目錄
一、數據倉庫概述
(一)從傳統數據庫到數據倉庫
(二)數據倉庫的4個特征
(三)數據倉庫系統
(四)數據倉庫系統體系結構
(五)數據倉庫數據的粒度與組織
二、數據挖掘概述
(一)數據挖掘產生的背景
(二)數據挖掘與知識發現
(三)數據挖掘的數據來源
(四)數據挖掘的任務
(五)數據挖掘的步驟
(六)數據挖掘的應用
三、數據倉庫與數據挖掘的關系
(一)數據倉庫與數據挖掘的區別
(二)數據倉庫與數據挖掘的聯系
一、數據倉庫概述
(一)從傳統數據庫到數據倉庫
????????一般來說,計算機數據處理有兩種主要方式:事務型處理和分析型處理。
1、傳統數據庫與事務處理
(1)傳統數據庫(DataBase,簡稱DB)是長期存儲在計算機內的、有組織的、可共享的數據集合。
(2)應用廣泛:有嚴格的數學理論支持,并在商業領域得到普及應用,長盛不衰,至今枝繁葉茂。
(3)聯機事務處理(On-Line Transaction Processing)系統,簡稱 OLTP 系統。財務管理和超市管理系統等,數據存儲在傳統數據庫中,因此又稱為 OLTP 數據庫。
(4)處理特點:對傳統數據庫進行聯機的日常操作,如對一個或一組記錄的查詢和修改等存取操作,用戶希望每次操作能夠實時響應,并保證數據安全性和完整性。
2、傳統決策支持與分析處理
(1)數據的分析處理:對當前和大量歷史數據的統計和分析,并從中提取管理決策所需重要信息的數據處理方法。
(2)決策支持系統(Decision Support System,DSS):對數據進行分析處理任務的計算機系統;
(3)決策支持:將決策支持系統分析所得到數據信息,提供給企事業董事會或主管領導決策參考的過程。
(4)分析型處理系統:決策支持系統的別名,通常需要對大量歷史數據進行長時間的分析處理。
(5)處理特點:用戶對分析處理的時間長短不在意,而對數據分析的深度和廣度,以及分析結果的使用價值非常重視。
(6)早期分析處理系統開發:在事務處理系統中,直接增加一些統計分析軟件或決策支持程序。
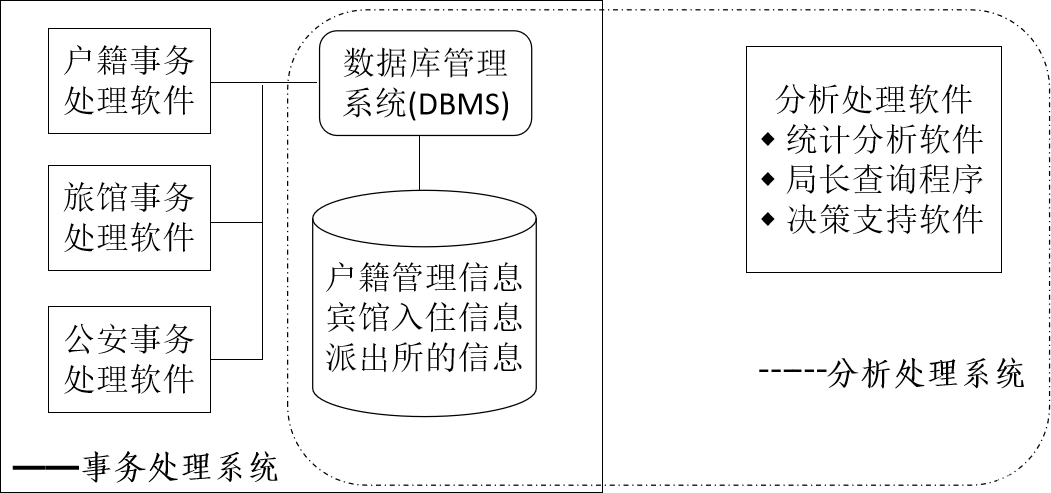
3、傳統分析處理的問題
(1)分析處理的系統響應問題:事務處理的實時響應修改需求(排它鎖)與決策分析需要長時間遍歷數據庫中大部分甚至全部數據(共享鎖)有很大沖突。
(2)分析處理的數據需求問題
① 外部數據需求問題:甚至包括競爭對手的相關數據,但傳統數據庫中只存儲了部門內部的事務處理數據。
② 系統平臺差異問題:決策分析的數據通常來自多個處理系統,必須解決不同數據處理系統的差異性問題。
③ 數據不一致性問題:多個處理系統相同屬性的取值類型或長度不一致。
????????● 性別屬性值有的用 “1” 和 “0” ,有的用邏輯值 T 和 F ,還有用字符串 “男” 和 “女” 表示。
????????● 屬性名 PCS 表示派出所,有的使用 ZZPCS 來表示等。
④ 非結構化數據問題:決策分析處理的數據集成過程中涉及行業統計報告、咨詢公司的市場調查分析數據,其格式可能是 Excel,Word 或者 Web 頁面等。
⑤ 歷史數據需求問題:決策分析處理需要較長時期的歷史數據,而傳統數據庫一般只保留當前或近期的數據。
⑥ 數據動態更新問題:決策分析處理需要不斷的增加最近幾個月,但傳統的分析處理系統在對數據進行一次集成以后,往往就與原來的數據源斷絕了聯系。
(3)分析處理的多樣性問題:決策分析人員希望能夠利用各種工具對數據進行多種方式的處理,并希望數據處理的結果能以商業智能的方式表達出來,不僅要便于理解,而且能有力地支持決策。?傳統分析處理系統很難,甚至無法實現這種需求。
(4)操作型數據與分析型數據的區別
| 對比內容 | 操作型數據(原始的) | (導出的)分析型數據 |
|---|---|---|
| 數據粒度 | 實時細節 | 綜合集成 |
| 數據內容 | 當前和近期的數據 | 歷史的、計算的數據 |
| 數據特性 | 可以修改 | 不可修改,定時添加 |
| 數據組織 | 面向事務應用 | 面向主題分析 |
| 數據用量 | 一次操作數據量小 | 一次操作數據量大 |
(5)操作型系統與分析型系統的區別
● SDLC(Systems Development Life Cycle)稱為系統開發生命周期,即操作型系統遵循 “需求調查需求分析
設計&編程
系統測試
系統集成
系統實施” 。 ?
● Inmon 認為,分析型系統開發周期 CLDS(Reverse of SDLC)是 SDLC 逆過程,即 “ DW 實施數據集成
偏差測試
針對數據編程
設計 DSS 系統
結果分析
理解需求” 的螺旋式開發過程。但我們從實際應用中發現,還是要進行一定的前期需求調查和系統設計,才能開始 DW 實施。
3、事務處理與分析處理系統的分離
????????正是兩者存在很大的不同,甚至相互沖突,人們認識到應該將事務處理系統的數據抽取出來,構建一個不受傳統事務處理約束、獨立而高效率的數據分析處理系統。
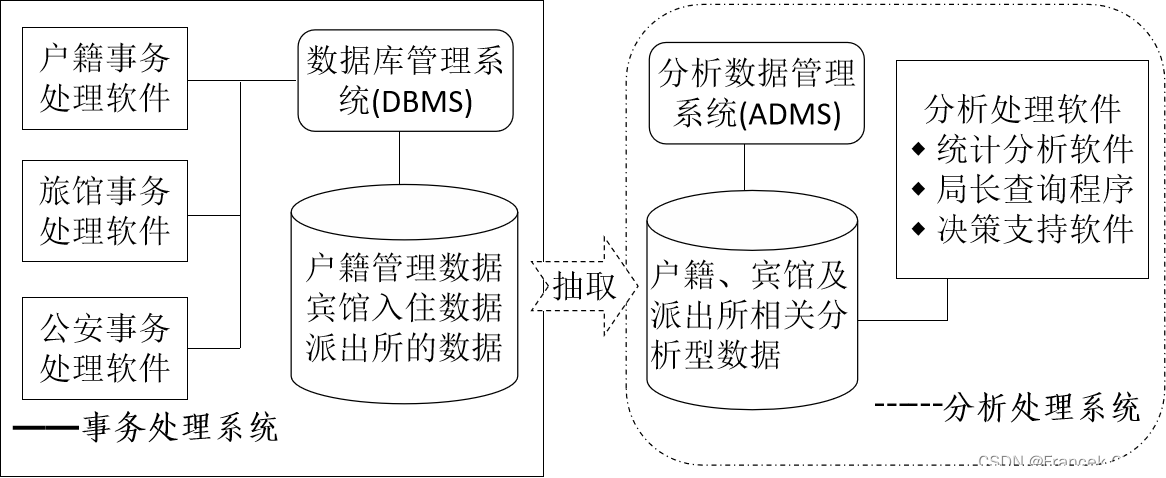
????????ADMS 是什么、有啥功能等? 這就是數據倉庫原理、OLAP(On Line Analytic Processing)技術和數據挖掘技術等將要介紹的內容。
4、數據倉庫的定義
????????美國著名信息工程學家 William H. Inmon 教授,因1993年出版的專著《建立數據倉庫》被世人譽為數據倉庫之父。
定義1-1(Inmon):數據倉庫(Data Warehouse,DW)是一個面向主題的(Subject Oriented)、集成的(Integrated)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的,支持管理決策(Decision Making Support)的數據集合。 ? ?以上定義被廣泛引用稱為經典,但初學者理解困難。
定義1-2(H):數據倉庫是一個面向主題的、集成的、不可修改的、隨時間變化的,支持管理決策的數據集合。 因此可以說,數據倉庫是一個特殊的數據庫,其特殊性體現在它的數據具有面向主題、集成、不可修改和隨時間變化等4個特征,其目的是支持企業的管理決策而不是支持事務管理。
(二)數據倉庫的4個特征
1、數據倉庫的數據是面向主題的
定義1-3:主題是宏觀決策問題的一個分析對象,它由決策分析問題的要求來確定,并用一個在較高管理層次上的綜合數據集合來描述。
(1)從信息管理的角度看,主題是在一個較高管理層次上對數據庫系統中數據,按照具體的管理要求重新綜合、歸類的分析對象。
(2)從數據組織的角度看,主題就是一個數據集合,這些數據對分析對象進行了比較完整、一致的描述,不僅描述了數據自身,還描述了數據之間的關系。
定義1-4:主題是一個在較高管理層次上描述決策分析問題的綜合數據集合。
????????比如,“旅館入住人次”就是警務管理者的一個決策分析對象,因此,“旅館入住人次”或“旅館入住”就是警務數據倉庫的一個主題,它需要一個數據集來描述它。
2、數據倉庫的數據是集成的
(1)數據集成:根據決策分析的主題需要,把多個異種數據源中的數據收集起來形成一個統一并且一致的數據集合的過程。
(2)數據 ETL(Extract-Transform-Load,抽取-轉換-加載):對數據源數據進行抽取、清理、轉換和加載到DW的過程。
(3)ETL 的目的:確保數據倉庫數據在屬性名稱、屬性值度量等方面完全一致性。
(4)ETL 主要有兩個任務:
????????① 消除數據源中所有矛盾之處,如字段的同名異義、異名同義、單位不統一、字長不一致等。
????????② 對數據進行綜合計算。比如,把每分中的數據匯總為每天的數據等。
3、數據倉庫的數據是不可修改的
????????數據倉庫的數據都是從事務處理數據源抽取過來的歷史數據,因而是不可以修改的,且基于數據倉庫的決策分析只有讀操作而沒有修改操作。
4、數據倉庫的數據是隨時間變化的
主要體現在以下3方面:
(1)數據倉庫隨時間變化不斷增加新的數據內容。
(2)數據倉庫隨時間變化不斷刪去舊的數據內容。
(3)數據倉庫中包含有大量的綜合數據,且隨著時間要求的變化而不斷變化。
數據倉庫定義的內涵:1個集合,4個特征,1個目的。
(三)數據倉庫系統
定義1-5:數據倉庫管理系統(Data Warehouse Manage-ment System,簡稱DWMS)是位于用戶與操作系統(OS)之間的一層數據分析管理軟件,負責對數據倉庫數據進行統一更新、管理和使用控制,為用戶和應用程序提供訪問數據倉庫的方法或接口軟件的集合。
????????微軟、Oracle 等已在自己的商品化關系數據庫管理系統(RDBMS)產品中,增加并集成了與 DW 相關的管理控制軟件,即 DBMSDWMS ,或者 RDBMS
RDWMS 。
定義1-6:數據倉庫系統(Data Warehouse System,簡稱 DWS )是計算機系統、DW 、DWMS 、應用軟件、數據庫管理員和用戶的集合。
????????因此,數據倉庫系統一般由硬件、軟件(包括開發工具)、數據倉庫、數據倉庫管理員等構成。
(四)數據倉庫系統體系結構
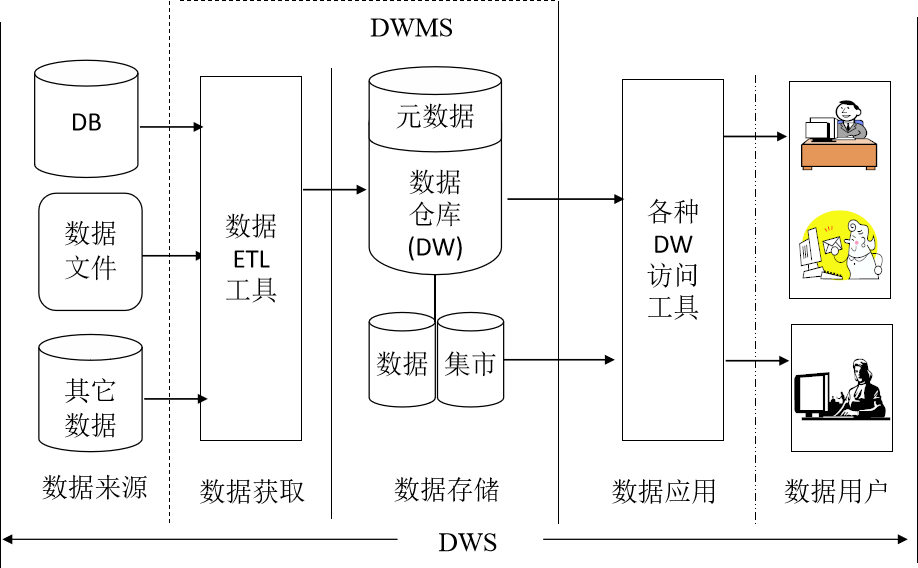
1、數據來源?
????????數據倉庫系統的數據源,包括內部的 OLTP 數據庫、OA 數據和外部的市場信息、競爭對手信息,以及政府統計數據和其它有關文檔。
2、數據獲取
????????從數據源中抽取數據,集成數據,預處理后轉換成數據倉庫對應的數據格式,并將其加載到數據倉庫之中。
3、數據管理
????????對數據倉庫數據,元數據和數據集市的存儲管理,包括數據存儲、數據的安全性、一致性和并發控制管理、以及數據的維護、備份和恢復等管理功能,由 DWMS 負責。
(1)(企業級)數據倉庫:包含從企業所有可能的數據源抽取得到的明細數據和匯總數據。
(2)數據集市(Data Mart,DMt)是企業級數據倉庫的一個子集,通常稱之為部門級數據倉庫。?
(3)元數據(Meta Data):“關于數據的數據”,即描述其它數據的基礎數據。按其用途可將分為兩種類型。
????????① 技術元數據(Technical Metadata):是關于數據源、數據轉換和數據倉庫的描述,如數據對象和數據結構的定義、數據清理和數據更新的規則、元數據到目的數據的映射、用戶訪問權限等。供數據倉庫設計和管理人員使用,又稱為管理元數據(Administrative Metadata)。
????????② 商業元數據(Business Metadata):用商業術語描述數據倉庫中的數據,包括對業務主題、數據來源和數據訪問規則,各種分析方法及報表展示形式的描述,以便使數據倉庫管理人員和用戶更好地理解和使用數據倉庫。也被稱為用戶元數據(User Metadata)。
(4)元數據的作用
????????① 為決策支持系統分析員和高層決策人員服務提供便利。如廣義索引(元素據)存放的有關決策匯總數據項。
????????② 解決操作型環境和數據倉庫的復雜映射關系。如數據源的項名、屬性及其在數據倉庫中的轉換。
(5)元數據的使用
????????① 元數據在數據倉庫開發期間的使用。元數據主要描述 DW 目錄表的每個運作模式,數據的轉化、凈化、轉移、概括和綜合的規則與處理規則。
????????② 元數據在數據源抽取中使用。利用元數據確定將數據源的哪些資源加載到 DW 中;跟蹤歷史數據結構變化過程;描述屬性到屬性的映射、屬性轉換等。
????????③ 元數據在數據清理與綜合中的使用。數據清理與綜合負責凈化資源中的數據、增加資源戳和時間戳,將數據轉換為符合數據倉庫的數據格式,計算綜合數據的值。
4、數據應用
????????通過數據分析工具、數據挖掘工具和其它應用程序來使用 DW 中的數據。數據倉庫技術本身并不提供對數據倉庫進行分析的技術和工具,用戶一般可以根據需要,自行開發或委托軟件公司開發合適的決策分析工具。
5、數據用戶
????????企業中高層管理者和決策分析人員。正是因為有了使用它的用戶,數據倉庫才真正體現出它的價值。
(五)數據倉庫數據的粒度與組織
1、數據的粒度
????????數據倉庫的數據單元中所保存數據的綜合程度。數據的綜合程度越高,其粒度也就越粗。反之,數據的綜合程度越低,其粒度也就越細。數據粒度越細,則占用的存儲空間越大,但可以提供豐富的細節查詢,反之,占用存儲空間小,卻只能提供粗略的查詢。
????????數據的粒度選擇是否恰當,不僅對數據倉庫中數據量的大小有直接影響,同時還影響數據倉庫所能回答的查詢類型和查詢深度。在數據倉庫設計時,數據粒度的大小需要依據數據量的大小與查詢的詳細程度之間做出權衡。
2、雙重粒度
????????指數據倉庫中僅存放真實細節數據(最低粒度)和輕度的綜合數據。
3、數據倉庫數據的粒度層級
????????在數據倉庫設計時,通常可以將數據按照3重粒度級別4個層次的存儲方式,即將數據分為早期細節層、當前細節層、輕度綜合層、高度綜合層等4個層級。數據源經過最低粒度級別的綜合進入當前細節層,并根據具體需要進行更高一層的綜合,從而形成輕度綜合層乃至高度綜合層的數據。
? ? ? ? 如下圖所示,數據倉庫數據的粒度層級示例。

4、數據倉庫的數據組織
(1)簡單堆積文件:將每日從 OLTP 數據庫中提取轉換加工得到的數據逐天積累存儲起來形成一個數據文件(左)。
(2)輪轉綜合文件。數據存儲單位被分為日、周、月、年等幾個粒度級別(右)。
 ? ? ? ?
? ? ? ?
二、數據挖掘概述
(一)數據挖掘產生的背景
????????信息化社會產生出海量的數據,并形成具有巨大潛在價值的 “大數據” ,猶如蘊藏大量 “黃金白銀” 的礦山。信息提取及其處理技術的相對落后,使世界陷入了 “數據豐富、知識貧乏” 的境地。
????????1989年第11屆國際聯合人工智能學術會議上首次提到數據庫中的知識發現(Knowledge Discovery in database,KDD)的概念。它把數據庫 “數據” 比喻為礦山,將 “數據挖掘(Data Mining,DM)” 作為開采工具,因此,“數據挖掘” 一詞很快流傳開來,成為信息技術領域的研究熱點。
????????數據挖掘和知識發現作為一種知識自動提取技術,涉及機器學習、模式識別、統計學、數據庫和人工智能等眾多學科領域,以及信息技術的支撐。
(二)數據挖掘與知識發現
定義1-7:知識發現(KDD)就是采用有效算法從大量的、不完全的、有噪聲的、模糊和隨機的數據中識別出有效的、新穎的、潛在有用乃至最終可理解的模式(Patterns)的非平凡過程。
例1-1 在20世紀90年代某日,美國加州一個超級連鎖店通過數據挖掘,從記錄著每天銷售和顧客基本情況的數據庫中發現,下班以后來購買嬰兒尿布的顧客多數是男性,他們往往也同時購買啤酒。于是這個連鎖店的經理當機立斷,立即重新布置了商場貨架,把啤酒類商品布置在嬰兒尿布貨架附近,并在二者之間放上土豆片之類的佐酒小食品,同時把男士們需要的日常生活用品也就近布置。這樣一來,使上述幾種商品的銷量幾乎馬上成倍增長。 啤酒銷量與尿布銷量居然有關聯!確實是新穎非平凡的。
(三)數據挖掘的數據來源
1、數據庫類型的數據
(1)傳統數據庫(DB)是數據挖掘最常見、最豐富的數據來源之一。
(2)數據倉庫(DW):從多個數據源,經過抽取-轉化-集成(ETL)后加載到數據庫中,用于支持管理決策的數據集合。
(3)空間數據庫(Spatial Database),如地理信息數據、遙感圖像數據等。
(4)時態數據庫和時間序列數據庫(Temporal Database and Time-Series Database)。
????????① ?時態數據庫通常存放與時間相關的屬性值,如個人簡歷信息與時間相關的職務、工資等個人信息。
????????② ?時間序列數據庫存放隨時間變化的值序列,如股票交易數據、氣象觀測數據等。
(5)多媒體數據庫(Multimedia Database)。存儲有圖形(Graphics)、圖像(Image)、音頻(Audio)、視頻(Video)等。
(6)文本數據庫(Text Database),包括無結構類型(大部分的文本資料和網頁)、半結構類型(XML數據)、結構類型(如關系數據庫),OA 系統使用文本數據庫。
2、非數據庫類型數據
(1)數據流(Data Stream):大量、高速、連續到達的,潛在無限的有序序列數據。如網絡監控、網頁點擊流、股票交易、流媒體和傳感器網絡等產生的數據。
????????① 數據處理特點:數據一經處理,除非特意保存,否則不能被再次讀取處理,或再次讀取數據的代價十分昂貴。
????????② ?數據流處理的實時性要求,是它與傳統數據庫在存儲、查詢、訪問等方面的最大區別。
(2)Web數據:互聯網上的數據。
????????互聯網上的部分數據存儲在數據庫之中,但更多的數據并不是存儲在數據庫之中,故將Web數據作為非數據庫類型。?
(四)數據挖掘的任務
1、分類分析(Classification Analysis)
(1)通過分析已知類別標記的樣本集合(示例數據庫)中的數據對象(記錄),為每個類別做出準確的描述,或建立分類模型,或提取出分類規則(Classification Rules);
(2)然后用這個分類模型或規則對樣本集合以外的記錄進行分類。
????????比如:銀行或移動通信公司,首先從現有已知類別的客戶信息中提取分類規則,然后應用分類規則去判斷新客戶可能的類別。
例1-2 設有3個屬性4條記錄的數據庫,它記錄了顧客前來商店咨詢電腦事宜,以及顧客身份和年齡的信息,其中 “電腦” 屬性標記了一個顧客咨詢結束后買了電腦,或者沒買就直接離開商店了。

(1)分類分析:用某種分類算法對表中數據進行分析,挖掘出兩條分類規則。
????????① If 學生=是 或者 年齡段≥41歲 then買了電腦;
????????② If 學生=否 而且 年齡段=31~40 then沒買電腦;
(2)規則應用:假設商店來了一個新顧客咨詢電腦事宜,老板也詢問他是不是學生、年齡和收入情況,得知此人基本信息為(學生=否,年齡=44歲,收入=一般)
????????因此,老板應用規則①預測此人是誠心買電腦的顧客,就會在接待和介紹產品過程中有更多些的耐心和關心,并可能最終促成顧客購買電腦。
2、聚類分析(Clustering Analysis)
????????根據給定的某種相似性度量標準,將沒有類別標記的數據庫記錄集劃分成若干個不相交的子集(簇),使簇內的記錄之間相似度很高,而不同簇的記錄之間相似度很低。
????????聚類分析可以幫助我們判斷,數據庫中記錄劃分成什么樣的簇更有實際意義,在客戶細分、定向營銷、信息檢索等領域廣泛應用。
例1-3 設有記錄了4個顧客3個信息的數據庫。

????????試用某種相似性度量標準,將記錄進行聚類分析。
解:由于沒有指定具體的相似度標準,因此,我們根據表1-4的屬性,可以考慮選擇幾個不同的標準來進行聚類分析,并對結果進行比較。
(1)以是否為 “學生” 為相似度標準,則4條記錄可聚成2個簇 ? ? ? ? ? ?
A學生={X1,X4}, B非學生={X2,X3};
(2)以顧客的年齡段作為相似度標準,則4條記錄可聚成3個簇 ? ? ? ? ? ?
A≤30歲={X2},B31~40={X1,X3}, C≥41歲={X4};
(3)以收入水平作為相似度標準,則4條記錄可聚成2個簇
A一般={X1,X2,X4},B較好={X3};
????????由此例可以看出:
????????① ?聚類分析是對顧客集合的一個劃分。
????????② ?對一個給定顧客數據庫,如果相似性度量標準不同,則劃分結果也不同,即聚類算法對相似性度量標準是敏感的。
????????③ 可選擇不同的度量標準對數據庫記錄進行聚類分析,以期得到更加符合實際工作需要的聚類結果。
????????聚類與分類是容易混淆的兩個概念:? ?
????????① 分類問題是有指導的示例式學習,即每個記錄預先給定了類別標識,分類分析就是找出每個類別標識的描述,即滿足什么條件的記錄就一定是什么類別的判斷規則。
????????② ?聚類問題是一種無指導的觀察式學習.每個記錄沒有預先定義的類別標識,聚類分析就是給每個記錄指定一個類別標號。
3、關聯分析(Association Analysis)
????????關聯分析最初是針對購物籃分析問題而提出的,其目的是發現交易數據庫中商品之間的相互聯系的規則,即關聯規則(Association rules)。 關聯分析主要用于市場營銷、事務分析等領域。
????????在超市交易數據庫中發現了 “啤酒與尿布” 之間的關聯規則(例1-1),就是關聯分析成功的一個典型例子。
4、序列模式(Sequential Patterns)
????????數據間的前后序列關系,包括相似模式發現、周期模式發現等,主要應用于客戶購買行為模式預測、疾病診斷、防災救災、Web 訪問模式預測和網絡入侵檢測等領域。
????????比如,“顧客今天購買了商品 A,則隔不了幾天他就會來購買商品B” ,就是顧客購物方面的一種序列模式。
5、離群點檢測(Outlier detection)
????????離群點(Outlier)是一個數據集中過分偏離其它絕大部分數據的特殊數據。離群點檢測就是希望從數據集中發現這種與眾不同的數據,已在銀行、保險、電信、電子商務等行業的欺詐行為檢測中得到廣泛應用,比如銀行的反洗錢檢測系統,互聯網的入侵檢測系統等。
6、統計分析(Statistical Analysis)
????????運用統計方法,結合事物相關的專業知識,從描述事物的數據上去推斷該事物可能存在的內在規律。
????????①聚集統計:計數、求和、求平均值、求最大值和最小值;
????????② 回歸分析,比如線性回歸分析、非線性回歸分析、多元線性和非線性回歸分析等;
????????③ 判別分析:貝葉斯判別、費歇爾判別、非參數判別等;
????????④ 探索性分析,如主元分析、相關分析等等。 ? ? ?
7、新型挖掘任務
????????物聯網、傳感網絡,衛星通訊和 GPS 導航導致許多新的數據類型和數據形式,加之量子計算等新理論,由此產生許多新型數據挖掘任務,如文本數據挖掘、web 數據挖掘、微博數據挖掘、空間數據挖掘、數據流挖掘、不確定性數據挖掘和量子數據挖掘等。
(五)數據挖掘的步驟
1、問題定義
????????弄清楚需要哪些方面的數據(也稱為數據選擇)以及希望挖掘出什么樣的知識,即確定挖掘任務。
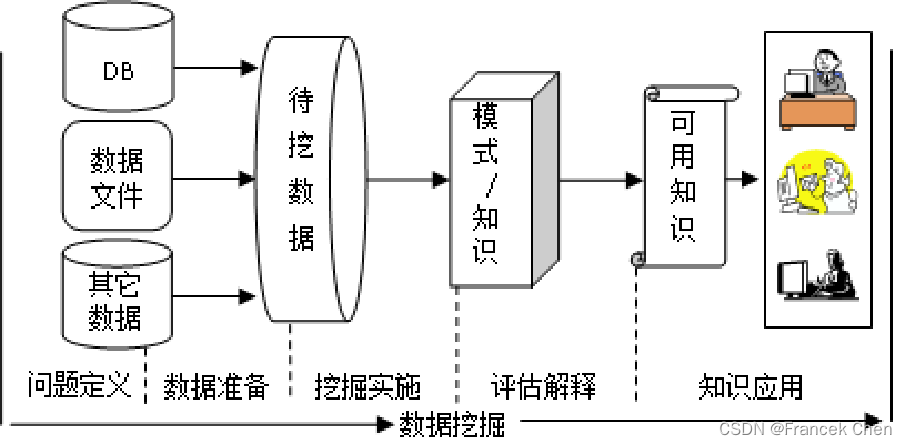
2、數據準備
(1)數據抽取,從各種可用數據源中抽取與挖掘任務相關的數據。
(2)預處理,包括消除噪聲、補充缺損值數據、消除重復記錄、轉換數據類型(連續型數據轉換為離散型數據,或與之相反)等。
(3)數據存儲,即把經過預處理的數據,按照數據挖掘任務和挖掘算法的要求集成起來,重新組織并以數據庫或數據文件等恰當的方式存儲,作為數據挖掘的對象。
????????當挖掘對象是數據倉庫時,一般就不需要數據準備工作了。通常數據挖掘的數據源有多種類型(關系數據庫、XML數據庫、Web頁面和文本文件),因此,數據準備是數據挖掘中十分重要、也是費時最多的一個步驟,可以占到整個數據挖掘過程70%左右的時間。
3、挖掘實施
????????選定數據挖掘算法,編寫應用程序或使用商品化挖掘工具的功能模塊,從數據挖掘對象中挖掘出用戶可能需要的知識或模式,并將這些知識或模式用一種特定的方式,比如表格、圖形等可視化方法表示。
4、評估解釋
????????挖掘人員、企業高管和領域專家,對發現的知識或模式進行評估,剔除冗余或無關的模式,并對余下的知識或模式進行解釋,發現并理解其中有實際應用價值的知識。 如果挖掘出來的知識無法滿足用戶的要求,就需要開始新一輪的數據挖掘,或者回到前面的某一步重新開始。
5、知識應用
????????將經過評估解釋,且被用戶理解的知識,用于商業決策。比如,發現并理解“尿布與啤酒”銷量的關聯規則后,改變商場商品布局,促使兩種商品銷量都得到大幅提升的過程。
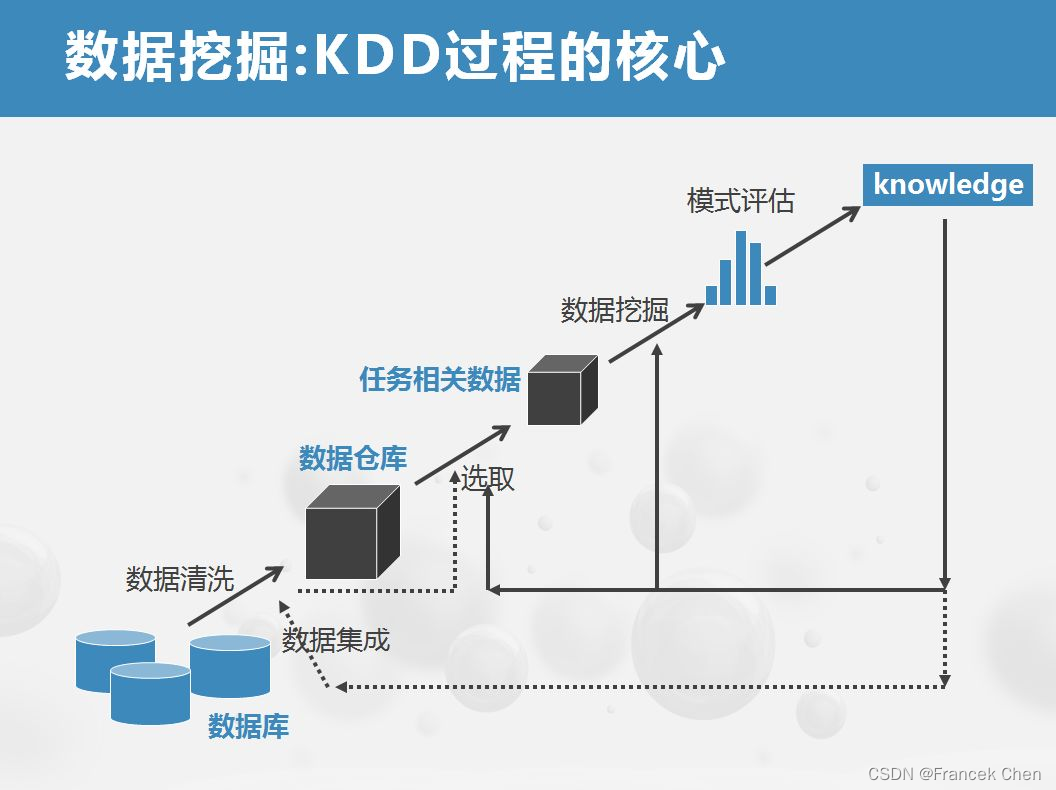
(六)數據挖掘的應用
1、在金融行業的應用
(1)對賬戶進行信用等級的評估。
(2)對龐大的數據進行主成分分析,剔除錯誤矛盾的數據雜質,有效地進行金融市場分析和預測。
(3)分析信用卡的使用模式,“什么樣的人使用信用卡屬于什么樣的模式” 。
(4)從股票交易的歷史數據中得到股票交易的規則或規律。
(5)探測金融政策與金融業行情的相互影響的關聯關系。
2、在保險行業的應用
(1)保險金額度的確定。通過數據挖掘可以得到,對不同行業的人、不同年齡段的人、處于不同社會層次的人,他們的保險金額度應該如何確定。
(2)險種關聯分析。分析購買了某種保險的人是否會同時購買另一種保險。
(3)預測什么樣的顧客將會購買什么樣的新險種。
3、在零售業中的應用
(1)分析顧客的購買行為和習慣。如 “顧客一般購買了野營帳蓬后,過了一段時間就會購買睡袋和背包” 。
(2)分析銷售商品的構成。將商品分成 “暢銷且單位贏利高” 、“暢銷但單位贏利低” 、“暢銷但無贏利” 、“不暢銷但單位贏利高” 、“不暢銷且單位贏利低” 、“滯銷”等多個類別,找出 “滿足什么條件的商品屬于哪一種情況” 。
4、在客戶關系管理中的應用
(1)客戶細分。對大量的客戶分類,提供針對性的產品和服務。
(2)客戶流失和保持分析。從已流失客戶數據找出客戶屬性,服務屬性和客戶消費數據與客戶流失的最終狀態關系。
(3)價值客戶判斷。將客戶分為目前利潤貢獻大的 “成熟期” ;當前利潤貢獻少但未來增長大的 “成長期” ;當無利潤貢獻,為后續增長引擎的 “開拓期” 等幾類。
(4)客戶滿意度分析。客戶滿意度與客戶忠誠度密切相關,隨著客戶滿意度的增加客戶忠誠度也隨之增加。所以,企業與客戶交往的目標就是盡可能的增加客戶滿意度。
5、在信息領域中的應用
(1)網絡信息安全保障。利用數據挖掘技術對網絡的入侵檢測數據進行分析,可從海量的安全事件數據中提取出盡可能多的潛在威脅信息特征,從而發現未知的入侵行為。
(2)互聯網信息挖掘。利用數據挖掘技術,從與 Web 相關的資源和行為中抽取用戶感興趣的、有用的模式和隱含信息。
????????① Web結構挖掘。Web 文檔之間的超級鏈接結構反映了文檔之間的包含、引用或者從屬關系。利用挖掘算法,分析 Web 頁面之間的鏈接引用關系,識別出權威頁面和非法鏈接等。
????????② Web使用挖掘。對網絡日志文件和用戶瀏覽等 Web 使用行為的分析,可以深層次挖掘出用戶的興趣愛好,并建立用戶興趣模型,以便為用戶提供個性化服務,如智能搜索、網頁或個性化商品推薦等。
????????③ ?Web內容挖掘。就是對 Web 頁面內容以及后臺交易數據庫進行挖掘,從中獲取有用知識或模式的過程。
6、在其它行業中的應用
(1)生物信息或基因數據挖掘:利用計算機從海量生物信息中提取有用知識,發現生物知識。
(2)數據挖掘在醫學中的應用:利用分類分析方法,提高一些復雜體征疾病的診斷準確率。對病人的病情和病人的個人信息進行關聯規則分析,可以發現疾病的發病危險因素,便于指導患者如何預防該疾病。對以往病例數據的挖掘,可以歸納出疾病的診斷規則,確定某些疾病的發展模式,從而有針對性的預防新疾病的發生。
(3)其它高科技研究領域:數據挖掘工具在科研工作的作用往往表現在處理大批量的數據,得出一些信息來激發或點燃科研工作者的思路。
(4)社會科學研究領域:如從社會發展的歷史進程中得出社會發展的規律,預測社會發展的趨勢;或從人類發展的進程和人類的社會行為變化中尋求對人類行為規律的答案。
三、數據倉庫與數據挖掘的關系
(一)數據倉庫與數據挖掘的區別
| 序號 | 主要不同點 | 數據倉庫 | 數據挖掘 |
|---|---|---|---|
| 1 | 提出的時間 | 1991年 | 1989年 |
| 2 | 提出的學者 | W.?H.?Inmon?(恩門) | 第11屆國際人工智能聯合會 |
| 3 | 概念的內涵 | 綜合集成的歷史數據 | 挖掘數據中隱藏知識的算法或工具 |
| 4 | 解決的問題 | 數據本身的組織存儲問題 | 數據中隱藏知識的自動發現問題 |
| 5 | 使用的技術 | 數據庫及其相關技術 | 機器學習、模式識別等人工智能技術 |
結論:數據倉庫不是為數據挖掘而生的,反過來數據挖掘也不是為數據倉庫而活的。它們是支持決策的兩個相對獨立的知識體系。
(二)數據倉庫與數據挖掘的聯系
????????數據倉庫(DW)和數據挖掘(DM)都是為決策支持而提出的,其聯系可以概括為以下幾個方面。
(1)DW 為 DM 提供了更好的、更廣泛的數據源。因為 DW 存有來自企業內部和外部較長時間的歷史數據。
(2)DW 為 DM 提供了新的數據支持平臺。DW 的只讀方式,集成更新專門的機制(ETL)保證 DM 效率更高。
(3)DW 為 DM 提供了方便。無需自己動手抽取集成數據。
(4)DM 為 DW 提供了更好的決策支持工具。DW 無決策工具。
(5)DM 為 DW 的數據組織提出了更高的要求。DW 不僅滿足 OLAP 需要,還應滿足 DM 需要。
(6)DM 為 DW 提供了廣泛的技術支持。 一個中心(決策支持),兩個基本點(DW,DM)。



)

及其常見組件)





)







