目標
- 了解什么是文本張量表示及其作用.
- 文本張量表示的幾種方法及其實現.
1 文本張量表示
-
將一段文本使用張量進行表示,其中一般將詞匯為表示成向量,稱作詞向量,再由各個詞向量按順序組成矩陣形成文本表示.
["人生", "該", "如何", "起頭"]==># 每個詞對應矩陣中的一個向量
[[1.32, 4,32, 0,32, 5.2],[3.1, 5.43, 0.34, 3.2],[3.21, 5.32, 2, 4.32],[2.54, 7.32, 5.12, 9.54]]
-
文本張量表示的作用:
- 將文本表示成張量(矩陣)形式,能夠使語言文本可以作為計算機處理程序的輸入,進行接下來一系列的解析工作.
-
文本張量表示的方法:
- one-hot編碼
- Word2vec
- Word Embedding
2 one-hot詞向量表示
-
又稱獨熱編碼,將每個詞表示成具有n個元素的向量,這個詞向量中只有一個元素是1,其他元素都是0,不同詞匯元素為0的位置不同,其中n的大小是整個語料中不同詞匯的總數.
-
舉個例子:
["改變", "要", "如何", "起手"]` ==>[[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]] - onehot編碼實現:
- 進行onehot編碼:
-
# 導入用于對象保存與加載的joblib import joblib # 導入keras中的詞匯映射器Tokenizer from keras.preprocessing.text import Tokenizer # 假定vocab為語料集所有不同詞匯集合 vocab = {"周杰倫", "陳奕迅", "王力宏", "李宗盛", "吳亦凡", "鹿晗"} # 實例化一個詞匯映射器對象 t = Tokenizer(num_words=None, char_level=False) # 使用映射器擬合現有文本數據 t.fit_on_texts(vocab)for token in vocab:zero_list = [0]*len(vocab)# 使用映射器轉化現有文本數據, 每個詞匯對應從1開始的自然數# 返回樣式如: [[2]], 取出其中的數字需要使用[0][0]token_index = t.texts_to_sequences([token])[0][0] - 1zero_list[token_index] = 1print(token, "的one-hot編碼為:", zero_list)# 使用joblib工具保存映射器, 以便之后使用 tokenizer_path = "./Tokenizer" joblib.dump(t, tokenizer_path) - 輸出效果:
鹿晗 的one-hot編碼為: [1, 0, 0, 0, 0, 0] 王力宏 的one-hot編碼為: [0, 1, 0, 0, 0, 0] 李宗盛 的one-hot編碼為: [0, 0, 1, 0, 0, 0] 陳奕迅 的one-hot編碼為: [0, 0, 0, 1, 0, 0] 周杰倫 的one-hot編碼為: [0, 0, 0, 0, 1, 0] 吳亦凡 的one-hot編碼為: [0, 0, 0, 0, 0, 1]# 同時在當前目錄生成Tokenizer文件, 以便之后使用 - onehot編碼器的使用:
# 導入用于對象保存與加載的joblib # from sklearn.externals import joblib # 加載之前保存的Tokenizer, 實例化一個t對象 t = joblib.load(tokenizer_path)# 編碼token為"李宗盛" token = "李宗盛" # 使用t獲得token_index token_index = t.texts_to_sequences([token])[0][0] - 1 # 初始化一個zero_list zero_list = [0]*len(vocab) # 令zero_List的對應索引為1 zero_list[token_index] = 1 print(token, "的one-hot編碼為:", zero_list) - 輸出效果:
李宗盛 的one-hot編碼為: [1, 0, 0, 0, 0, 0]-
one-hot編碼的優劣勢:
- 優勢:操作簡單,容易理解.
-
劣勢:完全割裂了詞與詞之間的聯系,而且在大語料集下,每個向量的長度過大,占據大量內存.
-
正因為one-hot編碼明顯的劣勢,這種編碼方式被應用的地方越來越少,取而代之的是接下來我們要學習的稠密向量的表示方法word2vec和word embedding.
3 word2vec模型
3.1 模型介紹
-
word2vec是一種流行的將詞匯表示成向量的無監督訓練方法, 該過程將構建神經網絡模型, 將網絡參數作為詞匯的向量表示, 它包含CBOW和skipgram兩種訓練模式.
-
CBOW(Continuous bag of words)模式:
- 給定一段用于訓練的文本語料, 再選定某段長度(窗口)作為研究對象, 使用上下文詞匯預測目標詞匯.
3.2 word2vec的訓練和使用
- 第一步: 獲取訓練數據
- 第二步: 訓練詞向量
- 第三步: 模型超參數設定
- 第四步: 模型效果檢驗
- 第五步: 模型的保存與重加載
1 獲取訓練數據
數據來源:http://mattmahoney.net/dc/enwik9.zip
在這里, 我們將研究英語維基百科的部分網頁信息, 它的大小在300M左右。這些語料已經被準備好, 我們可以通過Matt Mahoney的網站下載。
注意:原始數據集已經放在/root/data/enwik9.zip,解壓后數據為/root/data/enwik9,預處理后的數據為/root/data/fil9
- 查看原始數據:
$ head -10 data/enwik9# 原始數據將輸出很多包含XML/HTML格式的內容, 這些內容并不是我們需要的 <mediawiki xmlns="http://www.mediawiki.org/xml/export-0.3/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.3/ http://www.mediawiki.org/xml/export-0.3.xsd" version="0.3" xml:lang="en"><siteinfo><sitename>Wikipedia</sitename><base>http://en.wikipedia.org/wiki/Main_Page</base><generator>MediaWiki 1.6alpha</generator><case>first-letter</case><namespaces><namespace key="-2">Media</namespace><namespace key="-1">Special</namespace><namespace key="0" /> - 原始數據處理:
# 使用wikifil.pl文件處理腳本來清除XML/HTML格式的內容
# perl wikifil.pl data/enwik9 > data/fil9 #該命令已經執行- 查看預處理后的數據:
# 查看前80個字符
head -c 80 data/fil9# 輸出結果為由空格分割的單詞anarchism originated as a term of abuse first used against early working class2 訓練詞向量
# 代碼運行在python解釋器中
# 導入fasttext
>>> import fasttext
# 使用fasttext的train_unsupervised(無監督訓練方法)進行詞向量的訓練
# 它的參數是數據集的持久化文件路徑'data/fil9'# 注意,該行代碼執行耗時很長
>>> model1 = fasttext.train_unsupervised('data/fil9') # 可以使用以下代碼加載已經訓練好的模型
>>> model = fasttext.load_model("data/fil9.bin")# 有效訓練詞匯量為124M, 共218316個單詞
Read 124M words
Number of words: 218316
Number of labels: 0
Progress: 100.0% words/sec/thread: 53996 lr: 0.000000 loss: 0.734999 ETA: 0h 0m3 查看單詞對應的詞向量
# 通過get_word_vector方法來獲得指定詞匯的詞向量
>>> model.get_word_vector("the")array([-0.03087516, 0.09221972, 0.17660329, 0.17308897, 0.12863874,0.13912526, -0.09851588, 0.00739991, 0.37038437, -0.00845221,...-0.21184735, -0.05048715, -0.34571868, 0.23765688, 0.23726143],dtype=float32)4 模型超參數設定
# 在訓練詞向量過程中, 我們可以設定很多常用超參數來調節我們的模型效果, 如:
# 無監督訓練模式: 'skipgram' 或者 'cbow', 默認為'skipgram', 在實踐中,skipgram模式在利用子詞方面比cbow更好.
# 詞嵌入維度dim: 默認為100, 但隨著語料庫的增大, 詞嵌入的維度往往也要更大.
# 數據循環次數epoch: 默認為5, 但當你的數據集足夠大, 可能不需要那么多次.
# 學習率lr: 默認為0.05, 根據經驗, 建議選擇[0.01,1]范圍內.
# 使用的線程數thread: 默認為12個線程, 一般建議和你的cpu核數相同.>>> model = fasttext.train_unsupervised('data/fil9', "cbow", dim=300, epoch=1, lr=0.1, thread=8)Read 124M words
Number of words: 218316
Number of labels: 0
Progress: 100.0% words/sec/thread: 49523 lr: 0.000000 avg.loss: 1.777205 ETA: 0h 0m 0s5 模型效果檢驗
# 檢查單詞向量質量的一種簡單方法就是查看其鄰近單詞, 通過我們主觀來判斷這些鄰近單詞是否與目標單詞相關來粗略評定模型效果好壞.# 查找"運動"的鄰近單詞, 我們可以發現"體育網", "運動汽車", "運動服"等.
>>> model.get_nearest_neighbors('sports')[(0.8414610624313354, 'sportsnet'), (0.8134572505950928, 'sport'), (0.8100415468215942, 'sportscars'), (0.8021156787872314, 'sportsground'), (0.7889881134033203, 'sportswomen'), (0.7863013744354248, 'sportsplex'), (0.7786710262298584, 'sporty'), (0.7696356177330017, 'sportscar'), (0.7619683146476746, 'sportswear'), (0.7600985765457153, 'sportin')]# 查找"音樂"的鄰近單詞, 我們可以發現與音樂有關的詞匯.
>>> model.get_nearest_neighbors('music')[(0.8908010125160217, 'emusic'), (0.8464668393135071, 'musicmoz'), (0.8444250822067261, 'musics'), (0.8113634586334229, 'allmusic'), (0.8106718063354492, 'musices'), (0.8049437999725342, 'musicam'), (0.8004694581031799, 'musicom'), (0.7952923774719238, 'muchmusic'), (0.7852965593338013, 'musicweb'), (0.7767147421836853, 'musico')]# 查找"小狗"的鄰近單詞, 我們可以發現與小狗有關的詞匯.
>>> model.get_nearest_neighbors('dog')[(0.8456876873970032, 'catdog'), (0.7480780482292175, 'dogcow'), (0.7289096117019653, 'sleddog'), (0.7269964218139648, 'hotdog'), (0.7114801406860352, 'sheepdog'), (0.6947550773620605, 'dogo'), (0.6897546648979187, 'bodog'), (0.6621081829071045, 'maddog'), (0.6605004072189331, 'dogs'), (0.6398137211799622, 'dogpile')]6 模型的保存與重加載
# 使用save_model保存模型
>>> model.save_model("fil9.bin")# 使用fasttext.load_model加載模型
>>> model = fasttext.load_model("fil9.bin")
>>> model.get_word_vector("the")array([-0.03087516, 0.09221972, 0.17660329, 0.17308897, 0.12863874,0.13912526, -0.09851588, 0.00739991, 0.37038437, -0.00845221,...-0.21184735, -0.05048715, -0.34571868, 0.23765688, 0.23726143],dtype=float32)4 詞嵌入word embedding介紹
- 通過一定的方式將詞匯映射到指定維度(一般是更高維度)的空間.
- 廣義的word embedding包括所有密集詞匯向量的表示方法,如之前學習的word2vec, 即可認為是word embedding的一種.
-
狹義的word embedding是指在神經網絡中加入的embedding層, 對整個網絡進行訓練的同時產生的embedding矩陣(embedding層的參數), 這個embedding矩陣就是訓練過程中所有輸入詞匯的向量表示組成的矩陣.
-
word embedding的可視化分析:
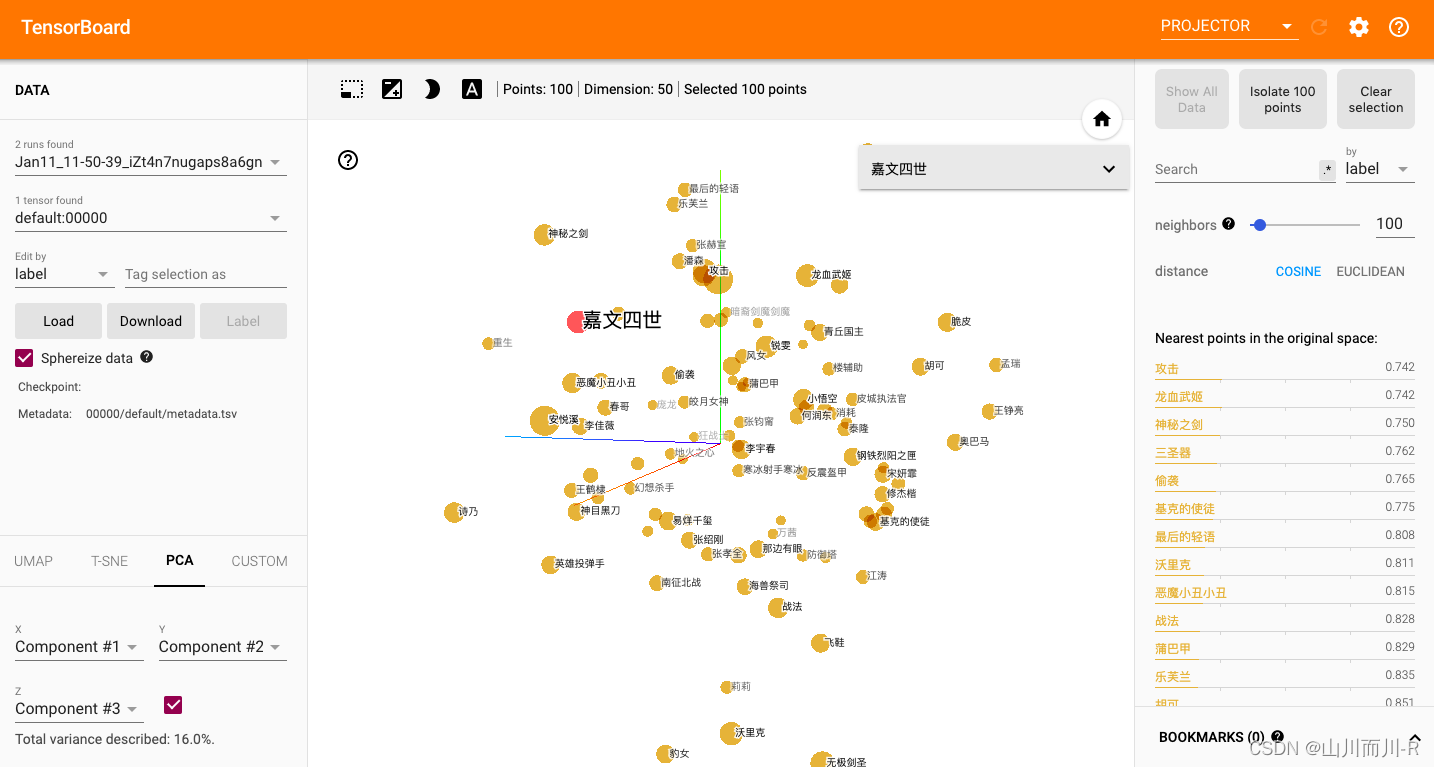
- 通過使用tensorboard可視化嵌入的詞向量.
import tensorflow as tf
import tensorboard as tb
tf.io.gfile = tb.compat.tensorflow_stub.io.gfile# 導入torch和tensorboard的摘要寫入方法
import torch
import json
import fileinput
from torch.utils.tensorboard import SummaryWriter
# 實例化一個摘要寫入對象
writer = SummaryWriter()# 隨機初始化一個100x50的矩陣, 認為它是我們已經得到的詞嵌入矩陣
# 代表100個詞匯, 每個詞匯被表示成50維的向量
embedded = torch.randn(100, 50)# 導入事先準備好的100個中文詞匯文件, 形成meta列表原始詞匯
meta = list(map(lambda x: x.strip(), fileinput.FileInput("./vocab100.csv")))
writer.add_embedding(embedded, metadata=meta)
writer.close()- 在終端啟動tensorboard服務:
$ cd ~
$ tensorboard --logdir=runs --host 0.0.0.0# 通過http://192.168.88.161:6006訪問瀏覽器可視化頁面- 瀏覽器展示并可以使用右側近鄰詞匯功能檢驗效果:






)




-應用架構)

)

--- 牛馬耍雜技)



Tensor使用教程)