
?🎈個人主頁:庫庫的里昂
?收錄專欄:C++從練氣到飛升
🎉鳥欲高飛先振翅,人求上進先讀書。

目錄
推薦
前言
什么是C++
C++的發展史
📋命名空間
命名空間定義
命名空間使用
命名空間的嵌套
std命名空間的使用
📋C++輸入&輸出
缺省參數的定義
缺省參數分類
缺省參數出現的位置
📋函數重載
函數重載的概念
函數重載的種類
C++支持函數重載的原理
📋引用
引用的概念
引用的特性
引用的使用場景
傳值和引用性能比較
常引用
引用和指針的區別?
📋內聯函數
內聯函數的概念
內聯函數的特征
📋auto關鍵字
auto簡介
auto使用規則
auto無法使用的場景
📋基于范圍的for循環
范圍for的語法
范圍for的使用條件
📋指針空值nullptr
??推薦
前些天發現了一個巨牛的人工智能學習網站,通俗易懂,風趣幽默,忍不住分享一下給大家。點擊跳轉到網站
前言
什么是C++
????????C語言是結構化和模塊化的語言,適合處理較小規模的程序。對于復雜的問題,規模較大的程序,需要高度的抽象和建模時,C語言則不合適。為了解決軟件危機, 20世紀80年代, 計算機界提出了OOP(object oriented programming:面向對象)思想,支持面向對象的程序設計語言應運而生。
????????1982年,Bjarne Stroustrup博士在C語言的基礎上引入并擴充了面向對象的概念,發明了一種新的程序語言。為了表達該語言與C語言的淵源關系,命名為C++。因此:C++是基于C語言而產生的,它既可以進行C語言的過程化程序設計,又可以進行以抽象數據類型為特點的基于對象的程序設計,還可以進行面向對象的程序設計。
C++的發展史
????????1979年,貝爾實驗室的本賈尼等人試圖分析unix內核的時候,試圖將內核模塊化,于是在C語言的基礎上進行擴展,增加了類的機制,完成了一個可以運行的預處理程序,稱之為C with classes。
語言的發展就像是練功打怪升級一樣,也是逐步遞進,由淺入深的過程。我們先來看下C++的歷史版本。

C++還在不斷的向后發展。但是:現在公司主流使用還是C++98和C++11,所有大家不用追求最新,重點將C++98和C++11掌握好,等工作后,隨著對C++理解不斷加深,有興趣的小伙伴可以去琢磨下更新的特性。
📋命名空間
在C/C++中,變量、函數和后面要學到的類都是大量存在的,這些變量、函數和類的名稱將都存在于全局作用域中,可能會導致很多沖突。使用命名空間的目的是對標識符的名稱進行本地化,以避免命名沖突或名字污染,namespace關鍵字的出現就是針對這種問題的。
#include <stdio.h>
#include <stdlib.h>int rand = 10;// C語言沒辦法解決類似這樣的命名沖突問題,所以C++提出了namespace來解決
int main()
{printf("%d\n", rand);return 0;
}// 編譯后后報錯:error C2365: “rand”: 重定義;以前的定義是“函數”命名空間定義
命名空間的定義由兩部分構成:首先是關鍵字namespace,后面跟命名空間的名字,然后接一對{},{}中即為命名空間的成員。?命名空間中可以定義變量、函數、類型和其他命名空間。
namespace N1//命名空間的名字
{//定義變量int rand = 10;//定義函數int Add(int left, int right){return left + right;}//定義類型struct Node{struct Node* next;int val;};//嵌套命名空間namespace N2{int Sub(int left, int right){return left - right;}}
}注意:
- 一個命名空間就定義了一個新的作用域,命名空間中的所有內容都局限于該命名空間中。
- 用一個工程中允許出現多個相同名稱的命名空間,編譯器最后會將它們合并為一個命名空間。
命名空間使用
命名空間的使用有三種方式:
- 加命名空間名稱及域作用限定符
namespace N {int a=10;int b=5; }int main() {printf("%d\n", N::a);return 0; }
- 使用 using 將命名空間中某個成員引入
using N::b; int main() {printf("%d\n", N::a);printf("%d\n", b);return 0; }
- 使用 using namespace 命名空間名稱引入(展開命名空間)
namespace N {int a=10;int b=5; }int a=20;using namespce N;int main() {printf("%d\n", a); //a不明確,有二義性printf("%d\n", ::a); //訪問全局的a printf("%d\n", N::a); //訪問N中的aprintf("%d\n", b);return 0; }N中的成員a?就與全局作用域中的a?產生了沖突。這種沖突是允許存在的,但是要想使用沖突的名字,我們就必須明確指出名字的版本。main函數中所有未加限定的a都會產生二義性錯誤。
這時我們必須使用域作用限定符(::)來明確指出所需的版本
- :?:a來表示全局作用域中的a
- N: :a來表示定義在N中的a
注意:
如果命名空間沒有展開,編譯器默認是不會搜索命名空間中的變量,去訪問變量是訪問不到的。
訪問的優先級:局部域 > 全局域
命名空間的嵌套
嵌套的命名空間同時是一個嵌套的作用域,它嵌套在外層命名空間的作用域中。嵌套的命名空間中的名字遵循的規則與往常類似:內層命名空間聲明的名字將隱藏外層命名空間聲明的同名成員。在嵌套的命名空間中定義的名字只在內層命名空間中有效,外層命名空間的代碼想要訪問它必須在名字前添加限定符。
namespace N
{int a = 10;namespace N1{int a = 20; //將外層作用域的a隱藏了int b = 15;namespace N2{int c = N1::b;}
}int main()
{printf("%d\n", N::N2::c);printf("%d\n", N::N1::a);printf("%d\n", N::a);return 0;
}std命名空間的使用
std是C++標準庫的命名空間,如何展開std使用更合理呢?
- 在日常練習中,建議直接using namespace std;即可,這樣就很方便。
- ?using namespace std;展開,標準庫就全部暴露出來了,如果我們定義跟庫重名的類型、對象、函數,就存在沖突問題。該問題在日常練習中很少出現,但是項目開發中代碼較多、規模 大,就很容易出現。所以建議在項目開發中使用,像std::cout這樣使用時指定命名空間例如: using std::cout展開常用的庫對象、類型等方式。?
📋C++輸入&輸出
#include <iostream>
using namespace std;int main()
{int a = 10;double b = 10.5;cout << a << endl;cout << b << endl;return 0;
}我們在項目中要經常使用?cout?和?endl,每次指定命名空間很不方便,直接展開會全部暴露,有沖突風險,我們可以指定展開來解決問題。
using std::cout;
using std::endl;說明:
- 使用cout標準輸出對象(控制臺)和cin標準輸入對象(鍵盤)時,必須包含< iostream >頭文件以及按命名空間使用方法使用std。
- cout?和?cin?是全局的流對象,endl?是特殊的C++符號,表示換行輸出,他們都包含在包含?< iostream >頭文件中。
<<是流插入運算符,>>是流提取運算符。- 使用C++輸入輸出更方便,不需要像 printf和scanf 輸入輸出時那樣,需要手動控制格式。?C++的輸入輸出可以自動識別變量類型。
📋缺省參數
缺省參數的定義
? ? ?缺省參數是聲明或定義函數時為函數的參數指定一個缺省值。在調用該函數時,如果沒有指定實參則采用該形參的缺省值,否則使用指定的實參。
void Func(int a = 5)
{cout << a << endl;
}int main()
{Func(); // 沒有傳參時,使用參數的默認值Func(10); // 傳參時,使用指定的實參return 0;
}
上面代碼在第一次調用?Func()?時,沒有傳遞參數,a?就使用了缺省值。
缺省參數分類
- 全缺省參數 -- 所有參數都給了缺省值
void Func(int a = 10, int b = 20, int c = 30) {cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl; }int main() {Func(1,2,3); Func(1,2); Func(1); Func(); return 0; }
全缺省參數在傳參時,參數是按照從左往右的順序進行缺省的,不能跳著缺省,例如:Func(1,? ,3) ,讓第一個形參和第三個形參都使用傳遞值,而讓第二個參數使用缺省值,這種做法是不被允許的。
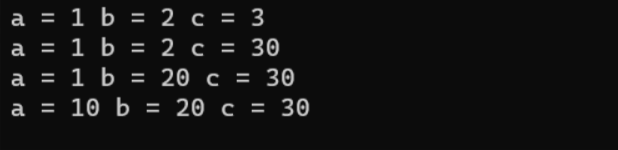
- 半缺省參數 --?部分的參數給了缺省值
void Func(int a, int b = 20, int c = 30) {cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl; }int main() {Func(1,2,3); Func(1,2); Func(1); return 0; }半缺省參數必須從右往左依次來給出,不能間隔著給。
注意:
- 缺省參數不能在函數聲明和定義中同時出現,只能出現在函數聲明中。
- 缺省值必須是常量或者全局變量。
缺省參數出現的位置
??? ??缺省參數只能出現在函數聲明中,如下面的代碼,在聲明和定義中都給了缺省參數,而且給定的值不相同,就不知道以哪個值為準。
//a.h
void Func(int a = 10);//a.cpp
void Func(int a = 20)
{}不能只在聲明處給缺省參數,如下面的代碼,如果只在聲明處給缺省參數,在其他的文件中沒有缺省參數,就不知是什么值。
//a.cpp
void Func(int a = 10)
{}//b.cpp
void Func(int a)
{}📋函數重載
? ? ?自然語言中,一個詞可以有多重含義,人們可以通過上下文來判斷該詞真實的含義,即該詞被重載了。 比如:以前有一個笑話,國有兩個體育項目大家根本不用看,也不用擔心。一個是乒乓球,一個 是男足。前者是“誰也贏不了!”,后者是“誰也贏不了!”
函數重載的概念
? ? ?函數重載是函數的一種特殊情況,C++允許在同一作用域中聲明幾個功能類似的同名函數,這些同名函數的形參列表(參數個數或類型或類型順序)不同,常用來處理實現功能類似數據類型不同的問題。
函數重載的種類
- 參數類型不同
int Add(int left, int right) {cout << "int Add(int left, int right)" << endl;return left + right; }double Add(double left, double right) {cout << "double Add(double left, double right)" << endl;return left + right; }int main() {cout << Add(1, 2) << endl;cout << Add(1.0, 2.0) << endl; }上面的代碼定義了兩個同名的Add函數,但是它們的參數類型不同,第一個函數的兩個參數都是int型,第二個函數的兩個參數都是double型,在調用Add函數的時候,編譯器會根據所傳實參的類型自動判斷調用哪個函數。
- 參數個數不同
void Fun() {cout << "f()" << endl; }void Fun(int a) {cout << "f(int a)" << endl; }int main() {Fun();Fun(1);return 0; }

- 參數類型順序不同
void Text(int a, char b) {cout << "Text(int a,char b)" << endl; }void Text(char b, int a) {cout << "Text(char b, int a)" << endl; }int main() {Text(1, 'a');Text('a', 1);return 0; }
- 有缺省參數的情況
void Fun() {cout << "f()" << endl; }void Fun(int a = 10) {cout << "f(int a)" << endl; }int main() {Fun(); //無參調用會出現歧義Fun(1); //調用的是第二個return 0; }上面代碼中的兩個Fun函數構成函數重載,編譯可以通過,因為第一個沒有參數,第二個有一個整型參數,屬于上面的參數個數不同的情況。但是Fun函數存在一個問題:在沒有參數調用的時候會產生歧義,因為有缺省參數,所以對兩個Fun函數來說,都可以不傳參。
注意:返回值的類型與函數是否構成重載無關。
C++支持函數重載的原理
? ? ?在C/C++中,一個程序要運行起來,需要經歷以下幾個階段:預處理、編譯、匯編、鏈接。
我們想理解清楚函數重載,還要了解函數簽名的概念,函數簽名包含了一個函數的信息,包括函數名、它的參數類型、他所在的類和名稱空間以及其他信息。函數簽名用于識別不同的函數。 C++編譯器和鏈接器都使用符號來標識和處理函數和變量,所以對于不同函數簽名的函數,即使函數名相同,編譯器和鏈接器都認為他們是不同的函數。
Linux環境下采用C語言編譯器編譯后結果
可以看出經過gcc編譯后,函數名字的修飾沒有發生改變。這也就是為什么C語言不支持函數重
載,因為同名函數沒辦法區分。
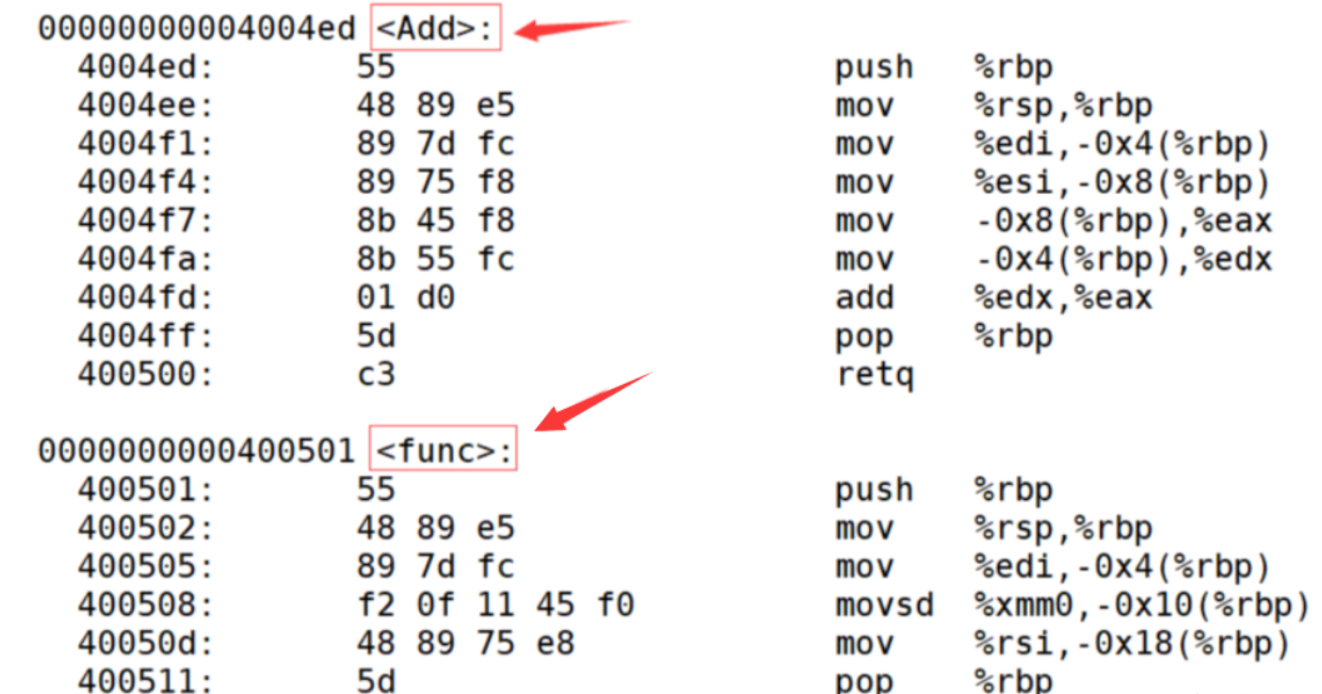
采用C++編譯器編譯后結果
其中_Z是固定的前綴;3表示函數名的長度;Add就是函數名;i是int的縮寫,兩個i表示兩個參數都是int類型,d是double的縮寫,兩個d表示兩個參數都是double類型。C++就是通過函數修飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。通過分析可以發現,修飾后的名稱中并不包含任何于函數返回值有關的信息,因此也驗證了上面說的返回值的類型與函數是否構成重載無關。

總結:
- C語言之所以沒辦法支持重載,是因為同名函數沒辦法區分。而C++是通過函數修飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。
- 如果兩個函數函數名和參數是一樣的,返回值不同是不構成重載的,因為調用時編譯器沒辦法區分。
📋引用
引用的概念
引用不是新定義一個變量,而是給已存在變量取了一個別名,編譯器不會為引用變量開辟內存空 間,它和它引用的變量共用同一塊內存空間。

類型& 引用變量名(對象名) = 引用實體
int main()
{int a = 0;int& b = a;//定義引用類型,b是a的引用return 0;
}注意:引用類型必須和引用實體是同種類型的
引用的特性
- 引用在定義時必須初始化
int main() {int a = 10;int& b; //錯誤的return 0; }
在使用引用時,我們必須對變量進行初始化。int& b = a;,這樣的代碼才是被允許的。

- 引用不能改變指向
int main() {int a = 10;int b = 20;int& c = a;c = b;return 0; }
我們可以看到b和c的地址不同,所以c = b表示的不是c是b引用,而是是把b變量的值賦值給c引用的實體,c依舊是a的引用,所以引用一旦引用一個實體,再不能引用其他實體,也就是引用不能改變指向。

引用的使用場景
🎀做參數
引用做參數的意義:
- 做輸出型參數,即要求形參的改變可以影響實參
- 提高效率,自定義類型傳參,用引用可以避免拷貝構造,尤其是大對象和深拷貝對象
交換兩個整型變量:?
void Swap(int& num1, int& num2) {int tmp = num1;num1 = num2;num2 = tmp; }int main() {int a = 5;int b = 10;Swap(a,b);return 0; }如上代碼,我們可以使用引用做參數實現了兩個數的交換,num1是?a?的引用,和?a?在同一塊空間,對num1的修改也就是對?a?修改,?b?同理,所以在函數體內交換num1和num2實際上就是交換?a?和?b?。以前交換兩個數的值,我們需要傳遞地址,還要進行解引用,相對繁瑣。
交換兩個指針變量:
void Swap(int*& p1, int*& p2) {int* tmp = p1;p1 = p2;p2 = tmp; }int main() {int a = 5;int b = 10;int* pa = &a;int* pb = &b;Swap(pa,pb);return 0; }如果用C語言來實現交換兩個指針變量,實參需要傳遞指針變量的地址,那形參就需要用二級指針來接收,這顯然十分容易出錯。有了引用之后,實參直接傳遞指針變量即可,形參用指針類型的引用。
🎀做返回值
引用做返回值的意義:
- 減少拷貝,提高效率。
- 可以同時讀取和修改返回對象
int& add(int x, int y)
{int sum = x + y;return sum;
}int main()
{int a = 5;int b = 10;int ret = add(a, b);cout << ret << endl;return 0;
}如上代碼,我們使用傳值返回,調用函數要創建棧幀,sum是add函數中的一個局部變量,存儲在當前函數的棧幀中,函數調用結束棧幀銷毀,sum也會隨之銷毀,對于這種傳值返回,會生成一個臨時的中間變量,用來存儲返回值,在返回值比較小的情況下,這個臨時的中間變量一般就是寄存器。
如上代碼,傳引用就是給sum起了一個別名,返回的值就是sum的別名,但是這里會出現問題,函數調用結束棧幀銷毀,sum也會隨之銷毀,返回它的值再進行調用就是越界訪問,打印出的值為隨機值。

可是這里的值為什么是正確的呢?這是取決于編譯器的,看編譯器是否會對這塊空間進行清理。
傳值和引用性能比較
? ? ?以值作為參數或者返回值類型,在傳參和返回期間,函數不會直接傳遞實參或者將變量本身直 接返回,而是傳遞實參或者返回變量的一份臨時的拷貝,因此用值作為參數或者返回值類型,效 率是非常低下的,尤其是當參數或者返回值類型非常大時,效率就更低。
struct A
{int a[100000];
};void TestFunc1(A a)
{;
}void TestFunc2(A& a)
{;
}void TestFunc3(A* a)
{;
}//引用傳參————可以提高效率(大對象或者深拷貝的類對象)
void TestRefAndValue()
{A a;// 以值作為函數參數size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)//就是單純的調用一萬次這個函數傳一萬次參TestFunc1(a);size_t end1 = clock();// 以引用作為函數參數size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);//這里直接傳的是變量名size_t end2 = clock();//以指針作為函數參數size_t begin3 = clock();for (int i = 0; i < 10000; i++){TestFunc3(&a);}size_t end3 = clock();// 分別計算兩個函數運行結束后的時間cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;cout << "TestFunc3(A*)-time:" << end3 - begin3 << endl;
}
值和引用的作為返回值類型的性能比較:
struct A
{int a[100000];
};
A a;//全局的,函數棧幀銷毀后還在// 值返回
A TestFunc1()
{return a;
}// 引用返回
A& TestFunc2()
{return a;
}
void TestReturnByRefOrValue()
{// 以值作為函數的返回值類型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();//就讓他返回不接收size_t end1 = clock();// 以引用作為函數的返回值類型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 計算兩個函數運算完成之后的時間cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}int main()
{TestReturnByRefOrValue();return 0;
}
常引用
🎀?權限放大
int main()
{const int a = 10;int& b = a;return 0;
}![]()
???????上面代碼中,用const定義了一個常變量?a?,然后給a取一個別名?b?,這段代碼在編譯過程中出現了錯誤,這是為什么呢?
? ? ??a?是一個常變量,是不可以被修改的,給?a?取別名為變量?b?,變量b沒有用const修飾,所以不具有常屬性,是可以被修改的,相當于權限的放大,這種情況是不允許的。正確的做法是:
int main()
{const int a = 10;const int& b = a;return 0;
}🎀?權限縮小
int main()
{int a = 10;const int& b = a;return 0;
}????????上面代碼中,給一個普通的變量a取了一個別名b,這個b是一個常引用。這意味著,可以通過a變量去對內存中存儲的數據進行修改,但是不能通過b去修改內存中存儲的數據,但是b會跟著變。
引用和指針的區別?
- 引用在概念上定義一個變量的別名,指針存儲一個變量的地址。
- 引用在定義時必須初始化,指針沒有要求。
- 引用在初始化時引用一個一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何一個同類型實體。
- 沒有NULL引用,但有NULL空指針。
- 在sizeof中的含義不同,引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32位機下占四個字節,64位機下占八個字節)。
- 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小。
- 有多級指針,但是沒多級引用。
- 訪問實體方式不同。指針顯式解引用,引用編譯器自己做處理。
- 引用比指針使用起來相對更安全。
📋內聯函數
? ???普通的函數在調用的時候會開辟函數棧幀,會產生一定量的消耗,在C語言中可以用宏函數來解決這個問題,但是宏存在以下缺陷:復雜、容易出錯、可讀性差、不能調試。為此,C++中引入了內聯函數這種方法。.
內聯函數的概念
? ? ?以inline修飾的函數叫做內聯函數,編譯時C++編譯器會在調用內聯函數的地方展開,沒有函數調 用建立棧幀的開銷,內聯函數提升程序運行的效率。
int Add(int x, int y)
{return x + y ;
}int main()
{int ret = 0;ret = Add(3, 5);cout << ret << endl;return 0;
}
🎀內聯函數
inline int Add(int x, int y)
{return x + y ;
}內聯函數在編譯期間編譯器會用函數體替換函數的調用。

注意:在默認的Debug模式下,內聯函數是不會展開的。
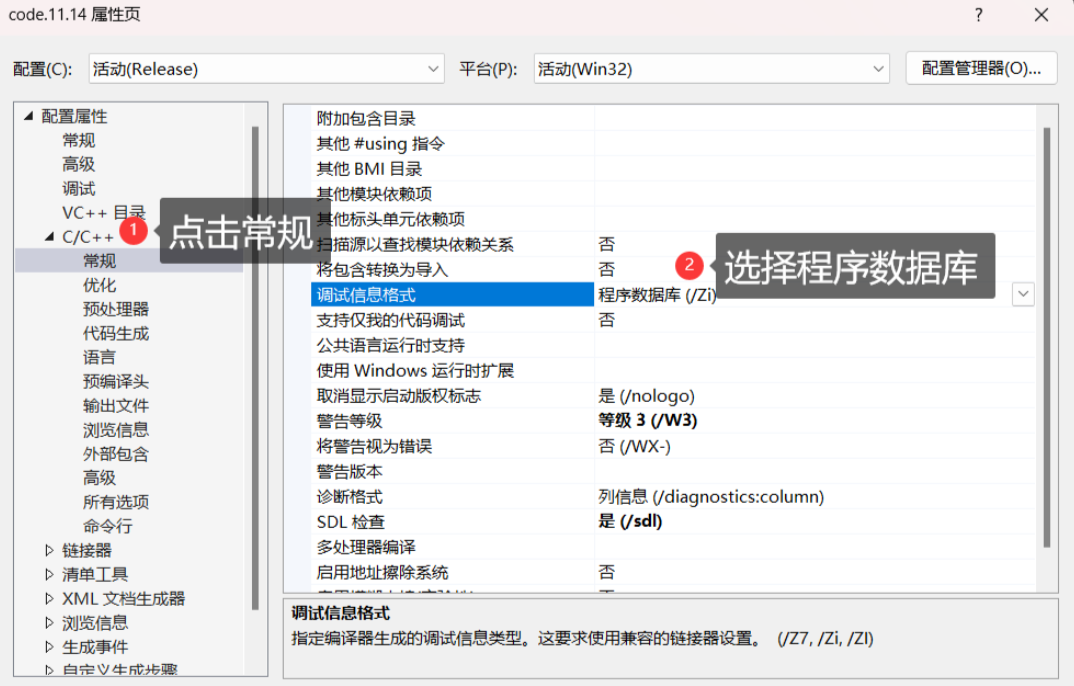
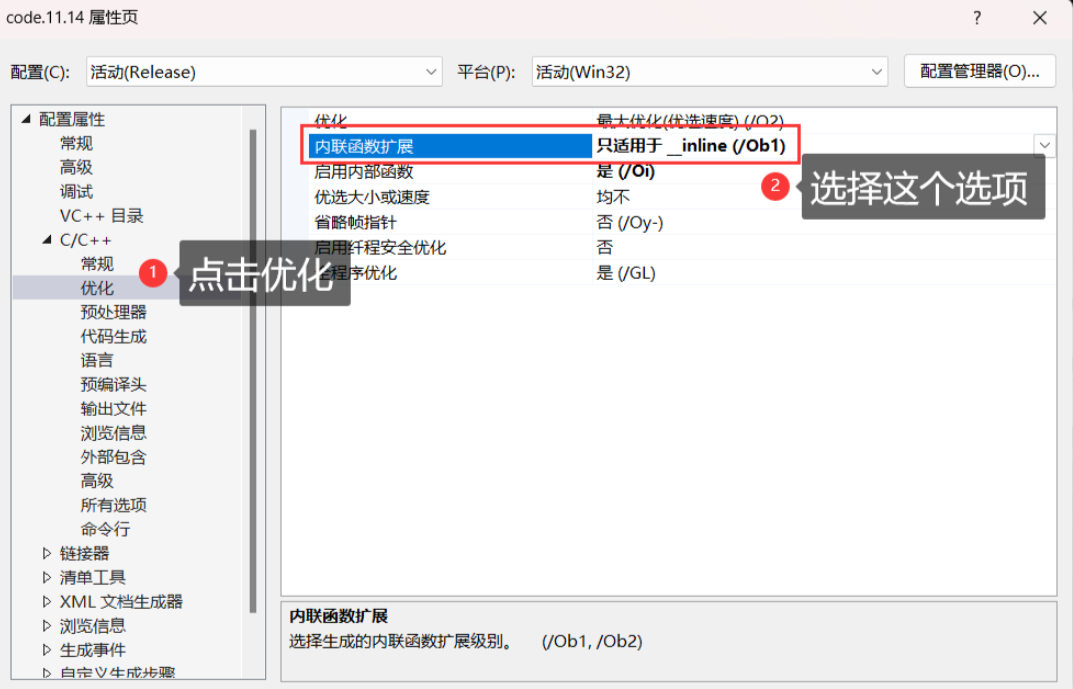
查看方式:
- 在release模式下,查看編譯器生成的匯編代碼中是否存在call Add。
- 在debug模式下,需要對編譯器進行設置,否則不會展開,需要進行設置,設置過程如下:
內聯函數的特征
- inline是一種以空間換時間的做法,如果編譯器將函數當成內聯函數處理,在編譯階段,會用函數體替換函數調用,缺陷:可能會使目標文件變大,優勢:少了調用開銷,提高程序運行效率。?
- inline對于編譯器而言只是一個建議,不同編譯器關于inline實現機制可能不同,一般建議:將函數規模較小(即函數不是很長,具體沒有準確的說法,取決于編譯器內部實現)、不是遞歸、且頻繁調用的函數采用inline修飾,否則編譯器會忽略inline特性。
- inline不建議聲明和定義分離,分離會導致鏈接錯誤。因為inline被展開,就沒有函數地址 了,鏈接就會找不到。
📋auto關鍵字
?????????隨著程序越來越復雜,程序中用到的類型也越來越復雜,例如:
#include <vector>
#include <string>int mian()
{vetcor<string> v;vetcor<string>::iterator it = v.begin();return 0;
}?vetcor<string>::iterator是一個類型,但是該類型太長了,特別容易寫錯。在C語言中,我們可以通過?typedef?給類型取別名,比如:
typedef vetcor<string>::iterator Map;使用 typedef 給類型取別名確實可以簡化代碼,但使用 typedef 又會遇到新的問題。在編程時,常常需要把表達式的值賦值給變量,這就要求在聲明變量的時候清楚地知道表達式的類型。但這點有時很難做到,因此C++11給auto賦予了新的含義。
auto it = v.degin();auto簡介
在早期C/C++中auto的含義是:使用auto修飾的變量,是具有自動存儲器的局部變量, 但在C++11中:auto不再是一個存儲類型指示符,而是作為一個新的類型指示符來指示編譯器,auto聲明的變量必須由編譯器在編譯時期推導而得。簡單來說,auto會根據表達式自動推導類型。
int main()
{int a = 0;auto b = a;auto& c = a;auto* d = &a;//typeid可用來查看變量類型cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;return 0;
}
注意:
? ? ?使用auto定義變量時必須對其進行初始化,在編譯階段編譯器需要根據初始化表達式來推導auto 的實際類型。因此auto并非是一種“類型”的聲明,而是一個類型聲明時的“占位符”,編譯器在編譯期會將auto替換為變量實際的類型。
int main()
{auto a; //要初始化return 0;
}
auto使用規則
🎀auto與指針和引用結合起來使用
- 用auto聲明指針類型時,用auto和auto*沒有任何區別
int main() {int x = 10;auto a = &x;auto* b = &x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;return 0; }

- 用auto聲明引用類型時,則必須加&
int main() {int x = 10;auto& a = x;cout << typeid(a).name() << endl;return 0; }
🎀在同一行定義多個變量?
? ???當在同一行聲明多個變量的時候,這些變量必須是相同的類型,否則編譯器會報錯,因為編譯器實際只對第一個類型進行推導,然后用推導出來的類型定義其他變量。
int main()
{auto a = 10, b = 30;auto c = 15, d = 1.5;//該行編譯失敗,c和d的初始化類型不同
}auto無法使用的場景
🎀auto不能作為函數的參數
//錯誤,編譯器無法對x的實際類型進行推導
void Text(auto x)
{}int main()
{int a=5;Test(a);return 0;
}🎀auto不能作返回值
auto Test(int x)
{}🎀auto不能直接用來聲明數組
void Text()
{auto arr[] = { 1, 2, 3 };//錯誤寫法int arr[] = {1, 2, 3}//這才是正確寫法
}📋基于范圍的for循環
范圍for的語法
? ? ?我們在以前使用 for 遍歷一個數組,會用下面這種方法:
int main()
{int arr[] = { 1,2,3,4,5 };int size = sizeof(arr) / sizeof(arr[0]);for (int i = 0; i < size; ++i){cout << arr[i] << " ";}cout << endl;
}對于一個有范圍的集合而言,由程序員來說明循環的范圍是多余的,有時候還會容易犯錯誤。因此C++11中引入了基于范圍的for循環。for循環后的括號由冒號“ :”分為兩部分:第一部分是范 圍內用于迭代的變量,第二部分則表示被迭代的范圍。
int main()
{int arr[] = { 1,2,3,4,5 };int size = sizeof(arr) / sizeof(arr[0]);for (auto e : arr){cout << e << " ";}return 0;
}
依次取數組arr中的每個數賦值給e,e也就是數組中每個數的拷貝,所以e的改變不會影響數組中數的改變,想要改變數組的值,要使用引用。
int main()
{int arr[] = { 1,2,3,4,5 };int size = sizeof(arr) / sizeof(arr[0]);for (auto e : arr){e++;cout << e << " ";}cout << endl;for (auto e : arr){cout << e << " ";}return 0;
}
范圍for的使用條件
- for循環迭代的范圍必須是確定的
- 迭代的對象要實現++和==的操作
對于數組而言,就是數組中第一個元素和最后一個元素的范圍;對于類而言,應該提供 begin 和end的方法,begin和end就是for循環迭代的范圍。
注意:以下代碼就有問題,因為for的范圍不確定?
void Text(int arr[])//arr本質上只是一個地址,沒有范圍 {for (auto a : arr){cout << a << endl;} }數組不能傳參,數組傳參傳遞的是數組首元素的地址
📋指針空值nullptr
? ? ?在C/C++編程習慣中,我們聲明一個變量時最好給該變量一個合適的初始值,否則可能會出現 不可預料的錯誤,比如未初始化的指針。如果一個指針沒有合法的指向,我們都會把它置為空指針。
void Test()
{int* p1 = NULL;int* p2 = 0;
}?NULL實際是一個宏,在傳統的C頭文件(stddef.h)中,可以看到如下代碼:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif下面這段代碼的結果是什么呢?
void f(int)
{cout<<"f(int)"<<endl;
}void f(int*)
{cout<<"f(int*)"<<endl;
}int main()
{f(0);f(NULL);f(nullptr);return 0;
}
程序本意是想通過 f(NULL) 調用 f(int*) 函數,但是由于NULL被定義成0,因此與程序的初衷相悖。 在C++98中,字面常量0既可以是一個整形數字,也可以是無類型的指針(void*)常量,但是編譯器默認情況下將其看成是一個整形常量,如果要將其按照指針方式來使用,必須對其進行強轉(void *)0。?
注意:
- ?在使用nullptr表示指針空值時,不需要包含頭文件,因為nullptr是C++11作為新關鍵字引入的。
- ?在C++11中,sizeof(nullptr) 與 sizeof((void*)0)所占的字節數相同。
- 為了提高代碼的健壯性,在后續表示指針空值時建議最好使用nullptr。
本次的內容到這里就結束啦。希望大家閱讀完可以有所收獲,同時也感謝各位讀者三連支持。文章有問題可以在評論區留言,博主一定認真認真修改,以后寫出更好的文章。你們的支持就是博主最大的動力。


題)


)
【python源碼+UI界面+功能源碼詳解】)






檢驗法)
應用架構的設計與實踐)




