傳統的3D場景理解方法依賴于帶標簽的3D數據集,用于訓練一個模型以進行單一任務的監督學習。我們提出了OpenScene,一種替代方法,其中模型在CLIP特征空間中預測與文本和圖像像素共同嵌入的3D場景點的密集特征。這種零樣本方法實現了與任務無關的訓練和開放詞匯查詢。例如,為了執行最先進的零樣本 3D語義分割,它首先推斷每個3D點的CLIP特征,然后根據與任意類別標簽的嵌入的相似性對它們進行分類。更有趣的是,它實現了一系列以前從未實現過的開放詞匯場景理解應用。例如,它允許用戶輸入任意文本查詢,然后查看一個熱圖,指示場景的哪些部分匹配。我們的方法在復雜的3D場景中有效地識別對象、材料、功能、活動和房間類型,所有這些只使用一個模型進行訓練,而無需任何帶標簽的3D數據。
1. Introduction
3D場景理解是計算機視覺中的一項基本任務。給定一個帶有一組RGB圖像的3D網格或點云,目標是推斷每個3D點的語義、可視性、功能和物理屬性。例如,給定圖1所示的房子,我們想要預測哪些表面是風扇(語義)的一部分,由金屬(材料)制成,在廚房(房間類型)內,人可以坐在哪里(可供性),人可以在哪里工作(功能),哪些表面是柔軟的(物理性質)。這些問題的答案可以幫助機器人與場景進行智能交互,或者通過交互式查詢和可視化幫助人們理解場景。
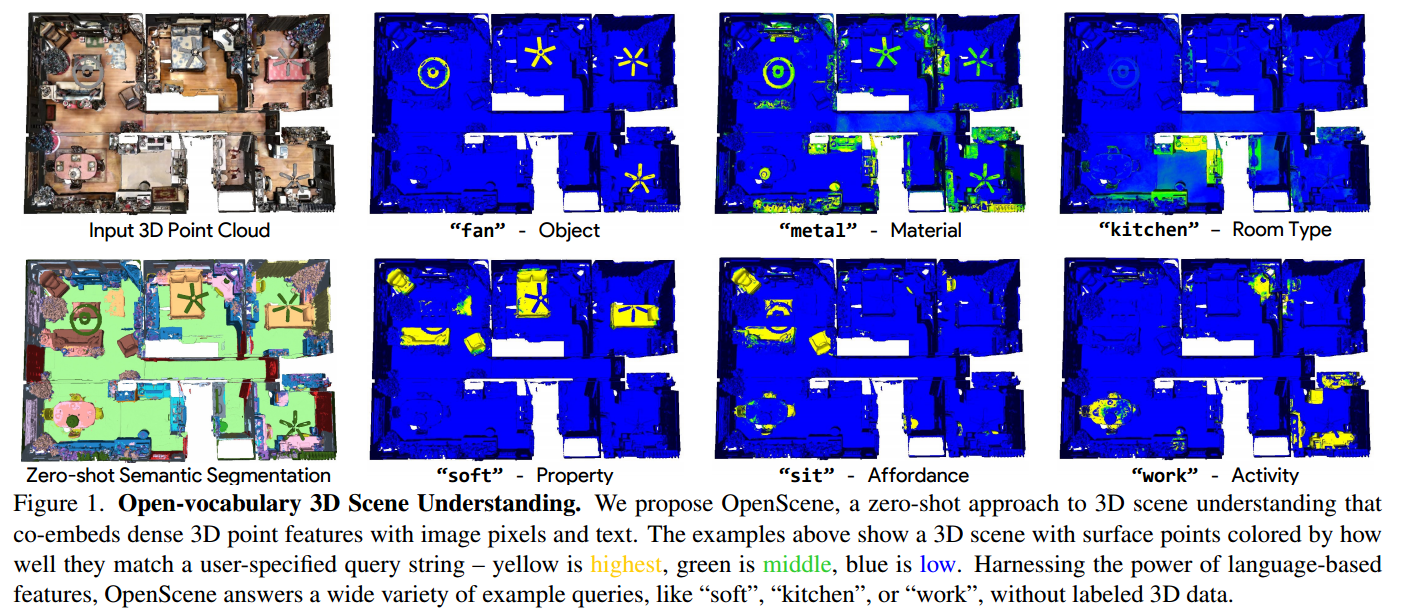
(圖1:開放詞


)













)
(2))

)