目錄
4.缺省參數
4.1缺省參數的概念
4.2缺省參數分類
4.3聲明和定義分離(聲明使用缺省參數)
4.🐍聲明和定義分離到鏈接
5.函數重載
5.1函數重載的概念
5.2可執行程序的形成步驟
5.3C++支持函數重載的原理—名字修飾(name Mangling)
4.缺省參數
4.1缺省參數的概念
缺省參數是聲明或定義函數時為函數的參數指定一個缺省值。在調用該函數時,如果沒有指定實參則采用該形參的缺省值,否則使用指定的實參。缺省參數又叫默認參數。
#include<iostream>
using namespace std;void Func(int a = 0)
{cout << a << endl;
}
int main()
{Func(); // 沒有傳參時,使用參數的默認值Func(10); // 傳參時,使用指定的實參return 0;
}
4.2缺省參數分類
- 全缺省參數
- 半缺省參數
- 函數在給半缺省參數,必須是從右往左連續依次給出,不能間隔跳躍。(從第一個開始)
- 調用函數傳參:必須從左到右連續傳參,不能跳躍。(從第一個開始)
- 形式參數是實際參數的一份臨時拷貝。
- 缺省參數不能在函數聲明和定義中同時出現,若有聲明只能在聲明中出現。
- 缺省值必須是常量或者全局變量。
- C語言不支持(編譯器不支持。
//全缺省參數
void Func(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}
//半缺省參數
void Func(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}//給半缺省參數
#include<iostream>
using namespace std;
//半缺省參數
void Func2(int a, int b = 10, int c = 20)
void Func2(int a, int b , int c = 20)
void Func2(int a, int b, int c)
//?void Func2(int a, int b = 10, int c)
//?void Func2(int a=10, int b, int c = 20)
{cout << "a = " << a ;cout << "b = " << b ;cout << "c = " << c ;cout << endl;
}//調用傳參
#include<iostream>
using namespace std;
//全缺省參數
void Func1(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a ;cout << "b = " << b ;cout << "c = " << c ;cout << endl;
}
int main()
{Func1(1, 2, 3);Func1(1, 2);Func1(1);Func1();//Func1(, 2, );//?return 0;
}?
4.3聲明和定義分離(聲明使用缺省參數)
如果聲明與定義位置同時出現缺省參數,恰巧兩個位置提供的值不同,那編譯器就無法確定到底該用那個缺省值?
在聲明處給缺省參數。因為.cpp在預處理階段會展開頭文件.h。會把.h的聲明拷貝到.cpp里面。在后面編譯階段,檢查語法也不會出錯。
?//a.hvoid Func(int a = 10);//a.cppvoid Func(int a = 20)
{///
}
// 注意:如果聲明與定義位置同時有缺省參數,
//恰巧兩個位置提供的值不同,那編譯器就無法確定到底該用那個缺省值。4.🐍聲明和定義分離到鏈接
tips:
從語法的角度:函數名就是函數的地址。
從底層的角度:函數調用的本質是call? 函數(地址)(物理空間是連續的)
地址是函數的地址。函數底層也是一堆指令。也就是函數底層指令的第一條指令的地址。
CPU執行也是執行指令。?
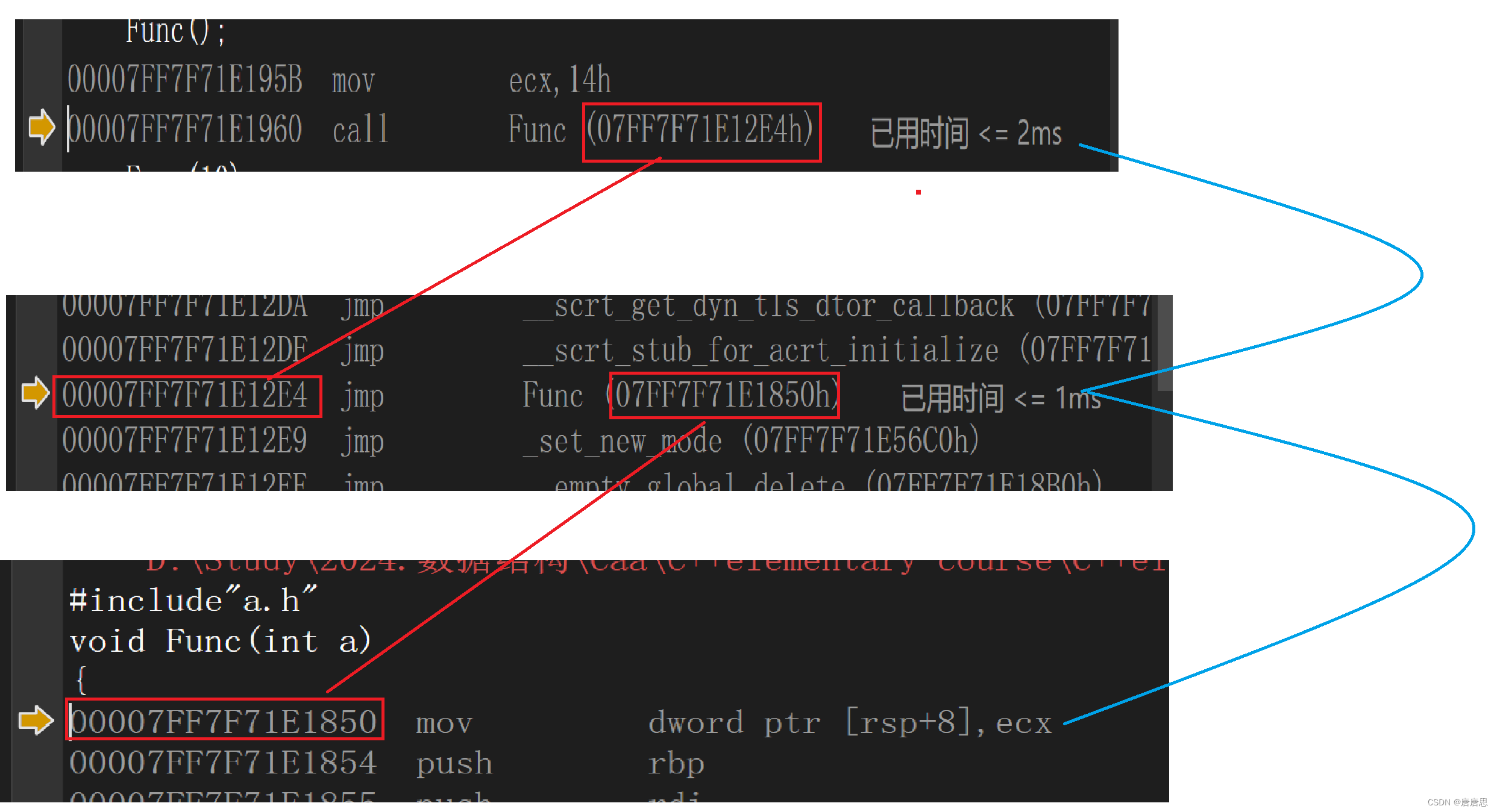
聲明和定義分離,編譯階段檢查語法,call Func(?)里面是沒有地址的,還沒有鏈接。那編譯階段檢查語法為什么不會報錯。(前面預處理/編譯/匯編階段是各自走各自的)
- 編譯階段:語法檢查(自定義類型/變量/函數 搜索出處)
- 在匯編階段,編譯器就只是搜索找到聲明(承諾)
- 在鏈接階段,形成了符號表。
- 編譯器去符號表里搜索,找到函數定義(兌現承諾)
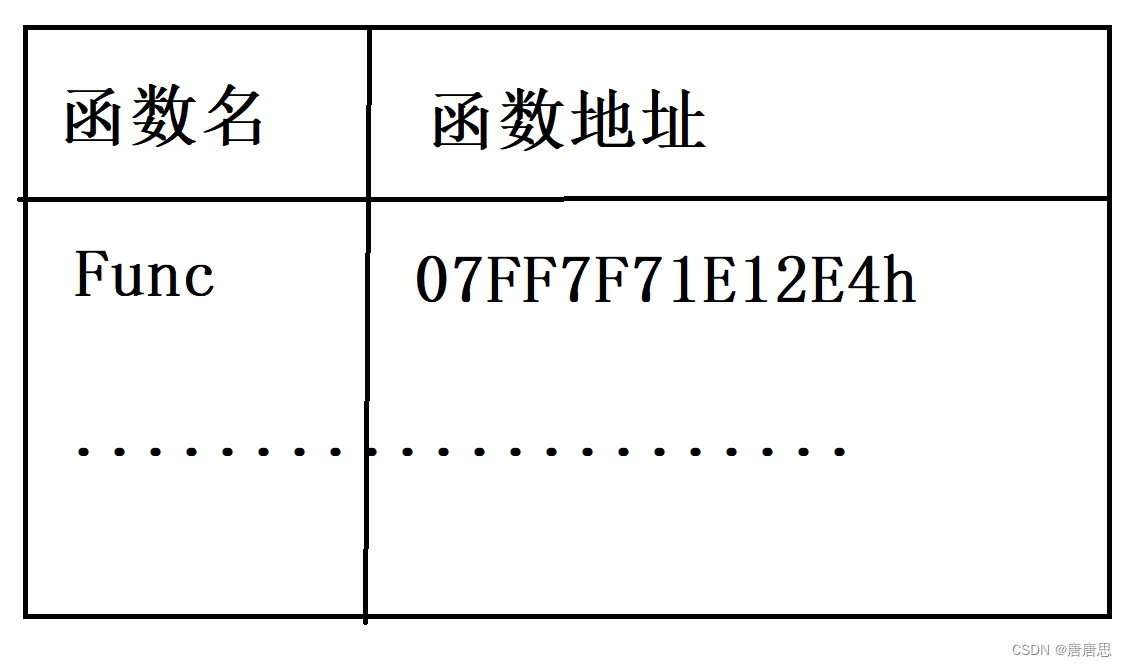
- 編譯器把函數定義的地址放到 call Func(07FF7F71E12E4h)
- 符號表

//"a.cpp"
#include"a.h"
void Func(int a)
{cout << a << endl;
}//"a.h"
#pragma once
#include<iostream>
using namespace std;
void Func(int a =20);//test.cpp
#include"a.h"
int main()
{Func();Func(10);return 0;
}在編譯階段沒有找到聲明:語法錯誤?
在鏈接階段沒有找到定義:鏈接?


5.函數重載
自然語言中,一個詞可以有多重含義,人們可以通過上下文來判斷該詞真實的含義,即該詞被重載了。函數重載也就是一詞多義。
比如:以前有一個笑話,國有兩個體育項目大家根本不用看,也不用擔心。一個是乒乓球,一個是男足。前者是“誰也贏不了!”,后者是“誰也贏不了!”?
5.1函數重載的概念
函數重載:是函數的一種特殊情況,C++允許在同一作用域中聲明幾個功能類似的同名函數,這些同名函數的形參列表(參數個數 或 類型 或 類型順序)不同,常用來處理實現功能類似數據類型不同的問題。
- C語言不允許同名函數
- C++語言允許同名函數。
- 要求:函數名相同,參數不同,構成函數重載。(編譯器會根據數據類型自動匹配)
- 參數不同:
- 參數類型不同
- 參數個數不同
- 參數類型順序不同
#include<iostream>
using namespace std;
// 1、參數類型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}// 2、參數個數不同
void f()
{cout << "f()" << endl;
}
void f(int a)
{cout << "f(int a)" << endl;
}// 3、參數類型順序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}int main()
{Add(10, 20);Add(10.1, 20.2);f();f(10);f(10, 'a');f('a', 10);return 0;
}5.2可執行程序的形成步驟
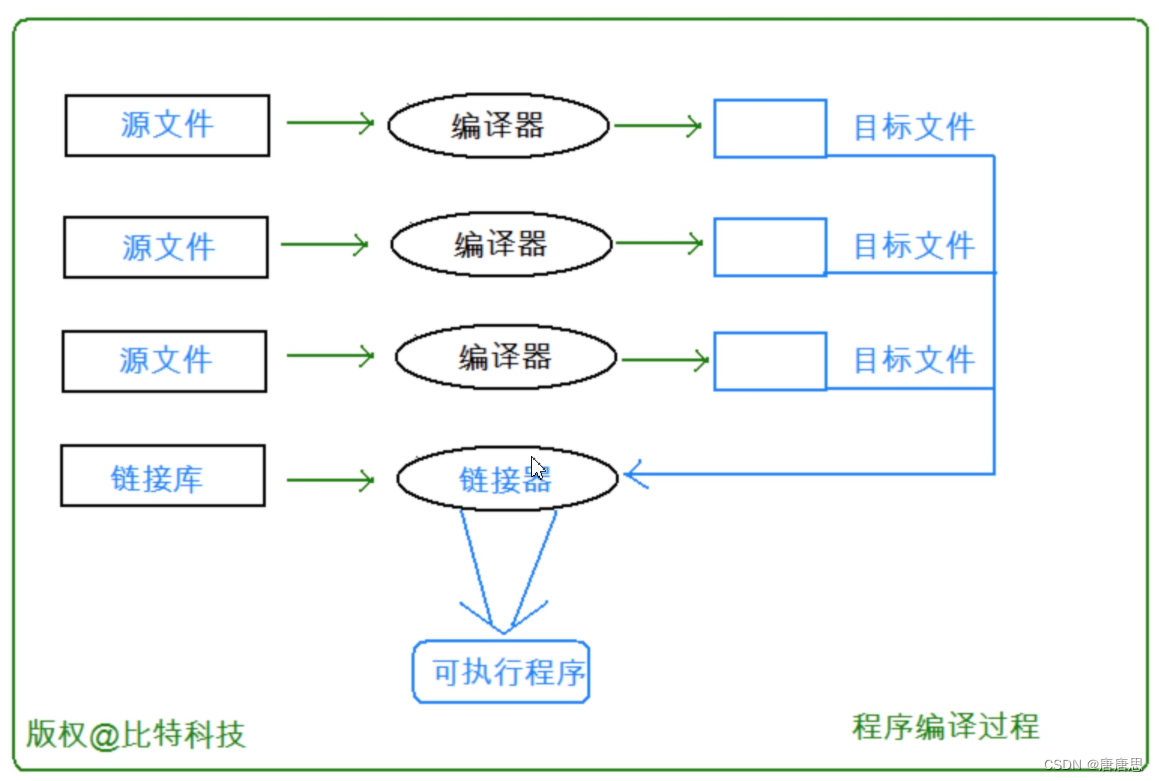
在C/C++中,一個程序要運行起來,需要經歷以下幾個階段:預處理、編譯、匯編、鏈接。
(前面缺省參數的聲明和定義分離鋪墊過了)
 ?
?
- 1. 實際項目通常是由多個頭文件和多個源文件構成,而通過C語言階段學習的編譯鏈接,我們可以知道,【當前a.cpp中調用了b.cpp中定義的Add函數時】,編譯后鏈接前,a.o的目標文件中沒有Add的函數地址,因為Add是在b.cpp中定義的,所以Add的地址在b.o中。那么怎么辦呢?
- 2. 所以鏈接階段就是專門處理這種問題,鏈接器看到a.o調用Add,但是沒有Add的地址,就會到b.o的符號表中找Add的地址,然后鏈接到一起。
3.面對鏈接函數的地址到括號里:call? 函數(函數地址)- C語言符號表:函數名 函數地址
- C++符號表的規則:函數名且包含函數參數類型等? 函數地址(那么鏈接時,面對Add函數,鏈接器會使用哪個方式去符號表找呢?這里每個編譯器都有自己的函數名修飾規則。只要能區分開即可)(下面細講)
5.3C++支持函數重載的原理—名字修飾(name Mangling)
C語言不支持函數重載?C++如何支持函數重載?
>>>>>>>>>? ?和前面我們講到的聲明和定義分離到鏈接中鏈接步驟(符號表搜索函數地址)
>>>>>>>>>(在符號表中去搜索函數地址)這個步驟非常關鍵。
C語言沒辦法支持重載,因為同名函數沒辦法區分。而C++是通過函數修飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。如果兩個函數函數名和參數是一樣的,返回值不同是不構成重載的,因為調用時編譯器沒辦法區分。
?【C語言】?
C語言在符號表中去搜索函數地址 >>>>只根據函數名搜索函數地址,當然C語言不支持函數重載。C語言鏈接時,直接用函數名去找地址,有同名函數,區分不開。
?【C++】
祖師爺為了C++能夠支持函數重載,于是把搜索規則改變了。C++在符號表去搜索函數地址,規則>>>>>>>>>>>>>>>>>>>函數名且包含函數參數類型等? 函數地址,支持函數重載。
這里每個編譯器都有自己的函數名修飾規則。函數名修飾規則,名字中引入參數類型,各個編譯器有自己的實現一套。(下面從windows和Linux舉例)
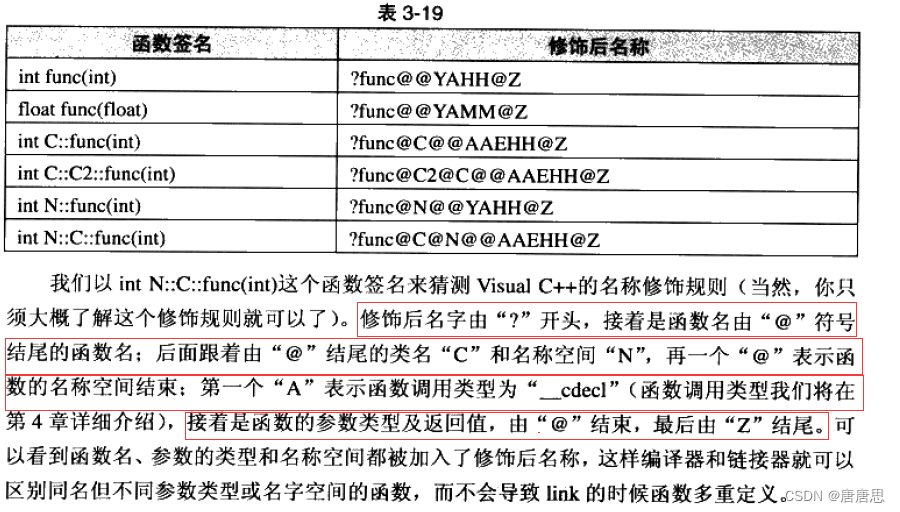
【windows下名字修飾規則】?
【擴展學習:C/C++函數調用約定和名字修飾規則--有興趣好奇的可以看看,里面
有對vs下函數名修飾規則講解】C/C++ 函數調用約定___declspec(dllexport) void test2();-CSDN博客
#include<iostream>
using namespace std;
int Add(int left, int right);
double Add(double left, double right);
int main()
{Add(10, 20);Add(10.1, 20.2);
}
//可以去VS上只有聲明沒有定義,此時就會報鏈接錯誤?
【Linux下名字修飾規則】
通過下面我們可以看出gcc的函數修飾后名字不變。而g++的函數修飾后變成【_Z+函數長度+函數名+類型首字母】。
- 采用C語言編譯器編譯后結果
- 結論:在linux下,采用gcc編譯完成后,函數名字的修飾沒有發生改變。
- 采用C++編譯器編譯后結果
- 結論:在linux下,采用g++編譯完成后,函數名字的修飾發生改變,編譯器將函數參
數類型信息添加到修改后的名字中。
#include<stdio.h> 2 int Add(int a,int b) 3 { 4 return a+b; 5 } 6 void func(int a,double b,int* p) 7 { 8 9 } 10 int main() 11 { 12 Add(1,2); 13 func(1,2,0); 14 return 0; 15 } - 采用C語言編譯器編譯后結果
gcc -o projectC project.c
objdump -S projectC
- 采用C++編譯器編譯后結果
g++ -o proejctCPP project.cpp
objdump -S projectCPP(proejctCPP)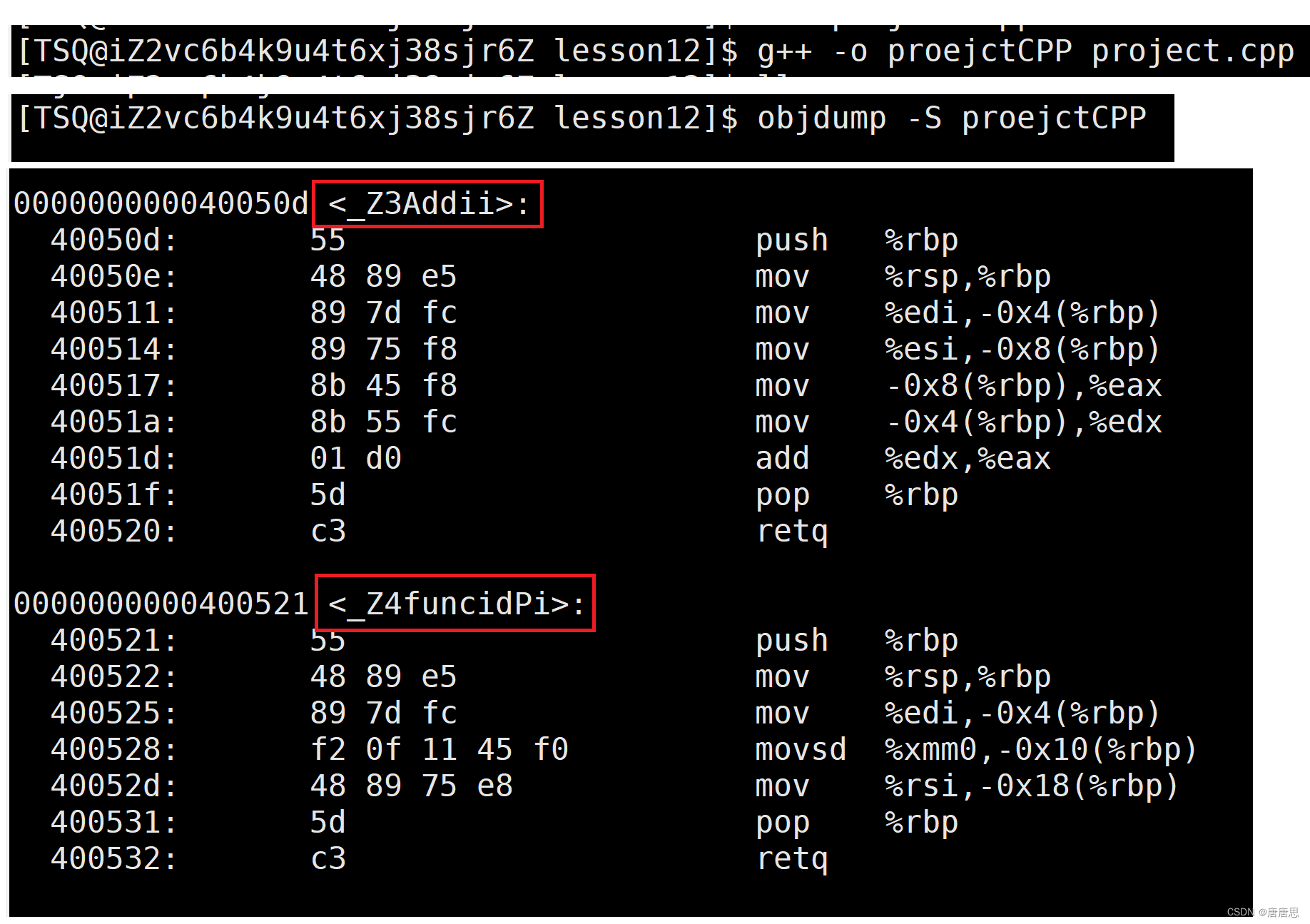
對比Linux會發現,windows下vs編譯器對函數名字修飾規則相對復雜難懂,但道理都
是類似的,我們就不做細致的研究了。?🙂感謝大家的閱讀,若有錯誤和不足,歡迎指正。

![[計算機網絡]--五種IO模型和select](http://pic.xiahunao.cn/[計算機網絡]--五種IO模型和select)





)

)
)

)






