【 聲明:版權所有,歡迎轉載,請勿用于商業用途。 聯系信箱:feixiaoxing @163.com】
? ? ? ? 如果最終部署在客戶現場的是一個嵌入式設備,那么上位機在做好了算法編輯和算法部署之后,很重要的一步就是處理上位機和下位機之間的通訊了。當然,我們可以通過一些開源庫來解決通信問題,比如xmlrpc。但是,我們有時候可能需要自定義協議來處理。自定義協議還是有很多好處的,比如說你的嵌入式設備只能和你的上位機進行通信。
? ? ? ? 這樣如果是自定義協議的話,那么有三個注意點就要小心一下。
1、CPU大小端
? ? ? ? 目前我們的筆記本電腦、臺式機都是x86或者x64 cpu,這些cpu都是小端結構。而報文協議一般都是大端結構。所謂的小端、大端,主要代表了數據字節的存儲次序。舉個例子來說,如果有一個整數是0x12345678,那么0x78如果保存在低端地址,那么cpu就是小端;如果0x12保存在低端地址,那么cpu就是大端。寫成函數就是這樣的,
bool isCpuLittleEndian()
{unsigned int val = 0x12345678;unsigned char* p = (unsigned char*)&val;return (*p == 0x78) ? true : false;
}? ? ? ? 既然是這樣,那我們在編寫報文的時候,就需要把數據從小端轉成大端結構。等到收到報文、解析報文的時候,再把數據從大端解析成小端。這個過程都是少不了的。
2、數據補齊
? ? ? ? 很多時候,編譯器考慮到cpu訪問數據的效率和便利,會有意、無意幫我們做數據對齊的動作。這些動作如果在平時,通常關系不大。但是通信的時候,我們的報文是要和別人的設備做數據交接的,這種情況下一個byte的偏移都是不應該的。所以,在上下文交互的時候,這種數據補齊必須是要避免發生的。舉個例子來說,下面這個結構體,
typedef struct _DataVal
{short a;char b;int c;
}DataVal;? ? ? ? 如果不做特殊處理的話,這個數據結構體的大小就是8。但是實際大小應該是7。因為short長度是2,char長度是1,int長度是4,所以整體長度是7。這個時候,如果我們不想編譯器幫助我們做數據補齊,應該怎么處理呢,
#pragma pack(1)
typedef struct _DataVal
{short a;char b;int c;
}DataVal;
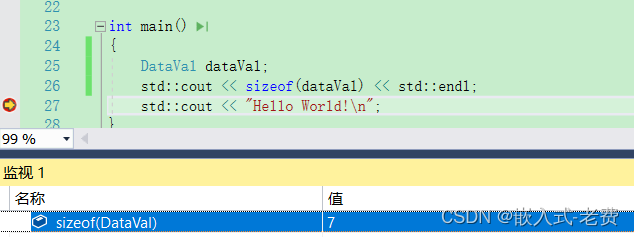
#pragma unpack? ? ? ? 這個語法目前在visual studio和gdb上都是支持的,大家自己可以好好測試下。通過測試,我們可以清楚地看到,加了pack之后,DataVal的大小是7。
3、json數據的使用
? ? ? ? 早期協議開發的時候,特別是協議還沒有穩定的時候,臨時增添數據、減少數據,這都是很常見的事情。另外,即使協議比較穩定,添加新的客戶需求,變更協議,這也不罕見。所以,建議大家可以在協議開發的時候,對于其中一部分內容,可以考慮用json保存和傳遞,還不用考慮字節序的問題。比如說,發送前,把json轉成字節碼。收到報文后,再恢復為json數據。雖然傳輸的效率效率有所降低,但是勝在穩定,易于拓展。朋友們可以在開發的過程中參考下。




——初始化列表)





優化函數,學習速率與反向傳播算法--九五小龐)
:閾值處理、掩膜和重新映射圖像)
)
_neuralforecast)





