一、數據增強
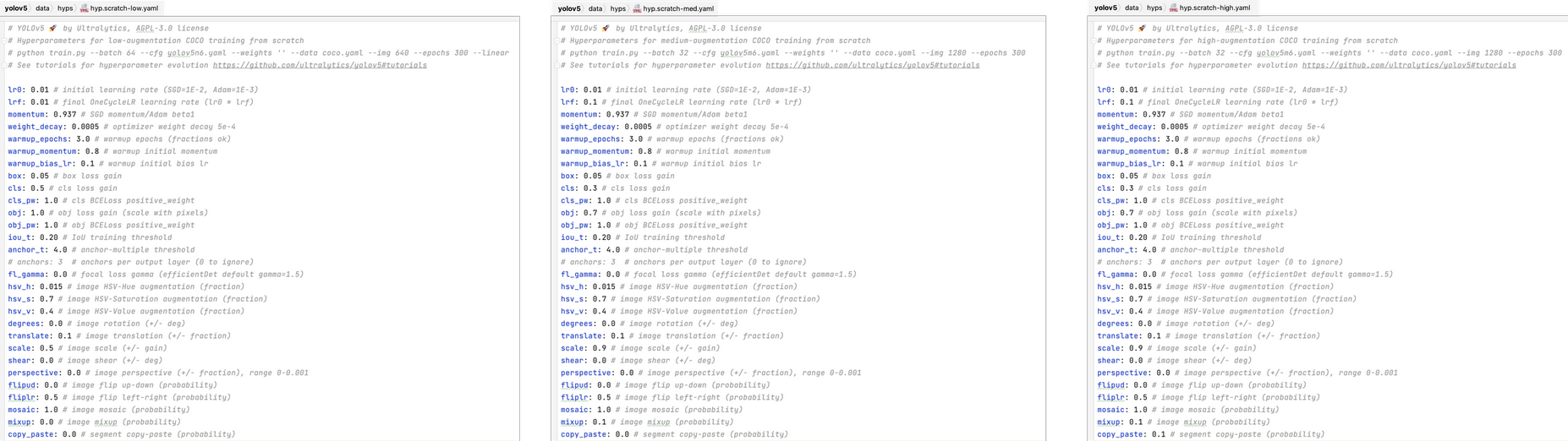
- mosaic
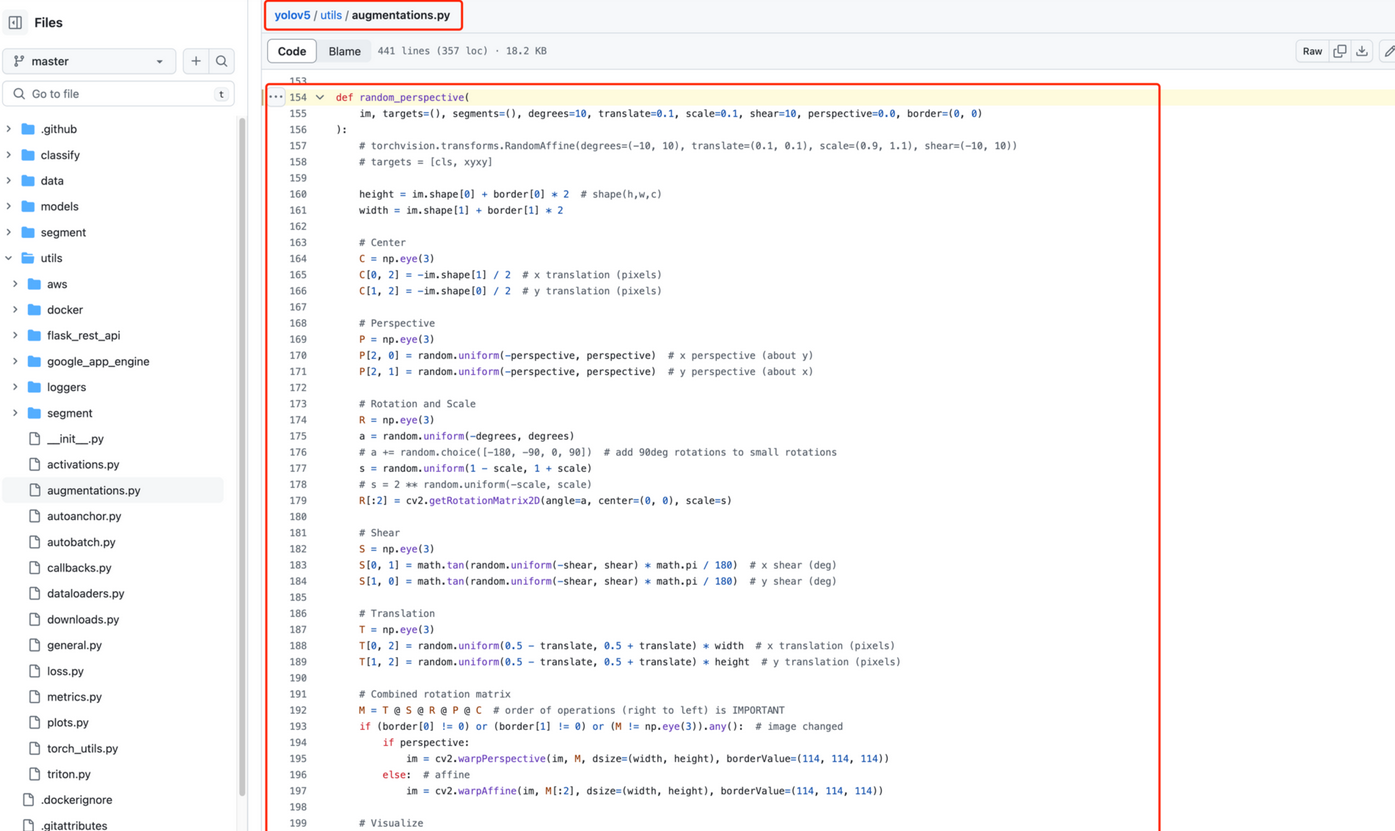
- 仿射變換與透視變換
- Mixup
mosaic代碼位置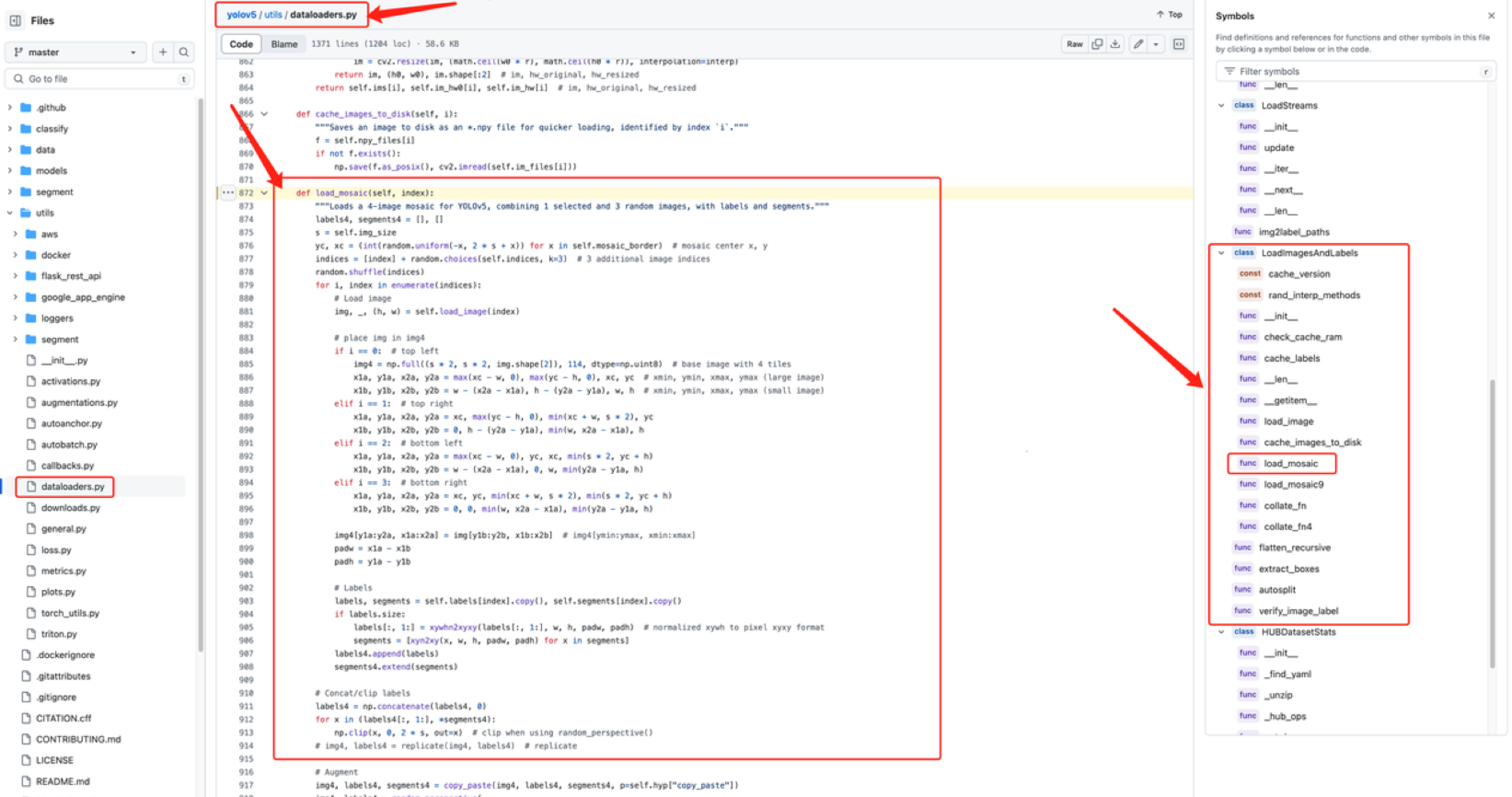 仿射變換 與 透視變換?代碼片段位置
仿射變換 與 透視變換?代碼片段位置
二、網絡結構
1. 網絡不同尺寸
nsmlx與網絡深寬度
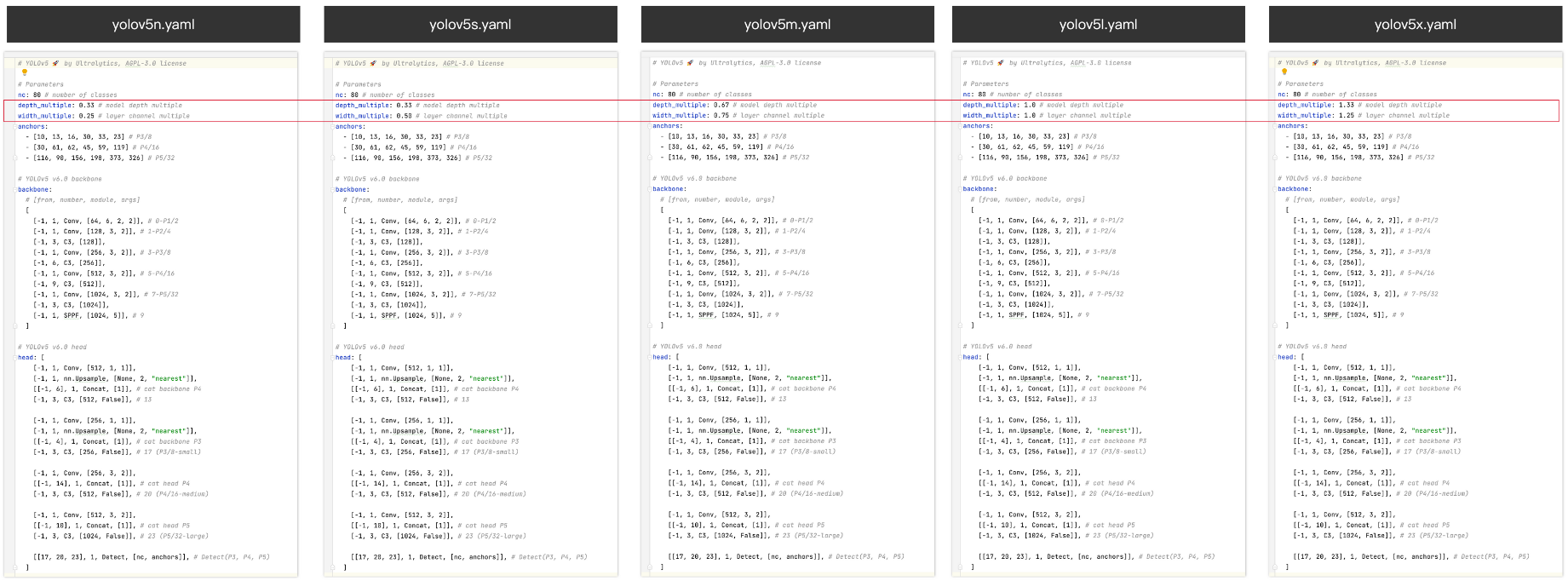
yolov5 官方提供了5個目標檢測的網絡版本:yolov5n、yolov5s、yolov5m、yolov5l、yolov5x ,早年是剛好對應的五個yaml文件:
后來改為了一個yaml文件,通過scales參數控制尺寸:
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 1024]l: [1.00, 1.00, 1024]x: [1.33, 1.25, 1024]
- 各版本的網絡結構都是類似的,backbone和head參數都一樣,不同的只是
depth_multiple和width_multiple這兩個參數depth_multiple控制網絡深度:有些模塊需要重復 n 次,此時,我們就會用到depth_multiple * n來控制該模塊重復的次數,達到控制網路深度的作用width_multiple控制網絡寬度:用于控制某些模塊輸出的特征圖channel數,比如 卷積層的輸出channel數,達到控制網絡寬度的效果。
yolov5n是yolov5系列中深度最小,特征圖channel數最少的網絡。其他的都是在此基礎上不斷加深(depth),不斷加寬(width)。

nsmlx從左往右網絡的尺寸變大,參數量變大。
舉例說明l和s尺寸
# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args]- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C3, [128]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C3, [256]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 9, C3, [512]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C3, [1024]]- [-1, 1, SPPF, [1024, 5]] # 9
depth控制網絡深度:
比如說,yolov5l型號的backbone中,number表示該模塊的重復次數,四個C3塊分別重復3, 6, 9, 3次。
如果是yolov5s型號,那么需要都乘depth = 0.33,重復次數變為1, 2, 3, 1。原本就是1或者乘完小于1的就不用乘重復1次。
width控制網絡寬度:
比如,yolov5l型號的backbone中,args表示參數列表,第一個值是模塊輸出的channel數,前兩Conv層分別為64, 128。
如果是yolov5s型號,需要都乘width=0.5,變為32, 64。

官方更多改造版
還有其他版本的配置文件,可查看https://github.com/ultralytics/yolov5/tree/master/models/hub
常規版本名稱后加了6的,是能更好支持更大尺寸圖像(常規只能處理640x640)1280x1280。


2. yaml參數解讀
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# Ultralytics YOLOv5 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolov5
# Task docs: https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 1024]l: [1.00, 1.00, 1024]x: [1.33, 1.25, 1024]# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args]- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C3, [128]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C3, [256]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 9, C3, [512]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C3, [1024]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv5 v6.0 head
head:- [-1, 1, Conv, [512, 1, 1]]- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C3, [512, False]] # 13- [-1, 1, Conv, [256, 1, 1]]- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C3, [256, False]] # 17 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 14], 1, Concat, [1]] # cat head P4- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)每一行有4個參數[from, number, module, args]
from:模塊輸入來源,- 一般為-1,表示上一層輸出是本層輸入。
- 其他數字指層的索引(從0開始)
- 對于
Concat模塊,from參數是一個list列表,因為有兩個輸入,比如[-1, 4]
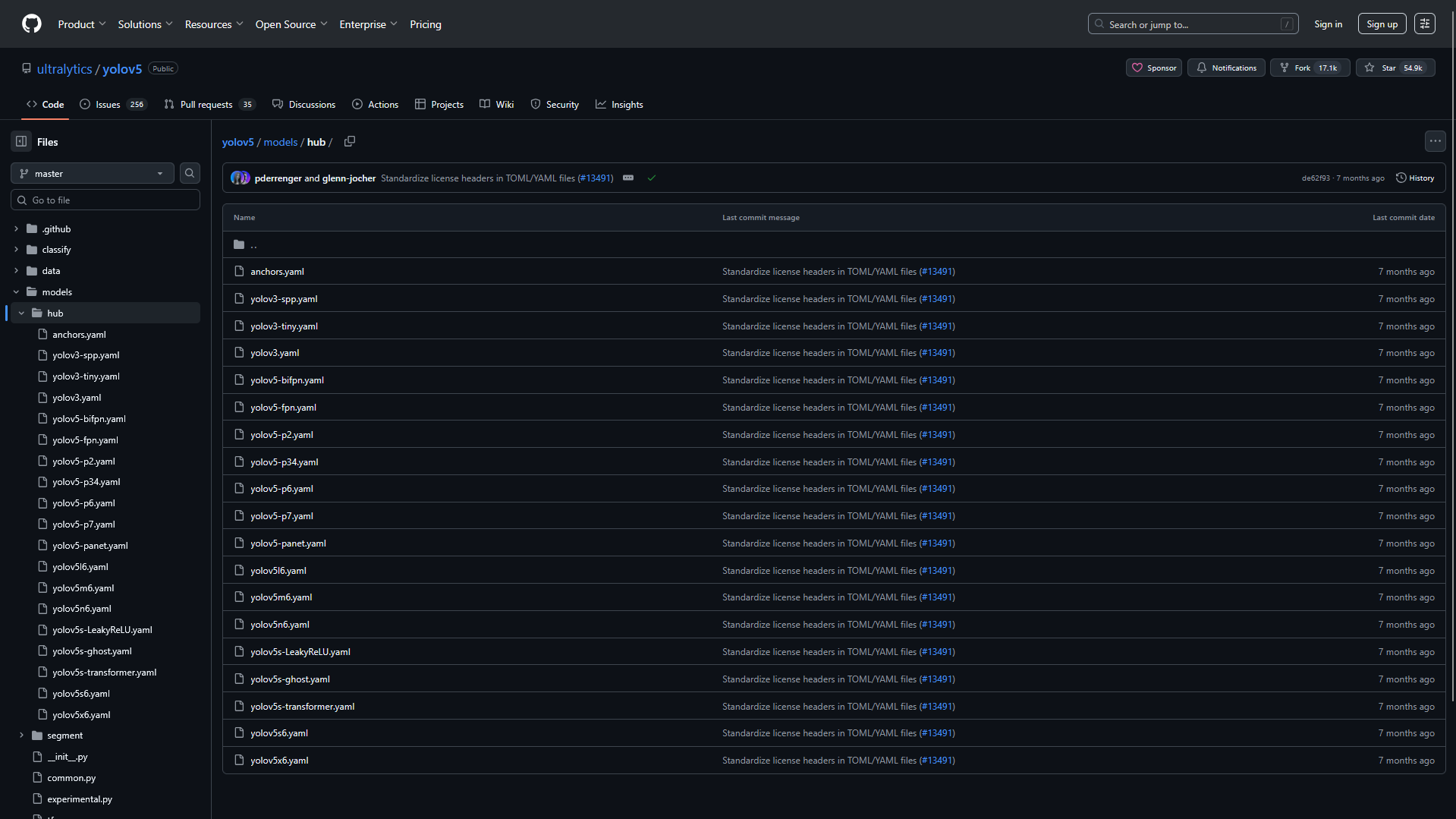
number:這個模塊或者模塊內的某一部分,重復堆疊多少次。比如[-1, 3, C3, [128]]說明C3塊中的殘差塊要堆疊3次。module:模塊名稱。args:為一個list,記錄該模塊的參數,一般第一個值表示輸出的channel數,具體看下面圖片
3. 各個模塊
Conv
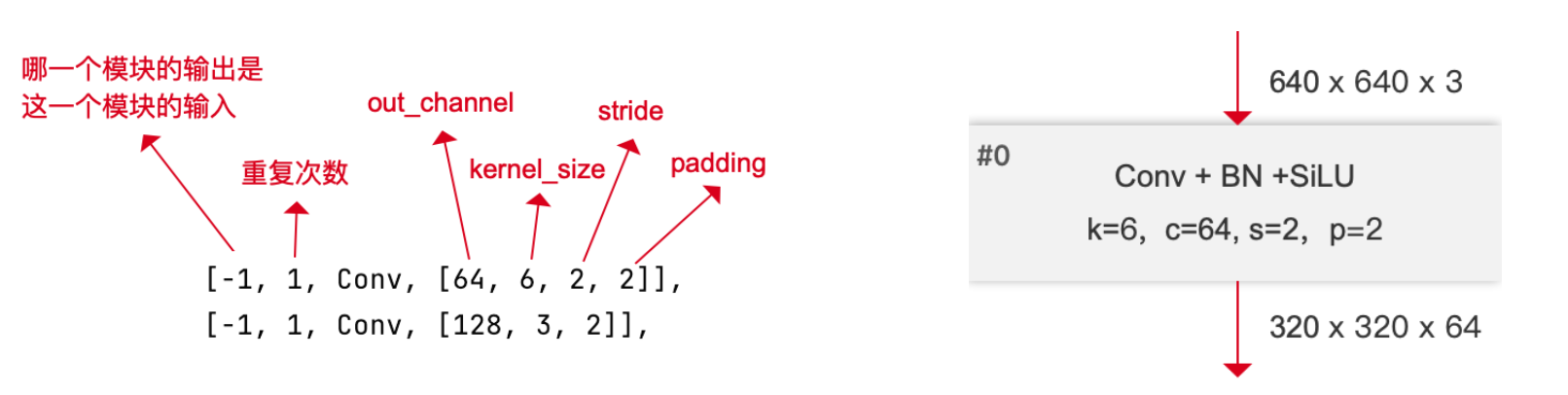
padding不寫時,默認輸出尺寸不變,自動計算padding大小。
C3
一個CSP模塊。C3的名稱含義是,除了要重復的殘差塊以外,有3個卷積層。( a CSP bottleneck includes 3 conv layers)?
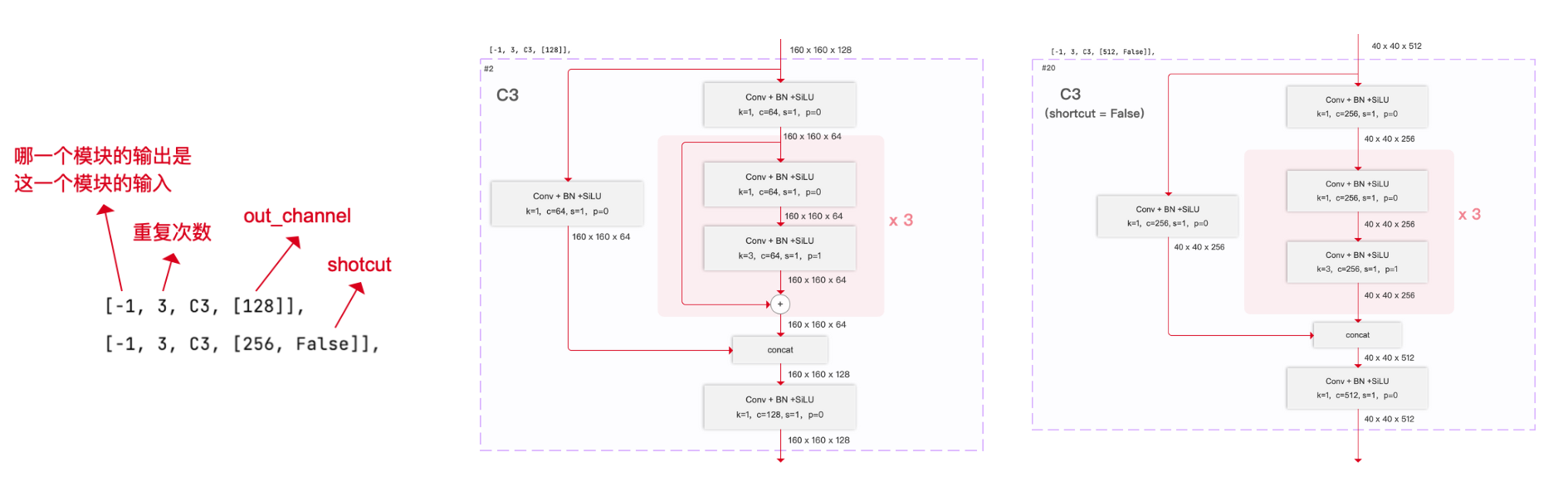
args的第二個參數為True或者不寫時,表示殘差塊都有殘差連接。
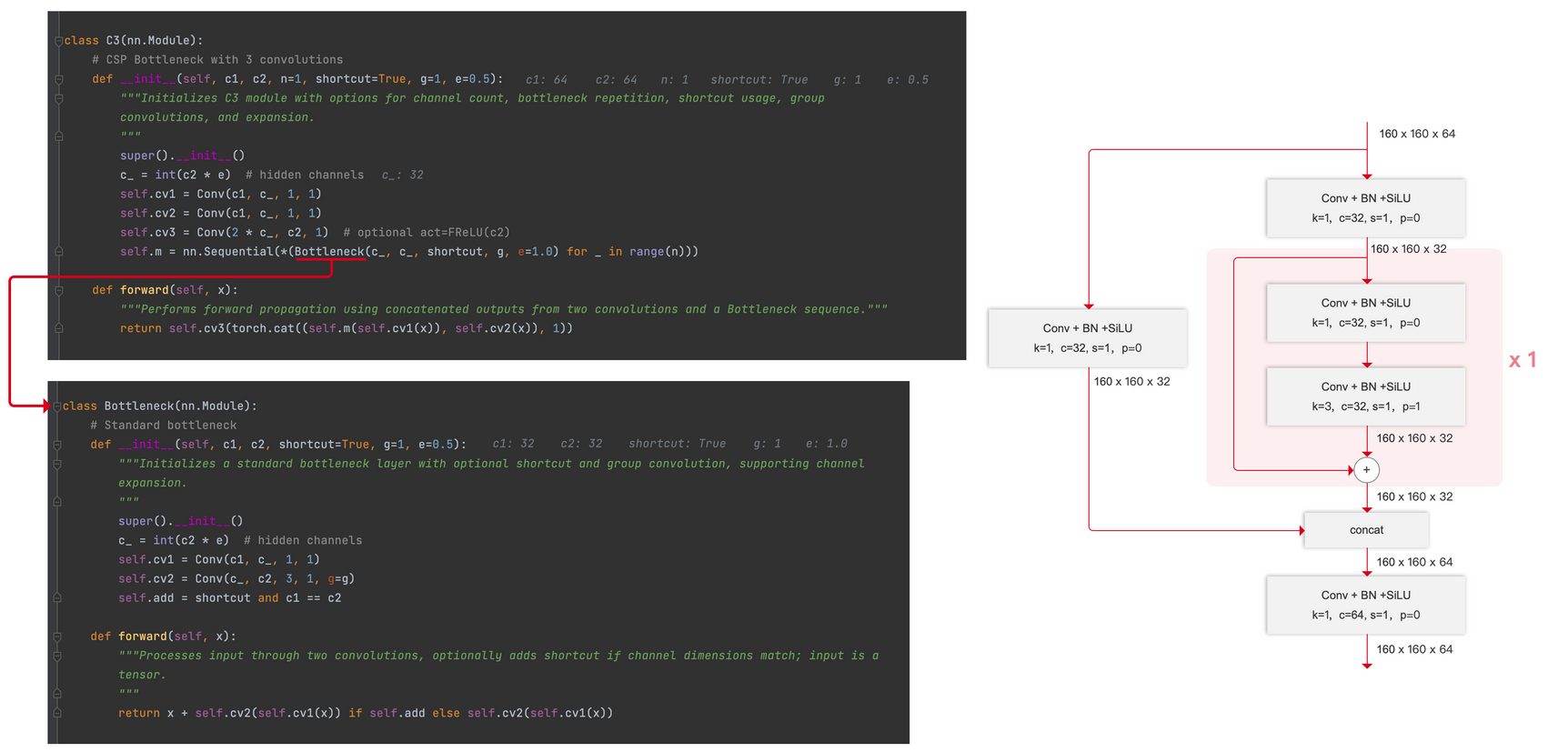
例子中,輸入尺寸為 160x160x64 , c1=64 ,c2=64, n=1?
SPPF
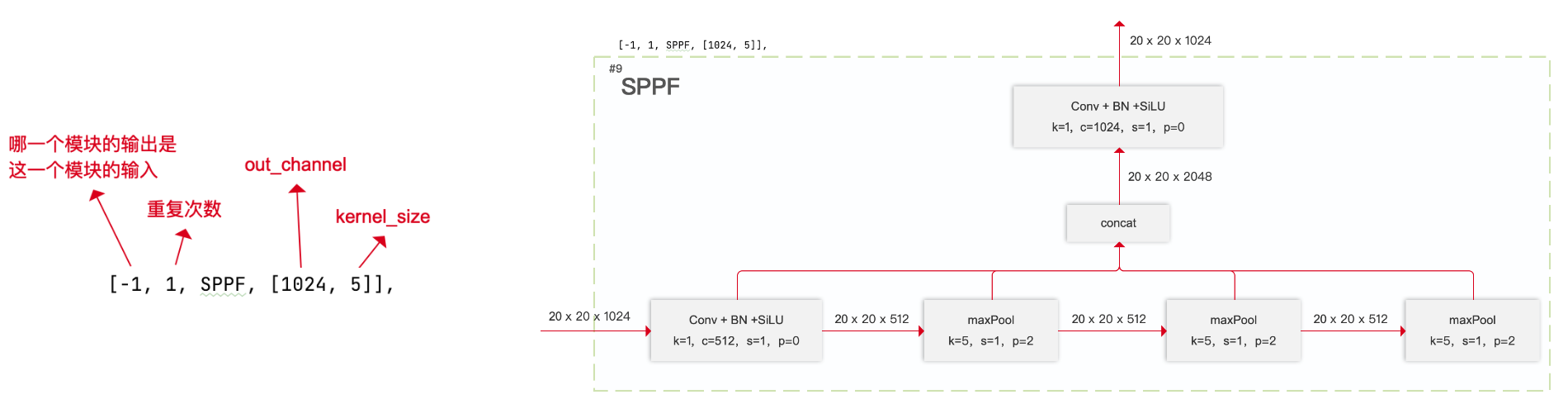
args的第二個參數表示max_pooling層的Kernel size
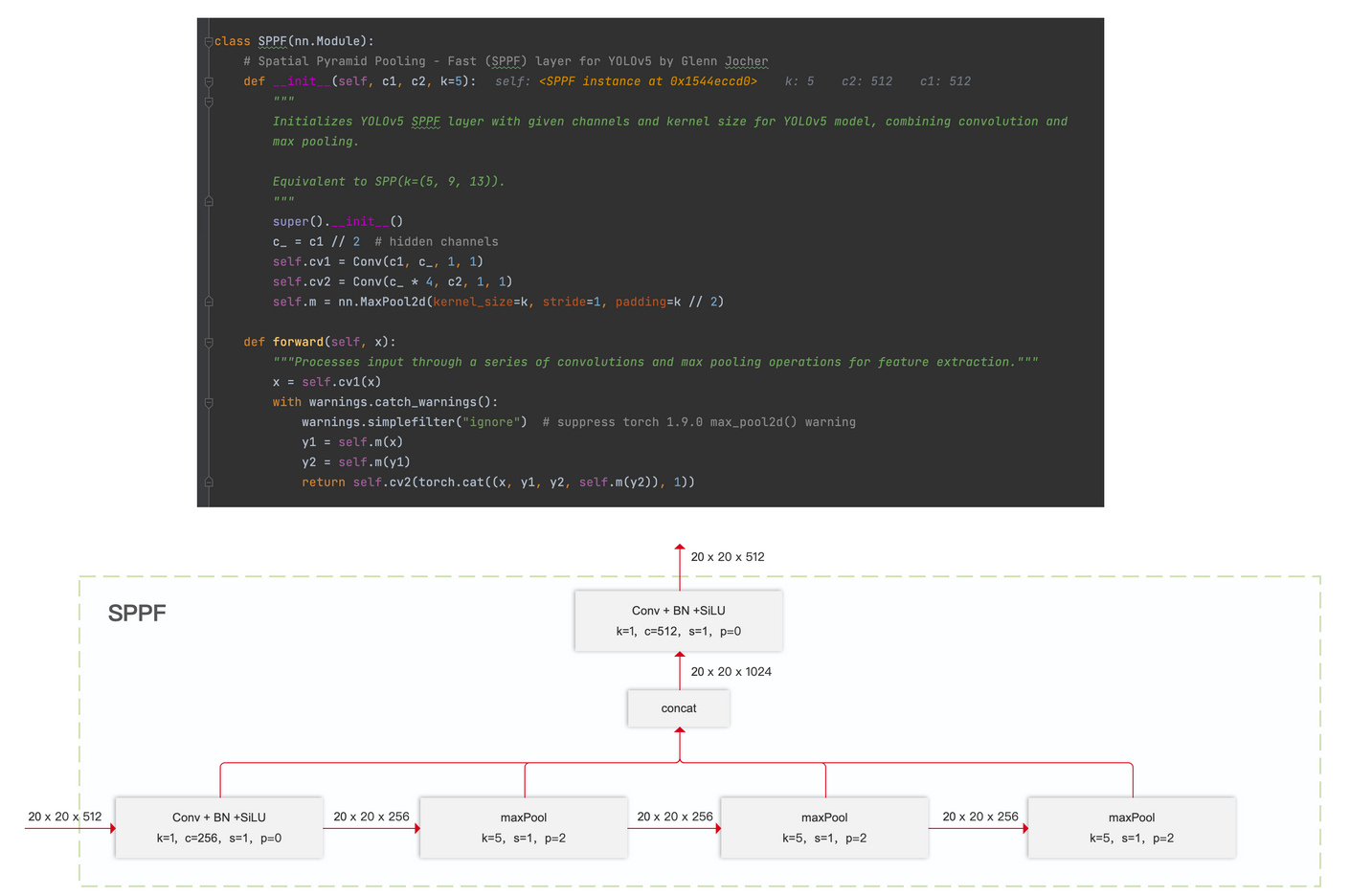
例子中,輸入尺寸為 20x20x512 , c1=512 ,c2=512, k=5?
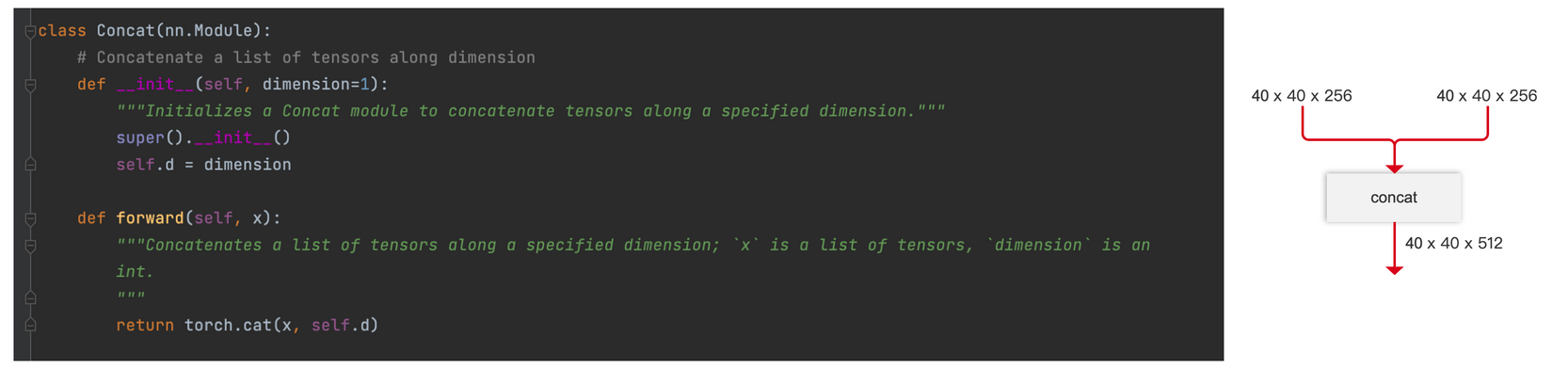
Concat

args就一個元素,記錄在第幾個維度上拼接。1表示第二個維度也就是channel維度。(batch, channel, w, h)
nn.Upsample

args的三個值對應nn.Upsample的參數,輸出尺寸、縮放比例、插值方法。
直接調用 nn.Upsample ,傳入對應參數
import torch.nn as nnupsample = nn.Upsample(size=None, scale_factor=2, mode='nearest')
size:指定輸出的尺寸 。size和scale_factor只能二選一填寫,輸出尺寸和縮放比例都指定時會報錯。scale_factor:指定尺寸放大的比例因子。mode:指定上采樣的模式。可選的模式包括:'nearest':最近鄰插值,使用最近鄰像素的值來進行插值。'linear':線性插值,使用線性插值方法。'bilinear':雙線性插值,對每個輸出像素使用二維線性插值方法。'bicubic':雙三次插值,使用雙三次插值方法。'trilinear':三線性插值,對每個輸出像素使用三維線性插值方法。
Detect
網絡輸出層

 每個輸出對應3個anchor。
每個輸出對應3個anchor。
后來版本就用Anchor-free,所以不指定anchors參數了[[17, 20, 23], 1, Detect, [nc]]
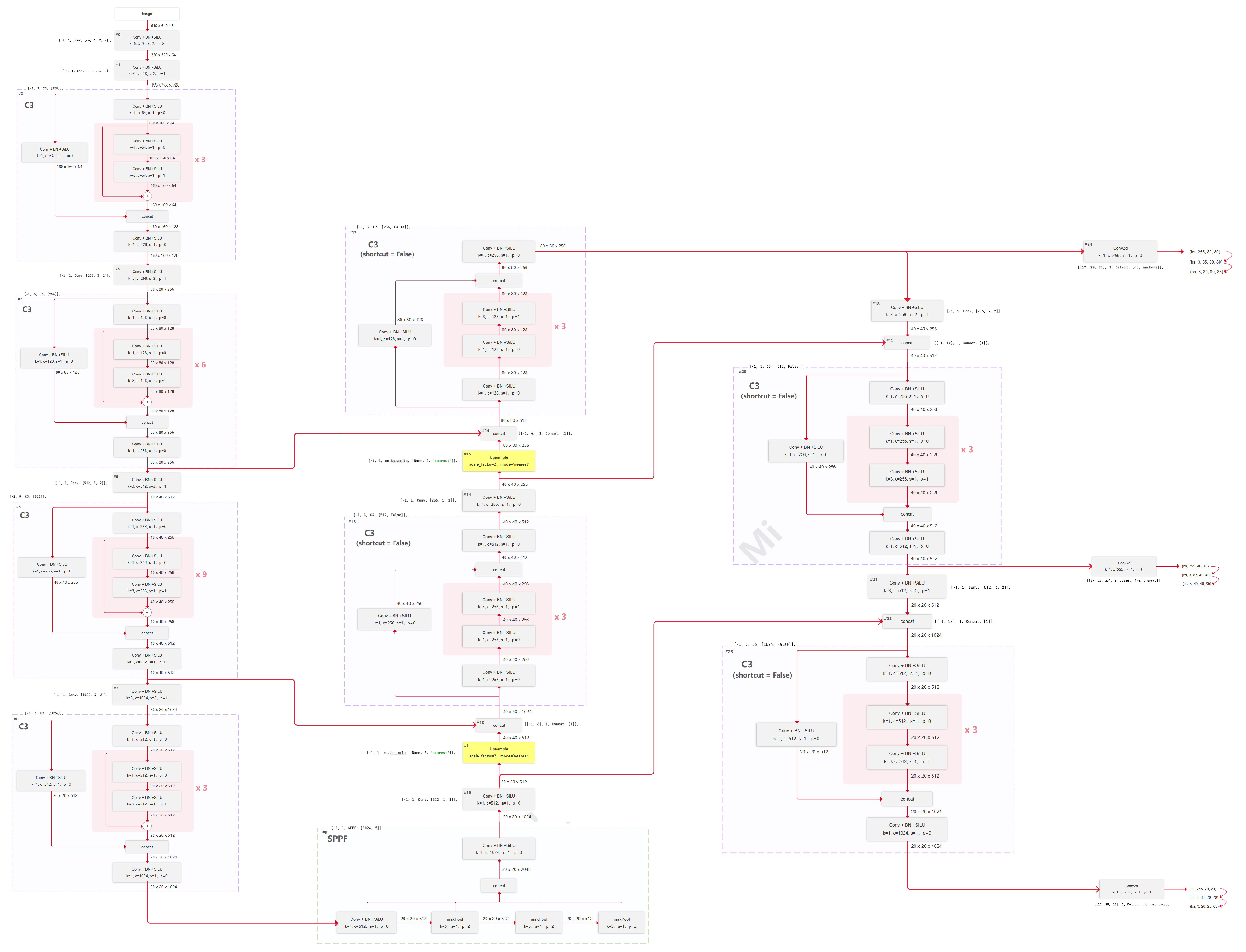
3. yolov5l完整網絡結構圖
Axure圖片資料
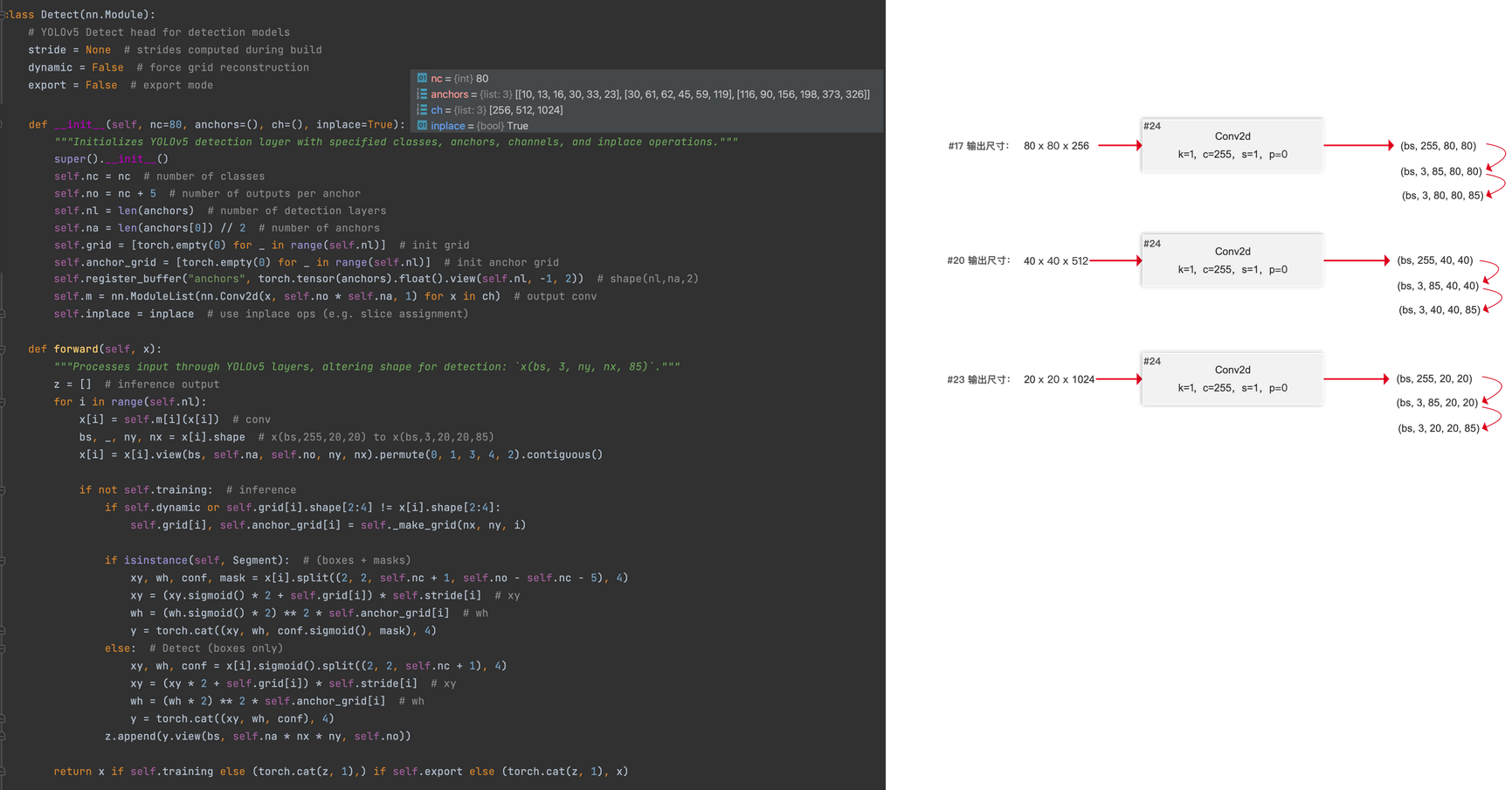
4. 網絡搭建代碼詳解
三、損失函數
YOLOv5 是基于 anchor 的目標檢測算法,即 anchor - base。每個網格(grid cell)都會預先設定幾個不同尺寸和比例的 anchor 框。這些 anchor 框是根據訓練數據集里目標的尺寸統計信息得到的, 例如常見的目標寬度、高度的分布等。在檢測過程中,模型會以這些 anchor 框為基礎,預測目標的位置、尺寸以及類別等信息。比如,模型會預測相對于 anchor 框的偏移量(包括中心點的偏移、寬高的縮放比例),從而得到最終的預測邊界框(bounding box)
在訓練過程中,需要確定哪些 anchor 是正樣本(負責預測目標),哪些是負樣本(不負責預測目標),具體規則下面介紹。
1. 網絡預測結果

網絡預測出的結果為一個list,三個元素對應于三個尺度的feature map。比如feature map 1張量尺寸為(2,3,80,80,85),對應不同維度在特征圖、錨框、預測參數(坐標、置信度、類別 )上的含義。
張量維度 (2, 3, 80, 80, 85) 的拆解說明
2:batch_size(批次大小,即一次處理的圖像數量 )3:對應該尺度下的3個anchors(錨框數量 )80:feature map的寬(特征圖寬度維度 )80:feature map的高(特征圖高度維度 )85:由以下部分組成(85 = 2 + 2 + 1 + 80):2:(tx, ty),預測的bbox的中心點坐標偏移量2:(tw, th),預測的bbox的寬高因子1:包含預測對象的置信度(不關心是什么類別,只判斷是否有 )80:COCO數據集的80個類別的置信度(每個類別對應的預測置信度 )
如何通過網絡預測結果的 tx,ty,tw,tht_x, t_y, t_w, t_htx?,ty?,tw?,th?,進一步計算得到feature map 尺度下的預測框bbox的中心點坐標和寬高的:
predicted bbox 的中心點坐標計算
回故yolov3的坐標計算方式:

- 模型輸出的 tx,tyt_x, t_ytx?,ty? 是無約束的數值,通過 Sigmoid 函數 σ(t)=11+e?t\sigma(t) = \frac{1}{1 + e^{-t}}σ(t)=1+e?t1?
可將其壓縮到(0, 1),表示 預測中心點在網格內的相對偏移比例(0 對應網格左上角,1 對應右下角)。
v3方法是直接網格基準 + 歸一化偏移得到 bbox 中心點在特征圖上的絕對位置。但計算得到的中心點預測存在的問題:
因為 預測值 tx、tyt_x、t_ytx?、ty? 無法取到正負無窮,那么預測中心點坐標 bx,byb_x, b_ybx?,by? 無法取到 0 或 1,即 中心點無法落在 grid cell 的四個邊緣上。
yolov5對其做了改進:

取值范圍 (圖中黃色綠區域):
cx?0.5<x<cx+1.5cy?0.5<y<cy+1.5c_x - 0.5 < x < c_x + 1.5 \\ c_y - 0.5 < y < c_y + 1.5 cx??0.5<x<cx?+1.5cy??0.5<y<cy?+1.5
中心點的范圍上下界正好是grid cell四個角相鄰的grid cell的中心點。所以本grid cell 取不到邊緣,會由相鄰周圍grid cell來負責預測。
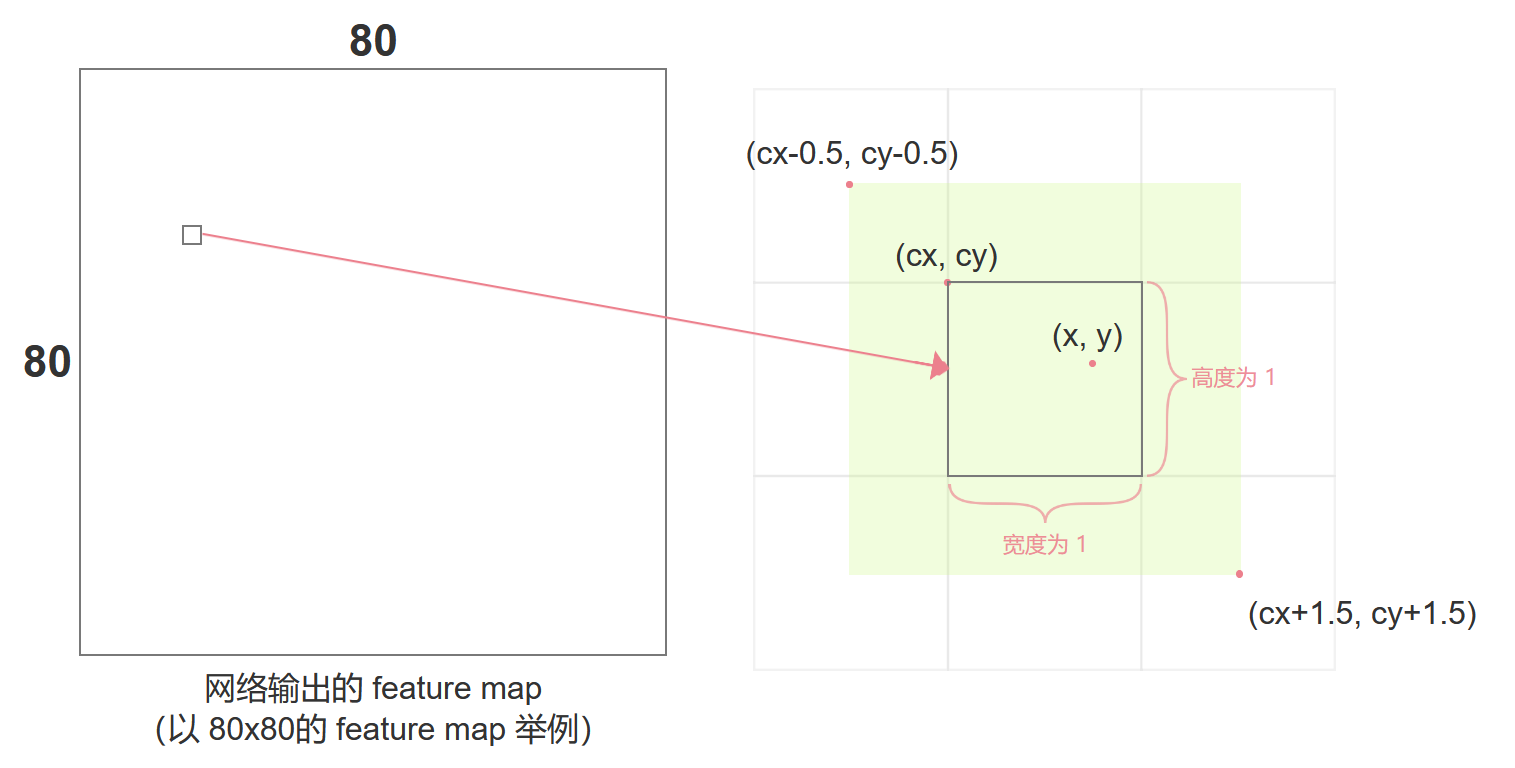
yolov5進行改進:偏移范圍擴展(2?σ(t)?0.52 \cdot \sigma(t) - 0.52?σ(t)?0.5)
給偏移量 σ(t)\sigma(t)σ(t) 乘以 2 并減 0.5 后,偏移范圍變為 [-0.5, 1.5] 。這讓預測的中心點可以“超出當前網格”,覆蓋當前grid cell的邊緣以及相鄰網格區域(比如目標中心靠近網格邊緣時,可能屬于當前網格預測,但實際坐標在相鄰網格范圍內),提升對邊界目標的預測能力。
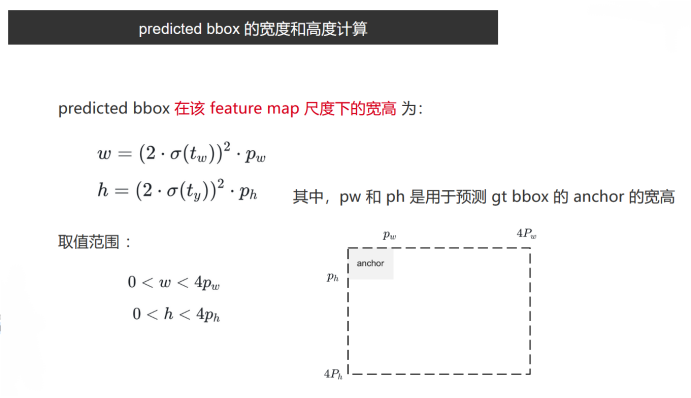
predicted bbox 的寬高計算
回歸yolov3的bbox寬高計算:
github上有人提出了高度和寬度預測存在的問題 ,yolov3和yolov4都有這個問題:

當 twt_wtw? 和 tht_hth? 較大時,etwe^{t_w}etw?和 ethe^{t_h}eth? 可能會指數爆炸,導致預測框bbox的寬度和高度不受限,進一步導致梯度不受控,損失值為NaN,最終會導致訓練失敗。
yolov5也對這點做了改進,使得bbox寬高范圍限值在了4倍的anchor尺寸以內:
2. 正樣本匹配
正樣本匹配的目的,對于圖像中的每一個 bbox,找出:
- 它由輸出特征圖中的哪些
grid cell來負責預測 - 它由哪些尺寸的
anchor來負責預測
基于這些負責預測的 grid cells 中負責預測的 anchors,得到的預測 bbox 就是正樣本,否則就是負樣本
也可以簡單理解為
- 負責預測
gt box的anchor就是正樣本, - 不負責預測的
anchor就是負樣本
正樣本匹配舉例說明
下面我們舉例說明:
我們想要從網絡輸出的 3個 feature map 中分別找出預測某 gt box 的正樣本,下面我們以 feature map 1 舉例 (從 feature map 1 中找正樣本)
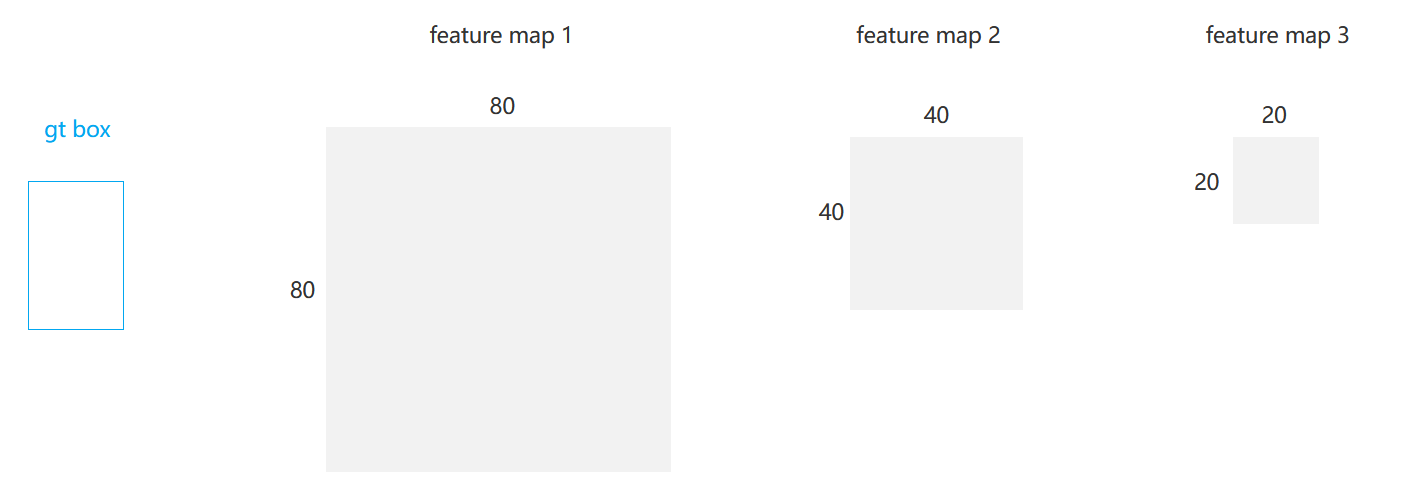
yaml文件中預設的anchors:

- 第一個用于檢測小尺度物體的3個anchors,對應80x80的feature map 1,
P3/8。 - 第二行是用于檢測中等尺度物體的3個anchors,對應40x40的feature map 2,
P4/16。 - 第三行是用于檢測大物體的,對應20x20的feature map 3,
P5/32。
yaml文件中預設的anchors的尺寸,相對于640x640的原圖大小。第一行的三個大小的anchors映射到feature map 1的尺寸縮減8倍,如圖所示。
fearture map1中的每個像素映射會原圖都是一個grid cell,每個grid cell都會基于三個尺寸的anchors預測出三個bbox。所以,feature map 1 一共會預測出 80 x 80 x 3 = 19200 個 anchors。

如何從19200個anchors篩選出正樣本。
(1)假設 gt bbox 的中心點落在如上圖所示的 grid cell 中的左下方區域,根據規則(具體選grid cell的規則后面介紹)我們就讓3個grid cell一起來預測該gt box。
- 該grid cell
- 它左邊的grid cell
- 它下邊的grid cell

(2)將 gt box 的寬度和高度 分別和 3個 anchor 的寬度和高度做對比,選出適合的 anchors 用于預測 gt box (具體選擇anchors的規則之后介紹)。

這里假設 anchor 1 和 anchor 2 用于負責預測 gt box,對應正樣本。不負責預測的anchor 3對應負樣本。
所以,一共 80 x 80 x 3 = 19200 個 anchors 中,僅僅對于這feature map 1的一個 gt box 來說,有6個正樣本(3個grid_cell x 2個anchors),其他的都是負樣本。
選擇負責預測的grid cell的規則
規則為:如果ground truth中心點落在 grid cell 左上區域,那么本身和左還有上3個grid cell共同負責預測。
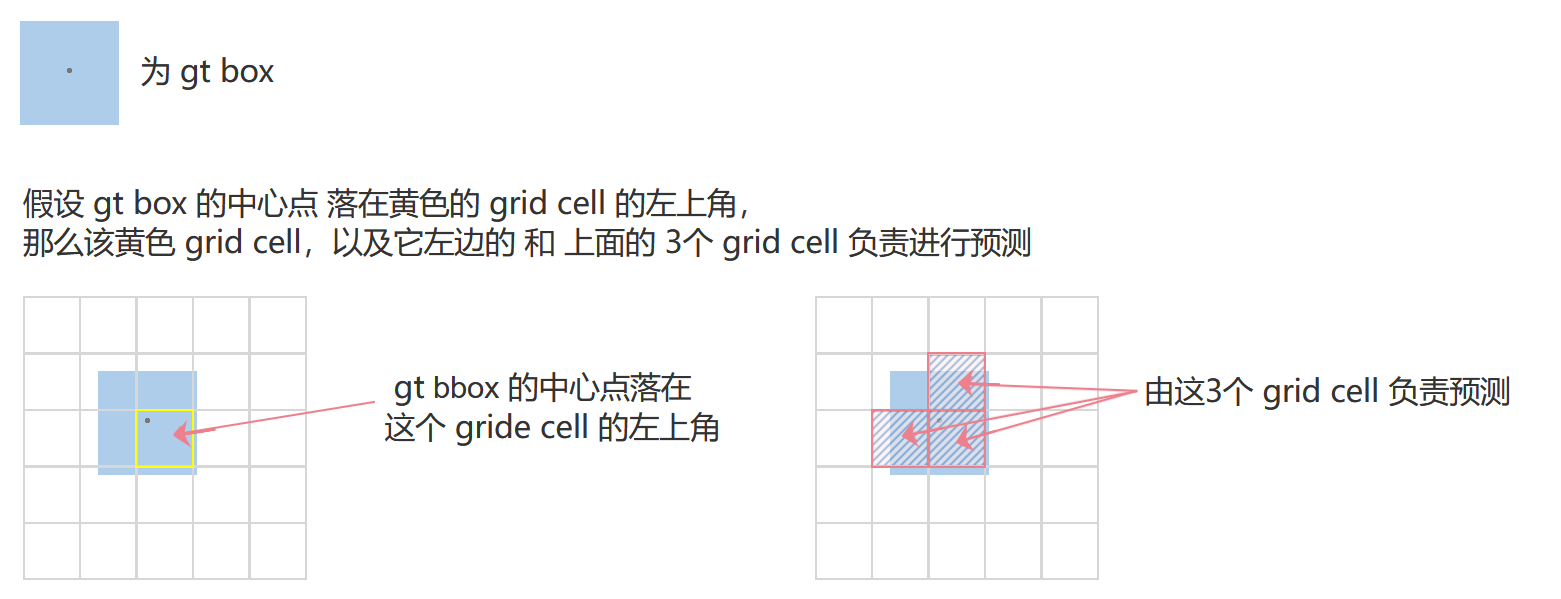
為什么是這三個grid cell,因為 gt box中心點所在的 grid cell 以及它的左側、上側、左上側的 4個 grid cell 的預測中心點位置都可能落在 該 grid cell 的左上角,其他的不行。
這里對gt box中心點所在的 grid cell 周圍一圈的grid cell 分析。圖中粉色 grid cell 對應的預測中心點的取值范圍為黃色區域

有四個grid cell的范圍覆蓋到了gt box的中心點,但官方實現時,僅使用 該 grid cell 左側 和上側的 grid cell 來一起進行預測,不使用 左上角的grid cell,可能是因為 左上角的 grid cell 預測中心點落在 該區域的概率太小,所以不進行考慮。

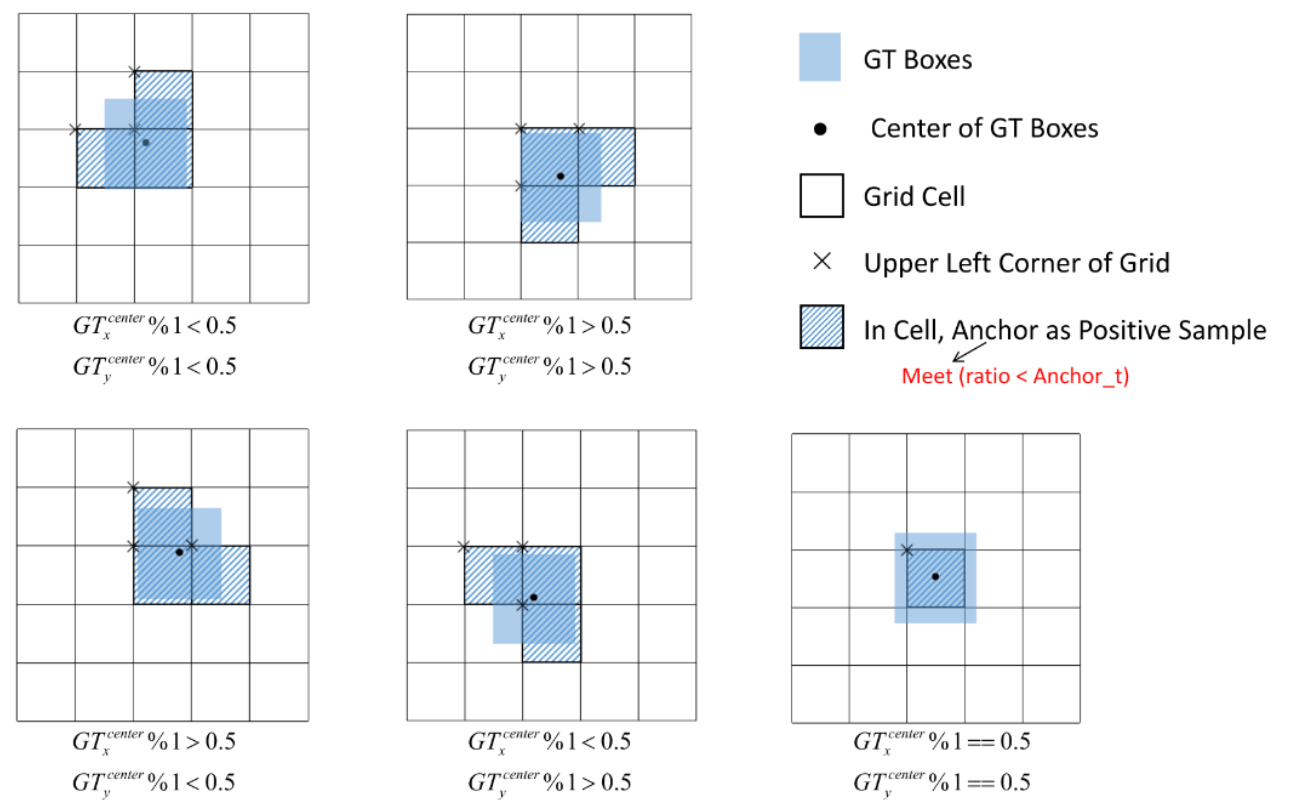
上面我們是以 gt bbox 的中心點落在 grid cell 左上角為例 來進行分析的,以下是 gt bbox 的中心點落在 grid cell 左上角、右上角,左下角、右下角的,中心點的所有情況。圖片來源:https://docs.ultralytics.com/yolov5/tutorials/architecture_description/#44-build-targets
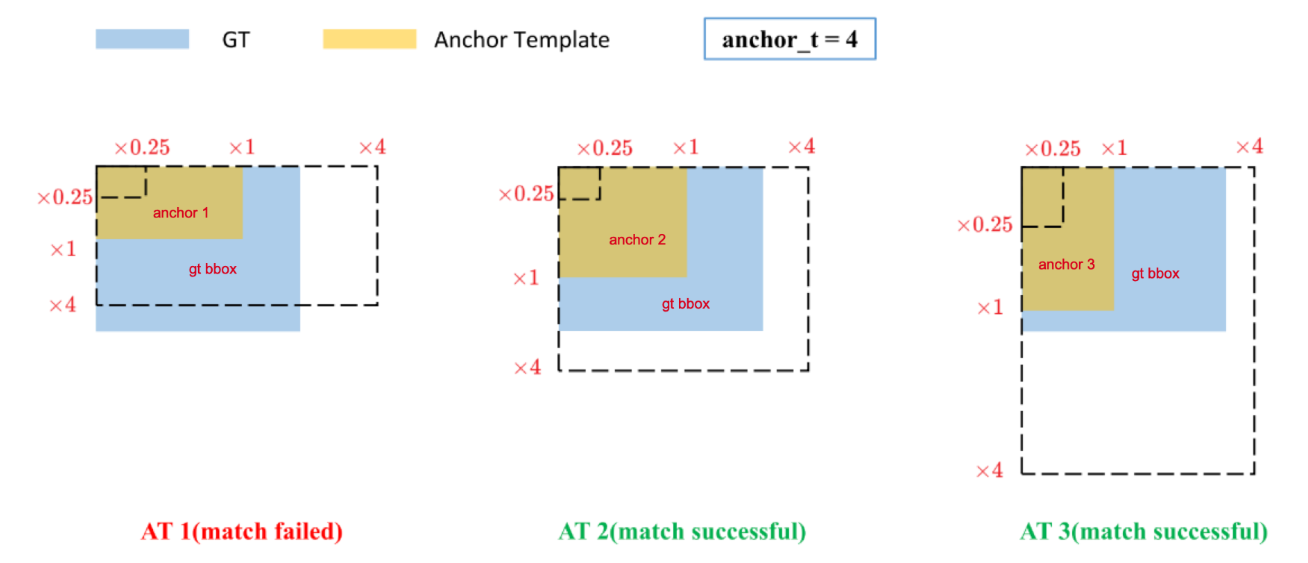
選擇負責預測的anchor的規則
選擇規則為:將 gt box 和 3個 anchors 比對寬度和高度, 如果滿足我們指定的條件,那么這個尺寸的 anchors 就負責預測這個 gt box。

指定的條件為:
max?(wgtwat,watwgt,hgthat,hathgt)<4\max\left( \frac{w_{\text{gt}}}{w_{\text{at}}},\ \frac{w_{\text{at}}}{w_{\text{gt}}},\ \frac{h_{\text{gt}}}{h_{\text{at}}},\ \frac{h_{\text{at}}}{h_{\text{gt}}} \right) < 4 max(wat?wgt??,?wgt?wat??,?hat?hgt??,?hgt?hat??)<4
翻譯與代碼:
j = torch.max(r, 1 / r).max(2)[0] < self.hyp["anchor_t"]
等價轉換后:
14<wgtwat,watwgt,hgthat,hathgt<4\frac{1}{4} < \frac{w_{\text{gt}}}{w_{\text{at}}},\ \frac{w_{\text{at}}}{w_{\text{gt}}},\ \frac{h_{\text{gt}}}{h_{\text{at}}},\ \frac{h_{\text{at}}}{h_{\text{gt}}} < 4 41?<wat?wgt??,?wgt?wat??,?hat?hgt??,?hgt?hat??<4
即兩個框的寬高比誤差分別不大于4倍。如圖:

舉例參考:https://docs.ultralytics.com/yolov5/tutorials/architecture_description/#44-build-targets
因為每個尺寸的特征圖都設計的三個尺寸的anchors,anchors長寬都放大4倍后分別和gt box對比,如果超出就為負樣本。比如圖匯總的anchor 1,而對于anchor 2 和 3是符合條件的。
注 : 同一個 gt bbox 可以由多個不同尺寸的 anchor 來進行預測
正樣本匹配代碼講解
代碼在官方build_targets函數中,代碼解釋圖






安裝Qt5.15.2)


和標準模式(Standards Mode)最明顯的區別)

:歸并排序)







)