Shuffle Tracking
Shuffle Tracking 是 Spark 在沒有 ESS(External Shuffle Service)情況,并且開啟 Dynamic Allocation 的重要功能。如在 K8S 上運行 spark 沒有 ESS。本文檔所有的前提都是基于以上條件的。
如果開啟了 ESS,那么 Executor 計算完后,把 shuffle 數據交給 ESS, Executor 沒有任務時,可以安全退出,下游任務從 ESS 拉取 shuffle 數據。
1. 背景
如果 Executor 執行了上游的 Shuffle Map Task 并且把 shuffle 數據些到本地。并且現在 Executor 沒有 Task 運行,那么此 Executor 是否能銷毀?
現狀是如果 Executor 沒有 active 的 shuffle 數據,則可以被銷毀。
active shuffle 的定義:如果 Shuffle Map Stage 的 task 把 shuffle 數據輸出到本地。如果依賴此 shuffle 的Stage 沒有計算完畢,則稱此 shuffle 為 active shuffle。因為依賴此 shuffle 的 Task 可能從 Driver 端獲取了 MapStatus,但是還沒有拉取完 shuffle 數據。
為了達到此目的,需要跟蹤每個 Stage 和每個 Task 的運行信息。并且啟動定時任務,定時掃描每個 Executor,判斷是否有任務運行,是否有 active 的 shuffle,如果沒有則可以退出。
退出有兩種,如果開啟了 decommission,則到期的 executors 進入 decommission 模式,否則執行 killExecutors。
參數配置
spark.dynamicAllocation.shuffleTracking.enabled: 默認 true,是否開啟 shuffle tracking。
spark.dynamicAllocation.shuffleTracking.timeout: 默認 Long.MaxValue,
2. 設計
ExecutorMonitor 為每個 Executor 創建一個 Tracker, 用于跟蹤此 Executor 的狀態。
private val executors = new ConcurrentHashMap[String, Tracker]()
定時任務間隔時間查找 timeout 的 executor,然后處理。
timedOutExecutors 方法的主要邏輯,就是遍歷 executors。如果 executor 沒有 active 的 shuffle 并且當前時間大于 executor 的超時時間 timeoutAt,則此 executor 可以被安全釋放。
為什么 executor 有 active shuffle 數據就不能 kill?
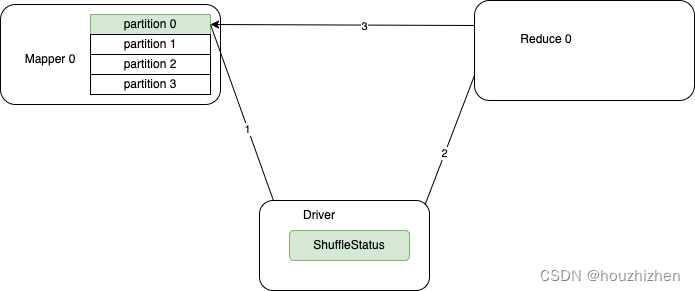
- Shuffle 的過程:
- MapTask 把 shuffle 寫到本地,并且把狀態匯報給 Driver.
- Reduce Task 從 Driver 獲取 shuffle status,并從 shuffle status 獲取每個 shuffle 數據的地址。
- 連接對應的 executor 獲取 shuffle 數據。
如果在 reduce 獲取完 shuffle status 后,MapTask 所在的 Executor 被 kill 掉,Reduce Task 就無法獲取 shuffle 數據。
如果執行 decommission 邏輯,把 MapTask 的 shuffle 數據長傳到 bos 等分布式存儲是否可以?
也是不可以的,因為 reduce 可能已經把 shuffle status 拿走,獲取的 shuffle status 沒有記錄 shuffle 數據在分布式存儲上。
參考: ExecutorMonitor,ExecutorAllocationManager
Executor 狀態的更新
ExecutorMonitor 實現了 SparkListner 接口,當 Job, Stage, Task 等 start 和 end 時,都會執行回調。
以 hasActiveShuffle 為例
每個 executor 用一個集合 shuffleIds 存儲其上擁有的 shuffle 數據。 當其為空時,說明沒有 shuffle 數據。
在 onTaskEnd 和 onBlockUpdated 時調用 addShuffle 向 shuffleIds 添加數據。
在以下時機刪除 shuffleIds 里的數據。
- 依賴 driver 端的 ContextCleaner,當 ShuffleRDD 僅有 weakReference 時觸發。
- rdd.cleanShuffleDependencies 方法,但是此方法僅在 org.apache.spark.ml.recommendation.ALS 使用。
timeoutAt 的計算邏輯
總結:timeoutAt 根據 idle 的時間,spark.dynamicAllocation.cachedExecutorIdleTimeout 和 spark.dynamicAllocation.shuffleTracking.timeout 這 3 個值中最大的值。
詳細計算邏輯:
timeoutAt 在一些事件發生時觸發計算,如 onBlockUpdated, onUnpersistRDD, updateRunningTasks, removeShuffle, updateActiveShuffles
timeoutAt 的計算邏輯:
當執行器有計算任務時 為 Long.MaxValue。
否則為 max(_cacheTimeout, _shuffleTimeout, idleTimeoutNs)
_cacheTimeout: 如果沒有 cache 數據,為0,否則為參數 spark.dynamicAllocation.cachedExecutorIdleTimeout 的值(默認 Long.MaxValue)。
_shuffleTimeout: 如果沒有 shuffle數據,為 0, 否則為參數 spark.dynamicAllocation.shuffleTracking.timeout 的值(默認 Long.MaxValue)。
idleTimeoutNs 為 spark.dynamicAllocation.executorIdleTimeout
3. 測試
測試命令
spark-shell \--conf spark.dynamicAllocation.enabled=true \--conf spark.dynamicAllocation.initialExecutors=2 \--conf spark.dynamicAllocation.maxExecutor=400 \--conf spark.dynamicAllocation.minExecutors=1 \--conf spark.shuffle.service.enabled=false \--conf spark.dynamicAllocation.shuffleTracking.enabled=true
參考資料:
https://www.waitingforcode.com/apache-spark/what-new-apache-spark-3-shuffle-service-changes/read



)






:滾動彈幕的設計與實現)








