目錄
前言
P80-P85
添加數據
遷移學習
機器學習項目的完整周期
公平、偏見與倫理
P86-P95
傾斜數據集的誤差指標?
決策樹模型
測量純度
選擇拆分方式增益
使用分類特征的一種獨熱編碼
連續的有價值特征
回歸樹
前言
這是吳恩達機器學習筆記的第五篇,第四篇筆記請見:
吳恩達機器學習全課程筆記第四篇
完整的課程鏈接如下:
吳恩達機器學習教程(bilibili)
推薦網站:
scikit-learn中文社區
吳恩達機器學習資料(github)
P80-P85
機器學習的迭代發展:

以“垃圾郵箱分類器”為例,如何減少學習算法中可能出現的錯誤?

添加數據
有一種技術,特別是對于圖像和音頻數據,可以顯著增加訓練集大小,這種技術稱為“數據增強”
如圖所示,改變x使之有相同的y,以達到數據增強的效果

除了圖像數據,對于音頻數據,也可以進行數據增強,如下所示:

在數據增強中,如果加入的扭曲(噪聲)不合適,可能不會對增大數據集產生作用

除了使用數據增強去添加數據之外,還可以使用合成數據去添加數據
合成數據是基于計算機模擬或算法生成模仿現實世界觀察的人造數據,簡言之,合成數據是人工制造的模擬數據

以OCR照片為例,現在想要訓練一個模型去提取圖片中的文字:

下面是一個真實的數據:

為這項任務創建人工數據的一種方法是:轉到計算機的文本編輯器,里面有很多不同的字體,使用這些字體在文本編輯器中鍵入隨機文本,截圖它們并使用不同顏色、不同對比度和不同的字體


遷移學習
對于一個沒有那么多數據的應用程序,可以使用遷移學習,它允許使用來自不同任務的數據來幫助你的應用程序
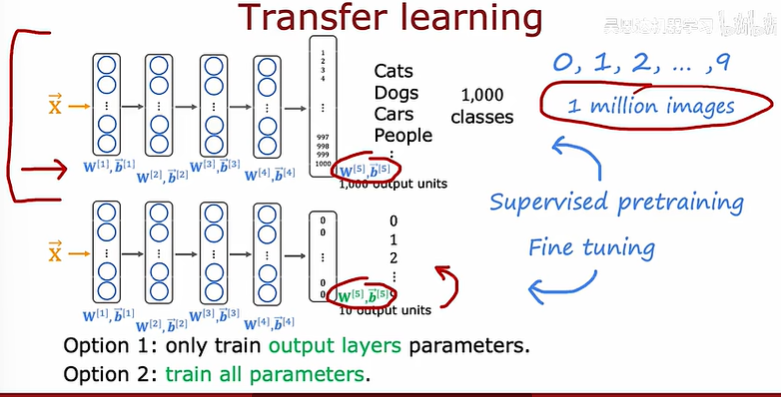
如上圖所示,對于一個數據集很小很小的網絡,建議使用選項一,即僅僅訓練輸出層的參數,否則使用選項二
遷移學習的一個好處是:你可能不需要稱為監督的執行人,許多神經網絡的預訓練已經有研究人員在大圖像上訓練了神經網絡,會在網上發布一個經過訓練的神經網絡,免費授權給任何人下載和使用
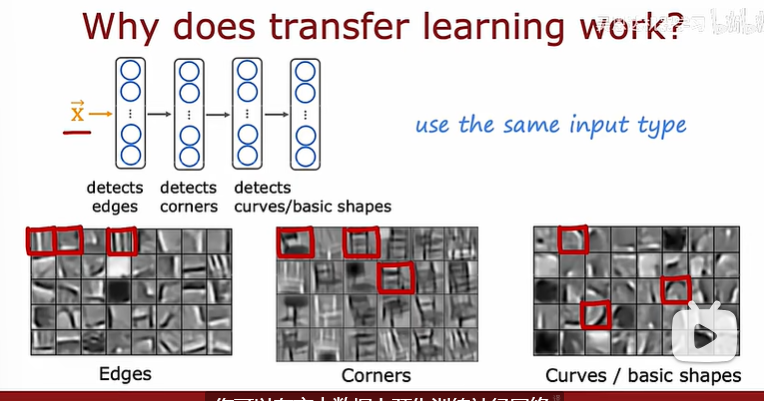
遷移學習的總結如下:

機器學習項目的完整周期
確定項目的范圍------->定義和收集數據<---------->訓練模型、誤差診斷、迭代優化------->部署、檢測、維持模型系統

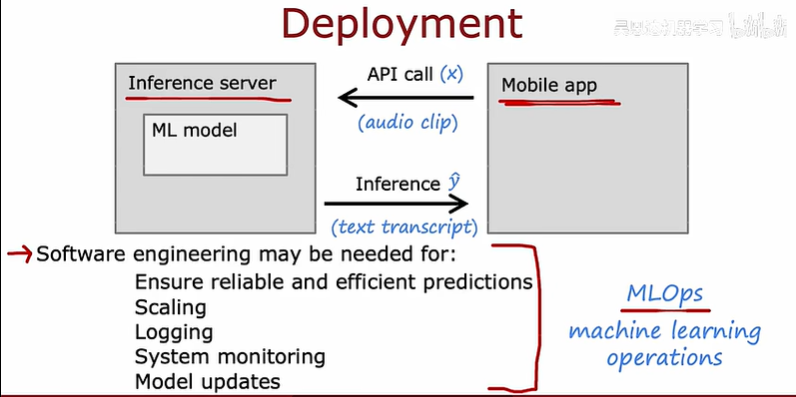
下面展示的是模型部署的一些細節
如圖,開發的移動應用可以通過api進行調用
部署過程需要一定的軟件工程技術,軟件工程需要編寫代碼使得可靠準確的預測、擴大服務范圍、保存數據、系統監控、模型更新
MLOps是一門工程學科,旨在統一 ML 系統開發(dev)和 ML 系統部署(ops),以標準化過程生產高性能模型的持續交付
公平、偏見與倫理

除了偏見之外,公平對待個人,機器學習也有一些負面用例

下面有一些讓你工作更公平的建議,在部署可能造成傷害的系統之前,減少偏見,更道德

P86-P95
傾斜數據集的誤差指標?
如果你正在開發機器學習應用程序,數據集的正面和負面例子非常不平衡,會發現,通常的誤差度量如準確率不會那么有效
比如下面這個罕見疾病檢測的問題,我們的學習算法成功診斷概率是99%,即誤差1%,但如果全世界只有0.5%的人發生這種疾病,即使我寫一個print("y=0")的程序,即永遠告訴病人沒有患病的誤差0.5%都比上面那個1%低。因此單單看準確率去評判學習算法是不夠的

精確率和召回率的定義如下:

提高輸出標簽1的門檻,即像下面一樣把0.5改成0.7再改成0.9會提高準確率、降低召回率
下面展示如何權衡準確率和召回率
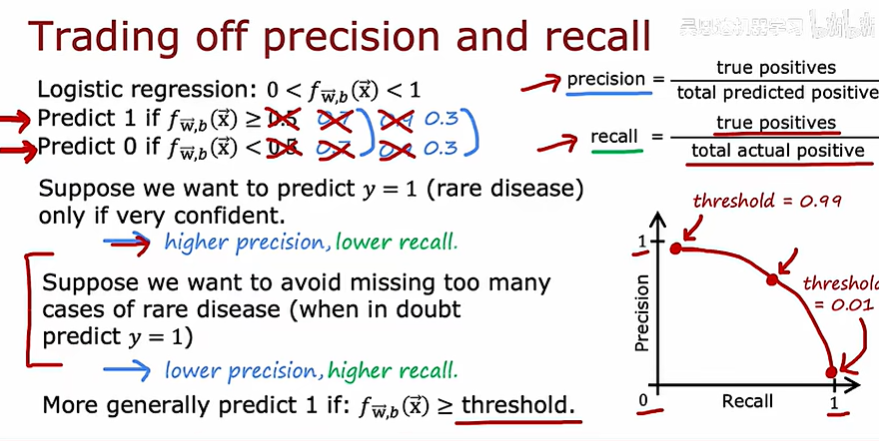
取平均值的方法并不是一個好的方法,而使用F1 score權衡可以強調兩個指標中更小的那個
通過F1 score去權衡上述這兩個指標從而選擇學習算法

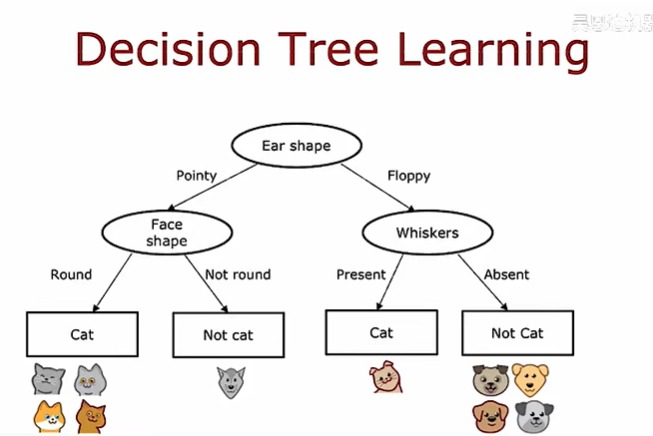
決策樹模型
許多用來贏得機器學習比賽的應用程序是決策樹和樹的集合
以檢測是否為貓的算法為例:
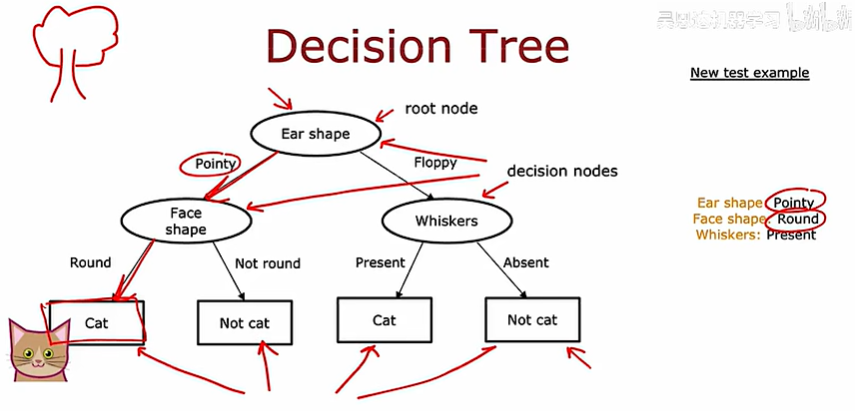
決策樹是一個預測模型,它代表的是對象屬性與對象值之間的一種映射關系。樹中每個節點表示某個對象,而每個分叉路徑則代表某個可能的屬性值,而每個葉節點則對應從根節點到該葉節點所經歷的路徑所表示的對象的值
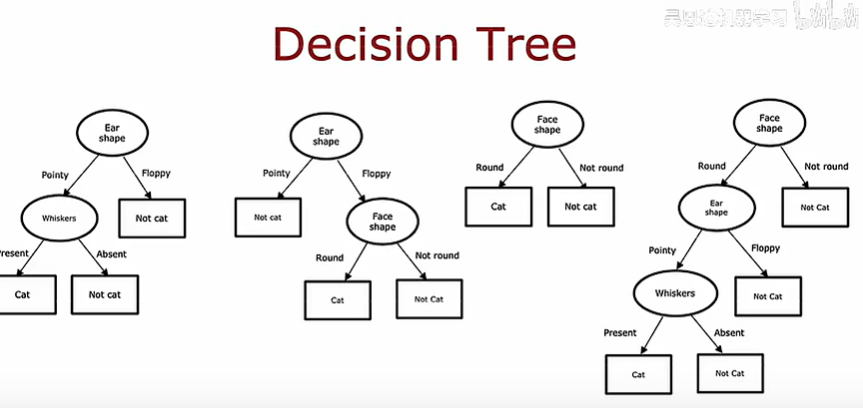
給定訓練集構建決策樹的過程有幾個步驟
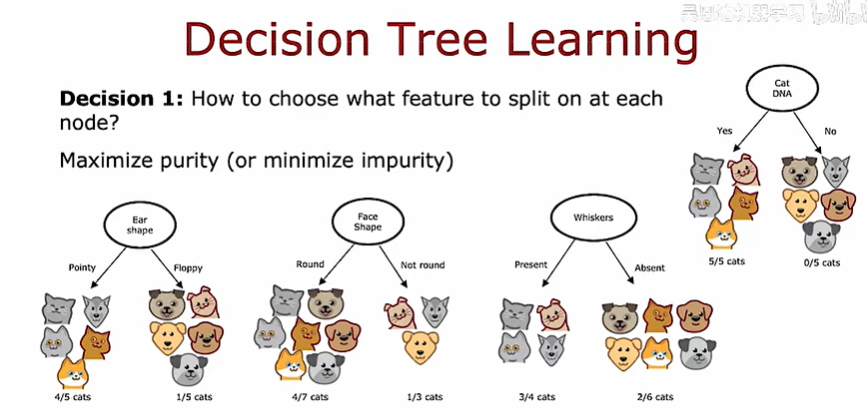
第一個步驟是:在每個節點上使用什么特征去劃分
第一個步驟是:決定什么什么停止劃分

測量純度
通過熵函數可以測量一組數據的不純度

熵函數真實的表達式如下所示:
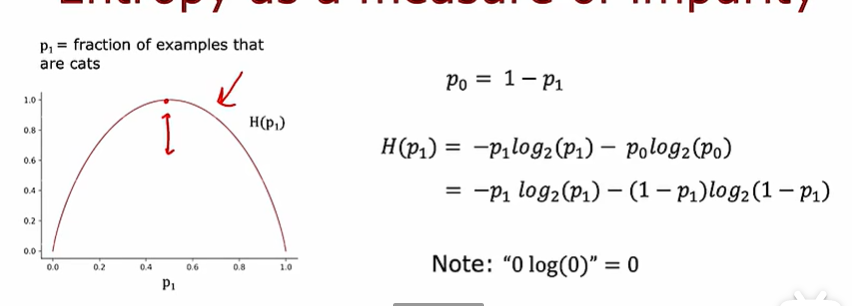
選擇拆分方式增益
在構建決策樹時,我們將決定在結點上拆分什么特征,將決定根據什么特征在減少熵,學習熵的減少稱為信息增益
如下圖所示,計算每一種拆分方式的信息增益,就是用原來的熵減去新的熵

總結起來,信息增益的計算方式如下:

決策樹構建過程總結

使用分類特征的一種獨熱編碼
在剛才的例子中,對于耳朵這個特征不是圓的就是尖的,下面使用獨熱編碼解決這個問題
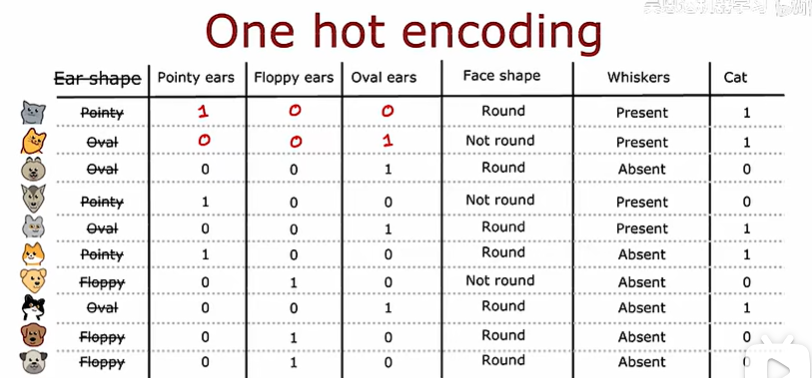
也就是說:如果一個分類特征有k個值,那么就創造k個二進制數字(取值0或1)
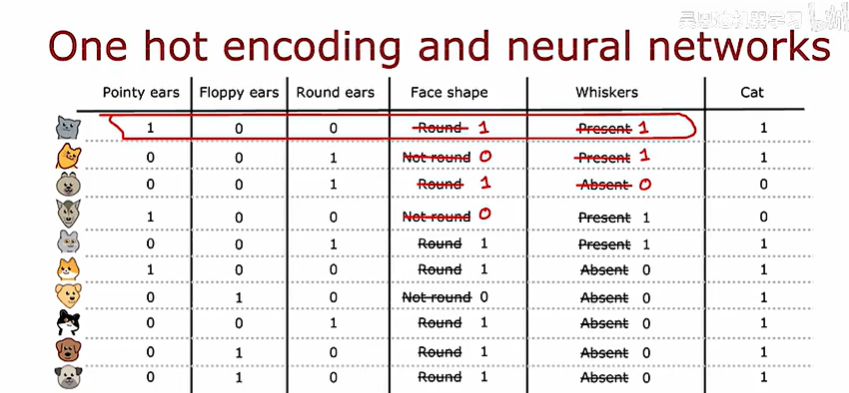 ?
?
連續的有價值特征
上面的特征都是離散的,當特征是連續值是會怎么樣呢
比如在上面例子的基礎上加一個體重的特征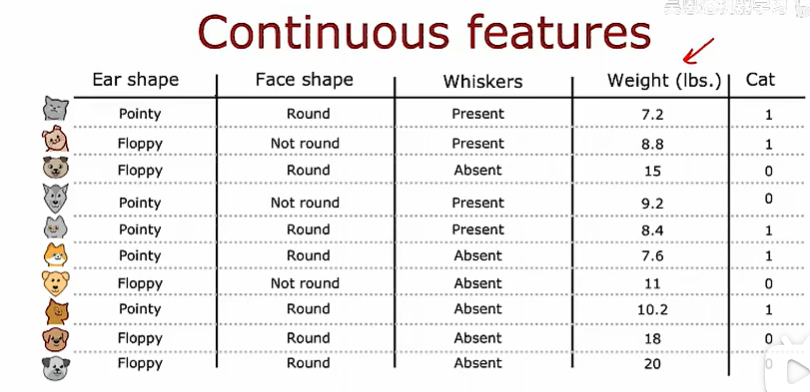
選擇不同的閾值,計算信息增益然后決定最終的拆分閾值

回歸樹
到目前為止,我們只把決策樹作為分類算法來討論,使用回歸樹可以將決策樹推廣為回歸算法
比如對于體重的預測,可以通過決策樹進行劃分,最后求得每一種類的平均值
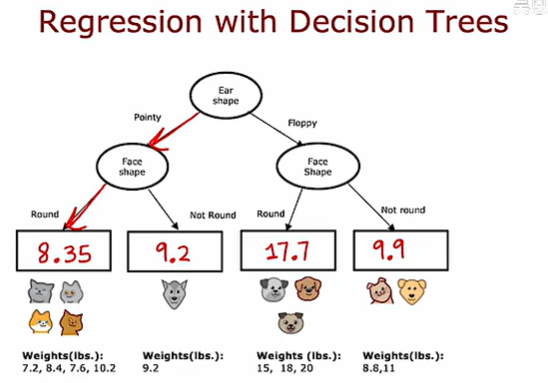
建立回歸樹時,如何選擇一個劃分呢?
在建立回歸樹時,不是去減少熵,相反的,我們應該去減少權重的方差,這是回歸樹的信息增益











占用的錯誤。)
python初中組初賽真題)

)





