目錄
- 一、引言
- 二、Java 8之前的ConcurrentHashMap
- 1、內部結構與初始化
- 2、Segment類
- 3、并發控制
- 4、擴容與重哈希
- 5、總結
- 三、Java 8中的ConcurrentHashMap
- 1、數據結構
- 2、并發控制
- 2.1. CAS操作
- 2.2. synchronized同步塊
- 3、哈希計算與定位
- 4、擴容與重哈希
- 5、總結
- 四、Java 17中的ConcurrentHashMap
- 1、數據結構
- 2、并發控制
- 3、哈希計算與定位
- 4、擴容與重哈希
- 5、其他改進和優化
- 五、總結
一、引言
在Java的并發編程中,ConcurrentHashMap以其出色的并發性能和數據一致性成為了眾多開發者的首選。從Java 5的引入至今,ConcurrentHashMap經歷了多次重大的改進和優化。本文將詳細深入全面地探討從Java 8之前到Java 17中ConcurrentHashMap的實現原理及其變化。
二、Java 8之前的ConcurrentHashMap
在Java 8之前,ConcurrentHashMap的實現原理主要基于分段鎖(Segmentation Lock)的機制,這種設計使得它能夠在高并發環境下提供良好的性能。以下是詳細的介紹:
1、內部結構與初始化
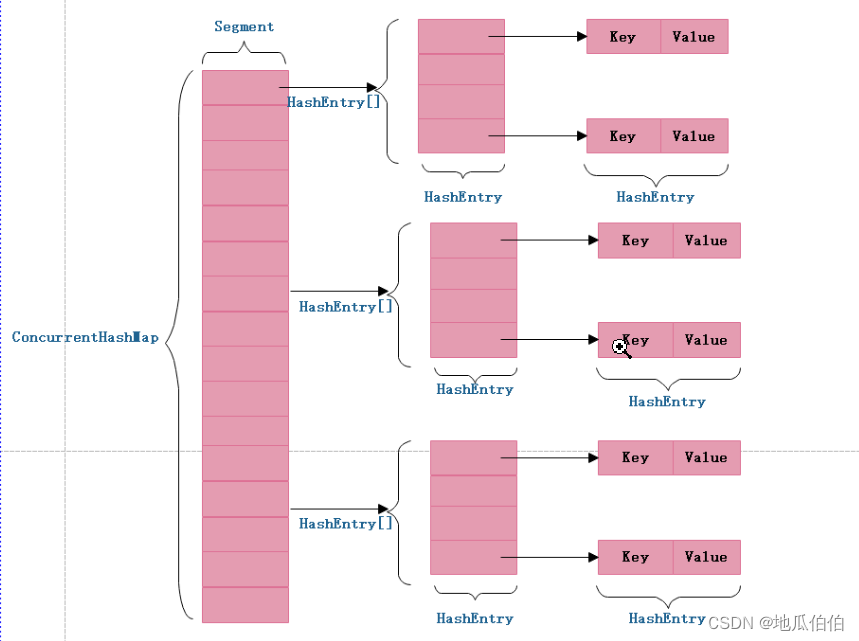
ConcurrentHashMap內部主要由三個組件構成:一個Segment數組、哈希函數和鍵值對節點。其中,Segment是一個可重入的互斥鎖,每個Segment包含一個哈希表,哈希表中的每個元素都是一個鏈表。
在初始化ConcurrentHashMap時,會創建一個Segment數組,并指定初始容量和負載因子。每個Segment的初始容量和負載因子與整個ConcurrentHashMap的相同。此外,還會為每個Segment分配一個鎖,用于控制對該Segment的并發訪問。
2、Segment類
Segment類是ConcurrentHashMap實現并發控制的核心。它繼承自ReentrantLock,擁有自己的鎖,并且包含一個哈希表。Segment類中的哈希表結構與普通的HashMap類似,采用鏈表解決哈希沖突。每個鏈表節點包含一個鍵值對和一個指向下一個節點的引用。
除了哈希表之外,Segment還維護了一些統計信息,如元素數量、修改次數等。這些信息用于支持擴容和迭代器操作。
3、并發控制
當線程需要訪問ConcurrentHashMap中的某個鍵時,它會首先計算鍵的哈希值,并根據哈希值的高位定位到對應的Segment。然后,線程會嘗試獲取該Segment的鎖。如果鎖已經被其他線程持有,則當前線程會等待直到獲取鎖為止。
一旦線程獲得Segment的鎖,它就可以在該Segment內部進行哈希表的查找、插入或刪除操作。這些操作與普通的HashMap類似,但需要在鎖的保護下進行以確保線程安全。完成操作后,線程會釋放鎖,使得其他線程有機會訪問該Segment。
需要注意的是,雖然每個Segment都有自己的鎖,但整個ConcurrentHashMap的并發性能并不完全取決于鎖的數量。實際上,鎖的競爭程度、哈希函數的分布性以及負載因子等因素都會對并發性能產生影響。
4、擴容與重哈希
當某個Segment的負載因子超過閾值時,會觸發擴容操作。擴容時,會創建一個新的Segment數組,并將原有Segment中的鍵值對重新散列到新的Segment數組中。這個過程涉及到大量的數據復制和重哈希計算。
為了減少擴容對并發性能的影響,ConcurrentHashMap采用了分段擴容的策略。它每次只處理一個Segment,并且在擴容過程中仍然允許其他線程訪問未處理的Segment。這樣確保了擴容操作不會阻塞整個ConcurrentHashMap的并發訪問。
此外,在擴容過程中,ConcurrentHashMap還采用了一種稱為“轉移策略”的技術來避免死鎖和饑餓問題。具體來說,當某個線程正在處理一個Segment時,如果該Segment需要擴容,那么擴容操作會由另一個線程來完成。這樣確保了處理線程不會因等待擴容而阻塞過長時間。
5、總結
Java 8之前的ConcurrentHashMap通過分段鎖的設計實現了高并發性能。它將哈希表劃分為多個段,并使用細粒度的鎖來控制對每個段的訪問。這種設計大大減少了鎖的競爭,提高了并發性能。然而,隨著Java版本的迭代和硬件性能的提升,分段鎖的設計逐漸暴露出一些問題,如內存占用較大、擴容操作復雜等。
三、Java 8中的ConcurrentHashMap
在Java 8中,ConcurrentHashMap的實現原理發生了顯著的變化,它摒棄了之前版本中的分段鎖(Segmentation Lock)機制,轉而采用了一種更為高效和靈活的并發控制策略,即CAS(Compare-and-Swap)操作結合synchronized同步塊。這種新的設計不僅簡化了數據結構,還提高了在多核處理器環境下的并發性能。
1、數據結構
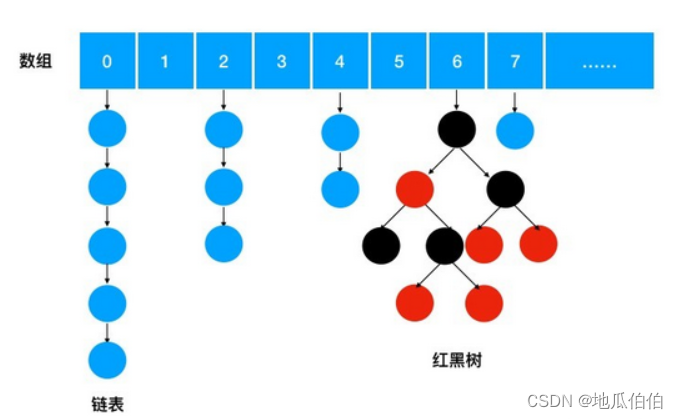
Java 8中的ConcurrentHashMap底層數據結構主要由數組、鏈表和紅黑樹組成。數組用于存儲鍵值對的節點,每個節點要么是一個鏈表,要么是一個紅黑樹。當鏈表長度超過一定閾值(默認為8)時,鏈表會轉換為紅黑樹,以提高搜索效率。
2、并發控制
2.1. CAS操作
CAS(Compare-and-Swap)是一種無鎖化的算法,它包含三個操作數——內存位置(V)、預期原值(A)和新值(B)。如果內存位置V的值與預期原值A相匹配,那么處理器會自動將該位置的值更新為新值B。否則,處理器不做任何操作。無論哪種情況,它都會在CAS指令之前返回該位置的值。在ConcurrentHashMap中,CAS操作被廣泛應用于節點的添加、刪除和更新等場景,以確保并發修改的安全性。
2.2. synchronized同步塊
盡管CAS操作能夠在很大程度上減少鎖的競爭,但在某些情況下,仍然需要更嚴格的同步機制來保證并發操作的正確性。因此,Java 8中的ConcurrentHashMap在必要時會使用synchronized同步塊來保護某些關鍵代碼段,如樹化操作、擴容等。與分段鎖相比,synchronized同步塊具有更低的開銷和更高的靈活性。
3、哈希計算與定位
與之前的版本類似,Java 8中的ConcurrentHashMap也使用哈希算法來計算鍵的哈希值,并根據哈希值來定位數組中的索引位置。不同的是,Java 8中的哈希計算過程更加復雜和精細,以減少哈希沖突和提高空間利用率。此外,當發生哈希沖突時,新的鍵值對會添加到鏈表或紅黑樹的末尾,而不是像之前版本那樣使用頭插法。
4、擴容與重哈希
當ConcurrentHashMap中的元素數量超過數組的容量閾值時,就會觸發擴容操作。在擴容過程中,會創建一個新的數組,并將原有數組中的鍵值對重新散列到新的數組中。與之前的版本不同,Java 8中的擴容操作不再需要對整個數組進行鎖定,而是采用了更細粒度的并發控制策略。具體來說,它將數組劃分為多個小段(每個小段包含多個桶),并允許多個線程同時處理不同的小段。這樣設計可以減少鎖的競爭和提高擴容操作的并發性能。
5、總結
Java 8中的ConcurrentHashMap通過采用CAS操作結合synchronized同步塊的并發控制策略以及優化后的數據結構和哈希算法等技術手段實現了高并發性能下的線程安全訪問。與之前的版本相比,它在簡化數據結構、提高空間利用率和降低鎖競爭等方面取得了顯著的進步。這些改進使得ConcurrentHashMap成為Java并發編程中不可或缺的重要組件之一。
四、Java 17中的ConcurrentHashMap
在Java 17中,ConcurrentHashMap的實現原理基本保持了Java 8引入的設計,但可能包含了一些優化和改進,以適應新的JDK版本和硬件環境。以下是Java 17中ConcurrentHashMap實現原理的深入介紹:
1、數據結構
與Java 8相似,Java 17中的ConcurrentHashMap也使用了數組、鏈表和紅黑樹作為底層數據結構。數組用于存儲鍵值對的節點,每個節點在哈希沖突時形成鏈表,當鏈表長度超過一定閾值(默認為8)并且數組長度大于64時,鏈表會轉換為紅黑樹,以提高搜索效率。如果數組長度小于等于64,則不會進行樹化,而是采用擴容來減少哈希沖突。
2、并發控制
Java 17中的ConcurrentHashMap仍然采用CAS操作和synchronized同步塊來實現并發控制。CAS操作用于無鎖化的節點添加、刪除和更新等操作,而synchronized同步塊則用于保護樹化、擴容等需要更嚴格同步的代碼段。
不過,在Java 17中,JDK可能對這些操作進行了進一步的優化,以減少不必要的CAS操作和鎖競爭,提高并發性能。例如,通過更精細的粒度控制synchronized同步塊的范圍,或者使用更高效的鎖實現等。
3、哈希計算與定位
Java 17中的ConcurrentHashMap哈希計算過程與Java 8類似,但可能包含了一些針對新硬件環境的優化。哈希值用于定位數組中的索引位置,當發生哈希沖突時,新的鍵值對會添加到鏈表或紅黑樹的末尾。
此外,Java 17中的ConcurrentHashMap可能還引入了一些新的哈希算法或哈希沖突解決策略,以進一步減少哈希沖突和提高空間利用率。
4、擴容與重哈希
當ConcurrentHashMap中的元素數量超過數組的容量閾值時,會觸發擴容操作。在Java 17中,擴容操作的基本原理與Java 8相似,即創建一個新的數組,并將原有數組中的鍵值對重新散列到新的數組中。然而,Java 17可能對擴容過程中的并發控制、數據遷移等方面進行了優化和改進。
例如,通過更細粒度的并發控制策略來減少鎖的競爭;使用更高效的數據遷移算法來減少擴容過程中的性能開銷;或者引入一些新的技術手段來提高擴容操作的并發性能和可靠性等。
5、其他改進和優化
除了上述基本原理外,Java 17中的ConcurrentHashMap還包含一些其他改進和優化:
- 更好的內存布局和緩存利用:通過優化數據結構的內存布局和訪問模式,提高緩存利用率和減少內存訪問開銷。
- 更高效的節點操作:通過優化節點的添加、刪除和更新等操作,減少不必要的內存分配和垃圾回收開銷。
- 更靈活的參數配置:提供更多的參數配置選項,以便用戶根據具體應用場景進行更精細的性能調優。
- 更完善的錯誤處理和異常處理機制:增強錯誤處理和異常處理能力,提高程序的健壯性和可靠性。
總之,在Java 17中,ConcurrentHashMap仍然是一個高性能、線程安全的并發哈希表實現,它在數據結構、并發控制、哈希計算與定位以及擴容與重哈希等方面都進行了深入的設計和優化。
五、總結
從Java 8之前到Java 17,ConcurrentHashMap經歷了顯著的演進。Java 8之前的版本采用分段鎖機制實現并發控制;Java 8引入了紅黑樹和更細粒度的鎖策略來優化性能;而Java 17在保持Java 8基本設計的同時,對并發控制和內部實現進行了進一步的優化和改進。這些變化使得ConcurrentHashMap在并發性能、內存開銷和穩定性等方面不斷得到提升和完善。作為Java并發編程中的重要組成部分,ConcurrentHashMap的演進歷程反映了Java平臺對并發性能和穩定性的持續追求和提升。在未來的Java版本中,我們可以期待更多的優化和改進,以滿足不斷增長的并發編程需求。








)

及其常見組件)





)


