引言:
北京時間:2023/11/20/9:17,昨天成功更文,上周實現了更文兩篇,所以這周再接再厲。當然做題任在繼續,而目前做題給我的感覺以套路和技巧偏多,還是那句話很多東西不經歷你就是不懂,很多套路和技巧只有你見過用過,你才能明白,下次碰到某題涉及該知識點時,你才會往這個方向想,從而增加做出該題的可能性。而不是看到一個題,雖然有思路,但是卻不知道如何下手。而在上篇博客我們主要學習的是對數據加密,保證數據的安全性。我的看法就是別人的善良從不是因為它們大發慈悲,而是因為自身的強大。這句話給我的感想很深,從兩點出發,一點是人好像對這種越簡單的道理,反而認知更薄弱。另一點就是這句話表述的意思,無論是從數據安全問題,還是人際交往。人的善良好像總是容易被漠視,感受不到回報。心越軟你的感受越深。好比各種加密方法,當你無懈可擊的時候,你會發現自己一個人生活也挺好,所以在生活中我們一定要降低與他人的耦合程度,就像網絡協議棧一樣,每一層洋洋灑灑。

引言實時更新補充:
北京時間:2024/2/15/14:19,哈哈哈,先來三個字化解一下尷尬場面。看了一下上述引言,發現該篇博客是在去年11月份寫的,當然當時沒有及時發布,肯定是因為沒有寫完。簡單用小學學過的加減算了一下,已經85天沒有碼字了,當然同理之前博客中所說,當時的主攻方向不是寫博客,而是學習算法。生活就是這樣曲曲折折,因為一系列原因,你不可能一直保持同一狀態,簡單回顧了一下,發現至今已經68天沒有學習了,也就是說我以前視之為寶貝的小綠點(gitee),悄然已經失去了68個,回想當初只是因為失去一個小綠點而產生的失落感,現在只能是啞然一笑。如果沒記錯的話,從開始學習算法到結束,頭尾時間大概是一個月左右,而這一個月由淺入深的學習了雙指針、模擬、二分、位運算、字符串、鏈表、棧、優先級隊列、分治、哈希、遞歸、回溯、BFS,當然只是見識這一類的題型,同理目前的我還沒有獨立做題的能力。ok,講完了之前的學習內容,我就要開始分享擺爛68天都干了什么,大體分為兩部分:校園部分+寒假部分。我記得那是一個周六的下午,因為被算法題目折磨了許久,那天睡到了中午12點多,使得本應該日常8點去圖書館的我產生了一股無太大所謂情結,然后又因為當時體育選修課是籃球,在每個星期一節籃球課中,我逐漸熱愛上了籃球,從而萌生了去打籃球的想法。因為種種原因,舍友對于我的想法響應積極,也許當時是一句戲言,但在人情世故之下不出預料的我們打了一下午的籃球。這場籃球給我的印象很深,原因種種。第二天,在舍友的強烈要求,我開始了金鏟鏟S10賽季的闖蕩,從開始的被虐到后來的虐菜,那種人性和游戲的結合體現的淋漓盡致,當然這也就是游戲成癮的本質,至此一發不可收拾。放假之后,各回各家,組隊的人越來越少,最后高分段掉了幾把分之后,也就失去了玩該游戲的動力。后轉戰王者榮耀(00后的圈子真小),當然玩該游戲最初的動力來源于幾個新英雄以及剛好賽季更新,然后因為該游戲自身的一些策略,上分之路越來越艱辛,最終在連跪中失去了玩該游戲的動力。沒有了游戲可玩,就開始了追番之路,在追番的過程中,一部叫《惡魔法則》的動漫成功吊起了我的胃口,之后當然也就是將《惡魔法則》這本小說給看完了,具體用了多少時間忘記了。充分意識到當年跳舞(起點白金)有多強以及為什么當年連三少的斗羅大陸女主介紹都是:我叫小舞,跳舞的舞。可見當時網文界跳舞大佬的實力。看完該本經典小說,當然該小說在我心目中能排進前三,第一于紫川不可替代。我進入了一個空窗期,好多天無所適從,我開始尋找其它有意思的事物,看了幾部新劇,提到新劇,上述在學校過程中,我還看了胡歌的繁花。發現除了繁花其它新劇并不能給我很好的感覺,在機緣巧合之下我接觸到了知否。知否給我的感覺純屬就是另一個感覺,這個感覺比當時繁花完結不夠看還要深。足以和上述小說給我的感覺媲美。最終轉戰和平精英,當然這個游戲不像是上述游戲,這個游戲必須要有游戲塔子,之所以玩這個游戲,也是因為我姐她玩,所以在組隊的快樂之中又度過了幾天。可嘆,美好的時光終會如流水般消逝,我姐又要重新成為一個打工人。時至今日,我再也找不到任何有趣的事物,在無聲的夜晚和內心的空洞中,想起了曾經的許多往事。悲寂、無奈之感涌上心頭,感慨萬千。大道理說的好:即使時光不再,但是那些美好將永遠銘刻在我們的心中,成為我們一生寶貴的財富。最后送給自己四個字:我還是我。
回顧HTTPS協議相關知識
在上篇博客中,我們對HTTPS協議進行了詳細的學習。從區分HTTP和HTTPS到明確HTTPS的工作原理,在多個方面由淺入深的對HTTPS協議進行了立體化探究。理解了什么是HTTPS協議,原來HTTPS協議只不過是對HTTP協議在數據安全方面的缺陷進行了一個完善,保證了當前網絡通信的安全性和可靠性。并且本著追根究底的原則,我們明白了HTTPS協議之所以能夠保證數據安全,是因為它在HTTP協議的基礎上添加了一層提供加密解密操作的軟件層,其中最常見的軟件層為SSL/TLS。隨著學習的深入,我們逐漸明白了SSL/TLS中涉及的加密解密方式有對稱加密解密和非對稱加密解密,在明白了對稱加密解密和非對稱加密解密的工作機制之后,我們明白單獨使用其中一種,并不能保證網絡通信的安全性和高效性,從而誕生了對稱加密解密和非對稱加密解密配合使用的機制。最后經過不斷的探究,我們發現了網絡通信的核心BUG,對端主機無法確保公鑰來源的合法性。所以在對稱加密解密和非對稱加密解密配合使用機制之上,我們引入了CA證書的概念,明確CA證書的本質就是使用一套新的非對稱加密解密操作來確保公鑰來源的合法性。當然上篇博客在引入CA證書概念之前,我們對數據摘要、數字簽名等概念進行了詳細的介紹,對于數據摘要的使用場景以及優點進行了著重講解。并結合CA證書的理解,我們明白之所以對CA證書進行數字簽名,而不是直接對證書做加密,本質就是因為我們在提高加密解密效率的同時,還需要提供一套兼容性、靈活性高的解決方案。避免了因為數據間差異帶來的效率問題。最終明確,之所以HTTPS協議能夠保證網絡安全通信,是因為它使用了非對稱加密解密+對稱加密解密+證書認證的方案。而對于這個方案而言,其中一共涉及到了三組不同的秘鑰。明確,第一組秘鑰是CA機構為了確保網站合法性而產生的一組非對稱加密解密秘鑰,而第二組秘鑰則是網站自身為了確保數據通信安全而產生的一組非對稱加密解密秘鑰,最后一組則是對端主機獲取到合法公鑰之后同理為了數據通信安全而產生的一組對稱加密解密秘鑰。從這三組秘鑰的關系來看,一個共識扮演著重要角色。拓展: 一般的摘要算法MD5、SHA。成為中間人的方法ARP欺騙、ICMP攻擊。
正式進入傳輸層的學習
學完HTTP和HTTPS協議之后,應用層我們就算大功告成啦!當然在應用層還有非常多不同的協議,但憑借我們對HTTP協議的認知,我們明白在應用層,無論是何種協議,它都一定需要完成套接字的創建、數據序列化反序列化、數據接收響應和處理的工作。從網絡協議棧來談,它的工作就是確保應用程序之間能夠正確、高效地通信,只不過此時基于應用層而言,它的工作重點則體現在成功接收/響應和數據處理方面上。而談到數據處理,此時不同的開發者就可以根據不同的用戶需求來設計不同的軟件方案,從而讓應用層蓬勃發展。So,對于我們而言,應用層才是我們生存的地方,誰讓下層已經一成不變。但在當今這個時代,想要進入應用層的門檻越來越高,所以我們并不能局限于應用層,而需要不斷深入,所以接下來我們就正式開始學習應用層的下一層,網絡協議棧從上到下的第二層,大名鼎鼎的傳輸層吧!
傳輸層簡單理解
一個問題,什么是傳輸層?應用層的下一層嗎?答案顯然不符合我的預期,俗話說的好,想法來源于生活,此時我們就可以舉一個快遞的例子。在生活中,所有人各司其職,當我們需要寄一個快遞的時候,身為用戶我們需要完成的工作很簡單,只需要填寫地址以及接收人的電話,然后交給驛站。最后在我們的認知里,這個快遞就會被成功發送到目的地。同理在網絡數據傳輸過程中,用戶在應用層想要訪問某個遠端服務器,他只需要輸入目標服務器的IP地址和端口號,然后通過網絡協議棧將請求發送出去。類比上述例子,我們可以明白,當用戶將數據處理完成之后,也就是經過應用層之后,它來到的一定就是傳輸層,此時傳輸層起的作用與驛站所起的作用相差無幾。所以我們明白,當數據在應用層處理完成之后,并不是直接就發送到了網絡之中,它必須經過網絡協議棧,也就是必須經過傳輸層,由傳輸層起與驛站一樣的作用,規定該數據應該什么時候發送、采用什么方式發送、發送過程出錯了應該怎么辦等獨屬于傳輸層的策略。并且結合之前所學有關封裝和分用的知識,此時我們就意識到封裝并不只是簡單的兩個字,其中涉及到了非常多的細節,這也就是我們學習傳輸層的意義所在。所以此時的一個問題我們就轉變為:傳輸層如何封裝?
深入理解端口號
在之前應用層學習套接字通信的過程中,我們明白通信雙方是通過源IP、源端口、目的IP、目的端口的邏輯來定位,用IP來標識全網唯一的一臺主機,端口號來標識全網唯一的一個進程,從而讓網絡通信抽象成進程間通信。因此我們需要明確,端口號只與進程相關聯。并且明白,雖然不同的應用層協議都有與之配對的端口號,但是此端口號起的作用僅僅只是標識和區分。從瀏覽器的角度來看,為了降低用戶使用瀏覽器的成本,并且兼容所有的Web服務器,瀏覽器就規定了URL的首部只能為HTTP/HTTPS,也就是瀏覽器默認只會訪問Web服務器的80/443端口。所以也就導一個網站想要被瀏覽器訪問,那么該網站使用的協議只能是HTTP/HTTPS,并且在用戶不知道指定端口號的情況下,該網站程序的端口號只能是80/443。而從非瀏覽器客戶端的角度來看,你具體使用什么端口號,都是有開發者自己決定的,你可以根據對應程序使用的協議來匹配對應的端口號,當然你也可以使用任意端口號,同理上述所說,端口號只與進程相關聯。而為了標識區分不同的協議,達成一個共識,使得在某些方面變得更加便利,我們就將端口號進行范圍劃分,其中0~1023端口號代表的知名端口,提供給較為常見的協議使用,而1024 ~65535則默認為操作系統動態分配使用,如:當我們啟動了本地主機上的微信程序,那么此時該微信進程的端口號就是其中的一個,而對于遠端的微信服務器而言,因為其使用的協議通常為HTTPS協議,所以遠端微信服務器進程的端口號在外界看來通常就是443,但對于其設計者而言,基于多方面的考量,如:減少非法訪問和外部攻擊,它也可能使用任意端口號。
查看網絡狀態指令
在Linux系統中,我們可以通過netstat或者ss指令來查看當前系統中所有的網絡進程,其中配合該指令使用的選項如下:
- n 拒絕顯示別名,能顯示數字的全部轉化成數字
- l 僅列出有在 Listen (監聽) 的服務狀態
- p 顯示建立相關鏈接的程序名
- t (tcp)僅顯示tcp相關選項
- u (udp)僅顯示udp相關選項
- a (all)顯示所有選項,默認不顯示LISTEN相關
選項和指令相結合,所以平時我們經常使用的就是netstat -nltp、netstat -natp、netstat -naup
傳輸層協議之UDP
完成了上述基礎知識的鋪墊,此時我們正式開始學習傳輸層協議。當然對于傳輸層協議而言,它分為UDP協議和TCP協議,具體這兩種協議有什么不同,在之前學習套接字編程時我們有進行簡單介紹。而面對傳輸層有兩種不同的協議,此時我們就必須先解決一個問題,同理上述所說,我們是通過源IP、目的IP、源端口、目的端口來保證全網唯一兩個進程之間的通信,并且在通信過程中,數據都需要經過網絡協議棧,那么問題來了,當數據想要從網絡層交付到傳輸層,網絡層應該如何識別這兩種協議呢?換一種說法也就是網絡層(操作系統)應該調用那種協議的代碼呢?所以對于這個問題,此時基于傳輸層而言,它同理應用層中端口號可以標識不同的進程,只不過對于傳輸層而言,它使用協議號來標識不同的傳輸層協議(UDP/TCP)。對于UDP而言它的協議號為17,同理TCP協議號為6。當明確了協議號的概念之后,此時就可以分為兩部分來學習傳輸層協議,首先我們從UDP協議開始。同理類比學習法,通過之前應用層學習的HTTP協議以及對于封裝和分用的理解,我們明白對于UDP報文而言,它一定也是由報頭(UDP報頭)和有效載荷(應用層報文)組成。回顧應用層編碼過程中我們用到的sendto和recvfrom接口,當然因為UDP協議是一個面向數據報的協議,所以它并沒有發送緩沖區,而為了提高UDP協議接收數據的高效性,所以UDP協議具有接收緩沖區,也就是當時在應用層我們說,發送數據的本質就是將數據拷貝到下層緩沖區,接收數據就是從下層緩沖區讀取數據的說話是不完全正確的。除了兩種協議緩沖區之間的不同之外,更重要的是我們要明確,調用sendto和recvfrom接口并不只只意味著完成數據的拷貝,更為重要的是它會請求傳輸層完成對該數據的封裝和分用。 所以此時我們就基于UDP協議來看看它是如何完成封裝和分用功能的吧!當然想要深入理解,此時如下圖所示,我們就需要一幅UDP協議示意圖:
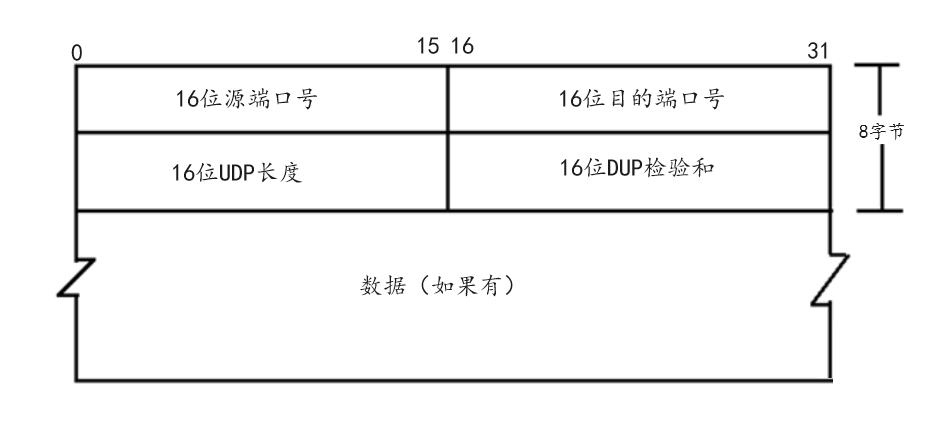
同理上述所說,因為UDP協議是一個面向數據報的協議,所以它不存在發送緩沖區,只存在接收緩沖區。并結合上述UDP協議示意圖我們發現一個UDP報文的長度為16位(64KB),所以我們明確,如果應用層報文超過64KB,那么此時它就無法直接對其進行封裝,而需要對其進行拆分。當然由于該部分知識還涉及到IP協議,也就是當UDP協議將大報文拆分成若干個小報文時,因為拆分過程是有序的,也就是封裝過程是有序的,所以當IP協議在對其進行封裝時,就可以通過一個叫序列號的字段來標識,以便于后續的報文還原過程。當然后續這個過程我們還會深入學習,此時只需要明白,對于UDP協議而言數據太大要拆分就行。同理上述所說,為了提高數據的接收效率,一般UDP協議也會有一個屬于自己的接收緩沖區,而因為有了這個接收緩沖區,此時就有可能導致緩沖區存放了多段數據,并且明確該緩沖區中的數據一般是以字節為單位,也就是當應用層想要從該緩沖區讀取其中一段數據,那么它一定是以字節流的方式讀取,因為只有這樣才能讀取到完整、可靠的數據。明白了這點之后,結合上述UDP協議示意圖,我們就很容易發現,因為UDP報文的報頭固定大小為8字節,所以當我們讀取接收緩沖區中的數據時,首先讀取的就是該緩沖區的首部8個字節。當我們將報頭讀取之后,此時我們就可以通過報頭中的UDP長度字段獲取到該UDP報文的總長度,然后減去報頭長度,最終獲取到有效載荷的長度。而當我們獲取到有效載荷的長度,此時我們就可以繼續讀取接收緩沖區該長度字節的數據,從而讀取到一個完整的應用層報文,以此類推我們就可以將對端發送的數據全部讀取到應用層了。當然最后該數據需要拷貝到那個進程的緩沖區中,此時操作系統就會根據對應的操作判斷該進程綁定的端口號是否與UDP報頭中的目的端口號匹配。當然根據上述這句話,我們可以明白,數據向上交付并不只是本層單獨完成的,它也需要上層調用對應的系統調用接口(recvfrom)配合完成。注意: 有關UDP報頭中的校驗和字段我們忽略。
理解UDP協議下的封裝和分用
明白了上述知識,對于UDP協議而言我們就學習完了,所以我們到底應該如何來理解封裝和分用呢?當然對于上述所說的封裝和分用,它只是一個宏觀的過程,并不能讓我們深入具體的理解封裝和分用,那么此時我們就可以從代碼的角度來理解。由于網絡協議棧和操作系統之間的關系,我們明確傳輸層屬于操作系統(Linux),并且因為操作系統是由C語言編碼,所以對于傳輸層的UDP報頭而言,它的本質就是一個結構體(struct udp_header),當然換一種說法也就是協議(UDP協議),類比當時在學習HTTP協議之前我們自己用標識符進行格式控制實現的協議,此時這種直接使用結構體作為協議的方法就會顯得非常清晰。當然值得注意的是,之所以UDP協議可以直接使用結構體作為協議來傳輸數據,本質是因為對于網絡協議棧(TCP/IP)而言,除了應用層之外,整個網絡協議棧是不會改變的、是全網互通的,而應用層因為開發需求不同,就會導致數據在進行格式控制時使用的協議不同,當然也就是結構體不同,所以應用層不允許直接使用結構體進行通信,當然也就是我們之前為什么要學習序列化和反序列化的本質原因。如下圖就是UDP協議代碼理解:
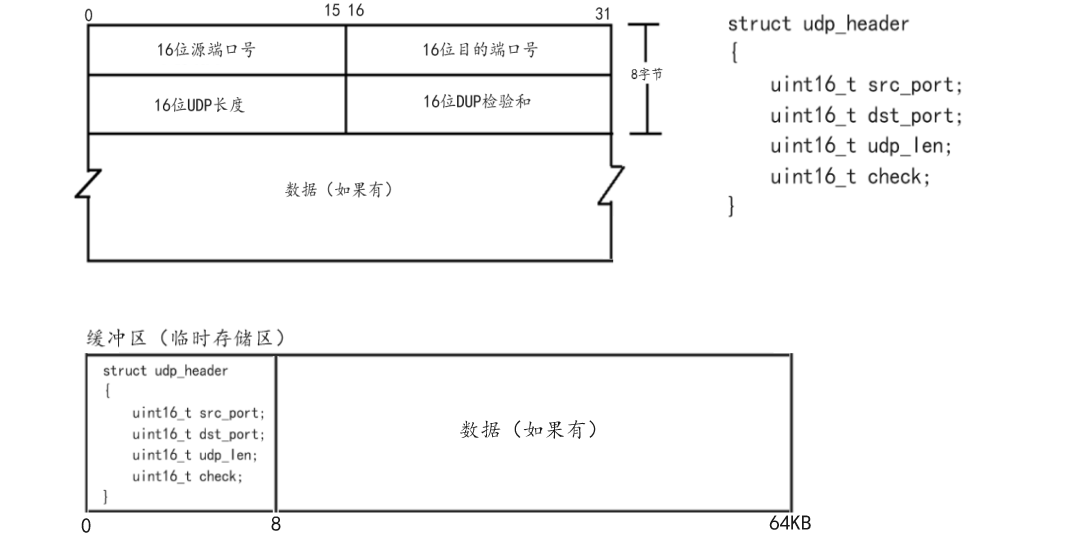
同理上述所說,UDP報頭的本質就是一個結構體數據,并且這個結構體數據是一成不變的。所以此時想要從代碼角度理解封裝,我們就有了一個很強的抓手,也就是對于UDP協議而言,封裝的本質: 通過一個臨時存儲區和一個指針(步長/字節),也就是一個char*類型的緩沖區,通過對指針進行固定字節的移動,也就是讓指針向后移動8個字節預留出存放報頭數據的空間大小,然后將應用層報文拷貝到該指針之后的空間中。當應用層報文拷貝完成之后,此時再將char *類型的指針還原到起始位置,并且將其強制類型轉換成struct udp_header *指針類型,最后依據已知和該指針變量讀取udp_header中的變量并賦值,至此封裝過程完成,UDP報文前往網絡層。當然值得注意的是,也就是回應之前所說,應用層調用sendto接口并不只是單純的拷貝數據,而是通過該系統調用讓操作系統完成數據封裝工作,當然也就是上述代碼的執行,所以明確上述無論是空間的預留,還是類型的強壯,亦或者是報頭的變量的賦值,都是操作系統通過特定的代碼完成。而我們需要明確的數據的來源,也就是目的端口、源端口、長度、校驗和(不考慮)是如何得到的。對于源端口號而言則非常明確,一定是操作系統通過特定的操作動態生成的,而目的端口號則是通過系統調用接口參數獲取到的,也就是sendto接口中的sockaddr_in參數獲取,當然目的IP地址同理,最后是UDP長度,同理該數據來源也是sendto接口,只不過此時是其中的第三個參數size_t len參數,通過應用層提前計算好發送數據的大小提供給系統調用接口,當然也就是操作系統,然后操作系統根據規則默認加8,從而構成了該長度大小。同理解包過程,當然也就是分用的本質: 還是將數據拷貝到一個char *類型的緩沖區中,然后先獲取前8個字節并同理將其類型轉換成struct udp_header *指針類型,讀取對應變量數據,獲取UDP長度,再減去報頭長度,得到應用層報文長度,最后向后讀取該長度字節的數據。當然最后如何進行數據交付,上述詳談,也就是讓操作系統進行匹配操作。
上述內容就是有關UDP協議的學習,對于UDP協議的特點無連接、不可靠、面向數據報而言之前介紹過,這里我們再重點理解一下面向數據報,區別于TCP的面向字節流,面向數據報也就是UDP協議在讀取數據時,每一次數據讀取都是固定的,也就是對端每一次發送多少,對應我就只能讀取多少,無法像TCP一樣,讀取任意字節大小的數據。其次明確,因為UDP協議沒有發送緩沖區,只有接收緩沖區,所以它們不存在共享資源的概念,所以允許一邊讀取,一邊發送,也就是對于UDP協議而言,它是全雙工的,反之稱為半雙工。拓展: 查看進程ID指令pidof 進程名









![找到數組的中間位置-1991-[簡單]](http://pic.xiahunao.cn/找到數組的中間位置-1991-[簡單])



)




)
