4.堆
堆
- 一個Java程序(main方法)對應一個jvm實例,一個jvm實例只有一個堆空間
- 堆是jvm啟動的時候就被創建,大小也確定了。大小可以用參數設置。堆是jvm管理的一塊最大的內存空間 核心區域,是垃圾回收的重點區域
- 堆可以位于物理上不連續的內存空間中,但在邏輯上是連續的
- 所有的線程共享堆,堆里還有TLAB(線程私有的緩沖區 Thread Local Allocation Buffer)
- 所有的對象及數組分配在堆里(如果對象在方法里面沒有逃逸,理論上可以棧上分配,取決于jvm設計者的選擇)
- 在方法結束后,堆中的對象不會被馬上移除,垃圾回收時才會移除
- 內存細分:現代垃圾收集器大部分都基于分代收集理論設計
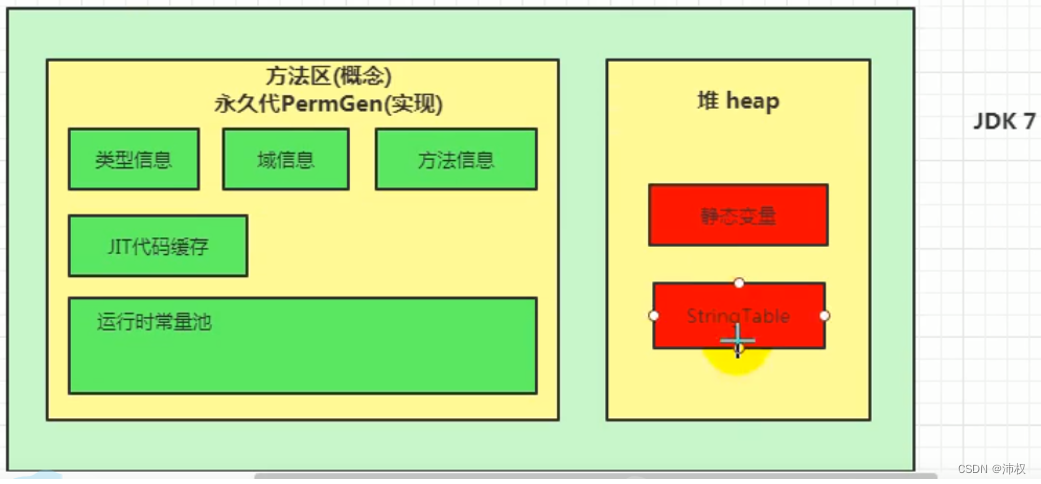
- 新生區=新生代=年輕代 養老區=老年區=老年代 永久區=永久代
- Java7及之前,堆內存邏輯上分為三部分:
- 新生代 Young/New Generation Space 又被分為 Eden區和 Survivor 0區 Survivor 1區(不空的為from區 空的為to區,to區是下一次要放的區域)
- 老年代 Old/Tenure Generation Space
- 永久代 Permanent Space
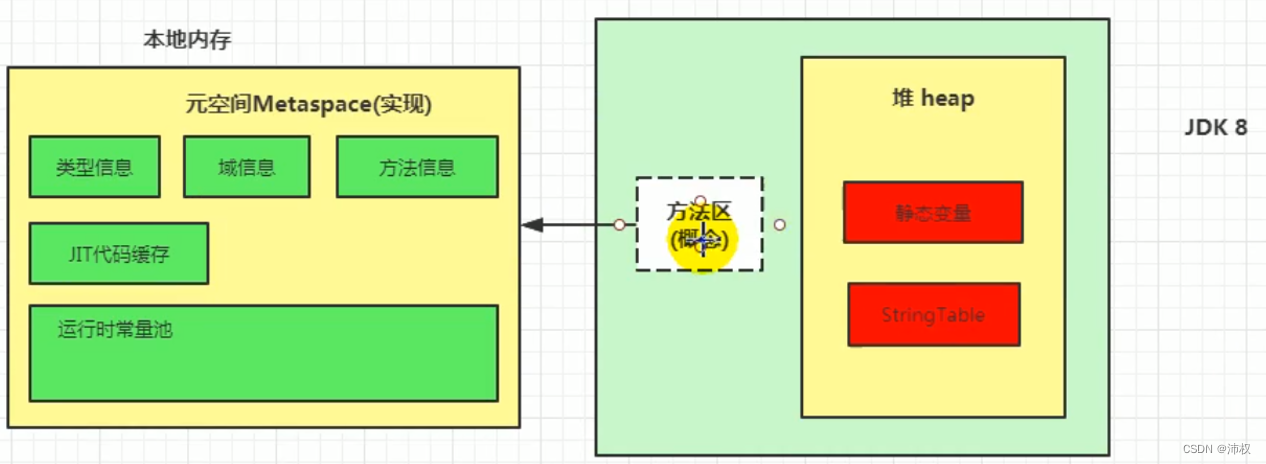
- Java8及之后,堆內存邏輯上分為三部分:新生代 老年代 元空間(Meta Space)
- 事實上,永久代 / 元空間 具體是方法區實現
- 當面試題問 jdk8內存結構有什么改變,要提出 永久代變成元空間
- 設置堆空間大小
- -Xms 用于設置堆空間(年輕代+老年代,不含元空間)初始大小(等價于 -XX:InitialHeapSize) 例子:-Xms10m
- -Xmx 用于設置堆空間最大大小(等價于 -XX:MaxHeapSize)例子:-Xmx10m
- 一旦堆空間超過 -Xmx 的值,就會報OOM
- 通常會設置 -Xms -Xmx為一樣的值,目的是為了能夠在Java垃圾回收完之后,不用再重新分隔計算堆區的大小,從而提高性能
- 默認情況下,初始內存 = 本機內存 / 64,最大內存 = 本機內存 / 4
- 查看堆空間大小
- java代碼中 用Runtime.getRuntime().totalMemory() / 1024 / 1024 可以看到堆空間大小 多少兆
- 【輸出的值和設置的值不一樣】因為survivor區只能用其中一個,所以所有加起來能用的區域就少一些
- 或者cmd ,jps查看當前Java程序的進程id ,然后jstat -gc 進程id (代碼加個 Thread.sleep() 執行長一些)
- 或者在vm參數加 -XX:+PrintGCDetails
- java代碼中 用Runtime.getRuntime().totalMemory() / 1024 / 1024 可以看到堆空間大小 多少兆
- 年輕代和老年代
- 堆中可以分成兩類對象
- 一種是生命周期較短的對象,創建和消亡十分迅速
- 另一種是生命周期比較長的對象,有些甚至和jvm生命周期一樣
- 配置年輕代和老年代的比例(一般用默認值)
- 默認:-XX:NewRatio=2,表示 年輕代/老年代 = 1/2,年輕代占堆 1/3
- 配置 Eden區和Survivor區比例(一般用默認值)
- 默認:-XX:SurvivorRatio=8 ,表示 Eden區:Survivor 0:Survivor 1=8:1:1
- 不過直接看不是這個比例,因為jvm有自適應的內存分配策略,可能可以用 -XX:-UseAdaptiveSizePolicy(不太管用)
- 可以顯式設置 -XX:SurvivorRatio=8
- 默認:-XX:SurvivorRatio=8 ,表示 Eden區:Survivor 0:Survivor 1=8:1:1
- 配置 Eden區最大大小(一般不用)【同時設置了比例和這個,以這個為準】
- -Xmn60m
- 幾乎所有的對象都是從Eden區new出來的(很大的除外,很大的對象在Eden區YGC之后還放不下就放Old區)
- 堆中可以分成兩類對象
- 對象分配過程
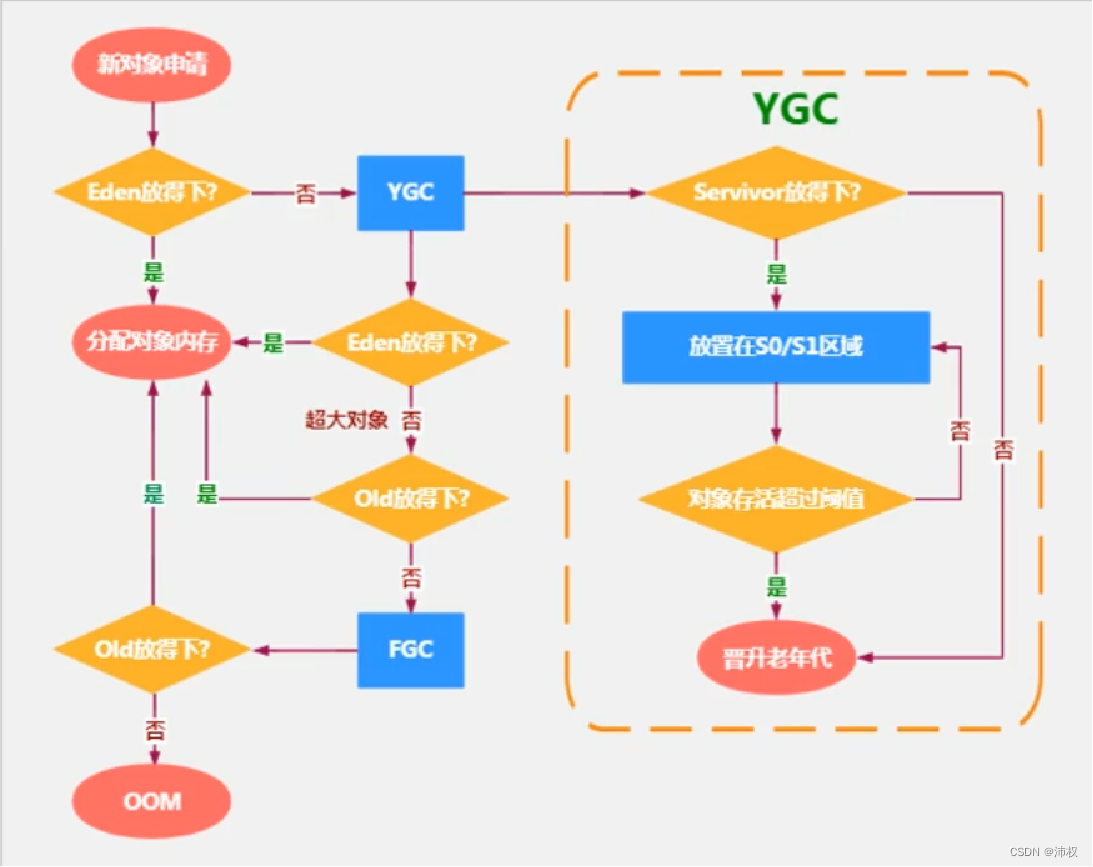
- 1.new的對象先分配到Eden區
- 2.如果Eden區滿了,會觸發young/minor gc,垃圾回收Eden區和Survivor區。Eden區 和 Survivor區中沒被回收的對象放到空的Survivor區,對象的age+1。然后再把新對象放到Eden區
- 3.如果這個對象過大,在Eden區YGC之后還放不下就放Old區
- 4.young gc后,當對象的age=15時,就是15次垃圾回收都沒有被回收,就會放到 Old區
- 這個次數可以設置。-XX:MaxTenuringThreshould=15
- 5.young gc后,當Survivor區滿了,會把Survivor區的對象放到Old區,即使不夠15次
- 6.young gc后,當Old區滿了,就會 Full gc
- (Survivor區滿了,不會觸發GC)
- 7.若Old區發生了Full gc 后,還是滿的,就會OOM
- 【s0,s1區,復制之后有交換,誰空誰是to】
- 【關于垃圾回收,頻繁Eden區,很少Old區,幾乎不在永久區/元空間】
- GC
- 針對hotspot jvm,按回收區域分為兩大類型:一種的部分收集(Partial GC),一種是整堆GC(full gc)
- 部分收集:在一部分堆空間進行垃圾回收
- 新生代收集 (Minor GC / Young GC):只收集Eden區 Survivor區
- 老年代收集(Major GC / Old GC):只收集 Old區
- 目前,只有CMS GC會有單獨收集老年代的行為
- 很多時候,Major GC 和 Full GC混用,需要具體分辨是老年代回收還是整堆回收【很多帖子混淆】
- 混合收集(Mixed GC)收集整個新生代及一部分老年代
- 目前,只有G1 GC有這種行為
- 整堆收集(Full GC):收集整個堆和方法區
- 年輕代GC(Minor GC)觸發機制:
- 當Eden區空間不足時觸發,Survivor區滿不觸發,清理的是Eden區和Survivor區
- 因為Java對象大都是朝生夕滅的,所以Minor GC非常頻繁,速度也比較快
- Minor GC會引發STW,暫停其他用戶線程,等垃圾回收結束,用戶線程才恢復執行
- 老年代GC(Major GC / Full GC 這樣說不正確其實)觸發機制:
- 發生在Old 區
- 出現Major GC 一般伴隨著一次Minor GC (但非絕對,在Parallel Scavenge收集器的收集策略里就有直接進行Major GC 的策略選擇過程)
- 也就是在老年代空間不足時,會先嘗試觸發Minor GC。但之后空間如果還不足,則觸發Major GC
- Major GC 的速度比Minor GC慢10倍以上,STW的時間更長
- 如果Major GC后,內存還不足,就OOM了
- Full GC觸發機制:(后面細講)
- 1.調用System.gc()時,系統建議使用Full GC,但是不必然執行
- 2.老年代空間不足
- 3.方法區空間不足
- 4.通過Minor GC 后進入老年代的平均大小大于老年代的可用內存
- 5.由Eden區,Survivor space0(From Space)區向Survivor space1(To Space)區進行復制時,對象大于To Space可用內存,則把對象轉存到老年區,且老年區的可用內存小于該對象大小
- Full GC 是開發或調優中要盡量避免的,這樣暫停時間短一點
- 為什么要把Java堆分代?不分代就不能工作嘛?
- 其實不分代可以,分代是為了優化GC性能。不分代的話,就要掃描整個堆。掃描范圍大,比較耗時。而進行分代,把新創建的對象放到一個區域,因為大部分的對象生命周期很短,那么就可以對這個區域進行頻繁GC。不用掃描整個堆,提高效率、
- 內存分配策略(或晉升(Promotion)規則)
- 優先分配到Eden區
- 大對象直接分配到老年代
- 盡量避免程序中出現過多的大對象(不僅僅是因為占很多空間,容易導致頻繁Major GC或Full GC。而且因為這些大對象大部分生命周期也很短,往往是Major GC或Full GC之后就被清楚掉,不值得放到老年代)
- 長期存活的對象分配到老年代
- 動態對象年齡判斷
- 如果Survivor區中相同年齡的所有對象大小的總和大于Survivor空間的一半,年齡大于或等于該年齡的對象可以直接進入老年代,無需等到MaxTenuringThreshold中要求的年齡
- 空間分配擔保
- -XX:HandlePromotionFailure 【Java7及以后,相當于默認開啟此參數,改變設置也不起作用】
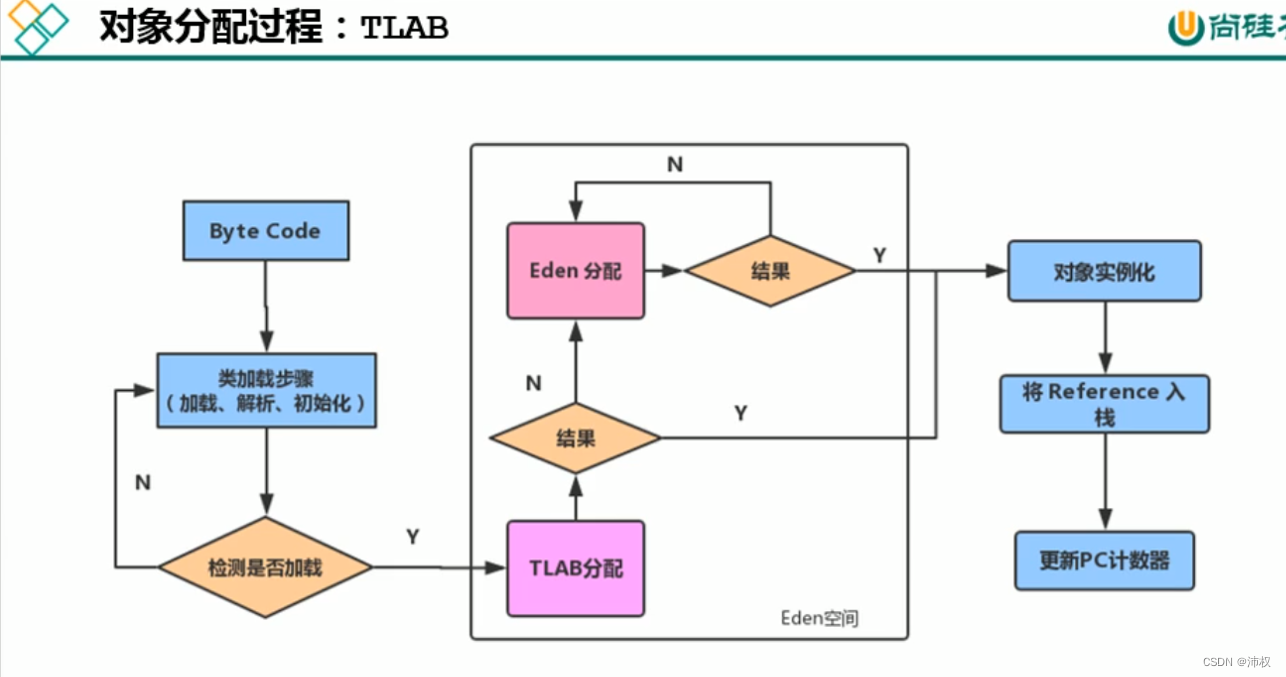
- TLAB——堆全部都是共享的嘛?不是
- 為什么有TLAB:因為堆是線程共享區域,而對象實例的創建在jvm中非常頻繁,因此在并發環境下從對中劃分空間是線程不安全的。為了避免多個線程操作同一地址,需要加鎖的話,就會影響分配速度。有了TLAB,對象在TLAB里創建就不會有線程安全問題
- 盡管不是所有的對象都能在TLAB內創建,但是TLAB確實是jvm內存分配的首選
- 所有OpenJDK衍生出的jvm都有TLAB
- -XX:UseTLAB 設置是否開啟TLAB空間,默認開啟
- TLAB很小,默認占Eden區 1%
- -XX:TLABWasteTargetPercent 設置TLAB占Eden百分比大小
- 一旦對象在TLAB分配失敗,就會在Eden中分配,使用時要加鎖
- 棧上分配—逃逸分析—堆是對象分配的唯一選擇嘛?是(逃逸分析->棧上分配),也可以不是(取決于jvm設計者要不要在棧上分配)
- 如果一個對象經過逃逸分析,發現沒有逃逸,那么就會在棧上分配(不分配到堆上,減少GC壓力)
- 而淘寶的TaoBaoVM,其中的GCIH(GC invisible heap)技術實現off-heap,將生命周期較長的Java對象從heap中移至heap外,并且GC不能管理GCIH內的Java對象,從而降低GC回收頻率,提升GC回收效率
- **逃逸分析:**如果在方法內使用的對象,它會在除本方法外的其他地方用到,那就是逃逸
- 比如:作為參數傳入,通過return返回,給對象屬性賦值,使用對象屬性
- 逃逸分析其實并不成熟。根本原因是無法保證做了逃逸分析的性能一定比不做好,因為逃逸分析也是一個相對耗時的過程。極端點就是經過逃逸分析發現沒有一個對象是逃逸的,那么分析的過程就白白浪費了一些性能。
- 雖然不成熟,但是也是即時編譯器優化技術中一個十分重要的手段。
- 重點:【通過逃逸分析,jvm會在棧上分配那些不會逃逸的對象,這種理論上是可行的,但是這取決于jvm設計者的選擇。Oracle Hotspot JVM中并沒有這樣做,這一點在逃逸分析相關的文檔里已經說明,所以,可以明確所以的對象實例都是創建在堆上。在實際代碼測試中,運行速度加快,是因為雖然沒有在棧上分配,但是jvm做了標量替換,加快了速度】
- 參數設置:
- 在Java7及以后,Hotspot默認開啟逃逸分析
- 如果使用的是較早的版本
- -XX:+DoEscapeAnalysis 顯式開啟逃逸分析
- -XX:+PrintEscapeAnalysis 查看逃逸分析的篩選結果
- 所以,能使用局部變量,就不要在方法外定義
- 使用逃逸分析,jvm能做的優化
- 1.棧上分配
- 2.同步省略 / 鎖消除:在動態編譯同步塊時,就是運行時,JIT編譯器通過逃逸分析判斷個對象是否只能從一個線程被訪問到。如果是,那么JIT編譯器在編譯這個同步塊時會取消對這部分代碼的同步。大大提高性能和并發(不過字節碼文件還是顯示有鎖的)
- 3.分離對象或標量替換:【簡單的說就是不用對象,而是創建幾個和對象屬性對應的變量】有的對象可能不需要作為一個連續的內存結構存在也可以被訪問到,那么對象的部分(或全部)可以不存儲在堆,而是存儲在棧中
- 標量就是一個無法再分解成更小數據的數據。聚合量就可以再分解。對象就是聚合量
- JIT階段,如果經過逃逸分析,發現對象不會逃逸,就會把那個對象分解成若干個標量。這個過程就是標量替換【比如下面兩張圖】
- 標量替換可以減少對象的創建,減少堆內存的分配,大大減少堆內存的占用。為棧上分配提供了很好的基礎
- 參數:-XX:+EliminateAllocations 開啟了標量替換,默認開啟,允許將對象打散分配在棧上

- 常用命令
- -XX:+PrintFlagsInitial:查看所有的參數的默認初始值
- -XX:+PrintFlagsFinal:查看所有的參數的最終值(可能會存在修改,不再是初始值)
- -Xms:初始堆空間內存(默認為物理內存的1/64)【常用】
- -Xmx:最大堆空間內存(默認為物理內存的1/4)【常用】
- -Xmn:設置新生代的大小。(初始值及最大值)
- -XX:NewRatio:配置新生代與老年代在堆結構的占比
- -XX:SurvivorRatio:設置新生代中Eden和s0/S1空間的比例
- -Xx:MaxTenuringThreshold:設置新生代垃圾的最大年齡 【常用】
- -XX:+PrintGCDetails:輸出詳細的GC處理日志 【常用】
- 打印gc簡要信息:1.-XX:+PrintGC 2.-verbose:go
- -XX:UseTLAB 設置是否開啟TLAB空間,默認開啟
- -XX:TLABWasteTargetPercent 設置TLAB占Eden百分比大小
- -XX:+DoEscapeAnalysis 顯式開啟逃逸分析,默認開啟
- -XX:+PrintEscapeAnalysis 查看逃逸分析的篩選結果 【常用】
- -XX:+EliminateAllocations 開啟了標量替換,默認開啟,允許將對象打散分配在棧上
- -XX:HandlePromotionFailure:是否設置空間分配擔保 【Java7及以后,相當于默認開啟此參數,改變設置也不起作用】

5.方法區 / 元空間
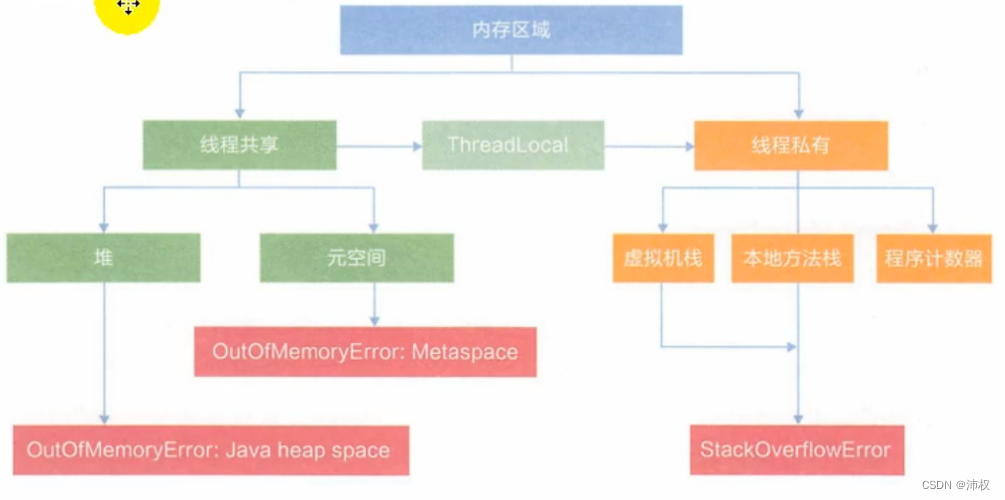
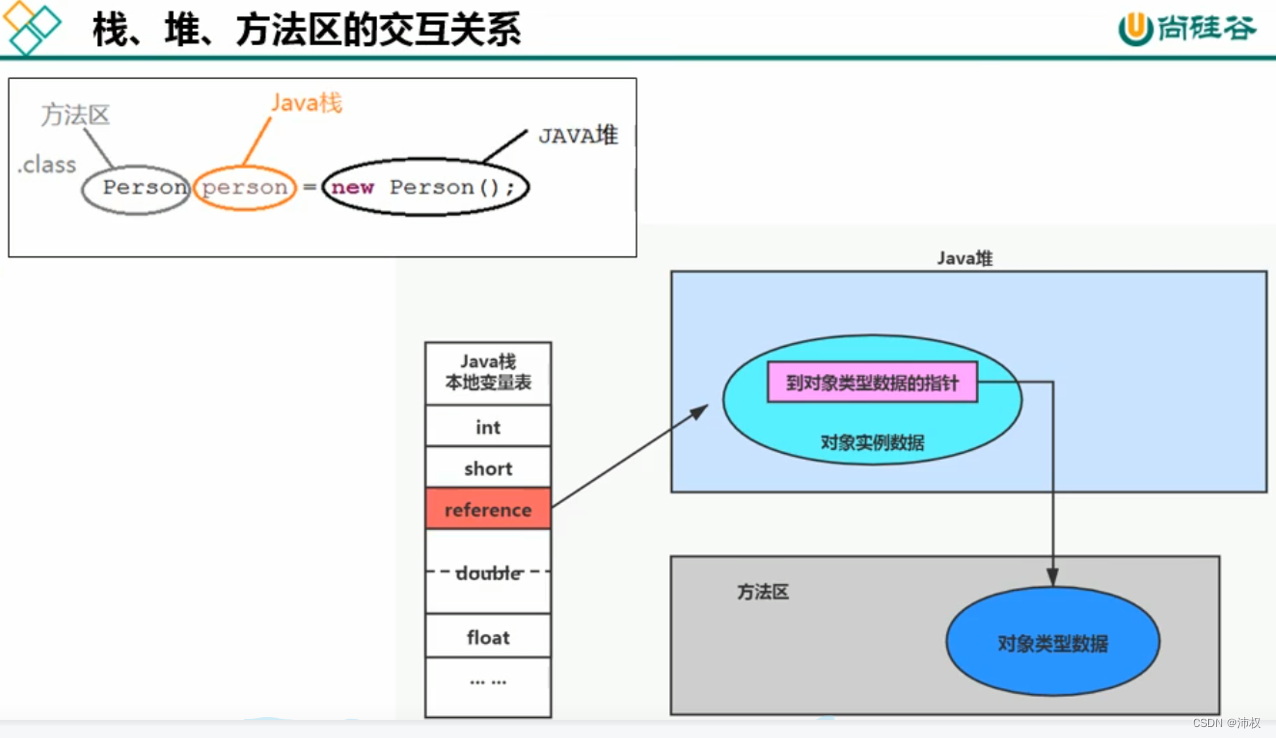
(對象類型數據 就是 類的數據)
方法區 / 元空間
- 方法區(Method Area)與Java堆一樣,是各個線程共享的內存區域。
- 方法區在JVM啟動的時候被創建,并且它的實際的物理內存空間中和Java堆區一樣都可以是不連續的。
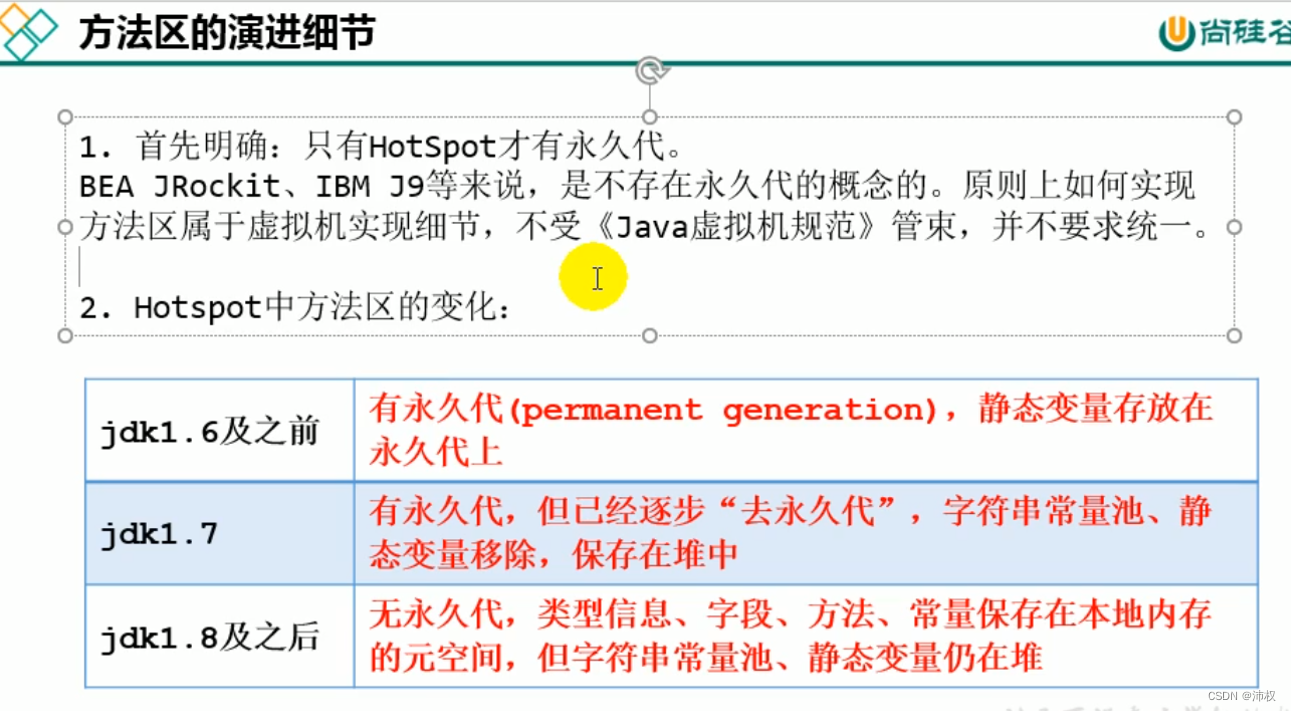
- 在Jdk7及以前,習慣把方法區稱為永久代。Jdk8及以后,永久代變成了元空間
- 本質上,方法區和永久代不等價。僅是對Hotspot而言是等價的。《Java虛擬機規范》對如何實現方法區,不做統一要求。例如:BEA 的 JRockit / IBM 的 J9不存在永久代的概念
- 現在看來,當年用永久代,不是一個好想法。因為它導致Java程序更容易OOM(超過 -XX:MaxPermSize上限)
- 元空間與永久代類似,都是對jvm規范中方法區的實現。他們最大的區別在于:元空間不是使用Java虛擬機的內存,而是使用本地內存
- 元空間不僅僅是名稱變了,內部結構也變了
- 方法區的大小,跟堆空間一樣,可以選擇固定大小或者可擴展。
- jdk7及以前
- -XX:PermSize=60m 來設置永久代初始分配空間。默認值是20.75m
- -XX:MaxPermSize=60m 來設置永久代最大可分配空間。32位機器默認64m,64位機器默認82m
- 當jvm加載的類超過最大大小,會報 java.lang.OutofMemoryError:PermGen space
- jdk8及以后
- 元數據區大小可以使用參數-XX:MetaspaceSize=100m和-XX:MaxMetaspaceSize指定
- 默認值依賴于平臺。window下,-XX:MetaspaceSize是21m,-XX:MaxMetaspaceSize是-1,即沒有限制,會一直用系統內存
- jdk7及以前
- 高水位線(在jdk8及以后)
- 初始的高水位線 和 -XX:MetaspaceSize的值一樣。一旦元空間大小觸及到這條線,Full GC就會被觸發并卸載沒用的類(即這些類對應的類加載器不再存活),然后這個高水位線就會被重置。新的高水位線的值取決于GC后釋放了多少元空間。如果釋放的空間不足,那么在不超過MaxMetaspaceSize時,適當提高改值。如果釋放的空間過多,適當降低該值。
- 如果初始的 高水位線設置過低,上述 高水位線調整情況會發生很多次,也會頻繁Full GC。建議將-XX:MetaspaceSize設置為一個相對較高的值
- 方法區的大小決定了系統可以保存多少個類,如果系統定義了太多的類,導致方法區溢出,虛擬機同樣會拋出內存溢出錯誤:java.lang.OutofMemoryError:PermGen space (java7及之前) 或者 java.lang.OutofMemoryError:Metaspace(java8及以后)
- 加載大量的第三方的jar包會OOM:Tomcat部署的工程過多(30-50個) , 大量動態的生成反射類
- 關閉JVM就會釋放這個區域的內存。
- OOM的例子:


- 方法區存的內容
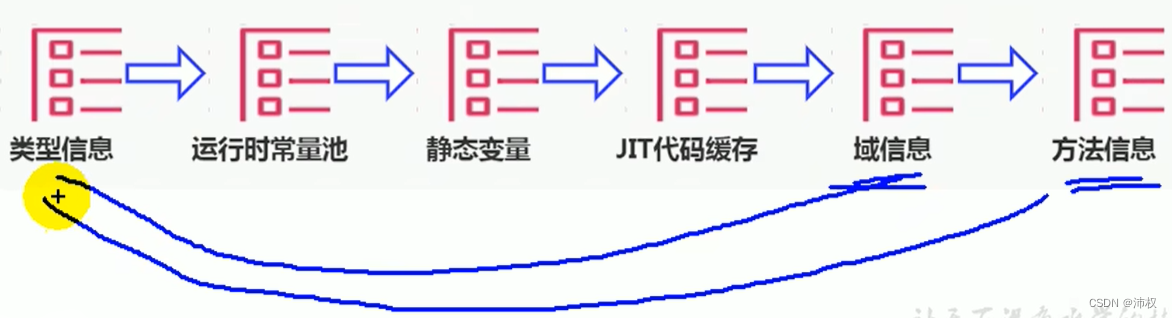
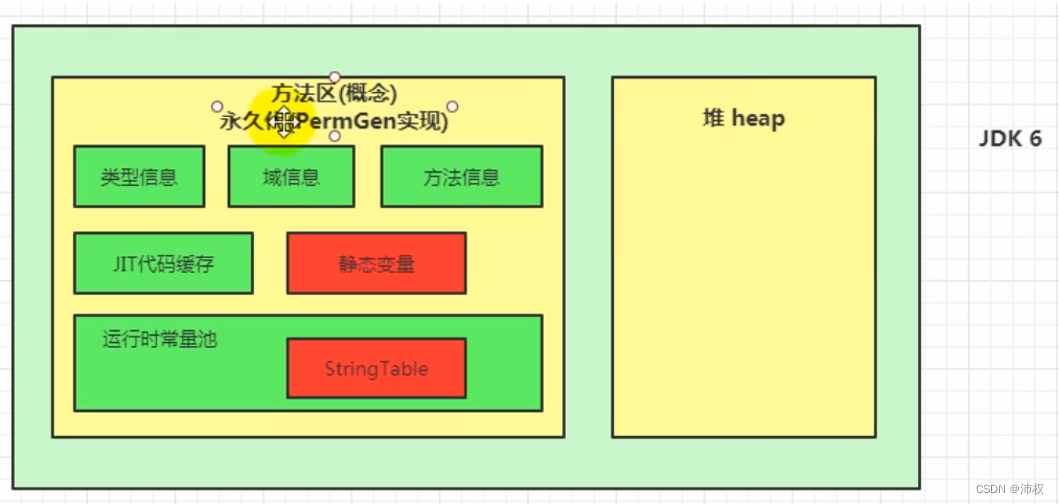
- 存放已被虛擬機加載的類型信息,常量,靜態變量,JIT即時編譯器編譯后的代碼緩存等。(隨jdk版本不同,會有些變化)
- 類型信息(類,接口,枚舉,注解)
- 這個類型的完整有效名稱(全名=包名.類名)
- 這個類型直接父類的完整有效名(對于接口和Object類都沒有父類)
- 這個類型的修飾符(public,abstract,final的某個子集)
- 這個類型實現的接口的一個有序列表
- 域(Field)信息(就是類的屬性信息)
- jvm必須在方法區中保存類型的所有域的相關信息以及域的聲明順序
- 域的相關信息包括:域名稱、域類型、域修飾符(public,private,protected,static,final,volatile,transient的某個子集)
- 方法(Method)信息
- jvm必須在方法區中保存所有方法的以下信息以及域的聲明順序
- 方法名稱
- 方法的返回類型(或 void)
- 方法參數的數量和類型(按順序)
- 方法的修飾符(public,private,protected,static,final,synchronized,native,abstract的一個子集)
- 方法的字節碼(bytecodes)、操作數棧、局部變量表及大小(abstracth和native方法除外)
- 異常表(abstracth和native方法除外)
- 每個異常處理的開始位置、結束位置、代碼處理在程序計數器中的偏移地址、被捕獲的異常類的常量池索引
- 類變量(static)
- 沒加final的:靜態變量和類關聯在一起,隨著類的加載而加載,它們成為類數據在邏輯上的一部分,但是放到堆中
- 加了final的:在編譯期就確定下來了,放到元空間
- 運行時常量
- 方法區中的運行時常量池和字節碼文件中的常量池的對應起來的
- Java中的字節碼需要數據支持,通常這種數據很大不能直接放到字節碼文件中,換另一種方式,可以存到常量池,在動態鏈接時再引用進來
- 字節碼的常量池包括各種字面量,和對類型、域、方法的符號引用
- jvm為每個已加載的類型(類或接口)都維護一個常量池,通過索引訪問
- 運行時常量池 把 字節碼文件的常量池中的符號引用 轉成了直接引用
- 運行時常量池 相當于Class文件常量池的另一重要特征是:具備動態性(有些沒有的東西會自動加進去)
- 運行時常量池類似于傳統編程語言中的符號表(symbol table),但是它所包含的數據卻比符號表要更加豐富一些
- 如果創建運行時常量池超過方法區的最大值,會OOM
- 方法區中的運行時常量池和字節碼文件中的常量池的對應起來的
- 還包含了加載這個字節碼文件的 類加載器
- 方法區的演進細節
-
jdk1.6及之前,有永久代,靜態變量存放在永久代上
-
jdk1.7,有永久代,但已經逐步“去永久代”,字符串常量池、靜態變量保存到堆中
-
jdk1.8及以后,無永久代,類型信息、字段、方法、常量保存在本地內存的元空間。但字符串常量池,靜態變量仍然在堆中
-
【要注意:如果靜態變量是對象的引用。比如:public static a = new int[10] 無論是哪個jdk,數組都是在堆中。因為它是被new 出來的對象。而變量a在不同jdk的位置就不一樣】
-
- 為什么元空間要替代永久代?
- 1.為永久代設置大小是很難的。設置小了在某些場景下容易OOM,特別是要動態加載很多類的時候。設置大了浪費空間。元空間使用本地內存,不用設置,僅僅受內存大小的限制
- 2.對永久代進行調優是很困難的。Full GC的時候會對方法區的垃圾回收。判斷類型信息是否要清理比較滿分。所以Full GC比較麻煩,調優也比較困難。用本地內存,空間大一些,Full GC也會少一些
- 為什么StringTable要放到堆里
- jdk7中將StringTable放入堆中。因為永久代很少進行垃圾回收,只有觸發Full GC的時候才會進行清理。Full GC只有在老年代空間不足,或者永久代空間不足才會觸發,這就導致StringTable的回收效率不高。在運行過程中,大量的字符串常量被創建,很多都是不用的,放到堆中可以及時清理
- 方法區的垃圾回收
- 有的虛擬機支持方法區GC,有的沒有GC。Java的虛擬機規范對方法區的約束很寬松,方法區實不實現垃圾回收都可以。(JDK 11的ZGC收集器就不支持類卸載)
- 方法區的回收效果比較難以讓人滿意,尤其是類型的卸載,條件很苛刻。但是這部分區域的回收有時又確實是必要的。以前Sun公司的Bug列表中,曾出現的幾個嚴重的BUG就是因為低版本的hotspot對方法區未完全回收導致內存泄露
- 主要回收兩部分內容:常量池中廢棄的常量 以及 不再使用的類型
- 常量包括字面量 和 符號引用
- 符號引用包括,類和接口的全限定名,字段的名稱和描述符,方法的名稱和描述符
- 常量只要沒有地方使用 就可以回收
- 但是類型是否回收的判斷條件很苛刻,下面是被回收的前提(但是滿足了也不一定會回收)
- 1.該類沒有實例。也沒有任何派送子類的實例
- 2.加載該類的類加載器已經被回收。除非是精心設計的可替換類加載器的場景,比如OSGI,JSP的重加載等,否則很難達成
- 3.該類對應的java.lang.class對象沒有被任何地方引用,無法在任何地方通過反射訪問該類的方法
- Java虛擬機被允許對滿足上述三個條件的無用類進行回收,這里說的僅僅是“被允許”,而并不是和對象一樣,沒有引用了就必然會回收。關于是否要對類型進行回收,HotSpot虛擬機提供了-Xnoclassgc參數進行控制,還可以使用-verbose:class以及-XX:+Traceclass-Loading、-XX:+TraceClassUnLoading查看類加載和卸載信息
- 常量包括字面量 和 符號引用
- 在大量使用反射、動態代理、CGLib等字節碼框架,動態生成JSP,以及OSGi這類頻繁自定義類加載器的場景中,通常需要Java虛擬機具備類型卸載的能力,以保證不會對方法區造成過大的內存壓力。













![[計算機網絡]--五種IO模型和select](http://pic.xiahunao.cn/[計算機網絡]--五種IO模型和select)





)

)