基礎介紹
Stable Diffusion 是一個文本到圖像的生成模型,它能夠根據用戶輸入的文本提示(prompt)生成相應的圖像。在這個模型中,CLIP(Contrastive Language-Image Pre-training)模型扮演了一個關鍵的角色,尤其是在將文本輸入轉換為機器可以理解的形式方面。
CLIP 模型最初由 OpenAI 開發,它是一個多模態預訓練模型,能夠理解圖像和文本之間的關系。CLIP 通過在大量的圖像和文本對上進行訓練,學習到了一種能夠將文本描述和圖像內容對齊的表示方法。這種表示方法使得 CLIP 能夠理解文本描述的內容,并將其與圖像內容進行匹配。
在 Stable Diffusion 中,CLIP 的文本編碼器(Text Encoder)部分被用來將用戶的文本輸入轉換為一系列的特征向量。這些特征向量捕捉了文本的語義信息,并且可以與圖像信息相結合,以指導圖像的生成過程。
貼一下模型結構:
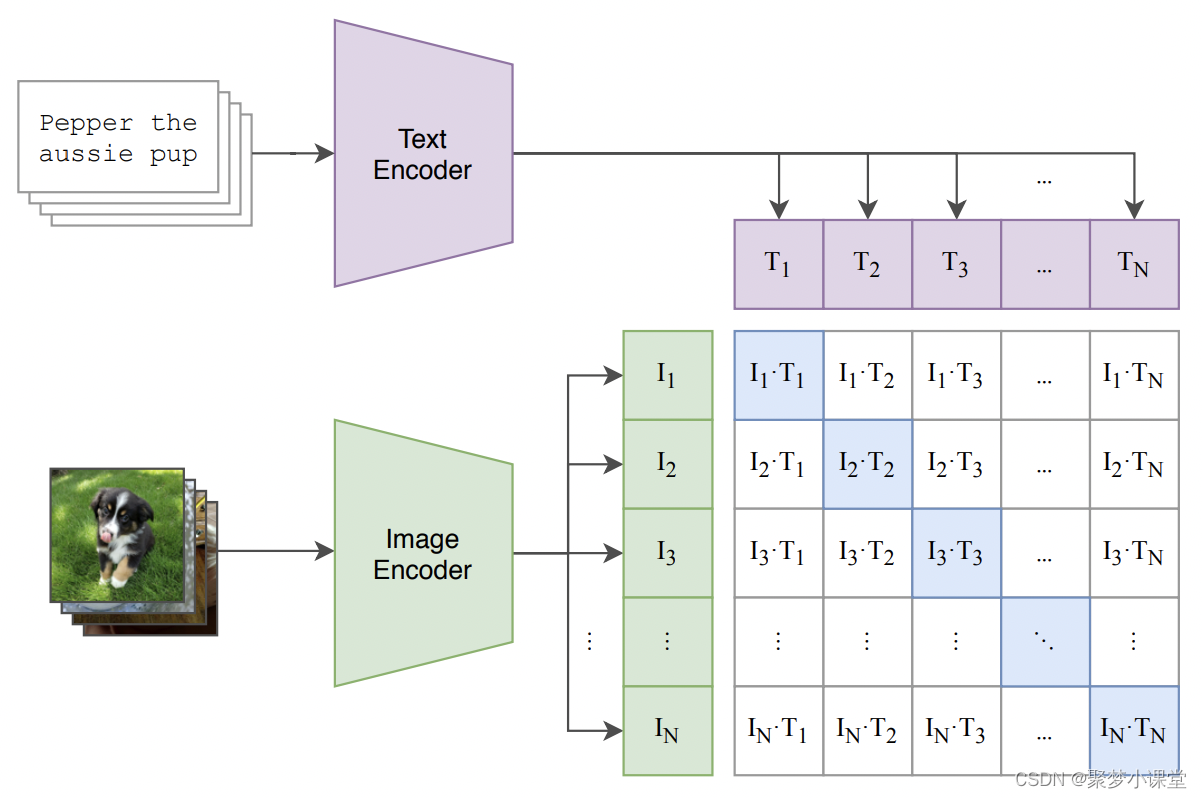
具體來說,當用戶輸入一個文本提示時,CLIP 的文本編碼器會將這個文本轉換成一個固定長度的向量序列。這個向量序列包含了文本的語義信息,并且與現實世界中的圖像有相關性。在 Stable Diffusion 的圖像生成過程中,這些文本特征向量與隨機噪聲圖像一起被送入模型的后續部分,如圖像信息創建器(Image Information Creator)和圖像解碼器(Image Decoder),以生成與文本描述相匹配的圖像。
總結來說,CLIP 模型在 Stable Diffusion 中的作用是將文本輸入轉換為機器可以理解的數值特征,這些特征隨后被用來指導圖像的生成,確保生成的圖像與文本描述相符合。這種結合了文本和圖像理解能力的多模態方法,使得 Stable Diffusion 能夠創造出豐富多樣且與文本描述高度相關的圖像。
關于特征向量的長度
在CLIP模型中,文本編碼器輸出的特征向量的長度是一致的。
CLIP模型的文本編碼器通常是一個基于Transformer架構的神經網絡,它將輸入的文本(例如單詞、短語或句子)轉換成一系列固定長度的向量。這些向量被稱為嵌入(embeddings),它們代表了文本在模型的內部表示空間中的位置。
在CLIP模型的訓練過程中,這些嵌入向量的長度是預先設定的,并且在模型的所有訓練和推理過程中保持不變。例如,如果CLIP模型被訓練為輸出768維的文本嵌入,那么無論輸入的文本長度如何,每個文本輸入都會被轉換成一個長度為768的向量。
這種固定長度的向量表示允許模型處理不同長度的文本輸入,同時保持模型的一致性和可擴展性。對于較長的文本,CLIP模型可能會采用截斷或填充(padding)的方法來確保所有輸入的長度一致。這樣,無論文本的實際長度如何,模型都能夠以統一的方式處理它們。
提示詞長度是不是越長越好
在CLIP模型中,如果輸入的文本提示(prompt)超過了模型處理的最大長度,可能會出現后半部分的文本不被編碼或者不被充分考慮的情況。
CLIP模型在處理文本時,通常會有一個最大長度限制,這意味著它只能有效地處理一定長度內的文本。如果輸入的文本超過了這個長度,模型可能會采取以下幾種策略之一來處理:
-
截斷(Truncation):模型會只考慮文本的前N個標記(tokens),忽略超出部分。這意味著超出長度限制的文本部分不會對最終的特征向量產生影響。
-
摘要(Summarization):模型可能會嘗試生成一個文本的摘要,只保留關鍵信息,但這通常不是CLIP模型的直接功能。
-
滑動窗口(Sliding Window):模型可以采用滑動窗口的方法,對文本的不同部分分別編碼,然后將這些局部編碼組合起來。這種方法可以保留更多文本信息,但可能會丟失一些上下文信息。
在實際應用中,為了確保文本提示能夠有效地影響圖像生成的結果,通常會對輸入的文本進行適當的編輯,使其長度適應模型的處理能力。
Clip模型是如何與unet模型結合使用的呢
CLIP(Contrastive Language-Image Pre-training)模型與UNet模型結合使用通常是為了在圖像生成或圖像處理任務中利用CLIP的文本理解能力和UNet的圖像處理能力。這種結合可以在多種應用中實現,例如在Stable Diffusion等文本到圖像的生成模型中。以下是CLIP與UNet結合使用的一種可能方式:
-
文本編碼:首先,CLIP的文本編碼器(Text Encoder)部分用于處理用戶提供的文本提示(prompt)。它將文本轉換為一系列的特征向量(text embeddings),這些向量捕捉了文本的語義信息。
-
圖像編碼:UNet結構通常用于圖像的編碼和解碼。在圖像生成任務中,UNet的編碼器(Encoder)部分可以將輸入的圖像或噪聲數據編碼為一個隱含向量(latent vector),而解碼器(Decoder)部分則可以從這個隱含向量重建圖像。
-
結合文本和圖像特征:在結合CLIP和UNet時,CLIP提取的文本特征可以與UNet處理的圖像特征進行交互。例如,文本特征可以作為注意力機制的一部分,引導UNet在圖像生成過程中關注與文本描述相關的圖像區域。
-
迭代優化:在生成過程中,UNet可能會進行多次迭代,每次迭代都會根據CLIP提供的文本特征來優化圖像。這可以通過交叉注意力(cross-attention)機制實現,其中文本特征作為注意力的鍵(key)和值(value),而UNet的特征作為查詢(query)。
-
生成圖像:通過這種結合,模型能夠生成與文本提示語義上一致的圖像。在迭代過程中,模型不斷調整圖像,直到生成的圖像與文本描述相匹配。
clip skip是什么意思
Stable Diffusion的應用中,Clip Skip是一個參數,它用于控制圖像生成過程中的細分程度。這個參數允許用戶在生成圖像時跳過CLIP模型中的一些層,從而影響生成圖像的細節和風格。
具體來說,Clip Skip的作用包括:
-
控制生成速度:
Clip Skip的值越大,Stable Diffusion在生成圖像時會跳過更多的層,這可以加快圖像生成的速度。但是,這可能會犧牲圖像的質量,因為跳過的層可能包含了對生成細節重要的信息。 -
調整圖像質量:較低的
Clip Skip值意味著生成過程中會使用更多的層,這通常會導致更詳細和精確的圖像。相反,較高的Clip Skip值可能會導致圖像質量下降,因為模型在生成過程中省略了一些細節。 -
靈活性和多樣性:通過調整
Clip Skip的值,用戶可以根據他們的需求和偏好來控制生成圖像的風格和細節程度。這為用戶提供了在速度和質量之間做出權衡的靈活性。
在實際應用中,用戶可能需要通過實驗來找到最佳的Clip Skip值,以便在保持所需圖像質量的同時,實現合理的生成速度。例如,如果用戶需要快速生成草圖或概念圖,可能會選擇較高的Clip Skip值;而如果用戶追求高質量的藝術作品,可能會選擇較低的Clip Skip值。
這里是聚夢小課堂,如果對你有幫助的話,記得點個贊哦~



)





WinRT 的錯誤和異常處理)



)





