何愷明新作 l-DAE:解構擴散模型
- 提出背景
- 擴散模型步驟
- 如何在不影響數據表征能力的同時簡化模型?
- 如何進一步推動模型向經典DAE靠攏?
- 如何去除對生成任務設計的DDM中不適用于自監督學習的部分?
- 如何改進DDM以專注于清晰圖像表示的學習?
?
提出背景
論文:https://arxiv.org/pdf/2401.14404.pdf
我們有一堆帶噪聲的照片,我們的任務是清理這些照片上的噪聲,讓它們看起來更清晰。
去噪擴散模型(DDM)就像是一個清潔工,它不僅能把照片清理得非常干凈,還能通過這個清潔過程學會識別照片中的內容。
但是,這個清潔工原本是被設計來做清潔工作的,人們開始好奇它是怎么學會識別照片內容的。
是因為它清理照片的方式特別(去噪過程),還是因為它在清理時用的一些特殊工具(擴散過程)?
我們的研究就是要探究這個問題。
我們嘗試了各種方法,最后發現,關鍵其實在于這個清潔工如何看待照片中的每一小塊內容,把它們轉換成更簡單的形式來理解。
這有點像是給它一副眼鏡,讓它能更好地看清楚照片的細節。
通過這個過程,我們設計出了一種簡單的方法,讓清潔工不僅能清理照片,還能更好地理解照片內容。
我們的方法雖然不是最頂尖的,但比之前的方法有了很大的進步,也讓我們看到了未來有更多可能性去改進這個過程。
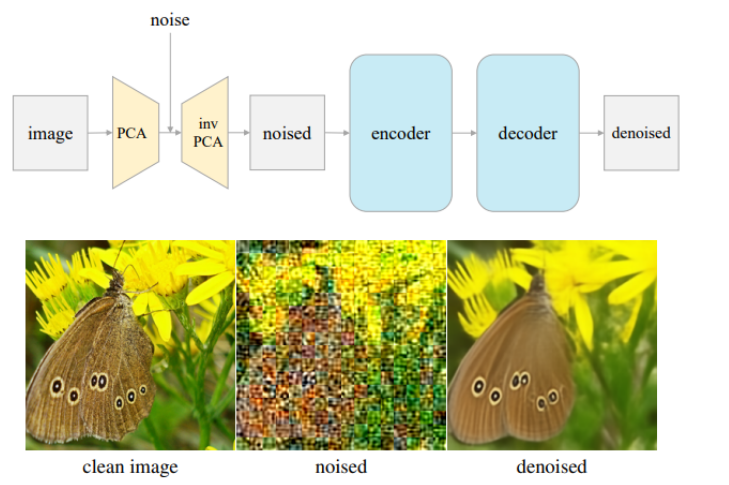
圖是一種被稱為“潛在去噪自編碼器”(L-DAE)的技術。它是一種圖像處理方法,用于從帶有噪聲的圖片中恢復出清晰的圖片。
-
原始圖像:左下角是一個沒有噪聲的原始圖像,這是一張蝴蝶停在黃色花朵上的照片。
-
噪聲添加:通過一種技術叫做“片段式主成分分析”(patch-wise PCA),原始圖像被轉化到一個叫做“潛在空間”的地方,在這個過程中添加了噪聲。
這就是中下角的圖像,你可以看到圖像變得模糊和雜亂,就像被隨機的色塊覆蓋了一樣。
-
自編碼器:在噪聲圖像的基礎上,一個自編碼器開始工作,包括一個編碼器和一個解碼器。
編碼器的作用是將噪聲圖像轉換為一個更簡潔的內部表示,而解碼器則嘗試從這個表示中重建原始圖像。
-
去噪圖像:最終,自編碼器輸出了一個去除噪聲的圖像,這是右下角的圖像。
盡管噪聲被去除,圖像中的細節和蝴蝶的特征都得以保留。
這個技術的目標是模仿和簡化更復雜的去噪擴散模型(DDM),同時嘗試保持與經典去噪自編碼器(DAE)相似的學習性能。
這張圖上方的流程圖解釋了整個過程:從原始圖像開始,通過PCA添加噪聲,然后通過自編碼器進行編碼和解碼,最終得到去噪圖像。
這種方法是自監督學習的一種形式,這意味著它可以通過觀察大量的例子自己學習去噪,而不需要人為指定噪聲和去噪之間的關系。
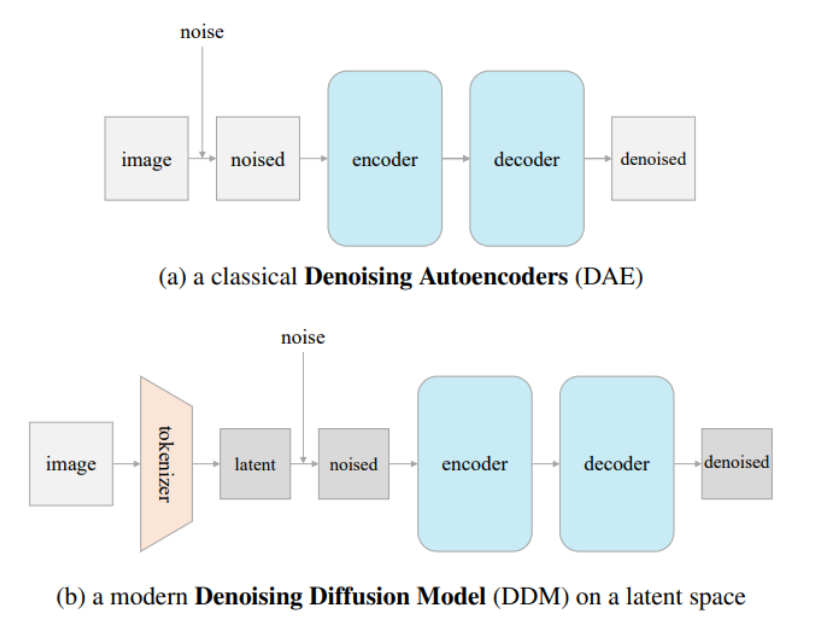
這幅圖是兩種不同的機器學習模型,用于處理圖像的去噪任務:
-
經典的去噪自編碼器(DAE):這個模型包括三個部分:
- 噪聲:在輸入圖像上添加噪聲。
- 編碼器:編碼器接收帶噪聲的圖像,將其編碼到某種內部表示。
- 解碼器:解碼器嘗試從內部表示中恢復去噪后的圖像。
-
現代去噪擴散模型(DDM):這個模型是在潛在空間上操作的去噪模型,它包括四個部分:
- tokenizer:這個組件將原始圖像轉換成潛在的表示形式。
- 噪聲:就像經典DAE一樣,它在潛在表示上添加噪聲。
- 編碼器:編碼器學習如何處理帶噪聲的潛在表示。
- 解碼器:解碼器從編碼器輸出的表示中恢復出去噪后的潛在表示,然后可以轉換回去噪后的圖像。
圖中的(a)部分展示的是傳統方法,直接在圖像空間上添加和預測噪聲
而(b)部分展示的是現代方法,如LDM(潛在擴散模型)和DIT(擴散變換器),它們在潛在空間上添加和預測噪聲,而不是直接在圖像空間上操作。
這種現代方法通常能夠更有效地處理高維數據,如圖像,因為潛在空間的維度通常遠小于原始圖像空間的維度,這可以提高處理速度并提升去噪效果。
擴散模型步驟
擴散模型是一類深度生成模型,它們通過模擬數據的擴散過程(即逐漸引入噪聲到數據中)來學習數據的分布。
在去噪擴散模型(Denoising Diffusion Models, DDM)中,這一過程被逆轉用來生成數據:模型學習如何逐步從噪聲中恢復出干凈的數據。
下面是解構現代去噪擴散模型的步驟和方法:
-
Tokenizer(向量化):
- 這一步是將高維的圖像數據映射到一個低維的潛在空間(latent space)。
?
潛在空間中的向量可以捕捉到圖像的重要特征,但是維度更低,這使得處理起來更高效。 -
添加噪聲:
- 在潛在空間中,這些低維的表示(latent representations)會被逐漸添加噪聲,這個過程稱為擴散過程。
?
添加噪聲是一個逐步的過程,在每一步中都會引入一些噪聲,直到數據完全變成噪聲。 -
訓練去噪模型:
- 訓練一個去噪模型來預測每一步擴散過程中添加的噪聲。
?
這個模型的目標是學習如何從帶噪聲的潛在表示中恢復出原始的潛在表示。 -
采樣(生成)過程:
- 通過逆向運行擴散過程來生成新的數據。
- 從純噪聲開始,模型逐步減少噪聲,逐步恢復出清晰的數據。
解構這個模型的關鍵點在于理解如何在潛在空間上進行擴散和去噪過程,而不是直接在原始的數據空間上進行。
如何在不影響數據表征能力的同時簡化模型?
在擴散模型中,到底哪個步驟最重要?
實驗發現,讓 DAE 得到好表征的是低維隱空間,而不是Tokenizer(向量化)。
- 說明復雜的tokenizer可能不是學習好的數據表示所必需的
- 簡化tokenizer相當于使用更簡單的廚具來達到相同的烹飪效果
如何在不影響數據表征能力的同時簡化模型?
- 實驗發現,可通過替換復雜的VQGAN tokenizer為更簡單的PCA tokenizer
不同的圖像處理方法:
-
TA們被用于將圖像分解成較小的片段,進而進行深入的特征提取。

-
Patch-wise VAE 分詞器: 這是一種處理圖像的方法,使用了一種稱為自編碼器的技術,但去掉了一些復雜的數學限制,讓它變得更簡單。
-
Patch-wise AE 分詞器: 這個方法更簡單,只是在圖像的小塊上應用基本的編碼和解碼過程。
-
Patch-wise PCA 分詞器: 這是最基本的方法,用一種稱為主成分分析的技術來處理圖像的小塊。PCA 是一種不需要復雜訓練就能找到圖像主要特征的方法。
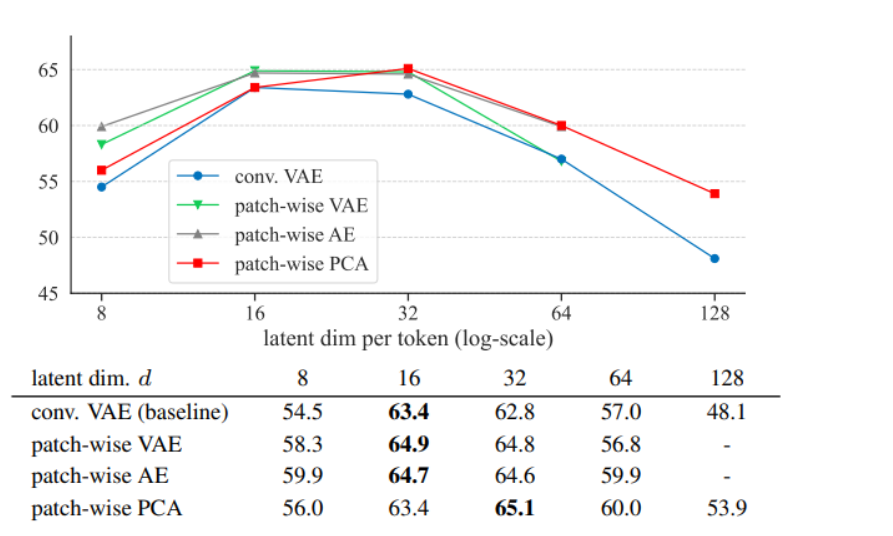
即使是最基本的PCA方法也表現出色,甚至簡單的圖像塊處理方法有時候比復雜的方法效果更好。
所以,完全可以用簡單的代替復雜的。
- 把復雜的VQGAN tokenizer 換為 更簡單的PCA tokenizer。
如何進一步推動模型向經典DAE靠攏?
直接在圖像空間操作有助于理解和提高模型的直觀性和可解釋性。
使用逆PCA直接在圖像空間操作,而非僅在隱空間。
如何去除對生成任務設計的DDM中不適用于自監督學習的部分?
因為類別條件化處理會限制模型學習更普遍的數據表示。
移除DDM的類別條件化處理。
如何改進DDM以專注于清晰圖像表示的學習?
原始噪聲調度太側重于噪聲圖像,不利于學習清晰圖像表示。
替換噪聲調度,讓模型更多地關注清晰的圖像。
?
如果將這個過程比作學習做菜的過程,那么:
- 去除類別條件化處理就像是摒棄菜譜中不必要的復雜步驟,專注于基本的烹飪技巧。
- 簡化tokenizer相當于使用更簡單的廚具來達到相同的烹飪效果。
- 改進噪聲調度類似于調整烤箱溫度,更加關注食物烹飪的質量而非速度。
- 直接在圖像空間操作就像是直接在爐子上(圖像上)調整火候,而不是依賴定時器(隱空間)的間接指示。

)


 Practice | 判斷題)


)





)
阻止用戶在某個操作執行期間操作頁面)
——棧)



