目錄
一、多線程環境使用ArrayList
二、多線程環境使用隊列
三、多線程環境使用哈希表
1、HashMap
2、Hashtable
3、ConcurrentHashMap
(1)縮小了鎖的粒度
(2)充分使用了CAS原子操作,減少一些加鎖
(3)針對擴容操作的一些優化(化整為零)
四、相關面試題
大部分集合類都是線程不安全的,Vector,Stack,Hashtable是線程安全的,但不建議使用,因為無論什么情況都要加鎖,甚至單線程也是,這樣就很不合理;并且這幾個集合類官方已經不推薦使用了,可能在未來的版本中就被刪掉了。
下面介紹一些線程不安全的集合類。
一、多線程環境使用ArrayList
1、自己使用同步機制(synchronized或者ReentrantLock)
2、Collections.synchronizedList(new ArrayList);
? ? ? ? 相當于給ArrayList套了個殼,ArrayList各種操作本身是不帶鎖的,通過上述操作套殼后,得到了新的對象,新的對象里面的關鍵方法都是帶有鎖的。
3、使用CopyOnWriteArrayList
????????CopyOnWrite容器即寫時復制的容器,多線程對這個順序表進行讀操作時,不會有線程安全問題,但是當多線程進行寫操作時,就會有線程安全問題,CopyOnWriteArrayList會復制一份原來的順序表,并且修改新的順序表內容,再把原來的引用指向新的順序表(此操作是原子的,不需要加鎖)。
二、多線程環境使用隊列
1、自己加鎖
2、使用BlockingQueue
1. ArrayBlockingQueue
基于數組實現的阻塞隊列
2. LinkedBlockingQueue
基于鏈表實現的阻塞隊列
3. PriorityBlockingQueue
基于堆實現的帶優先級的阻塞隊列
4. TransferQueue
最多只包含?個元素的阻塞隊列
三、多線程環境使用哈希表
1、HashMap
? ? ? ? HashMap本身就是線程不安全的。
2、Hashtable
? ? ? ? 在一些關鍵方法上加了鎖
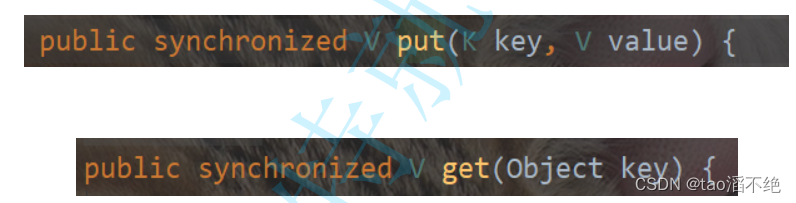
? ? ? ? 這也相當于對this加了鎖,也就是針對Hashtable對象本身加鎖,如果嘗試修改Hash表中兩個不同Hash值里的鏈表,會發生鎖沖突。如圖:

3、ConcurrentHashMap
相對于Hashtable,進行了些優化。
(1)縮小了鎖的粒度
????????多線程如果修改Hash表里Hash值不同的鏈表都發生鎖沖突,是不合理的,而且鎖沖突是很耗時的,所以ConcurrentHashMap是對Hash表里每個鏈表都進行加鎖,這樣,不同的鏈表有不同的鎖對象,多線程修改兩個不同的鏈表,就不會發生鎖沖突了,如圖:
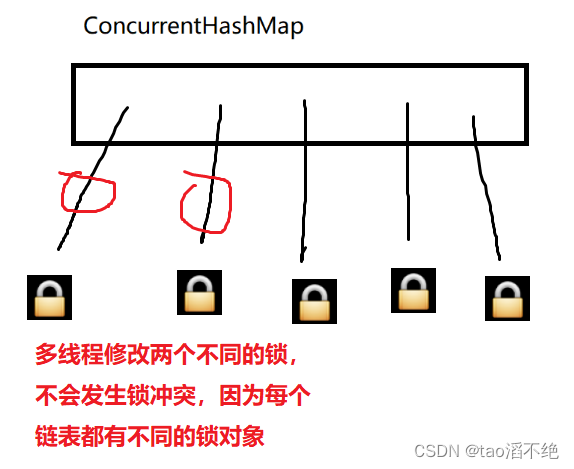
注意:更多的鎖并不意味著要耗費更多的空間,因為在java中的任何對象都可以作為鎖對象,而本身Hash表中就得有數組,數組元素都已經存在,即鏈表的頭結點,每個鏈表都有一個頭結點,可以直接把這個頭結點作為鏈表的鎖對象。
(2)充分使用了CAS原子操作,減少一些加鎖
? ? ? ? 比如,針對Hash表元素個數的維護。
(3)針對擴容操作的一些優化(化整為零)
? ? ? ? 負載因子:描述了每個桶(Hash表)平均有多少個元素;公式:實際個數 / 數組長度(桶的個數)。0.75是默認的擴容閾值(也可以是其他數字值),如果我們算出的負載因子超過規定的擴容閾值,Hash表就會進行擴容。
? ? ? ? 進行擴容時,如果不是concurrentHashMap,會創建一個更大是數組,把舊的數組元素搬運到新的數組中,一次性的全部搬運完,如果Hash表本身的元素就非常多,這里擴容就會非常耗時,但可能過一會兒就又好了,存在不穩定因素,我們無法控制Hash表何時觸發擴容。
? ? ? ? concurrentHashMap則不是一次性的全部搬運完,而是把Hash表中的元素分為若干次搬運完,而不是直接一次性梭哈完,假設Hash表有1kw個元素,每次就只搬運5k哥元素,一共花費2k次搬運完成(搬運的時間會更長一些),但能確保每次搬運消耗的時間不會很長,避免出現很卡的情況。
總的來說,擴容是一個低頻的操作(前提把擴容閾值設置合理),運行整個程序,可能一天都不會觸發擴容,觸發了每次可能會花費幾分鐘的時間進行搬運。
注意:在擴容過程中,存在兩份Hash表,一份是新的,一份是舊的。
? ? ? ? 進行插入操作,直接往新的Hash表上插入。
? ? ? ? 進行刪除操作,新的舊的都要刪除。
? ? ? ? 進行查找操作,新的舊的都要查找。
四、相關面試題
1.ConcurrentHashMap的讀是否要加鎖,為什么?
?讀操作沒有加鎖.目的是為了進一步降低鎖沖突的概率.為了保證讀到剛修改的數據,搭配了volatile關鍵字.
2.介紹下ConcurrentHashMap的鎖分段技術?
這個是Java1.7所采取的技術.Java1.8中已經不再使用了.簡單的說就是把若干個哈希桶分成一個"段"(Segment),針對每個段分別加鎖.
目的也是為了降低鎖沖突的概率.當兩個線程訪問的數據恰好在同一個段上時,才會觸發鎖競爭
3.ConcurrentHashMap在jdk1.8做了哪些優化?
取消了分段鎖,直接給每個哈希桶(每個鏈表)分配了一個鎖(就是以每個鏈表的頭節點對象作為鎖對象).
將原來的數組 + 鏈表的實現方式改進成 數組 + 鏈表 /紅黑樹的方式.當鏈表較長的時候(大于等于8個元素)就轉換成紅黑樹.?
4.HashMap和HashTable,ConcurrentHashMap之間的區別?
HashMap: 線程不安全.key允許為null
HashTable:線程安全.使用synchronized鎖HashTable對象,效率較低.key不允許設置為null.
ConcurrentHashMap: 線程安全.使用synchronized鎖每個鏈表的頭節點,鎖沖突概率較低,充分利用CAS機制,優化了擴容方式.key不允許為null.?








函數詳解上)






![[算法沉淀記錄] 分治法應用 —— 二分搜索(Binary Search)](http://pic.xiahunao.cn/[算法沉淀記錄] 分治法應用 —— 二分搜索(Binary Search))



