Redis入門與應用
Redis的技術全景
Redis一個開源的基于鍵值對(Key-Value)NoSQL數據庫。使用ANSI C語言編寫、支持網絡、基于內存但支持持久化。性能優秀,并提供多種語言的API。
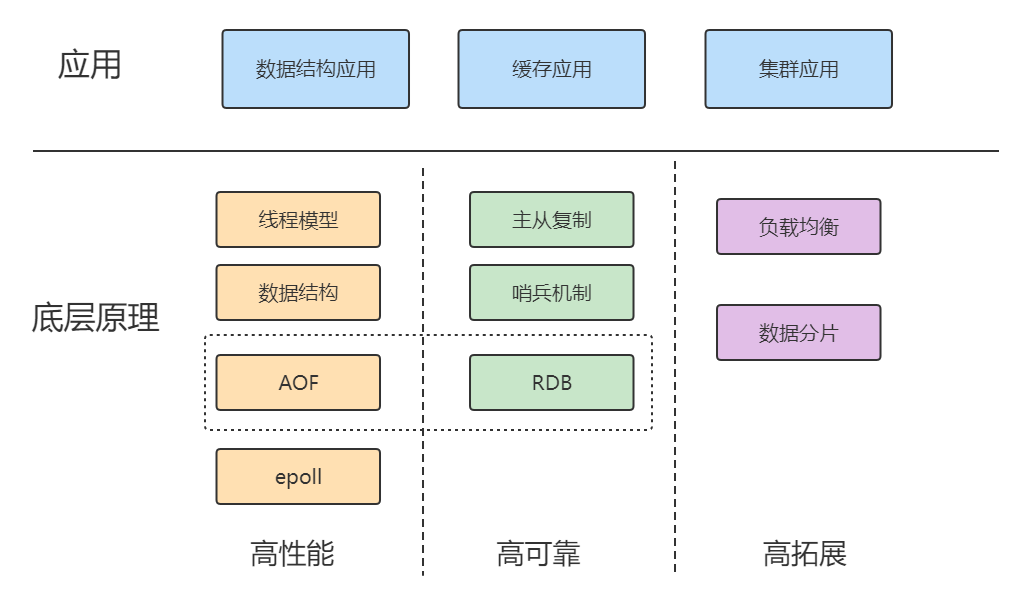
兩大維度
兩大維度:應用維度、底層原理維度
我們知道,緩存和集群是Redis 的兩大廣泛的應用場景。同時Redis 豐富的數據模型,就導致它有很多零碎的應用場景,很多很雜。而且,還有一些問題隱藏得比較深,只有特定的業務場景下(比如億級訪問壓力場景)才會出現,所以同時還必須精通Redis的數據結構。
Redis應用場景
1.緩存
緩存機制幾乎在所有的大型網站都有使用,合理地使用緩存不僅可以加快數據的訪問速度,而且能夠有效地降低后端數據源的壓力。Redis提供了鍵值過期時間設置,并且也提供了靈活控制最大內存和內存溢出后的淘汰策略。可以這么說,一個合理的緩存設計能夠為一個網站的穩定保駕護航。
一般MySQL數據庫寫的并發是600/s,讀的2000/s,對于大型互聯網項目的百萬并發,根本扛不住,Redis的官方顯示Redis能夠單臺達到10W+/s的并發。
2.排行榜系統
排行榜系統幾乎存在于所有的網站,例如按照熱度排名的排行榜,按照發布時間的排行榜,按照各種復雜維度計算出的排行榜,Redis提供了列表和有序集合數據結構,合理地使用這些數據結構可以很方便地構建各種排行榜系統。
3.計數器應用
計數器在網站中的作用至關重要,例如視頻網站有播放數、電商網站有瀏覽數,為了保證數據的實時性,每一次播放和瀏覽都要做加1的操作,如果并發量很大對于傳統關系型數據的性能是一種挑戰。Redis天然支持計數功能而且計數的性能也非常好,可以說是計數器系統的重要選擇。
4.社交網絡
贊/踩、粉絲、共同好友/喜好、推送、下拉刷新等是社交網站的必備功能,由于社交網站訪問量通常比較大,而且傳統的關系型數據不太適合保存這種類型的數據,Redis提供的數據結構可以相對比較容易地實現這些功能。
5.消息隊列系統
消息隊列系統可以說是一個大型網站的必備基礎組件,因為其具有業務解耦、非實時業務削峰等特性。Redis提供了發布訂閱功能和阻塞隊列的功能,雖然和專業的消息隊列比還不夠足夠強大,但是對于一般的消息隊列功能基本可以滿足。這個是Redis的作者參考了Kafka做的拓展。
三大主線
三大主線:高性能、高可靠和高可擴展
高性能:包括線程模型、數據結構、持久化、網絡框架;
高可靠:包括主從復制、哨兵機制;
高可擴:包括數據分片、負載均衡。
因為Redis的應用場景非常多,不同的公司有不同的玩法,但如何不掌握三高這條主線的話,你會遇到以下問題:
1、數據結構的復雜度、跨 CPU 核的訪問會導致CPU飆升的問題
2、主從同步和 AOF 的內存競爭,這些會導致內存問題
3、在 SSD 上做快照的性能抖動,這些會導致存儲持久化的問題
4、多實例時的異常網絡丟包的問題
Redis的版本選擇與安裝
在Redis的版本計劃中,版本號第二位為奇數,為非穩定版本,如2.7、2.9、3.1;版本號第二為偶數,為穩定版本如2.6、2.8、3.0;一般來說當前奇數版本是下一個穩定版本的開發版本,如2.9是3.0的開發版本。
同時Redis的安裝也非常簡單,到Redis的官網(Download | Redis),下載對應的版本,簡單幾個命令安裝即可。
Redis的linux安裝
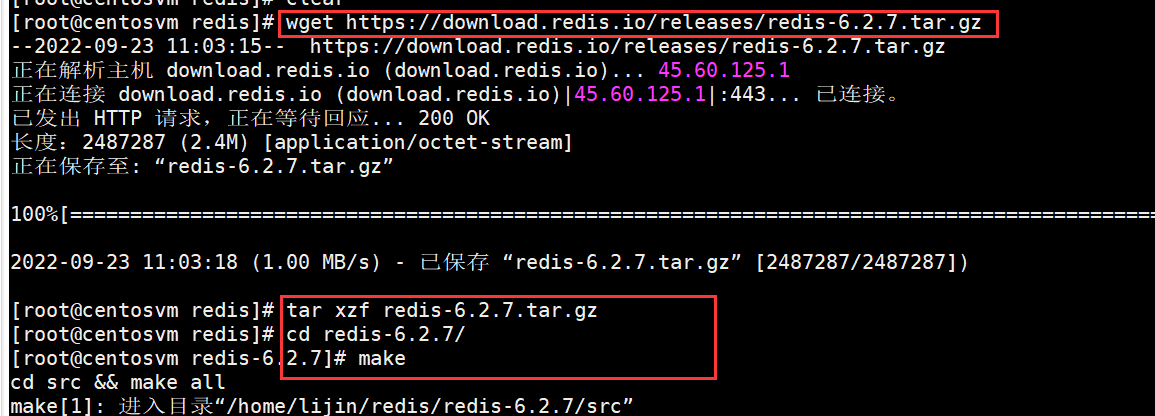
wget https://download.redis.io/releases/redis-6.2.7.tar.gz
tar xzf redis-6.2.7.tar.gz
cd redis-6.2.7/
make

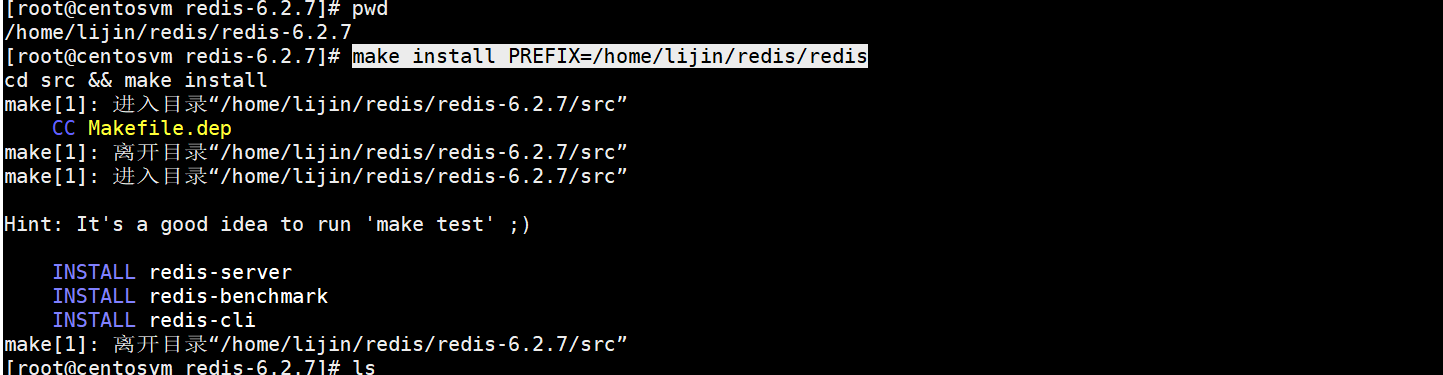
安裝后源碼和執行目錄會混在一起,為了方便,我做了一次install
make install PREFIX=/home/lijin/redis/redis

因為Redis的安裝一般來說對于系統依賴很少,只依賴了Linux系統基本的類庫,所以安裝很少出問題
安裝常見問題
如果執行make命令報錯:cc 未找到命令,原因是虛擬機系統中缺少gcc,執行下面命令安裝gcc:
yum -y install gcc automake autoconf libtool make
如果執行make命令報錯:致命錯誤:jemalloc/jemalloc.h: 沒有那個文件或目錄,則需要在make指定分配器為libc。執行下面命令即可正常編譯:
make MALLOC=libc
Redis的啟動
Redis編譯完成后,會生成幾個可執行文件,這些文件各有各的作用,我們現在先簡單了解下,后面的課程會陸續說到和使用這些可執行文件。

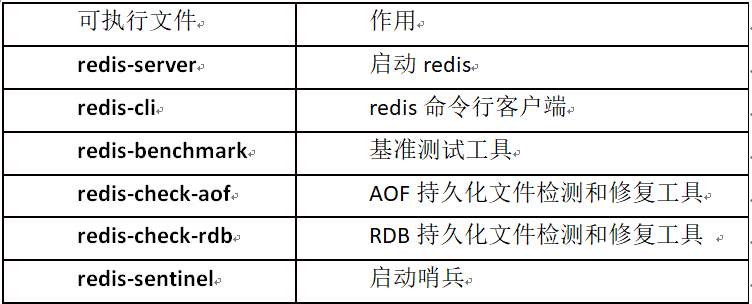
一般來說redis-server和redis-cli這些平時用得最多。
Redis有三種方法啟動Redis:默認配置、帶參數啟動、配置文件啟動。
默認配置
使用Redis的默認配置來啟動,在bin目錄下直接輸入 ./redis-server
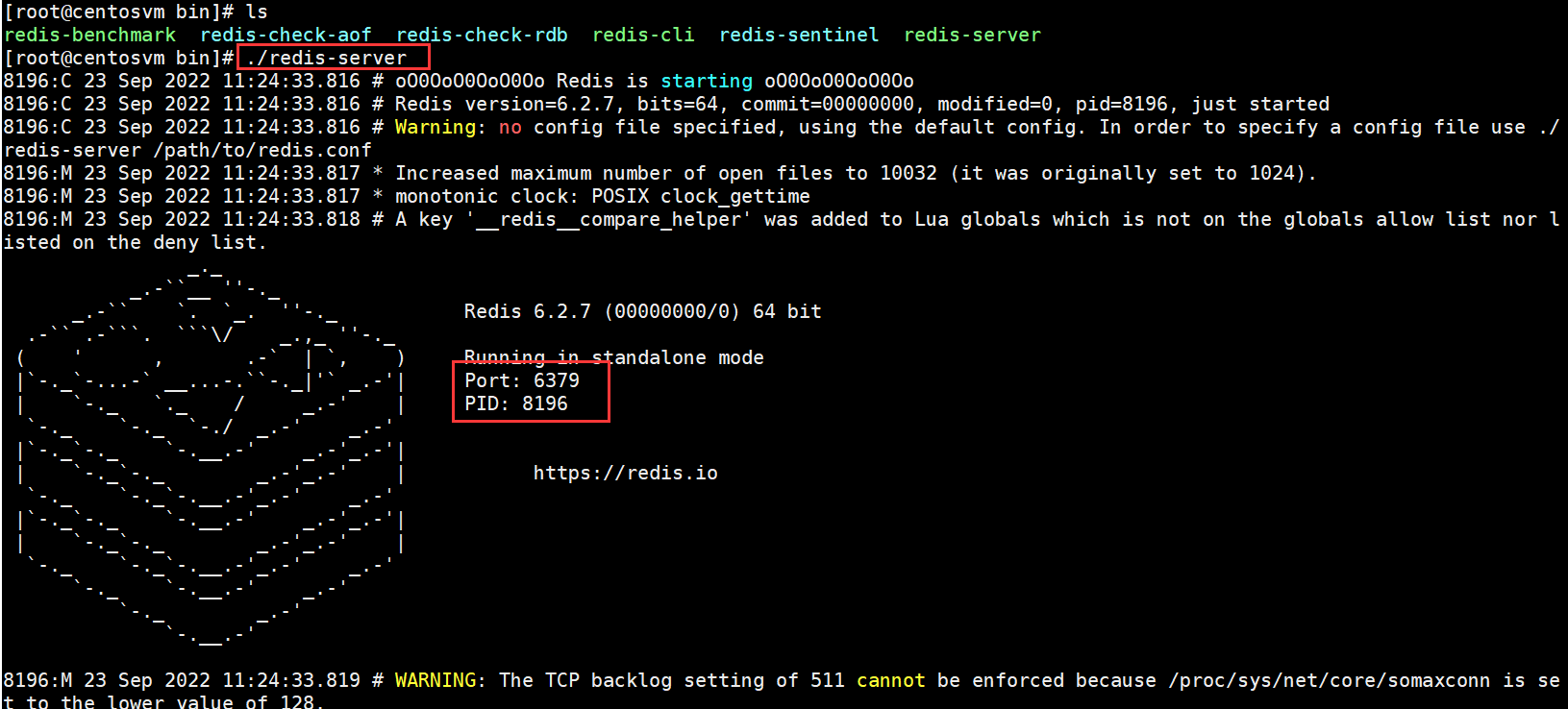
可以看到直接使用redis-server啟動Redis后,會打印出一些日志,通過日志可以看到一些信息:
當前的Redis版本的是64位的6.2.7,默認端口是6379。Redis建議要使用配置文件來啟動。
因為直接啟動無法自定義配置,所以這種方式是不會在生產環境中使用的。
帶參數啟動
redis-server加上要修改配置名和值(可以是多對),沒有設置的配置將使用默認配置,例如:如果要用6380作為端口啟動Redis,那么可以執行:
./redis-server --port 6380
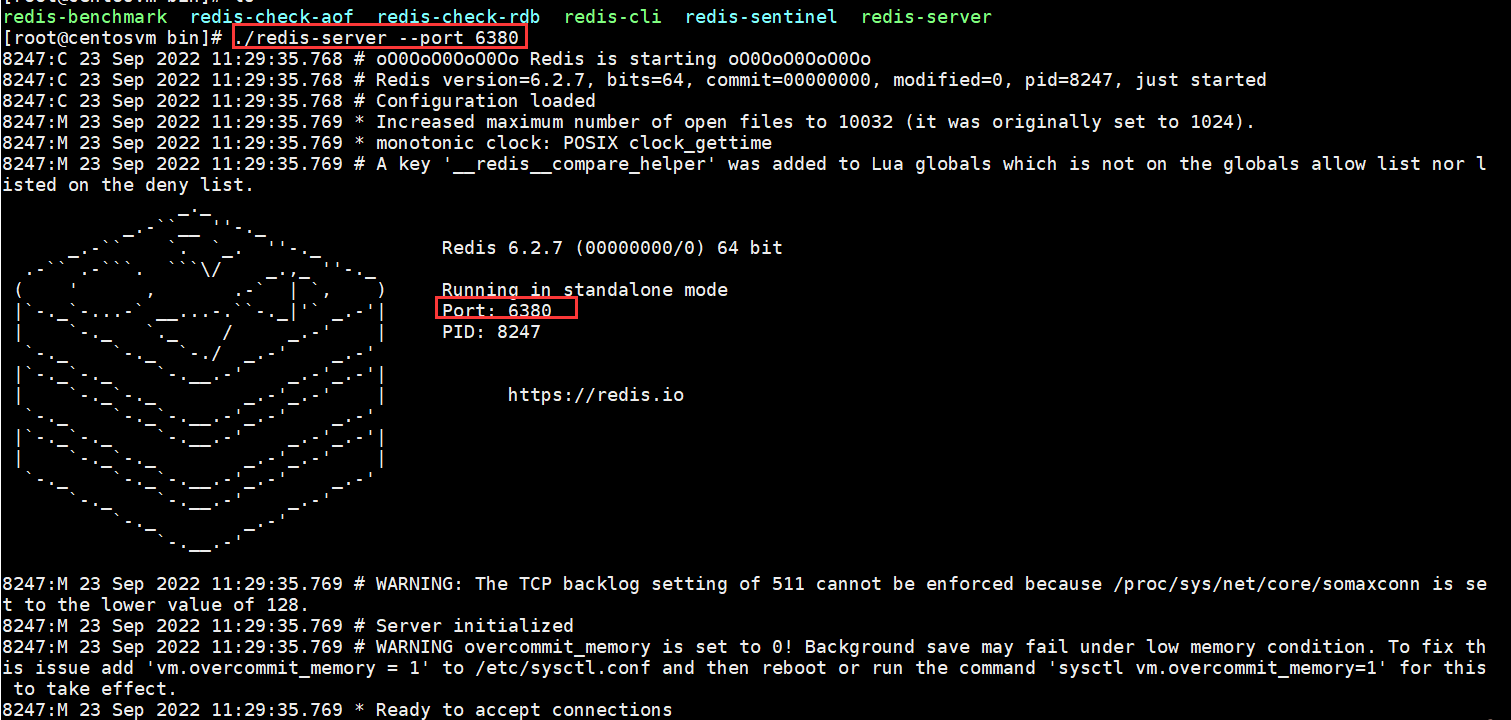
這種方式一般我們也用得比較少。
配置文件啟動
配置文件是我們啟動的最多的模式,配置文件安裝目錄中有

復制過來

改一下權限

通過配置文件來啟動
./redis-server ../conf/redis.conf
注意:這里對配置文件使用了相對路徑,絕對路徑也是可以的。
同時配置文件的方式可以方便我們改端口,改配置,增加密碼等。

打開注釋,設置為自己的密碼,重啟即可
操作
Redis服務啟動完成后,就可以使用redis-cli連接和操作Redis服務。redis-cli可以使用兩種方式連接Redis服務器。
1、單次操作
用redis-cli -hip {host} -p{port} {command}就可以直接得到命令的返回結果,例如:
那么下一次要操作redis,還需要再通過redis-cli。

2、命令行操作

通過redis-cli -h (host}-p {port}的方式連接到Redis服務,之后所有的操作都是通過控制臺進行,例如:
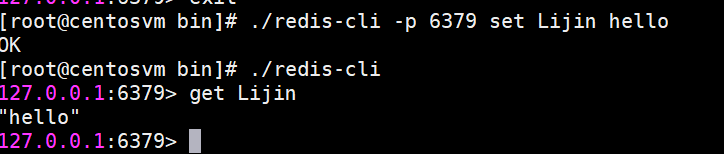
我們沒有寫-h參數,那么默認連接127.0.0.1;如果不寫-p,那么默認6379端口,也就是說如果-h和-p都沒寫就是連接127.0.0.1:6379這個 Redis實例。
停止
Redis提供了shutdown命令來停止Redis服務,例如我們目前已經啟動的Redis服務,可以執行:
./redis-cli -p 6379 shutdown
redis服務端將會顯示:
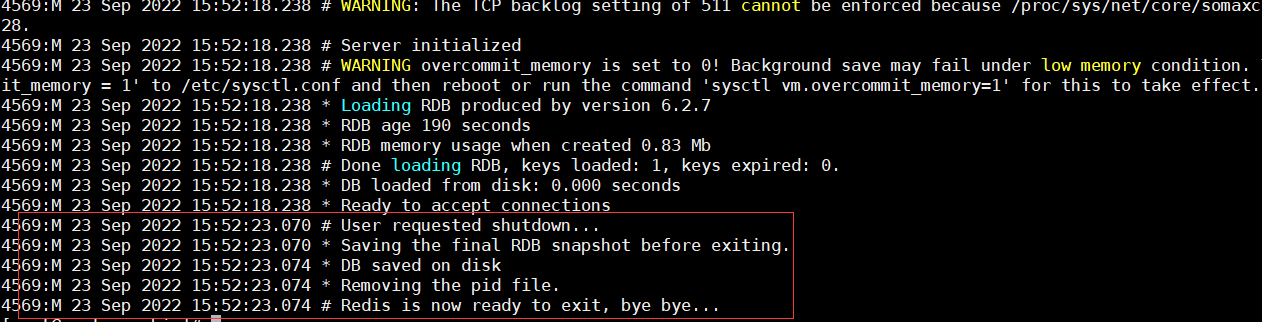
除了可以通過shutdown命令關閉Redis服務以外,還可以通過kill進程號的方式關閉掉Redis,但是強烈不建議使用kill -9強制殺死Redis服務,不但不會做持久化操作,還會造成緩沖區等資源不能被優雅關閉,極端情況會造成AOF和復制丟失數據的情況。如果是集群,還容易丟失數據。
同樣還可以在命令行中執行shutdown指令

shutdown還有一個參數,代表是否在關閉Redis前,生成持久化文件,缺省是save,生成持久化文件,如果是nosave則不生成持久化文件
Redis全局命令
對于鍵值數據庫而言,基本的數據模型是 key-value 模型,Redis 支持的 value 類型包括了 String、哈希表、列表、集合等,而Memcached支持的 value 類型僅為 String 類型,所以Redis 能夠在實際業務場景中得到廣泛的應用,就是得益于支持多樣化類型的 value。
Redis里面有16個庫,但是Redis的分庫功能沒啥意義(默認就是0號庫,尤其是集群操作的時候),我們一般都是默認使用0號庫進行操作。
在了解Rediskey-value 模型之前,Redis的有一些全局命令,需要我們提前了解。
keys命令
keys *
keys L*
查看所有鍵(支持通配符):
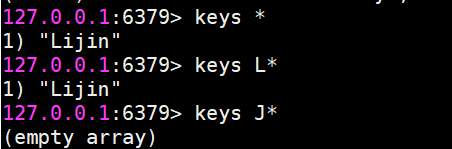
但是這個命令請慎用,因為keys命令要把所有的key-value對全部拉出去,如果生產環境的鍵值對特別多的話,會對Redis的性能有很大的影響,推薦使用dbsize。
keys命令會遍歷所有鍵,所以它的時間復雜度是o(n),當Redis保存了大量鍵時線上環境禁止使用keys命令。
dbsize命令
dbsize命令會返回當前數據庫中鍵的總數。
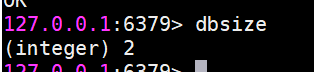
dbsize命令在計算鍵總數時不會遍歷所有鍵,而是直接獲取 Redis內置的鍵總數變量,所以dbsize命令的時間復雜度是O(1)。
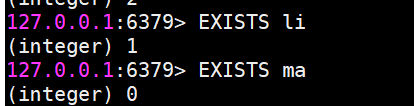
exists
檢查鍵是否存在,存在返回1,不存在返回0。
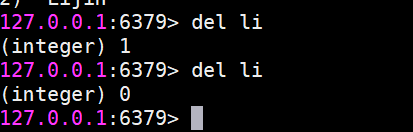
del
刪除鍵,無論值是什么數據結構類型,del命令都可以將其刪除。返回刪除鍵個數,刪除不存在鍵返回0。同時del命令可以支持刪除多個鍵。

鍵過期
expire
Redis支持對鍵添加過期時間,當超過過期時間后,會自動刪除鍵,時間單位秒。
ttl命令會返回鍵的剩余過期時間,它有3種返回值:
大于等于0的整數:鍵剩余的過期時間。
-1:鍵沒設置過期時間。
-2:鍵不存在
除了expire、ttl命令以外,Redis還提供了expireat、pexpire,pexpireat、pttl、persist等一系列命令。
expireat key
timestamp: 鍵在秒級時間截timestamp后過期。
ttl命令和pttl都可以查詢鍵的剩余過期時間,但是pttl精度更高可以達到毫秒級別,有3種返回值:
大于等于0的整數:鍵剩余的過期時間(ttl是秒,pttl是毫秒)。
-1:鍵沒有設置過期時間。
-2:鍵不存在。
pexpire key
milliseconds:鍵在milliseconds毫秒后過期。
pexpireat key
milliseconds-timestamp鍵在毫秒級時間戳timestamp后過期。
在使用Redis相關過期命令時,需要注意以下幾點。
1)如果expire key 的鍵不存在,返回結果為0:
2)如果過期時間為負值,鍵會立即被刪除,猶如使用del命令一樣:
3 ) persist命令可以將鍵的過期時間清除:
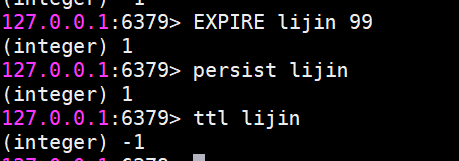
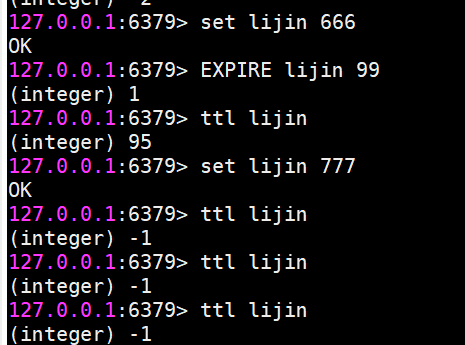
4)對于字符串類型鍵,執行set命令會去掉過期時間,這個問題很容易在開發中被忽視。
5 ) Redis不支持二級數據結構(例如哈希、列表)內部元素的過期功能,不能對二級數據結構做過期時間設置。
type
返回鍵的數據結構類型,例如鍵lijin是字符串類型,返回結果為string。鍵mylist是列表類型,返回結果為list,鍵不存在返回none

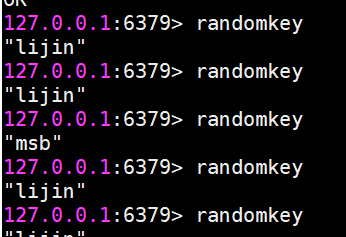
randomkey
隨機返回一個鍵,這個很簡單,請自行實驗。
rename
鍵重命名
但是要注意,如果在rename之前,新鍵已經存在,那么它的值也將被覆蓋。
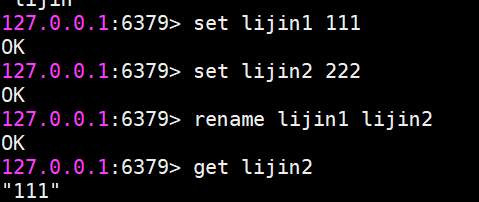
為了防止被強行rename,Redis提供了renamenx命令,確保只有newKey不存在時候才被覆蓋。
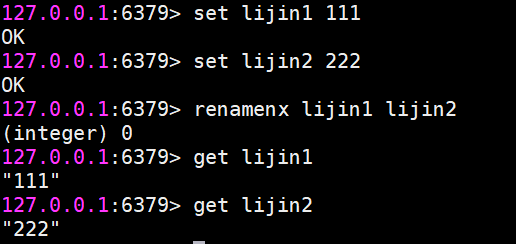
從上面我們可以看出,由于重命名鍵期間會執行del命令刪除舊的鍵,如果鍵對應的值比較大,會存在阻塞Redis的可能性。
鍵名的生產實踐
Redis沒有命令空間,而且也沒有對鍵名有強制要求。但設計合理的鍵名,有利于防止鍵沖突和項目的可維護性,比較推薦的方式是使用“業務名:對象名: id : [屬性]”作為鍵名(也可以不是分號)。、
例如MySQL 的數據庫名為mall,用戶表名為order,那么對應的鍵可以用"mall:order:1",
"mall:order:1:name"來表示,如果當前Redis 只被一個業務使用,甚至可以去掉“order:”。
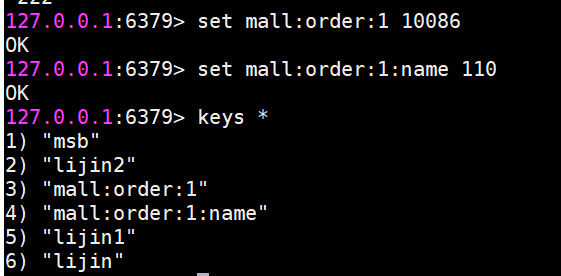
在能描述鍵含義的前提下適當減少鍵的長度,從而減少由于鍵過長的內存浪費。
Redis常用數據結構
Redis提供了一些數據結構供我們往Redis中存取數據,最常用的的有5種,字符串(String)、哈希(Hash)、列表(list)、集合(set)、有序集合(ZSET)。
字符串(String)
字符串類型是Redis最基礎的數據結構。首先鍵都是字符串類型,而且其他幾種數據結構都是在字符串類型基礎上構建的,所以字符串類型能為其他四種數據結構的學習奠定基礎。字符串類型的值實際可以是字符串(簡單的字符串、復雜的字符串(例如JSON、XML))、數字(整數、浮點數),甚至是二進制(圖片、音頻、視頻),但是值最大不能超過512MB。
(雖然Redis是C寫的,C里面有字符串<本質使用char數組來實現>,但是處于種種考慮,Redis還是自己實現了字符串類型)
操作命令
set 設置值
set key value
set命令有幾個選項:
ex seconds: 為鍵設置秒級過期時間。
px milliseconds: 為鍵設置毫秒級過期時間。
nx: 鍵必須不存在,才可以設置成功,用于添加(分布式鎖常用)。
xx: 與nx相反,鍵必須存在,才可以設置成功,用于更新。
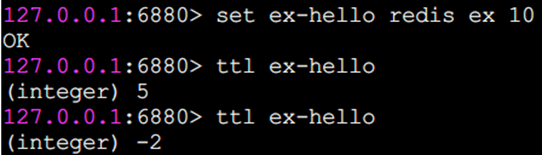
從執行效果上看,ex參數和expire命令基本一樣。還有一個需要特別注意的地方是如果一個字符串已經設置了過期時間,然后你調用了set 方法修改了它,它的過期時間會消失。
而nx和xx執行效果如下
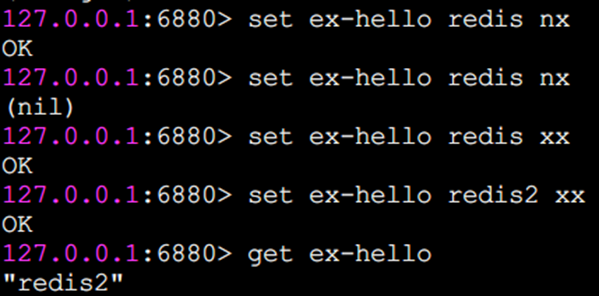
除了set選項,Redis 還提供了setex和 setnx兩個命令:
setex key
seconds value
setnx key value
setex和 setnx的作用和ex和nx選項是一樣的。也就是,setex為鍵設置秒級過期時間,setnx設置時鍵必須不存在,才可以設置成功。
setex示例:

setnx示例:
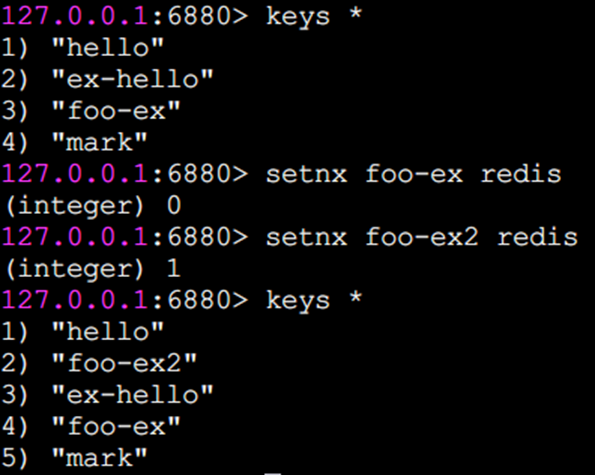
因為鍵foo-ex已存在,所以setnx失敗,返回結果為0,鍵foo-ex2不存在,所以setnx成功,返回結果為1。
有什么應用場景嗎?以setnx命令為例子,由于Redis的單線程命令處理機制,如果有多個客戶端同時執行setnx key value,根據setnx的特性只有一個客戶端能設置成功,setnx可以作為分布式鎖的一種實現方案。當然分布式鎖沒有不是只有一個命令就OK了,其中還有很多的東西要注意,我們后面會用單獨的章節來講述基于Redis的分布式鎖。
get 獲取值
如果要獲取的鍵不存在,則返回nil(空):
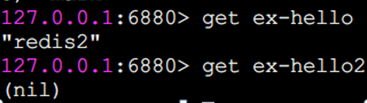
mset 批量設置值
通過mset命令一次性設置4個鍵值對

mget 批量獲取值
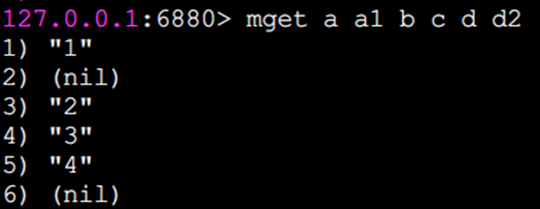
批量獲取了鍵a、b、c、d的值:
如果有些鍵不存在,那么它的值為nil(空),結果是按照傳入鍵的順序返回。
批量操作命令可以有效提高效率,假如沒有mget這樣的命令,要執行n次get命令具體耗時如下:
n次 get時間=n次網絡時間+n次命令時間
使用mget命令后,要執行n次get命令操作具體耗時如下:
n次get時間=1次網絡時間+n次命令時間
Redis可以支撐每秒數萬的讀寫操作,但是這指的是Redis服務端的處理能力,對于客戶端來說,一次命令除了命令時間還是有網絡時間,假設網絡時間為1毫秒,命令時間為0.1毫秒(按照每秒處理1萬條命令算),那么執行1000次 get命令需要1.1秒(10001+10000.1=1100ms),1次mget命令的需要0.101秒(11+10000.1=101ms)。
Incr 數字運算
incr命令用于對值做自增操作,返回結果分為三種情況:
值不是整數,返回錯誤。
值是整數,返回自增后的結果。
鍵不存在,按照值為0自增,返回結果為1。
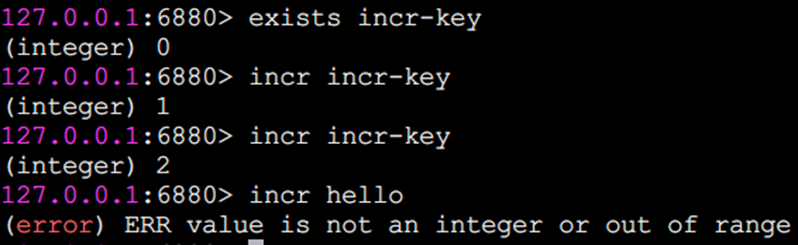
除了incr命令,Redis提供了decr(自減)、 incrby(自增指定數字)、decrby(自減指定數字)、incrbyfloat(自增浮點數),具體效果請同學們自行嘗試。
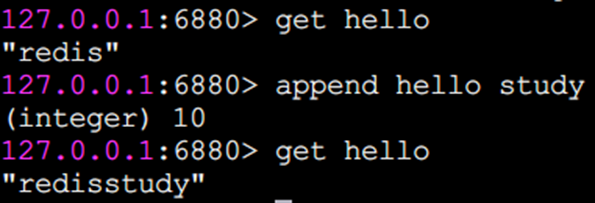
append追加指令
append可以向字符串尾部追加值
strlen 字符串長度
返回字符串長度
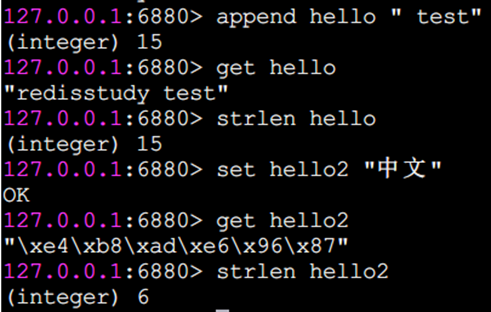
注意:每個中文占3個字節
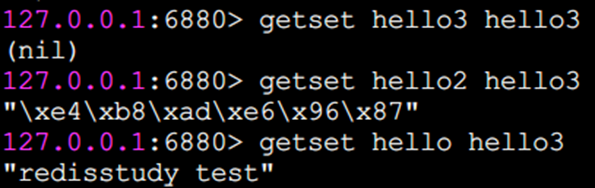
getset 設置并返回原值
getset和set一樣會設置值,但是不同的是,它同時會返回鍵原來的值
setrange 設置指定位置的字符
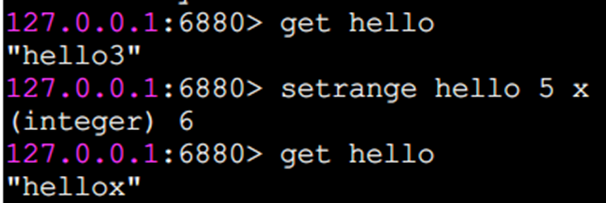
下標從0開始計算。
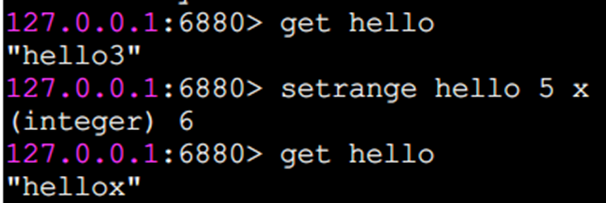
getrange 截取字符串
getrange 截取字符串中的一部分,形成一個子串,需要指明開始和結束的偏移量,截取的范圍是個閉區間。
命令的時間復雜度
字符串這些命令中,除了del 、mset、 mget支持多個鍵的批量操作,時間復雜度和鍵的個數相關,為O(n),getrange和字符串長度相關,也是O(n),其余的命令基本上都是O(1)的時間復雜度,在速度上還是非常快的。
使用場景
字符串類型的使用場景很廣泛:
緩存功能
Redis 作為緩存層,MySQL作為存儲層,絕大部分請求的數據都是從Redis中獲取。由于Redis具有支撐高并發的特性,所以緩存通常能起到加速讀寫和降低后端壓力的作用。
計數
使用Redis 作為計數的基礎工具,它可以實現快速計數、查詢緩存的功能,同時數據可以異步落地到其他數據源。
共享Session
一個分布式Web服務將用戶的Session信息(例如用戶登錄信息)保存在各自服務器中,這樣會造成一個問題,出于負載均衡的考慮,分布式服務會將用戶的訪問均衡到不同服務器上,用戶刷新一次訪問可能會發現需要重新登錄,這個問題是用戶無法容忍的。
為了解決這個問題,可以使用Redis將用戶的Session進行集中管理,,在這種模式下只要保證Redis是高可用和擴展性的,每次用戶更新或者查詢登錄信息都直接從Redis中集中獲取。
限速
比如,很多應用出于安全的考慮,會在每次進行登錄時,讓用戶輸入手機驗證碼,從而確定是否是用戶本人。但是為了短信接口不被頻繁訪問,會限制用戶每分鐘獲取驗證碼的頻率,例如一分鐘不能超過5次。一些網站限制一個IP地址不能在一秒鐘之內方問超過n次也可以采用類似的思路。
哈希(Hash)
Java里提供了HashMap,Redis中也有類似的數據結構,就是哈希類型。但是要注意,哈希類型中的映射關系叫作field-value,注意這里的value是指field對應的值,不是鍵對應的值。
操作命令
基本上,哈希的操作命令和字符串的操作命令很類似,很多命令在字符串類型的命令前面加上了h字母,代表是操作哈希類型,同時還要指明要操作的field的值。
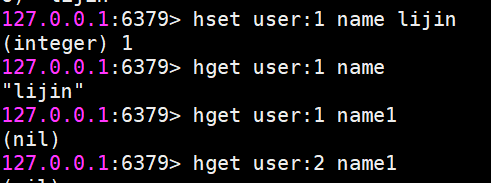
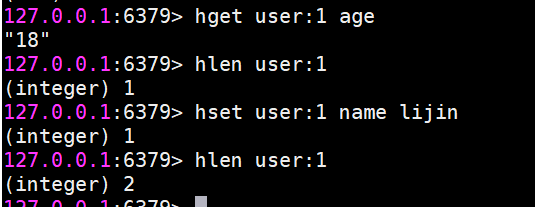
hset設值
hset user:1 name lijin

如果設置成功會返回1,反之會返回0。此外Redis提供了hsetnx命令,它們的關系就像set和setnx命令一樣,只不過作用域由鍵變為field。
hget取值
hget user:1 name
如果鍵或field不存在,會返回nil。
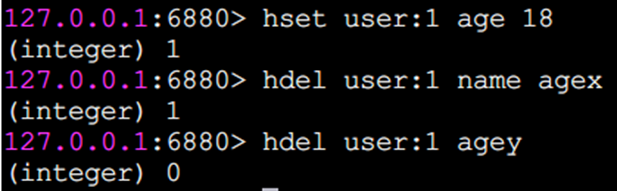
hdel刪除field
hdel會刪除一個或多個field,返回結果為成功刪除field的個數。
hlen計算field個數
hmset批量設值

hmget批量取值

hexists判斷field是否存在
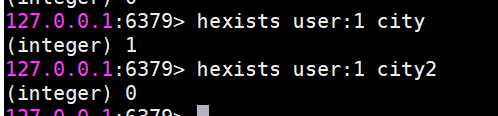
若存在返回1,不存在返回0
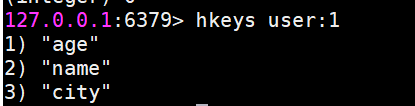
hkeys獲取所有field
它返回指定哈希鍵所有的field
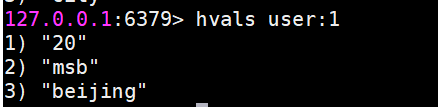
hvals獲取所有value
hgetall獲取所有field與value
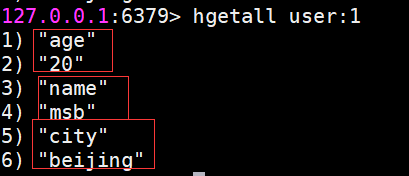
在使用hgetall時,如果哈希元素個數比較多,會存在阻塞Redis的可能。如果只需要獲取部分field,可以使用hmget,如果一定要獲取全部field-value,可以使用hscan命令,該命令會漸進式遍歷哈希類型,hscan將在后面的章節介紹。
hincrby增加
hincrby和 hincrbyfloat,就像incrby和incrbyfloat命令一樣,但是它們的作用域是filed。
hstrlen 計算value的字符串長度
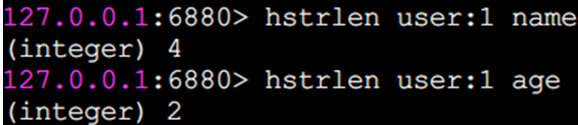
命令的時間復雜度
哈希類型的操作命令中,hdel,hmget,hmset的時間復雜度和命令所帶的field的個數相關O(k),hkeys,hgetall,hvals和存儲的field的總數相關,O(N)。其余的命令時間復雜度都是O(1)。
使用場景
從前面的操作可以看出,String和Hash的操作非常類似,那為什么要弄一個hash出來存儲。
哈希類型比較適宜存放對象類型的數據,我們可以比較下,如果數據庫中表記錄user為:
| id | name | age |
|---|---|---|
| 1 | lijin | 18 |
| 2 | msb | 20 |
1、使用String類型
需要一條條去插入獲取。
set user:1:name lijin;
set user:1:age 18;
set user:2:name msb;
set user:2:age 20;
優點:簡單直觀,每個鍵對應一個值
缺點:鍵數過多,占用內存多,用戶信息過于分散,不用于生產環境
2、將對象序列化存入redis
set user:1 serialize(userInfo);
優點:編程簡單,若使用序列化合理內存使用率高
缺點:序列化與反序列化有一定開銷,更新屬性時需要把userInfo全取出來進行反序列化,更新后再序列化到redis
3、使用hash類型
hmset user:1 name lijin age 18
hmset user:2 name msb age 20
優點:簡單直觀,使用合理可減少內存空間消耗
缺點:要控制內部編碼格式,不恰當的格式會消耗更多內存
列表(list)
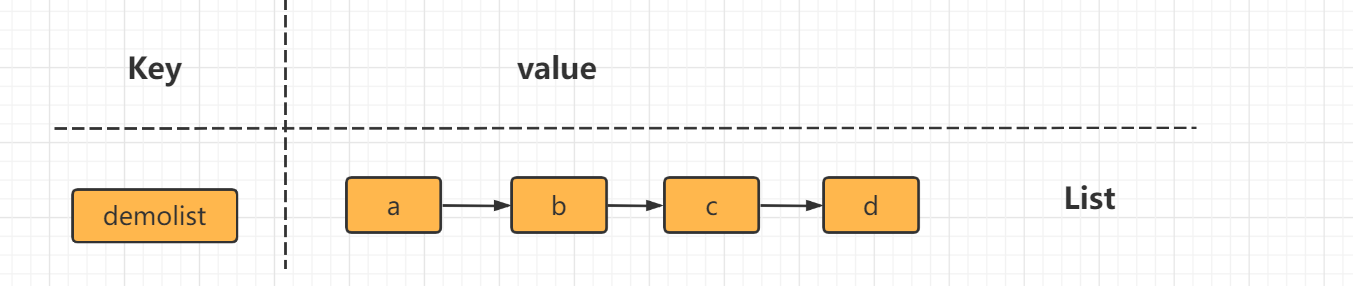
列表( list)類型是用來存儲多個有序的字符串,a、b、c、c、b四個元素從左到右組成了一個有序的列表,列表中的每個字符串稱為元素(element),一個列表最多可以存儲(2^32-1)個元素(4294967295)。

在Redis 中,可以對列表兩端插入( push)和彈出(pop),還可以獲取指定范圍的元素列表、獲取指定索引下標的元素等。列表是一種比較靈活的數據結構,它可以充當棧和隊列的角色,在實際開發上有很多應用場景。
列表類型有兩個特點:
第一、列表中的元素是有序的,這就意味著可以通過索引下標獲取某個元素或者某個范圍內的元素列表。
第二、列表中的元素可以是重復的。
操作命令
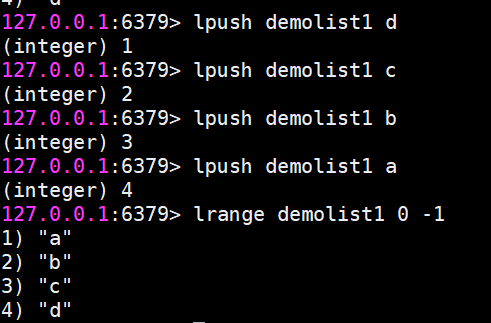
lrange 獲取指定范圍內的元素列表(不會刪除元素)
key start end
索引下標特點:從左到右為0到N-1
lrange 0 -1命令可以從左到右獲取列表的所有元素
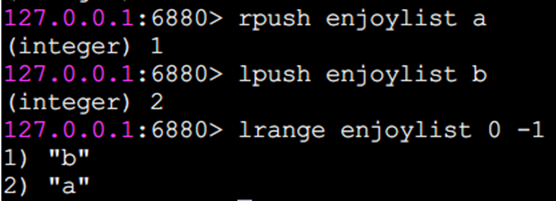
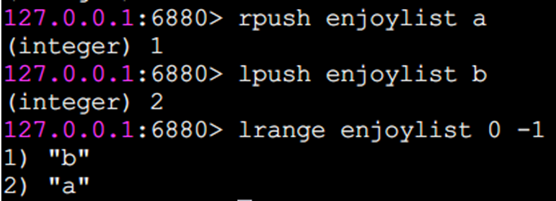
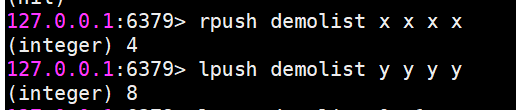
rpush 向右插入
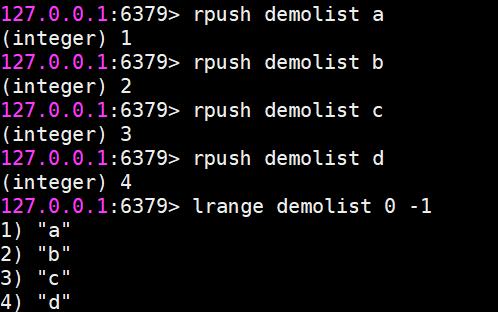
lpush 向左插入
linsert 在某個元素前或后插入新元素
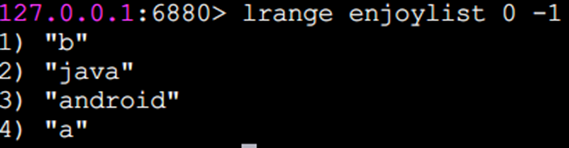
這三個返回結果為命令完成后當前列表的長度,也就是列表中包含的元素個數,同時rpush和lpush都支持同時插入多個元素。
lpop 從列表左側彈出(會刪除元素)
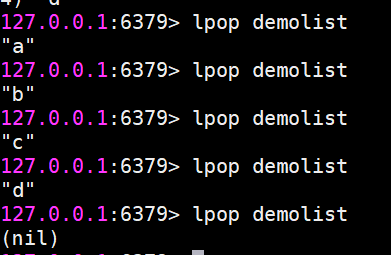 r
r
請注意,彈出來元素就沒了。
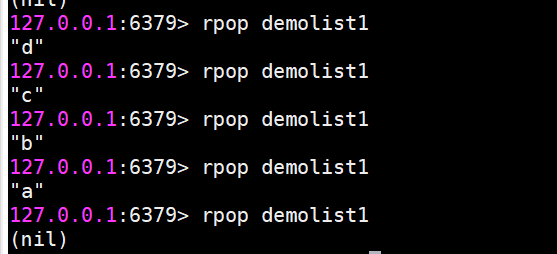
rpop 從列表右側彈出
rpop將會把列表最右側的元素d彈出。
lrem 對指定元素進行刪除

lrem命令會從列表中找到等于value的元素進行刪除,根據count的不同分為三種情況:
count>0,從左到右,刪除最多count個元素。
count<0,從右到左,刪除最多count絕對值個元素。
count=0,刪除所有。
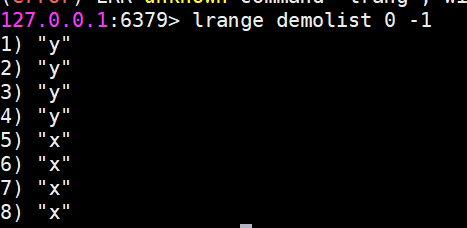
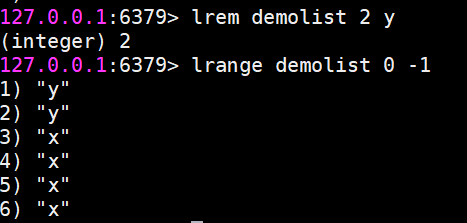
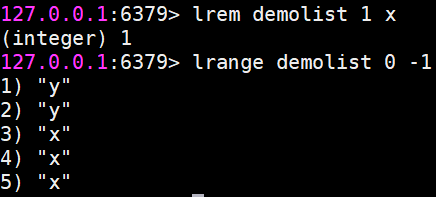
返回值是實際刪除元素的個數。
ltirm 按照索引范圍修剪列表
例如想保留列表中第0個到第1個元素
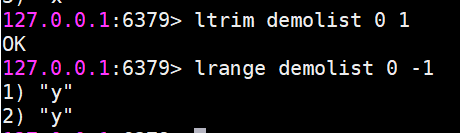 ls
ls
lset修改指定索引下標的元素
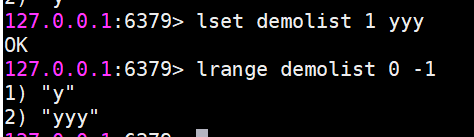
lindex 獲取列表指定索引下標的元素
 l
l
llen 獲取列表長度

blpop和brpop阻塞式彈出元素
blpop和brpop是lpop和rpop的阻塞版本,除此之外還支持多個列表類型,也支持設定阻塞時間,單位秒,如果阻塞時間為0,表示一直阻塞下去。我們以brpop為例說明。
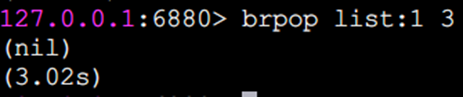
A客戶端阻塞了(因為沒有元素就會阻塞)

A客戶端一直處于阻塞狀態。此時我們從另一個客戶端B執行

A客戶端則輸出

注意:brpop后面如果是多個鍵,那么brpop會從左至右遍歷鍵,一旦有一個鍵能彈出元素,客戶端立即返回。
使用場景
列表類型可以用于比如:
消息隊列,Redis 的 lpush+brpop命令組合即可實現阻塞隊列,生產者客戶端使用lrpush從列表左側插入元素,多個消費者客戶端使用brpop命令阻塞式的“搶”列表尾部的元素,多個客戶端保證了消費的負載均衡和高可用性。
文章列表
每個用戶有屬于自己的文章列表,現需要分頁展示文章列表。此時可以考慮使用列表,因為列表不但是有序的,同時支持按照索引范圍獲取元素。
實現其他數據結構
lpush+lpop =Stack(棧)
lpush +rpop =Queue(隊列)
lpsh+ ltrim =Capped Collection(有限集合)
lpush+brpop=Message Queue(消息隊列)
集合(set)

集合( set)類型也是用來保存多個的字符串元素,但和列表類型不一樣的是,集合中不允許有重復元素,并且集合中的元素是無序的,不能通過索引下標獲取元素。
一個集合最多可以存儲2的32次方-1個元素。Redis除了支持集合內的增刪改查,同時還支持多個集合取交集、并集、差集,合理地使用好集合類型,能在實際開發中解決很多實際問題。
集合內操作命令
sadd 添加元素
允許添加多個,返回結果為添加成功的元素個數

srem 刪除元素
允許刪除多個,返回結果為成功刪除元素個數

scard 計算元素個數

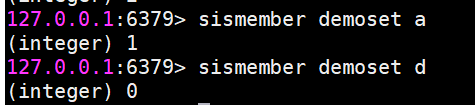
sismember 判斷元素是否在集合中
如果給定元素element在集合內返回1,反之返回0
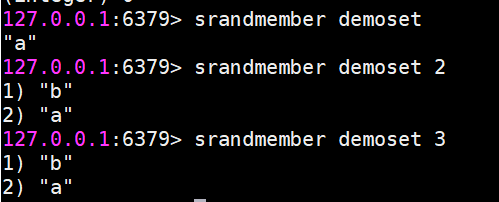
srandmember 隨機從集合返回指定個數元素
指定個數如果不寫默認為1
spop 從集合隨機彈出元素
同樣可以指定個數,如果不寫默認為1,注意,既然是彈出,spop命令執行后,元素會從集合中刪除,而srandmember不會。

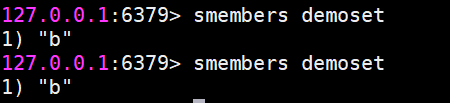
smembers 獲取所有元素(不會彈出元素)
返回結果是無序的
集合間操作命令
現在有兩個集合,它們分別是set1和set2
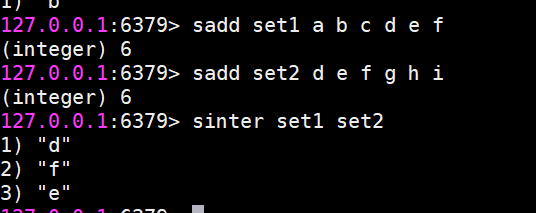
sinter 求多個集合的交集
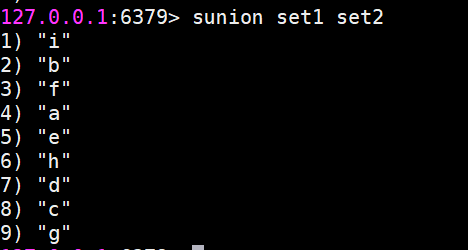
suinon 求多個集合的并集
sdiff 求多個集合的差集
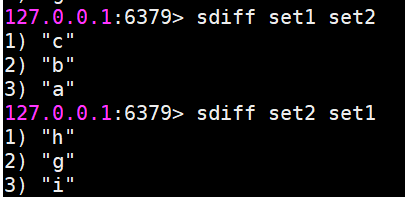
將交集、并集、差集的結果保存
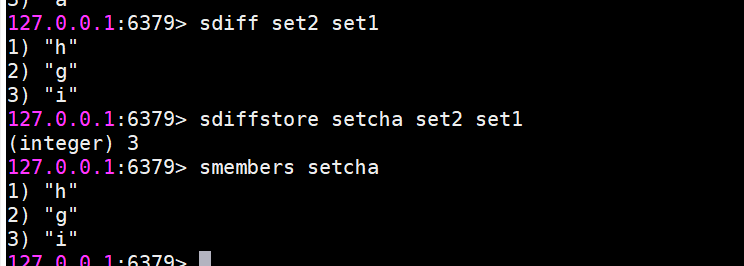
sinterstore destination key [key ...]
suionstore destination key [key ...]
sdiffstore destination key [key ...]集合間的運算在元素較多的情況下會比較耗時,所以 Redis提供了上面三個命令(原命令+store)將集合間交集、并集、差集的結果保存在destination key中,例如:
使用場景
集合類型比較典型的使用場景是標簽(tag)。例如一個用戶可能對娛樂、體育比較感興趣,另一個用戶可能對歷史、新聞比較感興趣,這些興趣點就是標簽。有了這些數據就可以得到喜歡同一個標簽的人,以及用戶的共同喜好的標簽,這些數據對于用戶體驗以及增強用戶黏度比較重要。
例如一個電子商務的網站會對不同標簽的用戶做不同類型的推薦,比如對數碼產品比較感興趣的人,在各個頁面或者通過郵件的形式給他們推薦最新的數碼產品,通常會為網站帶來更多的利益。
除此之外,集合還可以通過生成隨機數進行比如抽獎活動,以及社交圖譜等等。
有序集合(ZSET)

有序集合相對于哈希、列表、集合來說會有一點點陌生,但既然叫有序集合,那么它和集合必然有著聯系,它保留了集合不能有重復成員的特性,但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下標作為排序依據不同的是,它給每個元素設置一個分數( score)作為排序的依據。
有序集合中的元素不能重復,但是score可以重復,就和一個班里的同學學號不能重復,但是考試成績可以相同。
有序集合提供了獲取指定分數和元素范圍查詢、計算成員排名等功能,合理的利用有序集合,能幫助我們在實際開發中解決很多問題。
集合內操作命令
zadd添加成員
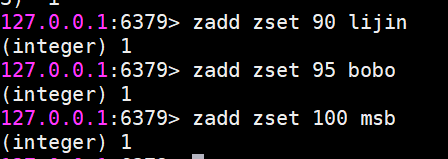
返回結果代表成功添加成員的個數
要注意:

zadd命令還有四個選項nx、xx、ch、incr 四個選項
nx: member必須不存在,才可以設置成功,用于添加。
xx: member必須存在,才可以設置成功,用于更新。
ch: 返回此次操作后,有序集合元素和分數發生變化的個數
incr: 對score做增加,相當于后面介紹的zincrby
zcard 計算成員個數

zscore 計算某個成員的分數
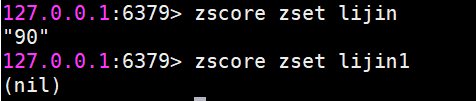
如果成員不存在則返回nil
zrank計算成員的排名
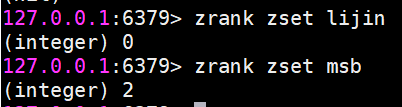
zrank是從分數從低到高返回排名
zrevrank反之
很明顯,排名從0開始計算。
zrem 刪除成員
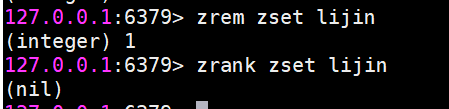
允許一次刪除多個成員。
返回結果為成功刪除的個數。
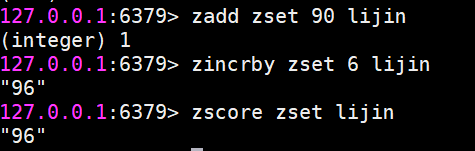
zincrby 增加成員的分數
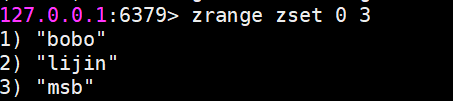
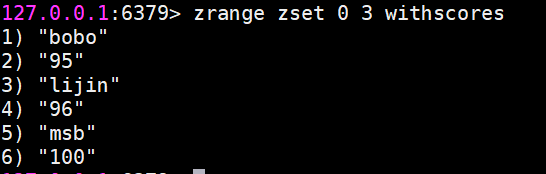
zrange和zrevrange返回指定排名范圍的成員
有序集合是按照分值排名的,zrange是從低到高返回,zrevrange反之。如果加上
withscores選項,同時會返回成員的分數
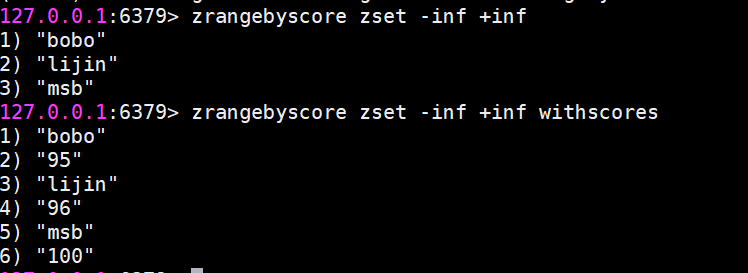
zrangebyscore返回指定分數范圍的成員
zrangebyscore key min max [withscores] [limit offset count]
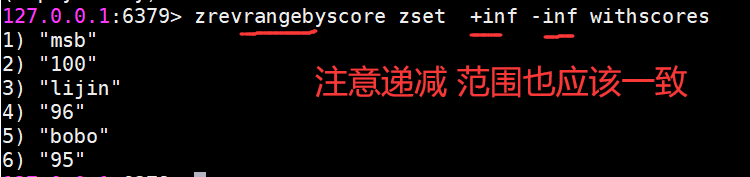
zrevrangebyscore key max min [withscores][limit offset count]其中zrangebyscore按照分數從低到高返回,zrevrangebyscore反之。例如下面操作從低到高返回200到221分的成員,withscores選項會同時返回每個成員的分數。
同時min和max還支持開區間(小括號)和閉區間(中括號),-inf和+inf分別代表無限小和無限大:

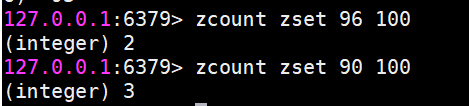
zcount 返回指定分數范圍成員個數
zcount key min max
zremrangebyrank 按升序刪除指定排名內的元素
zremrangebyrank key start end
zremrangebyscore 刪除指定分數范圍的成員
zremrangebyscore key min max
集合間操作命令
zinterstore 交集
zinterstore
這個命令參數較多,下面分別進行說明
destination:交集計算結果保存到這個鍵。
numkeys:需要做交集計算鍵的個數。
key [key …]:需要做交集計算的鍵。
weights weight
[weight …]:每個鍵的權重,在做交集計算時,每個鍵中的每個member 會將自己分數乘以這個權重,每個鍵的權重默認是1。
aggregate sum/
min |max:計算成員交集后,分值可以按照sum(和)、min(最小值)、max(最大值)做匯總,默認值是sum。
不太好理解,我們用一個例子來說明。(算平均分)

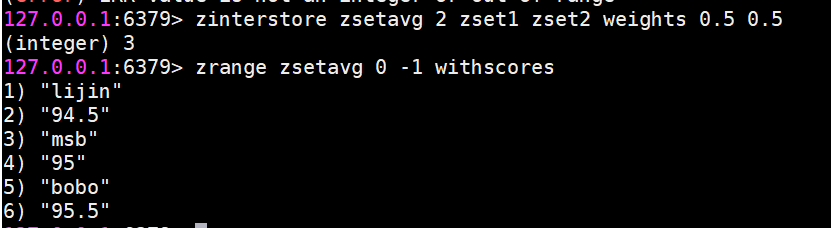
zunionstore 并集
該命令的所有參數和zinterstore是一致的,只不過是做并集計算,大家可以自行實驗。
使用場景
有序集合比較典型的使用場景就是排行榜系統。例如視頻網站需要對用戶上傳的視頻做排行榜,榜單的維度可能是多個方面的:按照時間、按照播放數量、按照獲得的贊數。
Redis高級數據結構
Bitmaps
現代計算機用二進制(位)作為信息的基礎單位,1個字節等于8位,例如“big”字符串是由3個字節組成,但實際在計算機存儲時將其用二進制表示,“big”分別對應的ASCII碼分別是98、105、103,對應的二進制分別是01100010、01101001和 01100111。
許多開發語言都提供了操作位的功能,合理地使用位能夠有效地提高內存使用率和開發效率。Redis提供了Bitmaps這個“數據結構”可以實現對位的操作。把數據結構加上引號主要因為:
Bitmaps本身不是一種數據結構,實際上它就是字符串,但是它可以對字符串的位進行操作。
Bitmaps單獨提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把 Bitmaps想象成一個以位為單位的數組,數組的每個單元只能存儲0和1,數組的下標在 Bitmaps 中叫做偏移量。
操作命令
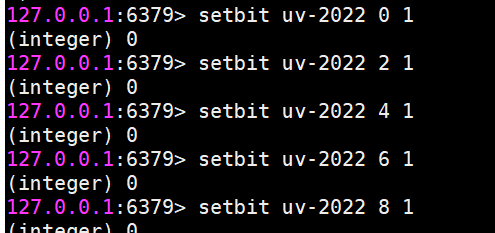
setbit 設置值
setbit key offset value
設置鍵的第 offset 個位的值(從0算起)。
假設現在有20個用戶,userid=0,2,4,6,8的用戶對網站進行了訪問,存儲鍵名為日期。
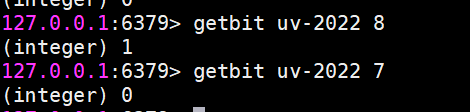
getbit 獲取值
getbit key offset
獲取鍵的第 offset位的值(從0開始算),比如獲取userid=8的用戶是否在2022(年/這天)訪問過,返回0說明沒有訪問過:
當然offset是不存在的,也會返回0。
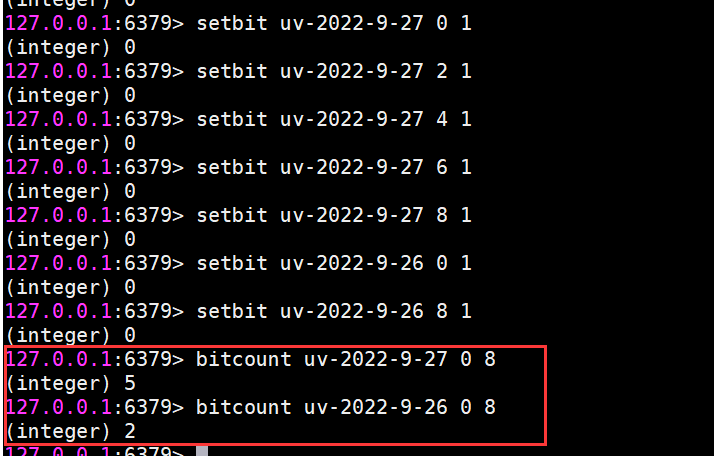
bitcount 獲取Bitmaps指定范圍值為1的個數
bitcount [start] [end]
下面操作計算26號和27號這天的獨立訪問用戶數量
[start]和[end]代表起始和結束字節數
bitop Bitmaps 間的運算
bitop op destkey key [key . …]

bitop是一個復合操作,它可以做多個Bitmaps 的 and(交集)or(并集)not(非)xor(異或)操作并將結果保存在destkey中。
bitpos 計算Bitmaps中第一個值為targetBit 的偏移量
bitpos key targetBit [start] [end]
計算0815當前訪問網站的最小用戶id
除此之外,bitops有兩個選項[start]和[end],分別代表起始字節和結束字節。

Bitmaps優勢
假設網站有1億用戶,每天獨立訪問的用戶有5千萬,如果每天用集合類型和 Bitmaps分別存儲活躍用戶,很明顯,假如用戶id是Long型,64位,則集合類型占據的空間為64位x50 000 000= 400MB,而Bitmaps則需要1位×100 000 000=12.5MB,可見Bitmaps能節省很多的內存空間。
面試題和場景
1、目前有10億數量的自然數,亂序排列,需要對其排序。限制條件-在32位機器上面完成,內存限制為 2G。如何完成?
2、如何快速在億級黑名單中快速定位URL地址是否在黑名單中?(每條URL平均64字節)
3、需要進行用戶登陸行為分析,來確定用戶的活躍情況?
4、網絡爬蟲-如何判斷URL是否被爬過?
5、快速定位用戶屬性(黑名單、白名單等)
6、數據存儲在磁盤中,如何避免大量的無效IO?
傳統數據結構的不足
當然有人會想,我直接將網頁URL存入數據庫進行查找不就好了,或者建立一個哈希表進行查找不就OK了。
當數據量小的時候,這么思考是對的,
確實可以將值映射到 HashMap 的 Key,然后可以在 O(1) 的時間復雜度內返回結果,效率奇高。但是 HashMap 的實現也有缺點,例如存儲容量占比高,考慮到負載因子的存在,通常空間是不能被用滿的,舉個例子如果一個1000萬HashMap,Key=String(長度不超過16字符,且重復性極小),Value=Integer,會占據多少空間呢?1.2個G。實際上,1000萬個int型,只需要40M左右空間,占比3%,1000萬個Integer,需要161M左右空間,占比13.3%。可見一旦你的值很多例如上億的時候,那HashMap 占據的內存大小就變得很可觀了。
但如果整個網頁黑名單系統包含100億個網頁URL,在數據庫查找是很費時的,并且如果每個URL空間為64B,那么需要內存為640GB,一般的服務器很難達到這個需求。
布隆過濾器
布隆過濾器簡介
1970 年布隆提出了一種布隆過濾器的算法,用來判斷一個元素是否在一個集合中。
這種算法由一個二進制數組和一個 Hash 算法組成。
本質上布隆過濾器是一種數據結構,比較巧妙的概率型數據結構(probabilistic data structure),特點是高效地插入和查詢,可以用來告訴你 “某樣東西一定不存在或者可能存在”。
相比于傳統的 List、Set、Map 等數據結構,它更高效、占用空間更少,但是缺點是其返回的結果是概率性的,而不是確切的。
實際上,布隆過濾器廣泛應用于網頁黑名單系統、垃圾郵件過濾系統、爬蟲網址判重系統等,Google 著名的分布式數據庫 Bigtable 使用了布隆過濾器來查找不存在的行或列,以減少磁盤查找的IO次數,Google Chrome瀏覽器使用了布隆過濾器加速安全瀏覽服務。
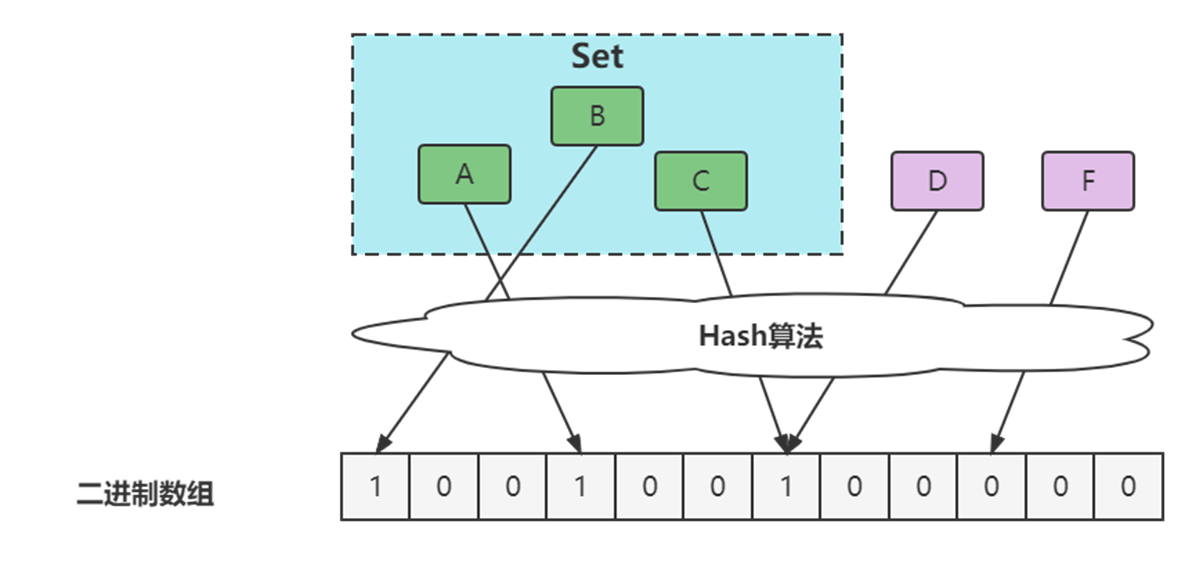
布隆過濾器的誤判問題
?通過hash計算在數組上不一定在集合
?本質是hash沖突
?通過hash計算不在數組的一定不在集合(誤判)
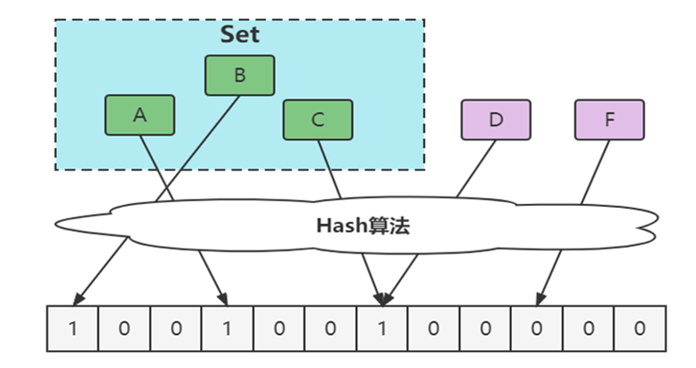
優化方案
增大數組(預估適合值)
增加hash函數
Redis中的布隆過濾器
Redisson
Maven引入Redisson
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.12.3</version></dependency>
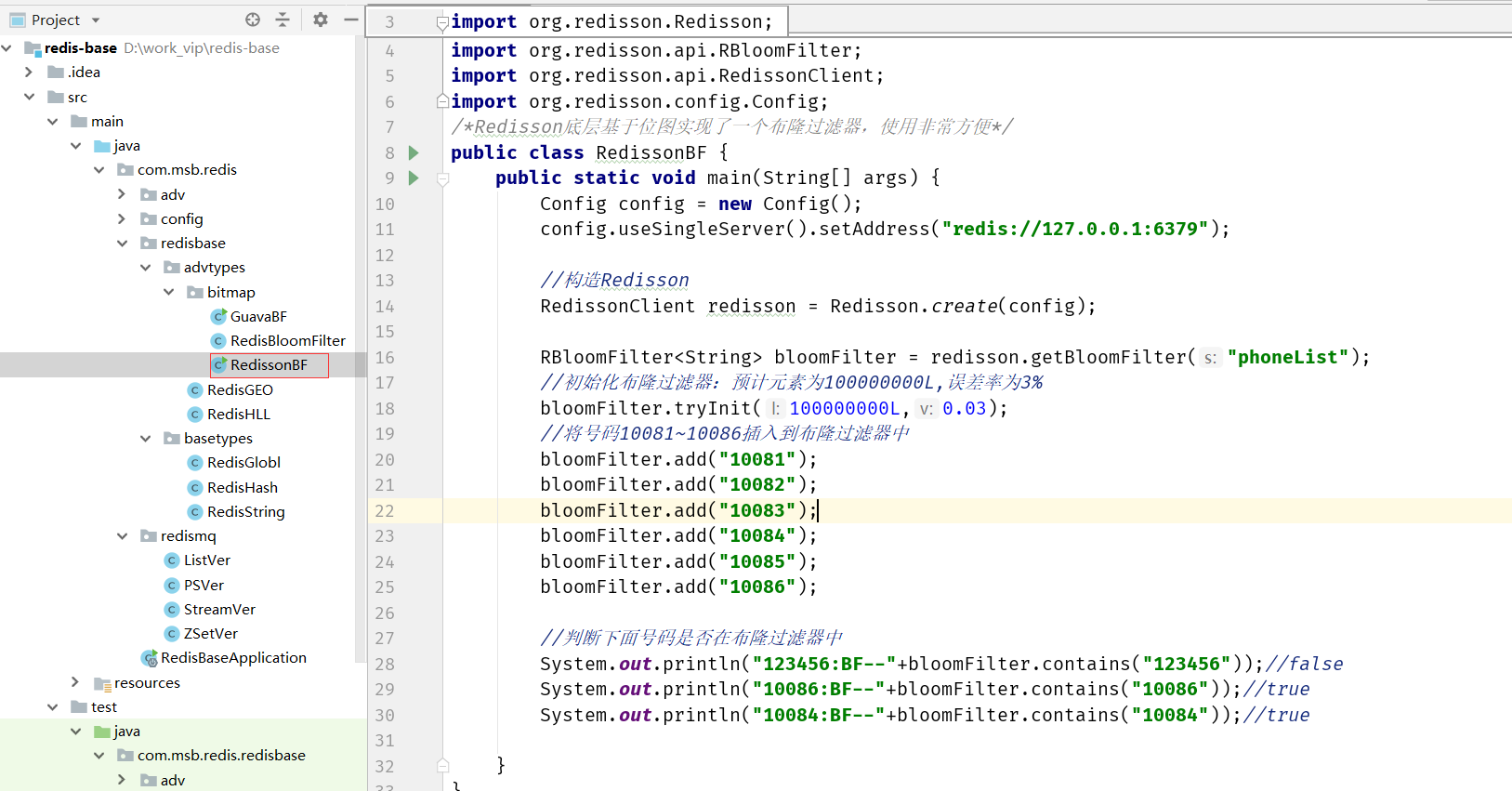
自行實現
就是利用Redis的bitmaps來實現。
單機下無Redis的布隆過濾器
使用Google的Guava的BloomFilter。
Maven引入Guava
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>30.1.1-jre</version></dependency>
HyperLogLog
介紹
HyperLogLog(Hyper[?ha?p??])并不是一種新的數據結構(實際類型為字符串類型),而是一種基數算法,通過HyperLogLog可以利用極小的內存空間完成獨立總數的統計,數據集可以是IP、Email、ID等。
如果你負責開發維護一個大型的網站,有一天產品經理要網站每個網頁每天的 UV 數據,然后讓你來開發這個統計模塊,你會如何實現?
如果統計 PV 那非常好辦,給每個網頁一個獨立的 Redis 計數器就可以了,這個計數器的 key 后綴加上當天的日期。這樣來一個請求,incrby 一次,最終就可以統計出所有的 PV 數據。
但是 UV 不一樣,它要去重,同一個用戶一天之內的多次訪問請求只能計數一次。這就要求每一個網頁請求都需要帶上用戶的 ID,無論是登陸用戶還是未登陸用戶都需要一個唯一 ID 來標識。
一個簡單的方案,那就是為每一個頁面一個獨立的 set 集合來存儲所有當天訪問過此頁面的用戶 ID。當一個請求過來時,我們使用 sadd 將用戶 ID 塞進去就可以了。通過 scard 可以取出這個集合的大小,這個數字就是這個頁面的 UV 數據。
但是,如果你的頁面訪問量非常大,比如一個爆款頁面幾千萬的 UV,你需要一個很大的 set集合來統計,這就非常浪費空間。如果這樣的頁面很多,那所需要的存儲空間是驚人的。為這樣一個去重功能就耗費這樣多的存儲空間,值得么?其實需要的數據又不需要太精確,105w 和 106w 這兩個數字對于老板們來說并沒有多大區別,So,有沒有更好的解決方案呢?
這就是HyperLogLog的用武之地,Redis 提供了 HyperLogLog 數據結構就是用來解決這種統計問題的。HyperLogLog 提供不精確的去重計數方案,雖然不精確但是也不是非常不精確,Redis官方給出標準誤差是0.81%,這樣的精確度已經可以滿足上面的UV 統計需求了。
百萬級用戶訪問網站

操作命令
HyperLogLog提供了3個命令: pfadd、pfcount、pfmerge。
pfadd
pfadd key element [element …]
pfadd用于向HyperLogLog 添加元素,如果添加成功返回1:
pfadd u-9-30 u1 u2 u3 u4 u5 u6 u7 u8

pfcount
pfcount key [key …]
pfcount用于計算一個或多個HyperLogLog的獨立總數,例如u-9-30 的獨立總數為8:

如果此時向插入一些用戶,用戶并且有重復

如果我們繼續往里面插入數據,比如插入100萬條用戶記錄。內存增加非常少,但是pfcount 的統計結果會出現誤差。
pfmerge
pfmerge destkey sourcekey [sourcekey … ]
pfmerge可以求出多個HyperLogLog的并集并賦值給destkey,請自行測試。
可以看到,HyperLogLog內存占用量小得驚人,但是用如此小空間來估算如此巨大的數據,必然不是100%的正確,其中一定存在誤差率。前面說過,Redis官方給出的數字是0.81%的失誤率。
原理概述
基本原理
HyperLogLog基于概率論中伯努利試驗并結合了極大似然估算方法,并做了分桶優化。
實際上目前還沒有發現更好的在大數據場景中準確計算基數的高效算法,因此在不追求絕對準確的情況下,使用概率算法算是一個不錯的解決方案。概率算法不直接存儲數據集合本身,通過一定的概率統計方法預估值,這種方法可以大大節省內存,同時保證誤差控制在一定范圍內。目前用于基數計數的概率算法包括:
舉個例子來理解HyperLogLog
算法,有一天李瑾老師和馬老師玩打賭的游戲。
規則如下: 拋硬幣的游戲,每次拋的硬幣可能正面,可能反面,沒回合一直拋,直到每當拋到正面回合結束。
然后我跟馬老師說,拋到正面最長的回合用到了7次,你來猜一猜,我用到了多少個回合做到的?
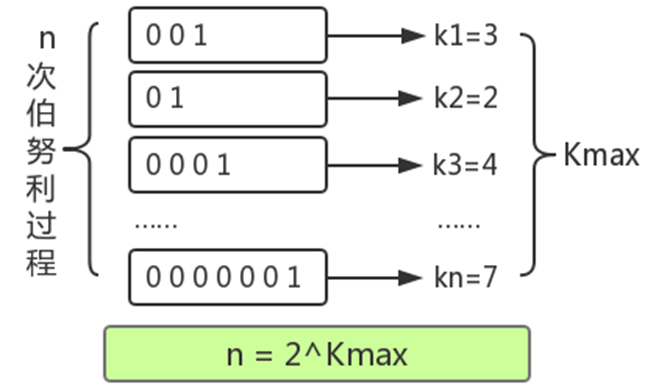
進行了n次實驗,比如上圖:
第一次試驗: 拋了3次才出現正面,此時 k=3,n=1
第二次試驗: 拋了2次才出現正面,此時 k=2,n=2
第三次試驗: 拋了4次才出現正面,此時 k=4,n=3
…………
第n 次試驗:拋了7次才出現正面,此時我們估算,k=7
馬老師說大概你拋了128個回合。這個是怎么算的。
k是每回合拋到1所用的次數,我們已知的是最大的k值,可以用kmax表示。由于每次拋硬幣的結果只有0和1兩種情況,因此,能夠推測出kmax在任意回合出現的概率 ,并由kmax結合極大似然估算的方法推測出n的次數n =
2^(k_max) 。概率學把這種問題叫做伯努利實驗。
但是問題是,這種本身就是概率的問題,我跟馬老師說,我只用到12次,并且有視頻為證。
所以這種預估方法存在較大誤差,為了改善誤差情況,HLL中引入分桶平均的概念。
同樣舉拋硬幣的例子,如果只有一組拋硬幣實驗,顯然根據公式推導得到的實驗次數的估計誤差較大;如果100個組同時進行拋硬幣實驗,受運氣影響的概率就很低了,每組分別進行多次拋硬幣實驗,并上報各自實驗過程中拋到正面的拋擲次數的最大值,就能根據100組的平均值預估整體的實驗次數了。
分桶平均的基本原理是將統計數據劃分為m個桶,每個桶分別統計各自的kmax,并能得到各自的基數預估值,最終對這些基數預估值求平均得到整體的基數估計值。LLC中使用幾何平均數預估整體的基數值,但是當統計數據量較小時誤差較大;HLL在LLC基礎上做了改進,采用調和平均數過濾掉不健康的統計值。
什么叫調和平均數呢?舉個例子
求平均工資:A的是1000/月,B的30000/月。采用平均數的方式就是:
(1000 + 30000) / 2 = 15500
采用調和平均數的方式就是:
2/(1/1000 + 1/30000) ≈ 1935.484
可見調和平均數比平均數的好處就是不容易受到大的數值的影響,比平均數的效果是要更好的。
結合Redis的實現理解原理
現在我們和前面的業務場景進行掛鉤:統計網頁每天的 UV 數據。
1.轉為比特串
通過hash函數,將數據轉為二進制的比特串,例如輸入5,便轉為:101。為什么要這樣轉化呢?
是因為要和拋硬幣對應上,比特串中,0 代表了反面,1 代表了正面,如果一個數據最終被轉化了 10010000,那么從右往左,從低位往高位看,我們可以認為,首次出現 1 的時候,就是正面。
那么基于上面的估算結論,我們可以通過多次拋硬幣實驗的最大拋到正面的次數來預估總共進行了多少次實驗,同樣也就可以根據存入數據中,轉化后的出現了 1 的最大的位置 k_max 來估算存入了多少數據。
2.分桶
分桶就是分多少輪。抽象到計算機存儲中去,就是存儲的是一個以單位是比特(bit),長度為 L 的大數組 S ,將 S 平均分為 m 組,注意這個 m 組,就是對應多少輪,然后每組所占有的比特個數是平均的,設為 P。容易得出下面的關系:
比如有4個桶的話,那么可以截取低2位作為分桶的依據。
比如
10010000 進入0號桶
10010001 進入1號桶
10010010 進入2號桶
10010011 進入3號桶
Redis 中的 HyperLogLog 實現
pfadd

當我們執行這個操作時,lijin這個字符串就會被轉化成64個bit的二進制比特串。
0010…0001 64位
然后在Redis中要分到16384個桶中(為什么是這么多桶:第一降低誤判,第二,用到了14位二進制:2的14次方=16384)
怎么分?根據得到的比特串的后14位來做判斷即可。

根據上述的規則,我們知道這個數據要分到 1號桶,同時從左往右(低位到高位)計算第1個出現的1的位置,這里是第4位,那么就往這個1號桶插入4的數據(轉成二進制)
如果有第二個數據來了,按照上述的規則進行計算。
那么問題來了,如果分到桶的數據有重復了(這里比大小,大的替換小的):
規則如下,比大小(比出現位置的大小),比如有個數據是最高位才出現1,那么這個位置算出來就是50,50比4大,則進行替換。1號桶的數據就變成了50(二進制是110010)
所以這里可以看到,每個桶的數據一般情況下6位存儲即可。
所以我們這里可以推算一下一個key的HyperLogLog只占據多少的存儲。
16384*6 /8/1024=12k。并且這里最多可以存儲多少數據,因為是64位嗎,所以就是2的64次方的數據,這個存儲的數據非常非常大的,一般用戶用long來定義,最大值也只有這么多。
pfcount
進行統計的時候,就是把16384桶,把每個桶的值拿出來,比如取出是 n,那么訪問次數就是2的n次方。
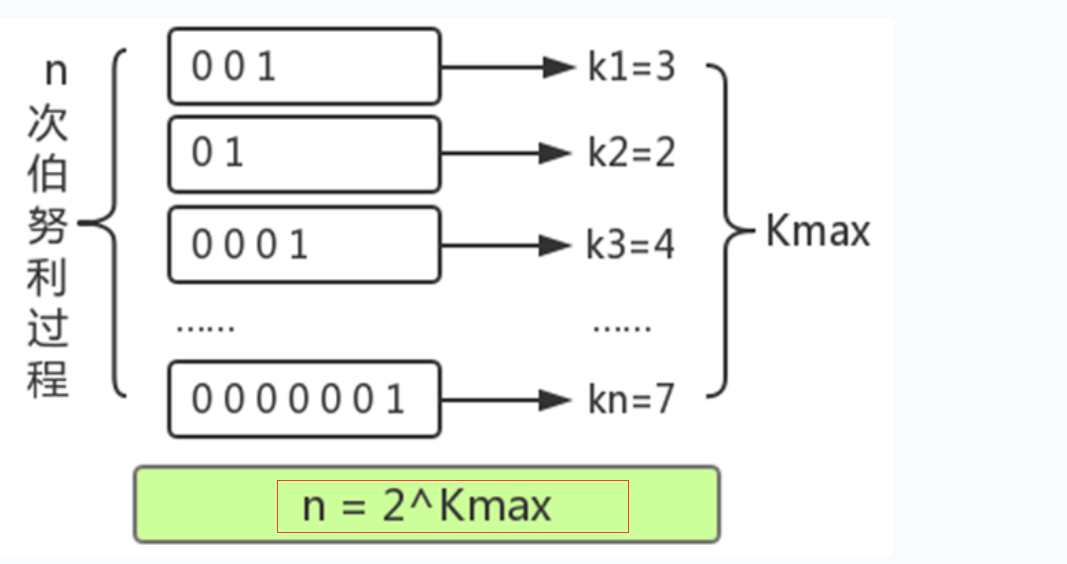
然后把每個桶的值做調和平均數,就可以算出一個算法值。
同時,在具體的算法實現上,HLL還有一個分階段偏差修正算法。我們就不做更深入的了解了。
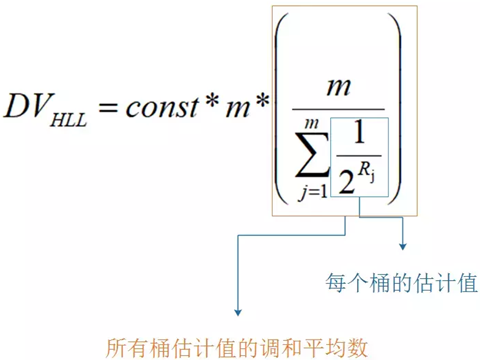
const和m都是Redis里面根據數據做的調和平均數。
GEO
Redis 3.2版本提供了GEO(地理信息定位)功能,支持存儲地理位置信息用來實現諸如附近位置、搖一搖這類依賴于地理位置信息的功能。
地圖元素的位置數據使用二維的經緯度表示,經度范圍(-180, 180],緯度范圍(-90,
90],緯度正負以赤道為界,北正南負,經度正負以本初子午線(英國格林尼治天文臺) 為界,東正西負。
業界比較通用的地理位置距離排序算法是GeoHash 算法,Redis 也使用GeoHash
算法。GeoHash
算法將二維的經緯度數據映射到一維的整數,這樣所有的元素都將在掛載到一條線上,距離靠近的二維坐標映射到一維后的點之間距離也會很接近。當我們想要計算「附近的人時」,首先將目標位置映射到這條線上,然后在這個一維的線上獲取附近的點就行了。
在 Redis 里面,經緯度使用 52 位的整數進行編碼,放進了 zset 里面,zset 的 value 是元素的 key,score 是 GeoHash 的 52 位整數值。
操作命令
增加地理位置信息
geoadd key longitude latitude member [longitude latitude member …J
longitude、latitude、member分別是該地理位置的經度、緯度、成員,例如下面有5個城市的經緯度。
城市 經度 緯度 成員
北京 116.28 39.55 beijing
天津 117.12 39.08 tianjin
石家莊 114.29 38.02 shijiazhuang
唐山 118.01 39.38 tangshan
保定 115.29 38.51 baoding
cities:locations是上面5個城市地理位置信息的集合,現向其添加北京的地理位置信息:
geoadd cities :locations 116.28 39.55 beijing
返回結果代表添加成功的個數,如果cities:locations沒有包含beijing,那么返回結果為1,如果已經存在則返回0。
如果需要更新地理位置信息,仍然可以使用geoadd命令,雖然返回結果為0。geoadd命令可以同時添加多個地理位置信息:
geoadd cities:locations 117.12 39.08 tianjin 114.29 38.02
shijiazhuang 118.01 39.38 tangshan 115.29 38.51 baoding
獲取地理位置信息
geopos key member [member …]下面操作會獲取天津的經維度:
geopos cities:locations tianjin1)1)“117.12000042200088501”
獲取兩個地理位置的距離。
geodist key member1 member2 [unit]
其中unit代表返回結果的單位,包含以下四種:
m (meters)代表米。
km (kilometers)代表公里。
mi (miles)代表英里。
ft(feet)代表尺。
下面操作用于計算天津到北京的距離,并以公里為單位:
geodist cities : locations tianjin beijing km
獲取指定位置范圍內的地理信息位置集合
georadius key longitude latitude radius m|km|ft|mi [withcoord][withdist]
[withhash][COUNT count] [ascldesc] [store key] [storedist key]
georadiusbymember key member radius m|km|ft|mi [withcoord][withdist]
[withhash] [COUNT count][ascldesc] [store key] [storedist key]georadius和georadiusbymember兩個命令的作用是一樣的,都是以一個地理位置為中心算出指定半徑內的其他地理信息位置,不同的是georadius命令的中心位置給出了具體的經緯度,georadiusbymember只需給出成員即可。其中radius m | km |ft |mi是必需參數,指定了半徑(帶單位)。
這兩個命令有很多可選參數,如下所示:
withcoord:返回結果中包含經緯度。
withdist:返回結果中包含離中心節點位置的距離。
withhash:返回結果中包含geohash,有關geohash后面介紹。
COUNT count:指定返回結果的數量。
asc l desc:返回結果按照離中心節點的距離做升序或者降序。
store key:將返回結果的地理位置信息保存到指定鍵。
storedist key:將返回結果離中心節點的距離保存到指定鍵。
下面操作計算五座城市中,距離北京150公里以內的城市:
georadiusbymember cities:locations beijing 150 km
獲取geohash
geohash key member [member ...]
Redis使用geohash將二維經緯度轉換為一維字符串,下面操作會返回beijing的geohash值。
geohash cities: locations beijing
字符串越長,表示的位置更精確,geohash長度為9時,精度在2米左右,geohash長度為8時,精度在20米左右。
兩個字符串越相似,它們之間的距離越近,Redis 利用字符串前綴匹配算法實現相關的命令。
geohash編碼和經緯度是可以相互轉換的。
刪除地理位置信息
zrem key member
GEO沒有提供刪除成員的命令,但是因為GEO的底層實現是zset,所以可以借用zrem命令實現對地理位置信息的刪除。













)
 time庫-日期和時間工具)
 Object Pascal 學習筆記---第6章第3節(字符串連接))



