需求分析
使用Spark來探索數據是一種高效處理大規模數據的方法,需要對數據進行加載、清洗和轉換,選擇合適的Spark組件進行數據處理和分析。需求分析包括確定數據分析的目的和問題、選擇合適的Spark應用程序和算法、優化數據處理流程和性能、可視化和解釋分析結果。同時,需要熟悉Spark的基本概念和操作,掌握Spark編程和調優技巧,以確保數據探索的準確性和效率。
系統實現
了解實驗目的
掌握python on Spark的使用理解探索數據的意義和方法,掌握使用Spark探索數據的過程。
1.實驗整體流程分析:
- 準備環境,安裝Hadoop和Spark組件
- 準備數據,采用開源movielens數據集
- 探索用戶數據
- 探索電影數據
- 探索電影評級數據
?2.準備數據:
- 打開終端,啟動Hadoop和Spark集群

- 下載相關數據集

- 將數據集解壓到/usr/目錄下

- 上傳數據至HDFS
#?hadoop?fs?-mkdir?/data
#?hadoop?fs?-ls?/
#?hadoop fs -put /usr/data/u.user /data/u.user
#?hadoop fs -put /usr/data/u.data /data/u.data
#?hadoop fs -put /usr/data/u.genre /data/u.genre
#?hadoop fs -put /usr/data/u.info /data/u.info
#?hadoop fs -put /usr/data/u.item /data/u.item
#?hadoop fs -put /usr/data/u.occupation /data/u.occupation
#?hadoop fs -ls /data上傳后的HDFS的data目錄結構如圖所示
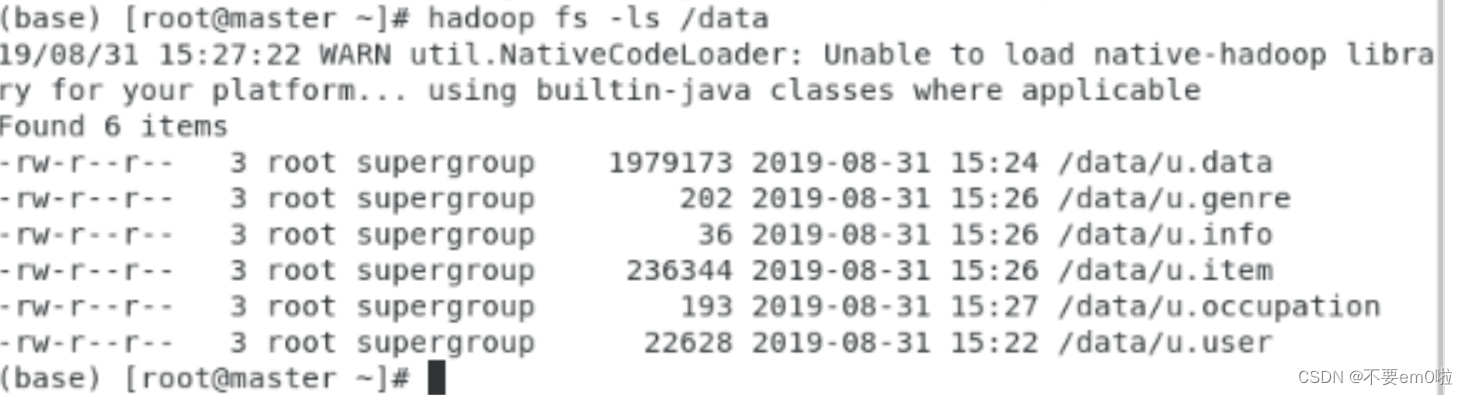
3.探索用戶數據:
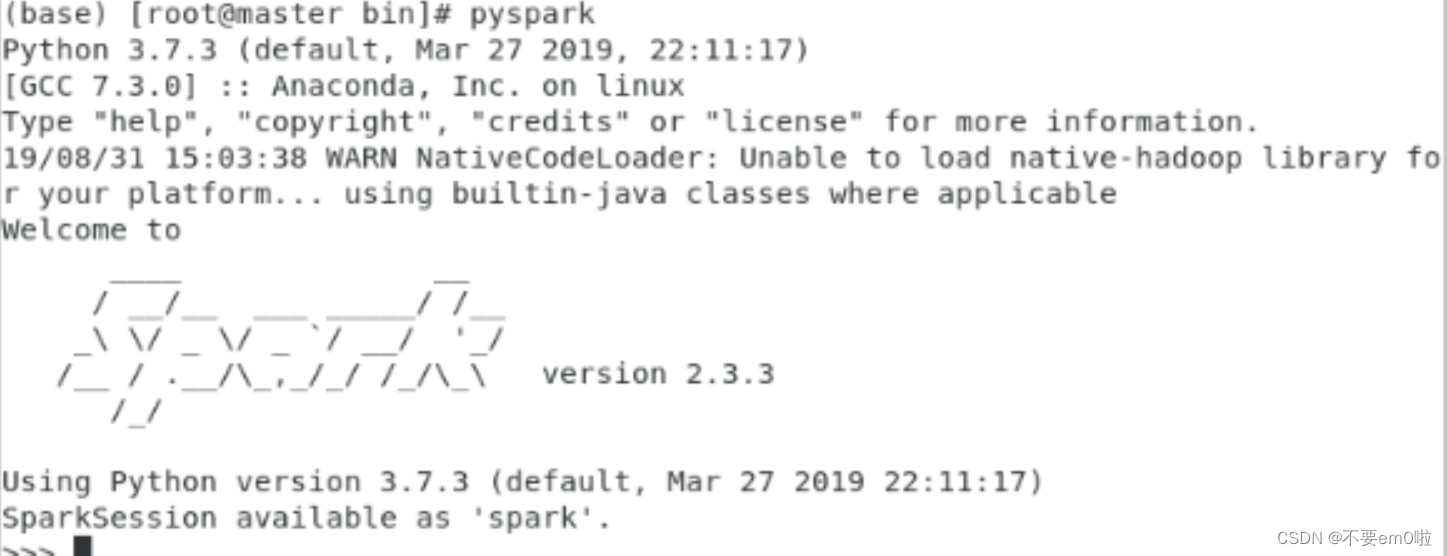
- 打開終端,執行pyspark命令,進入Spark的python環境

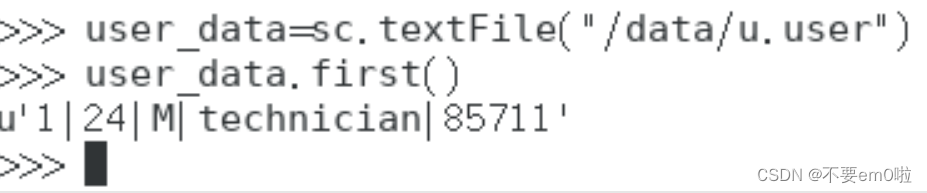
- 打印首行記錄

運行結果如下
- 分別統計用戶、性別和職業的個數
#?以'?|?'切分每列,返回新的用戶RDD
user_fields?=?user_data.map(lambda?line:?line.split("|"))
#?統計用戶數
num_users?=?user_fields.map(lambda?fields:?fields[0]).count()
#?統計性別數
num_genders?=?user_fields.map(lambda?fields:?fields[2]).distinct().count()
#?統計職業數
num_occupations?=?user_fields.map(lambda?fields:?fields[3]).distinct().count()
#?統計郵編數
num_zipcodes?=?user_fields.map(lambda?fields:?fields[4]).distinct().count()
#?返回結果
print?("用戶數:?%d,?性別數:?%d,?職業數:?%d,?郵編數:?%d"?%?(num_users,?num_genders,?num_occupations,?num_zipcodes))運行結果如下

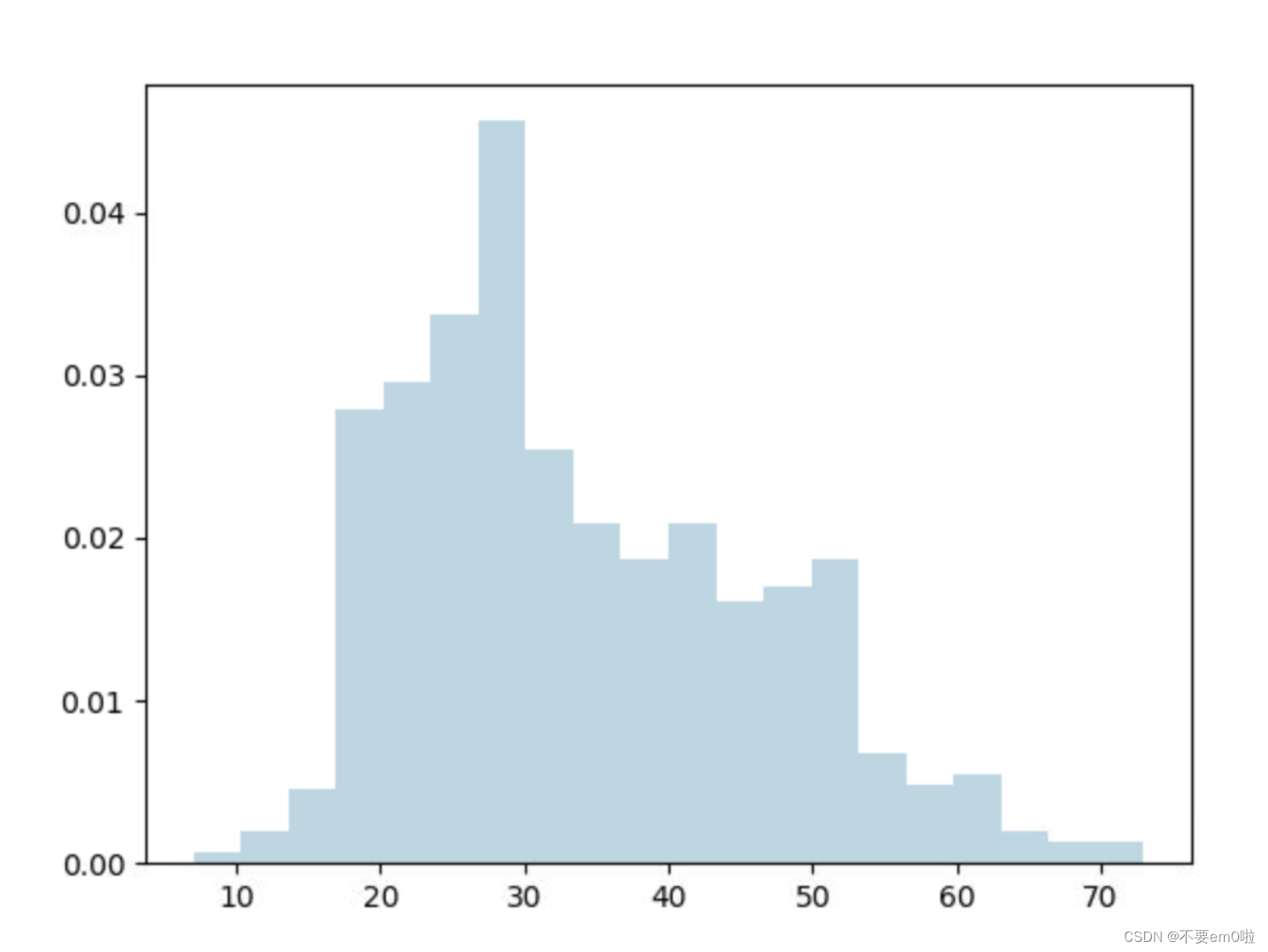
- 查看年齡分布情況,并用plt.show繪制

- 查看職業分布情況,同樣繪制圖
#?并行統計各職業人數的個數,返回職業統計RDD后落地
count_by_occupation?=?user_fields.map(lambda?fields:?(fields[3],?1)).reduceByKey(lambda?x,?y:?x?+?y).collect()
#?生成x/y坐標軸
x_axis1?=?np.array([c[0]?for?c?in?count_by_occupation])
y_axis1?=?np.array([c[1]?for?c?in?count_by_occupation])
x_axis?=?x_axis1[np.argsort(x_axis1)]
y_axis?=?y_axis1[np.argsort(y_axis1)]
#?生成x軸標簽
pos?=?np.arange(len(x_axis))
width?=?1.0
ax?=?plt.axes()
ax.set_xticks(pos?+?(width?/?2))
ax.set_xticklabels(x_axis)
#?繪制職業人數條狀圖
plt.xticks(rotation=30)
plt.bar(pos,?y_axis,?width,?color='lightblue')
plt.show()?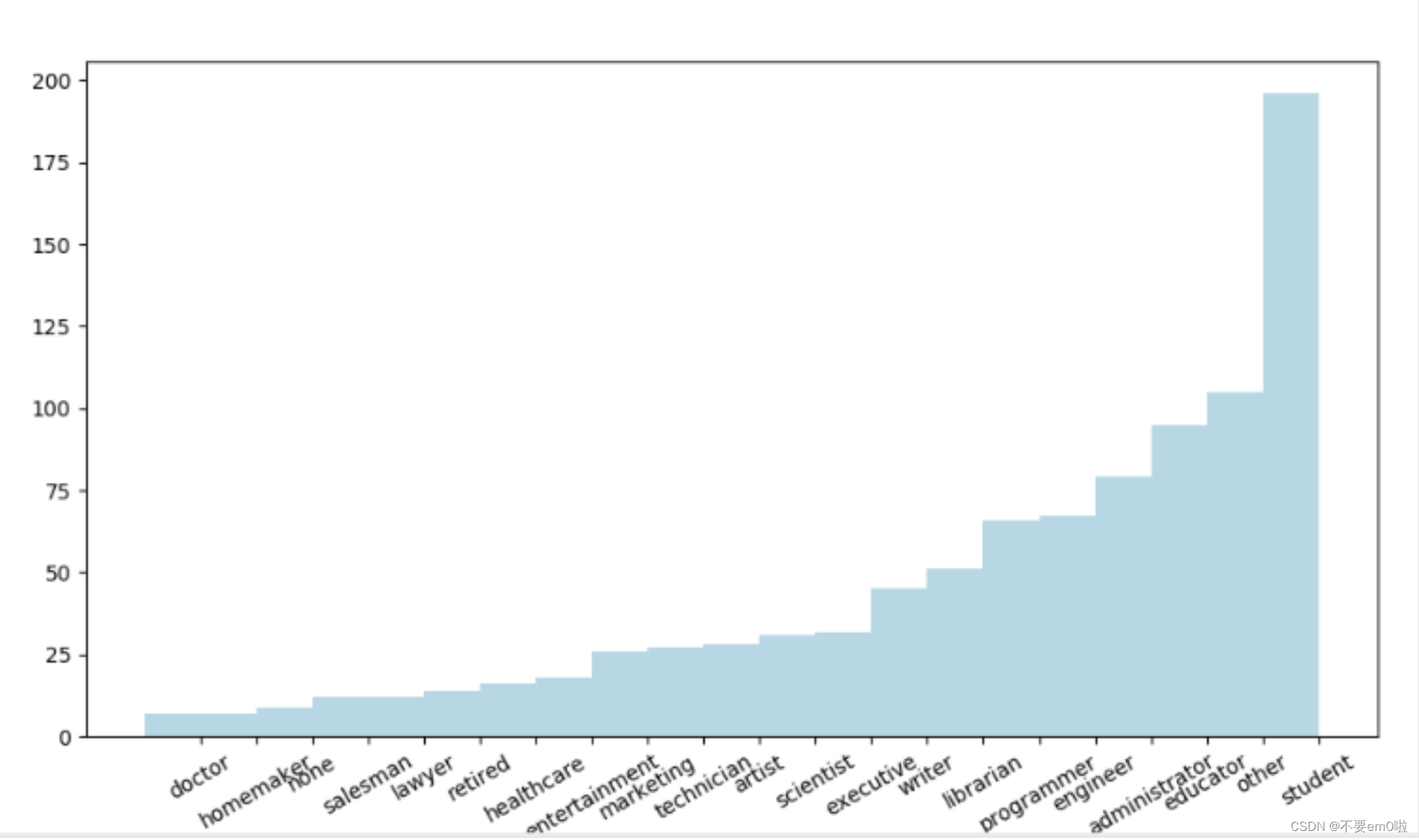
- 統計各職業人數


4.探索電影數據:
- 重新打開終端,執行pyspark命令,進入Spark的python環境
- 打印首行記錄


- 查看電影的數量


- 過濾掉沒有發現時間信息的記錄

注意,輸入時需要手動縮進

- 查看影片的年齡分布并繪圖

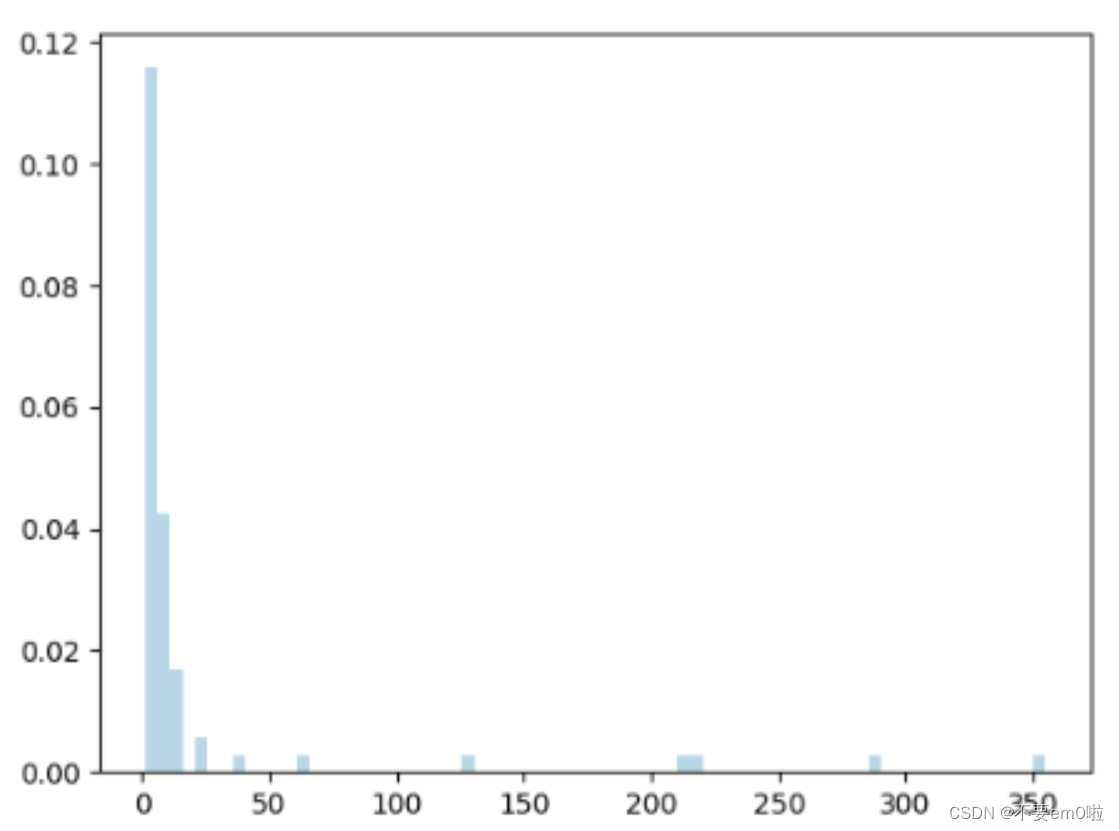
5.探索評級數據:
- 重新打開終端,進入Spark的bin目錄下,執行pyspark命令,進入Spark的python環境

- 打印首行記錄

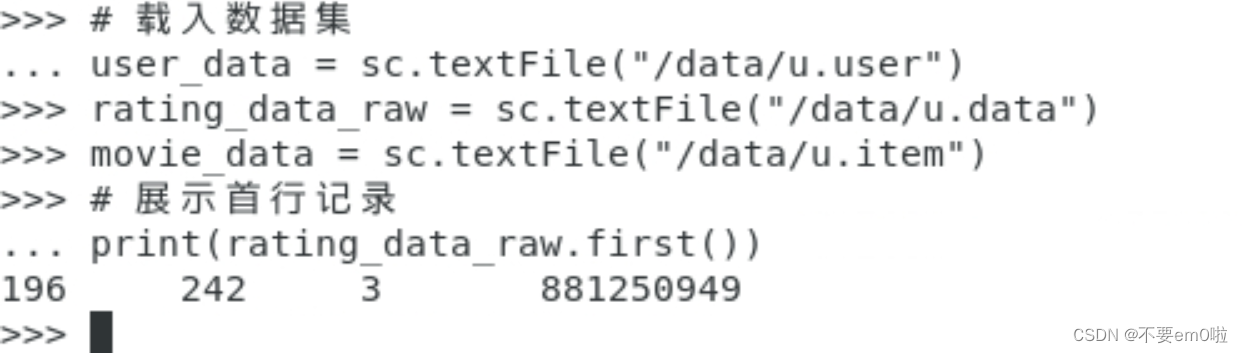
- 查看有多少人參與了評分


- 統計最高、最低、平均、中位評分,以及平均每個用戶的評分次數
#?以'?|?'切分每列,返回新的用戶RDD
user_fields?=?user_data.map(lambda?line:?line.split("|"))
#?統計用戶數
num_users?=?user_fields.map(lambda?fields:?fields[0]).count()
# 獲取電影數量
num_movies?=?movie_data.count()
#?獲取評分RDD
rating_data?=?rating_data_raw.map(lambda?line:?line.split("\t"))
ratings?=?rating_data.map(lambda?fields:?int(fields[2]))
#?計算最大/最小評分
max_rating?=?ratings.reduce(lambda?x,?y:?max(x,?y))
min_rating?=?ratings.reduce(lambda?x,?y:?min(x,?y))
#?計算平均/中位評分
mean_rating?=?ratings.reduce(lambda?x,?y:?x?+?y)?/?float(num_ratings)
median_rating?=?np.median(ratings.collect())
#?計算每個觀眾/每部電影平均打分/被打分次數
ratings_per_user?=?num_ratings?/?num_users
ratings_per_movie?=?num_ratings?/?num_movies
#?輸出結果
print("最低評分:?%d"?%?min_rating)
print("最高評分:?%d"?%?max_rating)
print("平均評分:?%2.2f"?%?mean_rating)
print("中位評分:?%d"?%?median_rating)
print("平均每個用戶打分(次數):?%2.2f"?%?ratings_per_user)
print("平均每部電影評分(次數):?%2.2f"?%?ratings_per_movie)
- 統計評分分布情況
#?生成評分統計RDD,并落地
count_by_rating?=?ratings.countByValue()
#?生成x/y坐標軸
x_axis?=?np.array(count_by_rating.keys())
y_axis?=?np.array([float(c)?for?c?in?count_by_rating.values()])
#?對人數做標準化
y_axis_normed?=?y_axis?/?y_axis.sum()
#?生成x軸標簽
pos?=?np.arange(len(y_axis))
width?=?1.0
ax?=?plt.axes()
ax.set_xticks(pos?+?(width?/?2))
ax.set_xticklabels(y_axis)
#?繪制評分分布柱狀圖
plt.bar(pos,?y_axis_normed,?width,?color='lightblue')
plt.xticks(rotation=30)
plt.show()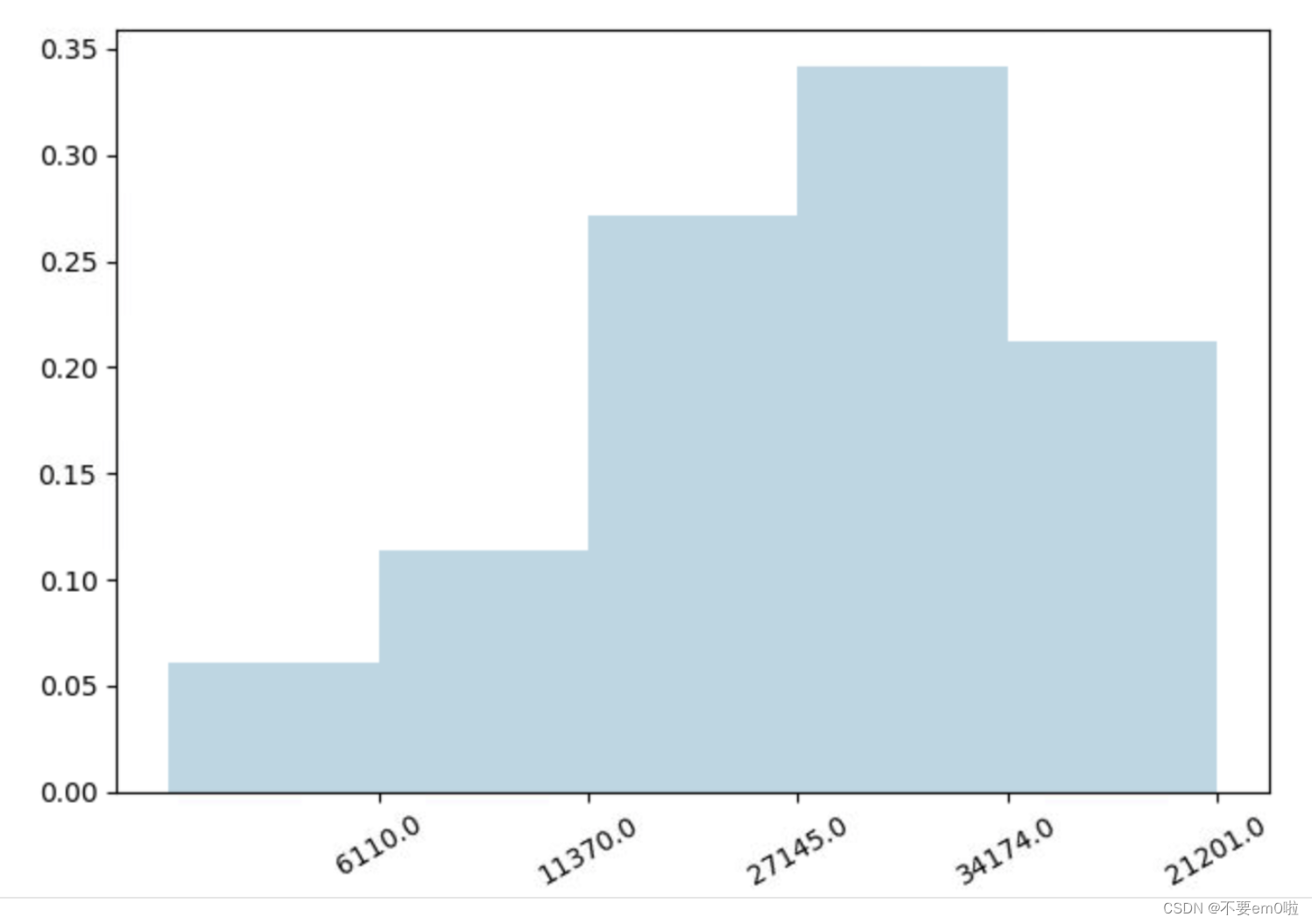












)
(2))

)


)
