本系列是基于OcenaBase 開發工程師在工作中的一些診斷經驗,也歡迎大家分享相關經驗。
1. 關于神醫的故事
扁鵲,中國古代第一個被正史記載的醫生,他的成才之路非常傳奇。年輕時,扁鵲是一家客棧的主管。有一位名叫長桑君的客人來到客棧,只有扁鵲看出他是一個不凡之人,對他非常恭敬。長桑君也知道扁鵲不同凡人,十多年里,他在客棧來來去去。有一天,長桑君請扁鵲和他坐在一起,悄聲告訴他:“我有秘傳的醫術,但我年事已高,想傳授給你,你不要外傳。”扁鵲答應了他,長桑君便將這些秘傳的醫術傳授給了扁鵲,然后便消失了。從此,扁鵲就像是得到了神仙的點撥一般,打通了“任督二脈”,短短三十天內就成為了絕世神醫。而扁鵲之所以能成為一代神醫,最重要的一點就是長桑君的那本秘籍。由此可見,要想成為OceanBase數據庫的“神醫”并成功診斷OceanBase數據庫,也需要一份秘籍。今天我將詳細揭秘在大部分場景下,診斷OceanBase故障的秘籍是什么?
2. OceanBase診斷秘籍
大部分場景下OceanBase的問題都可以通過以下的三板斧:環境分析、日志分析、性能視圖分析來定位和分析問題。所以我們的秘籍總結起來如下:
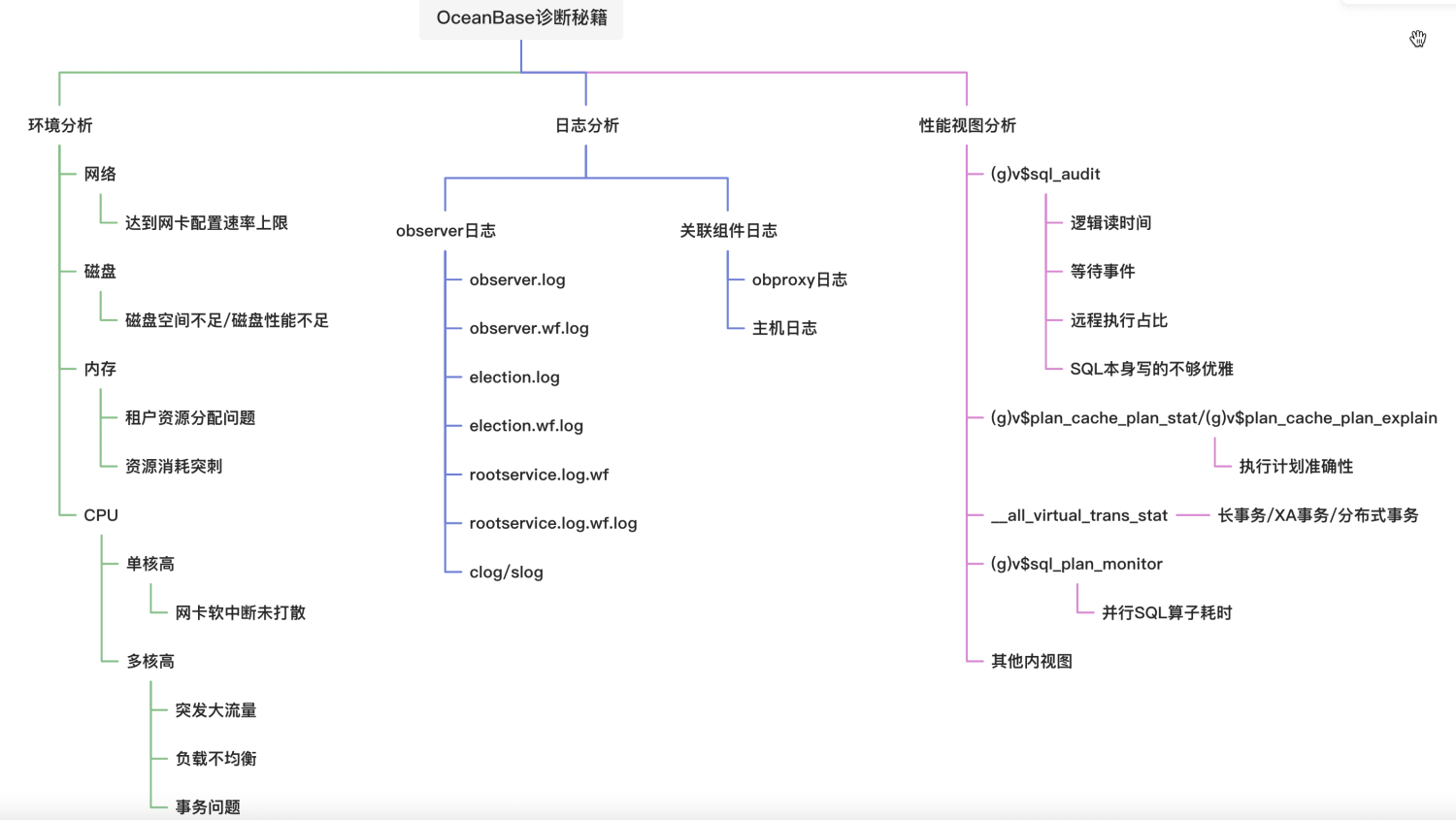
環境問題的分析和其他系統并無區別,主要是去分析一下網絡、磁盤、內存、CPU等信息,本文接下來的章節不做細致展開。文章會從日志分析和性能視圖分析做展開,帶你一覽OceanBase診斷的秘籍。
2.1.?日志分析
2.1.1.?日志概述
日志分析中最重要的就是OceanBase本身的日志。OceanBase 數據庫日志模塊所屬的日志文件分為?observer.log?、election.log和?rootservice.log?三種類型,默認打印 INFO 級別以上的日志。每類日志文件自動生成一個帶有?.wf?后綴的 WARNING 日志文件(?observer.log.wf、election.log.wf?、rootservice.log.wf?),只打印了 WARN 級別以上的日志。
| 日志名稱 | 日志路徑 |
| 啟動和運行日志( observer.log 、observer.log.wf ) | OBServer 服務器的 $work_dir/log 目錄下。 |
| 選舉模塊日志( election.log 、election.log.wf ) | OBServer 服務器的 $work_dir/log 目錄下。 |
| RootService 日志( rootservice.log 、rootservice.log.wf ) | OBServer 服務器的 $work_dir/log 目錄下。 |
OceanBase 數據庫日志劃分了六個日志級別,含義如下表所示。表中的日志級別從高到低依次排列。
| 日志級別 | 含義 |
| ERROR | 嚴重錯誤。用于記錄系統的故障信息,且必須進行故障排除,否則系統不可用。 |
| USER_ERROR | 用戶輸入導致的錯誤。 |
| WARN | 警告。用于記錄可能會出現的潛在錯誤。 |
| INFO | 提示。用于記錄系統運行的當前狀態,該信息為正常信息。 |
| TRACE | 與 INFO 相比更細致化地記錄事件消息。 |
| DEBUG | 調試信息。用于調試時更詳細地了解系統運行狀態,包括當前調用的函數名、參數、變量、函數調用返回值等。 |
2.1.2.?日志格式
日志數據格式如下,具體格式以實際情況為準。
- [time] log_level [module_name] (file_name:fine_no) [thread_id][Y_trace_id0-trace_id1] [lt=last_log_print_time] [dc=dropped_log_count] log_data_
- [time] log_level [module_name] function_name (file_name:fine_no) [thread_id][Y_trace_id0-trace_id1] [lt=last_log_print_time] [``dc=``dropped_log_count] log_data_
[admin@OceanBase000000000.sqa.ztt /home/admin/oceanbase/log]
$tail -f -n 1 observer.log
[2016-07-17 14:18:04.845802] INFO [RPC.OBMYSQL] obsm_handler.cpp:191 [9543][Y0-0] [lt=47] [dc=0] connection close(easy_connection_str(c)="192.168.0.2:56854_-1_0x7fb8a9171b68", version=0, sessid=2147562562, tenant_id=1, server_id=1, is_need_clear_sessid_=true, ret=0)
[admin@OceanBase000000000.sqa.ztt /home/admin/oceanbase/log]
$tail -f -n 1 observer.log.wf
[2016-07-17 14:18:28.431351] WARN [SQL.SESSION] set_conn (ob_basic_session_info.cpp:2568) [8541][YB420AF4005E-52A8CF4E] [lt=16] [dc=0] debug for set_conn(conn=0x7fb8a9171b68, lbt()="0x4efe71 0x818afd 0xe9ea5b 0x721fc8 0x13747bc 0x2636db0 0x2637d68 0x5054e9 0x7fb98705aaa1 0x7fb9852cc93d ", magic_num_=324478056, sessid_=2147562617, version_=0)
[admin@OceanBase000000000.sqa.ztt /home/admin/oceanbase/log]
$tail -f -n 1 rootservice.log
[2016-07-17 14:18:53.701463] INFO [RS] ob_server_table_operator.cpp:345 [8564][Y0-0] [lt=11] [dc=0] svr_status(svr_status="active", display_status=1)
[admin@OceanBase000000000.sqa.ztt /home/admin/oceanbase/log]
$tail -f -n 1 rootservice.log.wf
[2016-07-16 02:02:12.847602] WARN [RS] choose_leader (ob_leader_coordinator.cpp:2067) [8570][YB420AF4005E-4626EDFC] [lt=8] [dc=0] choose leader info with not same candidate num(tenant_id=1005, server="192.168.0.1:2882", info={original_leader_count:0, primary_zone_count:0, cur_leader_count:1, candidate_count:1, in_normal_unit_count:1})
2.1.3. 日志診斷秘籍
關注日志信息,尤其是錯誤日志信息,根據OceanBase的日志模型建立日志收集告警機制。
2.1.4. 日志診斷例子



2.2. 性能視圖分析
2.2.1. gv$sql_audit
OceanBase在SQL性能診斷方面有個很有用的功能叫SQL審計視圖(OceanBase 4.0 版本以前是gv$sql_audit,OceanBase 4.0以后是gv$ob_sql_audit,下文均以為OB 4.0版本以前為例,不再做特別說明)。該視圖可以方便開發運維排查在OceanBase運行過的任意一條SQL,不管這些SQL是成功還是失敗,都有詳細的運行信息記錄。GV$SQL_AUDIT ?的含義是查出每一臺機器上的 SQL_AUDIT 記錄,而 V$SQL_AUDIT 是查出連接的這臺server的SQL_AUDIT 記錄。如果是查詢 V$SQL_AUDIT ,無法確定請求會被路由到哪一臺機器上。所以如果想查詢某一臺機器上的SQL_AUDIT記錄,一定要直連到要這臺機器,或者查詢 GV$SQL_AUDIT 然后通過指定機器的 IP 與端口號來訪問具體機器的記錄。詳細的字段解釋可以參閱官網文檔。
幾點注意事項:
- SQL_AUDIT 是維護在內存中的,因此它的數據不可能無限地存放。所以當內存到達一定限制的時候,會觸發一些淘汰機制,以保證新的記錄能夠寫進去。SQL_AUDIT 采用先進先出的自動淘汰機制,內存到達高水位線(90%)的時候會自動觸發淘汰,直至內存達到低水位線(50%)。
- 除了基于內存水位線的淘汰,SQL_AUDIT 還有一個淘汰策略,當 SQL_AUDIT 的記錄達到 900 萬條的時候會觸發淘汰,一直淘汰到記錄剩 500 萬條為止。
- 此外,SQL_AUDIT 提供了一個集群級的配置項 enable_sql_audit 和一個租戶級的配置項 ob_enable_sql_audit,只有這兩個配置項都為 true 的時候,SQL_AUDIT 才會生效,否則為關閉狀態。
2.2.2. 性能視圖診斷案例
Case 1: 如何查看集群 SQL 的請求量是否均勻?
Action: 可以去查 SQL_AUDIT,找出某個時間段內所有執行的用戶 SQL, 然后在 server IP 的維度上做聚合,最后求出每一個 server IP 的分組里面,此時間段內有多少 SQL ,就可以大概得出每一個 server 上的流量。
select/*+ parallel(15)*/t2.zone, t1.svr_ip, count(*) as QPS, avg(t1.elapsed_time), avg(t1.queue_time)
from oceanbase.gv$sql_audit t1, __all_server t2
where t1.svr_ip = t2.svr_ip and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 1000000) and request_time < time_to_usec(now())
group by t1.svr_ip
order by t2.zone;Case 2: 如何找到消耗 CPU 最多的 SQL 。
Action: 首先查出某一個時間段內所有執行的用戶 SQL, 然后在 SQL_ID 維度上做聚合,求出每一個 SQL_ID 總的執行時間。這里的執行時間 = ELAPSED_TIME - QUEUE_TIME ,因為在隊列里等待的時間并沒有消耗 CPU ,實際消耗 CPU 的就是獲取和執行計劃的時間。最終可以基于這些消耗 CPU 最多的 SQL 做一些性能分析、性能調優之類的工作。
Case 3:如何分析 RT 突然抖動的 SQL?
Action:在此場景下,可以在抖動出現后立即將 SQL_AUDIT 關閉,保證產生抖動的 SQL 能夠在 SQL_AUDIT 中使用?(g)v$sql_audit?進行問題排查方式如下:
- 在線上如果出現 RT 抖動,但 RT 并不是持續很高的情況,可以考慮在抖動出現后,立刻將 sql_audit 關閉?(alter system set ob_enable_sql_audit = 0),從而確保該抖動的 SQL 請求在 sql_audit 中存在。
- 通過 SQL Audit 查詢抖動附近那段時間 RT 的 TOP N 請求,分析有異常的 SQL。
- 找到對應的 RT 異常請求,則可以分析該請求在 sql_audit 中的記錄進行問題排查:
- 查看 retry 次數是否很多(RETRY_CNT?字段),如果次數很多,則可能有鎖沖突或切主等情況。
- 查看 queue time 的值是否過大(QUEUE_TIME?字段)。
- 查看獲取執行計劃時間(GET_PLAN_TIME?字段),如果時間很長,一般會出現?IS_HIT_PLAN = 0,表示沒有命中 plan cache。
- 查看 EXECUTE_TIME 的值,如果值過大,則可以通過以下步驟進行排查:
a. 查看是否有很長等待事件耗時。
b. 分析邏輯讀次數是否異常多(突然有大賬戶時可能會出現)。
邏輯讀次數 = 2 * ROW_CACHE_HIT + 2 * BLOOM_FILTER_CACHE_HIT + BLOCK_INDEX_CACHE_HIT + BLOCK_CACHE_HIT + DISK_READS如果在 SQL Audit 中 RT 抖動的請求數據已被淘汰,則需要查看 OBServer 中抖動時間點是否有慢查詢的 trace 日志,并分析對應的 trace 日志。
3. 一個愿景
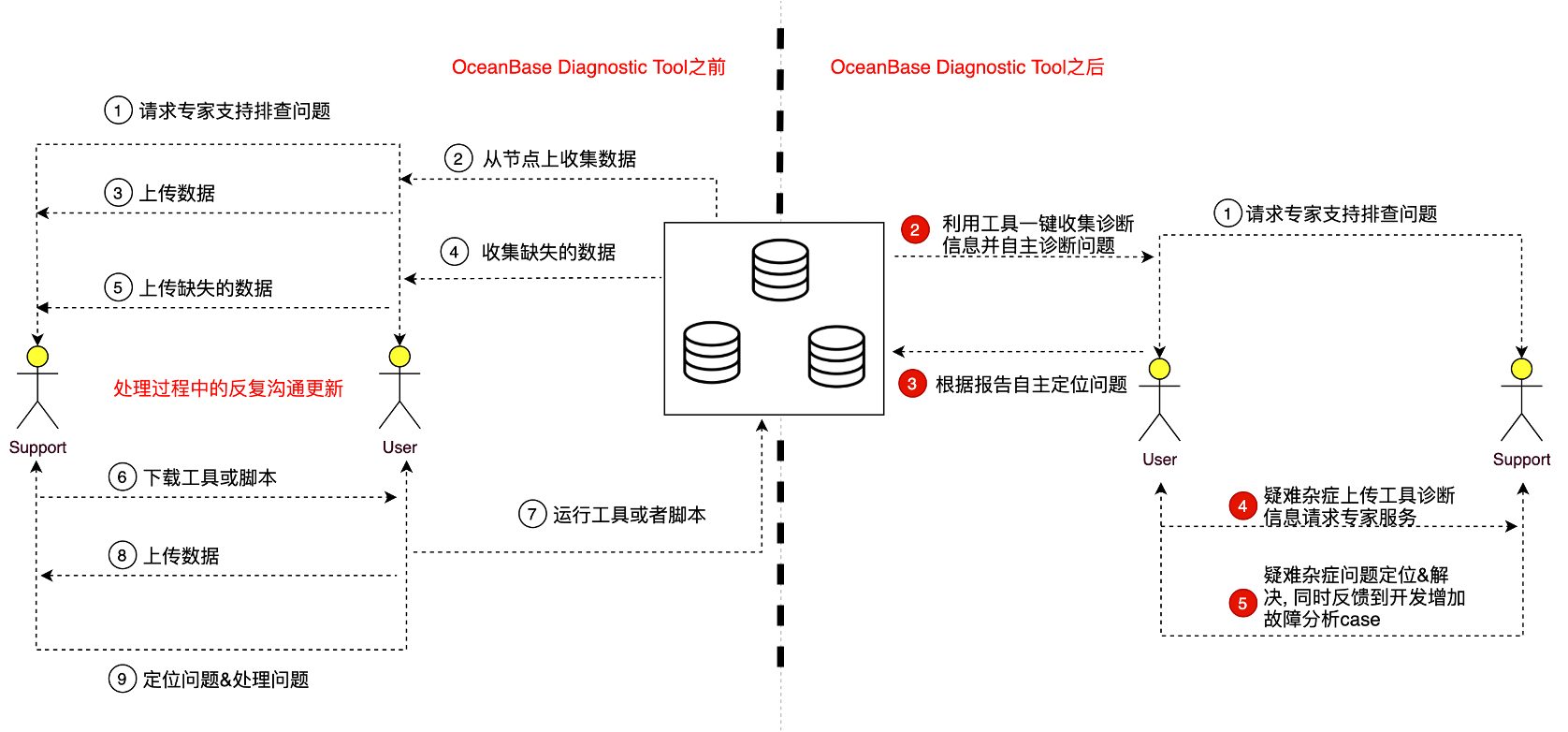
OceanBase是原生分布式數據庫系統,故障根因分析通常是比較繁瑣的,因為涉及的因素可能有很多,如機器環境、配置參數、運行負載等等。所以我們的愿景是:讓診斷OceanBase變得更快更容易。
4. 一個工具箱
4.1. 特性介紹
OceanBase是原生分布式數據庫系統,故障根因分析通常是比較繁瑣的,因為涉及的因素可能有很多,如機器環境、配置參數、運行負載等等。專家在排查問題的時候需要獲取大量的信息來分析故障,如何高效的獲取故障場景下分散在各個節點的信息,挖掘出其中的關聯性便是OceanBase敏捷診斷工具(OceanBase Diagnostic Tool) ,簡稱obdiag。需要解決的問題。
obdiag定位為OceanBase敏捷診斷工具。整體使用上備以下的特點:
- 部署簡單:提供rpm包和OBD上部署的模式,均可一鍵部署安裝,可以選擇部署到任意一臺能連接到集群各個節點的上,并不局限于OBServer節點。
- 開箱即用:使用中所依賴的python包,全部都是自包含的,只需要部署機器存在python2或者python3環境即可;
- 集中式收集:單點部署,無需每臺服務器部署。使用的時候只需要在部署機器上執行收集或分析命令即可;
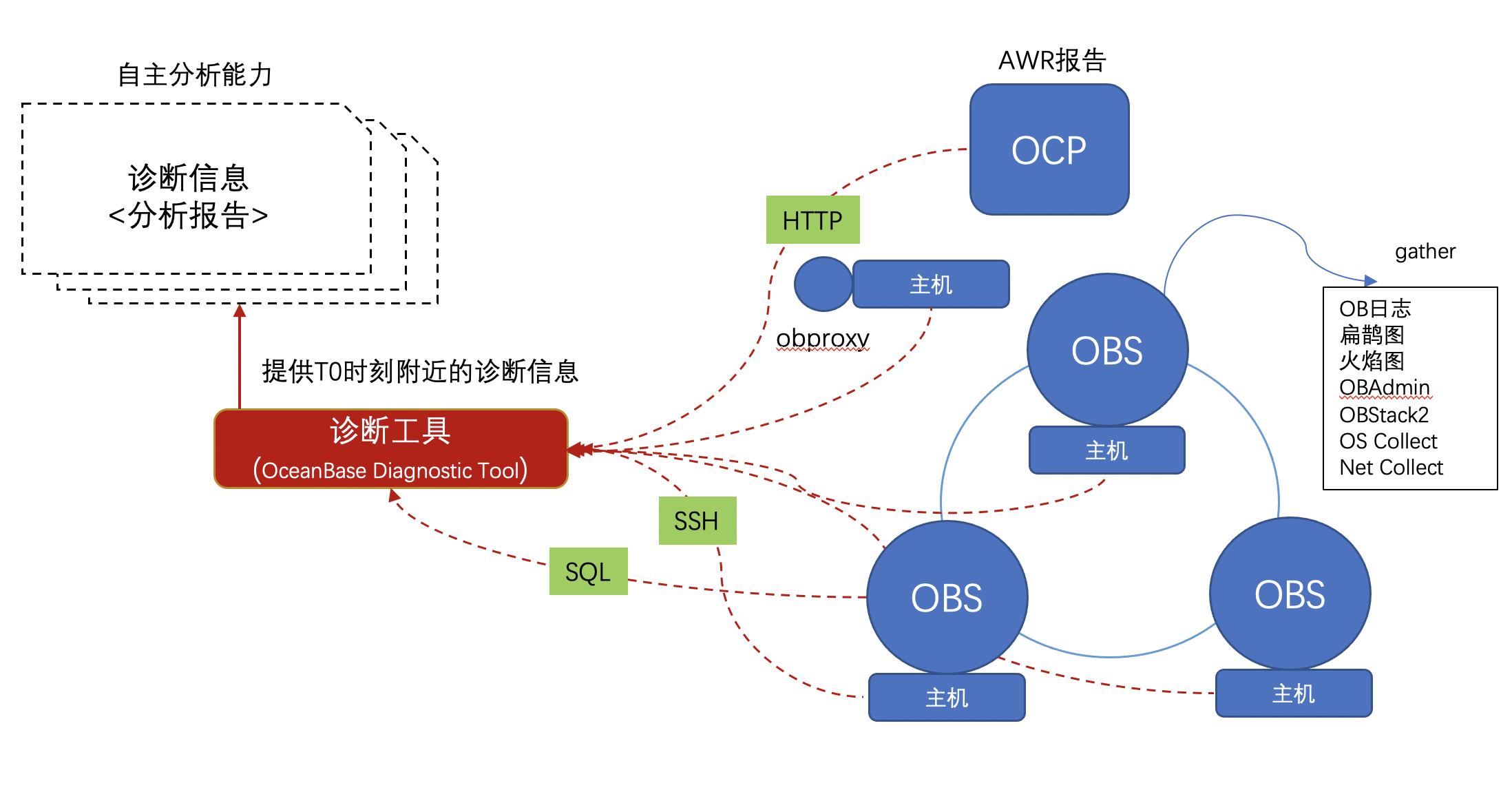
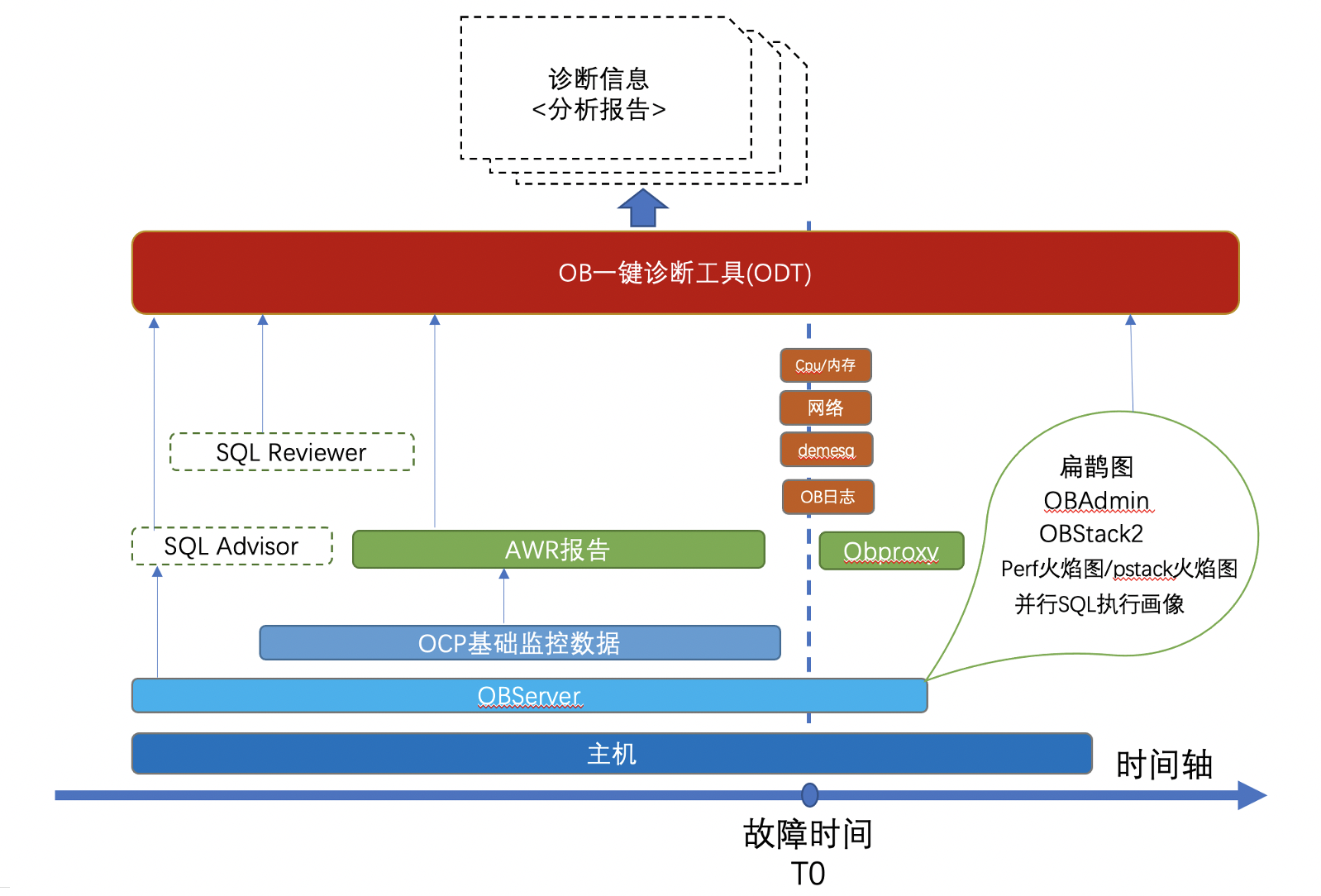
obdiag現有功能包含了對于OceanBase日志、SQL Audit以及OceanBase進程堆棧等信息進行的掃描、收集,可以在OceanBase集群不同的部署模式下(OCP,OBD或用戶根據文檔手工部署)實現一鍵執行。未來會加入診斷分析能力。一方面在現有采集能力的基礎上增加有效信息提取分析的能力形成診斷分析報告;另一方面將已有的SQL Reviewer(OceanBase的SQL審核工具)和SQL Diagnoser(OceanBase的敏捷SQL診斷工具)進行整合,擴展工具在SQL層面的診斷能力。
obdiag-1.2.0版本支持以下功能:
- 一鍵收集OB日志
- 一鍵收集AWR報告
- 一鍵收集主機信息
- 一鍵收集OB堆棧信息
- 一鍵收集(clog、slog解析后的日志)
- 一鍵收集perf信息(扁鵲圖、perf火焰圖、pstack火焰圖)
- 一鍵收集并行SQL的執行詳情信息
- 一鍵收集OBPROXY的日志
待解鎖功能(敬請期待): - 集成SQL Reviewer/SQL Diagnoser能力,支持一鍵分析SQL問題。
- 在診斷信息采集的基礎上加入自主分析能力,支持生成診斷信息分析報告
- 抽取OceanBase常見問題,形成快速診斷套餐
4.2. OBD模式下安裝使用obdiag
如果你的OceanBase集群是通過OBD安裝部署的,并且OBD的版本大于2.1.0那么,你可以直接通過下面的方式使用。
4.2.1. 安裝
- 安裝OBD 2.1.0 及以上版本
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/oceanbase/OceanBase.repo
sudo yum install -y ob-deploy
source /etc/profile.d/obd.sh
- 安裝obdiag工具
使用該命令可部署obdiag工具可在本機安裝部署obdiag, (如果用戶不安裝直接使用也會走自動安裝流程)
obd obdiag deploy4.2.2. 使用
4.2.2.1. obd obdiag gather
使用該命令可調用obdiag工具進行OceanBase相關的診斷信息收集
obd obdiag gather <gather type> <deploy name> [options]gather type包含:
- log:一鍵收集所屬OceanBase集群的日志?
- sysstat:一鍵收集所屬OceanBase集群主機信息?
- clog:一鍵收集所屬OceanBase集群(clog日志)?
- slog:一鍵收集所屬OceanBase集群(slog日志)?
- plan_monitor:一鍵收集所屬OceanBase集群指定trace_id的并行SQL的執行詳情信息?
- stack:一鍵收集所屬OceanBase集群的堆棧信息?
- perf:一鍵收集所屬OceanBase集群的perf信息(扁鵲圖、perf火焰圖、pstack火焰圖)?
- obproxy_log:一鍵收集所屬OceanBase集群所依賴的obproxy組件的日志?
- all:一鍵統一收集所屬OceanBase集群的診斷信息,包括收集OceanBase日志/主機信息/OceanBase堆棧信息/OceanBase clog、slog日志/OceanBase perf信息(扁鵲圖、perf火焰圖、pstack火焰圖)?
4.3. 獨立安裝使用obdiag
4.3.1. obdiag下載
obdiag工具可從OceanBase官網下載免費下載,下載鏈接
4.3.1. obdiag使用文檔
- 安裝文檔:?OceanBase分布式數據庫-海量數據 筆筆算數
- 配置文檔:?OceanBase分布式數據庫-海量數據 筆筆算數
- 使用文檔:?OceanBase分布式數據庫-海量數據 筆筆算數
5.?總結
當遇到OceanBase的問題時候,很多工程師可能會感到無從下手,本文介紹了一般情況下OceanBase的故障診斷路徑,大家可通過環境分析、日志分析、性能視圖分析來定位和分析問題。同時給大家推薦了一個很好用的OceanBase敏捷診斷工具(OceanBase Diagnostic Tool) ,簡稱obdiag,幫助大家方便的獲取這些故障信息。
| 第一篇 | “神醫”的修煉秘籍——《OceanBase診斷系列》之一 |
| 第二篇 | 《OceanBase診斷系列》——帶你認識sql_audit性能視圖 |
 靜態合批步驟與所有注意事項\游戲運行時使用代碼啟動靜態合批)

)
與激活函數)




![[數據集][目標檢測]雞蛋破蛋數據集VOC+YOLO格式792張2類別](http://pic.xiahunao.cn/[數據集][目標檢測]雞蛋破蛋數據集VOC+YOLO格式792張2類別)








)

)