之前寫過一點小知識:https://blog.csdn.net/qq_45927881/article/details/134959181?spm=1001.2014.3001.5501
參考鏈接
https://xiaolincoding.com/redis/data_struct/command.html#%E4%BB%8B%E7%BB%8D
目錄
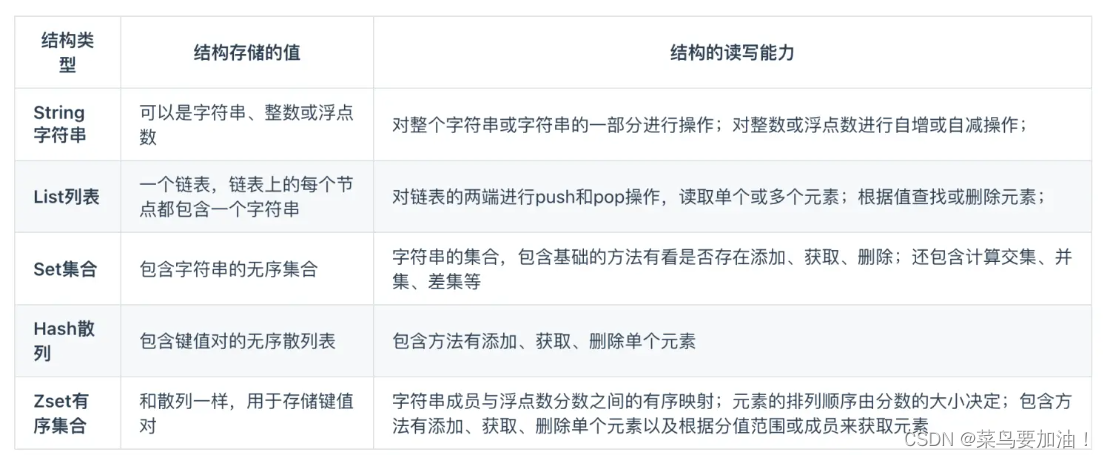
- 1. string(字符串)
- 2. Hash(哈希)
- 3. List(列表)
- 4. Set(集合)
- 5. Zset(有序集合)
1. string(字符串)
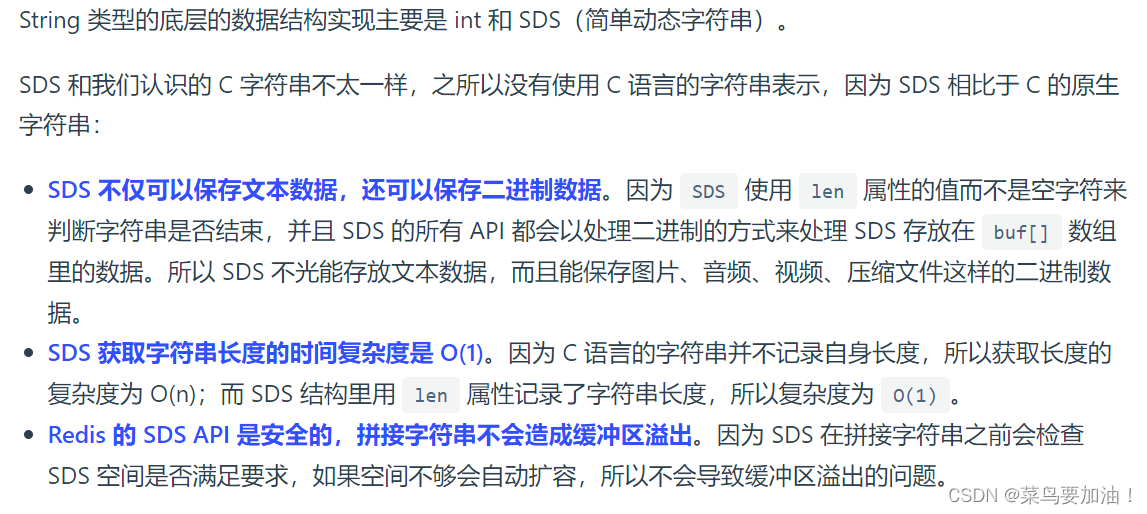
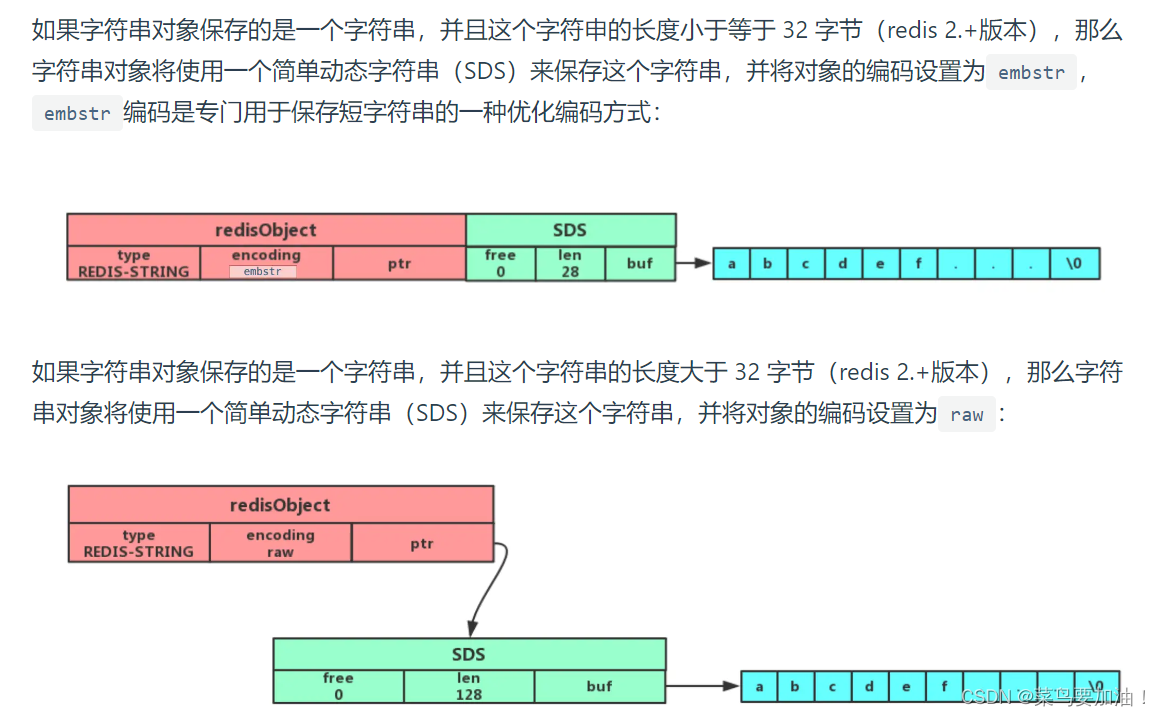
String 是最基本的 key-value 結構,key 是唯一標識,value 是具體的值,value其實不僅是字符串, 也可以是數字(整數或浮點數),value 最多可以容納的數據長度是 512M
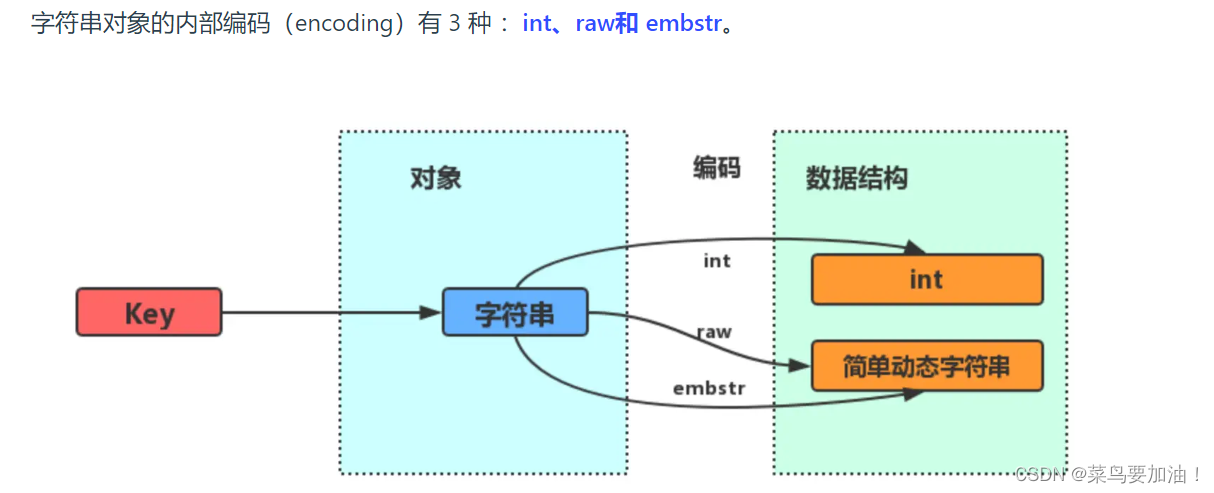
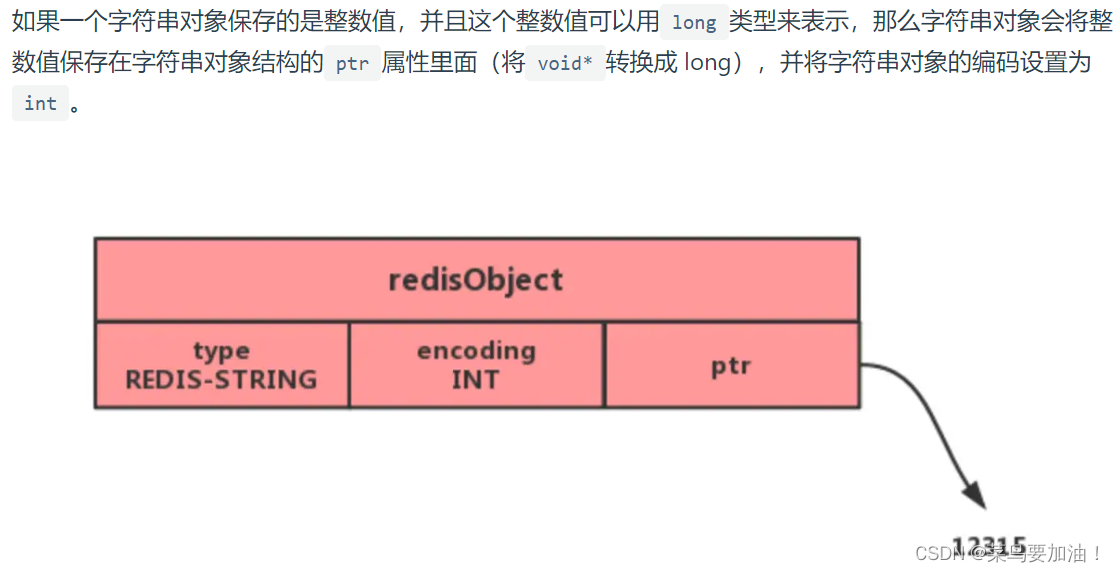
總結:
以下是Redis中string的主要特點和用法:
-
存儲字符串數據: string類型可以存儲任意長度的字符串數據,例如文本、JSON等。
-
存儲整數和浮點數: string類型還可以存儲整數和浮點數數據。當存儲整數時,Redis會對整數進行特殊處理,可以對整數進行自增、自減等操作。當存儲浮點數時,Redis會以字符串形式存儲,并支持對浮點數進行加減乘除等數學運算。
-
常見命令: Redis提供了一系列用于操作string的命令,包括:
- SET:設置指定鍵的值。
- GET:獲取指定鍵的值。
- DEL:刪除指定鍵及其對應的值。
- INCR:將指定鍵的值增加1。
- DECR:將指定鍵的值減少1。
- APPEND:在指定鍵的值后面追加字符串。
-
內存優化: Redis對于小字符串的存儲采用了一種優化策略,即使用SDS(Simple Dynamic String)來存儲字符串數據,可以減少內存的碎片化和浪費。
-
應用場景: string類型在Redis中有著廣泛的應用場景,例如==緩存、計數器、分布式鎖==等。

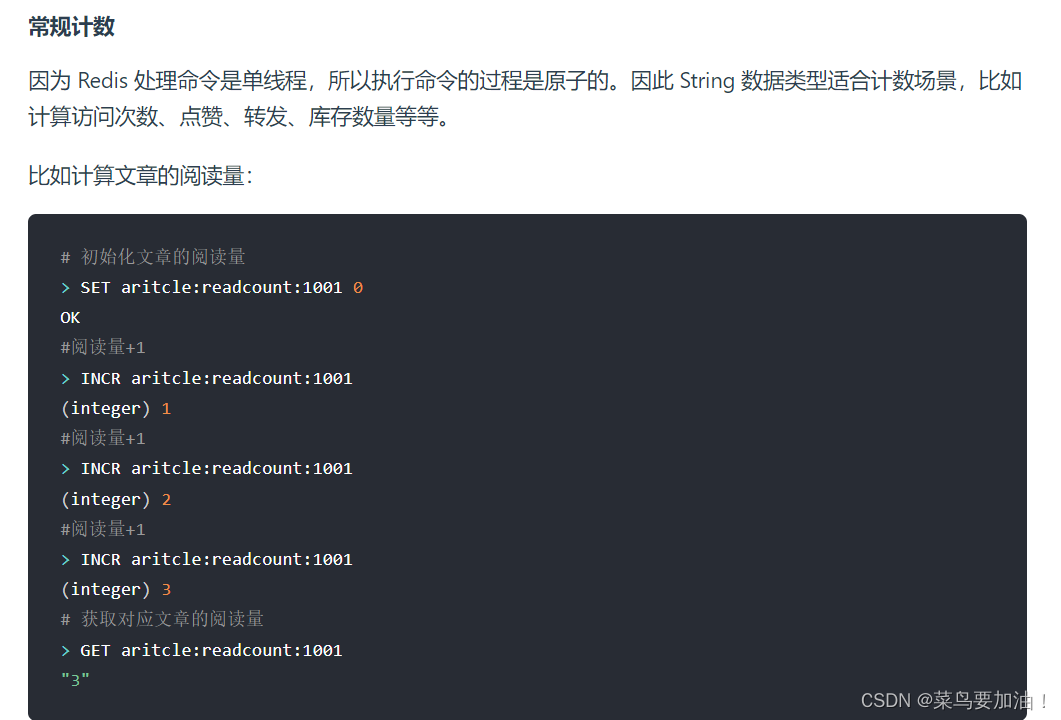
分布式鎖(還沒完全了解,待更新…)
共享 Session 信息
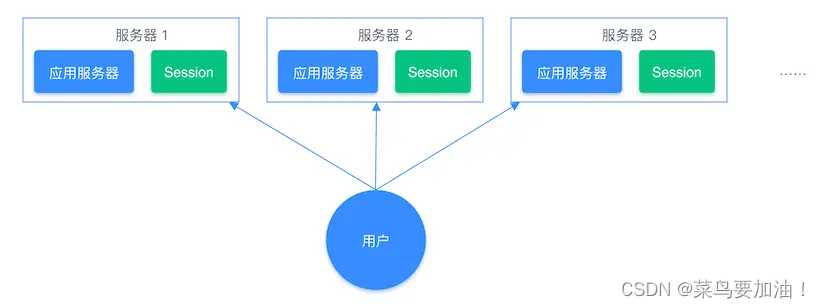
問題:通常我們在開發后臺管理系統時,會使用 Session 來保存用戶的會話(登錄)狀態,這些 Session 信息會被保存在服務器端,但這只適用于單系統應用,如果是分布式系統此模式將不再適用。
例如用戶一的 Session 信息被存儲在服務器一,但第二次訪問時用戶一被分配到服務器二,這個時候服務器并沒有用戶一的 Session 信息,就會出現重復登錄的問題,問題在于分布式系統每次會把請求隨機分配到不同的服務器。
分布式系統單獨存儲 Session 流程圖:
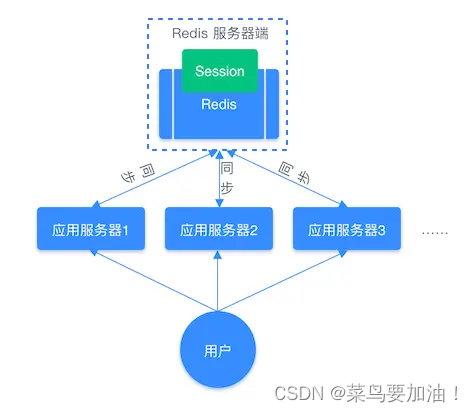
因此,需要借助 Redis 對這些 Session 信息進行統一的存儲和管理,這樣無論請求發送到哪臺服務器,服務器都會去同一個 Redis 獲取相關的 Session 信息,這樣就解決了分布式系統下 Session 存儲的問題。
分布式系統使用同一個 Redis 存儲 Session 流程圖:
2. Hash(哈希)
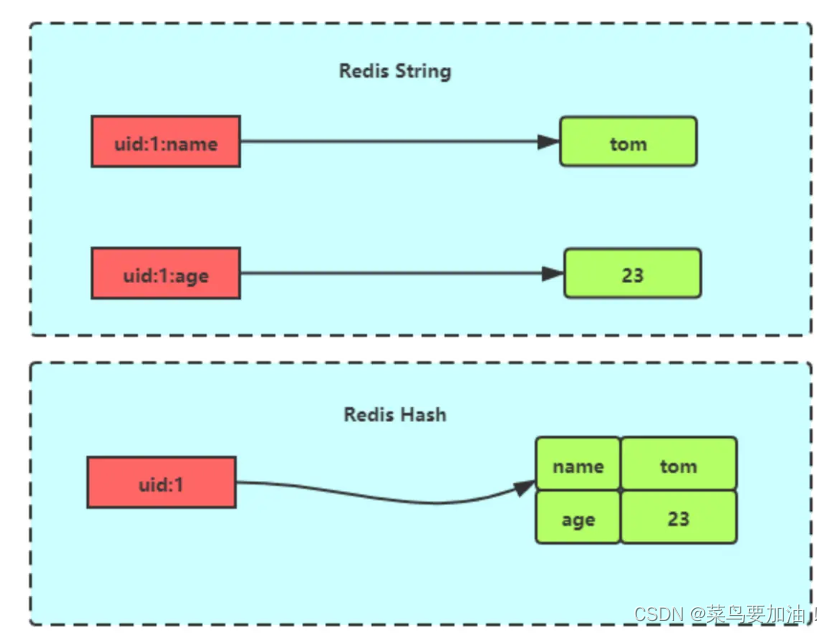
Hash 是一個鍵值對(key - value)集合,其中 value 的形式如: value=[{field1,value1},…{fieldN,valueN}]。Hash 特別適合用于存儲對象。
Hash 與 String 對象的區別如下圖所示:
總結
在Redis中,hash是一種用于存儲鍵值對的數據結構,類似于字典或者關聯數組。每個hash可以存儲多個鍵值對,其中每個鍵都是唯一的,且與一個值關聯。
以下是Redis中hash的主要特點和用法:
-
存儲鍵值對: hash類型可以存儲多個鍵值對,其中每個鍵都是唯一的,且與一個值關聯。這些值可以是字符串、整數或者浮點數等類型。
-
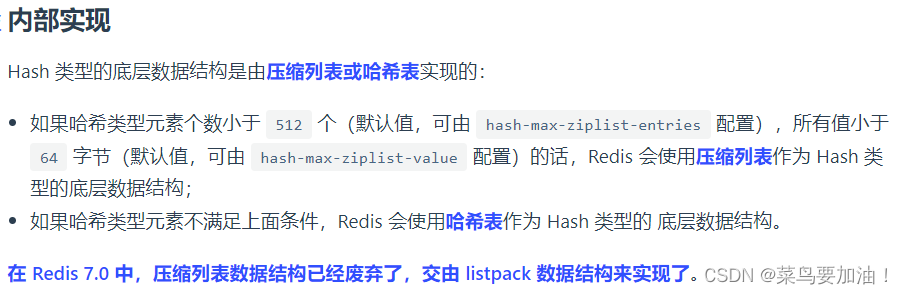
內存優化: Redis對于小hash的存儲采用了一種優化策略,可以減少內存的碎片化和浪費。
-
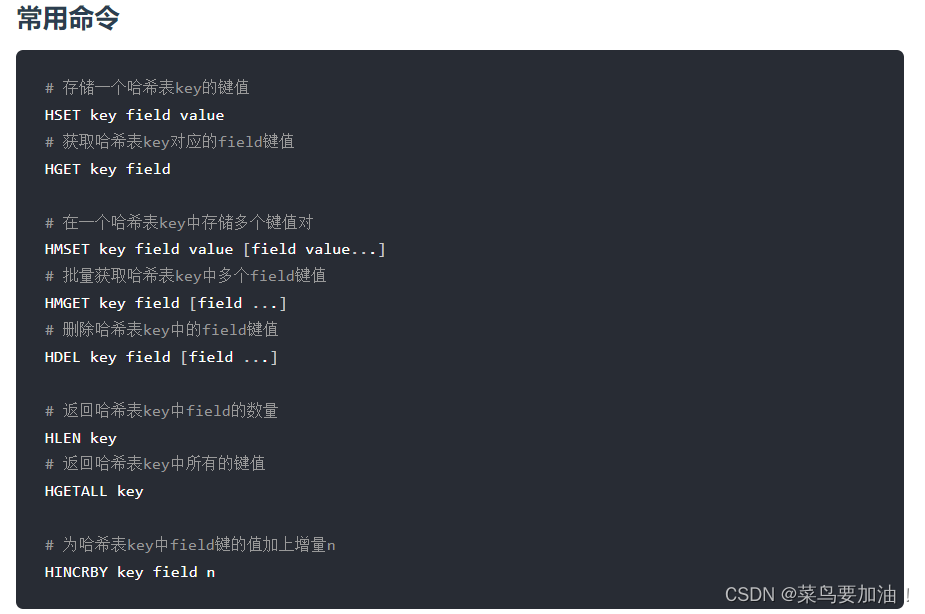
支持多字段操作: Redis提供了一系列用于操作hash的命令,包括:
- HSET:設置hash中指定字段的值。
- HGET:獲取hash中指定字段的值。 -
HDEL:刪除hash中指定字段及其對應的值。- HINCRBY:將hash中指定字段的值增加一個整數。
- HGETALL:獲取hash中所有字段和對應的值。
- HMSET:同時設置多個字段的值。 HMGET:同時獲取多個字段的值。
- 應用場景: hash類型在Redis中有著廣泛的應用場景,例如存儲對象的屬性、緩存數據、統計數據等。它可以將相關的數據組織在一起,方便進行管理和操作。
緩存對象
在介紹 String 類型的應用場景時有所介紹,String + Json也是存儲對象的一種方式,那么存儲對象時,到底用 String + json 還是用 Hash 呢?
一般對象用 String + Json 存儲,對象中某些頻繁變化的屬性可以考慮抽出來用 Hash 類型存儲。
緩存對象的例子:
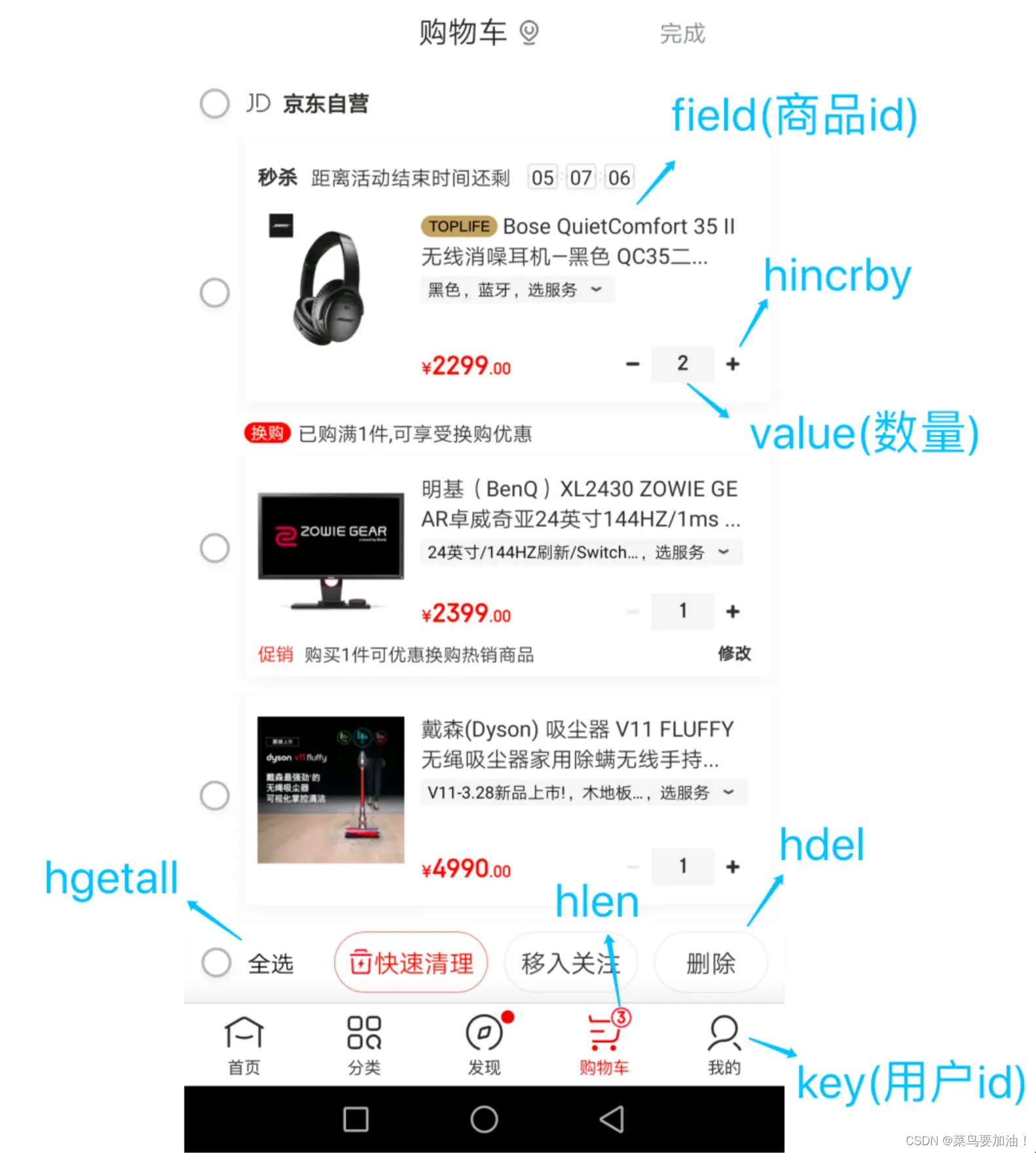
購物車
以用戶 id 為 key(因為用戶id不會頻繁發生變化),商品 id 為 field(商品id會頻繁發生變化),商品數量為 value,恰好構成了購物車的3個要素,
如下圖所示。
涉及的命令如下:
- 添加商品:HSET cart:{用戶id} {商品id} 1
- 添加數量:HINCRBY cart:{用戶id} {商品id} 1
- 商品總數:HLEN cart:{用戶id}
- 刪除商品:HDEL cart:{用戶id} {商品id}
- 獲取購物車所有商品:HGETALL cart:{用戶id}
當前僅僅是將商品ID存儲到了Redis 中,在回顯商品具體信息的時候,還需要拿著商品 id查詢一次數據庫,獲取完整的商品的信息
3. List(列表)
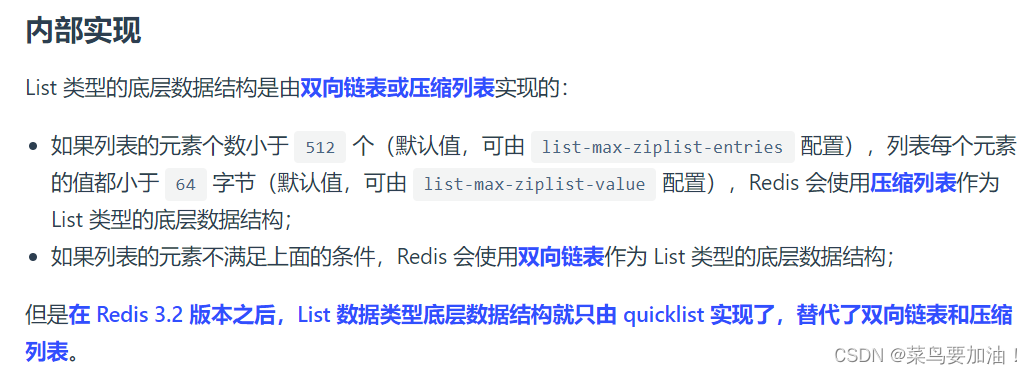
List 列表是簡單的字符串列表,按照插入順序排序,可以從頭部或尾部向 List 列表添加元素。
總結
在Redis中,List(列表)是一種常用的數據結構,它可以存儲一個有序的字符串列表。List中的每個元素都可以是一個字符串,它們按照插入順序排列,并且支持從兩端進行元素的插入和刪除操作。
以下是Redis中List的主要特點和用法:
-
有序性: List中的元素按照插入順序排列,保持了元素的有序性。這意味著元素的順序可以被保留和控制,可以按照特定的順序進行訪問和處理。
-
動態增長: List是一個動態數據結構,它可以根據需要動態地增長和縮減。在List中添加元素時,List會自動增長以容納新的元素;而刪除元素時,List會自動縮減以釋放空間。
-
支持重復元素: List中可以包含重復的元素,即同一個值可以被多次插入到List中。
-
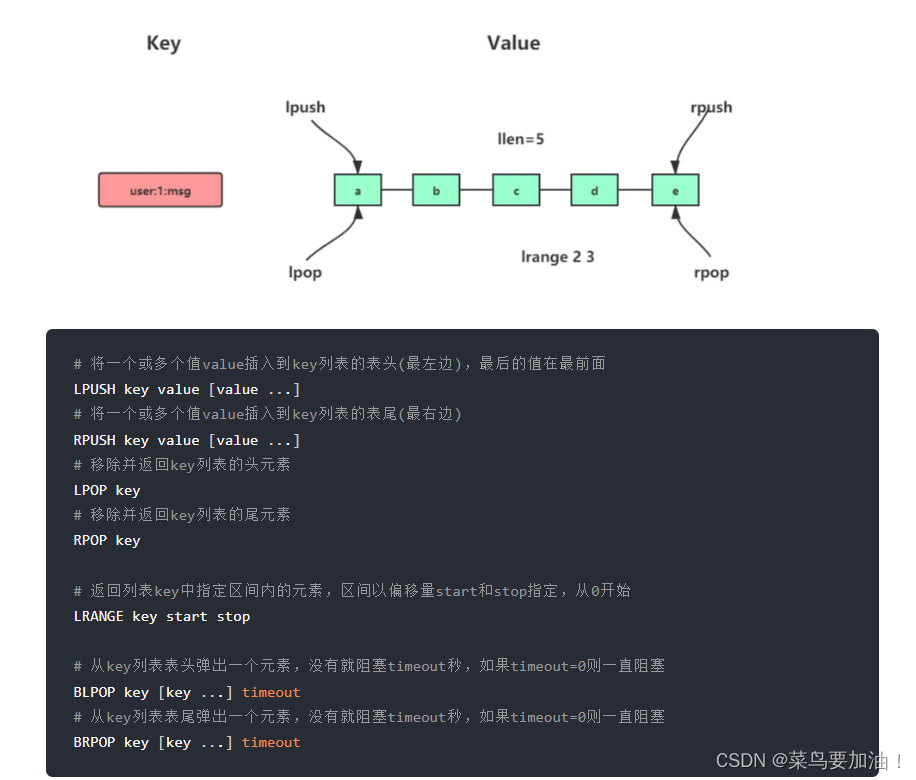
常見命令: Redis提供了一系列用于操作List的命令,包括:
- LPUSH / RPUSH:將一個或多個元素從左端(LPUSH)或右端(RPUSH)插入到List中。
- LPOP / RPOP:從左端(LPOP)或右端(RPOP)刪除并返回一個元素。
- LRANGE:獲取List中指定范圍的元素。
- LLEN:獲取List的長度(即元素個數)。
- LINDEX:獲取List中指定索引位置的元素。
- 應用場景: List在Redis中有著廣泛的應用場景,例如消息隊列、任務隊列、最新消息列表、粉絲列表等。通過List可以方便地實現先進先出(FIFO)的數據結構,以及實時更新和處理數據列表。
消息隊列
消息隊列的定義:
消息隊列(Message Queue)是一種基于消息的通信模式,用于在應用程序之間進行異步通信。它通常由消息生產者、消息隊列和消息消費者組成,消息生產者負責將消息發送到隊列中,消息消費者則從隊列中獲取消息并進行處理。消息隊列的主要特點包括:
解耦和異步: 消息隊列可以實現生產者和消費者之間的解耦,即生產者不需要知道消費者的存在,反之亦然。生產者可以將消息發送到隊列中之后即可繼續執行其他任務,而消費者則可以從隊列中異步地獲取消息并進行處理。
削峰填谷: 消息隊列可以平滑處理系統的高峰流量和突發請求,通過緩沖消息并控制消息處理速率,可以有效地減輕系統負載和提高系統的穩定性。
數據傳輸和持久化: 消息隊列通常提供可靠的消息傳輸和持久化機制,可以確保消息的可靠傳遞和持久化存儲,即使在系統故障或者網絡中斷的情況下也不會丟失消息。
消息分發和路由: 消息隊列通常支持靈活的消息分發和路由策略,可以根據消息的類型、優先級或者目的地進行消息的分發和路由,從而滿足不同的業務需求。
隊列管理和監控: 消息隊列通常提供豐富的管理和監控功能,可以對隊列進行監控和管理,包括隊列的創建、刪除、監控隊列的狀態、消息數量、消費者數量等。
消息隊列在分布式系統、微服務架構、異步任務處理等場景中有著廣泛的應用,可以提高系統的可伸縮性、可靠性和性能,實現系統之間的解耦和異步通信
消息隊列在存取消息時,必須要滿足三個需求,分別是消息保序、處理重復的消息和保證消息可靠性。
1、如何滿足消息保序需求?
List 本身就是按先進先出【FIFO】的順序對數據進行存取的,所以,如果使用 List 作為消息隊列保存消息的話,就已經能滿足消息保序的需求了。
List 可以使用 LPUSH + RPOP (或者反過來,RPUSH+LPOP)命令實現消息隊列。

生產者使用 LPUSH key value[value…] 將消息插入到隊列的頭部,如果 key 不存在則會創建一個空的隊列再插入消息。
消費者使用 RPOP key 依次讀取隊列的消息,先進先出。
不過,在消費者讀取數據時,有一個潛在的性能風險點。
在生產者往 List 中寫入數據時,List 并不會主動地通知消費者有新消息寫入,如果消費者想要及時處理消息,就需要在程序中不停地調用 RPOP 命令(比如使用一個while(1)循環)。如果有新消息寫入,RPOP命令就會返回結果,否則,RPOP命令返回空值,再繼續循環。
所以,即使沒有新消息寫入List,消費者也要不停地調用 RPOP 命令,這就會導致消費者程序的 CPU 一直消耗在執行 RPOP 命令上,帶來不必要的性能損失。
為了解決這個問題,Redis提供了 BRPOP 命令。BRPOP命令也稱為阻塞式讀取,客戶端在沒有讀到隊列數據時,自動阻塞,直到有新的數據寫入隊列,再開始讀取新數據。 (類似go語言的管道channel)和消費者程序自己不停地調用RPOP命令相比,這種方式能節省CPU開銷。
2、如何處理重復的消息?(因為 List中可以包含重復的元素)
消費者要實現重復消息的判斷,需要 2 個方面的要求:
- 每個消息都有一個全局的 ID。
- 消費者要記錄已經處理過的消息的 ID。當收到一條消息后,消費者程序就可以對比收到的消息 ID 和記錄的已處理過的消息 ID,來判斷當前收到的消息有沒有經過處理。如果已經處理過,那么,消費者程序就不再進行處理了。
但是 List 并不會為每個消息生成 ID 號,所以我們需要自行為每個消息生成一個全局唯一ID,生成之后,我們在用 LPUSH 命令把消息插入 List 時,需要在消息中包含這個全局唯一 ID。
例如,我們執行以下命令,就把一條全局 ID 為 111000102、庫存量為 99 的消息插入了消息隊列:
LPUSH mq “111000102:stock:99”
(integer) 1
3、如何保證消息可靠性?
當消費者程序從 List 中讀取一條消息后,List 就不會再留存這條消息了。所以,如果消費者程序在處理消息的過程出現了故障或宕機,就會導致消息沒有處理完成,那么,消費者程序再次啟動后,就沒法再次從 List 中讀取消息了。
為了留存消息,List 類型提供了 BRPOPLPUSH 命令,這個命令的作用是讓消費者程序從一個 List 中讀取消息,同時,Redis 會把這個消息再插入到另一個 List(可以叫作備份 List)留存。
這樣一來,如果消費者程序讀了消息但沒能正常處理,等它重啟后,就可以從備份 List 中重新讀取消息并進行處理了。
基于 List 類型的消息隊列,滿足消息隊列的三大需求(消息保序、處理重復的消息和保證消息可靠性)。
- 消息保序:使用 LPUSH + RPOP; (但是消費者循環讀取消息,如果這時候隊列中沒有此消息,那么消費者會讀取到空值,這不僅浪費資源,也沒有得到結果,需要改進,所以加了阻塞讀取)
- 阻塞讀取:使用 BRPOP;
- 重復消息處理:生產者自行實現全局唯一 ID;
- 消息的可靠性:使用 BRPOPLPUSH
List 作為消息隊列有什么缺陷?
-
List 不支持多個消費者消費同一條消息,因為一旦消費者拉取一條消息后,這條消息就從 List 中刪除了,無法被其它消費者再次消費。
-
要實現一條消息可以被多個消費者消費,那么就要將多個消費者組成一個消費組,使得多個消費者可以消費同一條消息,但是== List 類型并不支持消費組的實現==。
這就要說起 Redis 從 5.0 版本開始提供的 Stream 數據類型 了,Stream 同樣能夠滿足消息隊列的三大需求,而且它還支持「消費組」形式的消息讀取。
4. Set(集合)
Set 類型是一個無序并唯一的鍵值集合【ist 是按照元素的先后順序存儲元素,且支持重復元素】,它的存儲順序不會按照插入的先后順序進行存儲。

總結
在Redis中,set是一種無序、唯一的集合數據結構,它可以存儲多個不重復的元素。Redis的set數據結構提供了高效的添加、刪除、更新、查找等操作,常用于存儲一組唯一的元素。
以下是Redis中set的主要特點和用法:
-
存儲唯一元素: set類型可以存儲多個不重復的元素,每個元素在set中只會出現一次,不會重復。
-
無序性: set類型中的元素是無序的,即存儲元素的順序不會影響元素的存儲和查找。
-
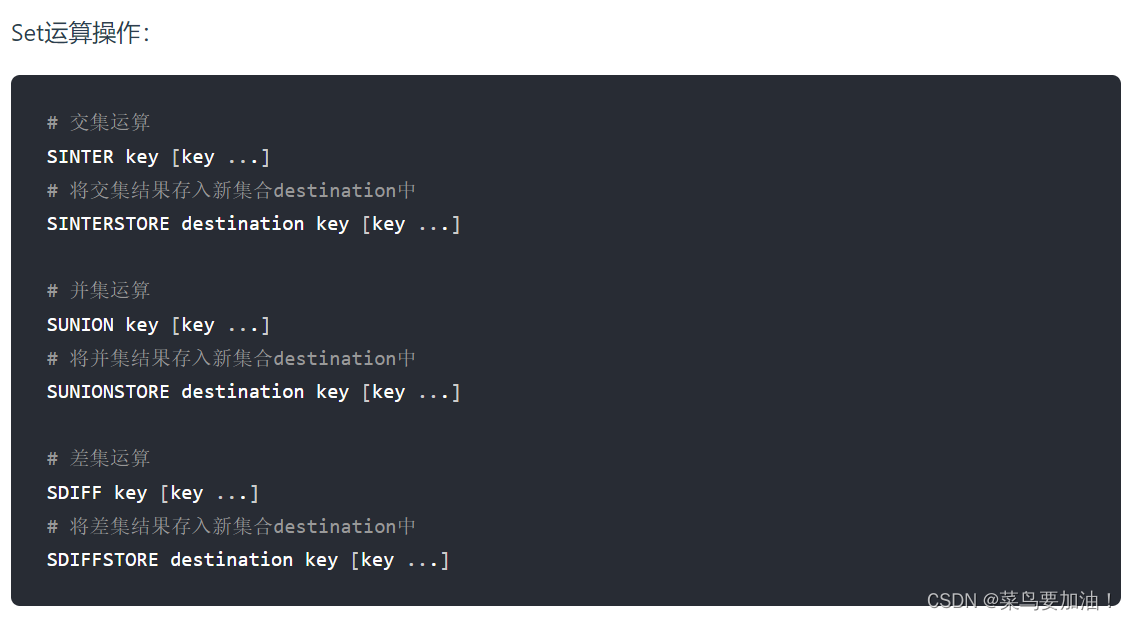
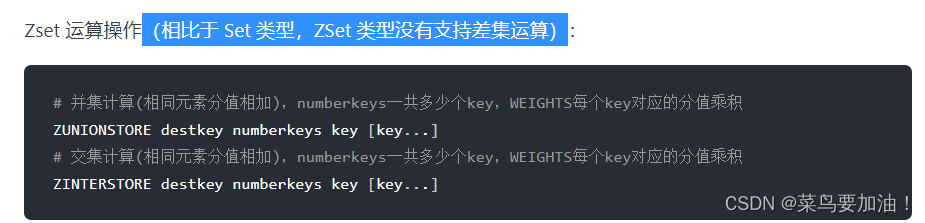
Redis的set類型支持多個集合之間的交集、并集、差集等運算,可以方便地進行集合操作。
-
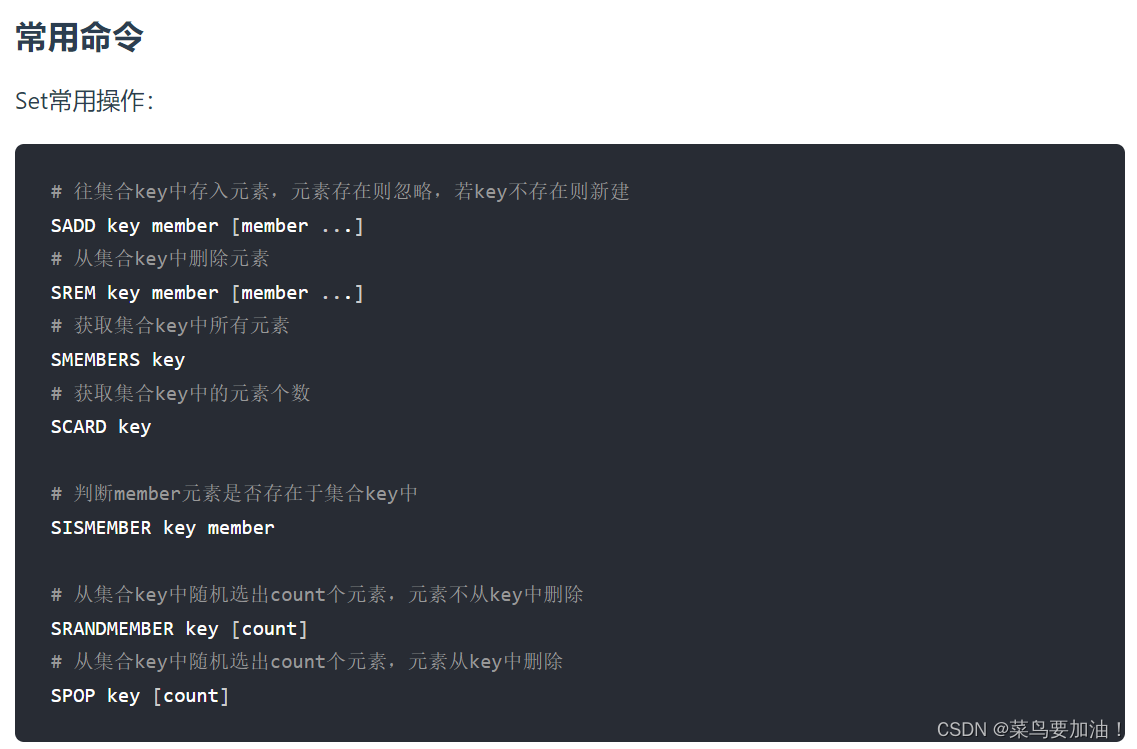
常見命令: Redis提供了一系列用于操作set的命令,包括:
- SADD:向指定集合中添加一個或多個元素。
- SREM:從指定集合中移除一個或多個元素。
- SISMEMBER:檢查指定元素是否存在于集合中。
- SMEMBERS:獲取集合中的所有元素。
- SCARD:獲取集合中元素的數量。 SINTER:求多個集合的交集。
- SUNION:求多個集合的并集。
- SDIFF:求多個集合的差集。 集合運算:
- 應用場景: set類型在Redis中有著廣泛的應用場景,例如標簽系統、關注列表、粉絲列表等。它可以存儲一組唯一的元素,并提供高效的操作命令,非常適合于需要存儲一組唯一元素的場景。

點贊
Set 類型可以保證一個用戶只能點一個贊,這里舉例子一個場景,key 是文章id,value 是用戶id。
共同關注
Set 類型支持交集運算,所以可以用來計算共同關注的好友、公眾號等。
key 可以是用戶id,value 則是已關注的公眾號的id。
抽獎活動
存儲某活動中中獎的用戶名 ,Set 類型因為有去重功能,可以保證同一個用戶不會中獎兩次。
key為抽獎活動名,value為員工名稱,把所有員工名稱放入抽獎箱
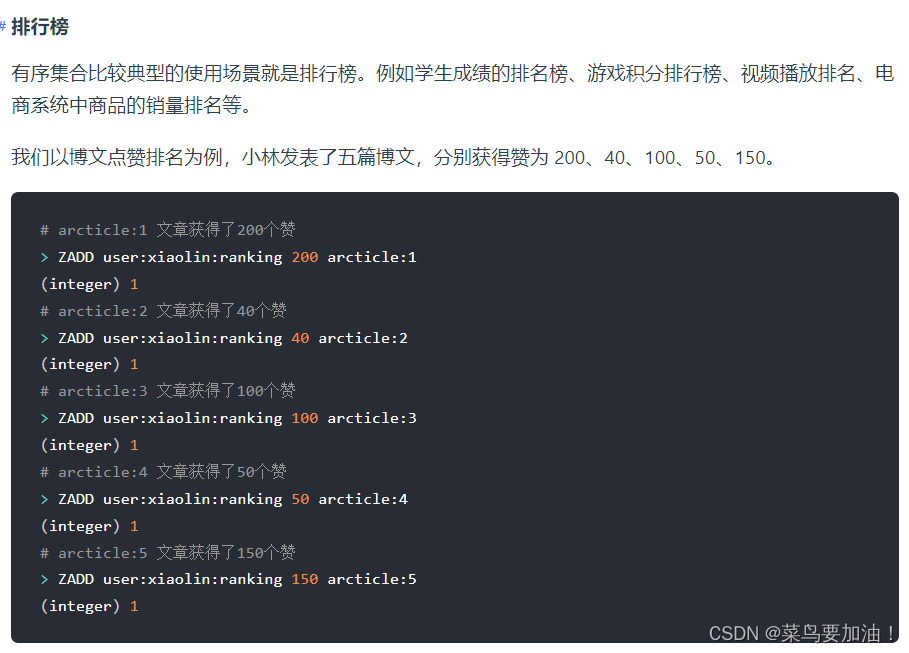
5. Zset(有序集合)
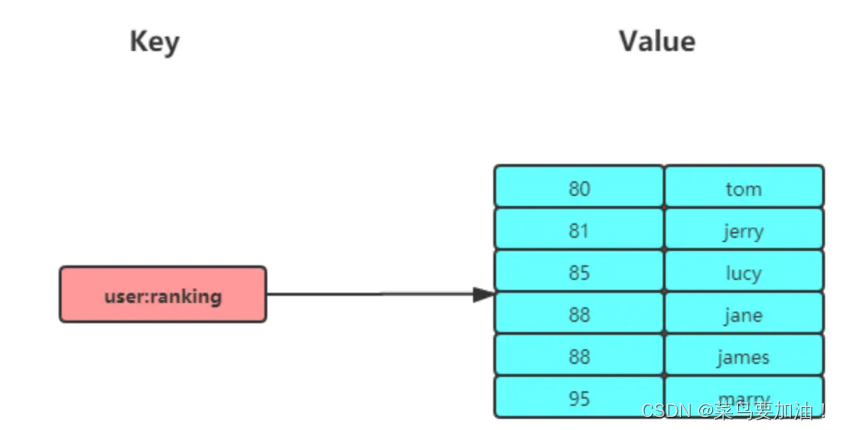
Zset 類型(有序集合類型)相比于 Set 類型多了一個排序屬性 score(分值),對于有序集合 ZSet 來說,每個存儲元素相當于有兩個值組成的,一個是有序集合的元素值,一個是排序值。
有序集合保留了集合不能有重復成員的特性(分值可以重復:80、80、81、88、88等),但不同的是,有序集合中的元素可以排序。
總結
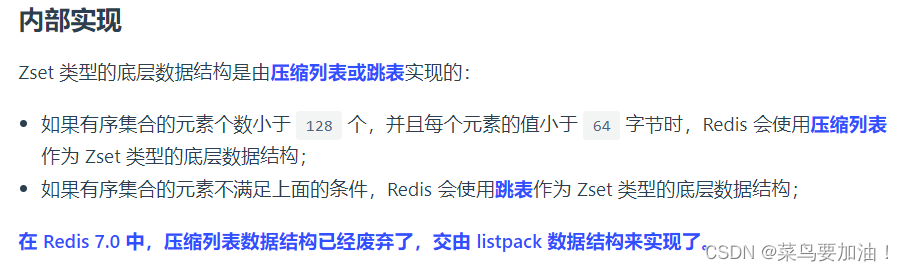
在Redis中,Zset(有序集合)是一種有序的數據結構,它類似于普通的集合(set),但每個元素都關聯了一個分數(score),使得元素可以按照分數進行排序。Zset中的元素是唯一的,但分數可以重復。(有序但可重復)
以下是Redis中Zset的主要特點和用法:
-
有序性: Zset中的元素是按照分數進行排序的,可以根據分數來獲取元素的排名和范圍。這種有序性使得Zset非常適合于需要按照某種順序來處理元素的場景。
-
元素唯一性: Zset中的每個元素都是唯一的,即使分數相同也可以存儲多個元素,但根據元素值來判斷唯一性。
-
支持范圍操作: Zset提供了一系列用于范圍操作的命令,例如根據排名獲取元素、根據分數范圍獲取元素等,可以方便地對Zset中的元素進行篩選和過濾。
-
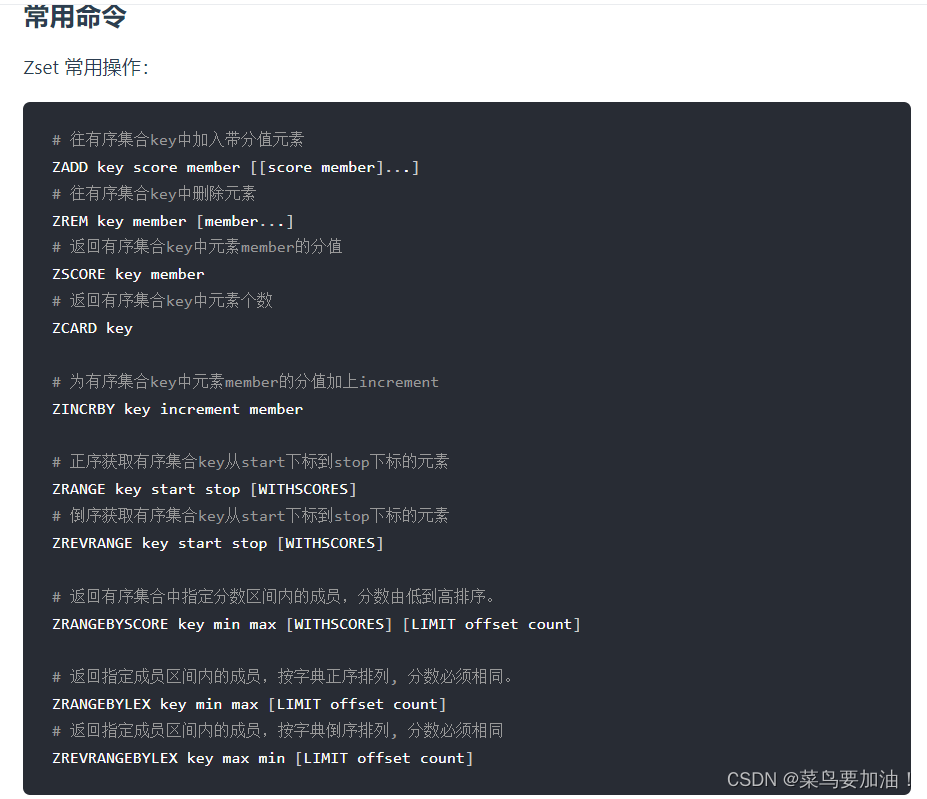
常見命令: Redis提供了一系列用于操作Zset的命令,包括:
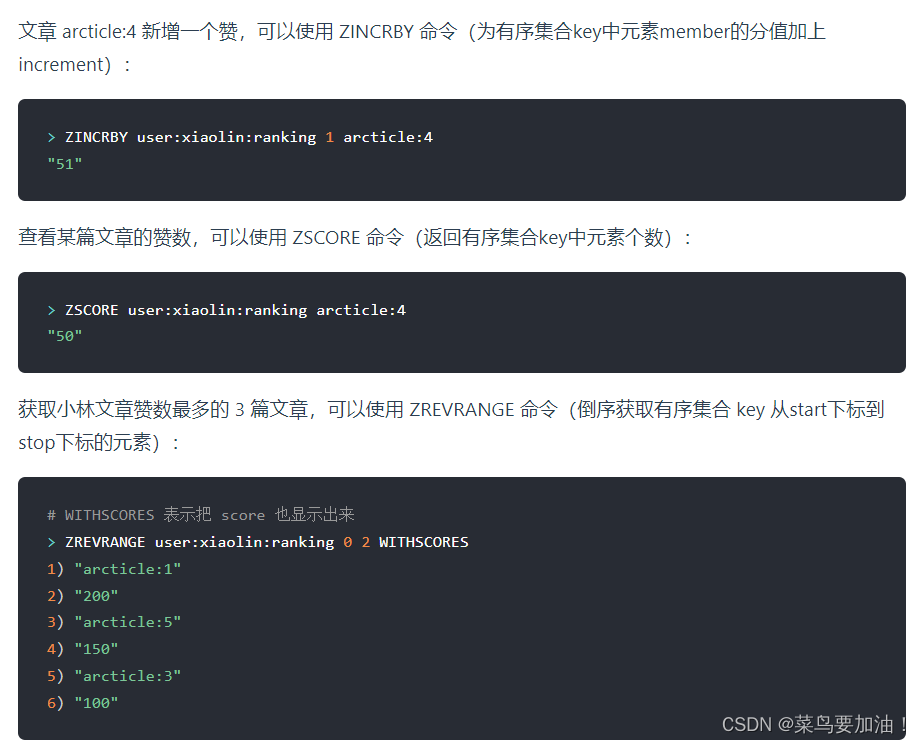
- ZADD:向Zset中添加一個或多個元素。
- ZSCORE:獲取指定元素的分數。
- ZRANK:獲取指定元素的排名。
- ZRANGE:根據排名范圍獲取元素列表。
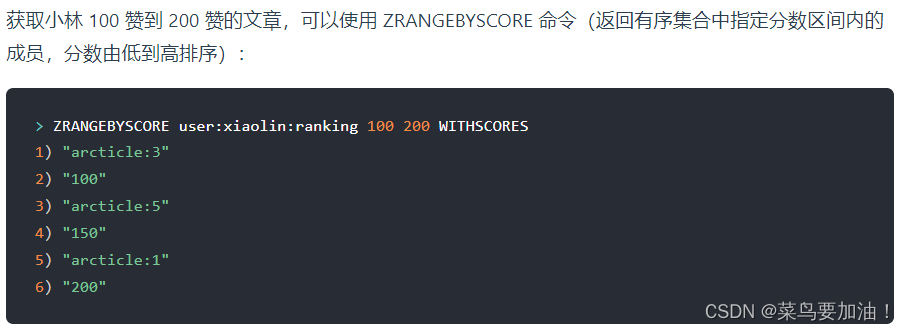
- ZRANGEBYSCORE:根據分數范圍獲取元素列表。
- 應用場景: Zset在Redis中有著廣泛的應用場景,例如排行榜、計分系統、事件調度等。它可以存儲帶有權重或者優先級的元素,并且可以根據分數來進行排序和過濾,非常適合于需要按照某種順序來處理元素的場景。



:滾動彈幕的設計與實現)














(三))
