原文:https://blog.iyatt.com/?p=13818
13 存儲引擎
查看一下前面創建的一張表的創建語句,當時并沒有顯式指定引擎,MySQL 自動指定的 InnoDB,即默認引擎是這個。
創建表的時候要顯式指定引擎可以參考這個語句
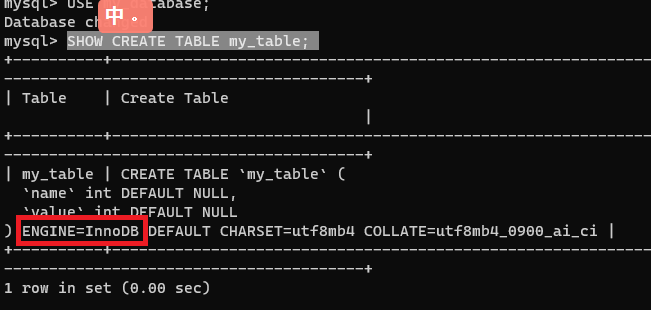
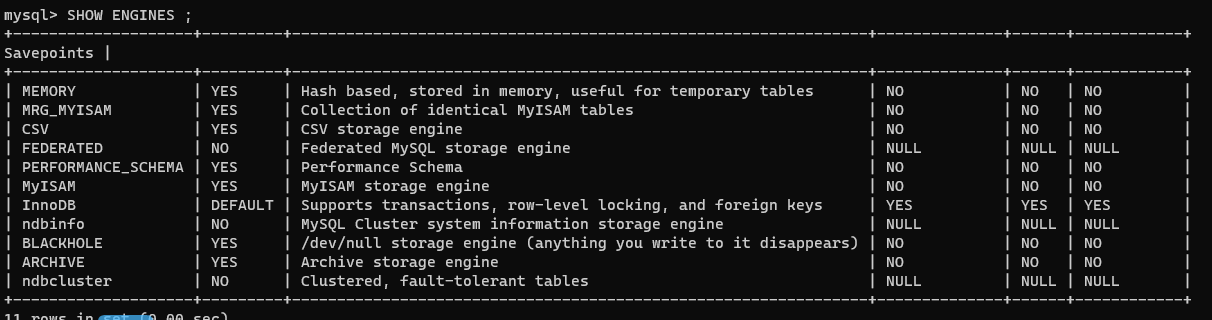
查看當前 MySQL 版本支持的引擎有那些
SHOW ENGINES ;
\begin{array}{|l|l|l|l|}
\hline
特點 & InnoDB & MyISAM & Memory \\
\hline
事務安全 & 支持 & - & - \\
鎖機制 & 行鎖 & 表鎖 &表鎖 \\
B+tree索引 & 支持 & 支持 & 支持 \\
Hash索引 & - & - & 支持 \\
全文索引 & 支持(5.6版本之后)& 支持 & - \\
空間使用 & 高 & 低 & N/A \\
內存使用 & 高 & 低 & 中等 \\
批量插入速度 & 低 & 高 & 高 \\
支持外鍵 & 支持 & - & - \\
\hline
\end{array}
-
InnoDB:MySQL 的默認存儲引擎,支持事務、外鍵。如果對事務的完整性有比較高的要求,在并發條件下要求數據的一致性。另外對數據的操作除了插入和查詢之外,還包含很多的更新、刪除操作,那么選擇這個引擎比較合適。
-
MyISAM:如果是以讀取和插入操作為主,只有很少的更新和刪除操作,并且對事務的完整性、并發性要求不是很高,那么可以選擇這個引擎。
-
MEMORY:所有數據都保存在內存中,訪問速度快,通常用于臨時表及緩存。不過存在一定的缺陷,對表的大小有限制,太大的表無法存儲在內存中,并且無法保障數據的安全性(意外斷電、宕機等可能造成數據丟失)
14 索引 - 查詢優化
\begin{array}{|l|l|}
\hline
索引結構 & 描述 \\
\hline
B+Tree & 最常見的索引類型,大部分存儲引擎都支持。 \\
Hash索引 & 底層數據結構是用哈希表實現的,只有精確匹配索引列的查詢才有效,不支持范圍查詢。\\
R-tree & 這是 MyISAM 引擎的一個特殊索引類型,主要用于地理空間數據類型,使用較少。 \\
Full-text & 通過建立倒排索引,快速匹配文檔的方式。\\
\hline
\end{array}
\begin{array}{|l|l|l|l|}
\hline
索引 & InnoDB & MyISAM & Memory \\
\hline
B+tree & 支持 & 支持 & 支持 \\
Hash & 不支持 & 不支持 & 支持 \\
R-tree & 不支持 & 支持 & 不支持 \\
Full-text & 支持(5.6版本后) & 支持 & 不支持 \\
\hline
\end{array}
數據結構可視化:https://iyatt.com/tools/DataStructureVisualizations/Algorithms.html
B+tree 依次插入100、65、169、368、900、556、780、35、215、1200、234、888、158、90、1000、88、120、268、250

\begin{array}{|l|l|l|l|}
\hline
分類 & 含義 & 特點 & 關鍵字 \\
\hline
主鍵索引 & 針對表中主鍵創建的索引 & 默認自動自動創建,只有一個 & PRIMARY \\
唯一索引 & 避免同一個表中某列數據重復 & 可以有多個 & UNIQUE \\
常規索引 & 快速定位特定數據 & 可以有多個 & \\
全文索引 & 全文索引查找的是文本中的關鍵詞,而不是比較索引中的值 & 可以有多個 & FULLTEXT \\
\hline
\end{array}
在 InnoDB 中
\begin{array}{|l|l|l|}
\hline
分類 & 含義 & 特點 \\
\hline
聚集索引(Clustered Index) & 將數據存儲與索引放在了一塊,索引結構的葉子節點保存了行數據 & 必須有,且只有一個 \\
二級索引(Secondary Index) & 將數據和索引分開存儲,索引結構的葉子節點關聯的是對應的主鍵 & 可以存在多個 \\
\hline
\end{array}
聚集索引選取規則:
- 如果存在主鍵,主鍵索引就是聚集索引
- 如果不存在主鍵,將使用第一個唯一索引作為聚集索引
- 如果前兩者都沒有合適的,則 InnoDB 會自動生成一個 rowid 作為隱藏的聚集索引
創建索引
(如果要創建常規索引,則不指定 UNIQUE 或 FULLTEXT)
CREATE [UNIQUE | FULLTEXT] INDEX 索引名 ON 表名 (索引列名);
查看索引
SHOW INDEX FROM 表名;
刪除索引
DROP INDEX 索引名 ON 表名;
14.1 語法
創建一張表,創建語句使用:https://blog.iyatt.com/?p=12631#101_%E4%B8%80%E8%88%AC%E7%BA%A6%E6%9D%9F%E7%A4%BA%E4%BE%8B
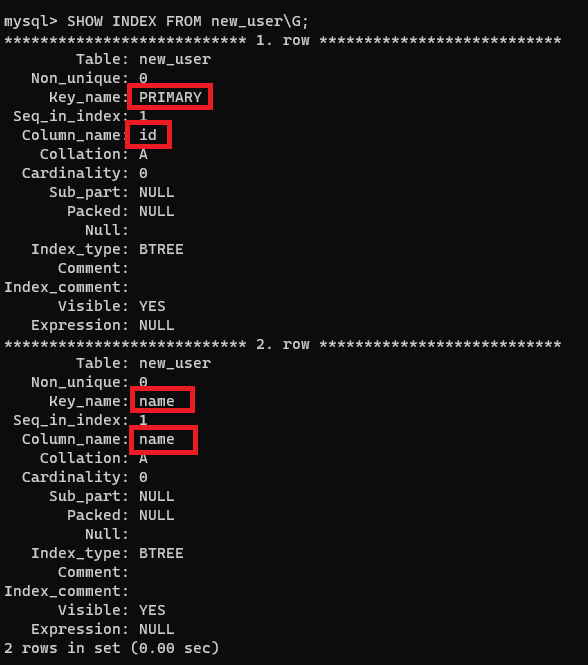
查看這張表的索引
(加上 \G 會按行顯示)
SHOW INDEX FROM new_user\G;
可以看到列名 id 的 Key_name 是 PRIMARY 主鍵索引(創建表指定了主鍵約束),列名 name 的 Key_name 就是列名,該列在創建表時指定了唯一約束,其它列則沒有索引。
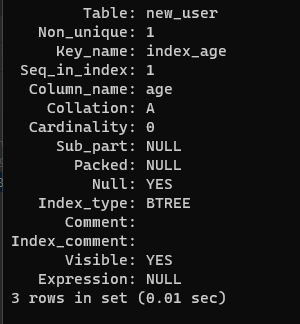
現在手動為 age 列創建一個常規索引名為 index_age
CREATE INDEX index_age ON new_user(age);
再次查看可以看到 age 列的索引
刪除創建的常規索引
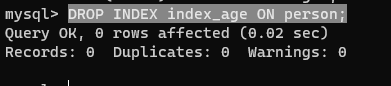
DROP INDEX index_age ON new_user;
再次為 age 和 status 同時創建一個唯一索引(聯合索引)
CREATE UNIQUE INDEX index_age ON new_user(age, status);
查看索引
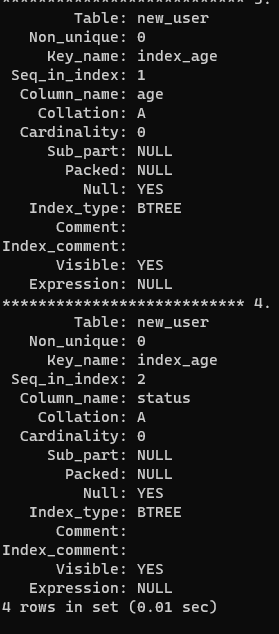
14.2 性能分析
14.2.1 查詢 SQL 執行頻次
查詢狀態信息
SHOW [SESSIOn | GLOBAL] STATUS;
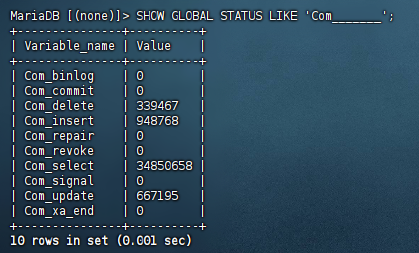
篩選出 SQL 語句執行次數,全局查詢含有 Com 的且后續還有 7 個字母的變量,用 7 個下劃線 _ 匹配
SHOW GLOBAL STATUS LIKE 'Com_______';
這里我在當前博客的服務器數據庫上查詢(Mariadb 和 MySQL 基本上兼容)
可以看到插入了 948768 次,刪除了 339467 次,查詢了 34850658 次,修改了 667195 次。可以看到里面查詢次數是最多的,畢竟博客大多數時候都是瀏覽查看,所以優化的重點就在查詢上。
14.2.2 慢查詢日志
當 MySQL 中某個語句執行超過設定時間,就會記錄到日志中,默認是沒有打開的。
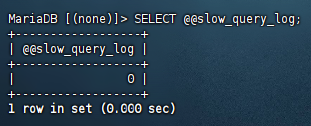
查看是否開啟慢查詢日志
當前是關閉的
SELECT @@slow_query_log;
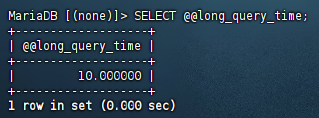
查看慢查詢時間
默認是 10s,查詢時間超過它就會記錄日志
SELECT @@long_query_time;
如果要開啟慢查詢日志可以配置:
- Windows:前往路徑 C:\ProgramData\MySQL\MySQL Server 版本,編輯 my.ini(打開顯示隱藏文件,不然看不到這個路徑)
這個文件默認是沒有編輯權限的,可以在這個文件上右鍵打開屬性
給自己的當前用戶添加修改權限
這樣就可以編輯這個文件了,Windows 默認是打開狀態的
slow-query-log 設置 1 就是開啟,設置 0 就是關閉。
slow_query_log_file 設置文件名,日志文件位于 C:\ProgramData\MySQL\MySQL Server 版本\Data 下。
long_query_time 設置超時時間。
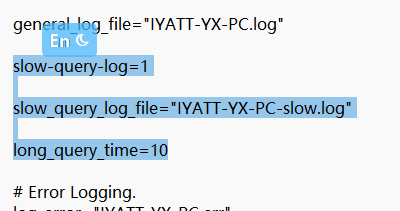
修改完保存,并重啟 MySQL 服務器
- Linux:以 root 權限編輯 /etc/my.cnf,我博客服務器用的 Mariadb 10.3.38 中這個文件在 /etc/mysql/my.cnf。配置參數方法同上。
如果要臨時設置可以使用下面命令(重啟恢復為配置文件中的默認狀態),后續其它變量一樣
# SESSION 只在當前會話中,GLOBAL 在所有客戶端都生效
SET [SESSION | GLOBAL] 變量名 = 變量值;
在 Windows 中默認試打開的,在 Linux 中默認是關閉的。估計因為一般開發是在 Windows 上,這個打開本來就是用于調試,而實際生產環境部署一般是在 Linux 上,所以默認是關閉的,在生產環境上開啟這些記錄只會增加資源消耗,浪費本該用于業務執行的性能。
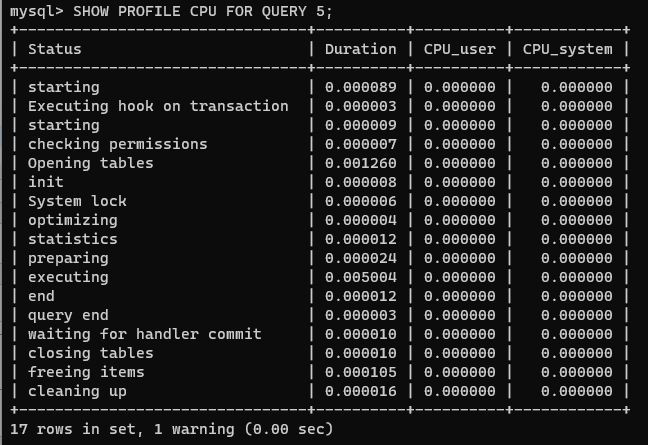
14.2.3 profile
查看語句執行耗時
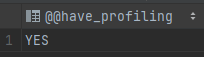
查看是否支持 profile
SELECT @@have_profiling;
查看打開狀態
SELECT @@profiling;
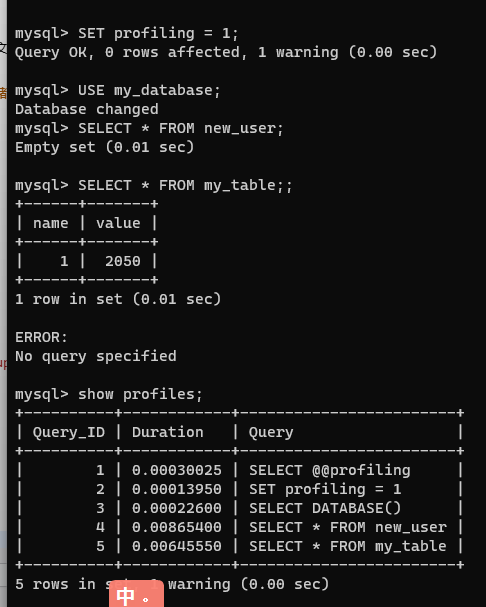
使用 SET 把這個變量改為 1 即可開啟,在執行語句后會記錄執行時間,通過命令可以查詢
SHOW PROFILES ;
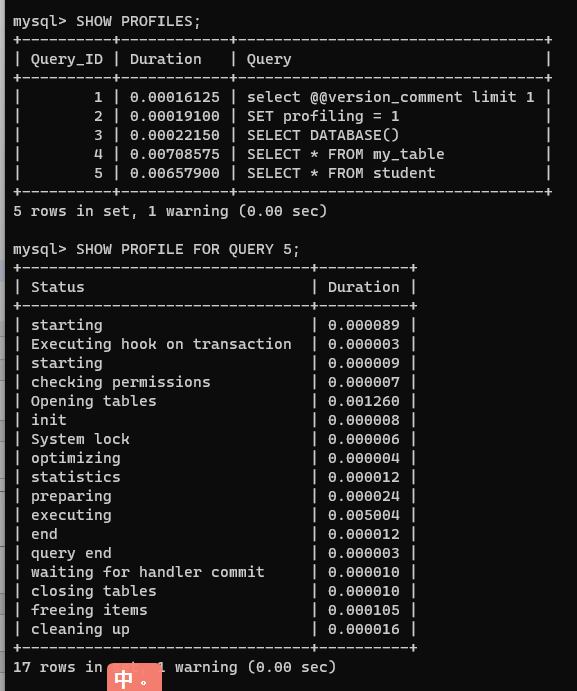
查看指定 query_id 的語句的詳細耗時
SHOW PROFILE FOR QUERY 查詢ID;
查看指定 query_id 的語句的 CPU 使用情況
SHOW PROFILE CPU FOR QUERY 查詢ID;
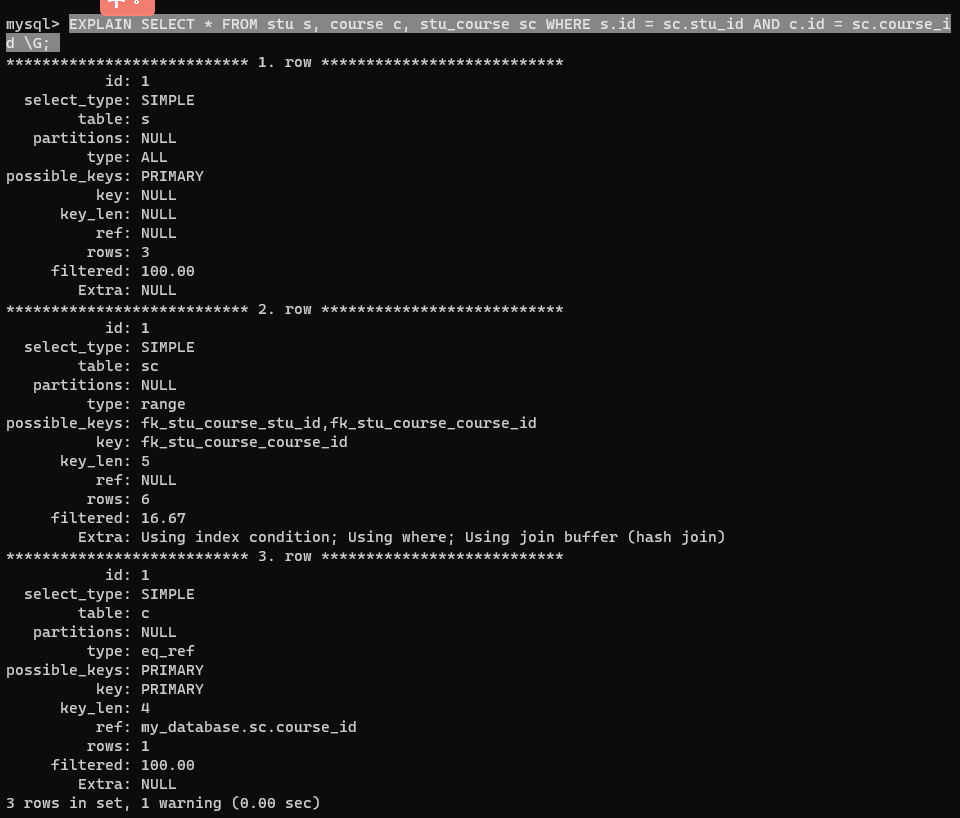
14.2.4 explain 執行計劃
在執行的語句前面加上 EXPLAIN 或 DESC,查詢項含義:
- id:表查詢的序列號,相同則從上往下,越大的越先執行
- select_type:查詢類型,常見的有 SIMPLE(簡單表,不使用表連接或子查詢)、PRIMARY(主查詢,即外層的查詢)、UNION(UNION 中的第二個或者后面的查詢語句)、SUBQUERY(包含子查詢)等
- type:連接類型,性能從低到高:NULL、system、const、eq_ref、ref、range、index、all
- possible_key:表中可能用到的索引。
- key:實際使用的索引
- key_len:索引字段的最大可能長度
- rows:必須要執行查詢的行數,在 InnoDB 中是一個估計值
- filltered:結果返回的行數占需要讀取行數的百分比,越大越好。
采用這里的三張表來演示:https://blog.iyatt.com/?p=12631#1113_%E5%A4%9A%E5%AF%B9%E5%A4%9A
內連接
EXPLAIN SELECT * FROM stu s, course c, stu_course sc WHERE s.id = sc.stu_id AND c.id = sc.course_id \G;
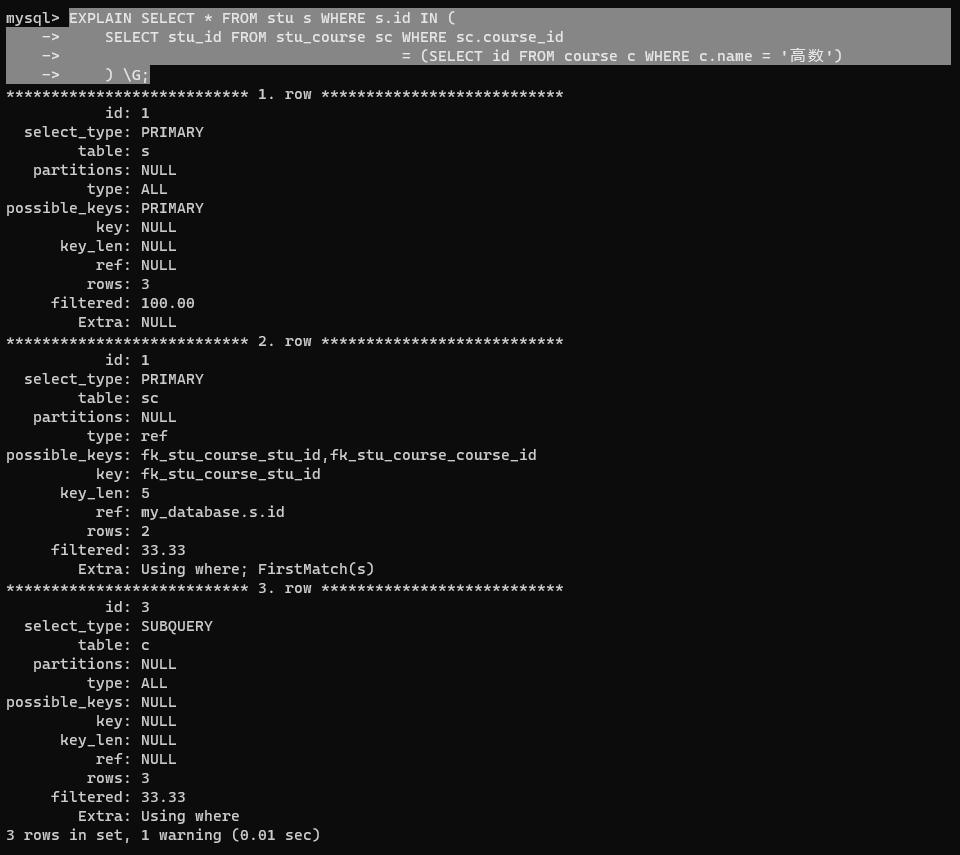
子查詢
EXPLAIN SELECT * FROM stu s WHERE s.id IN (SELECT stu_id FROM stu_course sc WHERE sc.course_id= (SELECT id FROM course c WHERE c.name = '高數')) \G;
14.3 使用
14.3.1 索引有效條件 - 最左前綴法則
如果索引了多列(聯合索引),要遵循最左前綴法則。
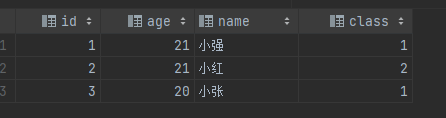
創建一張表
CREATE TABLE info (id tinyint,age tinyint,name char(2),class int
);
插入數據
INSERT INTO info VALUES(1, 21, '小強', 1),(2, 21, '小紅', 2),(3, 20, '小張', 1);
創建聯合索引(后續提到的左右都是基于創建索引時指定的列順序)
CREATE INDEX index_info ON info(age, name, class);
獲取每個列的 key_len
age name class 分別為 2 9 5
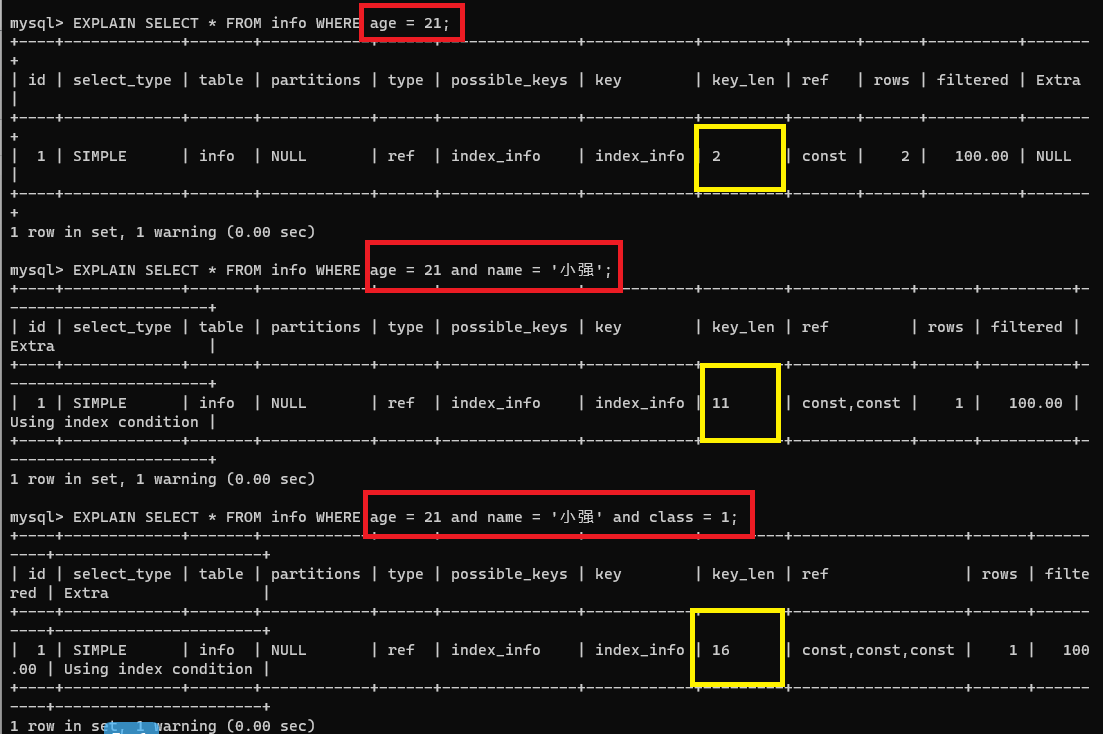
同時指定三列查詢
EXPLAIN SELECT * FROM info WHERE age = 21 and name = '小強' and class = 1;
使用了全部索引
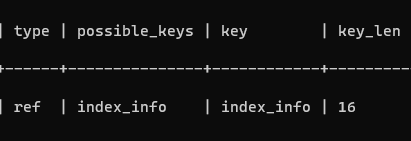
指定最左列和最右列查詢
EXPLAIN SELECT * FROM info WHERE age = 21 and class = 1;
key_len 為 2,只有最左列 age 使用索引
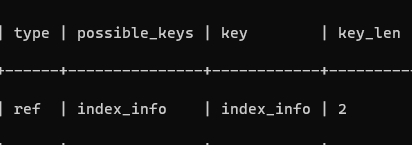
不指定最左側列
EXPLAIN SELECT * FROM info WHERE name = '小強' and class = 1;
沒有使用索引
age 列指定范圍
EXPLAIN SELECT * FROM info WHERE age > 20 and name = '小強' and class = 1;
key_len 為 2,從 age 列右側下一列開始沒有使用索引
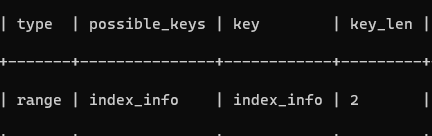
打亂順序
EXPLAIN SELECT * FROM info WHERE class = 1 and name = '小強' and age = 21;
順序不影響索引使用
即聯合索引必須包含最左列才會使用索引,且中間如果有留空,則從留空列開始不使用索引
14.3.2 索引失效情況 1 - 索引列運算
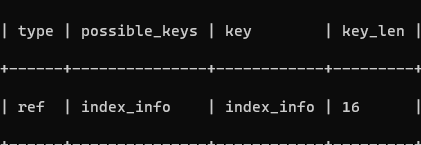
用上面的表演示,在這個表中查詢年齡為 21,名字第二個字為“強”的
EXPLAIN SELECT * FROM info WHERE age = 21 and substring(name, 2, 1) = '強';
key_len 為 2,即 name 字段索引失效了

14.3.3 索引失效情況 2 - 范圍索引
上面最左前綴法則中,age 指定范圍演示過。從范圍索引的右側列開始索引失效。
14.3.4 索引失效情況 3 - 模糊查詢
第一個字采用模糊匹配
EXPLAIN SELECT * FROM info WHERE age = 21 AND name LIKE '_強';
key_len 為 2,name 索引失效

非第一個字模糊匹配
EXPLAIN SELECT * FROM info WHERE age = 21 AND name LIKE '小_';
索引正常工作

第一個字符模糊查詢會導致索引失效,非第一個字符模糊查詢索引正常工作。
14.3.5 索引失效情況 4 - OR 連接的條件
OR 連接的條件,一個有索引,一個沒有索引,那么此時兩者都不會使用索引。
這里的 age 有索引,id 沒有索引
EXPLAIN SELECT * FROM info WHERE age = 21 OR id = 1;
結果都沒有使用索引

14.3.6 索引失效情況 5 - 數據分布影響(優化)
當使用索引可能更慢的時候,MySQL 會決定不使用索引。
創建一張表用于演示
CREATE TABLE info1 (id int,name char(2)
);INSERT INTO info1 (id, name) VALUES(1, '張三'),(2, '李四'),(3, '王五'),(4, '趙六'),(5, '孫七'),(6, '周八'),(7, '吳九'),(8, '鄭十'),(9, '陳一'),(10, '林二'),(11, '羅三'),(12, '何四'),(13, '高五'),(14, '馬六'),(15, '劉七'),(16, '梁八'),(17, '黃九'),(18, '曾十'),(19, '彭一'),(20, '胡二'),(21, '許三'),(22, '沈四'),(23, '韓五'),(24, '楊六'),(25, '朱七'),(26, '秦八'),(27, '尤九'),(28, '許十'),(29, '薛一'),(30, '侯二'),(31, '夏三'),(32, '邱四'),(33, '方五'),(34, '石六'),(35, '姚七'),(36, '譚八'),(37, '廖九'),(38, '范十'),(39, '汪一'),(40, '陸二'),(41, '金三'),(42, '魏四'),(43, '陶五'),(44, '戴六'),(45, '郭七'),(46, '洪八'),(47, '鄒九'),(48, '江十'),(49, '章一'),(50, '董二');CREATE INDEX index_info1 ON info1(id);
查詢 id > 10 的數據
EXPLAIN SELECT * FROM info1 WHERE id > 10;
沒有使用索引

查詢 id > 30 的數據
EXPLAIN SELECT * FROM info1 WHERE id > 30;
使用了索引

當查詢的數據是表中的少部分的時候,MySQL 會使用索引,這樣速度更快,但是查詢的是表中的大部分數據的時候,可能不如直接暴力遍歷的速度。
14.3.7 索引提示
當一個列存在多個索引時,可以指定使用某個索引。
這里示例還是使用上面創建的 info 表
為 age 列再創建一個單列索引
CREATE INDEX index_age ON info(age);
此時 age 同時具有前面的聯合索引,又有了一個單列索引
EXPLAIN SELECT * FROM info WHERE age = 21;
可能用到的索引有兩個,實際用的是聯合索引

指定使用 index_age 索引(單列)- 建議 MySQL 使用,MySQL 通過一定算法判斷是否使用
USE INDEX (索引名)
EXPLAIN SELECT * FROM info USE INDEX (index_age) WHERE age = 21;

忽略索引 index_info(聯合)
IGNORE INDEX (索引名)
EXPLAIN SELECT * FROM info IGNORE INDEX (index_info) WHERE age = 21;

強制使用索引 index_age(單列)
FORCE INDEX (索引名)
EXPLAIN SELECT * FROM info FORCE INDEX (index_age) WHERE age = 21;
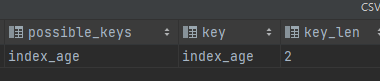
14.3.8 覆蓋索引
查詢的列數據都包含在索引中
使用上面的 info 表,刪掉創建的索引,只保留原先的聯合索引
當查詢項都在索引中時
EXPLAIN SELECT age, name, class FROM info WHERE age = 21 AND name = '小強' AND class = 1;
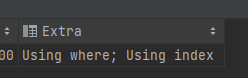
當查詢項多了一個 id(不在索引中)
EXPLAIN SELECT id, age, name, class FROM info WHERE age = 21 AND name = '小強' AND class = 1;
或者查 *
EXPLAIN SELECT * FROM info WHERE age = 21 AND name = '小強' AND class = 1;
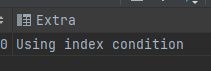
- Using index condition:表示使用了索引條件下推(Index Condition Pushdown,ICP)的優化,即在存儲引擎層對索引進行過濾,減少回表查詢的次數。
- Using where:表示在服務器層對數據進行過濾,通常是因為索引不能完全滿足查詢條件,或者沒有使用索引。
- Using index:表示使用了覆蓋索引(Covering Index)的優化,即索引已經包含了所需的所有列,無需訪問數據表
14.3.9 前綴索引
當字段類型為字符串時,有時候需要索引很長的字符串,但是這樣會讓索引變得很大,查詢的時候磁盤 IO 占用會非常高,影響查詢效率。因此可以只將字符串的一部分前綴建立索引,這樣可以提高索引效率。
CREATE INDEX 索引名 ON 表名(列名(前n個字符))
至于這前n個字符具體取多少個,可以參考“索引的選擇性”。比如某列的字段內容較長,考慮建立前綴索引,所在的表中有100行數據,如果每行的該字段都只取前 10 個字符,結果這 100 行都沒有重復,那么選擇性 = 沒有重復的行數 100 / 總行數 100 = 1。然后又嘗試往前推進看看,該字段取前 9 個字符,結果有 10 行和已經存在的重復,那么選擇性= 去除重復的行數 (100-10) / 總行數 100 = 0.9。前一種前綴取 10,每行都是獨一無二的,這種情況下索引速度必然好,后一種情況前綴取 9,但是只有 0.9 的比例為非重復,會影響一定效率(遇到重復等于索引失效,要回表查詢),但是索引能節省一個字符的空間。索引的選擇性就是一種作為參考的參數,來輔助選擇前綴大小,綜合前綴長度減小又能保證較好的選擇性數值。
下面是一個示例表,創建它
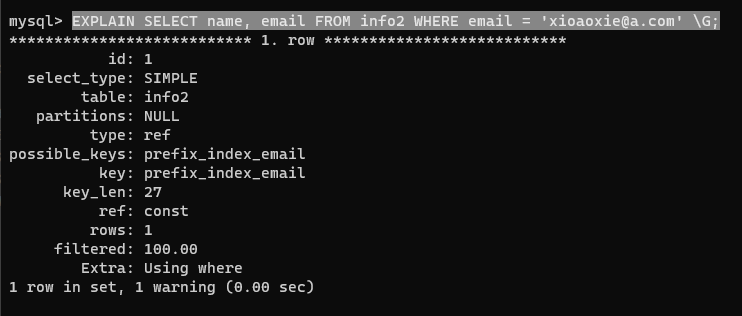
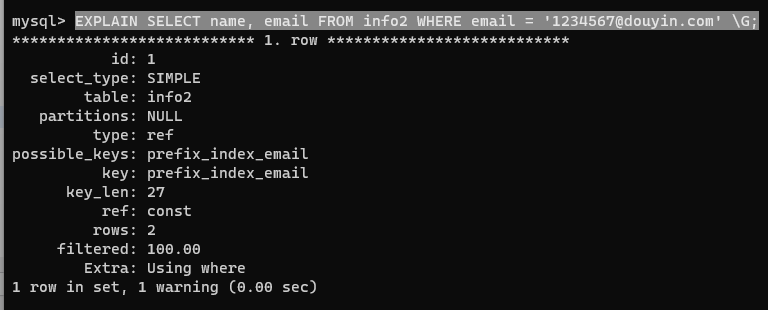
CREATE TABLE info2 (name char(2),email varchar(32)
);INSERT INTO info2 VALUES('小強', '123456789@qq.com'),('小王', '123459875@foxmail.com'),('小李', 'xiaoli@baidu.com'),('小紅', '1234567@douyin.com'),('小張', '123986@360.com'),('小謝', 'xioaoxie@a.com'),('小陳', 'xiaochen@b.cn'),('小楊', 'xiaoyang@c.cpn'),('小趙', 'xiaozhao@d.com'),('小唐', '1234587@t.com');
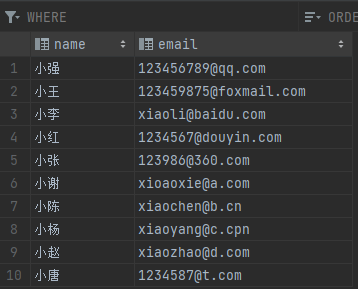
SELECT count(DISTINCT substring(email, 1, 前綴長度)) / count(*) FROM info2;
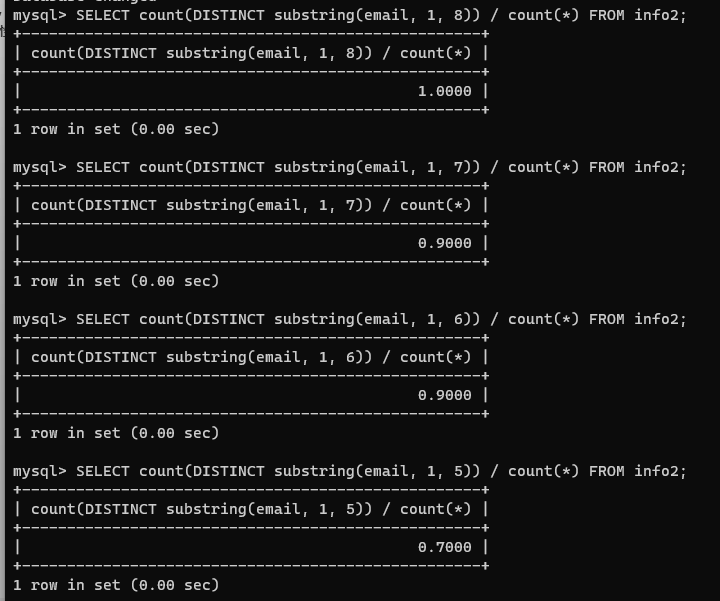
前綴取 8 的時候選擇性為 1,前綴取到 7、6 都是 0.9,取到 5 就只有 0.7 了,那我就取 6
CREATE INDEX prefix_index_email ON info2(email(6));
查看索引時,其中 Sub_part 字段為 6,非前綴索引這個值就是 NULL
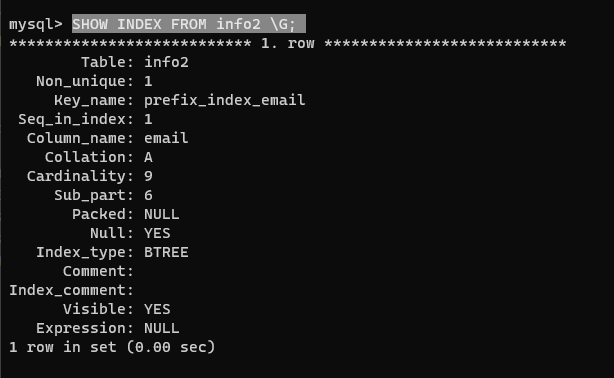
第一個 rows 為 1,第二個為 2。因為第一個在前綴索引取 6 時沒有重復的索引,而后一個索引有重復的,那么就需要回到數據表中去確認是否重復,也就還需要額外查一次。
15 其它優化
15.1 插入優化
- 多條數據,INSERT 最好一次性插入多條數據,而不是每次一條。
- 當數據量過于太大時,也不要一次性插入,可以一次性插入 500-1000 條
- 連續執行 INSERT 時最好顯式開啟事務,執行完所有插入后一次性提交
15.1.1 從文件導入數據
這里寫了一個 Python 腳本用來生成 csv 數據
import randomdef write_to_file(filename, delimiter, newline, rows):with open(filename, 'w', encoding='utf-8') as f:for i in range(rows):id = i + 1line = str(id) + delimiter + ''.join(random.sample('abcdefghijklmnopqrstuvwxyz', 12)) + delimiter + str(random.randint(0,1)) + delimiter + str(random.randint(0, 100))f.write(line + newline)# 生成文件名 test.csv
# 分隔符為英文逗號
# 換行符為 \r
# 數據行數 1000000
write_to_file('test.csv', ',', '\r', 1000000)
這里連接數據庫的命令要加上額外參數
mysql --local-infile -u root -p
啟用文件導入
SET GLOBAL local_infile = 1;
然后創建一張和數據列匹配的表,比如匹配這里的例子的表
CREATE TABLE person (id int PRIMARY KEY COMMENT '唯一標識',name char(12) COMMENT '名字',gender tinyint COMMENT '性別',age tinyint COMMENT '年齡'
);
導入文件
LOAD DATA LOCAL INFILE 文件路徑 INTO TABLE 表名 FIELDS TERMINATED BY 分隔符 LINES TERMINATED BY 換行符;
導入一百萬行數據用了 22.96s

15.2 主鍵優化
- 插入的數據會按照主鍵順序儲存,最好是按照主鍵順序插入,這樣每次插入都是接著前一個的后面順序插入,亂序插入時需要移動數據來保持主鍵順序影響效率(頁分裂)。創建表的時候最好使用自增主鍵,業務操作的時候盡量不要修改主鍵。
- 盡量降低主鍵的長度
15.3 排序優化
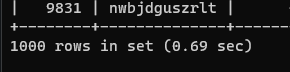
使用前面的 100 萬行數據的例子,按照年齡排序,并輸出前 1000 行
SELECT * FROM person ORDER BY age LIMIT 1000;
用時 0.69s
再為年齡創建一個索引(因為數據量大,創建過程可能比較耗時)

再次按年齡排序查詢,耗時可以忽略不記
15.4 分組優化
上面創建了 age 的索引,現在根據 age 分類統計每個年齡的人數
SELECT age, COUNT(*) FROM person GROUP BY age;
然后刪掉 age 的索引,再次執行,耗時差不多翻倍

16 視圖
現有數據庫中的表查詢結果創建出一張新的表(虛擬表),這張新的表就是視圖,視圖可以看作是一個快捷方式,創建的時候給指定語句整體起個別名,后續使用別名查詢就是在創建語句的基礎上操作,創建視圖并不額外存儲表,都是重新執行語句去查詢。
16.1 基本使用
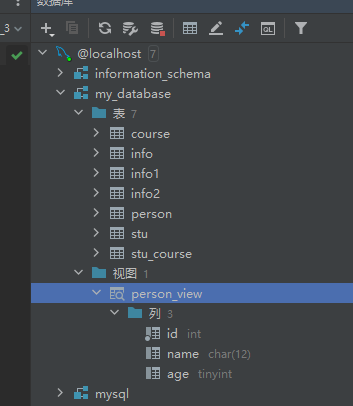
創建視圖
CREATE VIEW 視圖名 AS SELECT語句;

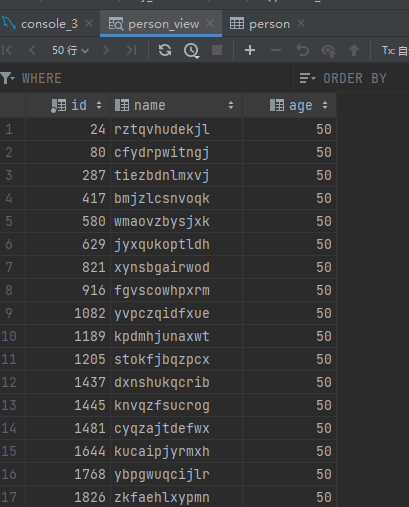
查詢創建語句
SHOW CREATE VIEW 視圖名;
查詢視圖
SELECT * FROM 視圖名;
修改視圖方式一
CREATE OR REPLACE VIEW 視圖名 AS SELECT語句;
修改視圖方式二
ALTER VIEW 視圖名 AS SELECT語句;
刪除視圖
DROP VIEW 視圖名;
16.2 檢查選項
創建視圖的時候在后面加上檢查選項,當查詢語句存在一定的 WHERE 條件,而嘗試對視圖插入的數據不滿足 WHERE 條件時會阻止插入。
CREATE VIEW 視圖名 AS SELECT語句 WITH [ CASCADED | LOCAL ] CHECK OPTION ;
不指定 CASCADED 或 LOCAL,默認就是 CASCADED。基于表創建視圖的時候,兩個沒有區別,都會對當前視圖的創建語句的 WHERE 條件檢查。區別在于基于視圖創建視圖的時候,LOCAL 只檢查當前視圖的創建語句,而對于它的所有上級視圖的條件不管,而 CASCADED 則是對所有的上級視圖起作用。
創建一張表進行測試
CREATE TABLE test (id int PRIMARY KEY AUTO_INCREMENT,num int
);
LOCAL 測試,創建四個視圖
CREATE OR REPLACE VIEW test_view1 AS SELECT * FROM test;
CREATE OR REPLACE VIEW test_view2 AS SELECT * FROM test_view1 WHERE num > 0 WITH LOCAL CHECK OPTION ;
CREATE OR REPLACE VIEW test_view3 AS SELECT * FROM test_view2 WHERE num > 5;
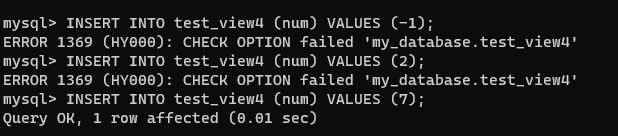
CREATE OR REPLACE VIEW test_view4 AS SELECT * FROM test_view3 WHERE num < 10 WITH LOCAL CHECK OPTION ;
插入 -1 不滿足 test_view2 的條件

插入 2 成功,滿足 test_view2 和 test_view4 的條件,雖然不滿足 test_view3 的條件,但是 test_view3 沒有檢查選項不受影響

CASCADED 測試,重新創建視圖
CREATE OR REPLACE VIEW test_view1 AS SELECT * FROM test;
CREATE OR REPLACE VIEW test_view2 AS SELECT * FROM test_view1 WHERE num > 0;
CREATE OR REPLACE VIEW test_view3 AS SELECT * FROM test_view2 WHERE num > 5;
CREATE OR REPLACE VIEW test_view4 AS SELECT * FROM test_view3 WHERE num < 10 WITH CASCADED CHECK OPTION ;
再次嘗試插入 -1 和 2 都失敗了,此時 test_view4 的檢查條件為 CASCADED,雖然往上都沒有檢查選項,但是 CASCADED 往上遞歸,全都會檢查,插入 7 的時候成功了,它滿足所有視圖的條件。
17 存儲過程
“儲存過程”的作用有點像一般編程語言里的函數,把一堆功能語句封裝起來調用。
17.1 語句分隔符修改
MySQL 默認的語句分隔符是英文分號 ;
在 MySQL 客戶端中創建存儲過程時,還是用分號作為分隔符的話會導致無法正常識別語句,所以需要修改(只在當前會話生效)
DELIMITER 新的分隔符
17.2 基本使用
創建存儲過程
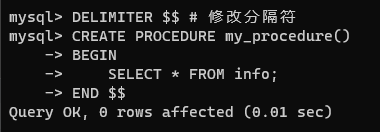
DELIMITER $$ # 修改分隔符
CREATE PROCEDURE 存儲過程名字()
BEGIN執行的操作
END $$
DELIMITER ; # 切換回分號
調用自定義的存儲過程
CALL 存儲過程名字();
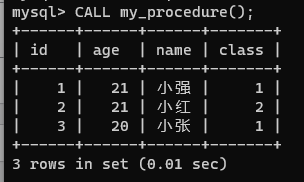
查看存儲過程定義
SHOW CREATE PROCEDURE 存儲過程名字;
刪除存儲過程
DROP PROCEDURE 存儲過程名字;

17.3 變量
17.3.1 系統變量
由 MySQL 定義的具有特殊含義的變量,有全局 GLOBAL 和 SESSION 兩類,前者針對整個數據庫系統生效,后者只對當前客戶端連接生效,不指定默認為 SESSION。
查看系統變量
SHOW [SESSION | GLOBAL] VARIABLES; # 查看全部SHOW [SESSION | GLOBAL] VARIABLES LIKE '關鍵詞'; # 模糊匹配SELECT @@[SESSION | GLOBAL] 變量名; # 查看指定的
設置系統變量
SET [SESSION | GLOBAL] 變量名 = 值;
SET @@[SESSION | GLOBAL] 變量名 = 值;
17.3.2 用戶自定義變量
用戶自定義變量沒有全局變量,只能在當前客戶端連接生效,系統變量是兩個@,用戶自定義變量則只有一個@。
賦值
SET @變量名 = 值;SET @變量名 := 值;SELECT @變量名 := 表達式;SELECT 字段名 INTO @變量名 FROM 表名; # 將表中的字段值賦值給變量
查看值
SELECT @變量名;
17.3.3 局部變量
可以在儲存過程中使用,作用范圍介于 BEGIN 和 END 之間。
定義局部變量,賦值操作同上
DECLARE 變量名 變量類型 [DEFAULT ...];
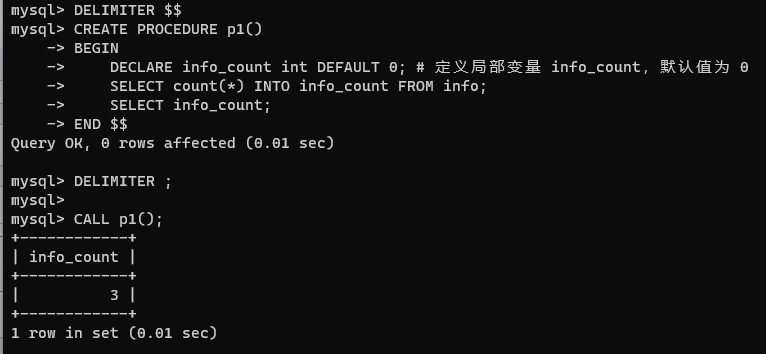
演示
DELIMITER $$
CREATE PROCEDURE p1()
BEGINDECLARE info_count int DEFAULT 0; # 定義局部變量 info_count,默認值為 0SELECT count(*) INTO info_count FROM info;SELECT info_count;
END $$
DELIMITER ;CALL p1();
17.3.4 存儲過程的參數傳遞
類似于一般變成語言中函數傳入參數和返回值。
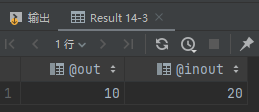
這里給出一個例子,創建一個存儲過程 p2,有三個參數,分別是傳入參數 in_arg,傳出參數 out_arg,傳入傳出參數 inout_arg
DELIMITER $$
CREATE PROCEDURE p2(IN in_arg int,OUT out_arg int,INOUT inout_arg int)
BEGINSET out_arg := in_arg + inout_arg;SET inout_arg := 2 * out_arg;
END $$
DELIMITER ;
調用存儲過程
SET @inout = 3;
CALL p2(7, @out, @inout);
SELECT @out, @inout;
17.4 條件判斷
17.4.1 IF
IF 條件1 THEN
...
ELSEIF 條件2 THEN
...
ELSE
...
END IF;
示例
DELIMITER $$
CREATE PROCEDURE p3(score float)
BEGINIF score > 90 THENSELECT '優秀';ELSEIF score > 75 THENSELECT '良好';ELSEIF score > 60 THENSELECT '及格';ELSESELECT '不及格';END IF;
END $$
DELIMITER ;CALL p3(85);
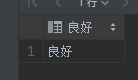
17.4.2 CASE
兩種語法參考流程函數部分:https://blog.iyatt.com/?p=12631#94_%E6%B5%81%E7%A8%8B%E5%87%BD%E6%95%B0
例一
DELIMITER $$
CREATE PROCEDURE p4(score float)
BEGINCASEWHEN score > 90 THENSELECT '優秀';WHEN score > 75 THENSELECT '良好';WHEN score > 60 THENSELECT '及格';ELSESELECT '不及格';END CASE;
END $$
DELIMITER ;CALL p4(59);
例二
DELIMITER $$
CREATE PROCEDURE p5(grades char(1))
BEGINCASE gradesWHEN 'A' THENSELECT '優秀';WHEN 'B' THENSELECT '良好';WHEN 'C' THENSELECT '一般';ELSESELECT '未知';END CASE;
END $$
DELIMITER ;CALL p5('C');
17.5 循環
17.5.1 WHILE
WHILE 條件 DO...
END WHILE
示例
累加 1-100
DELIMITER $$
CREATE PROCEDURE p6(n int)
BEGINDECLARE sum int DEFAULT 0;DECLARE counter int DEFAULT 0;WHILE counter < n DOSET counter := counter + 1;SET sum := sum + counter;END WHILE;SELECT sum;
END $$
DELIMITER ;CALL p6(100);
17.5.2 REPEAT
WHILE 是滿足條件執行循環,REPEAT 是滿足條件退出循環
REPEAT...UNTIL 條件
END REPEAT;
示例
DELIMITER $$
CREATE PROCEDURE p7(n int)
BEGINDECLARE sum int DEFAULT 0;REPEATSET sum := sum + n;SET n := n - 1;UNTIL n = 0END REPEAT;SELECT sum;
END $$
DELIMITER ;CALL p7(100);
17.5.3 LOOP
LOOP 循環本身不帶退出條件判斷,是可以實現無限循環的,通過自行調用 LEAVE 退出循環,或者調用 ITERATE 跳過本輪循環,像一般編程語言里的 break 和 continue。
自定義循環標簽名: LOOPEND LOPP 標簽名;
示例
累加 1-100 的偶數
DELIMITER $$
CREATE PROCEDURE p8(n int)
BEGINDECLARE sum int DEFAULT 0;my_sum: LOOPIF n <= 0 THENLEAVE my_sum; # 退出循環END IF ;IF n % 2 = 1 THENSET n := n -1;ITERATE my_sum; # 跳過本輪循環END IF ;SET sum := sum + n;SET n := n - 1;END LOOP my_sum;SELECT sum;
END $$
DELIMITER ;CALL p8(100);
17.6 游標和條件處理程序
游標的作用和一般編程語言里面的迭代器類似。
聲明
DECLARE 游標名稱 CURSOR FOR 查詢語句;
打開
OPEN 游標名稱;
獲取游標記錄
FETCH 游標名稱 INTO 變量;
關閉游標
CLOSE 游標名稱;
條件處理程序
這個有點像 Linux 捕獲信號
DECLARE hander_action HANDLER FOR condition_value statement;
hander_action:
- CONTINUE 繼續執行當前程序
- EXIT 終止執行當前程序
condition_value:
- SQLSTATE sqlstate_value 狀態碼,如 02000
- SQLWARNING 所有以 01 開頭的 SQLSTATE 的簡寫
- NOT FOUND 所有以 02 開頭的 SQLSTATE 的簡寫
- SQLEXCEPTIO 所有沒有被 SQLWARNING 或 NOT FOUND 捕獲的 SQLSTATE 的簡寫
示例
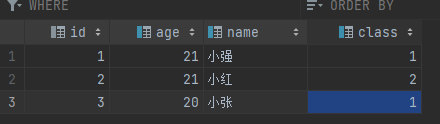
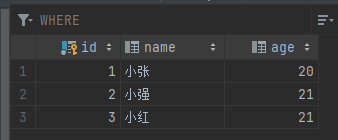
查詢 info 表的 name 列和 age 列,并將它們存到另外一張表 temp_table 中
DELIMITER $$
CREATE PROCEDURE p9()
BEGINDECLARE name1 char(2);DECLARE age1 tinyint;DECLARE my_cursor CURSOR FOR SELECT name, age FROM info; # 聲明一個遍歷 info 表 name、age 列的游標DECLARE EXIT HANDLER FOR SQLSTATE '02000' CLOSE my_cursor; # 沒有這個條件處理程序,當 FETCH 遍歷到沒有數據的位置會報錯 02000,所以這里捕獲這個狀態碼,來主動執行退出OPEN my_cursor; # 打開游標# 臨時表DROP TABLE IF EXISTS temp_table;CREATE TABLE temp_table (id tinyint PRIMARY KEY AUTO_INCREMENT,name char(2),age tinyint);WHILE TRUE DOFETCH my_cursor INTO name1, age1; # 從游標中取值INSERT INTO temp_table (name, age) VALUES (name1, age1); # 將取值插入新表中END WHILE ;CLOSE my_cursor; # 關閉游標END $$
DELIMITER ;CALL p9();
info 表
新建的表


)




)


【python源碼+UI界面+功能源碼詳解】)

動畫的基礎了解(感覺不了解其實也行))






)