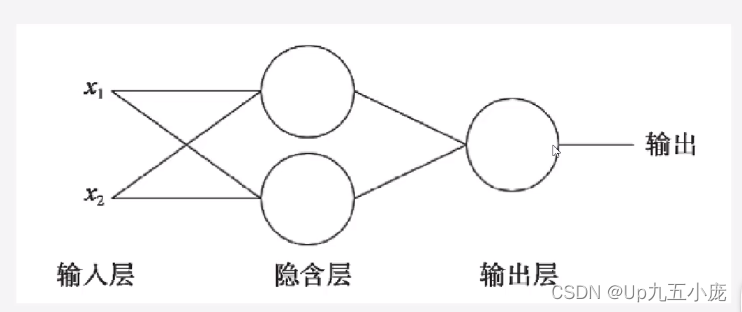
多層感知器
梯度下降算法
- 梯度的輸出向量表明了在每個位置損失函數增長最快的方向,可將它視為表示了在函數的每個位置向那個方向移動函數值可以增長。

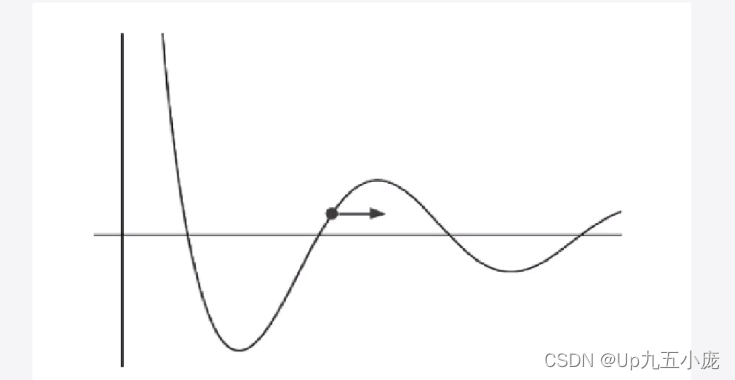
- 曲線對應于損失函數。點表示權值的當前值,即現在所在的位置。
- 梯度用箭頭表示,表明為了增加損失,需要向右移動。此外,箭頭的長度概念化地表示了如果在對應的方向移動,函數值能夠增長多少。如果向著梯度的反方向移動,則損失函數的值會相應減少。
學習速率
- 梯度就是表明損失函數相對參數的變化率,對梯度進行縮放的參數被稱為學習速率(learning rate)或可稱之為步長
- 學習速率是一種超參數或對模型的一種手工可配置的設置,需要為它指定正確的值。如果學習速率太小,則找到損失函數極小值點時可能需要許多輪迭代;如果太大,則算法可能會“跳過”極小值點并且因為周期性的“跳躍”而永遠無法找到極小值點。
- 在具體實踐中,可通過查看損失函數值隨時間變化曲線,來判斷學習速率的選取是否合適
- 合適的學習速率,損失函數隨時間下降,直到一個底部,不合適的學習速率,損失函數可能會發生震蕩
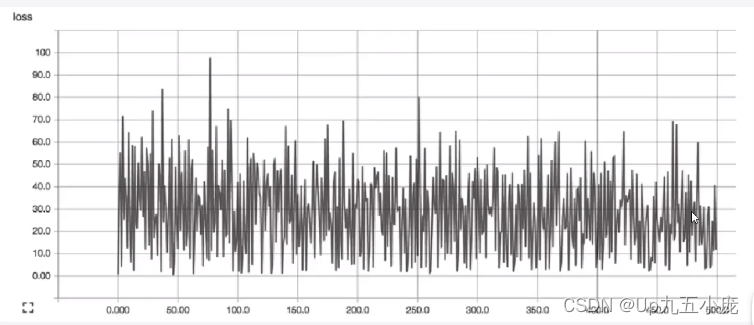
學習速率選取原則
- 在調整學習速率時,既要使其足夠小,保證不至于發生超調,也要保證它足夠大,以使損失函數能夠盡快下降,從而可通過較少次數的迭代更快的完成學習
反向傳播算法
- 反向傳播算法是一種高效計算數據流圖中梯度的技術,每一層的導數都是后一層的導數與前一層輸出之積,這正是鏈式法則的奇妙之處,誤差反向傳播算法利用的正是這一特點。
- 前饋時,從輸入開始,逐一計算每個隱含層的輸出,直到輸出層。
- 然后開始計算導數,并從輸出層經各隱含層逐一反向傳播。為了減少計算量,還需對所有已完成計算的元素進行復用。這便是反向傳播算法名稱的由來。
常見的優化函數
- 優化器(optimizer)是編譯模型的所需要的兩個參數之一。
- 可以先實例化一個優化器對象,然后將它傳入model.compile(),或者你可以通過名稱來調用優化器。在后一種情況下,將使用優化器的默認參數。
SGD:隨機梯度下降優化器
- 隨機梯度下降優化器SGD和min-batch是同一個意思,抽取m個小批量(獨立同分布)樣本,通過計算他們平梯度均值。
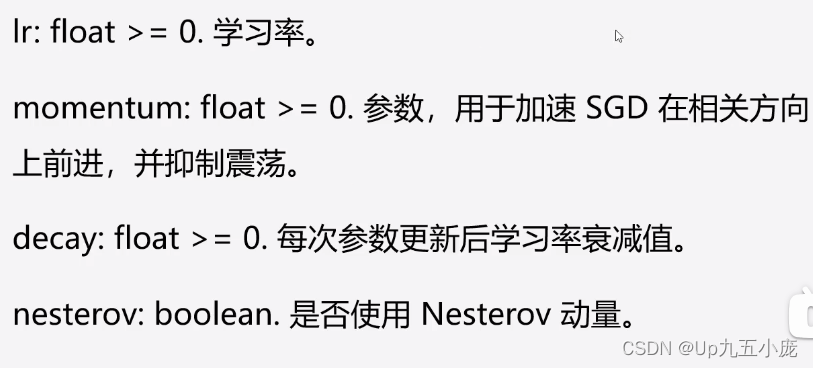
SGD參數
RMSprop:網絡優化算法
- 經驗上,RMSprop被證明有效且使用的深度學習網絡優化算法
- RMSprop增加了一個衰減系數來控制歷史信息的獲取多少,RMSprop會對學習率進行衰減。
- 建議使用優化器的默認參數(除了學習率lr,它可以被自由調節)
- 這個優化器你通常是訓練循環神經網絡RNN的不錯選擇。
Adam:Momentum+RMSprop
- Adam算法可以看做是修正后的Momentum+RMSprop算法
- Adam通常被認為對超參數選擇相當魯棒
- 學習率建議為0.0001
- Adam是一種可以替代傳統隨機梯度下降過程的一階優化算法,它能基于訓練數據迭代的更新神經網絡權重。
- Adam通過計算梯度的一階矩估計和二階矩估計而為不同的參數設計獨立的自適應性學習率
:閾值處理、掩膜和重新映射圖像)
)
_neuralforecast)












)



