摘要
中介分析在流行病學和臨床試驗中越來越受到關注。在現有的中介分析方法中,流行的聯合顯著性(JS)檢驗會產生過于保守的 I 類錯誤率,因此功效較低。但是,如果在使用 JS 測試高維中介假設時,可以準確控制族錯誤率 (FWER) 和錯誤發現率 (FDR)。分析的核心是基于估計三個分量零假設的比例并推導零 p 值的相應混合分布。
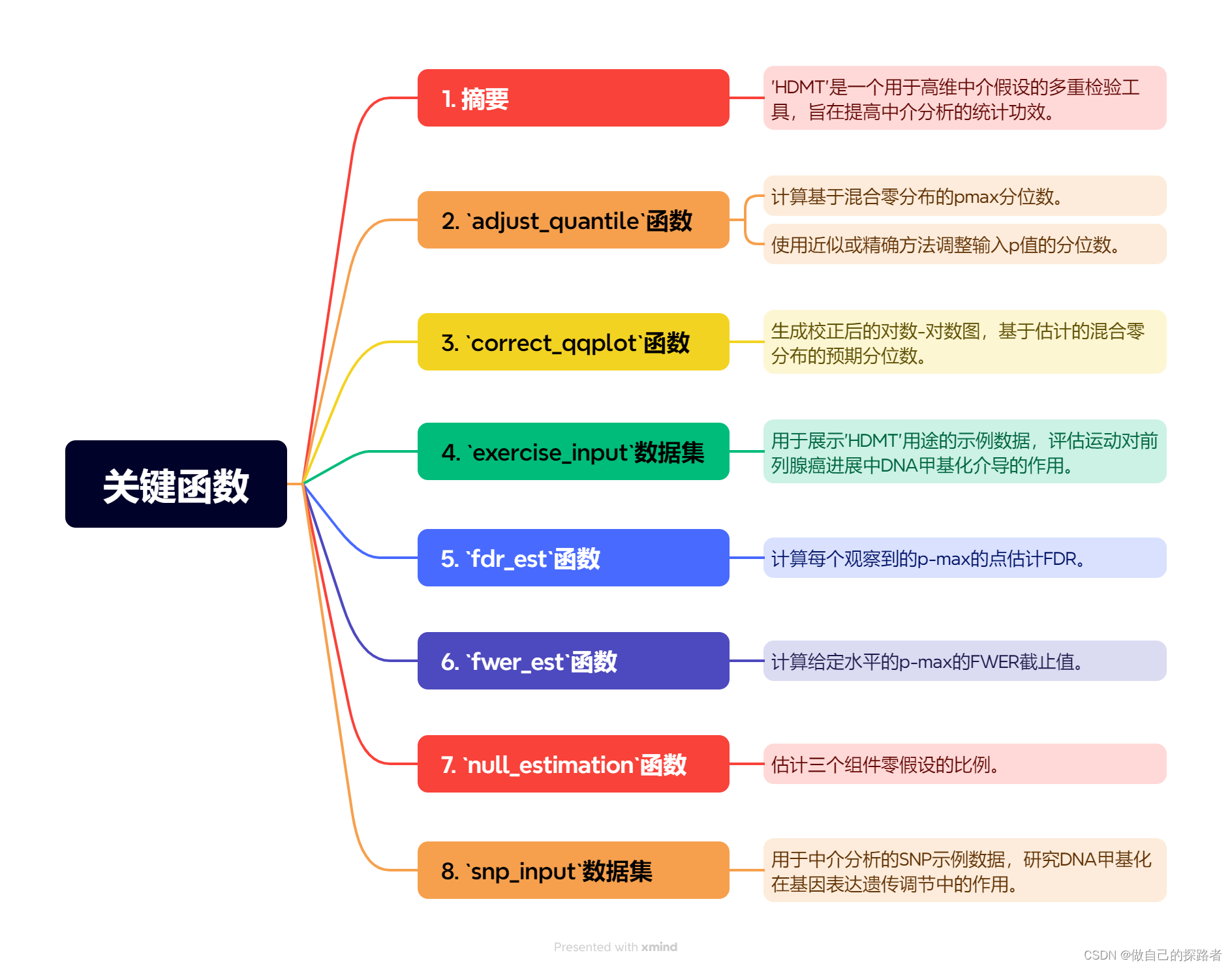
一言以蔽之:計算高維中介假設的校正后的p值
JS-混合方法
新提出的JS-混合方法(joint significance (JS) test) 通過估計三種類型組合零假設的比例來解決JS均勻方法在高維中介假設測試中的過度保守問題。這種方法衍生出控制家庭錯誤率(FWER)或假發現率(FDR)的顯著性規則。通過理論證明、廣泛的模擬實驗和兩個數據例子,JS-混合方法被證明是穩健的,適用于稀疏和密集替代假設,并且在FWER和FDR的控制上比JS-均勻方法提供了更令人滿意的結果。特別是,當使用有限樣本校正的JS-混合方法時,與基于漸近混合零分布的方法相比,其經驗FWER更接近目標的0.05,從而改善了控制效果。
種類型組合零假設的比例
通過估計與三種類型(H00, H01, H10)相關的零假設在所有J個假設中的比例,得到關于這些零假設在數據集中的相對頻率的信息。這些估計對于理解和控制假陽性率(FDR)以及在假設檢驗中區分真正和虛假發現至關重要。π01, π10, 和 π00 分別表示三種類型組合零假設(即,H01, H10, 和 H00)在J個假設中的比例。通過最大化似然函數分別得到αj 和 βj 的估計p1j 和 p2j,由于模型允許它們的似然性可以分解,所以這些估計是獨立的,這有助于更準確地估計pmax,j 在零假設H0j中的分布。
實現方法
以DNA甲基化在癌癥病因中的作用為例,介紹了兩個前列腺癌研究案例。以供自學。
瀏覽關鍵函數
安裝、導入包
# 安裝hdmt包
install.packages("HDMT")
# 加載hdmt包
library(HDMT)
導入數據
數據格式:數據集是一個矩陣,其中包含候選中介變量的兩列 p 值。第 1 列包含用于測試暴露是否與中介相關的 p 值 (alpha!=0)。第 2 列包含用于測試中介變量是否與暴露調整后的結果相關的 p 值 (beta!=0),需要先使用各類中介方法進行估計。
# 讀取數據
data(snp_input)
# 查看數據
head(snp_input)
# [,1] [,2]
# [1,] 0.1056981 0.253803463
# [2,] 0.9986436 0.862830855
# [3,] 0.1006569 0.726600653
# [4,] 0.1731411 0.327851970
# [5,] 0.8900695 0.001496449
# [6,] 0.8156905 0.087064991
# 查看數據結構
str(snp_input)
# num [1:69602, 1:2] 0.106 0.999 0.101 0.173 0.89 ...
input_pvalues <- snp_input# 從輸入數據中隨機抽取10%的數據【節省時間】
input_pvalues <- input_pvalues[sample(1:nrow(input_pvalues),size=ceiling(nrow(input_pvalues)/10)),]
str(input_pvalues)
# num [1:6961, 1:2] 0.37146 0.00373 0.56406 0.4913 0.78594 ... 估計三個分量零值比例備用
nullprop <- null_estimation(input_pvalues)
# $alpha10
# [1] 0.06608246
#
# $alpha01
# [1] 0.4640138
#
# $alpha00
# [1] 0.4692812
#
# $alpha1
# [1] 0.933295
#
# $alpha2
# [1] 0.5353637計算FDR校正后的p值
# 使用三個分量零值比例,基于所提出的聯合顯著性混合零方法(JS-mixture)計算估計的逐點 FDR
fdr <- fdr_est(nullprop$alpha00,nullprop$alpha01,nullprop$alpha10, nullprop$alpha1,nullprop$alpha2,input_pvalues,exact=0)
str(fdr)
# num [1:6961] 0.954 0.966 0.957 0.956 0.917 ...
結果解讀:如果一個p值對應的FDR小于0.05,那么這個結果被認為是在FDR控制下的顯著發現,表明存在關聯
?計算FWE校正后的p值的cutoff
# 使用估計的混合零分布計算 p-max 的 FWER 截止值cutoff
fwercut0 <- fwer_est(nullprop$alpha10,nullprop$alpha01,nullprop$alpha00,nullprop$alpha1, nullprop$alpha2,input_pvalues,alpha=0.05,exact=0) # exact= 0:不估計CDF的近似值
fwercut0
# [1] 1.491624e-05fwercut1 <- fwer_est(nullprop$alpha10,nullprop$alpha01,nullprop$alpha00,nullprop$alpha1, nullprop$alpha2,input_pvalues,alpha=0.05,exact=1) # exact = 1:非參數估計 CDF 的精確方法
fwercut1
# [1] 6.187122e-05結果解讀:
fwercut0是使用估計的混合零分布計算的 p-max 的 FWER 截止值,其中exact=0表示使用了不估計累積分布函數(CDF)的近似方法。 在顯著性水平alpha=0.05下,為了控制家庭錯誤率(FWER),當候選中介變量的p值小于或等于這個值(即1.354997e-05)時,我們將認為關聯性檢測達到統計顯著性。同理解讀fwercut1
作圖
用途:觀察經過JS 后,校正后的p值被“拉高”了,即更容易達到統計學顯著,提高了功效
# 通過上面計算的三個分量零值比例,并使用近似或精確方法計算 pmax 的估計混合零分布分位數--------
pnull <- adjust_quantile(nullprop$alpha00,nullprop$alpha01,nullprop$alpha10,nullprop$alpha1, nullprop$alpha2,input_pvalues,exact=0) # exact=0,推導混合零分布時,不估計CDF的近似方法
str(pnull)
# num [1:6961] 0.000298 0.000596 0.000894 0.001192 0.001489 ...# 使用預期分位數繪制 p-max 的校正分位數-分位數圖---------
pmax <- apply(input_pvalues,1,max) # 計算每行的最大值
pnull1 <- adjust_quantile(nullprop$alpha10,nullprop$alpha01,nullprop$alpha00, nullprop$alpha1,nullprop$alpha2,input_pvalues,exact=1) # exact=1,在推導混合零分布時,非參數估計 CDF 的精確方法correct_qqplot(pmax,pnull1) #如下圖展示
參考文獻
A Multiple-Testing Procedure for High-Dimensional Mediation Hypotheses: Journal of the American Statistical Association: Vol 117 , No 537 - Get Access (tandfonline.com)![]() https://www.tandfonline.com/doi/full/10.1080/01621459.2020.1765785??????
https://www.tandfonline.com/doi/full/10.1080/01621459.2020.1765785??????
應用架構的設計與實踐)










-弱電網下的LCL逆變器控制以及諧振峰問題(1))

和重寫(Override)的區別。重載的方法能否根據返回類型進行區分?)



的性能(來自OpenAI DevDay 會議))
![劍指offer》15--二進制中1的個數[C++]](http://pic.xiahunao.cn/劍指offer》15--二進制中1的個數[C++])
