MySQL - SQL 優化
1. 在 MySQL 中,如何定位慢查詢?
1.1 發現慢查詢
現象:頁面加載過慢、接口壓力測試響應時間過長(超過 1s)
可能出現慢查詢的場景:
- 聚合查詢
- 多表查詢
- 表數據過大查詢
- 深度分頁查詢
1.2 通過現象定位到問題是出在 MySQL 的慢查詢(查看慢日志法)
找到配置文件:
Windows:my.ini
Linux:/etc/my.cnf
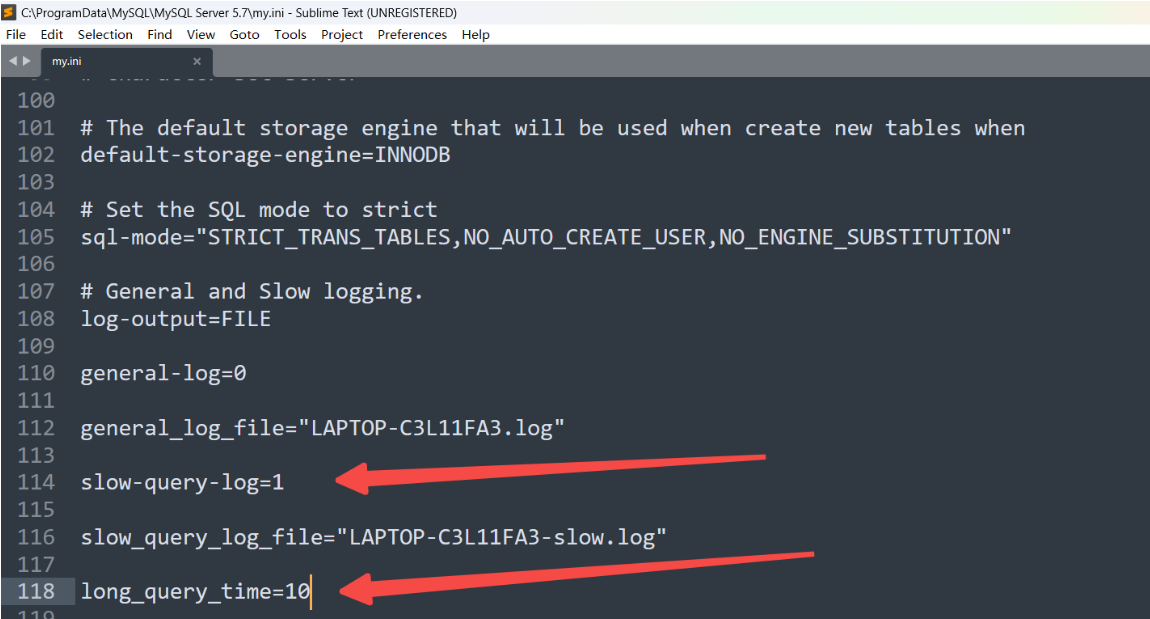
添加或修改兩個屬性:
- slow_query_log=1(1 為 true,開啟慢日志)
- long_query_time=2(單位為秒,超過 2 秒的將記錄在慢日志)
選擇性添加或修改,slow_query_log_file 屬性,慢日志名
- Linux 在
/var/lib/mysql/localhost-slow.log - Windows 見配置文件默認值
重啟 MySQL:
-
Windows
-
net stop MySQL -
net start MySQL
-
-
Linux
-
sudo systemctl stop mysql -
sudo systemctl start mysql
-
發現問題,找到對應的慢日志,定位到問題是出在 MySQL 的慢查詢:

1.3 回答問題
- 介紹一下當時產生問題的場景(我們當時的一個接口測試的時候非常的慢,壓力測試的結果大概 5 秒鐘);
- 而我們在調試階段,開啟了 MySQL 的慢日志記錄,我們設置的值為 2 秒,一旦 sql 執行超過 2 秒就會記錄在慢日志中,我們發現問題后查詢了 MySQL 的慢日志,最終定位到問題是出在 MySQL 的慢查詢;
2. 那這個 SQL 語句執行很慢,是如何分析的呢?
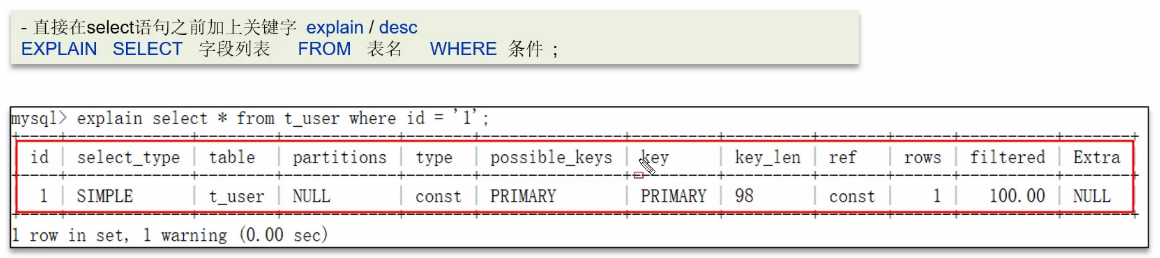
可以采用 MySQL 自帶的分析工具 explain
- 通過 key 和 key_len 查詢是否命中索引,也可以判斷索引本身存在是否失效的情況;
- 通過 type 字段查看 sql 是否有進一步的優化空間,是否村咋全索引掃描或者全盤掃描;
- 通過 Extra 建議判斷是否出現了回表的情況,如果出現了,可以嘗試添加索引或者修改返回字段來修復;
possible_key 當前 sql 可能會使用到的索引
key 當前 sql 實際命中的索引
key_len 索引占用的大小
Extra 額外的優化建議
type 這條 sql 的連接類型,性能由好到差:NULL、system、const、eq_ref、ref、range、index、all
- NULL:沒有使用到表
- system:查詢 MySQL 系統內置的表
- const:根據主鍵索引查詢
- eq_ref:主鍵索引查詢或者唯一索引查詢
- ref:索引查詢
- range:分為查詢
- index:索引樹(全索引)掃描
- all:全盤掃描

3. 了解過索引嗎?(什么是索引)
3.1 索引是什么
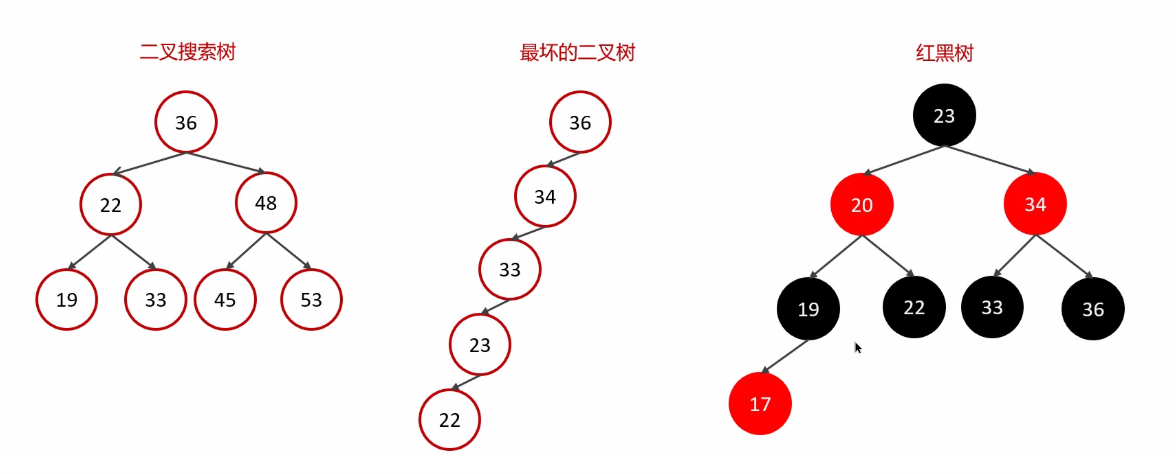
索引(index)是幫助 MySQL 高效獲取 數據的數據結構(有序)。在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構**(B+ 樹)**,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法,這種數據結構就是索引。
3.2 什么是 B+ 樹
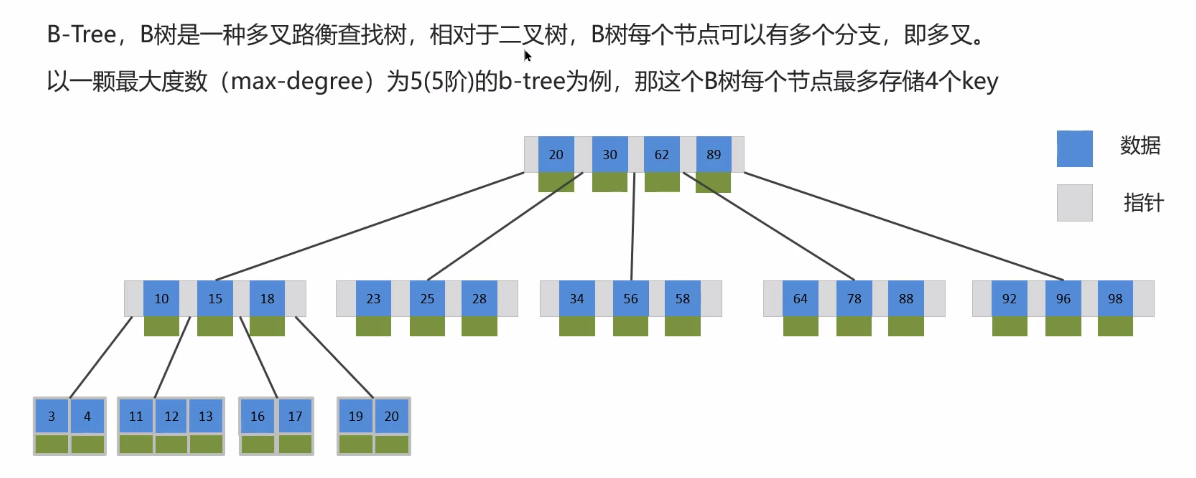
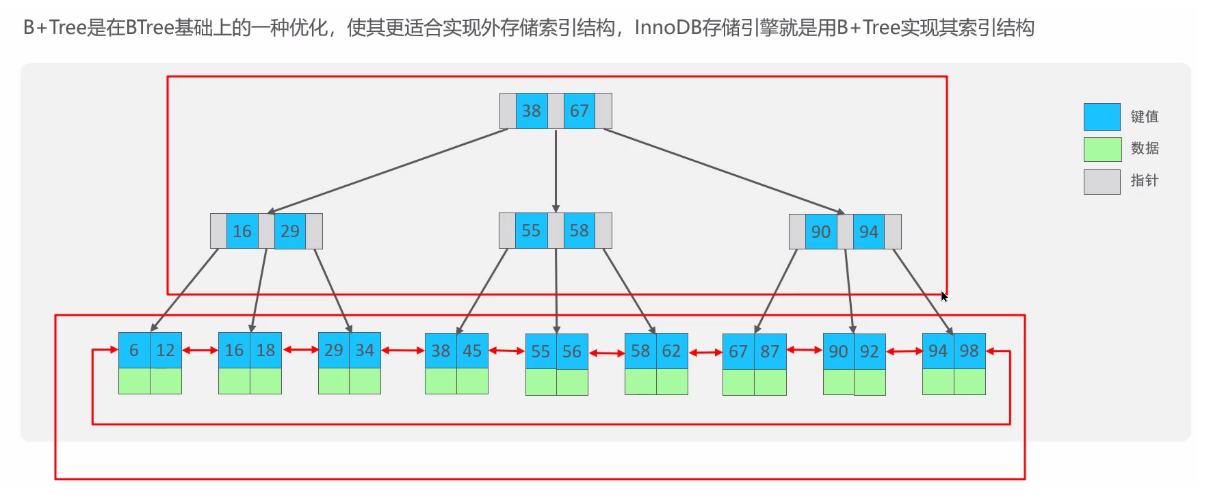
3.3 回答
了解過索引嗎?
- 索引(index)是幫助 MySQL 高效獲取數據的有序的數據結構;
- 提高數據檢索的效率,降低數據庫的 IO 成本,因為不需要全表掃描;
- 通過索引列對數據進行排序,降低數據排序的成本,降低了 CPU 的消耗;
索引列:以表中哪個列來創建索引;
索引的底層數據結構了解過嗎?
InnoDB是MySQL數據庫管理系統中的一種事務性存儲引擎。
MySQL 的 InnoDB 引擎采用的 B+ 樹的數據結構來作為索引的存儲結構;
- MySQL 的索引的底層數據結構是 B+ 樹;
- 階數更多,路徑更短;磁盤讀寫代價低,非葉子節點只存儲指針,葉子節點存儲數據;
- B+ 樹便于掃庫和區間的查詢,葉子節點是一個雙向鏈表;
4. 什么是聚簇索引,什么是非聚簇索引?
4.1 什么是聚集索引,什么是二級索引(非聚集索引)?


如果沒有主鍵,則會使用隱藏字段:DB_ROW_ID,隱藏主鍵
4.2 什么是回表查詢?
了解什么是聚集索引,什么是二級索引(非聚集索引)后,再進行理解:
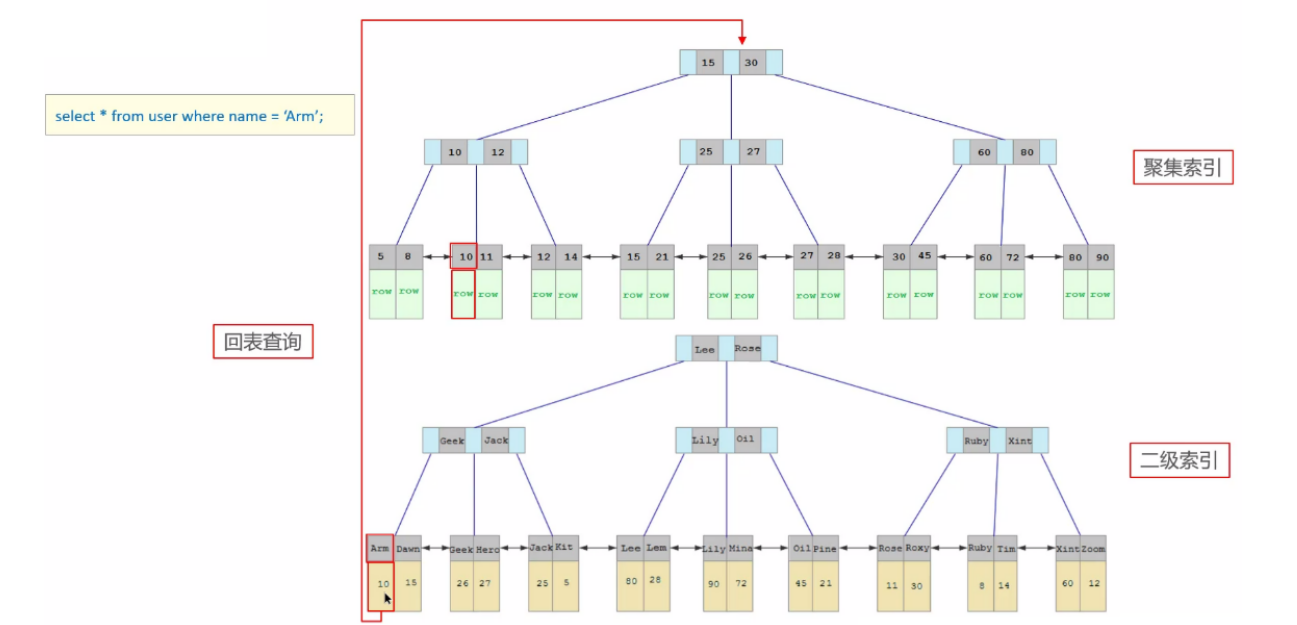
如果沒有主鍵,則會使用隱藏字段:DB_ROW_ID,隱藏主鍵進行回表查詢(如果不給隱藏主鍵創建索引,那么回表查詢是沒有走索引的,效率低下)
4.3 回答
- 聚簇索引(聚集索引):數據存放到索引中,B+ 樹的葉子節點保存了整行數據,有且只有一個;
- 非聚簇索引(二級索引,非聚集索引):數據不全部存放到索引中,B+ 樹的葉子節點保存了索引列以及對應的主鍵,可以有多個;
- 通過二級索引找到對應的主鍵值,再到聚集索引中查找整行數據,這個過程就是回表;(如果沒有聚集索引,回表查詢就不是通過索引查詢了,而是全表查詢,非常低性能)
5. 知道什么叫覆蓋索引嗎?
覆蓋索引就是查詢使用了索引,并且需要返回的列在該索引中已經全部覆蓋到了;
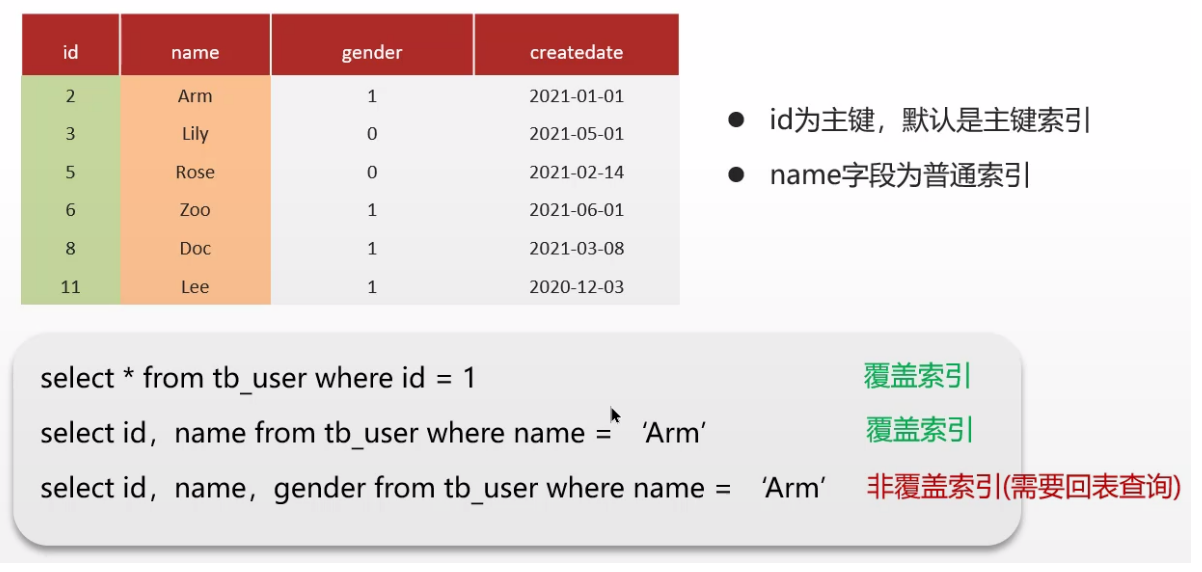
- 聚集索引一定是,二級索引不需要回表查詢也是;
回答:
- 聚集索引指的是查詢使用了索引,返回的列,在索引中全部都能找到;
- 使用 id 查詢,直接走聚集索引查詢,一次索引掃描,直接返回全部數據,性能高;
- 如果所需列在索引中不存在,就會觸發回表查詢,所以盡量避免使用
select *
6. MySQL 超大分頁怎么處理?
在數據量比較大的時候,如果進行 limit 分頁查詢,在查詢的時候,越往后,分頁查詢效率越低。
6.1 超大分頁場景
例如:
select * from user order by nickname limit 0, 10;
select * from user order by nickname limit 9000000, 10;
上面那個 0 毫秒不到,而下面那個甚至可以達到 10 秒以上!
因為,在執行的時候,需要加載 9000010 條記錄(每條都是 raw),再選取 9000000 - 9000010 的記錄,其他記錄丟棄,查詢排序的非常大。
而 nickname 在這里不是覆蓋索引,所以加載 9000010 條記錄時,性能很低。
- order by 子句使用索引需要:
order by子句中的字段必須創建了索引,索引查詢的字段覆蓋需要查詢的字段;order by子句中的字段要符合最左前綴法則(對于復合索引);
- 像這種非覆蓋索引,回表的性能還不如全表查詢呢,所以不走索引在這里是好事;
6.2 超大分頁 SQL優化
但是我們知道這條 sql 中是覆蓋索引:
select id from user ordery by nickname limit 9000000, 10;
那么我們再拿這 10 個 id 去表中查詢即可。
因此 sql 可以優化成這樣(覆蓋索引 + 子查詢):
select * fromuser u, (select id from user order by nickname limit 9000000, 10) a
where u.id = a.id;
6.3 回答
-
問題在于在數據量比較大時,limit 分頁查詢,需要對數據進行排序,效率低。
-
可以用到索引(有序性)查詢,而如果不是覆蓋索引,那么可以用覆蓋索引 + 子查詢進行優化!
7. 索引創建的原則有哪些?
先陳述自己實際開發中怎么用索引的,用了什么索引,如主鍵索引、唯一索引、復合索引…
再說原則:
- 數據量較大,且查詢比較頻繁的表;(10w+ 就可以創建索引增加用戶體驗了)
- 常常作為查詢條件、排序操作、分組操作的字段;
- 盡量使用聯合索引(多列索引),減少單列索引,這樣可以讓查詢更可能是覆蓋索引;
- 要控制索引的數量,并不是越多越好,增刪改都是需要維護的;
- 字段內容區分度高,盡量建立唯一索引,區分度越高性能越好;
- 字符串類型字段,內容較長,可以使用前綴索引;
- 如果索引列不能存儲 NULL 值,在創建表的時候使用 NOT NULL 約束,這有利于讓優化器選擇哪個索引進行更有效的查詢;
8. 什么情況下索引會失效?
8.1 復合索引
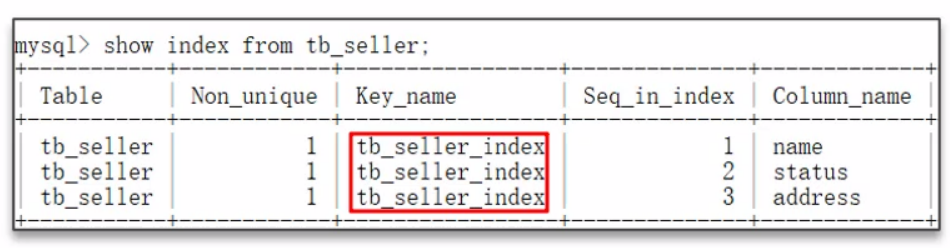
順序見 Seq_in_index,即 name、status、address
8.2 違反最左前綴法則
SQL 的查詢條件 / 排序 / 分組從索引的最左前列開始,才會走索引:

正向例子:

反向例子:

跳過某一列,則只有部分最左前綴索引生效:

8.3 范圍查詢右邊的列,不能使用索引

下面那個,name 和 status 走索引,status 右邊的字段 address 沒用到索引。
8.4 不要再索引列上進行運算操作,索引會失效
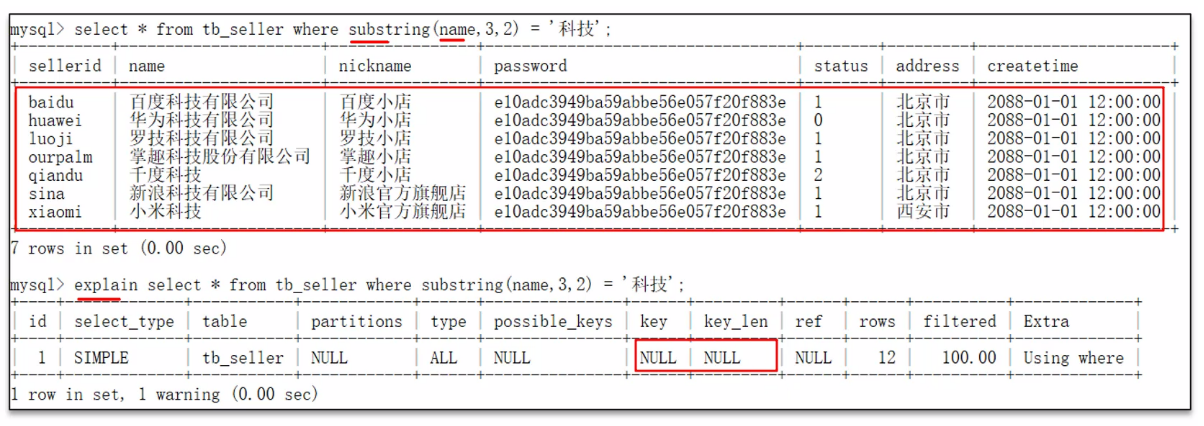
8.5 字符串不加單引號,造成索引失效

復雜行為往往導致索引失效~
8.6 模糊查詢有可能會導致索引失效
頭部模糊匹配,索引失效。如果僅僅是尾部模糊匹配,索引不會失效。
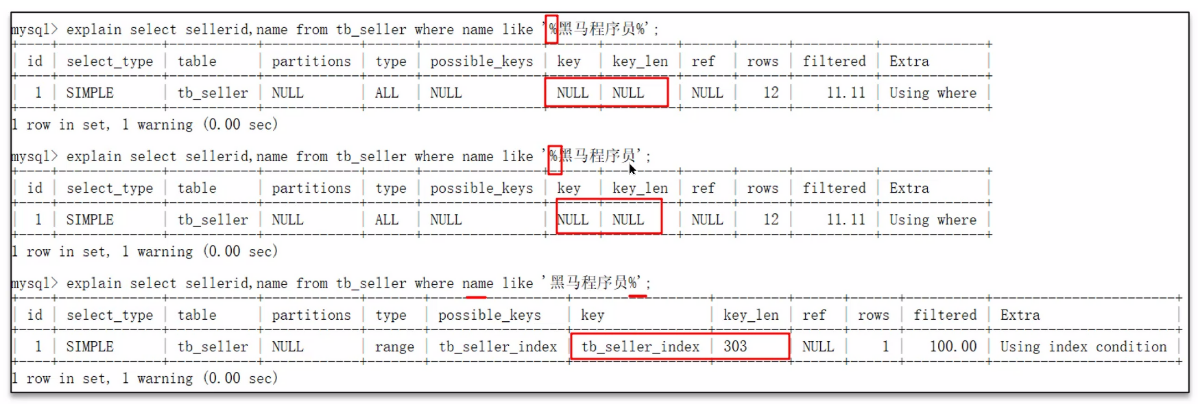
8.7 回答
同理,先陳述自己的遭遇,如某個場景創建了索引,性能還是很慢,explain 去查看 sql 語句的執行計劃,發現索引失效了。
對于復合索引:
- 違反最左前綴法則;
- 范圍查詢右邊的列;
- 在索引列上進行運算操作;
- 字符串不加單引號,導致 MySQL 優化器進行類型轉化;
- 頭部模糊查詢;
通常情況下,可以使用 explain 查看 sql 的執行計劃來判斷索引是否失效。
9. 談一談你對 SQL 優化的經驗
從三個方面:
- 表的設計優化
- 索引優化(參考優化創建原則和索引失效)
- SQL 語句優化
9.1 表的設計優化(參考阿里開發手冊《嵩山版》)
- 比如設置合適的數值(tinyint、int、bigint)要根據實際情況選擇;
- 比如設置合適的字符串類型(char,varchar)char定長效率高,varchar可變長度,效率稍低;
9.2 SQL 語句的優化
- select 語句務必指明字段的名稱(避免使用
select *); - SQL 語句要避免造成索引失效的寫法;
- 盡量用 union all 代替 union,union 會多一次過濾,效率低(union 會將重復的過濾掉,如果知道沒有重復的就可以用 union all)
這個就不能用 union all,并不是存在絕對地去優化,而是看情況決定~

-
避免在 where 子句對字段進行表達式/函數操作;
-
join 優化,能用 inner join 就不用 left join 或者 right join,如果必須使用,一定要以小表為驅動;
-
小表:數據量較小的表,大表:數據量較大的表,
-
這樣的好處就是以小表連接大表,連接次數較小,on 子句查詢的次數較小,并且由于是查詢大表,所以如果是有索引,索引效果更明顯!
-
內連接會對兩個表進行優化,優先把小表放外邊,把大表放里面;
-
left join 或者 right join 則不會重新調整順序;
-
 + Pycharm 錯誤(無法啟動)+ python 報錯)
)


 和 puts() 有兩個小區別))









—— 實用小函數總結)




)