本研究關注于利用大語言模型(LLMs)提供的自動化偏好反饋來增強決策過程
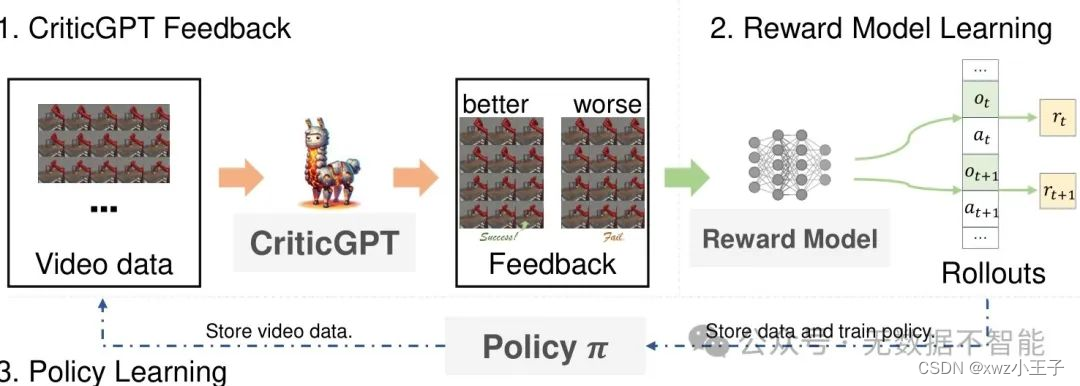
○ 提出了一種多模態LLM,稱為CriticGPT,可以理解機器人操作任務中的軌跡視頻,并提供分析和偏好反饋
○ 從獎勵建模的角度驗證了CriticGPT生成的偏好標簽的有效性
○ 實驗評估表明該算法對新任務具有有效的泛化能力,并且在Meta-World任務上的表現超過了基于最先進預訓練表示模型的獎勵
重要問題探討
-
CriticGPT能夠理解和評估機器人操作任務的軌跡視頻嗎?分析: 是的,CriticGPT通過細調LLaVA模型來進一步理解機器人操縱任務的軌跡視頻,并提供深入的分析和評估作為過程的評論家。
-
CriticGPT在訓練過程中的評價準確率如何?分析: CriticGPT模型在不同訓練時長、批次大小等因素下進行了評估。結果顯示,CriticGPT模型能夠在通常的情況下達到非常高的準確率,并在極具挑戰的情況下表現略高于隨機表現。
-
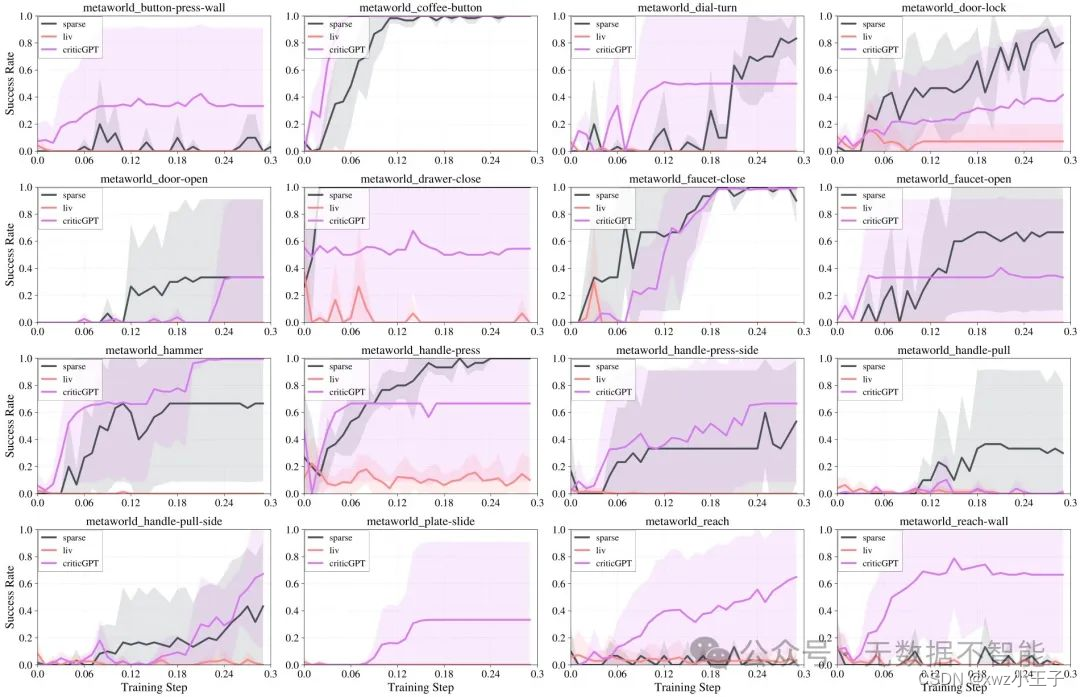
CriticGPT生成的評價反饋對于政策學習是否有效?分析: 實驗結果顯示,在CriticGPT生成的評價反饋指導下,政策學習相比其他基線算法表現更好,達到了更高的成功率。這表明CriticGPT生成的反饋對于政策學習具有有效的指導作用。
-
CriticGPT的評價反饋是否能與人類反饋相媲美?分析: CriticGPT生成的評價反饋在指導政策學習任務上的表現與人類反饋相媲美。最近的研究結果表明,CriticGPT生成的反饋能夠達到與人類反饋相當的性能。
-
CriticGPT RM相較于基于預訓練表示模型的獎勵有何優勢?分析: CriticGPT RM相比于基于預訓練表示模型的獎勵表現更出色,能夠更好地指導政策學習任務。預訓練表示模型的獎勵往往存在著一些缺陷,如難以區分接近完成狀態和任務完成狀態,模型在接近完成狀態下表現良好但不能成功完成任務等問題。
-
CriticGPT RM能夠更直接地指導行為嗎?分析: CriticGPT RM指導下的行為比起基于專家獎勵的模型更加直接,能夠更快地完成任務。相比之下,基于專家獎勵的模型往往需要較長的時間才能完成任務。
-
CriticGPT RM是否更注重目標導向?分析: CriticGPT RM更加目標導向,能夠更快地按照目標完成任務,而基于專家獎勵的模型往往給出許多小的獎勵來引導任務完成,可能會減慢任務的完成速度。
-
CriticGPT RM能夠更好地區分成功和失敗的軌跡嗎?分析: CriticGPT RM給予較高獎勵的軌跡與成功完成的軌跡的回報之間存在明顯的差距,能夠更好地區分成功和失敗的軌跡。這種區分能力使得CriticGPT RM能夠在300K個訓練步驟內取得出色的表現。
-
CriticGPT RM相較于專家獎勵和基于預訓練表示模型的獎勵具有何優勢?分析: CriticGPT RM相較于專家獎勵和基于預訓練表示模型的獎勵具有更合理的獎勵分配。專家獎勵模型存在較多給予失敗軌跡較高獎勵的情況,而基于預訓練表示模型的獎勵由于學習過程不穩定,在150K個訓練步驟內未能表現出明顯的優勢。CriticGPT RM給予的獎勵更加合理,在成功和失敗的軌跡之間有明顯的回報差距。
-
CriticGPT有潛力在更廣泛的視覺機器人任務中發揮作用嗎?分析: CriticGPT具有在更廣泛的視覺機器人任務中發揮作用的潛力。該研究結果表明,利用CriticGPT的反饋可以有效地指導政策學習任務的完成,預期隨著數據集的不斷擴充,CriticGPT的能力將得到進一步加強。


)
Tabs標簽頁打開、關閉與路由之間的關系)

)




 多態)







)
分類任務的評價指標)