StyTr2:引入 Transformer 解決 CNN 在長距離依賴性處理不足和細節丟失問題
- 提出背景
- StyTr2 組成
- StyTr2 架構
?
提出背景
論文:https://arxiv.org/pdf/2105.14576.pdf
代碼:https://github.com/diyiiyiii/StyTR-2
?
問題: 傳統的神經風格遷移方法因卷積神經網絡(CNN)的局部性,難以提取和維持輸入圖像的全局信息,導致內容表示偏差。
解法: 提出了一種新的方法StyTr2,這是一種基于變換器的圖像風格遷移方法,考慮輸入圖像的長距離依賴性。
StyTr2 組成
-
兩個不同的變換器編碼器(雙Transformer編碼器) - 內容域和風格域的分別編碼
之所以使用雙變壓器編碼器,是因為圖像的內容和風格信息在本質上是不同的域,需要獨立處理以更準確地捕捉各自的特征。
-
采用多層變換器解碼器,逐步生成輸出序列。
接著使用變壓器解碼器來逐步生成圖像塊的輸出序列,實現風格遷移。
之所以使用變壓器解碼器,是因為它可以有效地合并編碼階段得到的內容和風格信息,生成具有所需風格特征的內容圖像。
-
內容感知位置編碼(CAPE):提出了一種新的位置編碼方法,解決現有方法的不足,該方法是尺度不變的,更適合圖像風格遷移任務。
位置編碼在Transformer模型中用于提供序列中每個元素的位置信息。傳統的位置編碼方法可能不適合圖像生成任務,因為它們沒有考慮到圖像內容的語義信息。
CAPE通過將位置編碼與圖像內容的語義特征相結合,實現了對不同尺寸圖像的有效處理。
之所以使用內容感知位置編碼,是因為它能夠根據圖像的語義內容動態調整位置信息,使得Transformer模型在處理具有不同尺寸和風格的圖像時更加靈活和有效。
內容感知位置編碼(CAPE)的示意圖:
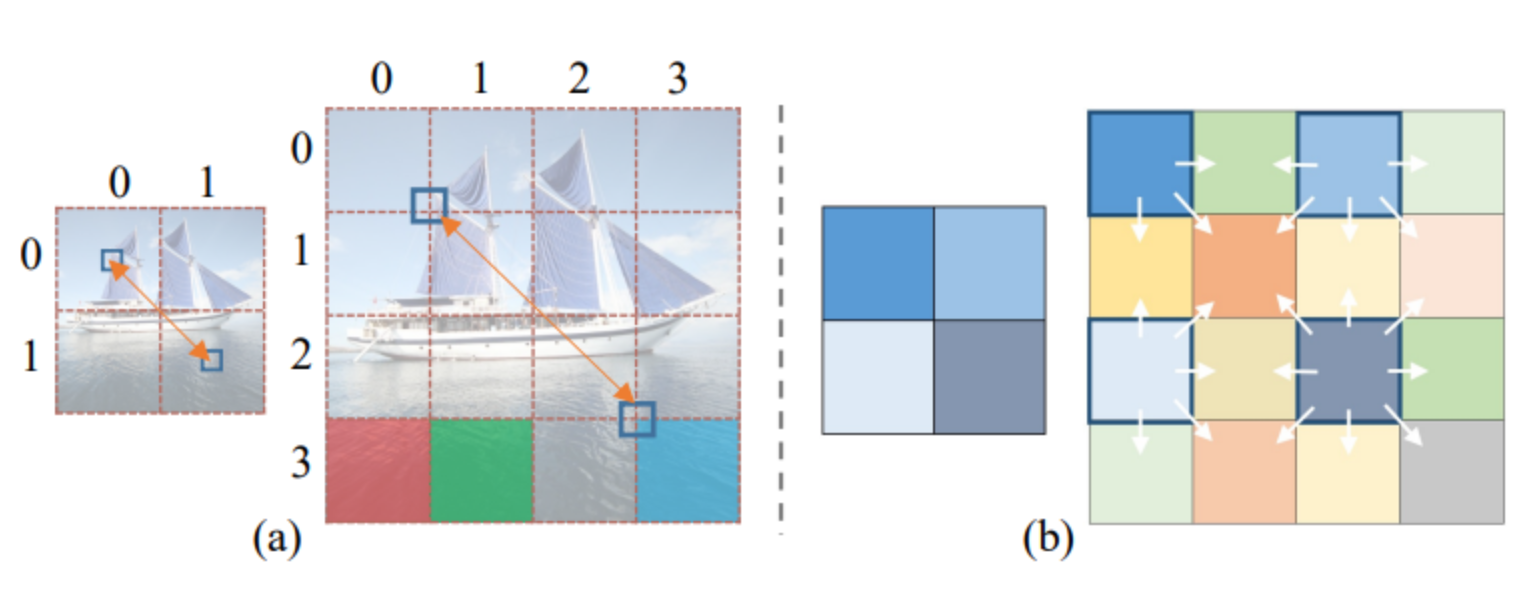
(a):展示了如何將一張圖片分割成不同的區塊,并對每個區塊進行標記。
(b):展示了內容感知位置編碼(CAPE)的結構,這是一個考慮圖像內容語義的位置編碼系統,與傳統的Transformer模型中使用的位置編碼不同,它基于圖像的內容來調整每個區塊的位置信息。
StyTr2 架構
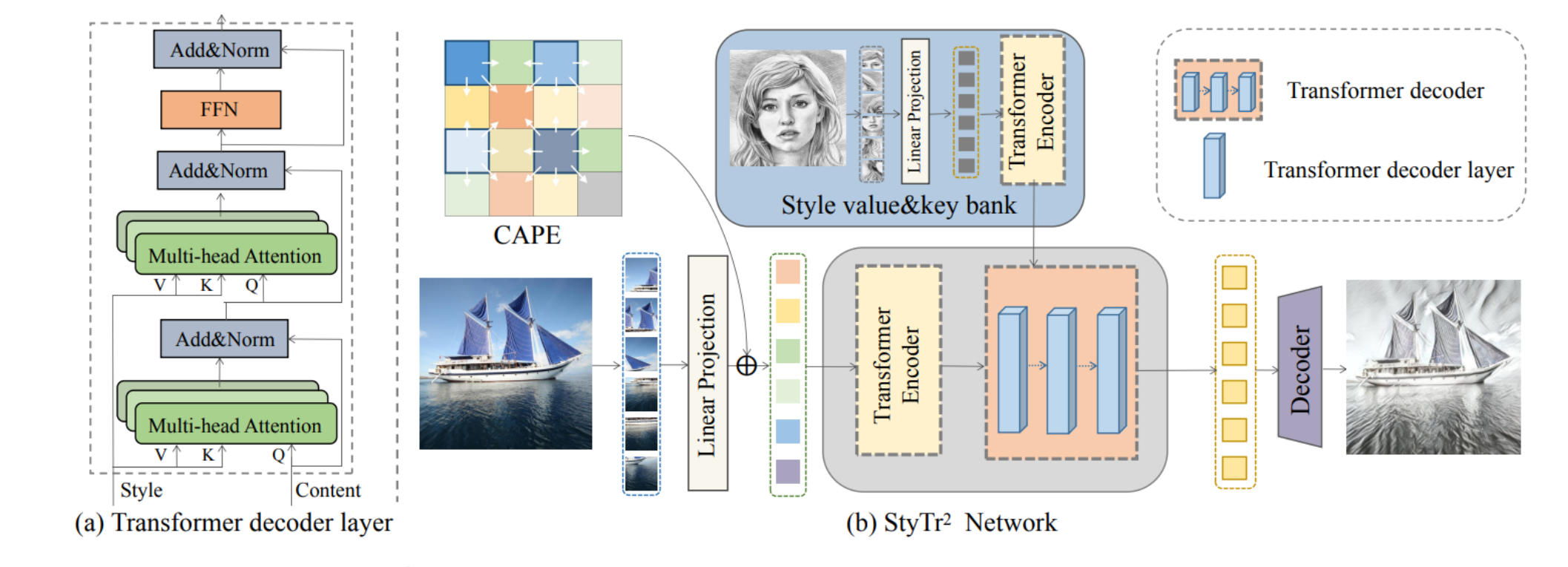
- (a) Transformer解碼器層:展示了Transformer解碼器的結構,包含多頭注意力機制和前饋神經網絡(FFN),說明了在風格遷移中,如何處理內容和風格信息。
- (b) StyTr2網絡:展示了整個網絡的結構,包括內容和風格圖像的分割、轉換成序列,以及使用Transformer編碼器和解碼器處理這些序列。最終,使用一個遞進式上采樣解碼器來得到最終的輸出圖像。
效果對比:

這個表格顯示了不同風格遷移方法在內容損失(Lc)和風格損失(Ls)方面的性能比較。
這些損失值用于衡量生成的圖像在保留輸入內容和風格方面的效果。
表格中,“我們的”結果指的是StyTr2方法的結果,它在保持內容和風格方面取得了最佳效果,其次是其他列出的方法。
這些結果說明StyTr2在風格遷移任務中表現出色,尤其是在保留內容結構和風格特征方面。










)








