
專欄介紹:YOLOv9改進系列 | 包含深度學習最新創新,主力高效漲點!!!
一、本文介紹
????????本文將以SE注意力機制為例,演示如何在YOLOv9種添加注意力機制!
?《Squeeze-and-Excitation Networks》
????????SENet提出了一種基于“擠壓和激勵”(SE)的注意力模塊,用于改進卷積神經網絡(CNN)的性能。SE塊可以適應地重新校準通道特征響應,通過建模通道之間的相互依賴關系來增強CNN的表示能力。這些塊可以堆疊在一起形成SENet架構,使其在多個數據集上具有非常有效的泛化能力。
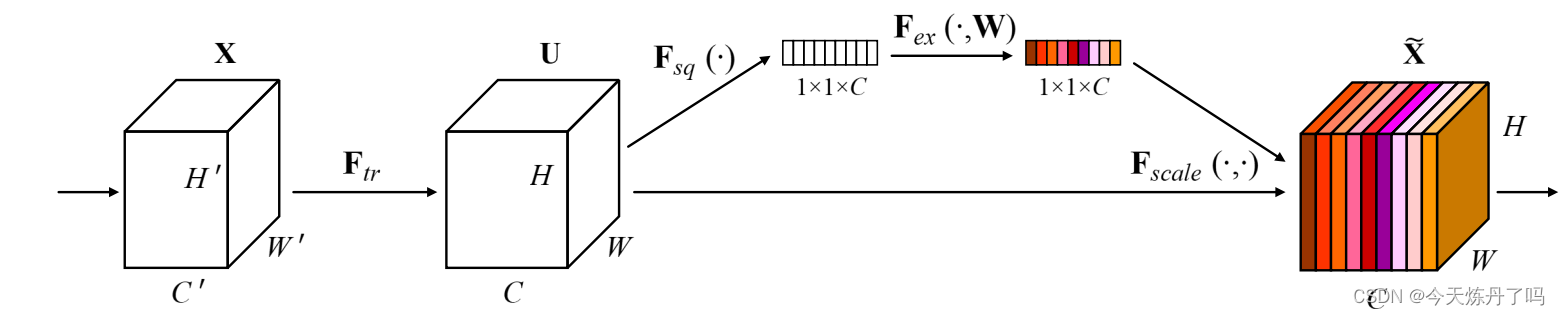
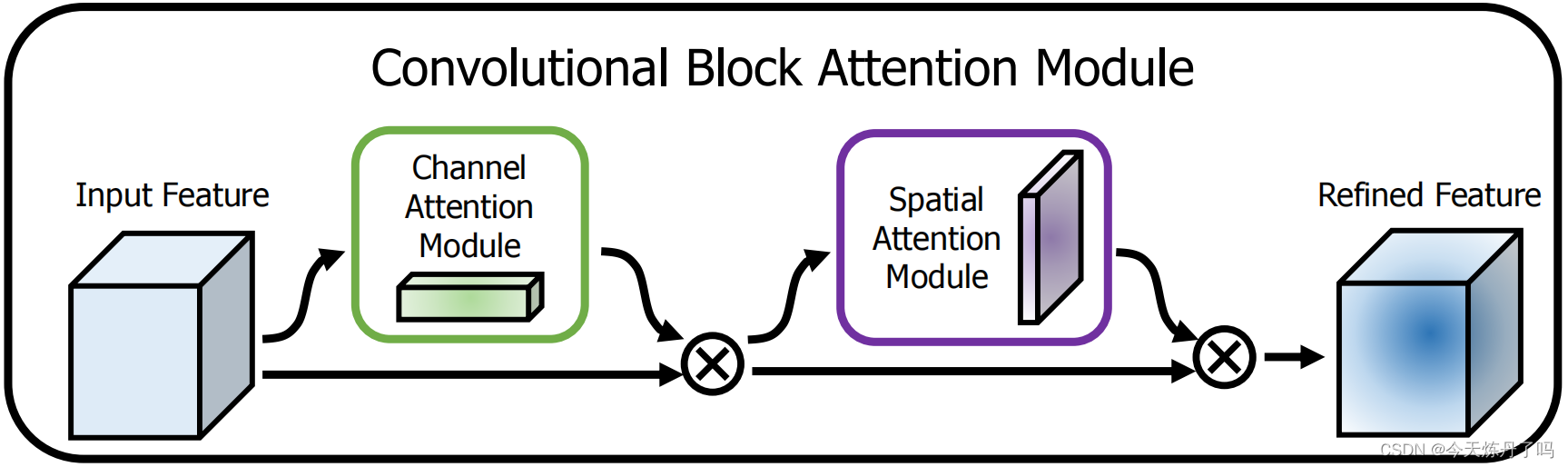
《CBAM:Convolutional Block Attention Module》
????????CBAM模塊能夠同時關注CNN的通道和空間兩個維度,對輸入特征圖進行自適應細化。這個模塊輕量級且通用,可以無縫集成到任何CNN架構中,并可以進行端到端訓練。實驗表明,使用CBAM可以顯著提高各種模型的分類和檢測性能。
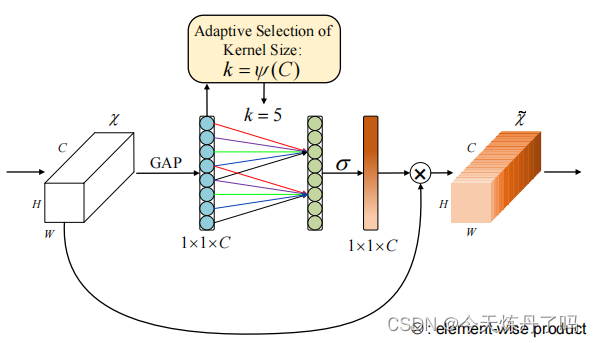
《ECA-Net:?Efficient?Channel?Attention?for?Deep?Convolutional?Neural?Networks》
????????通道注意力模塊ECA,可以提升深度卷積神經網絡的性能,同時不增加模型復雜性。通過改進現有的通道注意力模塊,作者提出了一種無需降維的局部交互策略,并自適應選擇卷積核大小。ECA模塊在保持性能的同時更高效,實驗表明其在多個任務上具有優勢。
《SimAM: A Simple, Parameter-Free Attention Module?for Convolutional Neural Networks》
????????SimAM一種概念簡單且非常有效的注意力模塊。不同于現有的通道/空域注意力模塊,該模塊無需額外參數為特征圖推導出3D注意力權值。具體來說,SimAM的作者基于著名的神經科學理論提出優化能量函數以挖掘神經元的重要性。該模塊的另一個優勢在于:大部分操作均基于所定義的能量函數選擇,避免了過多的結構調整。
 ?
?
適用檢測目標:? ?YOLOv9模塊通用改進
二、改進步驟
????????以下以SE注意力機制為例在YOLOv9中加入注意力代碼,其他注意力機制同理!
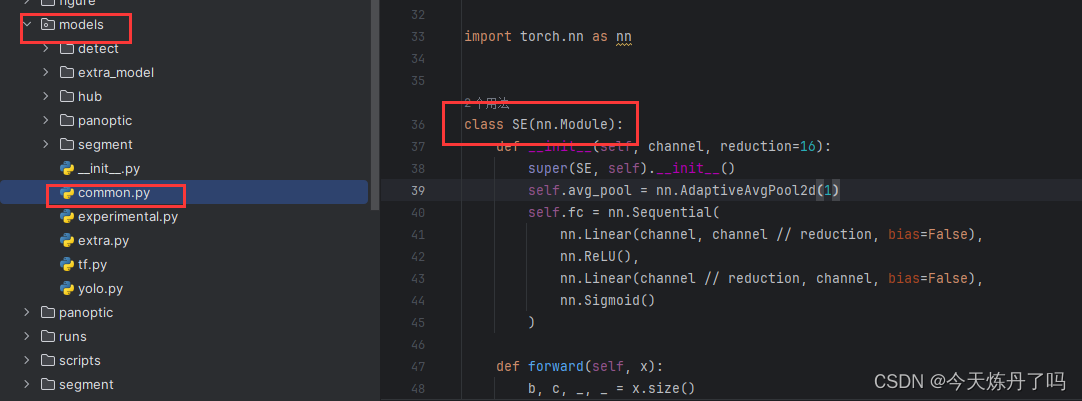
?2.1 復制代碼
????????將SE的代碼輔助到models包下common.py文件中。
?2.2?修改yolo.py文件
? ? ? ? 在yolo.py腳本的第700行(可能因YOLOv9版本變化而變化)增加下方代碼。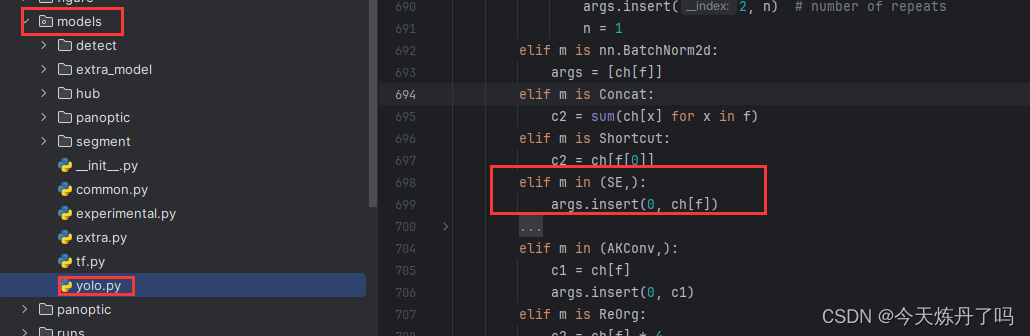
elif m in (SE,):args.insert(0, ch[f])2.3?創建配置文件
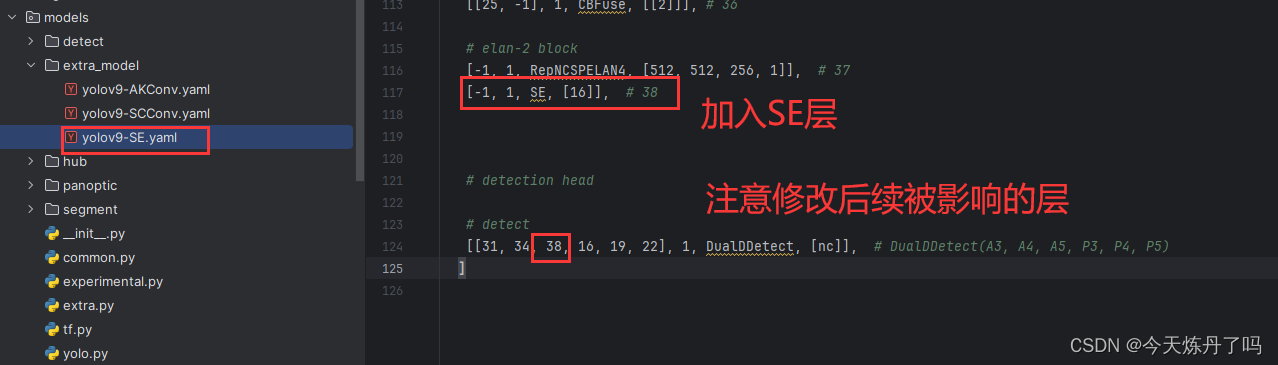
? ? ? ? 創建模型配置文件(yaml文件),將我們所作改進加入到配置文件中(這一步的配置文件可以復制models? - > detect 下的yaml修改。)。對YOLO系列yaml文件不熟悉的同學可以看我往期的yaml詳解教學!
YOLO系列 “.yaml“文件解讀-CSDN博客
# YOLOv9
# Powered bu https://blog.csdn.net/StopAndGoyyy
# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []], # conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# avg-conv down[-1, 1, ADown, [256]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# avg-conv down[-1, 1, ADown, [512]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# avg-conv down[-1, 1, ADown, [512]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)# avg-conv-down merge[-1, 1, ADown, [256]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)# avg-conv-down merge[-1, 1, ADown, [512]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)# multi-level reversible auxiliary branch# routing[5, 1, CBLinear, [[256]]], # 23[7, 1, CBLinear, [[256, 512]]], # 24[9, 1, CBLinear, [[256, 512, 512]]], # 25# conv down[0, 1, Conv, [64, 3, 2]], # 26-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 27-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28# avg-conv down fuse[-1, 1, ADown, [256]], # 29-P3/8[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31# avg-conv down fuse[-1, 1, ADown, [512]], # 32-P4/16[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34# avg-conv down fuse[-1, 1, ADown, [512]], # 35-P5/32[[25, -1], 1, CBFuse, [[2]]], # 36# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37[-1, 1, SE, [16]], # 38# detection head# detect[[31, 34, 38, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]
3.1?訓練過程
? ? ? ? 最后,復制我們創建的模型配置,填入訓練腳本(train_dual)中(不會訓練的同學可以參考我之前的文章。),運行即可。
YOLOv9 最簡訓練教學!-CSDN博客
??
 ??
??
SE代碼
class SE(nn.Module):def __init__(self, channel, reduction=16):super(SE, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)
CBAM代碼
class CBAMBlock(nn.Module):def __init__(self, channel=512, reduction=16, kernel_size=7):super().__init__()self.ca = ChannelAttention(channel=channel, reduction=reduction)self.sa = SpatialAttention(kernel_size=kernel_size)def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, _, _ = x.size()out = x * self.ca(x)out = out * self.sa(out)return outECA代碼
class ECAAttention(nn.Module):def __init__(self, kernel_size=3):super().__init__()self.gap = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2)self.sigmoid = nn.Sigmoid()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):y = self.gap(x) # bs,c,1,1y = y.squeeze(-1).permute(0, 2, 1) # bs,1,cy = self.conv(y) # bs,1,cy = self.sigmoid(y) # bs,1,cy = y.permute(0, 2, 1).unsqueeze(-1) # bs,c,1,1return x * y.expand_as(x)SimAM代碼
class SimAM(torch.nn.Module):def __init__(self, e_lambda=1e-4):super(SimAM, self).__init__()self.activaton = nn.Sigmoid()self.e_lambda = e_lambdadef __repr__(self):s = self.__class__.__name__ + '('s += ('lambda=%f)' % self.e_lambda)return s@staticmethoddef get_module_name():return "simam"def forward(self, x):b, c, h, w = x.size()n = w * h - 1x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5return x * self.activaton(y)
如果覺得本文章有用的話給博主點個關注吧!



#困難,想不到)






)








