1、說一說Java提供的常見集合?(畫一下集合結構圖)
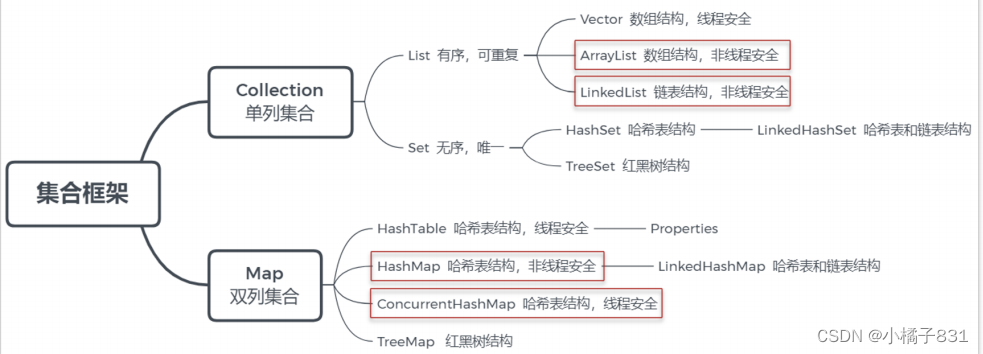
在java中提供了量大類的集合框架,主要分為兩類:
第一個是Collection 屬于單列集合,第二個是Map 屬于雙列集合
在Collection中有兩個子接口List和Set。在平常開發的過程中用的比較多的list接口中的實現類ArrarList和LinkedList。 在Set接口中有實現類HashSet和TreeSet。
在map接口中有很多的實現類,平時比較常見的是HashMap、TreeMap,還有一個線程安全的map:ConcurrentHashMap。
2、ArrayList底層是如何實現的?
我閱讀過arraylist的源碼,我主要說一下add方法吧
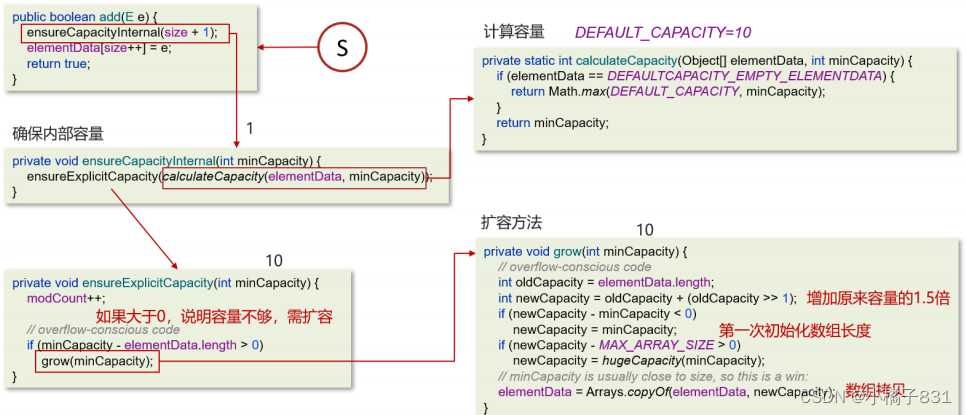
第一:確保數組已使用長度(size)加1之后足夠存下下一個數據
第二:計算數組的容量,如果當前數組已使用長度+1后的大于當前的數組長
度,則調用grow方法擴容(原來的1.5倍)
第三:確保新增的數據有地方存儲之后,則將新元素添加到位于size的位置上。
第四:返回添加成功布爾值。
3、ArrayList list=new ArrayList(10)中的list擴容幾次?
在ArrayList的源碼中提供了一個帶參數的構造方法,這個參數就是指定的集合初始長度,所以給了一個10的參數,就是指定了集合的初始長度是10,這里面并沒有擴容。
4、如何實現數組和List之間的轉換?
數組轉list,可以使用jdk自動的一個工具類Arrars,里面有一個asList方法
可以轉換為數組。
List 轉數組,可以直接調用list中的toArray方法,需要給一個參數,指定數組的類型,需要指定數組的長度。
5、用Arrays.asList轉List后,如果修改了數組內容,list受影響嗎?List用toArray轉數組后,如果修改了List內容,數組受影響嗎?
Arrays.asList轉換list之后,如果修改了數組的內容,list會受影響,因為它的底層使用的Arrays類中的一個內部類ArrayList來構造的集合,在這個集合的構造器中,把我們傳入的這個集合進行了包裝而已,最終指向的都是同一個內存地址。
list用了toArray轉數組后,如果修改了list內容,數組不會影響,當調用了toArray以后,在底層是它是進行了數組的拷貝,跟原來的元素就沒啥關系了,所以即使list修改了以后,數組也不受影響。
6、ArrayList 和 LinkedList 的區別是什么?
它們兩個主要是底層使用的數據結構不一樣,ArrayList 是動態數組,LinkedList 是雙向鏈表。數組易于查詢操作,鏈表易于增刪操作。
7、ArrayList和LinkedList都不是線程安全的,是如何解決這個的線程安全問題的?
主要有兩種解決方案:
第一:我們使用這個集合,優先在方法內使用,定義為局部變量,這樣的話,就不會出現線程安全問題。
第二:如果非要在成員變量中使用的話,可以使用線程安全的集合來替代
ArrayList可以通過Collections 的 synchronizedList 方法將 ArrayList 轉換成線程安全的容器后再使用。
LinkedList 換成ConcurrentLinkedQueue來使用。
8、說一下HashMap的實現原理?
它主要分為了一下幾個部分:
1,底層使用hash表數據結構,即數組+(鏈表 | 紅黑樹)
2,添加數據時,計算key的值確定元素在數組中的下標key相同則替換不同則存入鏈表或紅黑樹中
3,獲取數據通過key的hash計算數組下標獲取元素
9、HashMap的jdk1.7和jdk1.8有什么區別?
JDK1.8之前采用的拉鏈法,數組+鏈表
JDK1.8之后采用數組+鏈表+紅黑樹,鏈表長度大于8且數組長度大于64則會鏈表轉化為紅黑樹,紅黑樹拆分成的樹結點小于等于6個會轉化為鏈表。
10、你能說下HashMap的put方法的具體流程嗎?
1.判斷鍵值對數組table是否為空或為null,否則執行resize()進行擴容(初始化)
2. 根據鍵值key計算hash值得到數組索引
3. 判斷table[i]==null,條件成立,直接新建節點添加
4. 如果table[i]==null ,不成立
判斷table[i]的首個元素是否和key一樣,如果相同直接覆蓋value
判斷table[i] 是否為treeNode,即table[i] 是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對
遍歷table[i],鏈表的尾部插入數據,然后判斷鏈表長度是否大于8,大于8的話把鏈表轉換為紅黑樹,在紅黑樹中執行插入操 作,遍歷過程中若發現key已經存在直接覆蓋value
5.插入成功后,判斷實際存在的鍵值對數量size是否超多了最大容量threshold(數組長度*0.75),如果超過,進行擴容。
11、能講一講HashMap的擴容機制嗎?
1.在添加元素或初始化的時候需要調用resize方法進行擴容,第一次添加數據初始化數組長度為16,以后每次每次擴容都是達到了擴容閾值(數組長度 * 0.75)
2.每次擴容的時候,都是擴容之前容量的2倍;
3.擴容之后,會新創建一個數組,需要把老數組中的數據挪動到新的數組中
4.沒有hash沖突的節點,則直接使用 e.hash & (newCap - 1) 計算新數組的索引位置
5.如果是紅黑樹,走紅黑樹的添加
6.如果是鏈表,則需要遍歷鏈表,可能需要拆分鏈表,判斷(e.hash & oldCap)是否為0,該元素的位置要么停留在原始位置,要么移動到原始位置+增加的數組大小這個位置上
12、你了解hashMap的尋址算法嗎?
這個哈希方法首先計算出key的hashCode值,然后通過這個hash值右移16位后的二進制進行按位異或運算得到最后的hash值。
在putValue的方法中,計算數組下標的時候使用hash值與數組長度取模得到存儲數據下標的位置,hashmap為了性能更好,并沒有直接采用取模的方式,而是使用了數組長度-1 得到一個值,用這個值按位與運算hash值,最終得到數組的位置。
13、為什么HashMap的數組長度一定是2的次冪?
hashmap這么設計主要有兩個原因:
第一:
計算索引時效率更高:如果是 2 的 n 次冪可以使用位與運算代替取模
第二:
擴容時重新計算索引效率更高:在進行擴容是會進行判斷 hash值按位與運算舊數組長度是否 == 0
如果等于0,則把元素留在原來位置 ,否則新位置是等于舊位置的下標+舊數組長度
14、你知道hashmap在1.7情況下的問題嗎?
存在死循環問題
jdk7的的數據結構是:數組+鏈表
在數組進行擴容的時候,因為鏈表是頭插法,在進行數據遷移的過程中,有可能導致死循環
當然,JDK 8 將擴容算法做了調整,不再將元素加入鏈表頭(而是保持與擴容前一樣的順序),尾插法,就避免了jdk7中死循環的問題
15、hashmap是線程安全的嗎,如果不安全怎么做,講下其原理?
不是線程安全的
我們可以采用ConcurrentHashMap進行使用,它是一個線程安全的
HashMap,jdk1.7和1.8也做了很多調整。
JDK1.7的底層采用是分段的數組+鏈表 實現
JDK1.8 采用的數據結構跟HashMap1.8的結構一樣,數組+鏈表/紅黑二叉樹
在jdk1.7中 ConcurrentHashMap 里包含一個 Segment 數組。Segment 的結構和HashMap類似,是一 種數組和鏈表結構,一個 Segment 包含一個HashEntry 數組,每個 HashEntry 是一個鏈表結構 的元素,每個 Segment 守護著一個HashEntry數組里的元素,當對 HashEntry 數組的數據進行修 改時,必須首先獲得對應的 Segment的鎖。
Segment 是一種可重入的鎖 ReentrantLock,每個 Segment 守護一個
HashEntry 數組里得元 素,當對 HashEntry 數組的數據進行修改時,必須首先獲得對應的 Segment 鎖
在jdk1.8中的ConcurrentHashMap 做了較大的優化,性能提升了不少。首先是它的數據結構與jdk1.8的hashMap數據結構完全一致。其次是放棄了Segment的設計,取而代之的是采用Node + CAS + Synchronized來保 證并發安全進行實現,synchronized只鎖定當前鏈表或紅黑二叉樹的首節點,這樣只要hash不沖 突,就不會產生并發 , 效率得到提升
16、HashSet與HashMap的區別?
HashSet底層其實是用HashMap實現存儲的, HashSet封裝了一系列HashMap的方法. 依靠HashMap來存儲元素值,(利用hashMap的key鍵進行存儲), 而value值默認為Object對象. 所以HashSet也不允許出現重復值, 判斷標準和HashMap判斷標準相同, 兩個元素的hashCode相等并且通過equals()方法返回true。
17、HashTable與HashMap的區別?
第一,數據結構不一樣,hashtable是數組+鏈表,hashmap在1.8之后改為了數組+鏈表+紅黑樹
第二,hashtable存儲數據的時候都不能為null,而hashmap是可以的
第三,hash算法不同,hashtable是用本地修飾的hashcode值,而hashmap經常了二次hash
第四,擴容方式不同,hashtable是當前容量翻倍+1,hashmap是當前容量翻倍
第五,hashtable是線程安全的,操作數據的時候加了鎖synchronized,
hashmap不是線程安全的,效率更高一些
在實際開中不建議使用HashTable,在多線程環境下可以使用
ConcurrentHashMap類





:Docker 中的基本概念)

)


測試指南)







)
