神經網絡,這也是深度學習的基石,所謂的深度學習,也可以理解為很深層的神經網絡。說起這里,有一個小段子,神經網絡曾經被打入了冷宮,因為SVM派的崛起,SVM不了解的同學可以去google一下,中文叫支持向量機,因為其有著完備的數學解釋,并且之前神經網絡運算復雜等問題,導致神經網絡停步不前,這個時候任何以神經網絡為題目的論文都發不出去,反向傳播算法的鼻祖hinton為了解決這個問題,于是就想到了用深度學習為題目。
段子說完,接下來開始我們的簡單神經網絡。
Neural Network
其實簡單的神經網絡說起來很簡單
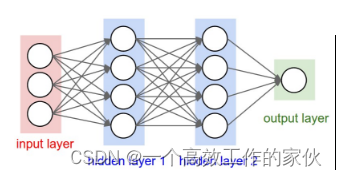
通過圖片就能很簡答的看出來,其實每一層網絡所做的就是 y=W×X+b,只不過W的維數由X和輸出維書決定,比如X是10維向量,想要輸出的維數,也就是中間層的神經元個數為20,那么W的維數就是20×10,b的維數就是20×1,這樣輸出的y的維數就為20。
中間層的維數可以自己設計,而最后一層輸出的維數就是你的分類數目,比如我們等會兒要做的MNIST數據集是10個數字的分類,那么最后輸出層的神經元就為10。
Code
有了前面兩節的經驗,這一節的代碼就很簡單了,數據的導入和之前一樣
定義模型
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | class Neuralnetwork(nn.Module): ????def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim): ????????super(Neuralnetwork, self).__init__() ????????self.layer1 = nn.Linear(in_dim, n_hidden_1) ????????self.layer2 = nn.Linear(n_hidden_1, n_hidden_2) ????????self.layer3 = nn.Linear(n_hidden_2, out_dim) ????def forward(self, x): ????????x = self.layer1(x) ????????x = self.layer2(x) ????????x = self.layer3(x) ????????return x model = Neuralnetwork(28*28, 300, 100, 10) if torch.cuda.is_available(): ????model = model.cuda() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=learning_rate) |
上面定義了三層神經網絡,輸入是28×28,因為圖片大小是28×28,中間兩個隱藏層大小分別是300和100,最后是個10分類問題,所以輸出層為10.
訓練過程與之前完全一樣,我就不再重復了,可以直接去github參看完整的代碼
這是50次之后的輸出結果,可以和上一節logistic回歸比較一下
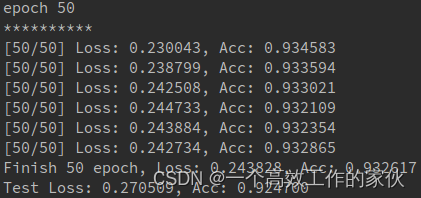
可以發現準確率大大提高,其實logistic回歸可以看成簡單的一層網絡,從這里我們就可以看出為什么多層網絡比單層網絡的效果要好,這也是為什么深度學習要叫深度的原因。
:函數、作用域、匿名函數)
)






)




-應用架構)

)

--- 牛馬耍雜技)

