目錄
前言
一、業務背景
二、數據中臺1.0—Lambda
三、新架構的設計目標
四、數據中臺2.0—Apache?Doris
4.1?新架構數據流轉
4.2?新架構收益
五、新架構的落地實踐
5.1?模型選擇
5.1.1?Unique模型
5.1.2?Aggregate模型
5.2?資源管理
5.3??批量建表
5.4?計算實現
5.4.1?實時計算
5.4.2?準實時計算?
通過 Java UDF 生成增量/全量數據
基于 Doris的大表優化
Doris Borker的協同計算
聯邦查詢在數據分析場景下的嘗試
六、運維保障
6.1?守護進程
6.2?Grafana 監控報警
七、總結收益
八、未來規劃
? 原文大佬的這篇Doris數倉建設案例有借鑒意義,這里摘抄下來用作學習和知識沉淀。
前言
? ? ?拈花云科NearFar X Lab 團隊調研并引進 Doris作為新架構下的數據倉庫選型方案。本文主要介紹了拈花云科數據中臺架構從 1.0 到 2.0 的演變過程,以及Doris在交付型項目和 SaaS 產品中的應用實踐。
一、業務背景
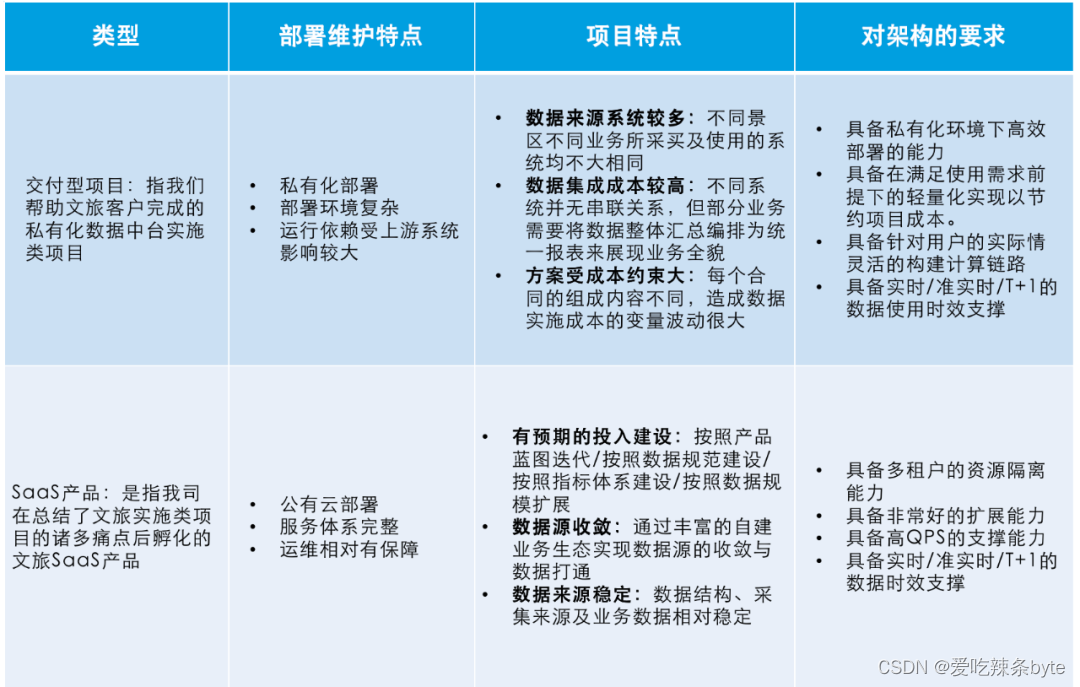
? ?拈花云科的服務對象主要是國內各個景區、景點,業務范圍涵蓋文旅行業的多個板塊,如票務、交通、零售、住宿、餐飲、影院、KTV、租賃等。多業務線下用戶對于數據使用的時效性需求差異較大,需要我們能夠提供實時、準實時、T+1的業務支撐能力。同時由于大部分景區為國有化的特點,也需要具備能夠提供私有化交付部署及SaaS 化數據中臺產品解決方案的雙重服務支撐能力。
二、數據中臺1.0—Lambda
?早期構建數據中臺時,為了優先滿足B端用戶數據整合的需求,以穩定數據輸出為出發點,因此我們基于行業中比較成熟的Lambda架構形成了數據中臺 1.0 。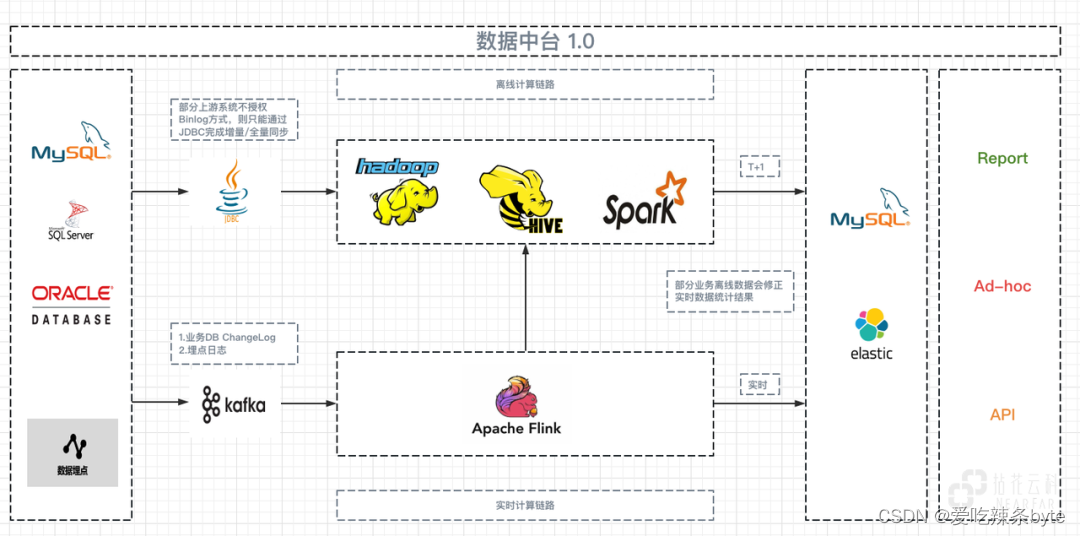
? 在數據中臺1.0架構中分為三層,分別為Batch Layer,Speed Layer 和 Serving Layer。其中,Batch Layer用于批量處理全部的數據,Speed Layer用于處理增量的數據,在Serving Layer中綜合Batch Layer生成的Batch Views 和 Speed Layer 生成的Realtime Views,提供給用戶查詢最終的結果。

? Batch Layer:在我們早期的實施類項目中,單純以離線T+1進行數據支持的項目占了絕大多數,但實施類項目在實現 Lambda 架構的過程中也會面臨很多問題。例如:由于項目本身的原因,業務系統不能開放DB 的Binlog 供數據倉庫采集,因此只能以JDBC的方式完成增量或全量的數據同步,而通過該方式同步的數據,往往會由于源端系統人工補充數據、時間戳不規范等問題產生同步數據差異的情況發生,最終只能通過額外的數據對比邏輯進行校驗,以保證其數據的一致性。
? Speed Layer:項目受成本約束較大,大面積基于流的實時計算對于不論是從硬件成本、部署成本還是實施成本,維護成本等角度均難以支撐。基于該原因,在實施類項目中只有部分業務會進行基于流的實時統計計算,同時滿足流計算條件的業務上游系統也同時滿足同步Binlog 的使用需求。
? Serving Layer:大部分的預計算結果存儲在MySQL 中提供 Report 支持,部分實時場景通過Merge Query 對外提供Ad-Hoc(數據探索)的查詢支持。
? ?隨著時間的推移,大量的項目交付使用增多,架構的問題也逐漸開始顯現:
- 開發和維度成本高:該架構需要維護兩套代碼,即批處理和實時處理的代碼,這無疑增加了開發和維護的成本。
- 數據處理復雜度高:Lambda 架構需要處理多個層次的數據,包括原始數據、批處理數據和實時數據,需要對不同的數據進行清洗、轉換和合并,數據處理的復雜度較高。
- 實時計算支持有限:業務方對于數據時效性要求越來越高,但是該架構能力有限,無法支持更多、更高要求的的實時計算。
-
資源利用率低:離線資源較多,但我們僅在凌晨后的調度時間范圍內使用,資源利用率不高。
- 受成本制約:該架構對于部分用戶而言使用成本較高,難以起到降低成本提高效率的作用。
三、新架構的設計目標
? ?基于以上架構問題,我們希望實現一套更加靈活的架構方案,同時希望新的架構可以滿足日益增高的數據時效性要求。在新方案實現之前,我們先對當前的業務應用場景和項目類型進行分析。
? 我們業務應用場景分為以下四類,這四類場景的特點和需求分別是:
- 看板類Reporting:包括?Web/移動端數據看板和大屏可視化,用于展示景區重要場所的數據,如業務播報(實時在園人數監控、車船調度管理等)、應急管理監控(客流密度監控、景區消防預警、景區能耗監控等)。其組成特點一般是業務匯總指標和監控指標報警,對數據時效性要求較高。
- 報表類:數據報表以圖表形式展示,主要服務于各業務部門的一線業務人員。會更多關注垂直業務的數據覆蓋程度,會有鉆取需求(也可能通過不同報表來體現不同數據粒度)。一般以景區的業務部門為單位構建報表欄目和分析主題,除財務結算類報表外,一般可接受 T+1 的報表時效。
- 分析類:自助分析基于較好的數據模型表(數據寬表)實現,對分析人員有一定的數據理解和操作需求,基于我們提供的BI分析平臺,業務人員可基于此數據范圍通過拖拽的方式組合出自己的數據結果,靈活度較高。該場景對數據時效性要求不高,更多關注業務數據沉淀和與往期歷史數據的對比分析,側重架構的OLAP能力。
- 服務類:一般對接三方系統,由數據中臺提供數據計算的結果。如畫像標簽等數據,通過數據接口控制權限,提供對外數據服務與其他業務系統集成,需要新架構能夠提供穩定的數據服務
? ? ?接著我們對項目類型的特點和需求也進行了分析,并確定新架構需要同時提供實施類項目和 SaaS 產品的數據中臺支撐能力:
四、數據中臺2.0—Apache?Doris
? ?結合以上需求,我i們計劃對原有架構進行升級,并對新架構的OLAP引擎進行選型。在對比了ClickHouse 等OLAP引擎后(社區有非常多的對比文章參考,這里不過多贅述)最終選擇了 Apache Doris 作為數據中臺 2.0 的基座。同時,在數據的同步、集成即計算環節,我們也構建了多套方案來適配以Doris 為核心的計算鏈路,以應對不同類型的實施類項目及SaaS產品需求。
? ?
? ? ? 數據中臺 2.0的核心思路是將Doris作為核心的數據倉庫,并將其作為實時數據同步中心,核心數據計算中心。數據集成環節將專注于數據同步,而計算交由Doris 完成或由 Doris 輔助計算引擎完成。同時,我們將在提供多種數據同步至Doris 的方案以應對不同的項目需求。在這個架構下,我們支持實現實時、準實時、T+1的計算場景支持,以滿足不同業務場景的需求。
4.1?新架構數據流轉
?1)數據同步集成:架構 2.0 有多種數據同步方式,我們主要借助Doris Unique Key模型完成數據的同步更新
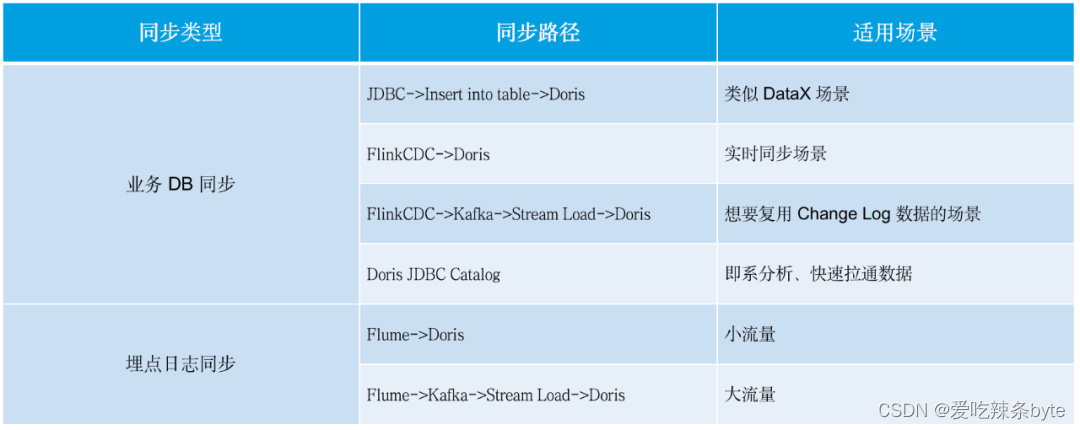
2)數據分層計算:根據項目資源情況分View/實體表單來構建后面的數據層級(DWD,DWS,ADS)。業務較輕或時效性很高的,通過View方式來實現邏輯層面的DWD,通過這種方式為下游Ad-hoc(數據探索)提供寬表查詢支持,Doris的謂詞下推及View優化的能力,為使用視圖查詢帶來了便利。而當業務較重時,通過實體表單+微批任務進行實現,按照調度依賴關系逐層完成計算,針對使用場景對表單進行優化。
3)數據計算時效:新架構下的數據時效受具體數據計算鏈路中三個方面限制,分別是數據采集時效、批次計算時效、數據查詢耗時。在不考慮網絡吞吐、消息積壓、資源搶占的情況下:
(實施類項目經常會遇到第三方不提供 Binlog 的情況,所以這里把通過批次采集數據也作為一個 case 列出來)
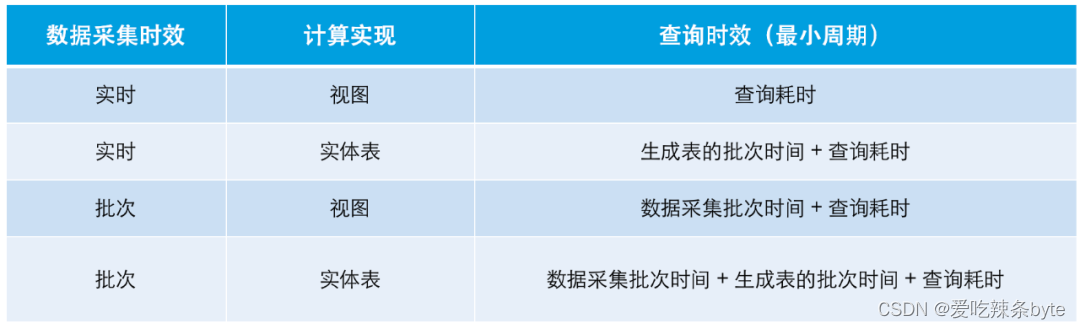
? ? 在Doris中為了達到更好的計算時效,基于Doris的數據計算流程相比在Hive中的計算流程可以進行一定的簡化,這樣可避免過多的冗余計算設計,以此提高計算產出效率。
4)補充架構能力:
??Hadoop:根據不同的項目資源及數據情況來決定是否引入Hadoop 補充大規模離線計算場景。以實施類項目為例,Doris可以涵蓋大部分核心業務數據計算場景。
? MySQL:基于預計算的結果數據可以推送到下游MySQL 中以供 Report 查詢,從而分散 Doris 計算查詢的資源消耗,這樣可以將資源充分留給核心且時效性要求高的應用或高頻批次任務。如果計算資源充足,Doris也可以直接作為應用層的加速查詢DB,而無須引入其它 DB。
4.2?新架構收益
? ? 通過引入Doris,我們成功構建了高時效、低成本的數據中臺2.0,并成功滿足了交付型項目和 SaaS 產品兩種需求場景下的使用需求。新架構的收益如下:
- 數據時效性提升:架構1.0中大部分業務為 T+1 的支持方式,而在新架構下大部分業務都可實現實時或小時級的計算支持
- 資源利用率提高:在架構1.0中,離線資源在白天大部分時間處于閑置狀態。而在新架構下,數據同步,計算(增量/全量)和查詢均在同一集群下完成,從而提高了資源利用率。相較于部署一套 CDH,同等資源成本下,部署一套Doris可以帶來更多的收益。
- 運維管理成本降低:在原有架構下,實時統計需求需要維護非常長的計算鏈路。而在新架構下,所有計算僅需在一個數據庫中完成,更加簡單、高效且易于維護。
- 易于業務擴展:Doris的節點擴展操作非常便捷,這對于業務的增量支持非常友好。
五、新架構的落地實踐
? ? 我們在2022年底首次在測試環境中部署了Doris 1.1.5 版本,并進行了一些業務數據的導入測試和新架構的可行性驗證。在測試后,我們決定在生產環境中落地實踐 Doris。目前,新項目已升級到 1.2.4 版本并使用。Apache Doris 作為新架構下的核心系統,在整個架構中發揮著重要的作用。下面從模型選擇、資源規劃、表架構同步、計算場景實現、運維保障等幾個角度分享基于 Doris 的項目落地經驗。
5.1?模型選擇
5.1.1?Unique模型
? 對于ODS層的表單來說,我們需要Doris?Table與源系統數據保持實時同步。為了保證數據同步的一致性,我們采用了Unique 模型,該模型會根據主鍵來對數據進行合并。在1.2.0 版本推出之后,采用了新的 Merge On Write的數據更新方式,在 Unique Key 寫入過程中,Doris會對新寫入的數據和存量數據進行Merge操作,從而大幅優化查詢性能。因此在使用 1.2 版本中,建議打開 Doris BE 的 Page Cache(在be.conf文件中增加配置項disable_storage_page_cache = false)。另外在很多情況洗,Unique 模型支持多種謂詞的下推,這樣表單也可以支持從源表直接建立視圖的查詢方式。
5.1.2?Aggregate模型
? ? 在某些場景下(如維度列和指標列固定的報表查詢),用戶只關心最終按維度聚合后的結果,而不需要明細數據的信息。針對這種情況,建議使用Aggregate 模型來創建表,該模型以維度列作為 Aggregate Key 建表。在導入數據時,Key列相同的行會聚合成一行(目前Doris支持 SUM、REPLACE、MIN、MAX 四種聚合方式)
???Doris 會在三個階段對數據進行聚合:
- 數據導入的ETL階段,在每一批次導入的數據內部進行聚合;
- 底層BE進行數據Compaction合并階段;
-
數據查詢階段
? ? ?聚合完成之后,Doris 最終只會存儲聚合后的數據,這種明細表單數據的預聚合處理大大減少了需要存儲和管理的數據量。當新的明細數據導入時,它們會和表單中存儲的聚合后的數據再進行聚合,以提供實時更新的聚合結果供用戶查詢。
5.2?資源管理
? ? 在生產環境中,我們使用一套 Doris 數據倉庫支撐了多個下游數據應用系統的使用。這些應用系統對數據訪問的資源消耗能力不同,對應的業務重要等級也不相同。為了能夠更好管理應用資源的使用,避免資源沖突,我們需要對應用賬號進行劃分和資源規劃,以保證多用戶在同一 Doris 集群內進行數據操作時減少相互干擾。而Doris的多租戶和資源隔離功能,可以幫助我們更合理地分配集群資源。Doris 對于資源隔離控制有兩種方式,一是集群內節點級別的資源組劃分,二是針對單個查詢的資源限制。這里主要介紹下方式一的集群內節點級別的資源組劃分過程。
1)第一步:需要梳理規劃各場景的用途、重要等級及資源需求等,舉例說明:
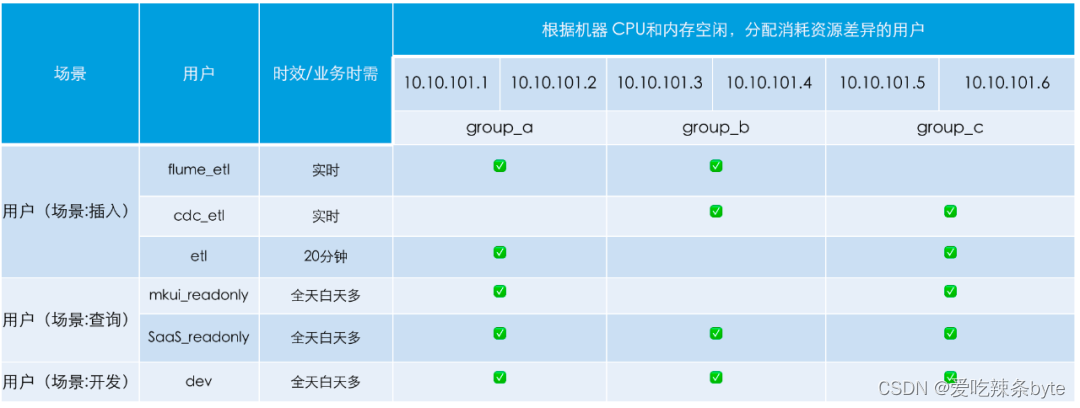
2)第二步:對節點資源進行劃分、給節點打上 tag 標簽:
alter system modify backend "10.10.101.1:9050" set ("tag.location" = "group_a");
alter system modify backend "10.10.101.2:9050" set ("tag.location" = "group_a");
alter system modify backend "10.10.101.3:9050" set ("tag.location" = "group_b");
alter system modify backend "10.10.101.4:9050" set ("tag.location" = "group_b");
alter system modify backend "10.10.101.5:9050" set ("tag.location" = "group_c");
alter system modify backend "10.10.101.6:9050" set ("tag.location" = "group_c");3)第三步:給應用下的表單指定資源組分布,將用戶數據的不同副本分布在不同資源組內
create table flume_etl<table>
(k1 int, k2 int)
distributed by hash(k1) buckets 1
properties("replication_allocation"="tag.location.group_a:2, tag.location.group_b:1"
)create table cdc_etl<table>
``` "replication_allocation"="tag.location.group_b:2, tag.location.group_c:1"create table etl<table>
```"replication_allocation"="tag.location.group_a:1, tag.location.group_c:2"create table mkui_readonly<table>
```"replication_allocation"="tag.location.group_a:2, tag.location.group_c:1"create table SaaS_readonly<table>
```"replication_allocation"="tag.location.group_a:1, tag.location.group_b:1, tag.location.group_c:1"create table dev<table>
`` `"replication_allocation"="tag.location.group_a:1, tag.location.group_b:1, tag.location.group_c:1"
?4)第四步:設置用戶的資源使用權限,來限制某一用戶的查詢只能使用其指定資源組中的節點來執行。
set property for 'flume_etl' 'resource_tags.location' = 'group_a';
set property for 'cdc_etl' 'resource_tags.location' = 'group_b';
set property for 'etl' 'resource_tags.location' = 'group_c';
set property for 'mkui_readonly' 'resource_tags.location' = 'group_a';
set property for 'SaaS_readonly' 'resource_tags.location' = 'group_a, group_b, group_c';
set property for 'dev' 'resource_tags.location' = 'group_b';? ? ? 值得一提的是,與社區交流中得知在即將發布的 Apache Doris 2.0 版本中還基于Pipeline執行引擎增加了 Workload Group 能力。?該能力通過對 Workload 進行分組管理,以保證內存和 CPU 資源的精細化管控。
? ??通過將 Query 與 Workload Group 相關聯,可以限制單個 Query (查詢)在BE節點上的CPU 和內存資源的百分比,并可以配置開啟資源組的內存軟限制。當集群資源緊張時,將自動 Kill 組內占用內存最大的若干個查詢任務以減緩集群壓力。當集群資源空閑時,一旦 Workload Group 使用資源超過預設值時,多個 Workload 將共享集群可用空閑資源并自動突破闕值,繼續使用系統內存以保證查詢任務的穩定執行。更詳細的Workload Group 介紹可以參考:
WORKLOAD GROUP - Apache Doris
5.3??批量建表
? ? ?初始化完成Doris的建表映射往往需要構建很多表單,而單獨建表低效且易出錯。為此,我們根據官方文檔的建議使用Cloudcanal 進行表結構同步來批量建表,大大提高了數據初始化的效率。
? ? 建表時需要注意的是:以 MySQL為例,MySQL數據源映射到Doris表結構的過程中需進行一定的表結構調整。在 MySQL 中varchar(n)?類型的字段長度是以字符個數來計算的,而 Doris 是以字節個數計算的。因此,在建表時需要將Doris varchar 類型字段的長度調整到MySQL 對應字段長度的 3 倍。在使用Unique 模型時需要注意建表時UNIQUE KEY 列要放在 Value 列前面聲明,且保證有序排列和設置多副本配置。

? ? ?除了以上方式,日前新發布的 Doris-Flink-Connector 1.4.0 版本中已集成了 Flink CDC、實現了從 MySQL 等關系型數據庫到 Apache Doris 的一鍵整庫同步功能。用戶無需提前在 Doris 中建表、可以直接使用Connector 快速將多個上游業務庫的表結構及數據接入到Doris 中。
5.4?計算實現
? ??根據我們對架構 2.0 的規劃,我們將所有計算轉移在 Doris 中完成。然而在支撐實時和準實時的場景下,具體的技術實現會有所不同,主要區別如下:
5.4.1?實時計算
? ??如上文提到會以實時數據采集 + Doris 視圖模型的方式提供實時計算結果,而為了在計算過程中達到更高的數據時效支持,應該盡量減少不必要的數據冗余設計。如傳統數據倉庫會按照ODS->DWD->DWS->ADS等分層逐層計算落表。而在實時計算場景下可以適當進行裁剪,裁剪的依據為整體查詢時效的滿足情況。此外,在實際的業務場景中也會有多層視圖嵌套調用的情況。

5.4.2?準實時計算?
? ? 在業務能接受的準實時場景下(10分鐘、30分鐘、小時級),可以通過實體表單 + 微批任務實現計算,計算過程按照調度層級依賴關系逐層完成。
-
通過 Java UDF 生成增量/全量數據
? ? 在實際業務中,存在增量/全量的日、月、年等不同時間頻度數據生成需求。我們通過 Doris 的 Java UDF 功能(1.2 版本后支持) +調度系統傳參的方式實現了一套腳本動態的生成增量/全量及日、月、年等不同的指標匯總。? 實現思路:
- period_type計算頻度 D/W/M/Y 代表計算日、周、月、年
- run_type:INC(增量)/ DF(全量)是通過傳遞begin_date,end_datel來篩選business_date數據進行匯總。
1)增量滿足:begin_date(對應計算頻度開始日期) <= business_date <= end_date (對應計算頻度結束日期)
2)全量滿足:begin_date(寫死一個業務最小日期) <= business_date <= end_date (對應計算頻度結束日期)
? ? 基于以上思路實現etlbegindate?函數來返回不同計算頻度下增量、全量的?begin_date
etlbegindate(run_type,period_type,end_date)? ? 為了在統計不同頻度時能夠生成對應頻度的識別id字段,我們還需要實現一個periodid?函數
periodid(period_type,business_date)
? ? 該函數的主要功能為:
-
period_type = 'D' 返回 business_date 所在日, 'YYYYMMDD' 格式的 period_id 字段
-
period_type = 'W' 返回 business_date 所在周的起始日期, 'YYYYMMDDYYYYMMDD' 格式的 period_id 字段
-
period_type = 'M' 返回 business_date 所在月,'YYYYMM' 格式的 period_id 字段
-
period_type = 'Y' 返回 business_date 所在年,'YYYY' 格式的 period_id 字段
? ? ?結合etlbegindate與?periodid?兩個函數,假定當前時間為 2023 年 6 月16 日則相應的實現如下:
? ? SQL 腳本使用函數示例:
-- 示例Demoselect ${period_type} as period_type -- 統計頻度 D/W/M/Y,period_id(${period_type},business_date) as period_id -- 時間頻度ID,count(goods_id) as goods_cnt -- 商品數where business_date >= etlbegindate(${run_type},${period_type},${end_date})and business_date <= ${end_date}
group by period_id? ? 運行調度前參數配置:

? ?任務運行結果示例:W/M/Y 是的實現方式一致,只是數據返回的period_id?格式會按照上文描述的格式輸出。
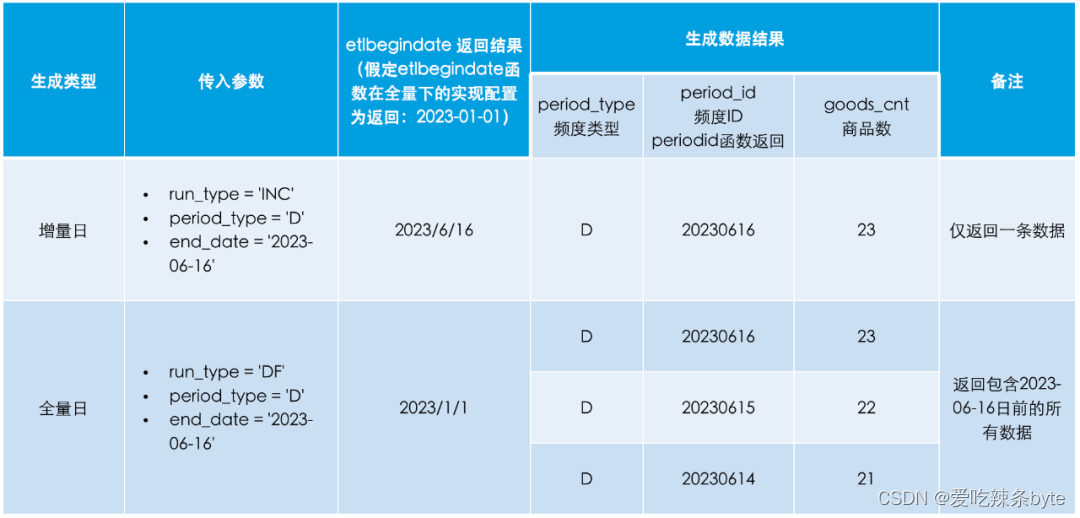
? 基于以上方法,我們高效地為公司SaaS 產品構建了相應的數據指標庫應用。
基于 Doris的大表優化
? ?我們的業務涉及基于用戶頁面訪問和景區設備日志信息的統計分析業務,這類指標計算需要處理大量日志數據。接下來,我們將介紹如何利用 Doris 提供的功能對數據進行優化處理。
? ?數據分區分桶:Doris 支持兩級分區,第一級叫做 Partition,支持 Range Partitioning 和 List Partitioning 兩種分區策略。第二級分區叫做 Bucket,支持 Hash Partitioning分區策略。
? ?對于用戶瀏覽行為的埋點事件表,按照時間做為分區(Range Partitioning):

? ?在實際應用中,業務的歷史冷數據可以按年進行分區,而近期的熱數據可以根據數據量增幅按照日、周、月等進行分區。另外,Doris 自 1.2.0 版本后支持批量創建Range分區,語法簡潔靈活。
? 從 Doris1.2.2 版本開始,Doris支持了自動分桶功能,免去了分桶上面的投入,一個分桶在物理層面為一個 Tablet,官方文檔建議 Tablet 大小在1GB - 10GB 之內,因此對于小數據量分桶數不應太多。自動分桶的開啟只需要建表時新增一個屬性配置:
DISTRIBUTED BY HASH(openid) BUCKETS AUTO PROPERTIES ("estimate_partition_size" = "1G")
Doris Borker的協同計算
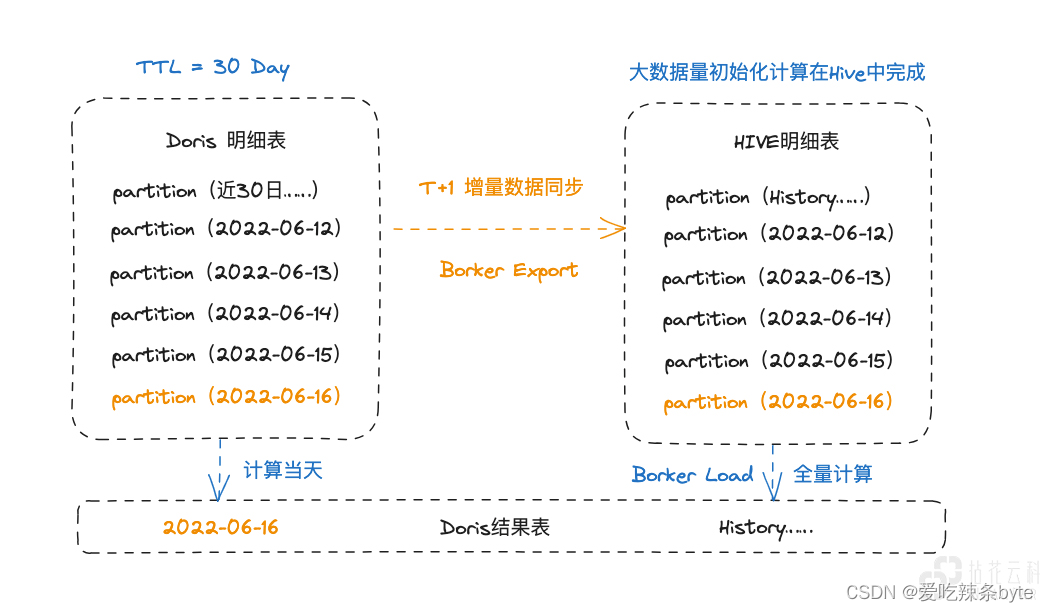
? 業務中存在部分大數據量的歷史數據統計需求,針對這部分需求我們進行了協同計算處理
-
FlinkCDC 讀取 Binglog 實時同步數據到 Doris明細表
-
Doris明細表會存儲近30日熱數據(需要進行TTL管理)
-
Doris每日通過Borker Export 同步一份日增量數據至HDFS,并加載至 Hive 中
-
Hive 中儲存所有明細數據,數據初始化生成計算結果在Hive中完成 Borker Load 至 Doris
-
Doris 在生成結果數據時僅生成當前日期數據,每天的增量生成沉淀為歷史結果
-
當業務有需要時通過 Borker Export 加載Hive全量計算結果刷新Doris 結果表
-
當業務有基于此明細數據的新開發需求時,可在Hive中計算完成初始化結果至 Doris
? ?數據導出(Export):Export 是 Doris 提供的一種將數據導出的功能。該功能可以將用戶指定的表或分區的數據以文本的格式,通過 Broker 進程導出到遠端存儲上,如 HDFS 或對象存儲(支持 S3 協議) 等。用戶提交一個 Export ?作業后,Doris 會統計這個作業涉及的所有 Tablet,然后對這些 Tablet 進行分組,每組生成一個特殊的查詢計劃。這些查詢計劃會讀取所包含的 Tablet 上的數據,然后通過 Broker 將數據寫到遠端存儲指定的路徑中。
? ? 數據導入(Broker load):Broker Load 是 Doris 的一種異步數據導入方式,可以導入 Hive、HDFS 等數據文件。Doris 在執行 Broker Load 時占用的集群資源比較大,一般適合數據量在幾十到幾百 GB 級別下使用。同時需要注意的是單個導入 BE 最大的處理量為 3G,如果超過 3G 的導入需求就需要通過調整B roker Load 的導入參數來實現大文件的導入。
聯邦查詢在數據分析場景下的嘗試
? 由于上游數據源較多,我們僅對常用的數據表單進行了數據倉庫采集建模,以便更好地進行管理和使用。對于不常用到的數據表單,我們沒有進行入倉,但業務方有時會臨時提出未入倉數據的統計需求,針對這種情況,我們可以通過 Doris的Multi-Catalog(多源目錄)進行快速響應、完成數據分析 ,待需求常態化后再轉換成采集建模的處理方式。
? ? Multi-Catalog 是 Doris 1.2.0 版本中推出的重要功能。該功能支持將多種異構數據源快速的接入Doris,包括Hive、Iceberg、Hudi、MySQL、Elasticsearch 和 Greenplum 等。使用 Catalog 功能,可以在Doris中統一的完成異構數據源之間的關聯計算。Doris1.2.0 以后的版本官方推薦通過 Resource 來創建 Catalog,這樣在多個使用場景下可以復用相同的 Resource。下面是Doris本地表與通過Multi-Catalog映射的遠程表單組合完成關聯計算的場景示例。

? ? ?Multi-Catalog帶來的收益:
- 更高的靈活性:通過Multi-Catalog,用戶可以靈活地管理不同數據源的數據,并在不同的數據源之間進行數據交換和共享。這可以提高數據應用的可擴展性和靈活性,使其更適應不同的業務需求。
- 高效的多源管理:由于 Multi-Catalog可以管理多個數據源,用戶可以使用多個 Catalog 來查詢和處理數據,解決了用戶跨庫訪問不便的問題,從而提高數據應用的效率。
? ? 社區中已經有非常多的伙伴基于 Multi-Catalog 功能落地了應用場景。另外如果要深度使用該功能,建議建立專門用于聯邦計算的BE 節點角色,當查詢使用 Multi-Catalog 功能時,查詢會優先調度到計算節點。
六、運維保障
6.1?守護進程
? ? ?為了保障 Doris 進程的持續運行,按照 Doris 官網的建議在生產環境中將所有實例都的守護進程啟動,以保證進程退出后自動拉起。我們還安裝部署了Supervisor 來進行進程管理,Supervisor 是用 Python 開發的一套通用的進程管理程序,可以將一個普通的命令行進程變為后臺 Daemon 并監控進程狀態,當進程異常退出時自動重啟。使用守護進程后,Doris 的進程變成了 Supervisor 的子進程,Supervisor 以子進程的 PID 來管理子進程,并可以在異常退出時收到相應的信號量。
? ?配置Supervisor 時的注意事項:
通過supervisorctl status查詢出來的進程 id不是 Fe、Be、Broker 的進程 ID,而是啟動它們的 Shell 進程 ID。在start_xxx.sh中會啟動真正的Doris 進程,因此才有了進程樹的說法。
stopasgroup=true;?是否停止子進程、killasgroup=true ;是否殺死子進程,需要保證這兩個參數為true,否則通過supervisorctl控制 Doris 的后臺進程是無效的,這也是通過 Supervisor 守護 Doris 進程的關鍵。
? ?配置完 Supervisor 后則通過守護進程的方式來管理 FE、BE、Borker……

? ? 由于 Superviosr 自帶的 Web UI 不支持跨機器管理,當多節點時管理非常不便,這里可以使用 Cesi 來對Supervisor 進行合并管理:
6.2?Grafana 監控報警
? ?關于 Doris 的運行監控,我們按照官網相關內容部署了Prometheus 和 Grafana ,并進行監控項的采集。同時對于一些關鍵指標進行了預報警,利用企微 Bot 完成信息推送。
? 以下為測試環境示例圖:

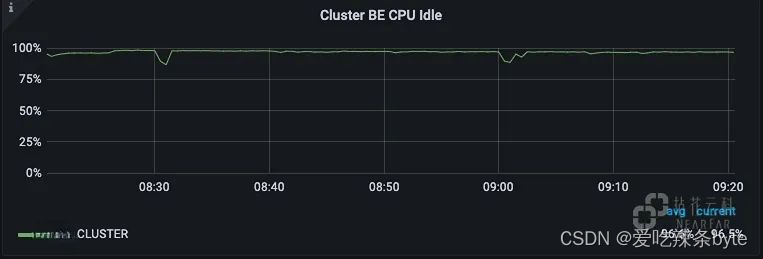
? 集群CPU空閑情況:
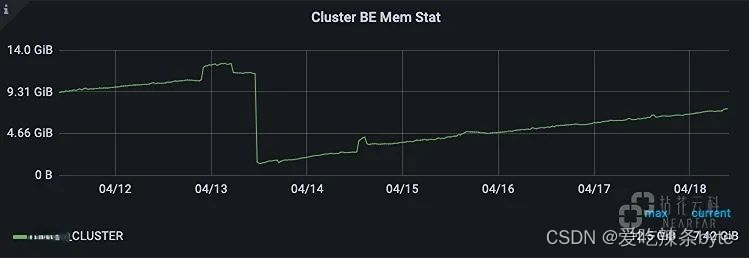
? ?集群內存使用情況:之前發現集群存在內存泄露
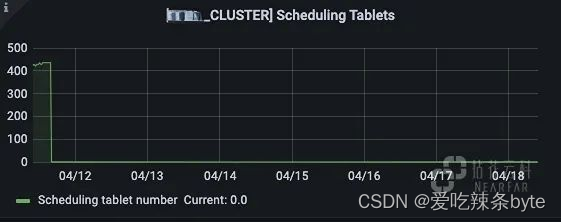
? ?開始調度運行的Tablet 數量:正常情況該值基本為 0 或個位數,出現波動的Tablet 說明可能在進行 Recovery 或 Balance。
? ?除此之外,我們還使用 QPC/99th Latency……等指標來查看監測集群服務能力,建議可以在 Doris 監控的基礎上額外加入集群機器的監控,因為我們的機器部署在VM中,曾經出現過硬盤問題、內存問題、網絡波動、專線異常等情況,多一層報警機制就多一份穩定性保障。
七、總結收益
? ?通過新架構的成功搭建,實現了以 Doris為核心數據倉庫 + OLAP引擎的使用方式(All in One),有效縮減了數據處理流程,大大降低了投遞型項目的實施成本。在舊架構下,需要部署、適配、維護非常多的組件,無論是實施還是運維都會比較繁重。相比之下,新架構下的Doris 易于部署、擴展和維護,組合方案也靈活多變。在我們近半年的使用時間內,Doris 運行非常穩定,為項目交付提供了強有力的計算服務保障能力。
? ? 此外,基于Doris 豐富的功能、完善的文檔,我們可以針對離線和在線場景進行高效且細致的數據開發和優化。通過引入 Doris 我們在數據服務時效性方面也有了大幅提高,當前我們已經成功地落地了多個數據項目,并孵化出了一個基于 Doris 的 SaaS 產品。同時Doris 擁有一個成熟活躍社區,SelectDB 技術團隊更是為社區提供了一支全職的技術團隊,推動產品迭代、解決用戶問題,也正是這強有力的技術支持,幫助我們更快上線生產,快速解決了我們在生產運用中遇到的問題。
八、未來規劃
? ? ?未來,我們計劃構建基于K8S 的 Doris 服務方式。在項目交付場景下,常常需要進行整套環境的部署。目前,我們已經在 K8S 上集成了 2.0 版本架構下除 Doris 以外的其他數據服務組件。隨著 Doris 社區 2.0 版本全面支持 K8S 的計劃,我們也會將方案集成到我們的新體系中,以方便后期的項目投遞。
? ?除此之外,我們還將結合 Doris 的功能特性提煉基于 Doris 的數倉方法論,優化開發過程。Doris 是一個包容性非常好的存儲計算引擎,而想要將原有的數據倉庫開發內容全部適配在 Doris 上還需要不斷的學習、優化與調整,以充分發揮 Doris 的優勢,同時我們也將在此基礎上沉淀一套與之相匹配的開發規范。
參考文章:
Apache Doris 在拈花云科的統一數據中臺實踐,One Size Fits All
)



)





![[伴學筆記]01-操作系統概述 [南京大學2024操作系統]](http://pic.xiahunao.cn/[伴學筆記]01-操作系統概述 [南京大學2024操作系統])






)

