一、目的
數倉的數據源是Kafka,因此離線數倉需要用Flume采集Kafka中的數據到HDFS中
在實際項目中,不可能一直在Xshell中啟動Flume任務,一是項目的Flume任務很多,二是一旦Xshell頁面關閉Flume任務就會停止,這樣非常不方便,因此必須在后臺啟動Flume任務。
所以經過測試后,發現海豚調度器也可以啟動Flume任務

二、海豚調度Flume任務配置
(一)Flume在Linux中的路徑
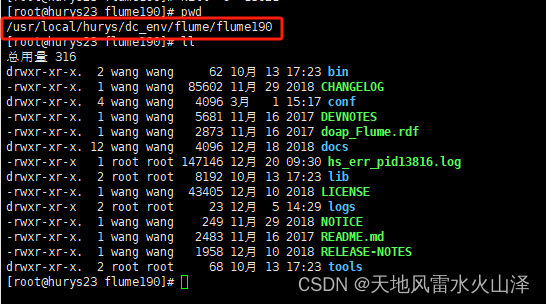
(二)Flume任務文件在Linux中的位置以及任務文件名
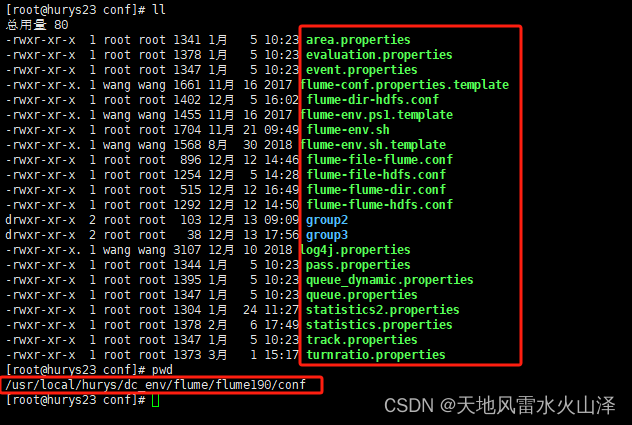
(三)在海豚中配置運行腳本
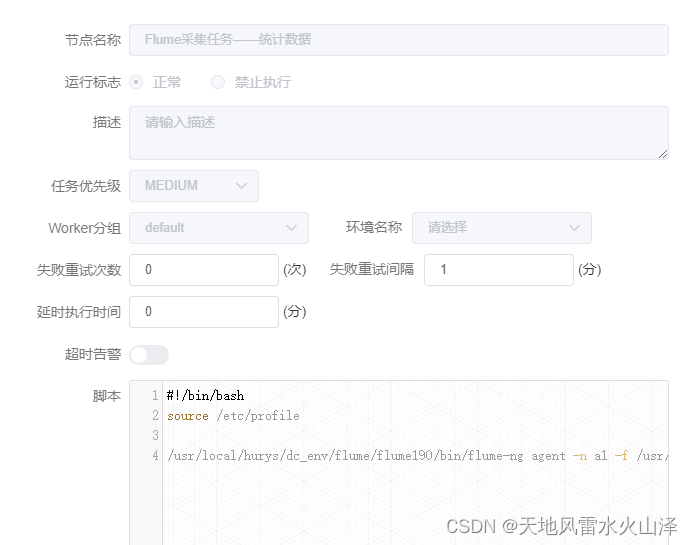
#!/bin/bash
source /etc/profile
/usr/local/hurys/dc_env/flume/flume190/bin/flume-ng agent -n a1 -f /usr/local/hurys/dc_env/flume/flume190/conf/statistics.properties
注意:/usr/local/hurys/dc_env/flume/flume190/為Flume在Linux中的安裝,根據自己安裝路徑進行調整
(四)海豚任務配置好后就可以啟動海豚任務

(五)在HDFS對應文件夾中驗證是否采集到數據
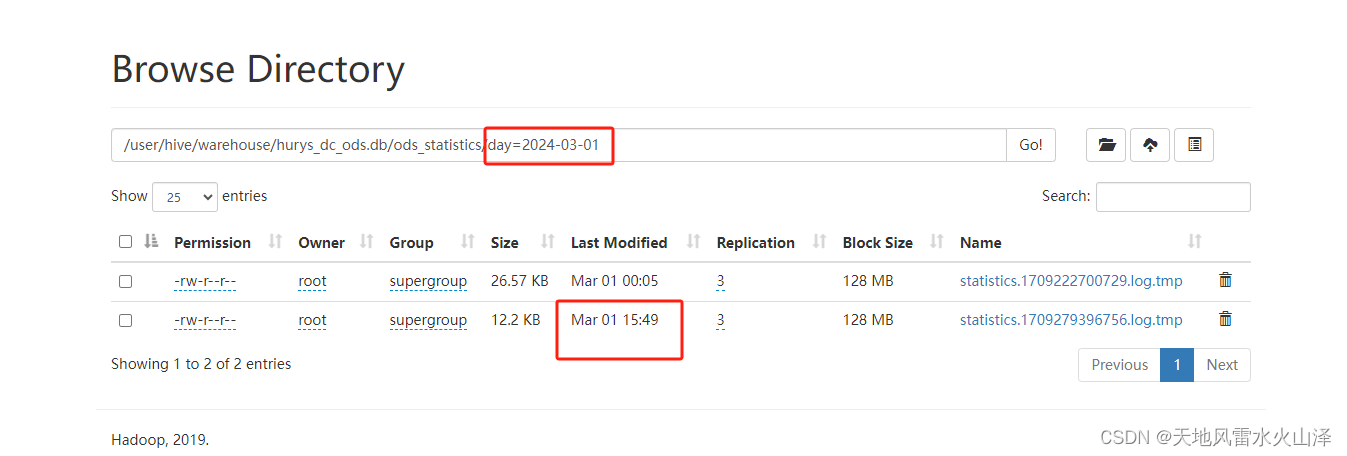
Flume采集Kafka數據成功寫入到HDFS中,成功實現用海豚執行Flume任務的目的!












(三))





)
