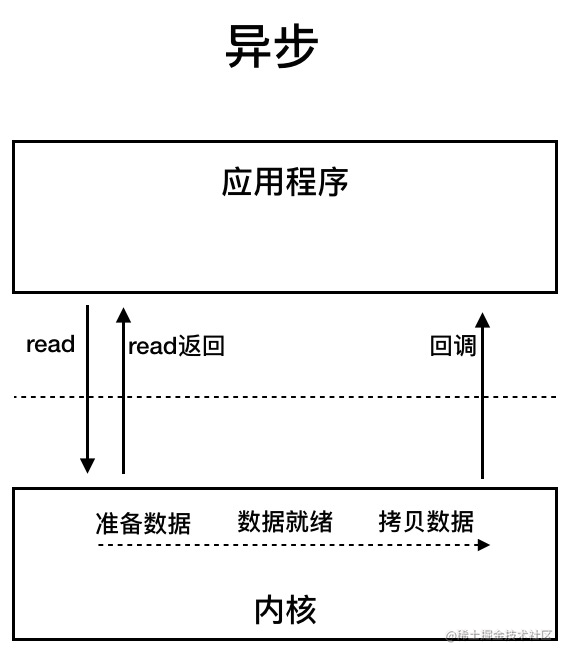
目前來說 AIO 的應用還不是很廣泛。Netty 之前也嘗試使用過 AIO,不過又放棄了。這是因為,Netty 使用了 AIO 之后,在 Linux 系統上的性能并沒有多少提升。
最后,來一張圖,簡單總結一下 Java 中的 BIO、NIO、AIO。
The End!!創作不易,歡迎點贊/評論!!歡迎關注個人GZH





_29_PPP協議判斷【6道題】)


 和 post() 方法—— W3school 詳解 簡單易懂(二十四))
)
)



)
:高級模擬算法)




- 12分庫分表)