目錄
第二篇 外部系統集成
第三篇 生產調優手冊
第1章 kafka硬件配置選擇
第2章 生產者調優
2.1 生產者核心參數配置
2.2 生產者如何提高吞吐量
2.3 數據可靠性
2.4 數據去重
2.5 數據有序
2.6 數據亂序
第3章 Kafka Broker調優
3.1 Broker核心參數配置
3.2 其他
第4章 消費者調優
4.1 消費者核心參數配置
4.2 消費者再平衡
4.3 指定offset消費
4.4 指定時間消費
4.5?消費者事務
4.6?消費者如何提高吞吐量
第5章 Kafka總體看調優
5.1 如何提升吞吐量★★★★★
5.2 數據精準一次
5.3 合理設置分區數
5.4 單條日志大于1m
5.5 服務器掛了
5.6 集群壓力測試
第四篇 源碼分析
第2章 生產者源碼
2.1 初始化
2.2?之后的略,詳見文檔
2.3 畫圖軟件推薦drawio
第二篇 外部系統集成
Flume、Spark、Flink、SpringBoot 這些組件都可以作為kafka的生產者和消費者,在企業中非常常見。
Flume官網:Welcome to Apache Flume — Apache Flume
Flink:Apache Flink_百度百科?
Spark:Apache Spark_百度百科
集成SpringBoot:略。?
第三篇 生產調優手冊
第1章 kafka硬件配置選擇

第2章 生產者調優
2.1 生產者核心參數配置
發送流程:做到心中有圖,回憶。
生產者核心參數:
| 參數名稱 | 描述 |
|---|---|
| bootstrap.servers | 生產者連接集群所需的 broker 地址清單。例如hadoop102:9092,hadoop103:9092,hadoop104:9092,可以設置 1 個或者多個,中間用逗號隔開。注意這里并非需要所有的 broker 地址,因為生產者從給定的 broker 里查找到其他 broker 信息。 |
| key.serializer 和 value.serializer ? | 指定發送消息的 key 和 value 的序列化類型。一定要寫全類名。 |
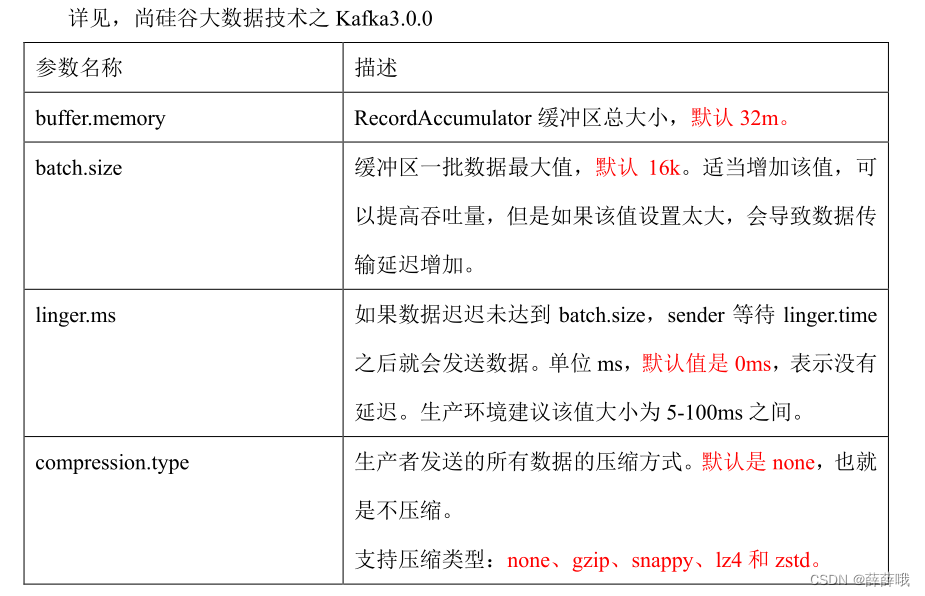
| buffer.memory | RecordAccumulator 緩沖區總大小,默認32m。 |
| batch.size | 緩沖區一批數據最大值,默認16k。適當增加該值,可以提高吞吐量,但是如果該值設置太大,會導致數據傳輸延遲增加。 |
| linger.ms | 如果數據遲遲未達到 batch.size,sender 等待 linger.time之后就會發送數據。單位 ms,默認值是 0ms,表示沒有延遲。生產環境建議該值大小為 5-100ms 之間。 |
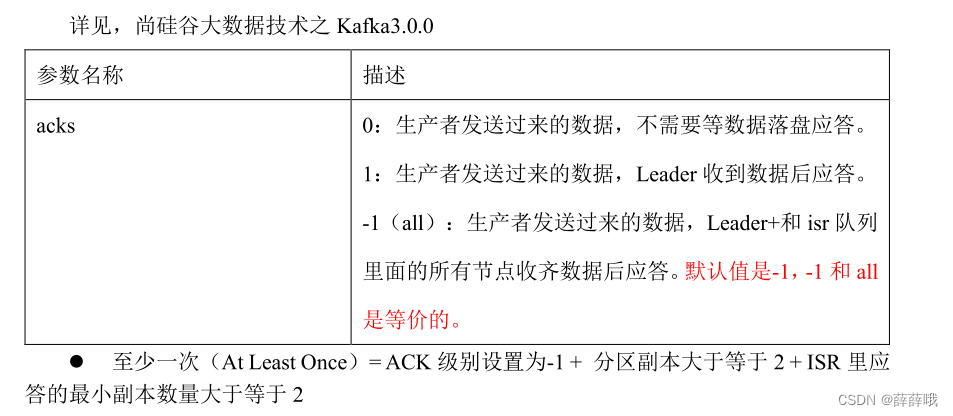
| acks | 0:生產者發送過來的數據,不需要等數據落盤應答。 1:生產者發送過來的數據,Leader 收到數據后應答。 -1(all):生產者發送過來的數據,eader+和 isr 隊列里面的所有節點收齊數據后應答。默認值是-1,-1 和 all是等價的。 |
| max.in.flight.requests.per.connection | 允許最多沒有返回 ack 的次數,默認為 5,開啟冪等性要保證該值是 1-5 的數字。 |
| retries | 當消息發送出現錯誤的時候,系統會重發消息。retries 表示重試次數。默認是 int 最大值,2147483647。如果設置了重試,還想保證消息的有序性,需要設置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1,否則在重試此失敗消息的時候,其他的消息可能發送成功了。 |
| retry.backoff.ms | 兩次重試之間的時間間隔,默認是 100ms。 |
| enable.idempotence | 是否開啟冪等性,默認 true,開啟冪等性。 |
| compression.type | 生產者發送的所有數據的壓縮方式。默認是 none,也就是不壓縮。支持壓縮類型:none、gzip、snappy、lz4 和 zstd。 |
2.2 生產者如何提高吞吐量
2.3 數據可靠性
2.4 數據去重
略。
2.5 數據有序
單分區內,有序(有條件的,不能亂序);多分區,分區與分區間無序。
2.6 數據亂序

第3章 Kafka Broker調優
3.1 Broker核心參數配置
Kafka Broker總體工作流程:心中有圖,回憶。
Broker核心參數:
| 參數名稱 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 長時間未向 Leader 發送通信請求或同步數據,則該 Follower 將被踢出 ISR。該時間閾值,默認 30s。 |
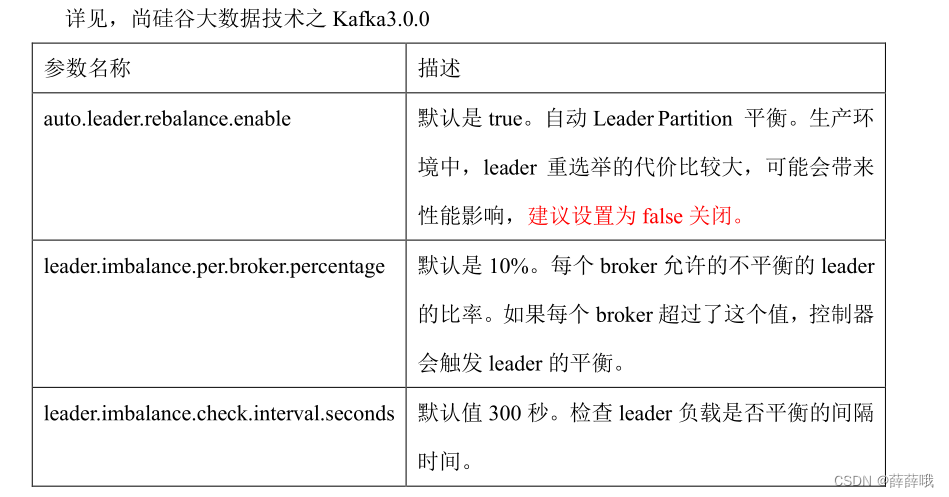
| auto.leader.rebalance.enable | 默認是 true。 自動 Leader Partition 平衡。建議關閉。 |
| leader.imbalance.per.broker.percentage | 默認是 10%。每個 broker 允許的不平衡的 leader的比率。如果每個 broker 超過了這個值,控制器會觸發 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默認值 300 秒。檢查 leader 負載是否平衡的間隔時間。 |
| log.segment.bytes | Kafka 中 log 日志是分成一塊塊存儲的,此配置是指 log 日志劃分成塊的大小,默認值 1G。 |
| log.index.interval.bytes | 默認4kb,kafka 里面每當寫入了 4kb 大小的日志(.log),然后就往 index 文件里面記錄一個索引。 |
| log.retention.hours | Kafka 中數據保存的時間,默認 7 天。生成中一般設置3天 |
| log.retention.minutes | Kafka 中數據保存的時間,分鐘級別,默認關閉。 |
| log.retention.ms | Kafka 中數據保存的時間,毫秒級別,默認關閉。 |
| log.retention.check.interval.ms | 檢查數據是否保存超時的間隔,默認是 5 分鐘。 |
| log.retention.bytes | 默認等于-1,表示無窮大。超過設置的所有日志總大小,刪除最早的 segment。 |
| log.cleanup.policy | 默認是 delete,表示所有數據啟用刪除策略; |
| num.io.threads | 默認是 8。負責寫磁盤的線程數。整個參數值要占總核數的 50%。 |
| num.replica.fetchers | 默認是 1。副本拉取線程數,這個參數占總核數的 50%的 1/3 |
| num.network.threads | 默認是 3。數據傳輸線程數,這個參數占總核數的 50%的 2/3 。 |
| log.flush.interval.messages | 強制頁緩存刷寫到磁盤的條數,默認是 long 的最大值,9223372036854775807。一般不建議修改,交給系統自己管理。 |
| log.flush.interval.ms | 每隔多久,刷數據到磁盤,默認是 null。一般不建議修改,交給系統自己管理。 |
?
3.2 其他
1. 服役/退役新節點
(1)創建一個要均衡的主題。
(2)生成一個負載均衡的計劃。
(3)創建副本存儲計劃(所有副本存儲在 broker0、broker1、broker2、broker3 中)。
(4)執行副本存儲計劃。
(5)驗證副本存儲計劃。
2. 增加分區
分區只能增加,不能減少。
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --alter --topic first --partitions 3
3. 增加副本因子
4. 手動調整分區副本存儲
5. Leader Partition負載均衡
6. 自動創建主題
如果 broker 端配置參數 auto.create.topics.enable 設置為 true(默認值是 true),那么當生
產者向一個未創建的主題發送消息時,會自動創建一個分區數為 num.partitions(默認值為
1)、副本因子為 default.replication.factor(默認值為 1)的主題。除此之外,當一個消費者
開始從未知主題中讀取消息時,或者當任意一個客戶端向未知主題發送元數據請求時,都會
自動創建一個相應主題。這種創建主題的方式是非預期的,增加了主題管理和維護的難度。
生產環境建議將該參數設置為 false。
第4章 消費者調優
4.1 消費者核心參數配置
消費者組初始化流程:回憶。
消費者組詳細消費流程如下:
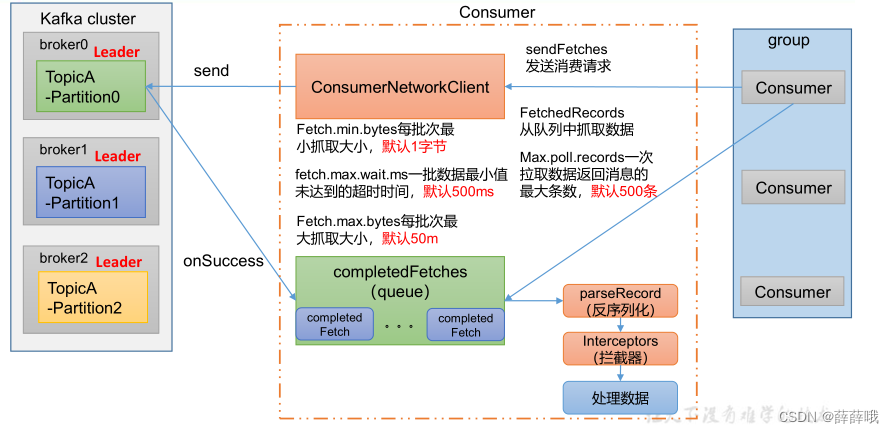
消費者核心參數:
| 參數名稱 | 描述 |
|---|---|
| bootstrap.servers? | 向 Kafka 集群建立初始連接用到的 host/port 列表。 |
| key.deserializer 和 value.deserializer | 指定接收消息的 key 和 value 的反序列化類型。一定要寫全類名。 |
| group.id | 標記消費者所屬的消費者組。 |
| enable.auto.commit | 默認值為 true,消費者會自動周期性地向服務器提交偏移量。 |
| auto.commit.interval.ms | 如果設置了 enable.auto.commit 的值為 true, 則該值定義了消費者偏移量向 Kafka 提交的頻率,默認 5s。 |
| auto.offset.reset | 當 Kafka 中沒有初始偏移量或當前偏移量在服務器中不存在(如,數據被刪除了),該如何處理?? earliest:自動重置偏移量到最早的偏移量。 latest:默認,自動重置偏移量為最新的偏移量。? none:如果消費組原來的(previous)偏移量不存在,則向消費者拋異常。? anything:向消費者拋異常。 |
| offsets.topic.num.partitions | __consumer_offsets 的分區數,默認是 50 個分區。不建議修改。 |
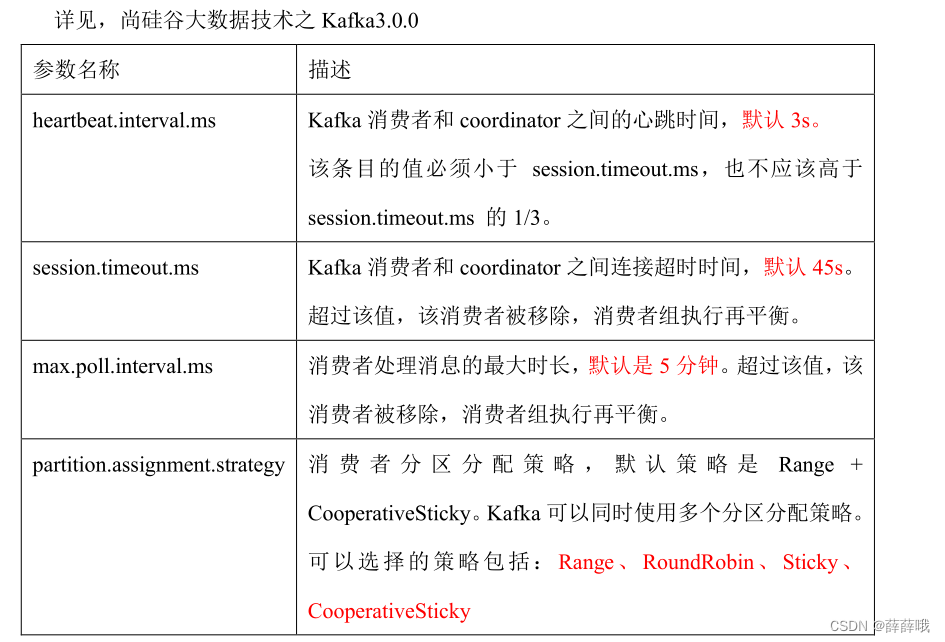
| heartbeat.interval.ms | Kafka 消費者和 coordinator 之間的心跳時間,默認 3s。該條目的值必須小于 session.timeout.ms ,也不應該高于session.timeout.ms 的 1/3。不建議修改。 |
| session.timeout.ms? | Kafka 消費者和 coordinator 之間連接超時時間,默認 45s。超過該值,該消費者被移除,消費者組執行再平衡。 |
| max.poll.interval.ms | 消費者處理消息的最大時長,默認是 5 分鐘。超過該值,該消費者被移除,消費者組執行再平衡。 |
| fetch.min.bytes | 默認 1 個字節。消費者獲取服務器端一批消息最小的字節數。 |
| fetch.max.wait.ms | 默認 500ms。如果沒有從服務器端獲取到一批數據的最小字節數。該時間到,仍然會返回數據。 |
| fetch.max.bytes | 默認 Default: 52428800(50 m)。消費者獲取服務器端一批消息最大的字節數。如果服務器端一批次的數據大于該值(50m)仍然可以拉取回來這批數據,因此,這不是一個絕對最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影響。 |
| max.poll.records | 一次 poll 拉取數據返回消息的最大條數,默認是 500 條。 |
4.2 消費者再平衡
4.3 指定offset消費
4.4 指定時間消費
4.5?消費者事務
4.6?消費者如何提高吞吐量
回憶。
第5章 Kafka總體看調優
5.1 如何提升吞吐量★★★★★
1)提升生產吞吐量
(1)buffer.memory:發送消息的緩沖區大小,默認值是 32m,可以增加到 64m。
(2)batch.size:默認是 16k。如果 batch 設置太小,會導致頻繁網絡請求,吞吐量下降;
如果 batch 太大,會導致一條消息需要等待很久才能被發送出去,增加網絡延時。
(3)linger.ms,這個值默認是 0,意思就是消息必須立即被發送。一般設置一個 5-100毫秒。如果 linger.ms 設置的太小,會導致頻繁網絡請求,吞吐量下降;如果 linger.ms 太長,會導致一條消息需要等待很久才能被發送出去,增加網絡延時。
(4)compression.type:默認是 none,不壓縮,但是也可以使用 lz4 壓縮,效率還是不錯的,壓縮之后可以減小數據量,提升吞吐量,但是會加大 producer 端的 CPU 開銷。
2)增加分區
3)消費者提高吞吐量
(1)調整 fetch.max.bytes 大小,默認是 50m。
(2)調整 max.poll.records 大小,默認是 500 條。
4)增加下游消費者處理能力
5.2 數據精準一次
1) 生產者角度
- acks 設置為-1 (acks=-1)。
- 冪等性(enable.idempotence = true) + 事務 。
2) broker服務端角度
- 分區副本大于等于2(--replication-factor 2)。
- ISR 里應答的最小副本數量大于等于2(min.insync.replicas = 2)。
3) 消費者
- 事務 + 手動提交offset(enable.auto.commit = false)。
- 消費者輸出的目的地必須支持事務(MySQL、Kafka)。
5.3 合理設置分區數
(1)創建一個只有 1 個分區的 topic。
(2)測試這個 topic 的 producer 吞吐量和 consumer 吞吐量。
(3)假設他們的值分別是 Tp 和 Tc,單位可以是 MB/s。
(4)然后假設總的目標吞吐量是 Tt,那么分區數 = Tt / min(Tp,Tc)。
例如:producer 吞吐量 = 20m/s;consumer 吞吐量 = 50m/s,期望吞吐量 100m/s;
分區數 = 100 / 20 = 5 分區
分區數一般設置為:3-10 個
分區數不是越多越好,也不是越少越好,需要搭建完集群,進行壓測,再靈活調整分區個數。
5.4 單條日志大于1m

5.5 服務器掛了
在生產環境中,如果某個 Kafka 節點掛掉。
正常處理辦法:
(1)先嘗試重新啟動一下,如果能啟動正常,那直接解決。
(2)如果重啟不行,考慮增加內存、增加 CPU、網絡帶寬。
(3)如果將 kafka 整個節點誤刪除,如果副本數大于等于 2,可以按照服役新節點的方式重新服役一個新節點,并執行負載均衡。
5.6 集群壓力測試
1. 生產者壓力測試
通過動態調整以下4個參數來控制
- batch.size=16384
- linger.ms=0
- compression.type
- buffer.memory
2. 消費者壓力測試
- max.poll.records(一次拉取條數)默認是500條;
- fetch.max.bytes(拉取一批數據大小)默認是50M;
通過修改這兩個參數的值來進行測試。這兩個參數在kafka/config/consumer.properties 文件中進行配置。這兩個參數可以提高吞吐量。
=========================源碼解析=============================
第四篇 源碼分析
第2章 生產者源碼
回憶發送流程原理圖,結合原理圖看源碼更容易。
發送流程:
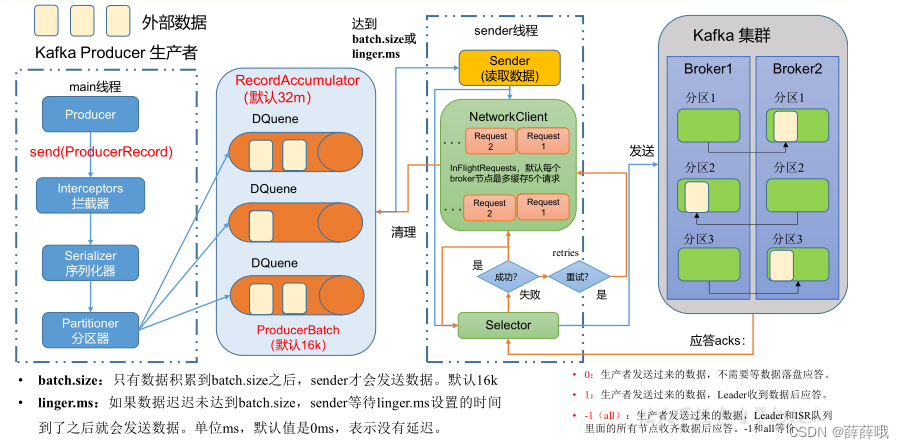
2.1 初始化
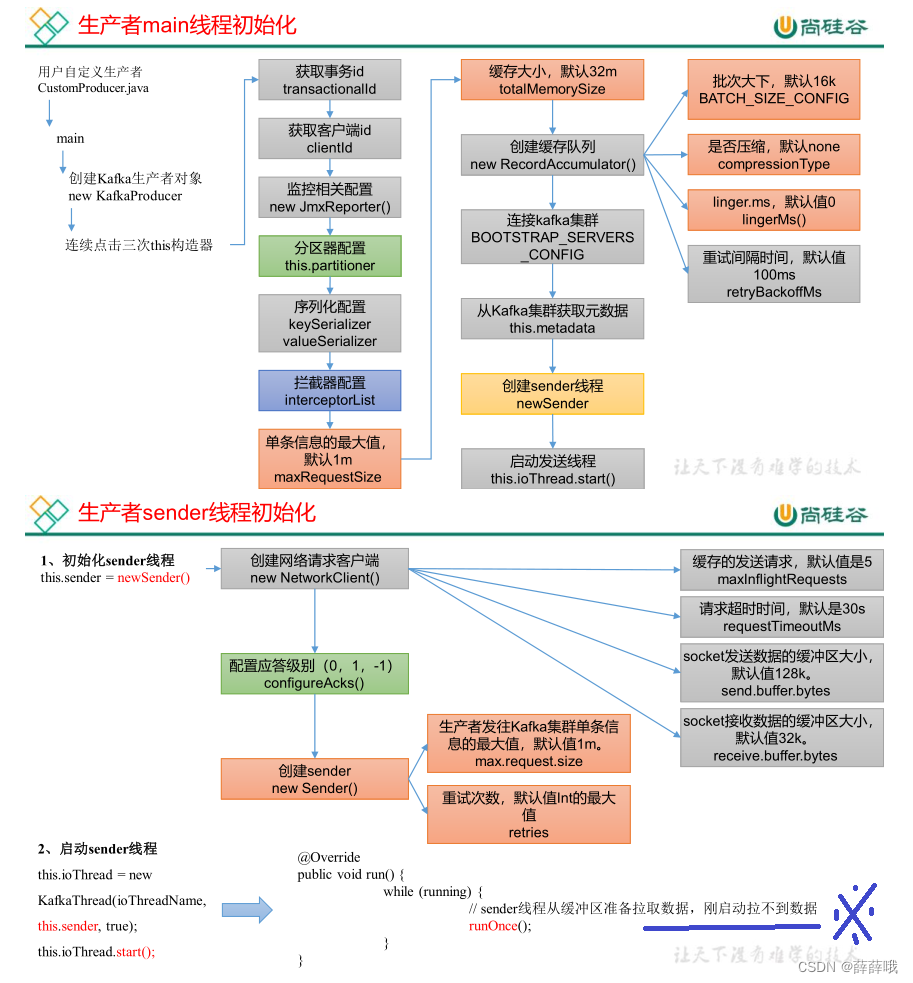
更多內容,見文檔。






多頁簽的實現(Tab))

-- 詳解)










