目錄
摘要
基本原理
通道注意力機制
空間注意力機制
GAM代碼實現?
Wise-IoU?
WIoU代碼實現
yaml文件編寫
完整代碼分享(含多種注意力機制)
摘要
人們已經研究了各種注意力機制來提高各種計算機視覺任務的性能。然而,現有方法忽視了保留通道和空間方面的信息以增強跨維度交互的重要性。因此,我們提出了一種全局注意力機制,通過減少信息減少和放大全局交互表示來提高深度神經網絡的性能。引入了具有多層感知器的 3D 排列,用于通道注意以及卷積空間注意子模塊。在 CIFAR-100 和 ImageNet-1K 上對所提出的圖像分類任務機制的評估表明,我們的方法穩定優于最近使用 ResNet 和輕量級 MobileNet 的幾種注意力機制。
基本原理
目標的設計是一種減少信息縮減并放大全局維度交互特征的機制。我們采用 CBAM 的順序通道空間注意力機制并重新設計子模塊。整個過程如圖 所示。
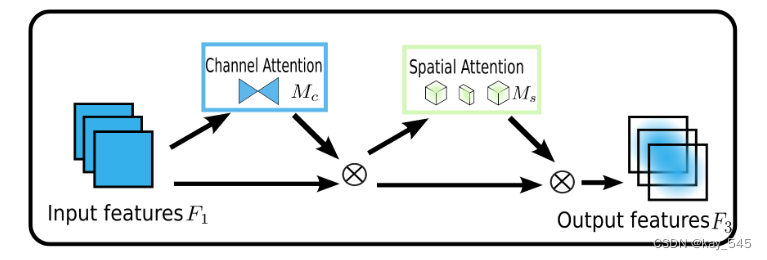
通道注意力機制
通道注意力子模塊使用 3D 排列來保留三個維度的信息。然后,它使用兩層 MLP(多層感知器)放大跨維度通道空間依賴性。 (MLP是一種編碼器-解碼器結構,其縮減比為r,與BAM相同。)通道注意子模塊如圖所示。?
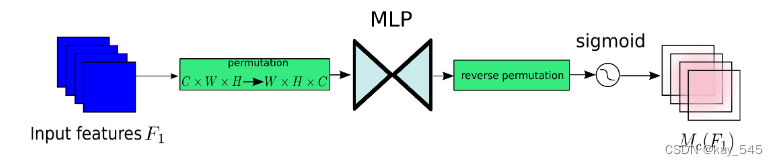
空間注意力機制
在空間注意力子模塊中,為了關注空間信息,我們使用兩個卷積層進行空間信息融合。我們還使用與 BAM 相同的通道注意子模塊的縮減率 r。同時,最大池化會減少信息并產生負面影響。我們刪除池化以進一步保留特征圖。因此,空間注意力模塊有時會顯著增加參數的數量。為了防止參數顯著增加,我們在 ResNet50 中采用帶有通道洗牌的組卷積。沒有組卷積的空間注意力子模塊如圖所示。?
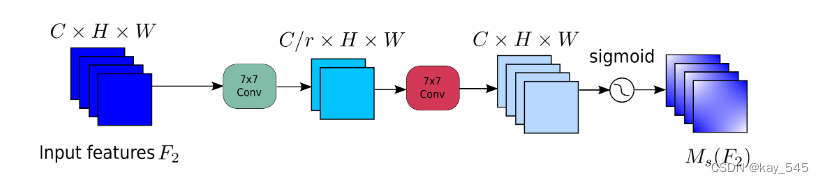
GAM代碼實現?
class GAM_Attention(nn.Module):def __init__(self, c1, c2, group=True, rate=4):super(GAM_Attention, self).__init__()self.channel_attention = nn.Sequential(nn.Linear(c1, int(c1 / rate)),nn.ReLU(inplace=True),nn.Linear(int(c1 / rate), c1))self.spatial_attention = nn.Sequential(nn.Conv2d(c1, c1 // rate, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(c1, int(c1 / rate),kernel_size=7,padding=3),nn.BatchNorm2d(int(c1 / rate)),nn.ReLU(inplace=True),nn.Conv2d(c1 // rate, c2, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(int(c1 / rate), c2,kernel_size=7,padding=3),nn.BatchNorm2d(c2))def forward(self, x):b, c, h, w = x.shapex_permute = x.permute(0, 2, 3, 1).view(b, -1, c)x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)x_channel_att = x_att_permute.permute(0, 3, 1, 2)# x_channel_att=channel_shuffle(x_channel_att,4) #last shufflex = x * x_channel_attx_spatial_att = self.spatial_attention(x).sigmoid()x_spatial_att = channel_shuffle(x_spatial_att, 4) # last shuffleout = x * x_spatial_att# out=channel_shuffle(out,4) #last shufflereturn out以上代碼添加在 ./ultralytics/nn/modules/conv.py 中
Wise-IoU?
Yolov7提出的損失函數是GIoU(Generalized Intersection over Union),能在更廣義的層面上計算IoU(Intersection over Union),但是當兩個預測框完全重合時,不能反映出實際情況,此時GIoU就要退化為IoU,并且GIoU對每個預測框與真實框均要計算最小外接框,故損失函數計算及收斂速度受到限制。
為了彌補這種遺憾,改進的網絡中使用了WIoU(Wise-IoU)作為損失函數。WIoU v3作為邊界框回歸損失,包含一種動態非單調機制,并設計了一種合理的梯度增益分配,該策略減少了極端樣本中出現的大梯度或有害梯度。該損失方法計算更多地關注普通質量的樣本,進而提高網絡模型的泛化能力和整體性能。
雖然幾種主流損失函數都采用靜態聚焦機制,但WIoU不僅考慮了方位角、質心距離和重疊面積,還引入了動態非單調聚焦機制。 WIoU應用合理的梯度增益分配策略來評估錨框的質量。WIoU有三個版本。 WIoU v1 設計了基于注意力的預測框損失,WIoU v2 和 WIoU v3 添加了聚焦系數。
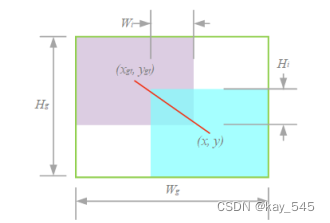
最小的包圍盒(綠色)和中心點的連接(紅色),其中并集的面積為?Su = wh + wgthgt ? WiHi .
WIoU代碼實現
def WIoU(cls, pred, target, self=None):self = self if self else cls(pred, target)dist = torch.exp(self.l2_center / self.l2_box.detach())return self._scaled_loss(dist * self.iou)?下面的代碼替換loss.py的class BboxLoss
class BboxLoss(nn.Module):def __init__(self, reg_max, use_dfl=False):"""Initialize the BboxLoss module with regularization maximum and DFL settings."""super().__init__()self.reg_max = reg_maxself.use_dfl = use_dfldef forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):"""IoU loss."""weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)loss,iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False,type_='WIoU')loss_iou=loss.sum()/target_scores_sum# DFL lossif self.use_dfl:target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weightloss_dfl = loss_dfl.sum() / target_scores_sumelse:loss_dfl = torch.tensor(0.0).to(pred_dist.device)return loss_iou, loss_dflyaml文件編寫
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 3, GAM_Attention, [1024]]- [-1, 1, SPPF, [1024, 5]] # 10# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13#- [-1, 1, GAM_Attention, [512,512]]- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)#- [-1, 1, GAM_Attention, [256,256]]- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)#- [-1, 1, GAM_Attention, [512,512]]- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 22 (P5/32-large)#- [-1, 1, GAM_Attention, [1024,1024]]- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
完整代碼分享(含多種注意力機制)
內涵SA,CBAM,GAM,ECA等多種注意力機制
鏈接: https://pan.baidu.com/s/1T9bVifTPCRMv2t7eREsuEw?pwd=nbrt 提取碼: nbrt?


)











 + Pycharm 錯誤(無法啟動)+ python 報錯)
)


 和 puts() 有兩個小區別))

