


索引的優缺點
索引是一種支持快速查找特定行的數據結構,如果沒有索引,就需要遍歷整個表進行查找。用于提高數據檢索的速度和效率。
好處:
提高檢索速度: 索引可以加快數據的檢索速度,因為它們允許數據庫系統直接定位到存儲數據的位置,而不必遍歷整個數據表。
優化數據訪問路徑: 索引可以優化數據訪問路徑,使得查詢更加高效。
壞處:
占用存儲空間: 索引會占用額外的存儲空間,特別是對于大型數據集來說,索引可能會占用相當大的空間。
影響寫操作的性能: 當執行插入、更新和刪除等寫操作時,數據庫系統需要更新索引,這可能會影響寫操作的性能。
維護成本高昂: 維護索引需要額外的系統資源和時間成本。隨著數據庫的增長和索引的數量增加,維護成本可能會變得很高。
數據庫索引的底層數據結構
B+樹。在數據庫中,B+樹的高度一般都在2~4層,效率很高。
B+樹中,所有記錄節點都是按鍵值的大小順序存放在同一層的葉子節點,各葉子節點通過指針進行鏈接。
非葉子節點只存儲與搜索有關的key
葉子節點存儲數據。從小到大有序,并且使用指針連接在一起。
B+樹索引在數據庫中的一個特點就是高扇出性。B-tree將數據庫拆分成了固定大小的塊,通常為4K,塊是內部讀寫的最小單元。這種設計更接近底層硬件,因為磁盤也是以固定大小的塊排列的。
問題:如果固定大小的塊已經滿了該怎么辦、答案:分裂多個塊解決,空的空間使用空閑空間。
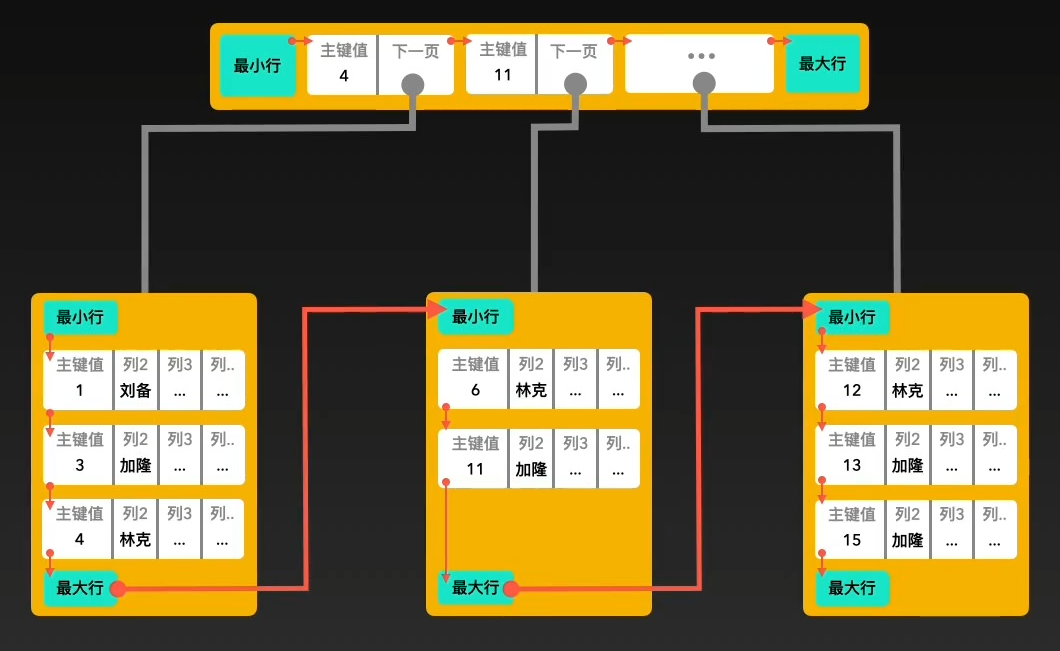
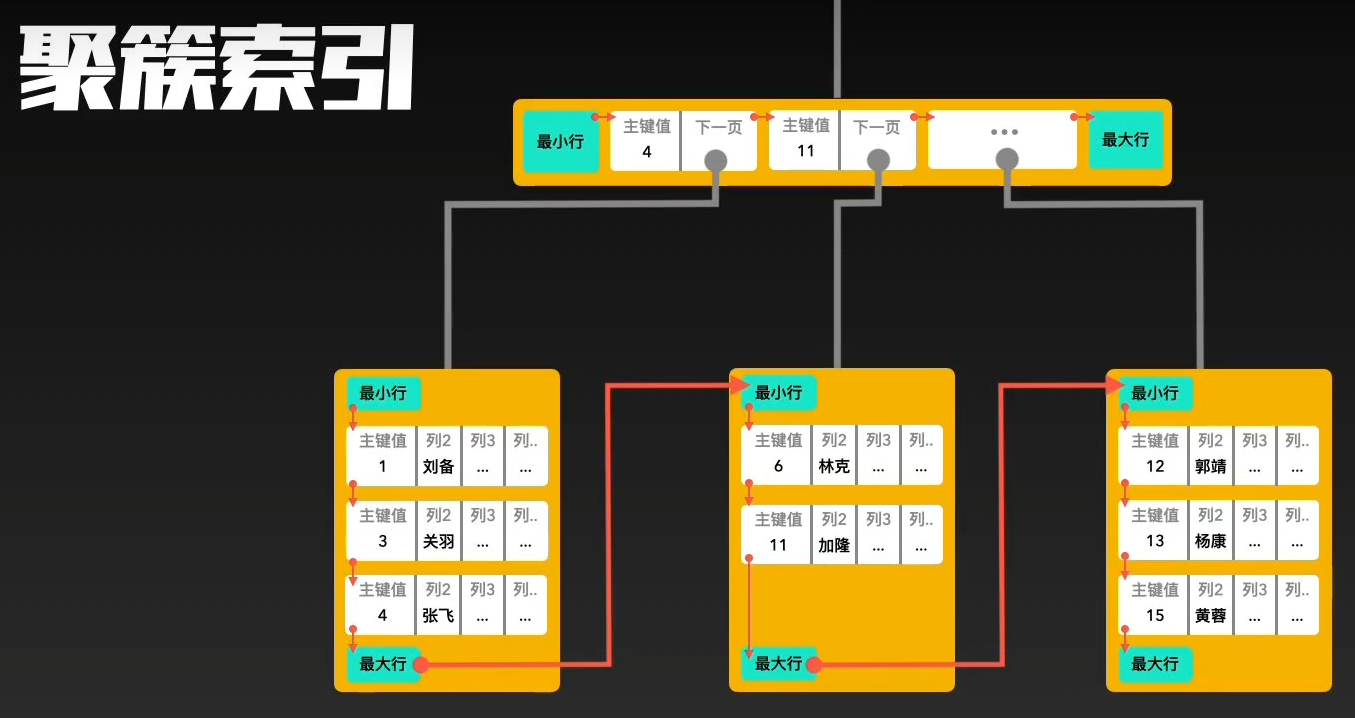
聚簇索引和非聚簇索引
兩者主要區別是數據和索引是否分離。
- 聚簇索引是將數據與索引存儲到一起,找到索引也就找到了數據;
葉子節點存儲真實數據
非葉子節點存儲查詢需要的key
一個表有且僅有一個聚簇索引,并且該索引是建立在主鍵上的,如果沒有主鍵,會建立在unique列上- 而非聚簇索引是將數據和索引存儲分離開,索引樹的葉子節點存儲了數據行的地址。
其他索引項都是非聚簇索引
葉子節點存儲聚簇索引的key
非葉子節點存儲查詢需要的key
查找會先找到葉子節點,拿葉子節點的聚簇索引的key再去搜索聚簇索引

索引為什么不用哈希表而用 B+ 樹
哈希表的查詢效率的確最高,時間復雜度O(1),但是它要求將所有數據載入內存,而數據庫存儲的數據量級可能會非常大,全部載入內存基本上是不可能實現的
索引為什么不用紅黑樹而用 B+ 樹
索引的底層用的并不是二叉樹和紅黑樹。因為二叉樹和紅黑樹在某些場景下都會暴露出一些缺陷。
二叉樹:在某些場景下會退化成鏈表,而鏈表的查找需要從頭部開始遍歷,而這就失去了加索引的意義。
紅黑樹:當數據表很多時,會導致索引樹的層數很高。索引從根節點開始查找,而如果我們需要查找的數據在底層的葉子節點上,那么樹的高度是多少,就要進行多少次查找,并且數據存在磁盤上,訪問還需要進行磁盤IO,這會導致效率過低。
提高查詢效率的方法
提高查詢效率的方法有很多,以下是一些常見的方法:
索引優化: 通過在經常查詢的列上創建索引,可以加快查詢速度。
優化查詢語句: 編寫高效的查詢語句是提高查詢效率的關鍵。避免使用SELECT *,只選擇需要的列;避免使用不必要的子查詢等。
內存緩存: 使用緩存技術將熱點數據存儲在內存中,可以減少數據庫訪問次數,提高查詢速度。
合適的數據類型: 使用合適的數據類型可以減少存儲空間并提高查詢效率。例如,選擇整數型而不是字符串型存儲數字數據。
定期優化數據庫: 定期清理無用數據、重建索引以及收集統計信息等可以提高數據庫性能。
)
)
)
的演進)






![[技巧]Arcgis之圖斑四至點批量計算](http://pic.xiahunao.cn/[技巧]Arcgis之圖斑四至點批量計算)




策略模式)

之數據校驗)

