🍨 本文為[🔗365天深度學習訓練營學習記錄博客🍦 參考文章:365天深度學習訓練營🍖 原作者:[K同學啊 | 接輔導、項目定制]\n🚀 文章來源:[K同學的學習圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)Seq2Seq模型是一種深度學習模型,用于處理序列到序列的任務,它由兩個主要部分組成:編碼器(Encoder)和解碼器(Decoder)。
-
編碼器(Encoder): 編碼器負責將輸入序列(例如源語言句子)編碼成一個固定長度的向量,通常稱為上下文向量或編碼器的隱藏狀態。編碼器可以是循環神經網絡(RNN)、長短期記憶網絡(LSTM)或者變種如門控循環單元(GRU)等。編碼器的目標是捕捉輸入序列中的語義信息,并將其編碼成一個固定維度的向量表示。
-
解碼器(Decoder): 解碼器接收編碼器生成的上下文向量,并根據它來生成輸出序列(例如目標語言句子)。解碼器也可以是RNN、LSTM、GRU等。在訓練階段,解碼器一次生成一個詞或一個標記,并且其隱藏狀態從一個時間步傳遞到下一個時間步。解碼器的目標是根據上下文向量生成與輸入序列對應的輸出序列。
在訓練階段,Seq2Seq模型的目標是最大化目標序列的條件概率給定輸入序列。為了實現這一點,通常使用了一種稱為教師強制(Teacher Forcing)的技術,即將目標序列中的真實標記作為解碼器的輸入。但是,在推理階段(即模型用于生成新的序列時),解碼器則根據先前生成的標記生成下一個標記,直到生成一個特殊的終止標記或達到最大長度為止。
下面演示了如何使用PyTorch實現一個簡單的Seq2Seq模型,用于將一個序列翻譯成另一個序列。這里我們將使用一個虛構的數據集來進行簡單的法語到英語翻譯。
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader, Dataset# 定義數據集
class SimpleDataset(Dataset):def __init__(self, data):self.data = datadef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]# 定義Encoder
class Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hidden_dim):super(Encoder, self).__init__()self.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.GRU(emb_dim, hidden_dim)def forward(self, src):embedded = self.embedding(src)outputs, hidden = self.rnn(embedded)return outputs, hidden# 定義Decoder
class Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hidden_dim):super(Decoder, self).__init__()self.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.GRU(emb_dim, hidden_dim)self.fc_out = nn.Linear(hidden_dim, output_dim)def forward(self, input, hidden):input = input.unsqueeze(0)embedded = self.embedding(input)output, hidden = self.rnn(embedded, hidden)prediction = self.fc_out(output.squeeze(0))return prediction, hidden# 定義Seq2Seq模型
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder, device):super(Seq2Seq, self).__init__()self.encoder = encoderself.decoder = decoderself.device = devicedef forward(self, src, trg, teacher_forcing_ratio=0.5):batch_size = trg.shape[1]trg_len = trg.shape[0]trg_vocab_size = self.decoder.fc_out.out_featuresoutputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)encoder_outputs, hidden = self.encoder(src)input = trg[0,:]for t in range(1, trg_len):output, hidden = self.decoder(input, hidden)outputs[t] = outputteacher_force = np.random.rand() < teacher_forcing_ratiotop1 = output.argmax(1) input = trg[t] if teacher_force else top1return outputs# 設置參數
INPUT_DIM = 10
OUTPUT_DIM = 10
ENC_EMB_DIM = 32
DEC_EMB_DIM = 32
HID_DIM = 64
N_LAYERS = 1
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5# 實例化模型
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Seq2Seq(enc, dec, device).to(device)# 打印模型結構
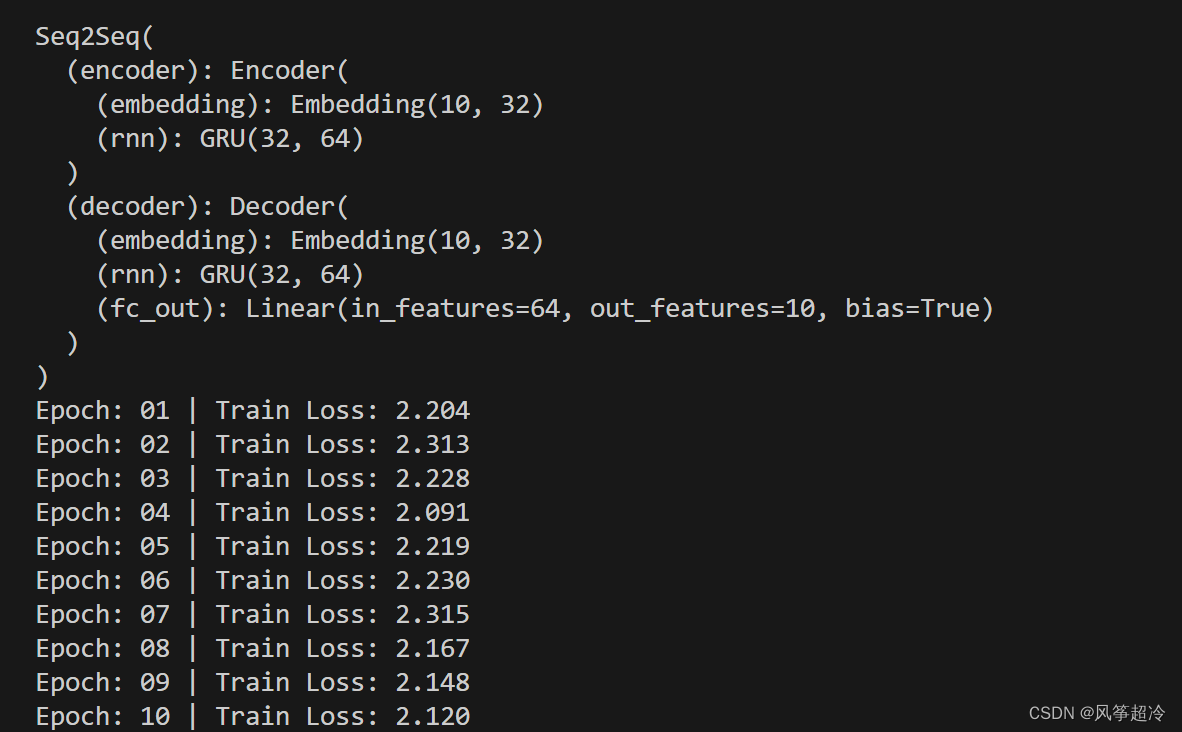
print(model)# 定義訓練函數
def train(model, iterator, optimizer, criterion, clip):model.train()epoch_loss = 0for i, batch in enumerate(iterator):src, trg = batchsrc = src.to(device)trg = trg.to(device)optimizer.zero_grad()output = model(src, trg)output_dim = output.shape[-1]output = output[1:].view(-1, output_dim)trg = trg[1:].view(-1)loss = criterion(output, trg)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()epoch_loss += loss.item()return epoch_loss / len(iterator)# 定義測試函數
def evaluate(model, iterator, criterion):model.eval()epoch_loss = 0with torch.no_grad():for i, batch in enumerate(iterator):src, trg = batchsrc = src.to(device)trg = trg.to(device)output = model(src, trg, 0) # 關閉teacher forcingoutput_dim = output.shape[-1]output = output[1:].view(-1, output_dim)trg = trg[1:].view(-1)loss = criterion(output, trg)epoch_loss += loss.item()return epoch_loss / len(iterator)# 示例數據
train_data = [(torch.tensor([1, 2, 3]), torch.tensor([3, 2, 1])),(torch.tensor([4, 5, 6]), torch.tensor([6, 5, 4])),(torch.tensor([7, 8, 9]), torch.tensor([9, 8, 7]))]# 超參數
BATCH_SIZE = 3
N_EPOCHS = 10
LEARNING_RATE = 0.001
CLIP = 1# 數據集與迭代器
train_dataset = SimpleDataset(train_data)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)# 定義損失函數與優化器
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss()# 訓練模型
for epoch in range(N_EPOCHS):train_loss = train(model, train_loader, optimizer, criterion, CLIP)print(f'Epoch: {epoch+1:02} | Train Loss: {train_loss:.3f}')
:概念、結構與實現機制(2))






)

:Docker CLI 基本用法解析)


)



)


